【Go学习】-01-4-项目管理及协程
【Go学习】-01-4-项目管理及协程
- 1 项目管理
- 1.1 包
- 1.1.1 包的基本概念
- 1.1.2 包的导入
- 1.1.3 包的导入路径
- 1.1.4 包的引用格式
- 1.2. go mod
- 1.2.1 项目中使用
- 2 协程并发
- 2.1 并发
- 2.2 Goroutine
- 2.2.1 使用
- 2.2.2 GMP
- 2.2.2.1 Golang “调度器” 的由来
- 2.2.2.2 Go 语言的协程 goroutine
- 2.2.2.3 Goroutine 调度器的 GMP 模型的设计思想
- 2.3 runtime包
- 2.3.1 runtime.Gosched()
- 2.3.2 runtime.Goexit()
- 2.3.3 runtime.GOMAXPROCS
- 3 协程通信
- 3.1 channel
- 3.1.1 创建通道
- 3.1.2 channel操作
- 3.1.3 无缓冲的通道
- 3.1.4 有缓冲的通道
- 3.1.5 close()
- 3.1.6 如何优雅的从通道循环取值
- 3.1.7 单向通道
- 3.2 select
- 4 协程安全
- 4.1 互斥锁
- 4.2 读写互斥锁
- 5 原子操作(atomic包)
1 项目管理
1.1 包
Go语言是使用包来组织源代码的,包(package)是多个 Go 源码的集合,是一种高级的代码复用方案。Go语言中为我们提供了很多内置包,如 fmt、os、io 等。
任何源代码文件必须属于某个包,同时源码文件的第一行有效代码必须是package pacakgeName 语句,通过该语句声明自己所在的包。
1.1.1 包的基本概念
Go语言的包借助了目录树的组织形式,一般包的名称就是其源文件所在目录的名称,虽然Go语言没有强制要求包名必须和其所在的目录名同名,但还是建议包名和所在目录同名,这样结构更清晰。
包可以定义在很深的目录中,包名的定义是不包括目录路径的,但是包在引用时一般使用全路径引用。
包的习惯用法:
- 包名一般是小写的,使用一个简短且有意义的名称。
- 包名一般要和所在的目录同名,也可以不同,包名中不能包含
-等特殊符号。 - 包名为 main 的包为应用程序的入口包,编译不包含 main 包的源码文件时不会得到可执行文件。
- 一个文件夹下的所有源码文件只能属于同一个包,同样属于同一个包的源码文件不能放在多个文件夹下。
1.1.2 包的导入
要在代码中引用其他包的内容,需要使用 import 关键字导入使用的包。具体语法如下:
import "包的路径"
注意事项:
- import 导入语句通常放在源码文件开头包声明语句的下面;
- 导入的包名需要使用双引号包裹起来;
包的导入有两种写法,分别是单行导入和多行导入。
单行导入
import "包 1 的路径"
import "包 2 的路径"
多行导入
import ("包 1 的路径""包 2 的路径"
)
1.1.3 包的导入路径
包的绝对路径就是GOROOT/src/或GOPATH后面包的存放路径,如下所示:
import "lab/test"
import "database/sql/driver"
import "database/sql"
上面代码的含义如下:
- test 包是自定义的包,其源码位于
GOPATH/lab/test目录下; - driver 包的源码位于
GOROOT/src/database/sql/driver目录下; - sql 包的源码位于
GOROOT/src/database/sql目录下。
1.1.4 包的引用格式
包的引用有四种格式,下面以 fmt 包为例来分别演示一下这四种格式。
-
标准引用格式
import "fmt"此时可以用
fmt.作为前缀来使用 fmt 包中的方法,这是常用的一种方式。package main import "fmt" func main() {fmt.Println("ms的go教程") } -
自定义别名引用格式
在导入包的时候,我们还可以为导入的包设置别名,如下所示:
import F "fmt"其中 F 就是 fmt 包的别名,使用时我们可以使用
F.来代替标准引用格式的fmt.来作为前缀使用 fmt 包中的方法package main import F "fmt" func main() {F.Println("ms的go教程") } -
省略引用格式
import . "fmt"这种格式相当于把 fmt 包直接合并到当前程序中,在使用 fmt 包内的方法是可以不用加前缀
fmt.,直接引用。package main import . "fmt" func main() {//不需要加前缀 fmt.Println("ms的go教程") } -
匿名引用格式
在引用某个包时,如果只是希望执行包初始化的 init 函数,而不使用包内部的数据时,可以使用匿名引用格式,如下所示:
import _ "fmt"匿名导入的包与其他方式导入的包一样都会被编译到可执行文件中。
使用标准格式引用包,但是代码中却没有使用包,编译器会报错。如果包中有 init 初始化函数,则通过
import _ "包的路径"这种方式引用包,仅执行包的初始化函数,即使包没有 init 初始化函数,也不会引发编译器报错。package main import (_ "database/sql""fmt" ) func main() {fmt.Println("ms的go教程") }
注意:
- 一个包可以有多个 init 函数,包加载时会执行全部的 init 函数,但并不能保证执行顺序,所以不建议在一个包中放入多个 init 函数,将需要初始化的逻辑放到一个 init 函数里面。
- 包不能出现环形引用的情况,比如包 a 引用了包 b,包 b 引用了包 c,如果包 c 又引用了包 a,则编译不能通过。
- 包的重复引用是允许的,比如包 a 引用了包 b 和包 c,包 b 和包 c 都引用了包 d。这种场景相当于重复引用了 d,这种情况是允许的,并且 Go 编译器保证包 d 的 init 函数只会执行一次。
1.2. go mod
go module 是Go语言从 1.11 版本之后官方推出的版本管理工具,并且从 Go1.13 版本开始,go module 成为了Go语言默认的依赖管理工具。
Modules 官方定义为:
Modules 是相关 Go 包的集合,是源代码交换和版本控制的单元。Go语言命令直接支持使用 Modules,包括记录和解析对其他模块的依赖性,Modules 替换旧的基于 GOPATH 的方法,来指定使用哪些源文件。
使用go module之前需要设置环境变量:
-
GO111MODULE=on
在环境变量中声明

