C++ 变量:深入理解与应用
C++ 变量:深入理解与应用
一、引言
C++作为一种强大且广泛应用的编程语言,变量是其程序设计的基础构建块之一。变量允许我们在程序中存储、操作和访问数据,对于实现各种复杂的功能至关重要。正确地理解和使用变量,能够编写出高效、可靠且易于维护的 C++ 程序。从简单的数值计算到复杂的系统开发,变量在其中都扮演着关键角色,因此深入探究 C++ 变量的各个方面具有重要的实践意义和理论价值。
二、变量的基本概念
(一)定义与声明
在 C++ 中,变量的定义是为变量分配内存空间并指定其数据类型。例如:
int num; // 定义一个名为 num 的整型变量
这里,int 是数据类型,表示整数,num 是变量名。变量声明则是告诉编译器变量的名称和类型,但并不为其分配内存空间(在某些情况下,如在多个文件中使用同一个变量时,声明可以让编译器知道该变量的存在)。例如:
extern int anotherNum; // 声明一个名为 anotherNum 的整型变量,其内存空间在其他地方分配
通常情况下,变量应该先定义后使用,但在某些特定的编程结构中,如函数原型中,变量声明可以提前出现,以告知编译器函数参数的类型信息。
(二)变量名规则
变量名必须遵循一定的命名规则,以保证程序的可读性和正确性。变量名可以由字母、数字和下划线组成,但必须以字母或下划线开头。C++ 是区分大小写的语言,因此 myVariable 和 myvariable 是两个不同的变量名。此外,变量名不能是 C++ 的关键字(如 int、if、while 等),因为这些关键字在语言中具有特定的含义和用途。选择有意义的变量名是良好的编程习惯,例如使用 studentCount 来表示学生的数量,而不是使用简单的 s 或 x 等无明确含义的名称,这样可以使代码更容易理解和维护。
(三)数据类型与变量
C++ 提供了丰富的数据类型,每种数据类型决定了变量所占用的内存空间大小以及能够存储的数据范围和精度。
- 基本数据类型:
- 整型:包括
short(短整型)、int(整型)、long(长整型)和long long(长长整型),用于存储整数值。例如,short age = 20;可以存储一个较小范围的整数,而long long population = 10000000000LL;(注意后面的LL后缀表示长长整型常量)可以处理更大的整数值。不同整型类型占用的字节数因编译器和系统而异,但通常short占用 2 字节,int占用 4 字节,long占用 4 字节(在某些系统上可能为 8 字节),long long占用 8 字节。 - 浮点型:有
float(单精度浮点型)和double(双精度浮点型),用于表示带有小数部分的数值。例如,float price = 9.99f;(注意后面的f后缀表示单精度浮点型常量)和double pi = 3.14159265358979323846;。float通常占用 4 字节,提供大约 6 - 7 位有效数字的精度;double占用 8 字节,具有更高的精度,大约为 15 - 16 位有效数字,适用于需要更高精度的科学计算和金融计算等领域。 - 字符型:
char类型用于存储单个字符,例如char grade = 'A';。char类型在内存中通常占用 1 字节,其可以表示 ASCII 字符集中的字符,包括字母、数字、标点符号和控制字符等。 - 布尔型:
bool类型只有两个取值,true和false,用于表示逻辑真和假。例如,bool isReady = true;。在内存中,bool类型通常占用 1 字节,但有些编译器可能会对其进行优化,使其占用更少的空间。
- 整型:包括
- 派生数据类型:
- 数组:是一组相同类型元素的集合,可以通过下标访问其中的元素。例如,
int scores[5];定义了一个包含 5 个整数元素的数组,用于存储学生的成绩。数组在内存中是连续存储的,通过下标可以快速访问元素,但数组的大小在定义时必须确定,并且不能动态改变(在 C++ 中,标准数组不支持动态扩展或收缩,但可以通过一些技巧如动态分配内存来实现类似的效果)。 - 指针:指针是一种特殊的变量,它存储的是另一个变量的内存地址。例如,
int *ptr;定义了一个指向整数的指针变量。指针可以用于动态内存分配、函数参数传递(通过指针可以在函数内部修改外部变量的值)、数据结构的实现(如链表、树等),但指针的使用需要谨慎,因为不正确的指针操作可能会导致内存泄漏、悬空指针、越界访问等问题,从而引发程序崩溃或产生不可预测的结果。 - 引用:引用是变量的别名,它必须在定义时初始化,并且在之后的使用中不能再绑定到其他变量。例如,
int num = 10; int &ref = num;这里ref就是num的引用,对ref的操作等同于对num的操作。引用在函数参数传递中可以避免复制大型对象的开销,同时也使得函数能够直接修改传入的参数值,增强了函数与调用者之间的数据交互能力,但引用的使用也需要遵循一定的规则,以确保程序的正确性和可读性。 - 结构体:结构体允许将不同类型的数据成员组合在一起,形成一个新的自定义数据类型。例如:
- 数组:是一组相同类型元素的集合,可以通过下标访问其中的元素。例如,
struct Student {std::string name;int age;float score;
};
Student stu1;
stu1.name = "John";
stu1.age = 20;
stu1.score = 85.5f;
结构体在实际编程中常用于表示具有多个属性的实体,如学生、员工、产品等,通过将相关的数据封装在一个结构体中,可以提高代码的组织性和可读性,方便对复杂数据的管理和操作。
- 类:类是 C++ 面向对象编程的核心,它不仅可以包含数据成员,还可以包含成员函数,用于对数据进行操作和处理。类具有封装、继承和多态等特性,使得程序的设计更加灵活和可扩展。例如:
class Rectangle {
public:// 成员函数void setWidth(int w) { width = w; }void setHeight(int h) { height = h; }int getArea() { return width * height; }
private:// 数据成员int width;int height;
};
Rectangle rect;
rect.setWidth(5);
rect.setHeight(3);
int area = rect.getArea();
在这个例子中,Rectangle 类封装了矩形的宽度和高度数据成员,并提供了设置宽度、设置高度和计算面积的成员函数,通过类的实例化对象可以方便地操作和获取矩形的相关信息,体现了面向对象编程的优势,即将数据和对数据的操作紧密结合在一起,提高了代码的安全性和可维护性。
