PCL点云库入门——PCL库点云滤波算法之统计滤波(StatisticalOutlierRemoval)
1、算法原理
统计滤波算法是一种利用统计学原理对点云数据进行处理的方法。它主要通过计算点云中每个点的统计特性,如均值、方差等,来决定是否保留该点。算法首先会设定一个统计阈值,然后对点云中的每个点进行分析。如果一个点的统计特性与周围点的统计特性相差不大,即认为该点是可靠的,并将其保留;反之,如果一个点的统计特性与周围点相比差异较大,那么这个点可能是一个异常点或噪声点,算法会将其移除。通过这种方式,统计滤波算法能够有效地减少数据中的噪声和异常值,提高点云数据的质量。这种算法特别适用于需要对数据进行精细处理的场合,例如在高精度建模和测量中。由于其能够提供较为精确的数据处理结果,统计滤波算法在点云数据处理领域中也占有一席之地。算法的实现步骤如下:
第1步:创建点云数据的拓扑结构,如KDtree或Octree。
第2步:计算每一个点的K邻域集合。
第3步:计算每个点与其K邻域的距离dij的均值,其中i=[1,....,m] 表示点云数目,j=[1,....,k] 点的K邻域点。
第4步:计算点云数据高斯分布模型参数d~N(u,α),距离的均值u,距离的标准差α,具体公式内容如下:


第5步:计算统计滤波的阈值。
dt= u+ S*α ;
第6步:遍历所有点,如果其距离的均值大于指定置阈值,则为外点,将会被移除。
2、主要成员函数和变量
1.主要的成员变量
1)、 构建点云空间拓扑的方法,如KDtree和Octree
SearcherPtr searcher_;
2)、搜索点K邻域的个数,用于计算点的平均距离信息
int mean_k_;3)、标准差修正因子
double std_mul_;2.主要的成员函数
1)、设置搜索点K邻域的个数,用于计算点的平均距离,可以根据直接点云数据分布情况设置一般值15、30、50等。
inline void setMeanK (int nr_k);2)、标准差修正因子 ,如0.1、0.3和0.5等。
inline void setStddevMulThresh (double stddev_mult)3、主要实现代码注解
template <typename PointT> void
pcl::StatisticalOutlierRemoval<PointT>::applyFilterIndices (std::vector<int> &indices)
{// 初始化构建点云拓扑关系方法if (!searcher_){if (input_->isOrganized ())//有序点云searcher_.reset (new pcl::search::OrganizedNeighbor<PointT> ());else //无序点云数据用KD树方法searcher_.reset (new pcl::search::KdTree<PointT> (false));}searcher_->setInputCloud (input_);// 初始化需要的参数,K个邻域的索引集、距离集;所有点云数据的距离集std::vector<int> nn_indices (mean_k_);std::vector<float> nn_dists (mean_k_);std::vector<float> distances (indices_->size ());//内点、外点索引集初始化indices.resize (indices_->size ());removed_indices_->resize (indices_->size ());int oii = 0, rii = 0; // oii = output indices iterator, rii = removed indices iterator//第一步:计算所有点相对于k个最近邻域点的平均距离int valid_distances = 0;for (int iii = 0; iii < static_cast<int> (indices_->size ()); ++iii) // iii = input indices iterator{//无效点判断if (!std::isfinite (input_->points[(*indices_)[iii]].x) ||!std::isfinite (input_->points[(*indices_)[iii]].y) ||!std::isfinite (input_->points[(*indices_)[iii]].z)){//无序点的距离为0distances[iii] = 0.0;continue;}// P执行K个邻域点搜索if (searcher_->nearestKSearch ((*indices_)[iii], mean_k_ + 1, nn_indices, nn_dists) == 0){distances[iii] = 0.0;PCL_WARN ("[pcl::%s::applyFilter] Searching for the closest %d neighbors failed.\n", getClassName ().c_str (), mean_k_);continue;}// 计算点与K个邻域点之间距离的平均值double dist_sum = 0.0;for (int k = 1; k < mean_k_ + 1; ++k) // k = 0 is the query pointdist_sum += sqrt (nn_dists[k]);//将距离均值信息保存到对应索引值中 distances[iii] = static_cast<float> (dist_sum / mean_k_);valid_distances++;}// 估计距离的均值和标准差(u,a)double sum = 0, sq_sum = 0;for (const float &distance : distances){sum += distance;sq_sum += distance * distance;}//均值double mean = sum / static_cast<double>(valid_distances);//方差---》前半部分为母体方差,double variance = (sq_sum - sum * sum / static_cast<double>(valid_distances)) / (static_cast<double>(valid_distances) - 1);//标准差double stddev = sqrt (variance);//getMeanStd (distances, mean, stddev);// 计算外点阈值 ,等于=均值+标准差的修正系数double distance_threshold = mean + std_mul_ * stddev;// 第二步:根据计算的距离阈值和每个点的距离值(分辨率)对点进行分类(内点和外点)for (int iii = 0; iii < static_cast<int> (indices_->size ()); ++iii) // iii = input indices iterator{//平均距离太高的点是离群值,传递给移除的索引if ((!negative_ && distances[iii] > distance_threshold) || (negative_ && distances[iii] <= distance_threshold)){if (extract_removed_indices_)(*removed_indices_)[rii++] = (*indices_)[iii];continue;}// Otherwise it was a normal point for output (inlier)indices[oii++] = (*indices_)[iii];}// Resize the output arraysindices.resize (oii);removed_indices_->resize (rii);
}4、代码示例
/*****************************************************************//**
* \file PCLPCLRadiusOutliermain.cpp
* \brief
*
* \author YZS
* \date January 2025
*********************************************************************/
#include<iostream>
#include <vector>
#include <ctime>
#include <pcl/point_types.h>
#include <pcl/point_cloud.h>
#include <pcl/io/auto_io.h>
#include <pcl/visualization/pcl_visualizer.h>
#include <pcl/filters/statistical_outlier_removal.h>
using namespace std;void PCLStatisticalOutlier()
{pcl::PointCloud<pcl::PointXYZ>::Ptr cloud(new pcl::PointCloud<pcl::PointXYZ>());std::string fileName = "E:/PCLlearnData/11/table.pcd";pcl::io::load(fileName, *cloud);std::cout << "Cloud Size:" << cloud->points.size() << std::endl;//保存滤波后的结果点云pcl::PointCloud<pcl::PointXYZ>::Ptr cloudFilter(new pcl::PointCloud<pcl::PointXYZ>());//统计滤波算法pcl::StatisticalOutlierRemoval<pcl::PointXYZ> sorFilter;// 统计滤波器对象sorFilter.setInputCloud(cloud);sorFilter.setMeanK(30);//设置搜索点K邻域的个数sorFilter.setStddevMulThresh(0.3);//设置标准差修正因子 ,如0.1、0.3和0.5等sorFilter.filter(*cloudFilter); // 执行滤波,并且保存结果到cloudFilter中std::cout << "filter Cloud Size:" << cloudFilter->points.size() << std::endl;//结果可视化
// PCLVisualizer对象pcl::visualization::PCLVisualizer viewer("FilterVIS");//创建左右窗口的ID v1和v2int v1(0);int v2(1);//设置V1窗口尺寸和背景颜色viewer.createViewPort(0.0, 0.0, 0.5, 1, v1);viewer.setBackgroundColor(0, 0, 0, v1);//设置V2窗口尺寸和背景颜色viewer.createViewPort(0.5, 0.0, 1, 1, v2);viewer.setBackgroundColor(0.1, 0.1, 0.1, v2);// 添加2d文字标签viewer.addText("v1", 10, 10, 20, 1, 0, 0, "Txtv1", v1);viewer.addText("v2", 10, 10, 20, 0, 1, 0, "Txtv2", v2);//设置cloud1的渲染属性,点云的ID和指定可视化窗口v1viewer.addPointCloud(cloud, "cloud1", v1);viewer.setPointCloudRenderingProperties(pcl::visualization::PCL_VISUALIZER_POINT_SIZE, 2, "cloud1");//设置cloud2的渲染属性,点云的ID和指定可视化窗口v2viewer.addPointCloud(cloudFilter, "cloud2", v2);viewer.setPointCloudRenderingProperties(pcl::visualization::PCL_VISUALIZER_POINT_SIZE, 2, "cloud2");// 可视化循环主体while (!viewer.wasStopped()){viewer.spinOnce();}
}
int main(int argc, char* argv[])
{PCLStatisticalOutlier();std::cout << "Hello World!" << std::endl;std::system("pause");return 0;
}结果:

5、统计滤波算法缺点
1)、计算每一个点的邻域集合时,可能会因为数据集的复杂性导致邻域集合的计算不准确,从而影响后续的距离计算和滤波效果。
2)、在计算每个点与其邻域的距离dij时,如果点云数据中存在噪声或异常值,这些异常值可能会扭曲距离的计算,导致滤波结果不理想。
3)、高斯分布模型参数的计算依赖于距离的均值u和标准差α,如果数据集中的离群值较多,可能会使得均值和标准差的估计不准确,进而影响到离群值的识别和删除。
4)、遍历所有点并移除外点的过程中,如果设定的置信度阈值过高或过低,可能会导致过多的正常点被错误地识别为离群点而被移除,或者真正的离群点没有被有效识别,从而影响数据集的质量。
至此完成第十二节PCL库点云滤波算法之统计滤波(StatisticalOutlierRemoval)学习,下一节我们将进入《PCL库中点云特征》的学习。
相关文章:
PCL点云库入门——PCL库点云滤波算法之统计滤波(StatisticalOutlierRemoval)
1、算法原理 统计滤波算法是一种利用统计学原理对点云数据进行处理的方法。它主要通过计算点云中每个点的统计特性,如均值、方差等,来决定是否保留该点。算法首先会设定一个统计阈值,然后对点云中的每个点进行分析。如果一个点的统计特性与周…...

【机器学习】Kaggle实战信用卡反欺诈预测(场景解析、数据预处理、特征工程、模型训练、模型评估与优化)
构建信用卡反欺诈预测模型 建模思路 本项目需解决的问题 本项目通过利用信用卡的历史交易数据,进行机器学习,构建信用卡反欺诈预测模型,提前发现客户信用卡被盗刷的事件。 项目背景 数据集包含由欧洲持卡人于2013年9月使用信用卡进行交的…...

【RISC-V CPU debug 专栏 4 -- RV CSR寄存器介绍】
文章目录 Overview1. CSR寄存器访问指令2. 为何CSR地址不是4字节对齐(1) CSR寄存器空间是独立的地址空间(2) 节省编码空间(3) 对硬件实现的简化 3. CSR的物理大小和对齐无关4. RISC-V 中的 GPR 寄存器及其作用GPR 的详细用途CSR(控制状态寄存器)与 GPR 的…...
 完整指南)
Object.defineProperty() 完整指南
Object.defineProperty() 完整指南 1. 基本概念 Object.defineProperty() 方法允许精确地添加或修改对象的属性。默认情况下,使用此方法添加的属性是不可修改的。 1.1 基本语法 Object.defineProperty(obj, prop, descriptor)参数说明: obj: 要定义…...

postgresql函数创建
postgresql的函数创建 1.创建函数的基本语法: CREATE [OR REPLACE] FUNCTION function_name(parameter_list) RETURNS return_type AS $$ BEGIN -- 函数体 END; $$ LANGUAGE language_name;2.创建函数时传入参数示例:add_user tbl_user表 | id | username | …...