-
GOPROXY=https://goproxy.io,direct
-
GOPROXY=https://goproxy.cn,direct(国内的七牛云提供)
GO111MODULE 有三个值:off, on和auto(默认值)。
- GO111MODULE=off,go命令行将不会支持module功能,寻找依赖包的方式将会沿用旧版本那种通过vendor目录或者GOPATH模式来查找。
- GO111MODULE=on,go命令行会使用modules,而一点也不会去GOPATH目录下查找。
- GO111MODULE=auto,默认值,go命令行将会根据当前目录来决定是否启用module功能。这种情况下可以分为两种情形:
- 当前目录在GOPATH之外且该目录包含go.mod文件 开启
- 当处于 GOPATH 内且没有 go.mod 文件存在时其行为会等同于 GO111MODULE=off
- 如果不使用 Go Modules, go get 将会从模块代码的 master 分支拉取
- 而若使用 Go Modules 则你可以利用 Git Tag 手动选择一个特定版本的模块代码
go mod 有以下命令:
| 命令 | 说明 |
|---|---|
| download | download modules to local cache(下载依赖包) |
| edit | edit go.mod from tools or scripts(编辑go.mod) |
| graph | print module requirement graph (打印模块依赖图) |
| init | initialize new module in current directory(在当前目录初始化mod) |
| tidy | add missing and remove unused modules(拉取缺少的模块,移除不用的模块) |
| vendor | make vendored copy of dependencies(将依赖复制到vendor下) |
| verify | verify dependencies have expected content (验证依赖是否正确) |
| why | explain why packages or modules are needed(解释为什么需要依赖) |
- 常用的有
init tidy edit
使用go get命令下载指定版本的依赖包:
执行go get 命令,在下载依赖包的同时还可以指定依赖包的版本。
- 运行
go get -u命令会将项目中的包升级到最新的次要版本或者修订版本; - 运行
go get -u=patch命令会将项目中的包升级到最新的修订版本; - 运行
go get [包名]@[版本号]命令会下载对应包的指定版本或者将对应包升级到指定的版本。
提示:
go get [包名]@[版本号]命令中版本号可以是 x.y.z 的形式,例如 go get foo@v1.2.3,也可以是 git 上的分支或 tag,例如 go get foo@master,还可以是 git 提交时的哈希值,例如 go get foo@e3702bed2。
1.2.1 项目中使用
-
在 GOPATH 目录下新建一个目录,并使用
go mod init初始化生成 go.mod 文件。go.mod 文件一旦创建后,它的内容将会被 go toolchain 全面掌控,go toolchain 会在各类命令执行时,比如
go get、go build、go mod等修改和维护 go.mod 文件。go.mod 提供了 module、require、replace 和 exclude 四个命令:
- module 语句指定包的名字(路径);
- require 语句指定的依赖项模块;
- replace 语句可以替换依赖项模块;
- exclude 语句可以忽略依赖项模块。
初始化生成的 go.mod 文件如下所示:
module hellogo 1.13 -
添加依赖。
新建一个 main.go 文件,写入以下代码:
package main import ("net/http""github.com/labstack/echo" ) func main() {e := echo.New()e.GET("/", func(c echo.Context) error {return c.String(http.StatusOK, "Hello, World!")})e.Logger.Fatal(e.Start(":1323")) }没下载依赖之前的go.mod
module learing02go 1.17执行
go mod tidy运行代码会发现 go mod 会自动查找依赖自动下载F:\Code\Golang\TuLing\workPath\hello>go mod tidy -compat=1.17 go: finding module for package github.com/labstack/echo go: found github.com/labstack/echo in github.com/labstack/echo v3.3.10+incompatible go: finding module for package github.com/stretchr/testify/assert go: finding module for package github.com/labstack/gommon/log go: finding module for package github.com/labstack/gommon/color go: finding module for package golang.org/x/crypto/acme/autocert go: found github.com/labstack/gommon/color in github.com/labstack/gommon v0.4.2 go: found github.com/labstack/gommon/log in github.com/labstack/gommon v0.4.2 go: found golang.org/x/crypto/acme/autocert in golang.org/x/crypto v0.31.0 go: found github.com/stretchr/testify/assert in github.com/stretchr/testify v1.10.0go.mod中的内容:
module hellogo 1.17require github.com/labstack/echo v3.3.10+incompatiblerequire (github.com/labstack/gommon v0.4.2 // indirectgithub.com/mattn/go-colorable v0.1.13 // indirectgithub.com/mattn/go-isatty v0.0.20 // indirectgithub.com/stretchr/testify v1.10.0 // indirectgithub.com/valyala/bytebufferpool v1.0.0 // indirectgithub.com/valyala/fasttemplate v1.2.2 // indirectgolang.org/x/crypto v0.31.0 // indirectgolang.org/x/net v0.21.0 // indirectgolang.org/x/sys v0.28.0 // indirectgolang.org/x/text v0.21.0 // indirect )启动项目访问localhost:1323