三、变量的作用域与生命周期
(一)作用域
变量的作用域决定了变量在程序中可见和可访问的范围。
- 局部变量:在函数内部定义的变量称为局部变量,其作用域仅限于该函数内部。例如:
void myFunction() {int localVar = 10; // localVar 是局部变量,只能在 myFunction 函数内部使用std::cout << localVar << std::endl;
}
当函数执行结束后,局部变量所占用的内存空间会被自动释放,其生命周期也随之结束。局部变量的优点是可以在函数内部使用独立的变量名,避免与其他函数中的变量发生冲突,同时也使得函数的逻辑更加清晰和独立,有利于代码的模块化设计和调试。
- 全局变量:在所有函数外部定义的变量称为全局变量,其作用域从定义点开始,到整个程序文件结束。例如:
int globalVar = 20; // globalVar 是全局变量,可以在整个程序文件中访问(在其他文件中使用时需要声明)void anotherFunction() {std::cout << globalVar << std::endl; // 可以在 anotherFunction 函数中访问 globalVar
}
全局变量在整个程序运行期间都存在,占用内存空间,直到程序结束才会被释放。虽然全局变量可以方便地在多个函数之间共享数据,但过度使用全局变量可能会导致程序的可读性变差,因为数据的来源和修改位置可能不明确,容易引发意想不到的错误,而且全局变量在多线程环境下还可能出现数据竞争等问题,因此在使用全局变量时需要谨慎考虑,并遵循一定的编程规范。
- 块作用域变量:除了函数内部,在代码块(如
if语句、for循环等内部的花括号括起来的部分)中定义的变量也具有块作用域。例如:
if (true) {int blockVar = 30; // blockVar 是块作用域变量,只能在这个 if 语句块内使用std::cout << blockVar << std::endl;
}
块作用域变量的生命周期从定义点开始,到块结束时结束,当块执行完毕,变量所占用的内存空间会被释放。这种变量的作用域限制在块内,有助于减少变量的可见范围,避免不必要的变量冲突和错误,提高程序的安全性和可靠性。
(二)生命周期
变量的生命周期是指变量从创建到销毁所经历的时间段。
- 自动存储期变量:局部变量和块作用域变量通常具有自动存储期,其生命周期由程序的执行流程自动管理。当程序进入变量所在的作用域时,变量被创建并分配内存空间,当程序离开该作用域时,变量被自动销毁,内存空间被回收。这种自动管理的方式使得程序员无需手动分配和释放这些变量的内存,减少了内存管理的复杂性,但也需要注意变量的作用域和生命周期,避免在变量生命周期结束后仍然使用该变量,导致未定义行为。
- 静态存储期变量:通过在变量声明前加上
static关键字,可以使变量具有静态存储期。对于局部静态变量,其生命周期从程序开始执行到程序结束,但作用域仍然局限于定义它的函数或块内。例如:
void staticFunction() {static int staticLocalVar = 0; // 静态局部变量,只会初始化一次,在多次调用函数时其值会保留staticLocalVar++;std::cout << staticLocalVar << std::endl;
}
在这个例子中,staticLocalVar 是静态局部变量,第一次调用 staticFunction 函数时,它被初始化为 0,之后每次调用该函数,staticLocalVar 的值都会在上一次的基础上递增,并且其内存空间在整个程序运行期间都存在,不会因为函数的多次调用和返回而被销毁和重新创建。对于全局静态变量,其作用域仅限于定义它的文件内(在其他文件中不可见,即使使用 extern 声明也不行),生命周期同样是从程序开始到结束,这种特性可以用于在文件内部隐藏一些不希望被其他文件访问的数据,同时保证数据在整个程序运行期间的持久性,例如在一个文件中定义一个全局静态的配置变量,供该文件内的多个函数使用,而不用担心其他文件对其进行意外的修改。
- 动态存储期变量:通过使用
new和delete运算符(在 C++ 11 及以后也可以使用智能指针来更安全地管理动态内存)可以创建和销毁具有动态存储期的变量。例如:
int *dynamicVar = new int(42); // 使用 new 动态分配一个整数内存空间,并初始化为 42
// 使用 dynamicVar 指向的内存空间
delete dynamicVar; // 使用完后,必须使用 delete 释放内存,否则会导致内存泄漏
动态分配的变量生命周期由程序员手动控制,使用 new 分配内存后,变量一直存在,直到使用 delete 显式地释放内存为止。如果在使用完动态分配的内存后没有及时释放,就会导致内存泄漏,即内存空间被占用但无法再被程序使用,随着程序的运行,内存泄漏可能会导致系统内存资源耗尽,从而使程序出现异常甚至崩溃。因此,在使用动态内存分配时,必须严格遵循内存管理的规则,确保正确地分配和释放内存,以保证程序的稳定性和可靠性。
四、变量的初始化与赋值
(一)初始化
变量的初始化是在定义变量的同时为其赋予初始值。初始化变量是一种良好的编程习惯,因为未初始化的变量可能包含随机的垃圾值,这可能会导致程序出现意想不到的错误。例如:
int num1 = 5; // 正确的初始化方式
int num2;
num2 = 10; // 先定义后赋值,这种方式可能会导致在赋值前 num2 包含不确定的值
对于一些复杂的数据类型,如类和结构体,初始化可以通过构造函数来实现,以确保数据成员被正确地初始化。例如:
class Point {
public:Point(int xVal, int yVal) : x(xVal), y(yVal) {} // 构造函数初始化列表
private:int x;int y;
};
Point p1(3, 4); // 使用构造函数初始化 p1 对象
在这个例子中,通过构造函数的初始化列表,将传入的参数值直接赋给数据成员 x 和 y,这种初始化方式比在构造函数体内使用赋值语句更加高效和安全,因为它可以避免不必要的默认构造和赋值操作,同时确保数据成员在对象创建时就被正确初始化,减少了出现错误的可能性。
(二)赋值
赋值是在变量已经定义后,将一个新的值赋给它。例如:
int num = 5;
num = 8; // 将 num 的值从 5 改为 8
