深度学习中的离群值
文章目录
- 深度学习中有离群值吗?
- 深度学习中的离群值来源:
- 处理离群值的策略:
- 1. 数据预处理阶段:
- 2. 数据增强和鲁棒模型:
- 3. 模型训练阶段:
- 4. 异常检测集成模型:
- 如何处理对抗样本?
- 总结:
- 能够使用PyTorch检测离群值吗?
- 1. 基于 Z-Score 的离群值检测
- 原理:
- 代码示例:
- 2. 基于 IQR 的离群值检测
- 原理:
- 代码示例:
- 3. 使用自动编码器(Autoencoder)检测离群值
- 原理:
- 代码示例:
- 4. 使用 Isolation Forest 检测离群值(借助 sklearn)
- 代码示例:
- 5. 使用基于密度的算法(DBSCAN)检测离群值
- 原理:
- 代码示例:
- 总结:
- 相关阅读
深度学习中有离群值吗?
是的,和许多刚刚接触深度学习的工程师默认的不一样的是——深度学习中也会遇到离群值(Outliers)。这些异常值可能存在于输入数据或标签中,并对模型的训练和预测结果产生负面影响。
深度学习中的离群值来源:
-
输入特征异常:
- 数据采集错误(例如传感器故障或录入错误)。
- 数据预处理错误或特征缩放问题。(这些错误甚至可能是模型训练者自己进行错误的数据增强造成的)
-
标签异常:
-
手动标注错误(例如分类错误的标签,在一些有名的开源数据集中,偶尔也会存在这类问题)。在一篇新论文中,麻省理工 CSAIL 和亚马逊的研究者对 10 个主流机器学习数据集的测试集展开了研究,发现它们的平均错误率竟高达 3.4%。其中,最有名的 ImageNet 数据集的验证集中至少存在 2916 个错误,错误率为 6%;QuickDraw 数据集中至少存在 500 万个错误,错误率为 10%。论文链接:https://arxiv.org/pdf/2103.14749.pdf
-
噪声或异常样本影响训练数据集。
-
-
特征空间偏差:
- 特征分布存在长尾效应或极端值。
-
对抗样本:
- 特意设计的输入,导致模型错误分类或输出异常结果(例如对抗攻击)。
处理离群值的策略:
1. 数据预处理阶段:
(a) 可视化分析:
- 绘制箱线图、散点图或直方图观察异常值分布。
- 示例代码:
import matplotlib.pyplot as plt
plt.boxplot(data)
plt.show()
(b) 统计检测法:
- 使用 Z-Score 或 IQR 方法检测离群值(适合小规模数据)。
© 清洗数据:
- 删除离群值: 如果异常值是错误数据,可以直接移除。
- 替代或修正: 替换为均值、中位数或插值估计值。
2. 数据增强和鲁棒模型:
(a) 数据增强(Data Augmentation):
- 使用扩增技术生成更多样化的样本,减少异常值的影响(错误的数据增强也会产生离群值数据,要对数据增强产生的数据进行检测,以避免该问题)。
(b) 使用鲁棒模型:
-
在训练深度学习模型时采用损失函数对离群值不敏感的方法,例如:
- Huber Loss:兼顾均方误差和绝对误差。
- Smooth L1 Loss:对离群值具有更高的鲁棒性。
- 示例代码:
import torch.nn as nn loss = nn.SmoothL1Loss()
3. 模型训练阶段:
(a) Early Stopping 和正则化:
- 使用Early Stopping防止模型过拟合异常样本。
- 使用L1/L2正则化约束权重,降低对极端值的敏感性。
(b) Dropout 技术:
- 随机丢弃部分神经元,减少模型对异常值的依赖。
4. 异常检测集成模型:
(a) 使用孤立森林或 LOF 检测异常值:
在深度学习之前,可以结合机器学习算法先检测异常样本,再将清洗后的数据输入深度学习模型。
(b) 使用自动编码器(Autoencoder):
训练一个自编码器重建输入数据,计算重建误差来检测异常值。
from keras.models import Model, Sequential
from keras.layers import Dense, Input# 建立 Autoencoder
input_dim = X_train.shape[1]
model = Sequential([Dense(64, activation='relu', input_shape=(input_dim,)),Dense(32, activation='relu'),Dense(64, activation='relu'),Dense(input_dim, activation='sigmoid')
])
model.compile(optimizer='adam', loss='mse')# 使用重建误差检测异常值
reconstruction = model.predict(X_test)
mse = np.mean(np.power(X_test - reconstruction, 2), axis=1)
threshold = np.percentile(mse, 95) # 取阈值
outliers = X_test[mse > threshold]
如何处理对抗样本?
- 对抗训练: 使用生成对抗样本增强模型鲁棒性。
- 正则化约束: 如 FGSM(Fast Gradient Sign Method)等方法提高模型的稳定性。
- 检测机制: 在输入层增加检测模块,过滤异常输入。
总结:
深度学习中的离群值可能来源于输入特征或标签的异常分布,对模型训练和预测精度产生负面影响。因此,可以通过数据预处理、鲁棒损失函数、正则化、数据增强和异常检测模型等方法降低其影响。同时,对于更复杂的问题如对抗样本,需要额外设计防御机制来保护模型安全性。
此外目前也有专门用于处理数据集标注错误的深度学习模型,有兴趣的朋友可以去自行了解一下。
关键字:置信学习。可参考阅读: 关于置信学习的文献综述(简易版)
能够使用PyTorch检测离群值吗?
首先回答,是的。不过方法大同小异。
在 PyTorch 中,可以使用多种方法来检测离群值。以下是几种常用的方法及代码示例:
1. 基于 Z-Score 的离群值检测
原理:
计算每个数据点的 Z-Score,如果其绝对值大于某个阈值(如 3),则认为是离群值。
代码示例:
import torch# 示例数据