go module 安装 package 的原则是先拉取最新的 release tag,若无 tag 则拉取最新的 commit
go 会自动生成一个 go.sum 文件来记录 dependency tree。
执行脚本
go run main.go,就可以运行项目。可以使用命令
go list -m -u all来检查可以升级的 package,使用go get -u need-upgrade-package升级后会将新的依赖版本更新到 go.mod ,比如:
go get -u github.com/labstack/gommon也可以使用
go get -u升级所有依赖。 -
一般使用包之前,是首先执行
go get命令,先下载依赖。比如github.com/labstack/echo
使用 replace 替换无法直接获取的 package:
由于某些已知的原因,并不是所有的 package 都能成功下载,比如:golang.org 下的包。
modules 可以通过在 go.mod 文件中使用 replace 指令替换成 github 上对应的库,比如:
replace (golang.org/x/crypto v0.0.0-20190313024323-a1f597ede03a => github.com/golang/crypto v0.0.0-20190313024323-a1f597ede03a
)
或者
replace golang.org/x/crypto v0.0.0-20190313024323-a1f597ede03a => github.com/golang/crypto v0.0.0-20190313024323-a1f597ede03a
go install命令将项目打包安装为可执行文件,在安装在GOPATH的bin目录下,go install执行的项目 必须有main方法
2 协程并发
2.1 并发
有人把Go语言比作 21 世纪的C语言,第一是因为Go语言设计简单,第二则是因为 21 世纪最重要的就是并发程序设计,而 Go 从语言层面就支持并发。同时实现了自动垃圾回收机制。
先来了解一些概念:
进程/线程
进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。
线程是进程的一个执行实体,是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。
一个进程可以创建和撤销多个线程,同一个进程中的多个线程之间可以并发执行。
并发/并行
多线程程序在单核心的 cpu 上运行,称为并发;
多线程程序在多核心的 cpu 上运行,称为并行。
并发与并行并不相同,并发主要由切换时间片来实现“同时”运行,并行则是直接利用多核实现多线程的运行,Go程序可以设置使用核心数,以发挥多核计算机的能力。
协程/线程
协程:独立的栈空间,共享堆空间,调度由用户自己控制,本质上有点类似于用户级线程,这些用户级线程的调度也是自己实现的。
线程:一个线程上可以跑多个协程,协程是轻量级的线程。
2.2 Goroutine
Goroutine 一般将其翻译为Go协程,也就是说Go语言在语言层面就实现了协程的支持。
在java/c++中我们要实现并发编程的时候,我们通常需要自己维护一个线程池,并且需要自己去包装一个又一个的任务,同时需要自己去调度线程执行任务并维护上下文切换,这一切通常会耗费程序员大量的心智。那么能不能有一种机制,程序员只需要定义很多个任务,让系统去帮助我们把这些任务分配到CPU上实现并发执行呢?
Go语言中的goroutine就是这样一种机制, goroutine是由Go的运行时(runtime)调度和管理的。
Go程序会智能地将 goroutine 中的任务合理地分配给每个CPU。
Go语言之所以被称为现代化的编程语言,就是因为它在语言层面已经内置了调度和上下文切换的机制。
在Go语言编程中你不需要去自己写进程、线程、协程,你的技能包里只有一个技能–goroutine,当你需要让某个任务并发执行的时候,你只需要把这个任务包装成一个函数,开启一个goroutine去执行这个函数就可以了,就是这么简单粗暴。
2.2.1 使用
Go语言中使用goroutine非常简单,只需要在调用函数的时候在前面加上go关键字,就可以为一个函数创建一个goroutine。
一个goroutine必定对应一个函数,可以创建多个goroutine去执行相同的函数。
go 函数名( 参数列表 )
- 函数名:要调用的函数名。
- 参数列表:调用函数需要传入的参数。
启动单个goroutine
func hello() {fmt.Println("Hello Goroutine!")
}
func main() {hello()fmt.Println("main goroutine done!")
}
这个示例中hello函数和下面的语句是串行的,执行的结果是打印完Hello Goroutine!后打印main goroutine done!。
接下来我们在调用hello函数前面加上关键字go,也就是启动一个goroutine去执行hello这个函数。
func main() {go hello() // 启动一个goroutine去执行hello函数fmt.Println("main goroutine done!")
}
这一次的执行结果只打印了main goroutine done!,并没有打印Hello Goroutine!。
为什么呢?
在程序启动时,Go程序就会为main()函数创建一个默认的goroutine。
当main()函数返回的时候该goroutine就结束了,所有在main()函数中启动的goroutine会一同结束,main函数所在的goroutine就像是权利的游戏中的夜王,其他的goroutine都是异鬼,夜王一死它转化的那些异鬼也就全部GG了。
所以我们要想办法让main函数等一等hello函数,最简单粗暴的方式就是time.Sleep了。
func main() {go hello() // 启动一个goroutine去执行hello函数fmt.Println("main goroutine done!")time.Sleep(time.Second)
}
执行上面的代码你会发现,这一次先打印main goroutine done!,然后紧接着打印Hello Goroutine!。
首先为什么会先打印main goroutine done!是因为我们在创建新的goroutine的时候需要花费一些时间,而此时main函数所在的goroutine是继续执行的。
启动多个goroutine
package mainimport ("fmt""time"
)func hello(i int) {fmt.Println("Hello Goroutine!" , i)
}func main() {for i := 0; i < 10; i++ {go hello(i)}fmt.Println("main goroutine done!")time.Sleep(time.Second * 2)
}多次执行上面的代码,会发现每次打印的数字的顺序都不一致。这是因为10个goroutine是并发执行的,而goroutine的调度是随机的。
问题:主协程 退出了,子协程还会执行吗?
如果主协程退出了,子协程不会自动停止,并且它会继续执行,除非有明确的同步机制(如
sync.WaitGroup或通道)来控制子协程。如果主协程结束时没有等待子协程完成,程序会在主协程退出后直接结束,未完成的子协程也会被强制终止。
OS线程(操作系统线程)一般都有固定的栈内存(通常为2MB),一个goroutine的栈在其生命周期开始时只有很小的栈(典型情况下2KB),goroutine的栈不是固定的,他可以按需增大和缩小,goroutine的栈大小限制可以达到1GB,虽然极少会用到这个大。所以在Go语言中一次创建十万左右的goroutine也是可以的。
2.2.2 GMP
GMP是Go语言运行时(runtime)层面的实现,是go语言自己实现的一套调度系统。区别于操作系统调度OS线程。
- G很好理解,就是个goroutine的,里面除了存放本goroutine信息外 还有与所在P的绑定等信息。
- P管理着一组goroutine队列,P里面会存储当前goroutine运行的上下文环境(函数指针,堆栈地址及地址边界),P会对自己管理的goroutine队列做一些调度(比如把占用CPU时间较长的goroutine暂停、运行后续的goroutine等等)当自己的队列消费完了就去全局队列里取,如果全局队列里也消费完了会去其他P的队列里抢任务。
- M是Go运行时(runtime)对操作系统内核线程的虚拟, M与内核线程一般是一一映射的关系, 一个groutine最终是要放到M上执行的;
P与M一般也是一一对应的。他们关系是: P管理着一组G挂载在M上运行。当一个G长久阻塞在一个M上时,runtime会新建一个M,阻塞G所在的P会把其他的G 挂载在新建的M上。当旧的G阻塞完成或者认为其已经死掉时 回收旧的M。
P的个数是通过runtime.GOMAXPROCS设定(最大256),Go1.5版本之后默认为物理线程数。 在并发量大的时候会增加一些P和M,但不会太多,切换太频繁的话得不偿失。
单从线程调度讲,Go语言相比起其他语言的优势在于OS线程是由OS内核来调度的,goroutine则是由Go运行时(runtime)自己的调度器调度的,这个调度器使用一个称为m:n调度的技术(复用/调度m个goroutine到n个OS线程)。 其一大特点是goroutine的调度是在用户态下完成的, 不涉及内核态与用户态之间的频繁切换,包括内存的分配与释放,都是在用户态维护着一块大的内存池, 不直接调用系统的malloc函数(除非内存池需要改变),成本比调度OS线程低很多。 另一方面充分利用了多核的硬件资源,近似的把若干goroutine均分在物理线程上, 再加上本身goroutine的超轻量,以上种种保证了go调度方面的性能。
2.2.2.1 Golang “调度器” 的由来
单进程时代不需要调度器

我们知道,一切的软件都是跑在操作系统上,真正用来干活 (计算) 的是 CPU。早期的操作系统每个程序就是一个进程,直到一个程序运行完,才能进行下一个进程,就是 “单进程时代”
一切的程序只能串行发生。
早期的单进程操作系统,面临 2 个问题:
- 单一的执行流程,计算机只能一个任务一个任务处理。
- 进程阻塞所带来的 CPU 时间浪费。
那么能不能有多个进程来宏观一起来执行多个任务呢?
后来操作系统就具有了最早的并发能力:多进程并发,当一个进程阻塞的时候,切换到另外等待执行的进程,这样就能尽量把 CPU 利用起来,CPU 就不浪费了。
多进程 / 线程时代有了调度器需求

在多进程 / 多线程的操作系统中,就解决了阻塞的问题,因为一个进程阻塞 cpu 可以立刻切换到其他进程中去执行,而且调度 cpu 的算法可以保证在运行的进程都可以被分配到 cpu 的运行时间片。这样从宏观来看,似乎多个进程是在同时被运行。
但新的问题就又出现了,进程拥有太多的资源,进程的创建、切换、销毁,都会占用很长的时间,CPU 虽然利用起来了,但如果进程过多,CPU 有很大的一部分都被用来进行进程调度了。

怎么才能提高 CPU 的利用率呢?
对于 Linux 操作系统来讲,cpu 对进程的态度和线程的态度是一样的。
很明显,CPU 调度切换的是进程和线程。尽管线程看起来很美好,但实际上多线程开发设计会变得更加复杂,要考虑很多同步竞争等问题,如锁、竞争冲突等。
协程来提高 CPU 利用率
多进程、多线程已经提高了系统的并发能力,但是在当今互联网高并发场景下,为每个任务都创建一个线程是不现实的,因为会消耗大量的内存 (进程虚拟内存会占用 4GB [32 位操作系统], 而线程也要大约 4MB)。
大量的进程 / 线程出现了新的问题
- 高内存占用
- 调度的高消耗 CPU
好了,然后工程师们就发现,其实一个线程分为 “内核态 “线程和” 用户态 “线程。

一个 “用户态线程” 必须要绑定一个 “内核态线程”,但是 CPU 并不知道有 “用户态线程” 的存在,它只知道它运行的是一个 “内核态线程”(Linux 的 PCB 进程控制块)。
我们再去细化去分类一下,内核线程依然叫 “线程 (thread)”,用户线程叫 “协程 (co-routine)”.