ECMAScript 变量
文章目录 前言一、ECMAScript 变量二、var 关键字1、var 声明作用域2、var 声明提升(hoist)三、let 关键字四、const 关键字🔰 总结前言 任何语言的核心所描述的都是这门语言在最基本的层面上如何工作,涉及 语法、操作符、数据类型以及内置功能,在此基础之上才可以构建复…...

CAN总线波形中最后一位电平偏高或ACK电平偏高问题分析
参考:https://zhuanlan.zhihu.com/p/689336144 有时候看到CAN总线H和L的差值波形的最后一位电平会变高很多,这是什么原因呢? 实际上这是正常的现象,最后一位是ACK位。问题描述为:CAN总线ACK电平偏高。 下面分析下原因…...

【C++】22___STL常用算法
目录 一、常用遍历算法 二、常用查找算法 2.1 find 2.2 其它查找算法 三、常用排序算法 3.1 sort 3.2 其它排序算法 四、拷贝 & 替换 4.1 copy 4.2 其它算法 五、常用的算数生成算法 5.1 accumulate 5.2 fill 六、常用集合算法 6.1 set_intersection 6…...

意静明和-十成
十成 责任(健康)、使命(事业)、信念(意义)、自律(排诱)、自修(知识)、总结(四为)、执行(一事不拖)、人情&…...

easyui textbox使用placeholder无效
easyui textbox使用placeholder无效 在easyui 的textbox控件,请使用data-options 设定 示例 <input type text class easyui-textbox data-options "prompt:请输入您的邮箱"/>...

flux中的缓存
1. cache,onBackpressureBuffer。都是缓存。cache可以将hot流的数据缓存起来。onBackpressureBuffer也是缓存,但是当下游消费者的处理速度比上游生产者慢时,上游生产的数据会被暂时存储在缓冲区中,防止丢失。 2. Flux.range 默认…...

代码重定位详解
文章目录 一、段的概念以及重定位的引入1.1 问题的引入1.2 段的概念1.3 重定位 二、如何实现重定位2.1 程序中含有什么?2.2 谁来做重定位?2.3 怎么做重定位和清除BSS段?2.4 加载地址和链接地址的区别 三、散列文件使用与分析3.1 重定位的实质…...
活动预告 | Microsoft 365 在线技术公开课:让组织针对 Microsoft Copilot 做好准备
课程介绍 通过Microsoft Learn免费参加Microsoft 365在线技术公开课,建立您需要的技能,以创造新的机会并加速您对Microsoft云技术的理解。参加我们举办的“让组织针对 Microsoft Copilot for Microsoft 365 做好准备” 在线技术公开课活动,学…...