data = torch.tensor([10, 12, 11, 13, 300, 14, 15], dtype=torch.float)# 计算均值和标准差
mean = torch.mean(data)
std = torch.std(data)# 计算 Z-Score
z_scores = (data - mean) / std# 筛选离群值
threshold = 3 # 设置阈值
outliers = data[torch.abs(z_scores) > threshold]
print("Outliers:", outliers)
2. 基于 IQR 的离群值检测
原理:
通过计算四分位数范围 (IQR),判断是否超出 1.5 倍 IQR 的范围。
代码示例:
import torch# 示例数据
data = torch.tensor([10, 12, 11, 13, 300, 14, 15], dtype=torch.float)# 计算四分位数
Q1 = torch.quantile(data, 0.25)
Q3 = torch.quantile(data, 0.75)
IQR = Q3 - Q1# 计算边界
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR# 筛选离群值
outliers = data[(data < lower_bound) | (data > upper_bound)]
print("Outliers:", outliers)
3. 使用自动编码器(Autoencoder)检测离群值
原理:
- 训练一个自编码器将输入数据重建,如果重建误差较大,则认为是离群值。
- 自编码器适合处理高维数据或复杂模式的离群检测。
代码示例:
import torch
import torch.nn as nn
import torch.optim as optim# 数据集
data = torch.tensor([[10.0], [12.0], [11.0], [13.0], [300.0], [14.0], [15.0]])# 定义 Autoencoder
class Autoencoder(nn.Module):def __init__(self):super(Autoencoder, self).__init__()self.encoder = nn.Sequential(nn.Linear(1, 4),nn.ReLU(),nn.Linear(4, 2),nn.ReLU())self.decoder = nn.Sequential(nn.Linear(2, 4),nn.ReLU(),nn.Linear(4, 1))def forward(self, x):x = self.encoder(x)x = self.decoder(x)return x# 初始化模型和参数
model = Autoencoder()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)# 训练模型
epochs = 100
for epoch in range(epochs):optimizer.zero_grad()outputs = model(data)loss = criterion(outputs, data)loss.backward()optimizer.step()# 检测异常值
with torch.no_grad():predictions = model(data)mse = torch.mean((data - predictions) ** 2, dim=1)threshold = torch.quantile(mse, 0.95) # 设定阈值outliers = data[mse > threshold]print("Outliers:", outliers)
4. 使用 Isolation Forest 检测离群值(借助 sklearn)
虽然 PyTorch 没有直接支持 Isolation Forest,但可以结合 sklearn 的 Isolation Forest 提取异常值后处理。
代码示例:
from sklearn.ensemble import IsolationForest
import torch# 示例数据
data = torch.tensor([[10], [12], [11], [13], [300], [14], [15]], dtype=torch.float)# 使用 Isolation Forest 模型
clf = IsolationForest(contamination=0.1, random_state=42)
predictions = clf.fit_predict(data)# 筛选离群值
outliers = data[predictions == -1]
print("Outliers:", outliers)
5. 使用基于密度的算法(DBSCAN)检测离群值
原理:
DBSCAN 根据密度聚类检测密度较低的数据点,这些点可能是离群值。
代码示例:
from sklearn.cluster import DBSCAN
import torch# 示例数据
data = torch.tensor([[10], [12], [11], [13], [300], [14], [15]], dtype=torch.float)# 使用 DBSCAN 模型
dbscan = DBSCAN(eps=3, min_samples=2)
labels = dbscan.fit_predict(data)# 筛选离群值
outliers = data[labels == -1]
print("Outliers:", outliers)
总结:
深度学习中存在异常值,并且会产生负面影响。可以使用以下方法进行处理:
- 低维数据: 可以直接使用 Z-Score 或 IQR 等统计方法检测异常值。
- 高维或复杂数据: 使用 Autoencoder 或 Isolation Forest 检测异常值。
- 密度分析: DBSCAN 更适合非线性分布或簇状数据的离群检测。
这些方法可以根据具体任务需求灵活选择和组合使用。
相关阅读
- 什么是离群值?如何检测?
- 文本分类中的离群值特征
- 关于置信学习的文献综述(简易版)
相关文章:

深度学习中的离群值
文章目录 深度学习中有离群值吗?深度学习中的离群值来源:处理离群值的策略:1. 数据预处理阶段:2. 数据增强和鲁棒模型:3. 模型训练阶段:4. 异常检测集成模型: 如何处理对抗样本?总结…...

如何利用Logo设计免费生成器创建专业级Logo
在当今的商业世界中,一个好的Logo是品牌身份的象征,它承载着公司的形象与理念。设计一个专业级的Logo不再需要花费大量的金钱和时间,尤其是当我们拥有Logo设计免费生成器这样的工具时。接下来,让我们深入探讨如何利用这些工具来创…...
)
Mysql SQL 超实用的7个日期算术运算实例(10k)
文章目录 前言1. 加上或减去若干天、若干月或若干年基本语法使用场景注意事项运用实例分析说明2. 确定两个日期相差多少天基本语法使用场景注意事项运用实例分析说明3. 确定两个日期之间有多少个工作日基本语法使用场景注意事项运用实例分析说明4. 确定两个日期相隔多少个月或多…...

运算指令(PLC)
加 ADD 减 SUB 乘 MUL 除 DIV 浮点运算 整数运算...
「Mac畅玩鸿蒙与硬件49」UI互动应用篇26 - 数字填色游戏
本篇教程将带你实现一个数字填色小游戏,通过简单的交互逻辑,学习如何使用鸿蒙开发组件创建趣味性强的应用。 关键词 UI互动应用数字填色动态交互逻辑判断游戏开发 一、功能说明 数字填色小游戏包含以下功能: 数字选择:用户点击…...

机器学习经典算法——逻辑回归
目录 算法介绍 算法概念 算法的优缺点 LogisticRegression()函数理解 环境准备 算法练习 算法介绍 算法概念 逻辑回归(Logistic Regression)是一种广泛应用于分类问题的机器学习算法。 它基于线性回归的思想,但通过引入一个逻辑函数&…...