既然一个协程 (co-routine) 可以绑定一个线程 (thread),那么能不能多个协程 (co-routine) 绑定一个或者多个线程 (thread) 上呢。
有 三种协程和线程的映射关系:
-
N:1 关系

N 个协程绑定 1 个线程,优点就是协程在用户态线程即完成切换,不会陷入到内核态,这种切换非常的轻量快速。但也有很大的缺点,1 个进程的所有协程都绑定在 1 个线程上
缺点:
- 某个程序用不了硬件的多核加速能力
- 一旦某协程阻塞,造成线程阻塞,本进程的其他协程都无法执行了,根本就没有并发的能力了。
-
1:1 关系
1 个协程绑定 1 个线程,这种最容易实现。协程的调度都由 CPU 完成了,不存在 N:1 缺点,
缺点:
- 协程的创建、删除和切换的代价都由 CPU 完成,有点略显昂贵了。

-
M:N 关系
M 个协程绑定 N 个线程,是 N:1 和 1:1 类型的结合,克服了以上 2 种模型的缺点,但实现起来最为复杂。

协程跟线程是有区别的,线程由 CPU 调度是抢占式的,协程由用户态调度是协作式的,一个协程让出 CPU 后,才执行下一个协程。
2.2.2.2 Go 语言的协程 goroutine
Go 为了提供更容易使用的并发方法,使用了 goroutine 和 channel。goroutine 来自协程的概念,让一组可复用的函数运行在一组线程之上,即使有协程阻塞,该线程的其他协程也可以被 runtime 调度,转移到其他可运行的线程上。最关键的是,程序员看不到这些底层的细节,这就降低了编程的难度,提供了更容易的并发。
Go 中,协程被称为 goroutine,它非常轻量,一个 goroutine 只占几 KB,并且这几 KB 就足够 goroutine 运行完,这就能在有限的内存空间内支持大量 goroutine,支持了更多的并发。虽然一个 goroutine 的栈只占几 KB,但实际是可伸缩的,如果需要更多内容,runtime 会自动为 goroutine 分配。
Goroutine 特点:
- 占用内存更小(几 kb)
- 调度更灵活 (runtime 调度)
被废弃的 goroutine 调度器
Go 目前使用的调度器是 2012 年重新设计的,因为之前的调度器性能存在问题,所以使用 4 年就被废弃了,那么我们先来分析一下被废弃的调度器是如何运作的?

来看看被废弃的 golang 调度器是如何实现的?

M 想要执行、放回 G 都必须访问全局 G 队列,并且 M 有多个,即多线程访问同一资源需要加锁进行保证互斥 / 同步,所以全局 G 队列是有互斥锁进行保护的。
老调度器有几个缺点:
- 创建、销毁、调度 G 都需要每个 M 获取锁,这就形成了激烈的锁竞争。
- M 转移 G 会造成延迟和额外的系统负载。比如当 G 中包含创建新协程的时候,M 创建了 G’,为了继续执行 G,需要把 G’交给 M’执行,也造成了很差的局部性,因为 G’和 G 是相关的,最好放在 M 上执行,而不是其他 M’。
- 系统调用 (CPU 在 M 之间的切换) 导致频繁的线程阻塞和取消阻塞操作增加了系统开销。
2.2.2.3 Goroutine 调度器的 GMP 模型的设计思想
新调度器中,除了 M (thread) 和 G (goroutine),又引进了 P (Processor)。

Processor,它包含了运行 goroutine 的资源,如果线程想运行 goroutine,必须先获取 P,P 中还包含了可运行的 G 队列。
GMP 模型
在 Go 中,线程是运行 goroutine 的实体,调度器的功能是把可运行的 goroutine 分配到工作线程上。

- 全局队列(Global Queue):存放等待运行的 G。
- P 的本地队列:同全局队列类似,存放的也是等待运行的 G,存的数量有限,不超过 256 个。新建 G’时,G’优先加入到 P 的本地队列,如果队列满了,则会把本地队列中一半的 G 移动到全局队列。
- P 列表:所有的 P 都在程序启动时创建,并保存在数组中,最多有 GOMAXPROCS(可配置) 个。
- M:线程想运行任务就得获取 P,从 P 的本地队列获取 G,P 队列为空时,M 也会尝试从全局队列拿一批 G 放到 P 的本地队列,或从其他 P 的本地队列偷一半放到自己 P 的本地队列。M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。
Goroutine 调度器和 OS 调度器是通过 M 结合起来的,每个 M 都代表了 1 个内核线程,OS 调度器负责把内核线程分配到 CPU 的核上执行。
有关 P 和 M 的个数问题
- P 的数量:
- 由启动时环境变量 $GOMAXPROCS 或者是由 runtime 的方法 GOMAXPROCS() 决定。这意味着在程序执行的任意时刻都只有 $GOMAXPROCS 个 goroutine 在同时运行。
- M 的数量:
- go 语言本身的限制:go 程序启动时,会设置 M 的最大数量,默认 10000. 但是内核很难支持这么多的线程数,所以这个限制可以忽略。
- runtime/debug 中的 SetMaxThreads 函数,设置 M 的最大数量
- 一个 M 阻塞了,会创建新的 M。
M 与 P 的数量没有绝对关系,一个 M 阻塞,P 就会去创建或者切换另一个 M,所以,即使 P 的默认数量是 1,也有可能会创建很多个 M 出来。
P 和 M 何时会被创建
- P 何时创建:在确定了 P 的最大数量 n 后,运行时系统会根据这个数量创建 n 个 P。
- M 何时创建:没有足够的 M 来关联 P 并运行其中的可运行的 G。比如所有的 M 此时都阻塞住了,而 P 中还有很多就绪任务,就会去寻找空闲的 M,而没有空闲的,就会去创建新的 M。
调度器的设计策略
复用线程:避免频繁的创建、销毁线程,而是对线程的复用。
- work stealing 机制
当本线程无可运行的 G 时,尝试从其他线程绑定的 P 偷取 G,而不是销毁线程。
- hand off 机制
当本线程因为 G 进行系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的线程执行。
利用并行:GOMAXPROCS 设置 P 的数量,最多有 GOMAXPROCS 个线程分布在多个 CPU 上同时运行。GOMAXPROCS 也限制了并发的程度,比如 GOMAXPROCS = 核数/2,则最多利用了一半的 CPU 核进行并行。
抢占:在 coroutine 中要等待一个协程主动让出 CPU 才执行下一个协程,在 Go 中,一个 goroutine 最多占用 CPU 10ms,防止其他 goroutine 被饿死,这就是 goroutine 不同于 coroutine 的一个地方。
全局 G 队列:在新的调度器中依然有全局 G 队列,但功能已经被弱化了,当 M 执行 work stealing 从其他 P 偷不到 G 时,它可以从全局 G 队列获取 G。
go func () 调度流程

从上图我们可以分析出几个结论:
-
我们通过 go func () 来创建一个 goroutine;
-
有两个存储 G 的队列,一个是局部调度器 P 的本地队列、一个是全局 G 队列。新创建的 G 会先保存在 P 的本地队列中,如果 P 的本地队列已经满了就会保存在全局的队列中;
-
G 只能运行在 M 中,一个 M 必须持有一个 P,M 与 P 是 1:1 的关系。M 会从 P 的本地队列弹出一个可执行状态的 G 来执行,如果 P 的本地队列为空,就会想其他的 MP 组合偷取一个可执行的 G 来执行;
-
一个 M 调度 G 执行的过程是一个循环机制;
-
当 M 执行某一个 G 时候如果发生了 syscall 或则其余阻塞操作,M 会阻塞,如果当前有一些 G 在执行,runtime 会把这个线程 M 从 P 中摘除 (detach),然后再创建一个新的操作系统的线程 (如果有空闲的线程可用就复用空闲线程) 来服务于这个 P;
-
当 M 系统调用结束时候,这个 G 会尝试获取一个空闲的 P 执行,并放入到这个 P 的本地队列。如果获取不到 P,那么这个线程 M 变成休眠状态, 加入到空闲线程中,然后这个 G 会被放入全局队列中。
调度器的生命周期