对于不同的数据类型,赋值操作的行为和效果可能会有所不同。对于基本数据类型,赋值是直接将新的值覆盖原来的值;对于数组,赋值操作可以逐个元素进行赋值,或者使用一些库函数(如 memcpy 等)进行批量赋值,但需要注意数组越界的问题;对于指针,赋值操作可以改变指针所指向的内存地址,但在进行指针赋值时,需要确保指针指向有效的内存空间,避免出现悬空指针或野指针的情况,例如:
int num1 = 10;
int num2 = 20;
int *ptr1 = &num1;
int *ptr2 = &num2;
ptr1 = ptr2; // 现在 ptr1 指向 num2,原来指向 num1 的指针变成了悬空指针,需要谨慎处理
在使用赋值操作时,还需要注意数据类型的兼容性,避免将不兼容的数据类型赋给变量,否则可能会导致数据丢失或类型转换错误。例如,将一个浮点型值赋给整型变量时,会自动进行截断操作,可能会丢失小数部分的信息:
float f = 3.14f;
int i = f; // i 的值将为 3,小数部分被截断
因此,在进行赋值操作时,需要根据数据类型的特点和程序的需求,谨慎地选择合适的赋值方式,以确保数据的准确性和完整性。
五、变量的存储类别
(一)自动变量(auto)
在 C++ 11 之前,函数内部的局部变量如果没有使用其他存储类别修饰符,默认就是自动变量(auto),其具有自动存储期和块作用域,在程序进入变量所在的块时自动创建,离开块时自动销毁。在 C++ 11 及以后,auto 关键字被赋予了新的含义,用于自动类型推导,例如:
auto num = 5; // num 的类型将被自动推导为 int
这种自动类型推导的功能使得代码编写更加简洁和灵活,尤其是在处理复杂的模板类型或迭代器类型时,可以大大减少代码中冗长的类型声明,提高代码的可读性和编写效率,但同时也需要注意,过度使用自动类型推导可能会使代码的类型信息不够明确,给代码的阅读和理解带来一定的困难,因此在使用时需要根据具体情况权衡利弊,确保代码的清晰性和可维护性。
(二)静态变量(static)
如前所述,static 关键字可以用于修饰局部变量和全局变量,使其具有静态存储期。对于局部静态变量,它在程序的整个生命周期内只初始化一次,并且在多次函数调用之间保持其值不变;对于全局静态变量,它限制了变量的作用域在定义它的文件内,避免了与其他文件中的同名变量发生冲突,同时也提供了一种在文件内部隐藏数据的方式,使得数据的访问和修改更加可控和安全,有助于提高程序的模块化和封装性,减少模块之间的耦合度,方便代码的维护和调试。
(三)寄存器变量(register)
register 关键字用于建议编译器将变量存储在寄存器中,以提高变量的访问速度,因为寄存器的访问速度比内存快得多。例如:
register int count = 0;
然而,这只是一个建议,编译器有权决定是否真正将变量存储在寄存器中。现代编译器在优化代码时,会自动对频繁使用的变量进行寄存器分配,所以在大多数情况下,显式使用 register 关键字的必要性已经降低。而且,由于寄存器数量有限,对于一些较大的数据类型(如结构体、数组等),即使使用了 register 关键字,编译器也可能无法将其全部存储在寄存器中。此外,register 变量不能取地址(因为它可能并不实际存储在内存中),这也限制了它的一些使用场景。所以在使用 register 关键字时,需要谨慎考虑,并且通常只有在对性能有极高要求且经过仔细测试后确定能带来明显性能提升的情况下才建议使用。
(四)外部变量(extern)
extern 关键字主要用于在一个文件中声明另一个文件中定义的全局变量,以便在本文件中使用该变量。例如,在 file1.cpp 中定义了一个全局变量:
// file1.cpp
int globalData = 100;
在 file2.cpp 中,如果要使用这个全局变量,需要使用 extern 进行声明:
// file2.cpp
extern int globalData;void someFunction() {std::cout << globalData << std::endl;
}
这样,file2.cpp 中的函数就能访问到 file1.cpp 中定义的 globalData 变量。extern 关键字的存在使得多个文件可以共享全局变量,方便在大型项目中进行数据的传递和共享,但也需要注意全局变量的滥用可能会导致程序的可维护性变差,因此在使用 extern 声明全局变量时,应该确保变量的定义和使用清晰明确,避免出现命名冲突和数据不一致等问题。
(五)线程本地变量(thread_local)
随着多线程编程的广泛应用,thread_local 关键字在 C++ 11 中被引入,用于定义线程本地变量。每个线程都有自己独立的该变量副本,这意味着不同线程对该变量的修改不会相互影响,保证了数据的线程安全性。例如:
thread_local int threadData = 0;void threadFunction() {threadData++;std::cout << "Thread " << std::this_thread::get_id() << " has threadData = " << threadData << std::endl;
}int main() {std::vector<std::thread> threads;for (int i = 0; i < 5; ++i) {threads.push_back(std::thread(threadFunction));}for (auto& th : threads) {th.join();}return 0;
}
在这个例子中,每个线程都会独立地对自己的 threadData 变量进行递增操作,输出结果将显示每个线程的 threadData 值都是不同的,互不干扰。这种线程本地变量的特性在多线程编程中非常有用,例如可以用于存储每个线程的特定状态信息、线程私有数据等,避免了在多线程环境下使用共享变量时需要进行复杂的同步操作,降低了编程的难度和出错的风险,提高了多线程程序的性能和可靠性。
六、变量在不同编程范式中的应用
(一)过程式编程
在过程式编程中,变量主要用于存储程序执行过程中的中间数据和状态信息。函数之间通过参数传递和返回值来共享数据,变量的作用域和生命周期相对较为明确和简单。例如,在一个计算阶乘的程序中:
int factorial(int n) {int result = 1;for (int i = 1; i <= n; ++i) {result *= i;}return result;
}
这里的 result 和 i 就是过程式编程中典型的局部变量,它们在函数内部定义和使用,用于存储计算过程中的临时结果和循环变量。过程式编程注重算法的实现和数据的处理流程,变量的使用围绕着函数的功能展开,通过合理地定义和使用变量,可以清晰地表达程序的逻辑和算法步骤,使得程序易于理解和调试。
