[Hive]七 Hive 内核
1. Hive架构
Hive架构主要包括:
- 用户界面:命令行(CLI)和web UI
- Thrift Server:公开了一个非常简单的客户端执行HiveQL语句的API,包括JDBC(Java)和ODBC(C++),python等
- Metastore:系统的目录。Hive的其他组件都与metastore交互
- Driver:管理HiveQL语句在编译、优化和执行期间的生命周期。收到来自Thrift Server或其他接口的HiveQL语句时,它创建一个Session Handle用于跟踪统计信息,如执行时间、输出行数等。
SQL Parser:将SQL字符串转换成抽象语法树(Abstract Syntax Tree, AST)
语义分析(Semantic Analyzer):将AST进一步划分为QueryBlock。
逻辑计划生成器(Logical Plan Generator):将抽象语法树生成逻辑计划
逻辑优化器(Logical Optimizer):对逻辑计划进行优化(比如谓词下推)
物理计划生成器(Physical Plan Generator):根据优化后的逻辑计划生成物理计划(比如MR任务,Spark任务,Tez任务)
物理优化器(Physical Optimizer):对物理计划进行优化(比如Map join)
执行器(Executor):执行计划,并将结果返回给客户端。
- Compiler:在Driver收到HQL语句之后引用,将语句翻译为DAG(有向无环图)形式的MapReduce任务组成的计划
- Driver按照拓扑顺序将各个Mapreduce作业从DAG提交到Execution Engine(执行引擎)
1.1 Metastore
Metastore是包含存储在hive中的表的元数据的系统目录。此元数据在表创建期间指定,并在HiveQL中每次引用该表时被重用。元数据包括:
| DataBase | 默认是default |
| Table | 表的元数据包含列及其类型、所有者、存储信息和SerDe信息的列表。它还可以包含任何用户提供的键值数据(TBLPROPERTIES)。存储信息包括表数据在底层系统中的位置、数据格式和bucketing分桶信息。SerDe元数据包括序列化器和反序列化器方法的实现类以及该实现类所需的任何支持信息。所有这些信息都可以在创建表的过程汇总提供。 |
| Partition | 每个分区都可以有自己的列,SerDe和存储信息。 |
CREATE TABLE `call_center`(
`cc_call_center_sk` bigint,
`cc_call_center_id` char(16),
`cc_rec_start_date` date,
`cc_rec_end_date` date,
`cc_closed_date_sk` bigint,
`cc_open_date_sk` bigint,
`cc_name` varchar(50),
`cc_class` varchar(50),
`cc_employees` int,
`cc_sq_ft` int,
`cc_hours` char(20),
`cc_manager` varchar(40),
`cc_mkt_id` int,
`cc_mkt_class` char(50),
`cc_mkt_desc` varchar(100),
`cc_market_manager` varchar(40),
`cc_division` int,
`cc_division_name` varchar(50),
`cc_company` int,
`cc_company_name` char(50),
`cc_street_number` char(10),
`cc_street_name` varchar(60),
`cc_street_type` char(15),
`cc_suite_number` char(10),
`cc_city` varchar(60),
`cc_county` varchar(30),
`cc_state` char(2),
`cc_zip` char(10),
`cc_country` varchar(20),
`cc_gmt_offset` decimal(5,2),
`cc_tax_percentage` decimal(5,2))
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'obs://bigdata-test1233/hive/warehouse/hive_tpcds_parquet_2tb/call_center'
TBLPROPERTIES (
'bucketing_version'='2',
'transient_lastDdlTime'='1735377714')
1.2 Compiler
Driver使用HiveQL字符串调用Compiler,HiveQL字符串可以是DDL、DML或DQL语句之一。Compiler将字符串转换为Plan。对于DDL语句,Plan只包含元数据操作,而对于Load语句,则包含HDFS操作。对于Insert语句和查询语句,该计划由MapReduce作业的Directed Acyclical Graph(DAG,有向无环图)组成。
- Parser将一个Query字符串转化成一个AST(Abstract Syntax Tree,抽象语法树)。
- 语义分析器(Semantic Analyzer)将AST转换为基于Block的内部查询表现形式(QueryBlock)。它从Metastore中检索输入表的模式信息(Schema Information)。使用此信息去验证列名,展开select * 并执行类型检查,包括添加隐式类型转换。
QueryBlock代表了查询语句中的一个逻辑块,通常由一个SELECT语句和其相关的子查询、JOIN操作或UNION操作组成。QueryBlock可以看作是查询语句的一个子部分,它有自己的语义和语法规则,并且可以独立进行语义分析和优化。
举个例子,假设有以下HiveQL查询语句:
```sql
SELECT a.id, b.name
FROM table1 a
JOIN table2 b ON a.id = b.id
WHERE a.salary > 1000;
```
在这个查询语句中,可以将其分解为两个QueryBlock:
QueryBlock 1:
```sql
SELECT a.id, b.name
FROM table1 a
JOIN table2 b ON a.id = b.id
```
QueryBlock 2:
```sql
SELECT a.salary
FROM table1 a
WHERE a.salary > 1000
```
每个QueryBlock都有自己的语义和语法规则,语义分析器会分别对它们进行分析和验证。在分析过程中,语义分析器会检查表和列是否存在、列的数据类型是否匹配、JOIN条件是否有效等,并生成相应的查询计划用于后续的执行阶段。
通过将查询语句拆分为多个QueryBlock,语义分析器可以更好地理解和处理复杂的查询语句,提高查询的效率和准确性。
- 逻辑计划生成器(Logical Plan Generator)将内部查询表示形式转换为逻辑计划,逻辑计划由逻辑运算符树组成。
- 优化器(Optimizer)对逻辑计划执行多次传递,并以多种方式重写它。
- 物理计划生成器(Physical Plan Generator)将逻辑计划转换为物理计划,其中包含MapReduce作业的DAG。它为逻辑计划中的每个标记Operator-repartition和union all创建一个新的MapReduce作业,然后它将包含在标记之间的逻辑计划的一部分分配给MapReduce作业的Mapper和Reducer。
1.3 Hive链接到数据库的模式
1.3.1 单用户模式
此模式链接到一个In-memory 数据库Derby,一般用于Unit Test。
1.3.2 多用户模式
通过网络连接到一个数据库中,是最经常使用到的模式。hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop101:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true</value>
</property><property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<value>com.mysql.jdbc.Driver</value>
</property><property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property><property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>xxx</value>
</property>1.3.3 远程服务器模式
用于非Java客户端访问元数据库,在服务器端启动MetaStore Server,客户端利用thrift协议通过MetaStore Server访问元数据库。
hive-site.xml
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop101:9083</value>
</property>启动HiveQL MetaStore Server:
java -Xmx1024m -Dlog4j.configuration=file://$HIVE_HOME/conf/hms-log4j.properties -cp $CLASSPATH org.apache.hadoop.hive.metastore.HiveMetaStore
Hive 客户端命令:
HIVE_LOG_DIR=$HIVE_HOME/logs
nohup hive --service metastore > $HIVE_LOG_DIR/metastore.log 2>&1 &
1.4 Hive 数据模型
Hive中所有的数据都存储在HDFS中,存储结构主要包括数据库、文件、表和视图。
Hive中包含以下数据模型:Inner Table内部表(也叫管理表),External Table外部表,Partition 分区,Bucket分桶。
1.4.1 数据库
类似传统数据库中的DataBase,使用方法如下:
| 操作 | HiveQL语句 |
| 创建数据库 | create database [db_name] |
| 使用数据库 | use db_name |
| 查看所有数据库 | show databases |
| 查看某个数据库的创建语句 | show create database db_name |
1.4.2 表
2. Hive运行过程
3. Hive SQL解析过程
4. MapReduce原理
5. UDF
6. MetaStore模块
7. Hive元数据说明
8. Hive权限说明
9. Hive On Spark
10. Hive 提交任务到Yarn
11. HiveSQL调优
相关文章:

[Hive]七 Hive 内核
1. Hive架构 Hive架构主要包括: 用户界面:命令行(CLI)和web UIThrift Server:公开了一个非常简单的客户端执行HiveQL语句的API,包括JDBC(Java)和ODBC(C)&…...

Druid密码错误重试导致数据库超慢
文章目录 密码错误重试导致数据库超慢如何避免呢? 密码错误重试导致数据库超慢 有同事把项目的数据库密码配错了,导致其他所有连接该数据库的项目全部连接都获取缓慢了,一个页面加载要花费十几秒。排查mysql连接发现很多connect命令的连接 …...

Ubuntu 24.04安装和使用WPS 2019
为Ubuntu找一款免费、功能丰富的 Microsoft Office 替代品?WPS Office是理想选择!在本文中,包含在Ubuntu上安装 WPS Office,修复初次使用出现问题的修复。 安装WPS,参考链接>>How to Install WPS Office on Ubu…...

week05_nlp大模型训练·词向量文本向量
1、词向量训练 1.1 CBOW(两边预测中间) 一、CBOW 基本概念 CBOW 是一种用于生成词向量的方法,属于神经网络语言模型的一种。其核心思想是根据上下文来预测中心词。在 CBOW 中,输入是目标词的上下文词汇,输出是该目标…...