2.3 runtime包
2.3.1 runtime.Gosched()
让出CPU时间片,重新等待安排任务(大概意思就是本来计划的好好的周末出去烧烤,但是你妈让你去相亲,两种情况第一就是你相亲速度非常快,见面就黄不耽误你继续烧烤,第二种情况就是你相亲速度特别慢,见面就是你侬我侬的,耽误了烧烤,但是还馋就是耽误了烧烤你还得去烧烤)
package mainimport ("fmt""runtime"
)func main() {go func(s string) {for i := 0; i < 2; i++ {fmt.Println(s)}}("world")// 主协程for i := 0; i < 2; i++ {// 切一下,再次分配任务runtime.Gosched()fmt.Println("hello")}
}
如果没有添加runtime.Gosched(),在main执行时,go协程还没有准备好,那么只会打印
hello
hello
加上runtime.Gosched()后让主协程让出CPU,这时候go协程已经准备好了,也就能打印了
world
world
hello
hello
2.3.2 runtime.Goexit()
退出当前协程(一边烧烤一边相亲,突然发现相亲对象太丑影响烧烤,果断让她滚蛋,然后也就没有然后了)
package mainimport ("fmt""runtime"
)func main() {go func() {defer fmt.Println("A.defer")func() {defer fmt.Println("B.defer")// 结束协程runtime.Goexit()defer fmt.Println("C.defer")fmt.Println("B")}()fmt.Println("A")}()for {}
}
2.3.3 runtime.GOMAXPROCS
Go运行时的调度器使用GOMAXPROCS参数来确定需要使用多少个OS线程来同时执行Go代码。默认值是机器上的CPU核心数。例如在一个8核心的机器上,调度器会把Go代码同时调度到8个OS线程上(GOMAXPROCS是m:n调度中的n)。
Go语言中可以通过runtime.GOMAXPROCS()函数设置当前程序并发时占用的CPU逻辑核心数。
Go1.5版本之前,默认使用的是单核心执行。Go1.5版本之后,默认使用全部的CPU逻辑核心数。
我们可以通过将任务分配到不同的CPU逻辑核心上实现并行的效果,这里举个例子:
func a() {for i := 1; i < 10; i++ {fmt.Println("A:", i)}
}func b() {for i := 1; i < 10; i++ {fmt.Println("B:", i)}
}func main() {runtime.GOMAXPROCS(1)go a()go b()time.Sleep(time.Second)
}
两个任务只有一个逻辑核心,此时是做完一个任务再做另一个任务。
B: 2025-01-03 20:10:58.7039707 +0800 CST m=+0.004812601
A: 2025-01-03 20:10:58.7145147 +0800 CST m=+0.015356601
将逻辑核心数设为2,此时两个任务并行执行,代码如下。
func a() {for i := 1; i < 10; i++ {fmt.Println("A:", i)}
}func b() {for i := 1; i < 10; i++ {fmt.Println("B:", i)}
}func main() {runtime.GOMAXPROCS(2)go a()go b()time.Sleep(time.Second)
}
B: 2025-01-03 20:12:02.5558789 +0800 CST m=+0.005289701
A: 2025-01-03 20:12:02.5558789 +0800 CST m=+0.005289701
Go语言中的操作系统线程和goroutine的关系:
- 1.一个操作系统线程对应用户态多个goroutine。
- 2.go程序可以同时使用多个操作系统线程。
- 3.goroutine和OS线程是多对多的关系,即m:n。
3 协程通信
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。
虽然可以使用共享内存进行数据交换,但是共享内存在不同的goroutine中容易发生竞态问题。为了保证数据交换的正确性,必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
Go语言的并发模型是CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
如果说goroutine是Go程序并发的执行体,channel就是它们之间的连接。channel是可以让一个goroutine发送特定值到另一个goroutine的通信机制。
Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
channel是一种类型,一种引用类型。声明通道类型的格式如下:
var 变量 chan 类型
var ch1 chan int // 声明一个传递整型的通道
var ch2 chan bool // 声明一个传递布尔型的通道
var ch3 chan []int // 声明一个传递int切片的通道
3.1 channel
3.1.1 创建通道
通道是引用类型,通道类型的空值是nil。
var ch chan int
fmt.Println(ch) // <nil>
声明通道后需要使用make函数初始化之后才能使用。
创建channel的格式如下:
make(chan 元素类型, [缓冲大小])
channel的缓冲大小是可选的。
ch4 := make(chan int)
ch5 := make(chan bool)
ch6 := make(chan []int)
3.1.2 channel操作
通道有发送(send)、接收(receive)和关闭(close)三种操作。
发送和接收都使用<-符号。
现在我们先使用以下语句定义一个通道:
ch := make(chan int)
发送:
将一个值发送到通道中。
ch <- 10 // 把10发送到ch中
接收:
从一个通道中接收值。
x := <- ch // 从ch中接收值并赋值给变量x
<-ch // 从ch中接收值,忽略结果
关闭:
我们通过调用内置的close函数来关闭通道。
close(ch)
关于关闭通道需要注意的事情是,只有在通知接收方goroutine所有的数据都发送完毕的时候才需要关闭通道。通道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的。
关闭后的通道有以下特点:
- 对一个关闭的通道再发送值就会导致panic。
- 对一个关闭的通道进行接收会一直获取值直到通道为空。
- 对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。
- 关闭一个已经关闭的通道会导致panic。
3.1.3 无缓冲的通道
无缓冲的通道又称为阻塞的通道。我们来看一下下面的代码:
func main() {ch := make(chan int)ch <- 10fmt.Println("发送成功")
}
上面这段代码能够通过编译,但是执行的时候会出现以下错误:
fatal error: all goroutines are asleep - deadlock!
为什么会出现deadlock错误呢?
因为我们使用ch := make(chan int)创建的是无缓冲的通道,无缓冲的通道只有在有人接收值的时候才能发送值。就像你住的小区没有快递柜和代收点,快递员给你打电话必须要把这个物品送到你的手中,简单来说就是无缓冲的通道必须有接收才能发送。
上面的代码会阻塞在ch <- 10这一行代码形成死锁,那如何解决这个问题呢?
一种方法是启用一个goroutine去接收值,例如:
func recv(c chan int) {ret := <-cfmt.Println("接收成功", ret)
}
func main() {ch := make(chan int)go recv(ch) // 启用goroutine从通道接收值ch <- 10fmt.Println("发送成功")
}
无缓冲通道上的发送操作会阻塞,直到另一个goroutine在该通道上执行接收操作,这时值才能发送成功,两个goroutine将继续执行。相反,如果接收操作先执行,接收方的goroutine将阻塞,直到另一个goroutine在该通道上发送一个值。
使用无缓冲通道进行通信将导致发送和接收的goroutine同步化。因此,无缓冲通道也被称为同步通道。
3.1.4 有缓冲的通道
我们可以在使用make函数初始化通道的时候为其指定通道的容量,例如:
func main() {ch := make(chan int, 1) // 创建一个容量为1的有缓冲区通道ch <- 10fmt.Println("发送成功")
}
只要通道的容量大于零,那么该通道就是有缓冲的通道,通道的容量表示通道中能存放元素的数量。就像你小区的快递柜只有那么个多格子,格子满了就装不下了,就阻塞了,等到别人取走一个快递员就能往里面放一个。
我们可以使用内置的len函数获取通道内元素的数量,使用cap函数获取通道的容量,虽然我们很少会这么做。
3.1.5 close()
可以通过内置的close()函数关闭channel(如果你的管道不往里存值或者取值的时候一定记得关闭管道)
package mainimport "fmt"func main() {c := make(chan int)go func() {for i := 0; i < 5; i++ {c <- i}close(c)}()for {if data, ok := <-c; ok {fmt.Println(data)} else {break}}fmt.Println("main结束")
}
注意:关闭已经关闭的channel会引发panic。
3.1.6 如何优雅的从通道循环取值
当通过通道发送有限的数据时,我们可以通过close函数关闭通道来告知从该通道接收值的goroutine停止等待。当通道被关闭时,往该通道发送值会引发panic,从该通道里接收的值一直都是类型零值。那如何判断一个通道是否被关闭了呢?
我们来看下面这个例子:
func main() {ch1 := make(chan int)ch2 := make(chan int)// 开启goroutine将0~100的数发送到ch1中go func() {for i := 0; i < 100; i++ {ch1 <- i}close(ch1)}()// 开启goroutine从ch1中接收值,并将该值的平方发送到ch2中go func() {for {i, ok := <-ch1 // 通道关闭后再取值ok=falseif !ok {break}ch2 <- i * i}close(ch2)}()// 在主goroutine中从ch2中接收值打印for i := range ch2 { // 通道关闭后会退出for range循环fmt.Println(i)}
}
从上面的例子中我们看到有两种方式在接收值的时候判断通道是否被关闭,我们通常使用的是for range的方式。
3.1.7 单向通道
有的时候我们会将通道作为参数在多个任务函数间传递,很多时候我们在不同的任务函数中使用通道都会对其进行限制,比如限制通道在函数中只能发送或只能接收。
Go语言中提供了单向通道来处理这种情况。例如,我们把上面的例子改造如下:
func counter(out chan<- int) {for i := 0; i < 100; i++ {out <- i}close(out)
}func squarer(out chan<- int, in <-chan int) {for i := range in {out <- i * i}close(out)
}
func printer(in <-chan int) {for i := range in {fmt.Println(i)}
}func main() {ch1 := make(chan int)ch2 := make(chan int)go counter(ch1)go squarer(ch2, ch1)printer(ch2)
}
chan<- int是一个只能发送的通道,可以发送但是不能接收;<-chan int是一个只能接收的通道,可以接收但是不能发送。
在函数传参及任何赋值操作中将双向通道转换为单向通道是可以的,但反过来是不可以的。
3.2 select
在某些场景下我们需要同时从多个通道接收数据。通道在接收数据时,如果没有数据可以接收将会发生阻塞。你也许会写出如下代码使用遍历的方式来实现:
for{// 尝试从ch1接收值data, ok := <-ch1// 尝试从ch2接收值data, ok := <-ch2…