(二)面向对象编程
在面向对象编程中,变量作为类的数据成员,与类的成员函数紧密结合,共同实现类的封装和行为。例如,对于一个表示矩形的类:
class Rectangle {
public:Rectangle(int widthVal, int heightVal) : width(widthVal), height(heightVal) {}int getArea() { return width * height; }int getPerimeter() { return 2 * (width + height); }private:int width;int height;
};
width 和 height 是类的私有数据成员,它们封装了矩形的属性,通过公有的成员函数 getArea 和 getPerimeter 来对外提供对这些数据的访问和操作接口。这种将数据和操作封装在一起的方式,符合面向对象编程的思想,提高了代码的安全性和可维护性。在面向对象编程中,变量的访问通常通过对象来进行,对象的状态通过其数据成员变量来表示,而对象的行为则通过成员函数来实现,变量的作用域和生命周期与对象的生命周期相关联,当对象被创建时,其数据成员变量被初始化并占用内存空间,当对象被销毁时,其数据成员变量也随之被释放,这种机制使得面向对象编程更加贴近现实世界的对象概念,便于组织和管理复杂的程序结构。
(三)泛型编程
在泛型编程中,变量的类型可以通过模板参数进行参数化,从而实现代码的通用性和复用性。例如,在一个简单的模板函数中:
template<typename T>
T add(T a, T b) {return a + b;
}
这里的 a 和 b 是模板函数中的变量,它们的类型 T 在函数调用时根据传入的实际参数类型确定。这种泛型编程的方式使得函数可以适用于不同类型的数据,只要这些数据类型支持相应的操作(如加法运算)。在泛型编程中,变量的类型灵活性得到了极大的提高,通过模板技术,可以编写更加通用和抽象的代码,减少代码的重复编写,提高代码的开发效率和质量。同时,泛型编程中的变量也需要遵循相应的模板规则和类型要求,以确保代码在不同类型参数下的正确性和稳定性。
七、变量的常见错误与调试技巧
(一)常见错误
- 未初始化变量:如前所述,使用未初始化的变量可能会导致程序出现意外的行为,因为它可能包含任意的垃圾值。例如:
int num;
std::cout << num << std::endl; // 输出的是未定义的垃圾值
这种错误可能会在程序的后续计算中引发错误的结果,而且很难排查,因为错误的表现可能与未初始化变量的实际使用位置相距较远。
- 变量作用域错误:在错误的作用域中访问变量或者在变量生命周期结束后仍然使用该变量是常见的错误。例如:
{int localVar = 5;
}
std::cout << localVar << std::endl; // 错误,localVar 在其作用域结束后已被销毁,这里无法访问
这种错误通常会导致编译错误或者运行时的未定义行为,如程序崩溃或产生不正确的结果。
- 类型不匹配:在赋值或进行运算时,使用了不兼容的数据类型,可能会导致数据丢失或类型转换错误。例如:
double num1 = 3.14;
int num2 = num1; // 数据截断,num2 的值将为 3
这种错误可能会使程序的计算结果不准确,而且可能不容易被发现,尤其是在复杂的表达式或函数调用中。
- 指针错误:指针相关的错误较为常见且难以调试,如悬空指针(指针指向的内存已经被释放,但指针仍然存在)、野指针(指针未被初始化就被使用)、内存泄漏(动态分配的内存未被正确释放)等。例如:
int *ptr = new int;
// 忘记释放内存,导致内存泄漏
int num = 10;
int *badPtr;
*badPtr = num; // 野指针错误,badPtr 未初始化就被解引用,可能导致程序崩溃
这些指针错误可能会导致程序出现严重的问题,如系统资源耗尽、程序崩溃或数据损坏等,而且排查起来较为困难,需要对指针的原理和内存管理有深入的理解。
(二)调试技巧
- 使用调试器:现代集成开发环境(IDE)通常都提供了强大的调试器,如 Visual Studio 的调试器、gdb 等。通过设置断点,可以在程序执行到特定位置时暂停程序的运行,查看变量的值、检查程序的执行流程和状态,从而帮助定位错误。在调试过程中,可以逐步执行代码(单步执行),观察变量值的变化,以确定错误发生的位置和原因。
- 输出调试信息:在程序中使用
std::cout等输出语句,将关键变量的值输出到控制台,以便在程序运行过程中查看变量的状态。例如:
int num = 5;
std::cout << "Before modification, num = " << num << std::endl;
num = 10;
std::cout << "After modification, num = " << num << std::endl;
这种方法虽然简单,但对于一些简单的程序或者初步排查问题时非常有效,可以快速了解变量在程序执行过程中的变化情况,帮助定位错误的大致范围。
-
代码审查:仔细检查代码,特别是涉及变量定义、使用和操作的部分,查找可能存在的错误。可以邀请其他程序员进行代码审查,因为不同的人可能会发现一些自己容易忽略的问题。在代码审查过程中,关注变量的命名是否清晰、作用域是否合理、是否存在未初始化或类型不匹配等问题,通过多人的经验和视角,可以提高发现错误的概率,同时也有助于提高代码的质量和规范性。
-
内存分析工具:对于指针相关的错误和内存泄漏问题,可以使用专门的内存分析工具,如 Valgrind(在 Linux 系统下)等。这些工具可以帮助检测内存泄漏、越界访问、悬空指针等问题,并提供详细的错误报告,有助于深入分析和解决与内存相关的复杂错误,确保程序的内存使用安全和稳定。
八、总结
C++ 变量是程序设计的基础和核心元素之一,涵盖了丰富的概念和特性,包括变量的定义、声明、数据类型、作用域、生命周期、存储类别以及在不同编程范式中的应用等方面。正确地理解和运用变量,对于编写高质量、高效、可靠且易于维护的 C++ 程序至关重要。同时,需要注意避免变量使用过程中的常见错误,如未初始化、作用域错误、类型不匹配和指针错误等,并掌握有效的调试技巧,如使用调试器、输出调试信息、代码审查和内存分析工具等,以便能够快速准确地定位和解决变量相关的问题。随着 C++ 语言的不断发展和演进,变量的相关特性也在不断完善和扩展,程序员需要持续学习和更新知识,以充分发挥 C++ 语言的强大功能,应对日益复杂的编程需求和挑战,在软件开发领域中创造出更加优秀的应用程序和系统。
相关文章:

C++ 变量:深入理解与应用
C 变量:深入理解与应用 一、引言 C作为一种强大且广泛应用的编程语言,变量是其程序设计的基础构建块之一。变量允许我们在程序中存储、操作和访问数据,对于实现各种复杂的功能至关重要。正确地理解和使用变量,能够编写出高效、可…...

http报头解析
http报文 http报文主要有两类是常见的,第一类是请求报文,第二类是响应报文,每个报头除了第一行,都是采用键值对进行传输数据,请求报文的第一行主要包括http方法(GET,PUT, POST&#…...

数据库的概念和操作
目录 1、数据库的概念和操作 1.1 物理数据库 1. SQL SERVER 2014的三种文件类型 2. 数据库文件组 1.2 逻辑数据库 2、数据库的操作 2.1 T-SQL的语法格式 2.2 创建数据库 2.3 修改数据库 2.4 删除数据库 3、数据库的附加和分离 1、数据库的概念和操作 1.1 物理数据库…...

《XML Schema 字符串数据类型》
《XML Schema 字符串数据类型》 1. 引言 XML Schema 是一种用于描述和验证 XML 文档结构和内容的语言。在 XML Schema 中,字符串数据类型是一种基本的数据类型,用于表示文本数据。本文将详细介绍 XML Schema 中的字符串数据类型,包括其定义…...

idea 开发Gradle 项目
在Mac上安装完Gradle后,可以在IntelliJ IDEA中配置并使用Gradle进行项目构建和管理。以下是详细的配置和使用指南: 1. 验证Gradle是否已安装 在终端运行以下命令,确保Gradle安装成功: gradle -v如果输出Gradle版本信息ÿ…...

Keepalived + LVS 搭建高可用负载均衡及支持 Websocket 长连接
一、项目概述 本教程旨在助力您搭建一个基于 Keepalived 和 LVS(Linux Virtual Server)的高可用负载均衡环境,同时使其完美适配 Websocket 长连接场景,确保您的 Web 应用能够高效、稳定地运行,从容应对高并发访问&…...

产品经理2025年展望
产品经理作为连接技术、设计与市场需求的桥梁,在快速变化的商业环境中扮演着至关重要的角色。展望2025年,随着技术的不断进步和消费者需求的日益多样化,产品经理的工作将面临更多挑战与机遇。 一、人工智能与自动化深化应用: 到…...

【信息系统项目管理师】第14章:项目沟通管理过程详解
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 一、规划沟通管理1、输入2、工具与技术3、输出二、管理沟通1、输入2、工具与技术3、输出三、监督沟通1、输入2、工具与技术3、输出一、规划沟通管理 定义:规划沟通管理是基于每个干系人或干系人群体的信息需求…...

串口DMA接收数据基本思路
串口DMA接收基本思路 串口DMA接收数据基本思路一、串口处理使用背景及常用处理方法二、串口DMA接收相关思路三、串口DMA发送相关思路 串口DMA接收数据基本思路 一、串口处理使用背景及常用处理方法 单片机经常有串口处理大量数据的场景,常用的串口处理数据方式有如…...

数据结构复习 (二叉查找树,高度平衡树AVL)
1.二叉查找树: 为了更好的实现动态的查找(可以插入/删除),并且不超过logn的时间下达成目的 定义: 二叉查找树(亦称二叉搜索树、二叉排序树)是一棵二叉树,其各结点关键词互异,且中根序列按其关键词递增排列。 等价描述: 二叉查找…...