【RabbitMQ消息队列原理与应用】
RabbitMQ消息队列原理与应用 一、消息队列概述 (一)概念 消息队列(Message Queue,简称MQ)是一种应用程序间的通信方式,它允许应用程序通过将消息放入队列中,而不是直接调用其他应用程序的接口…...
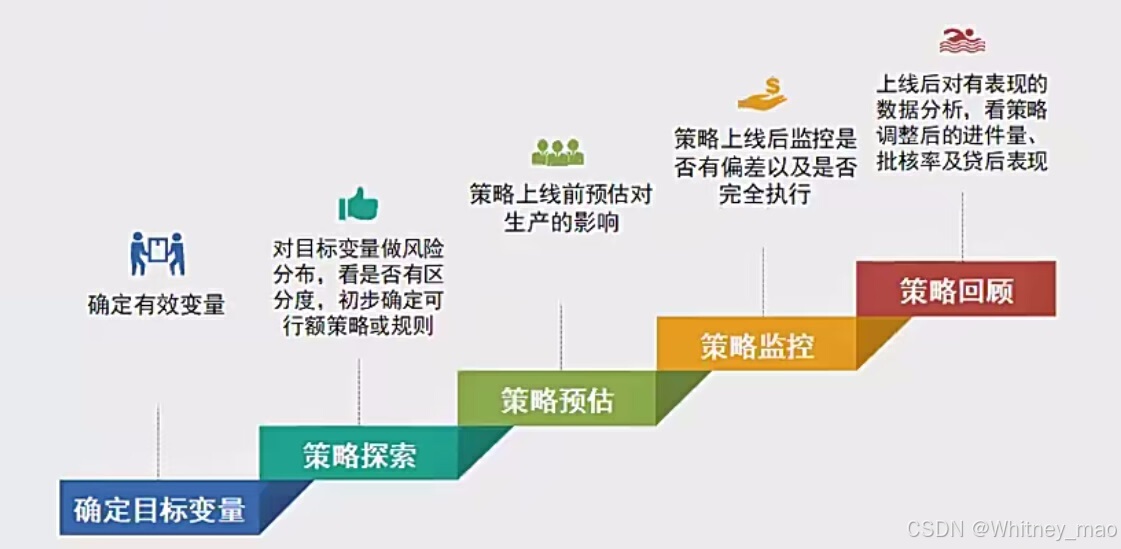
反欺诈风控体系及策略
本文详细介绍了互联网领域金融信贷行业的反欺诈策略。首先,探讨了反欺诈的定义、重要性以及在当前互联网发展背景下欺诈风险的加剧。接着,分析了反欺诈的主要手段和基础技术,包括对中介和黑产的了解、欺诈风险的具体类型和表现方式࿰…...

Mac 12.1安装tiger-vnc问题-routines:CRYPTO_internal:bad key length
背景:因为某些原因需要从本地mac连接远程linxu桌面查看一些内容,必须使用桌面查看,所以ssh无法满足,所以决定安装vnc客户端。 问题: 在mac上通过 brew install tiger-vnc命令安装, 但是报错如下: > D…...

【代码分析】Unet-Pytorch
1:unet_parts.py 主要包含: 【1】double conv,双层卷积 【2】down,下采样 【3】up,上采样 【4】out conv,输出卷积 """ Parts of the U-Net model """import torch im…...

【LLM入门系列】01 深度学习入门介绍
NLP Github 项目: NLP 项目实践:fasterai/nlp-project-practice 介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化、部署和应用,分享大模型算法工程师的日常工作和实战经验 AI 藏经阁:https://gitee.com/fasterai/a…...

安卓系统主板_迷你安卓主板定制开发_联发科MTK安卓主板方案
安卓主板搭载联发科MT8766处理器,采用了四核Cortex-A53架构,高效能和低功耗设计。其在4G网络待机时的电流消耗仅为10-15mA/h,支持高达2.0GHz的主频。主板内置IMG GE832 GPU,运行Android 9.0系统,内存配置选项丰富&…...

关键点检测——HRNet原理详解篇
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题 🍊专栏推荐:深度学习网络原理与实战 🍊近期目标:写好专栏的每一篇文章 🍊支持小苏:点赞👍🏼、…...