}
这种方式虽然可以实现从多个通道接收值的需求,但是运行性能会差很多。为了应对这种场景,Go内置了select关键字,可以同时响应多个通道的操作。
select的使用类似于switch语句,它有一系列case分支和一个默认的分支。每个case会对应一个通道的通信(接收或发送)过程。select会一直等待,直到某个case的通信操作完成时,就会执行case分支对应的语句。具体格式如下:
select {case <-chan1:// 如果chan1成功读到数据,则进行该case处理语句case chan2 <- 1:// 如果成功向chan2写入数据,则进行该case处理语句default:// 如果上面都没有成功,则进入default处理流程}
select可以同时监听一个或多个channel,直到其中一个channel ready
package mainimport ("fmt""time"
)func test1(ch chan string) {time.Sleep(time.Second * 5)ch <- "test1"
}
func test2(ch chan string) {time.Sleep(time.Second * 2)ch <- "test2"
}func main() {// 2个管道output1 := make(chan string)output2 := make(chan string)// 跑2个子协程,写数据go test1(output1)go test2(output2)// 用select监控select {case s1 := <-output1:fmt.Println("s1=", s1)case s2 := <-output2:fmt.Println("s2=", s2)}
}
如果多个channel同时ready,则随机选择一个执行
package mainimport ("fmt"
)func main() {// 创建2个管道intChan := make(chan int, 1)stringChan := make(chan string, 1)go func() {//time.Sleep(2 * time.Second)intChan <- 1}()go func() {stringChan <- "hello"}()select {case value := <-intChan:fmt.Println("int:", value)case value := <-stringChan:fmt.Println("string:", value)}fmt.Println("main结束")
}
可以用于判断管道是否存满
package mainimport ("fmt""time"
)// 判断管道有没有存满
func main() {// 创建管道output1 := make(chan string, 10)// 子协程写数据go write(output1)// 取数据for s := range output1 {fmt.Println("res:", s)time.Sleep(time.Second)}
}func write(ch chan string) {for {select {// 写数据case ch <- "hello":fmt.Println("write hello")default:fmt.Println("channel full")}time.Sleep(time.Millisecond * 500)}
}
4 协程安全
有时候在Go代码中可能会存在多个goroutine同时操作一个资源(临界区),这种情况会发生竞态问题(数据竞态)。类比现实生活中的例子有十字路口被各个方向的的汽车竞争。
举个例子:
var x int64
var wg sync.WaitGroupfunc add() {for i := 0; i < 5000; i++ {x = x + 1}wg.Done()
}
func main() {wg.Add(2)go add()go add()wg.Wait()fmt.Println(x)
}
上面的代码中我们开启了两个goroutine去累加变量x的值,这两个goroutine在访问和修改x变量的时候就会存在数据竞争,导致最后的结果与期待的不符。
4.1 互斥锁
互斥锁是一种常用的控制共享资源访问的方法,它能够保证同时只有一个goroutine可以访问共享资源。Go语言中使用sync包的Mutex类型来实现互斥锁。
使用互斥锁来修复上面代码的问题:
var x int64
var wg sync.WaitGroup
var lock sync.Mutexfunc add() {for i := 0; i < 5000; i++ {lock.Lock() // 加锁x = x + 1lock.Unlock() // 解锁}wg.Done()
}
func main() {wg.Add(2)go add()go add()wg.Wait()fmt.Println(x)
}
使用互斥锁能够保证同一时间有且只有一个goroutine进入临界区,其他的goroutine则在等待锁;当互斥锁释放后,等待的goroutine才可以获取锁进入临界区,多个goroutine同时等待一个锁时,唤醒的策略是随机的。
4.2 读写互斥锁
互斥锁是完全互斥的,但是有很多实际的场景下是读多写少的,当我们并发的去读取一个资源不涉及资源修改的时候是没有必要加锁的,这种场景下使用读写锁是更好的一种选择。读写锁在Go语言中使用sync包中的RWMutex类型。
读写锁分为两种:读锁和写锁。当一个goroutine获取读锁之后,其他的goroutine如果是获取读锁会继续获得锁,如果是获取写锁就会等待;当一个goroutine获取写锁之后,其他的goroutine无论是获取读锁还是写锁都会等待。
读写锁示例:
var (x int64wg sync.WaitGrouplock sync.Mutexrwlock sync.RWMutex
)func write() {// lock.Lock() // 加互斥锁rwlock.Lock() // 加写锁x = x + 1time.Sleep(10 * time.Millisecond) // 假设读操作耗时10毫秒rwlock.Unlock() // 解写锁// lock.Unlock() // 解互斥锁wg.Done()
}func read() {// lock.Lock() // 加互斥锁rwlock.RLock() // 加读锁time.Sleep(time.Millisecond) // 假设读操作耗时1毫秒rwlock.RUnlock() // 解读锁// lock.Unlock() // 解互斥锁wg.Done()
}func main() {start := time.Now()for i := 0; i < 10; i++ {wg.Add(1)go write()}for i := 0; i < 1000; i++ {wg.Add(1)go read()}wg.Wait()end := time.Now()fmt.Println(end.Sub(start))
}
需要注意的是读写锁非常适合读多写少的场景,如果读和写的操作差别不大,读写锁的优势就发挥不出来。
5 原子操作(atomic包)
代码中的加锁操作因为涉及内核态的上下文切换会比较耗时、代价比较高。针对基本数据类型我们还可以使用原子操作来保证并发安全,因为原子操作是Go语言提供的方法它在用户态就可以完成,因此性能比加锁操作更好。Go语言中原子操作由内置的标准库sync/atomic提供。
atomic包
| 方法 | 解释 |
|---|---|
func LoadInt32(addr *int32) (val int32) func LoadInt64(addr *int64) (val int64)func LoadUint32(addr *uint32) (val uint32)func LoadUint64(addr *uint64) (val uint64)func LoadUintptr(addr *uintptr) (val uintptr)func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer) | 读取操作 |
func StoreInt32(addr *int32, val int32) func StoreInt64(addr *int64, val int64) func StoreUint32(addr *uint32, val uint32) func StoreUint64(addr *uint64, val uint64) func StoreUintptr(addr *uintptr, val uintptr) func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer) | 写入操作 |
func AddInt32(addr *int32, delta int32) (new int32) func AddInt64(addr *int64, delta int64) (new int64) func AddUint32(addr *uint32, delta uint32) (new uint32) func AddUint64(addr *uint64, delta uint64) (new uint64) func AddUintptr(addr *uintptr, delta uintptr) (new uintptr) | 修改操作 |
func SwapInt32(addr *int32, new int32) (old int32) func SwapInt64(addr *int64, new int64) (old int64) func SwapUint32(addr *uint32, new uint32) (old uint32) func SwapUint64(addr *uint64, new uint64) (old uint64) func SwapUintptr(addr *uintptr, new uintptr) (old uintptr) func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer) | 交换操作 |
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool) func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool) func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool) func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool) func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool) | 比较并交换操作 |
比较下互斥锁和原子操作的性能:
var x int64
var l sync.Mutex
var wg sync.WaitGroup// 普通版加函数
func add() {// x = x + 1x++ // 等价于上面的操作wg.Done()
}// 互斥锁版加函数
func mutexAdd() {l.Lock()x++l.Unlock()wg.Done()
}// 原子操作版加函数
func atomicAdd() {atomic.AddInt64(&x, 1)wg.Done()
}func main() {start := time.Now()for i := 0; i < 10000; i++ {wg.Add(1)// go add() // 普通版add函数 不是并发安全的// go mutexAdd() // 加锁版add函数 是并发安全的,但是加锁性能开销大go atomicAdd() // 原子操作版add函数 是并发安全,性能优于加锁版}wg.Wait()end := time.Now()fmt.Println(x)fmt.Println(end.Sub(start))
}
atomic包提供了底层的原子级内存操作,对于同步算法的实现很有用。这些函数必须谨慎地保证正确使用。除了某些特殊的底层应用,使用通道或者sync包的函数/类型实现同步更好。
相关文章:
【Go学习】-01-4-项目管理及协程
【Go学习】-01-4-项目管理及协程 1 项目管理1.1 包1.1.1 包的基本概念1.1.2 包的导入1.1.3 包的导入路径1.1.4 包的引用格式 1.2. go mod1.2.1 项目中使用 2 协程并发2.1 并发2.2 Goroutine2.2.1 使用2.2.2 GMP2.2.2.1 Golang “调度器” 的由来2.2.2.2 Go 语言的协程 goroutin…...