【数据仓库金典面试题】—— 包含详细解答
大家好,我是摇光~,用大白话讲解所有你难懂的知识点 该篇面试题主要针对面试涉及到数据仓库的数据岗位。 以下都是经典的关于数据仓库的问题,希望对大家面试有用~ 1、什么是数据仓库?它与传统数据库有何区别? 数据仓库…...

【UE5 C++课程系列笔记】19——通过GConfig读写.ini文件
步骤 1. 新建一个Actor类,这里命名为“INIActor” 2. 新建一个配置文件“Test.ini” 添加一个自定义配置项 3. 接下来我们在“INIActor”类中获取并修改“CustomInt”的值。这里定义一个方法“GetINIVariable” 方法实现如下,其中第16行代码用于构建配…...

JS 中 json数据 与 base64、ArrayBuffer之间转换
JS 中 json数据 与 base64、ArrayBuffer之间转换 json 字符串进行 base64 编码 function jsonToBase64(json) {return Buffer.from(json).toString(base64); }base64 字符串转为 json 字符串 function base64ToJson(base64) {try {const binaryString atob(base64);const js…...

USB 驱动开发 --- Gadget 驱动框架梳理
编译链接 #----》 linux_5.10/drivers/usb/gadget/Makefileobj-$(CONFIG_USB_LIBCOMPOSITE) libcomposite.o libcomposite-y : usbstring.o config.o epautoconf.o libcomposite-y composite.o functions.o configfs.o u_f.oobj-$(CONFIG_USB_GADG…...
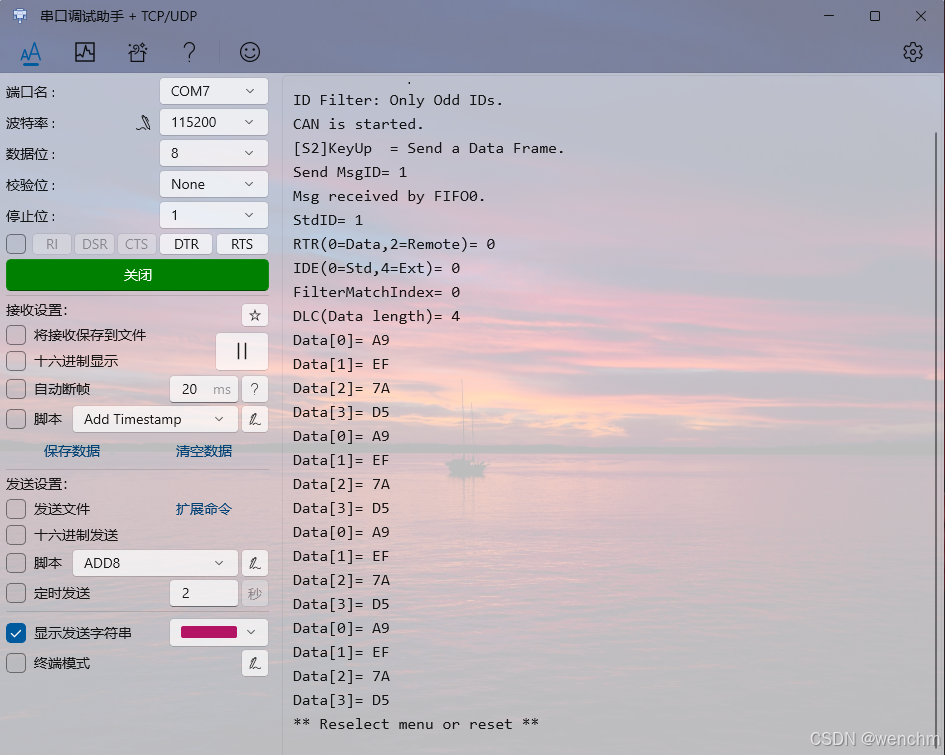
细说STM32F407单片机中断方式CAN通信
目录 一、工程配置 1、时钟、DEBUG、USART6、GPIO、CodeGenerator 2、CAN1 3、NVIC 二、软件设计 1、KEYLED 2、can.h 3、can.c (1)CAN1中断初始化 (2)RNG初始化和随机数产生 (3) 筛选器组设置…...