从0到机器视觉工程师(一):机器视觉工业相机总结
目录 相机的作用 工业相机 工业相机的优点 工业相机的种类 工业相机知名品牌 光源与打光 打光方式 亮暗场照明 亮暗场照明的应用 亮暗场照明的区别 前向光漫射照明 背光照明 背光照明的原理 背光照明的应用 同轴光照明 同轴光照明的应用 总结 相机的作用 相机…...
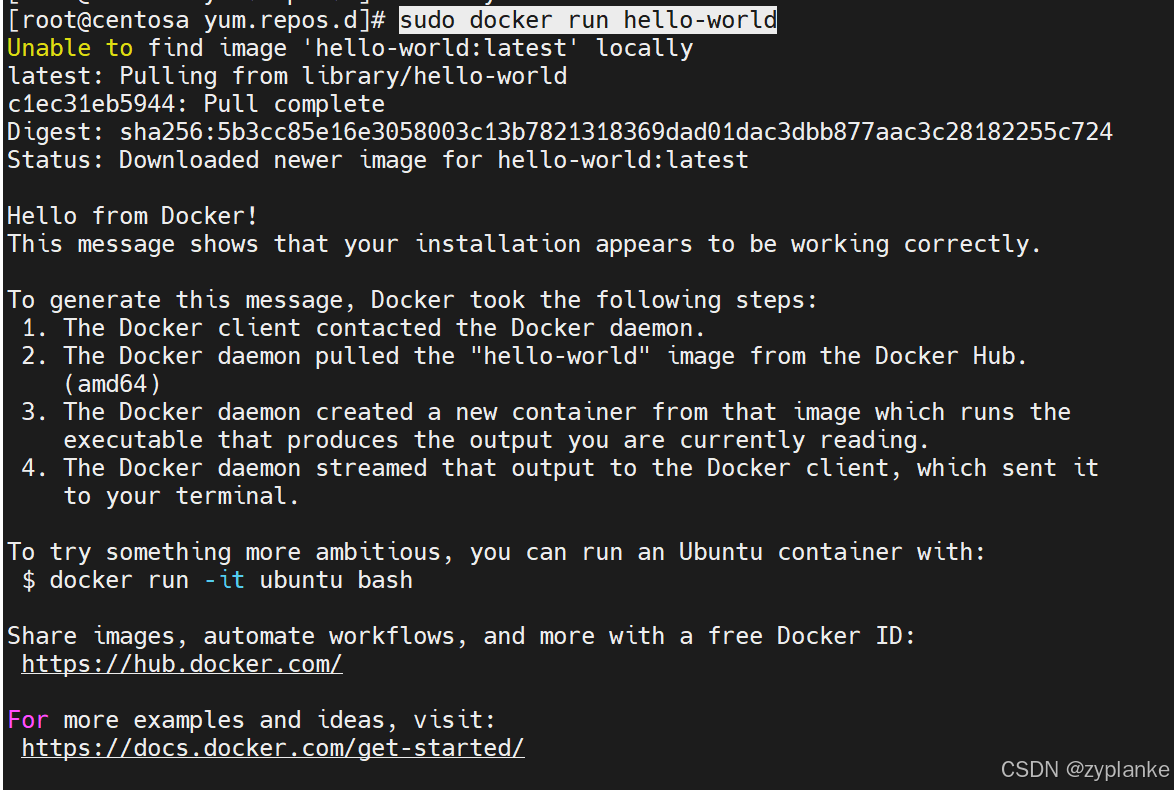
Docker安装(Docker Engine安装)
一、Docker Engine和Desktop区别 Docker Engine 核心组件:Docker Engine是Docker的核心运行时引擎,负责构建、运行和管理容器。它包括守护进程(dockerd)、API和命令行工具客户端(docker)。适用环境&#…...

数组的深度监听deep
场景:组件提供的emit事件可能被占用,在不能使用事件提交的情况下,就要上watch数组监听了,但是是发现只有在数组的长度发生变化的时候才会触发监听,这怎么行。。。。。 对于对象数组的深度监听,如果没有正确…...

点击锁定按钮,锁定按钮要变成解锁按钮,然后状态要从待绑定变成 已锁定(升级版)
文章目录 1、updateInviteCodeStatus2、handleLock3、InviteCodeController4、InviteCodeService5、CrudRepository 点击锁定按钮,锁定按钮要变成解锁按钮,然后状态要从待绑定变成 已锁定:https://blog.csdn.net/m0_65152767/article/details…...

UniApp 性能优化策略
一、引言 在当今数字化时代,移动应用的性能成为影响用户留存与满意度的关键因素。UniApp 作为一款热门的跨平台开发框架,以一套代码适配多端的特性极大提升了开发效率,但同时也面临着性能优化的挑战。优化 UniApp 性能,不仅能够让…...

【Linux报告】实训六 重置超级用户密码
实训六 重置超级用户密码 2018编写-今日公布 【练习一】忘记root密码 步骤一:开启或重启系统,并且要在五秒之内按任何键; 步骤二:按任意键,停止进入系统,按【e】键,跳转新页面,再…...

smolagents:一个用于构建代理的简单库
HF推出 smolagents,一个非常简单的库,它能够解锁语言模型的代理功能。以下是它的简要介绍: from smolagents import CodeAgent, DuckDuckGoSearchTool, HfApiModelagent CodeAgent(tools[DuckDuckGoSearchTool()], modelHfApiModel())agent…...