ES_如何设置ElasticSearch 8.0版本的匿名访问以及https_http模式的互相切换
总结: 设置匿名访问,只需要设置xpack.security.authc.anonymous.username和xpack.security.authc.anonymous.roles参数就行,设置好后,可以匿名访问也可以非匿名访问,但是非匿名访问的情况下必须保证用户名和密码正确 取…...
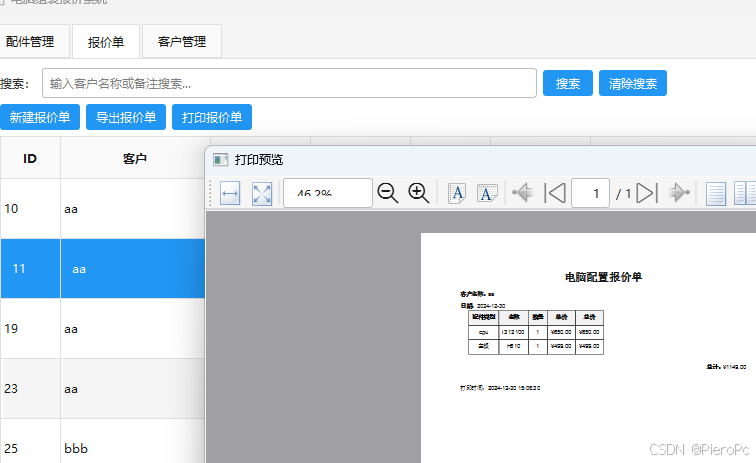
PySide6 SQLite3 做的 电脑组装报价系统
一、数据库结构说明 1. 配件类别表 (component_categories) 字段名类型说明约束category_idINTEGER类别IDPRIMARY KEY, AUTOINCREMENTcategory_nameTEXT类别名称NOT NULL, UNIQUEdescriptionTEXT类别描述 2. 配件表 (components) 字段名类型说明约束component_idINTEGER配件…...