FreeSWITCH 简单图形化界面39 - Windows安装FreeSWITCH For IPPBX(WSL环境)
FreeSWITCH 简单图形化界面39 - Windows安装FreeSWITCH For IPPBX(WSL环境) 0、界面预览1、部署WSL1.1 安装WSL1.2 安装Windows Terminal1.3 安装WSL配置工具 2、安装Ubuntu24.043、安装FreeSWITCH4、登录Web4.1 80端口占用了 5、测试6、卸载 0、界面预览…...

uniapp - 小程序实现摄像头拍照 + 水印绘制 + 反转摄像头 + 拍之前显示时间+地点 + 图片上传到阿里云服务器
前言 uniapp,碰到新需求,反转摄像头,需要在打卡的时候对上传图片加上水印,拍照前就显示当前时间日期地点,拍摄后在呈现刚才拍摄的图加上水印,最好还需要将图片上传到阿里云。 声明 水印部分代码是借鉴的…...
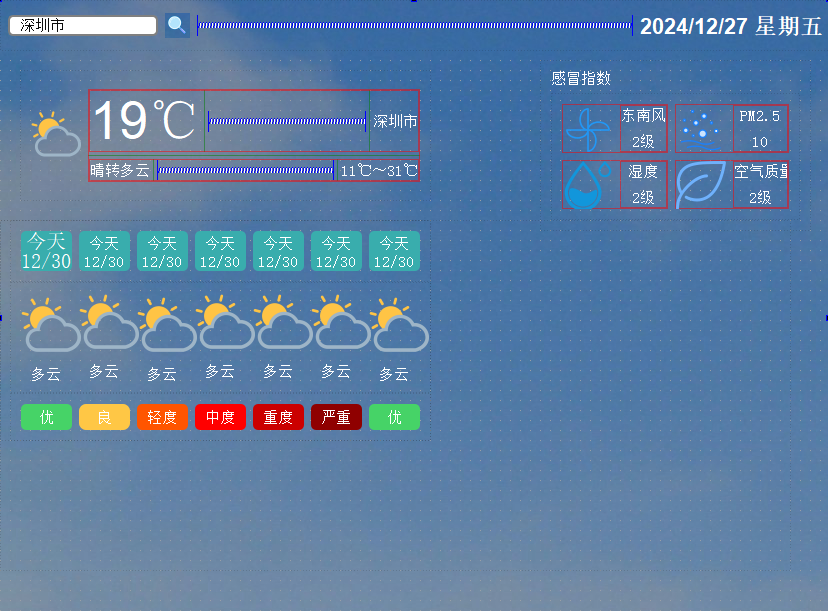
Qt天气预报系统设计界面布局第四部分左边
Qt天气预报系统设计 1、第四部分左边的第一部分1.1添加控件1.2修改控件名字 2、第四部分左边的第二部分2.1添加控件2.2修改控件名字 3、第四部分左边的第三部分3.1添加控件3.2修改控件名字 4、对整个widget04l调整 1、第四部分左边的第一部分 1.1添加控件 拖入一个widget&…...
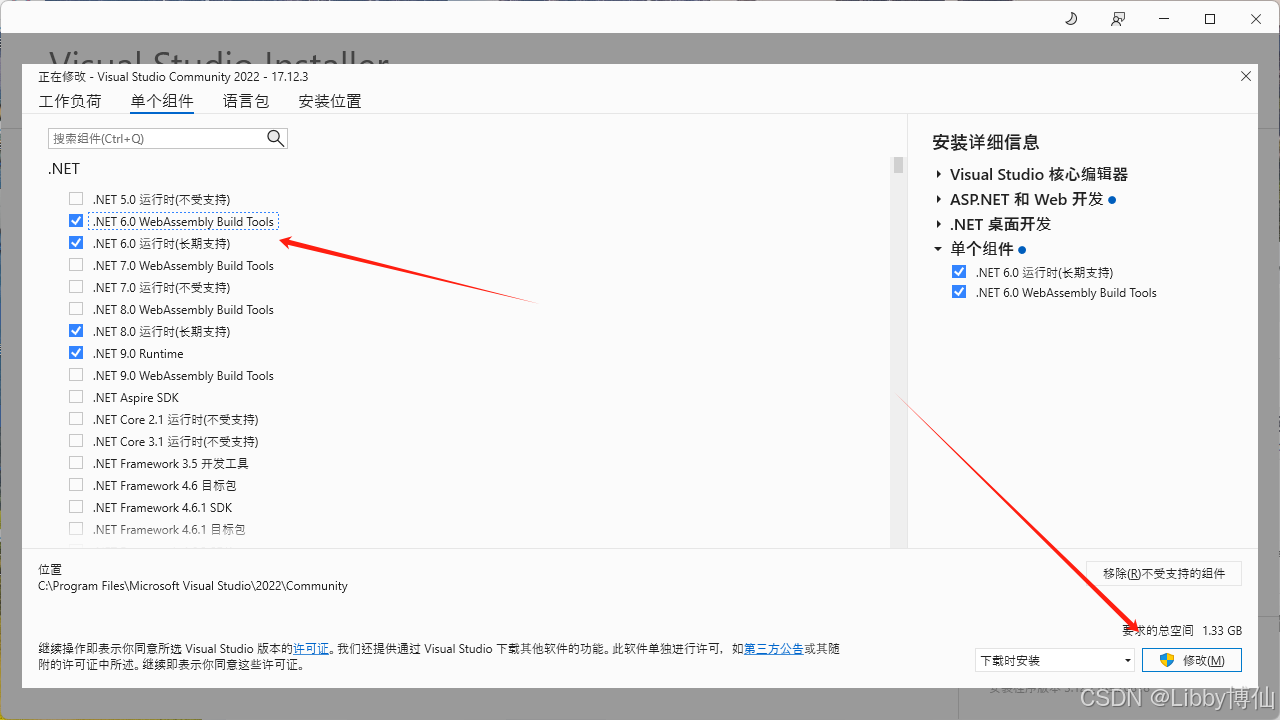
VS无法找到低版本的.net,vs2022创建不了.net6的项目
很多人会遇到安装完vs最新版(目前是2022)之后,创建不了旧版本的.net项目了,比如我在学习.net core 6,我的2022无法创建,只能创建.netcore8的项目,以及又安装了2019,同样无法创建,接下来介绍怎么…...