25考研总结
11408确实难,25英一直接单科斩杀😭 对过去这一年多备考的经历进行复盘,以及考试期间出现的问题进行思考。 考408的人,政治英语都不能拖到最后,408会惩罚每一个偷懒的人! 政治 之所以把政治写在最开始&am…...

网络安全态势感知
一、网络安全态势感知(Cyber Situational Awareness)是一种通过收集、处理和分析网络数据来理解当前和预测未来网络安全状态的能力。它的目的是提供实时的、安全的网络全貌,帮助组织理解当前网络中发生的事情,评估风险,…...

在K8S中,节点状态notReady如何排查?
在kubernetes集群中,当一个节点(Node)的状态变为NotReady时,意味着该节点可能无法运行Pod或不能正确相应kubernetes控制平面。排查NotReady节点通常涉及以下步骤: 1. 获取基本信息 使用kubectl命令行工具获取节点状态…...

深度学习在光学成像中是如何发挥作用的?
深度学习在光学成像中的作用主要体现在以下几个方面: 1. **图像重建和去模糊**:深度学习可以通过优化图像重建算法来处理模糊图像或降噪,改善成像质量。这涉及到从低分辨率图像生成高分辨率图像,突破传统光学系统的分辨率限制。 …...

树莓派linux内核源码编译
Raspberry Pi 内核 托管在 GitHub 上;更新滞后于上游 Linux内核,Raspberry Pi 会将 Linux 内核的长期版本整合到 Raspberry Pi 内核中。 1 构建内核 操作系统随附的默认编译器和链接器被配置为构建在该操作系统上运行的可执行文件。原生编译使用这些默…...
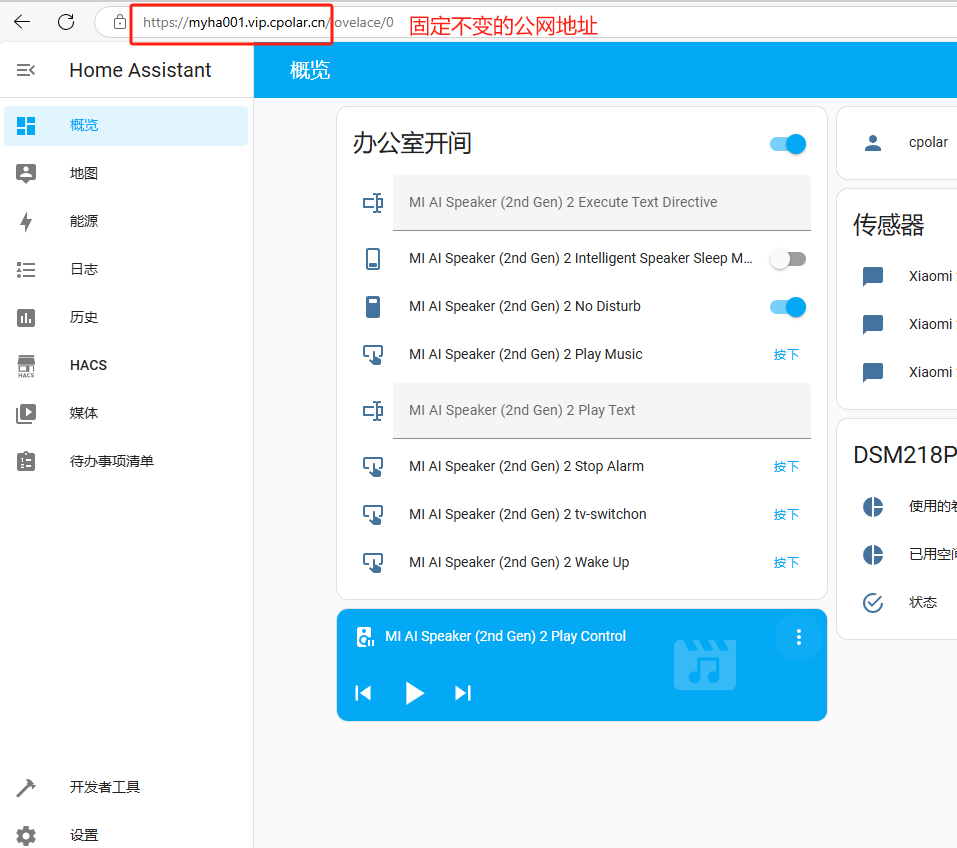
本地小主机安装HomeAssistant开源智能家居平台打造个人AI管家
文章目录 前言1. 添加镜像源2. 部署HomeAssistant3. HA系统初始化配置4. HA系统添加智能设备4.1 添加已发现的设备4.2 添加HACS插件安装设备 5. 安装cpolar内网穿透5.1 配置HA公网地址 6. 配置固定公网地址 前言 大家好!今天我要向大家展示如何将一台迷你的香橙派Z…...