逻辑回归(Logistic Regression) —— 机器学习中的经典分类算法
1. 逻辑回归简介 逻辑回归是一种线性分类模型,常用于二分类问题。它通过学习特征权重,将输入映射为0 到 1 之间的概率值,并根据阈值将样本归入某一类别。逻辑回归使用Sigmoid 函数将线性结果转化为概率。 尽管名字中有“回归”,…...

【数据库系统概论】数据库完整性与触发器--复习
在数据库系统概论中,数据库完整性是指确保数据库中数据的准确性、一致性和有效性的一组规则和约束。数据库完整性主要包括实体完整性、参照完整性和用户定义完整性。以下是详细的复习内容: 1. 数据库完整性概述 数据库完整性是指一组规则,这…...

【机器学习:一、机器学习简介】
机器学习是当前人工智能领域的重要分支,其目标是通过算法从数据中提取模式和知识,并进行预测或决策。以下从 机器学习概述、有监督学习 和 无监督学习 三个方面进行介绍。 机器学习概述 机器学习定义 机器学习(Machine Learning࿰…...

网关的主要类型和它们的特点
网关,作为网络通信的关键节点,根据其应用场景和功能特点,可以分为多种类型。 1.协议网关 特点: • 协议转换:协议网关的核心功能是转换不同网络之间的通信协议。例如,它可以将IPv4协议的数据包转换为IPv6协…...

NDA:Non-Disclosure Agreement
NDA 是 Non-Disclosure Agreement 的缩写,中文通常翻译为“保密协议”或“非披露协议”。其含义是:在协议约束下,协议的签署方有义务对协议中规定的信息或内容保密,不能向协议之外的第三方披露。 通常,NDA适用于以下场…...
)
方正畅享全媒体新闻采编系统 imageProxy.do 任意文件读取漏洞复现(附脚本)
0x01 产品描述: 方正畅享全媒体新闻生产系统是以内容资产为核心的智能化融合媒体业务平台,融合了报、网、端、微、自媒体分发平台等全渠道内容。该平台由协调指挥调度、数据资源聚合、融合生产、全渠道发布、智能传播分析、融合考核等多个平台组成,贯穿新闻生产策、采、编、…...

OpenHarmony通过挂载镜像来修改镜像内容,RK3566鸿蒙开发板演示
在测试XTS时会遇到修改产品属性、SElinux权限、等一些内容,修改源码再编译很费时。今天为大家介绍一个便捷的方法,让OpenHarmony通过挂载镜像来修改镜像内容!触觉智能Purple Pi OH鸿蒙开发板演示。搭载了瑞芯微RK3566四核处理器,树…...

代理模式和适配器模式有什么区别
代理模式(Proxy Pattern)和适配器模式(Adapter Pattern)是两种结构型设计模式,它们看似相似,但在设计意图、使用场景以及功能上有一些显著的区别。下面是它们的主要区别: 1. 目的与意图 代理模…...
报名公告)
2025年度全国会计专业技术资格考试 (甘肃考区)报名公告
2025年度全国会计专业技术资格考试 (甘肃考区)报名公告 按照财政部、人力资源和社会保障部统一安排,2025年度全国会计专业技术初级、中级、高级资格考试报名即将开始,现将甘肃考区有关事项通知如下: 一、报名条件 …...
ansible-playbook 搭建JDK
文件目录结构 main.yml #首先检测有无java,没有才会安装,有了就直接跳过 - name: Create installation directoryfile: path/var/www/ statedirectory- name: Check javashell: . /etc/profile && java -versionregister: resultignore_errors…...
数据结构(ing)
学习内容 指针 指针的定义: 指针是一种变量,它的值为另一个变量的地址,即内存地址。 指针在内存中也是要占据位置的。 指针类型: 指针的值用来存储内存地址,指针的类型表示该地址所指向的数据类型并告诉编译器如何解…...

杰盛微 JSM4056 1000mA单节锂电池充电器芯片 ESOP8封装
JSM4056 1000mA单节锂电池充电器芯片 JSM4056是一款单节锂离子电池恒流/恒压线性充电器,简单的外部应用电路非常适合便携式设备应用,适合USB电源和适配器电源工作,内部采用防倒充电路,不需要外部隔离二极管。热反馈可对充电电流进…...
)
webpack5基础(上篇)
一、基本配置 在开始使用 webpack 之前,我们需要对 webpack 的配置有一定的认识 1、5大核心概念 1)entry (入口) 指示 webpack 从哪个文件开始打包 2)output(输出) 制视 webpack 打包完的…...

快速理解MIMO技术
引言 在无线通信领域,MIMO(Multiple-Input Multiple-Output,多输入多输出)技术是一项革命性的进步,它通过在发射端和接收端同时使用多个天线,极大地提高了通信系统的容量、可靠性和覆盖范围。本文简要阐释其…...

【RTD MCAL 篇3】 K312 MCU时钟系统配置
【RTD MCAL 篇3】 K312 MCU时钟系统配置 一,文档简介二, 时钟系统理论与配置2.1 K312 时钟系统2.1.1 PLL2.1.2 MUX_0系统2.1.3 MUX_6 时钟输出2.1.4 option B推荐方案 2.2 EB 配置2.2.1 General 配置2.2.2 McuClockSettingConfig配置2.2.2.1 McuFIRC配置…...

探索Docker Compose:轻松管理多容器应用
探索Docker Compose:轻松管理多容器应用 在现代软件开发中,容器化已经成为构建、部署和扩展应用的主流方式。而Docker Compose作为Docker生态系统的重要组成部分,可以简化多容器应用的管理。本文将深入探讨Docker Compose的核心功能及应用场…...

计算机网络 (18)使用广播信道的数据链路层
一、广播信道的基本概念 广播信道是一种允许一个发送者向多个接收者发送数据的通信信道。在计算机网络中,广播信道通常用于局域网(LAN)内部的主机之间的通信。这种通信方式的主要优点是可以节省线路,实现资源共享。 二、广播信道数…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

销售怎么通过各种方法获取电话号码
第一种就是那个用爬虫电话号码,然后再打电话给客户。第二种是在别人的挪车电话看车挪车电话,然后再打电话找客户。第三就是。扫楼一顿顿的扫,第四就是这个那种商店,一个个的去问陌拜地推一个个的问店子要不要贷款,去问…...

钱钟书《围城》第1-5章阅读笔记:一场关于人生困境的提前预演
前言 钱钟书先生的《围城》被誉为"新儒林外史",是中国现代文学史上风格独特的讽刺经典。这部创作于20世纪40年代的长篇小说,以抗战初期为背景,通过主人公方鸿渐的人生轨迹,深刻揭示了知识分子群体的精神困境与人性弱点。…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

集成Taotoken为OpenClaw工作流提供持久化模型支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 集成Taotoken为OpenClaw工作流提供持久化模型支持 在构建基于OpenClaw的自动化Agent工作流时,一个稳定且可灵活切换的模…...

告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data
告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data在Unity关卡设计和技术美术的工作流中,地形数据的灵活复用往往意味着反复的手动操作——导出高度图、备份材质参数、复制植被分布,每个环节都可能成为效率瓶颈。想象这样…...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...

构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学
构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学 【免费下载链接】scdl Soundcloud Music Downloader 项目地址: https://gitcode.com/gh_mirrors/sc/scdl 在流媒体音乐主导的时代,音乐爱好者面临着一种矛盾:我们享受着…...

Claude Code + LM Studio + CC-Switch 本地自动化编程部署指南
Claude Code LM Studio CC-Switch 本地自动化编程部署指南 本指南汇总了在 Windows 本地环境下,使用 Claude Code 配合 LM Studio 本地模型、CC-Switch 代理进行自动化编程开发的完整配置方案。 目录 硬件与模型选型LM Studio 本地模型部署CC-Switch 代理配置Cla…...

为什么你的霓虹总像“塑料灯带”?Midjourney光子散射模拟缺陷曝光:3个被官方隐瞒的--sref调参禁区
更多请点击: https://kaifayun.com 第一章:为什么你的霓虹总像“塑料灯带”? 霓虹效果在现代 UI 设计中无处不在——按钮悬停、加载指示器、焦点高亮……但多数实现却流于表面:生硬的 box-shadow、固定色值的渐变边框、缺乏物理感…...