C++软件设计模式之解释器模式
解释器模式的目的和意图 解释器模式(Interpreter Pattern)是一种行为设计模式,主要用于定义一种语言的文法,并通过该文法解释语言中的句子(表达式)。解释器模式的核心思想是将一个特定的语言表示为其文法规…...
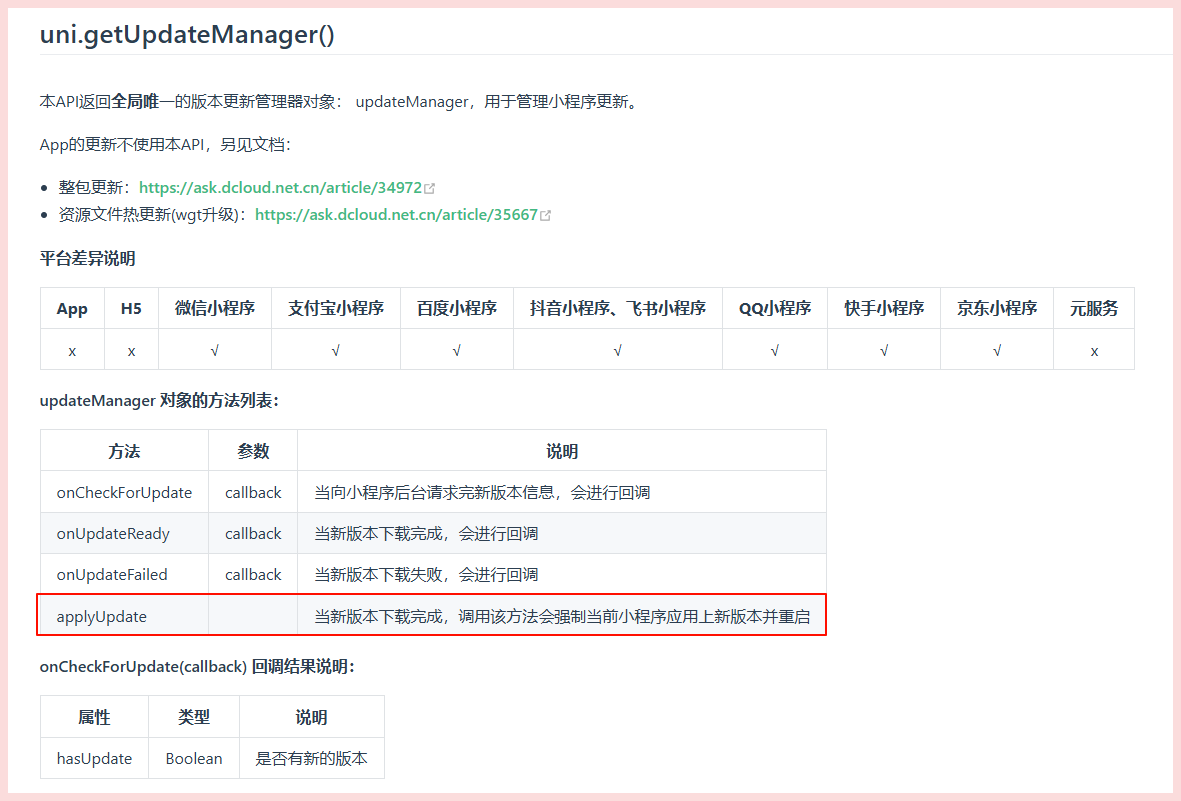
小程序发版后,用户使用时,强制更新为最新版本
为什么要强制更新为最新版本? 在小程序的开发和运营过程中,强制用户更新到最新版本是一项重要的策略,能够有效提升用户体验并保障系统的稳定性与安全性。以下是一些主要原因: 1. 功能兼容 新功能或服务通常需要最新版本的支持&…...
如何使用AI工具cursor(内置ChatGPT 4o+claude-3.5)
⚠️温馨提示: 禁止商业用途,请支持正版,充值使用,尊重知识产权! 免责声明: 1、本教程仅用于学习和研究使用,不得用于商业或非法行为。 2、请遵守Cursor的服务条款以及相关法律法规。 3、本…...