Python应用指南:高德交通态势数据
在现代城市的脉络中,交通流量如同流动的血液,交通流量的动态变化对出行规划和城市管理提出了更高的要求。为了应对这一挑战,高德地图推出了交通态势查询API,旨在为开发者提供一个强大的工具,用于实时获取指定区域或道路…...

医学图像分析工具01:FreeSurfer || Recon -all 全流程MRI皮质表面重建
FreeSurfer是什么 FreeSurfer 是一个功能强大的神经影像学分析软件包,广泛用于处理和可视化大脑的横断面和纵向研究数据。该软件由马萨诸塞州总医院的Martinos生物医学成像中心的计算神经影像实验室开发,旨在为神经科学研究人员提供一个高效、精确的数据…...

.NET框架用C#实现PDF转HTML
HTML作为一种开放标准的网页标记语言,具有跨平台、易于浏览和搜索引擎友好的特性,使得内容能够在多种设备上轻松访问并优化了在线分享与互动。通过将PDF文件转换为HTML格式,我们可以更方便地在浏览器中展示PDF文档内容,同时也更容…...

mamba-ssm安装
注意1:mamba-ssm要与casual-conv1d一起安装。 注意2:mamba-ssm与cuda、pytorch版本要对应。需要看你下载的代码的requirements.txt causal-conv1d与mamba的whl包官网下载: https://github.com/Dao-AILab/causal-conv1d/releases?page3 htt…...

网络IP协议
IP(Internet Protocol,网际协议)是TCP/IP协议族中重要的协议,主要负责将数据包发送给目标主机。IP相当于OSI(图1)的第三层网络层。网络层的主要作用是失陷终端节点之间的通信。这种终端节点之间的通信也叫点…...

双指针算法详解
目录 一、双指针 二、双指针题目 1.移动零 解法: 代码: 2.复写零 编辑 解法: 代码: 边界情况处理: 3.快乐数 编辑 解法:快慢指针 代码: 4.盛水最多的容器 解法:(对撞指针)…...

MySQL的最左匹配原则是什么
最左匹配原则是应用于联合索引的规则。 对于以下表F:f1,f2,f3;建立了联合索引(f2,f3),那么我们在查询的时候如果是: select * from F where f2 ? and f3 ?; 或 sele…...

LeetCode:106.从中序与后序遍历序列构造二叉树
跟着carl学算法,本系列博客仅做个人记录,建议大家都去看carl本人的博客,写的真的很好的! 代码随想录 LeetCode:106.从中序与后序遍历序列构造二叉树 给定两个整数数组 inorder 和 postorder ,其中 inorder …...

22. 【.NET 8 实战--孢子记账--从单体到微服务】--记账模块--切换主币种
这篇文章我们将结合主币种设置以及收支记录实现切换主币种后重新计算以前记录的转换后的金额。那么,为什么要在切换主币种后要重新计算转换后的金额呢?有以下两个原因: 统一的币种,方便我们统计数据方便用户按照当地的币种查看收…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...

[智能体-81]:工程化智能体 = 模型做脑力拆解 + 框架做流程落地。前者是决策者,后者是管理者,tools/function call是内部员工;mcp server是外部资源;
一、全角色人设 & 对应技术组件角色定位对应技术模块核心职责决策者(脑力大脑)大模型 LLM理解目标、任务拆解、逻辑判断、分支决策、内容生成,负责 “想方案、定步骤”管理者(流程总管)智能体编排框架(…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...

Windows文件夹共享
目标:同一局域网实现在一台计算机上共享文件夹,在另一台电脑访问一、电脑A 1.点击要共享的文件夹 -> 属性 -> 共享2.添加Everyone用户组3.控制面板中网络共享关闭密码保存,在访问时不用输入账号密码。二、电脑B 1.在文件资源管理器路径…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

掌握Umi-OCR:5分钟上手开源免费离线文字识别工具
掌握Umi-OCR:5分钟上手开源免费离线文字识别工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。…...