快速上手3DGS数字孪生开发:一份必做的技术动作盘点清单
一、行业核心技术科普:3DGS数字孪生开发的关键技术节点从零开始构建一个基于3D高斯泼溅(3DGS)的数字孪生应用,涉及多个关键技术节点。每个节点的执行质量,都直接影响最终应用的性能与用户体验。其域创新推出的LCC格式&…...

潍坊漆面车衣怎么选才合适?
很多潍坊车主在给爱车选漆面保护膜时,都会有这样的困惑:网上信息真假难辨,线下门店推荐又参差不齐,到底该怎么选才合适?其实,选漆面车衣没有想象中那么复杂,关键是要掌握一套通用的判断标准。本…...

Vue3生态系统:打造完整的前端开发体系
Vue3生态系统:打造完整的前端开发体系 前言 大家好,我是前端老炮儿。今天咱们来聊聊Vue3的生态系统。 如果说Vue3是一辆超级跑车,那它的生态系统就是配套的加油站、维修站和改装厂。一个好的框架不仅要有强大的核心能力,还要有…...
)
仅限内部团队使用的Perplexity行业扫描协议(附可复用Prompt模板库+信源可信度评分表v2.3)
更多请点击: https://codechina.net 第一章:Perplexity行业扫描协议的定位与适用边界 Perplexity行业扫描协议(Perplexity Industry Scanning Protocol,简称PISP)并非通用型AI评估框架,而是一套面向垂直领…...

基于CircuitPython与RP2040打造可编程USB脚踏开关:从硬件到软件的完整指南
1. 项目概述:为什么你需要一个可编程的脚踏开关? 在剪辑视频、处理音频、写代码或者玩游戏的时候,你的双手是不是永远不够用?频繁地在键盘、鼠标、调音台或者剪辑软件的面板之间切换,不仅效率低下,还容易打…...

RT-Thread USB HID设备数据发送失败排查:ops参数与报告ID的深度解析
1. 问题背景与核心需求解析 最近在捣鼓RT-Thread,想用它来实现一个USB HID设备,完成和电脑之间的双向数据收发。HID,也就是人机接口设备,大家最熟悉的可能就是键盘鼠标了,它的好处是免驱动,在主流操作系统…...

如何快速获取免费的EB Garamond 12字体:古典优雅的终极排版解决方案
如何快速获取免费的EB Garamond 12字体:古典优雅的终极排版解决方案 【免费下载链接】EBGaramond12 项目地址: https://gitcode.com/gh_mirrors/eb/EBGaramond12 EB Garamond 12是一款完全免费的开源字体,完美复刻了16世纪Claude Garamont的经典…...

【懒人专用】Windows 端 Open Claw v 2.7.5 全自动部署图文教程
📌 前言 2026 年开源圈热门的「数字员工」OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 零代码操作 自动干活的核心优势广受关注!很多人误以为它是普通聊天 AI,实则是能真正操控…...

从‘均分误差’到‘功率打架’:实战中调试微电网逆变器下垂系数的避坑指南
从‘均分误差’到‘功率打架’:实战中调试微电网逆变器下垂系数的避坑指南 微电网系统中,多个分布式电源并联运行时,有功功率分配不均的问题如同暗礁,稍有不慎就会导致系统效率下降甚至设备过载。这种被工程师们戏称为"功率打…...

实测Llama3 8B在国产AI盒子上的推理速度:算丰SG2300x Airbox跑出9.6 token/s
实测Llama3 8B在国产AI盒子上的推理速度:算丰SG2300x Airbox跑出9.6 token/s 当Meta开源Llama3大模型的消息席卷AI社区时,一个更实际的问题浮出水面:如何让这个性能怪兽在边缘设备上真正跑起来?我们拿到搭载算丰SG2300x芯片的Radx…...