SpringBoot返回文件让前端下载的几种方式
01 背景 在后端开发中,通常会有文件下载的需求,常用的解决方案有两种: 不通过后端应用,直接使用nginx直接转发文件地址下载(适用于一些公开的文件,因为这里不需要授权)通过后端进行下载&#…...

人工智能及深度学习的一些题目
1、一个含有2个隐藏层的多层感知机(MLP),神经元个数都为20,输入和输出节点分别由8和5个节点,这个网络有多少权重值? 答:在MLP中,权重是连接神经元的参数,每个连接都有一…...

15-利用dubbo远程服务调用
本文介绍利用apache dubbo调用远程服务的开发过程,其中利用zookeeper作为注册中心。关于zookeeper的环境搭建,可以参考我的另一篇博文:14-zookeeper环境搭建。 0、环境 jdk:1.8zookeeper:3.8.4dubbo:2.7.…...

5分钟掌握STDF-Viewer:半导体测试数据分析的图形化神器
5分钟掌握STDF-Viewer:半导体测试数据分析的图形化神器 【免费下载链接】STDF-Viewer A free GUI tool to visualize STDF (semiconductor Standard Test Data Format) data files. 项目地址: https://gitcode.com/gh_mirrors/st/STDF-Viewer STDF-Viewer是一…...

完整教程:DIY-Multiprotocol-TX-Module固件编译与烧录
完整教程:DIY-Multiprotocol-TX-Module固件编译与烧录 【免费下载链接】DIY-Multiprotocol-TX-Module Multiprotocol TX Module (or MULTI-Module) is a 2.4GHz transmitter module which controls many different receivers and models. 项目地址: https://gitco…...

KMS智能激活工具终极指南:免费解锁Windows与Office完整功能
KMS智能激活工具终极指南:免费解锁Windows与Office完整功能 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统提示"需要激活"而烦恼吗?Office试…...
任务通知)
FreeRTOS源码解析(9)任务通知
1.任务通知本质:直接操作目标任务的 TCB 字段。 它不自带控制块、不分配独立存储、不维护自己的等待列表——全程只做一件事:读写目标任务 TCB 里已有的 ulNotifiedValue 和 ucNotifyState,必要时将对方从延迟列表移到就绪列表。正因如此&…...

【智能体核心功能解析与落地实践指南】
智能体核心功能解析与落地实践指南 引言:智能体为何成为技术焦点 在人工智能技术飞速发展的今天,智能体(Agent)已经从学术概念走向产业应用的核心。无论是个人助手、企业自动化流程,还是复杂的决策支持系统,…...

【技术解析】从点测量到全场感知:DIC三维应变测量如何革新传统应变片测试范式
1. 从点到面的技术革命:为什么我们需要全场应变测量? 记得我第一次接触材料力学测试时,导师让我用传统应变片测量一块铝合金板的拉伸变形。我花了整整三天时间,在试样上贴了二十多个应变片,结果数据还是支离破碎。那时…...

Android项目集成CH340串口驱动:从官方Demo到体温检测模块的完整配置流程
Android项目集成CH340串口驱动:从官方Demo到体温检测模块的完整配置流程 在医疗设备、工业控制等物联网场景中,Android设备与外围硬件通过串口通信的需求日益增长。CH340作为一款高性价比的USB转串口芯片,因其稳定性和广泛兼容性成为许多硬件…...

如何彻底解决macOS多设备滚动冲突:Scroll Reverser完全指南
如何彻底解决macOS多设备滚动冲突:Scroll Reverser完全指南 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是不是经常在MacBook触控板和鼠标之间切换时࿰…...

从零构建AI智能体:核心架构、ReAct模式与实战指南
1. 项目概述:从零构建AI智能体的核心价值最近在GitHub上看到一个挺有意思的项目,叫pguso/ai-agents-from-scratch。光看名字,很多朋友可能就心动了——“从零开始构建AI智能体”,听起来就像是把那些神秘的大模型应用开发黑盒给彻底…...

科研实战:三种高效获取ERA5再分析数据的路径解析
1. ERA5再分析数据基础认知 第一次接触ERA5数据时,我和大多数科研新手一样被各种专业术语搞得晕头转向。简单来说,ERA5就像给地球做CT扫描生成的全球气象体检报告,它能提供从1950年到现在,每小时更新的气温、降水、风速等上百种气…...