说说缓存使用的具体场景都有哪些?缓存和数据库一致性问题该如何解决?缓存使用常见问题有哪些?
面试官:说说缓存使用的具体场景都有哪些?缓存和数据库一致性问题该如何解决?缓存使用常见问题有哪些? 缓存的具体使用场景有这些: 数据频繁读取: 当某些数据频繁被读取而不常变化时,可以将这些…...
2025-01-01 NO2. XRHands 介绍
文章目录 软件配置1 XR Hands 简介2 XRHand2.1 Pose2.2 Handedness 3 XRHandJoint3.1 XRHandJointID3.2 XRHandJointTrackingState 4 XRHandSubsystem4.1 数据属性4.1.1 UpdateSuccessFlags4.1.2 UpdateType 4.2 处理器管理:注册和注销4.3 更新手部数据:…...
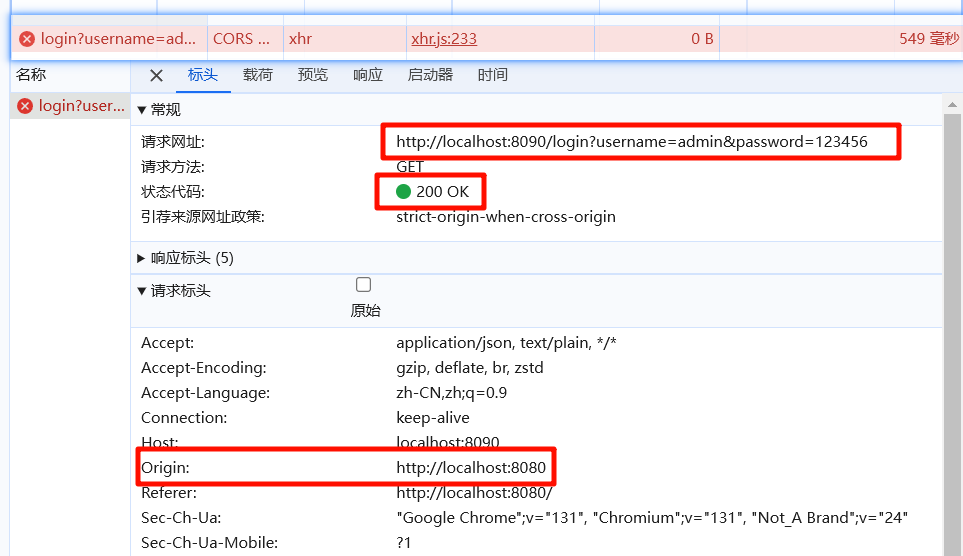
Java开发-后端请求成功,前端显示失败
文章目录 报错解决方案1. 后端未配置跨域支持2. 后端响应的 Content-Type 或 CORS 配置问题3. 前端 request 配置问题4. 浏览器缓存或代理问题5. 后端端口未被正确映射 报错 如下图,后端显示请求成功,前端显示失败 解决方案 1. 后端未配置跨域支持 …...

把ESP-01S变成智能开关:51单片机+ESP8266的简易物联网项目实战
从零打造智能灯控系统:51单片机ESP-01S物联网实战指南 项目背景与核心思路 在智能家居领域,远程控制灯光是最基础却最实用的功能之一。传统方案往往需要购买成套的智能家居设备,成本高昂且灵活性不足。而借助51单片机和ESP-01S WiFi模块的组合…...

当贝叶斯遇见流数据:在线变点检测在IoT异常监控中的实战指南
贝叶斯在线变点检测:IoT实时异常监控的智能引擎 工厂车间里,数百个温度传感器正以每秒10次的频率向中央系统发送数据流。突然,3号机床的轴承温度读数开始出现微妙波动——这是设备过热的早期信号,但传统阈值报警系统却毫无反应。两…...
深度解析:如何让你的飞控代码轻松跑在不同芯片上?)
ArduPilot硬件抽象层(HAL)深度解析:如何让你的飞控代码轻松跑在不同芯片上?
ArduPilot硬件抽象层(HAL)深度解析:跨平台飞控开发实战指南 当开发者尝试将ArduPilot移植到一块全新的飞控板时,最常遇到的挑战莫过于如何让同一套控制算法在不同硬件架构上无缝运行。这正是硬件抽象层(HAL)设计的精妙之处——它如同一位技艺高超的翻译官…...

麦当劳中国启动2026全国招聘周招募新生代人才
美通社消息:麦当劳中国正式启动2026年全国招聘周。今年,首批年满16周岁的10后将步入职场,与00后共同构成新生代主力军。在AI的变革时代,麦当劳以"有保障、有福利、有发展"的薪酬福利成长体系,以及长期、系统…...

告别‘天书’!手把手教你用vdex2dex、odex2smali等工具,把Android应用的vdex/odex/cdex转成可读的dex文件
Android逆向工程实战:从vdex/odex/cdex到可读dex的完整指南 当你兴致勃勃地打开一个APK文件准备分析时,却发现里面只有vdex、odex或cdex文件,用JADX直接打开全是乱码——这种挫败感每个逆向工程师都经历过。本文将带你一步步破解这些"天…...

从提示词到成片:2026年AI视频工作流效率革命——Top 5工具的Prompt工程兼容度、重绘响应延迟与跨平台资产复用率实测
更多请点击: https://intelliparadigm.com 第一章:2026年AI视频生成工具全景图谱与评测方法论 截至2026年,AI视频生成已从实验性原型迈入工业化应用阶段,工具生态呈现“三极分化”格局:消费级轻量工具专注短视频创意提…...

【MySQL百日打怪升级第8天】SELECT执行流程
【第8天】每天一个MySQL知识点,百日打怪升级 SQL基础:SELECT执行流程 大家好,我是一名拥有10年以上经验的DBA老兵。 做这个系列,源于一个朴素的愿望:把踩过的坑、总结的经验系统化输出,希望能帮到刚入行或…...

我给Postman配了个AI助手,管理API效率直接起飞
最近在研究MCP(Model Context Protocol)的时候,发现了一个挺有意思的项目——Postman MCP Server。简单说,它就是一个能让AI直接操作你Postman账号的“桥梁”。你现在可以用Claude或者其他支持MCP的AI工具,帮你创建集合…...

《CVPR2025-DEIM创新改进项目实战:从原理到部署的深度学习优化全攻略》005、DEIM模型架构总览——编码器-解码器与动态门控设计
CVPR2025-DEIM创新改进项目实战:DEIM模型架构总览——编码器-解码器与动态门控设计 从一次诡异的梯度爆炸说起 去年冬天调DEIM的早期原型,模型在训练到第47个epoch时突然loss飙到NaN。检查了三天,最后发现是门控模块的sigmoid输出在极端情况下饱和,导致梯度回传时门控信号…...

GitHub下载速度提升10倍:Fast-GitHub终极解决方案
GitHub下载速度提升10倍:Fast-GitHub终极解决方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 还在为GitHub的龟速下…...