逻辑回归(Logistic Regression) —— 机器学习中的经典分类算法
1. 逻辑回归简介
逻辑回归是一种线性分类模型,常用于二分类问题。它通过学习特征权重,将输入映射为0 到 1 之间的概率值,并根据阈值将样本归入某一类别。逻辑回归使用Sigmoid 函数将线性结果转化为概率。
尽管名字中有“回归”,但逻辑回归主要是用于分类任务。
2. 数学公式
预测函数
逻辑回归的预测公式为:
- x 为输入特征向量;
- θ 为参数向量;
表示样本属于正类的概率。
损失函数
逻辑回归的损失函数是对数损失函数(Log Loss):
- m 为样本数量;
为真实标签(0 或 1);
为第 i 个样本的预测概率。
- θ 为权重参数。
3. 示例代码
这里用 Python + scikit-learn 实现逻辑回归模型:
示例任务:使用鸢尾花数据集进行分类
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report# 1. 加载数据集
iris = load_iris()
X = iris.data[:, :2] # 选取前两个特征便于可视化
y = (iris.target != 0).astype(int) # 转换成二分类问题(是否为第一类)# 2. 数据预处理
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
scaler = StandardScaler() # 标准化特征
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 3. 训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)# 4. 预测并评估
y_pred = model.predict(X_test)
print("模型准确率:", accuracy_score(y_test, y_pred))
print("分类报告:\n", classification_report(y_test, y_pred))# 5. 可视化决策边界
def plot_decision_boundary(X, y, model):h = 0.01x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))Z = model.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, alpha=0.8)plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')plt.xlabel("Feature 1")plt.ylabel("Feature 2")plt.title("Logistic Regression Decision Boundary")plt.show()plot_decision_boundary(X_test, y_test, model)

4. 代码说明
-
加载数据集:
load_iris()加载鸢尾花数据集,将标签转换为二分类问题(0 或 1)。
-
数据预处理:
- 使用
StandardScaler对特征标准化,使其均值为 0,方差为 1。
- 使用
-
模型训练:
- 使用
LogisticRegression训练逻辑回归模型。
- 使用
-
模型评估:
- 使用
accuracy_score和classification_report评估模型性能。
- 使用
-
可视化:
- 绘制逻辑回归的决策边界。
5. 模型分析与扩展
优点:
- 输出概率值,具有良好的可解释性;
- 计算简单,训练速度快;
- 适合线性可分问题。
缺点:
- 对于复杂的非线性关系表现不佳;
- 容易受到异常值的影响。
扩展:
- 多分类逻辑回归:通过
multi_class='multinomial'和solver='lbfgs'参数,逻辑回归可以实现多分类。 - 正则化:
penalty参数可设置 L1(Lasso)或 L2(Ridge)正则化来防止过拟合。
6. 进一步提升
- 特征工程:创建更多有效的特征,如多项式特征。
- 正则化:合理设置正则化参数
C以控制模型复杂度。 - 非线性模型:如果逻辑回归效果不佳,可以尝试更复杂的非线性模型,如 SVM 或神经网络。
逻辑回归模型输入数据格式
LogisticRegression 模型来自 scikit-learn 库,fit(X_train, y_train) 方法用于训练模型。这里的 X_train 和 y_train 是输入特征和标签,要求的数据格式如下:
1. X_train(特征矩阵)
- 类型:
numpy.ndarray、pandas.DataFrame或其他可被转换为 NumPy 数组的格式。 - 形状:
(n_samples, n_features)n_samples:样本数量(行数)。n_features:每个样本的特征数量(列数)。
示例:
如果有 100 个样本,每个样本有 4 个特征,那么 X_train 的形状为 (100, 4):
X_train = np.array([[5.1, 3.5, 1.4, 0.2],[4.9, 3.0, 1.4, 0.2],... # 省略其他样本])
2. y_train(标签向量)
- 类型:
numpy.ndarray、pandas.Series或其他可被转换为一维数组的格式。 - 形状:
(n_samples,)n_samples:标签数量,必须与X_train的样本数量相同。
值的范围:
- 二分类问题时,
y_train通常为 0 或 1; - 多分类问题时,
y_train为类别索引(如 0、1、2 等整数)。
示例:
如果有 100 个样本,y_train 为长度为 100 的一维数组:
y_train = np.array([0, 1, 0, 1, 1, 0, ...])
3. 输入数据注意事项
-
缺失值:
X_train不允许有缺失值(NaN),可以使用SimpleImputer等方法填充缺失值。
-
数据类型:
- 输入数据最好为浮点型。可以通过
X_train.astype(float)将数据转换为float类型。
- 输入数据最好为浮点型。可以通过
-
标准化/归一化:
- 对特征进行标准化或归一化可以加快模型收敛速度,尤其是当特征值的量级差距较大时。
4. 示例代码
以下是完整的数据格式示例:
import numpy as np
from sklearn.linear_model import LogisticRegression# 示例数据
X_train = np.array([[5.1, 3.5, 1.4, 0.2],[4.9, 3.0, 1.4, 0.2],[4.7, 3.2, 1.3, 0.2]])
y_train = np.array([0, 1, 0]) # 标签对应样本类别# 模型训练
model = LogisticRegression()
model.fit(X_train, y_train)
5. 输出
- 训练后的模型:保存了特征权重
theta,可以通过model.coef_查看; - 预测新数据:调用
model.predict(X_test),输入格式同X_train。
总结:X_train 为二维矩阵,y_train 为一维向量,并且二者的样本数量需要一致。如果数据有问题(如缺失值或数据类型不匹配),需要在训练前进行预处理。
相关文章:
逻辑回归(Logistic Regression) —— 机器学习中的经典分类算法
1. 逻辑回归简介 逻辑回归是一种线性分类模型,常用于二分类问题。它通过学习特征权重,将输入映射为0 到 1 之间的概率值,并根据阈值将样本归入某一类别。逻辑回归使用Sigmoid 函数将线性结果转化为概率。 尽管名字中有“回归”,…...

【数据库系统概论】数据库完整性与触发器--复习
在数据库系统概论中,数据库完整性是指确保数据库中数据的准确性、一致性和有效性的一组规则和约束。数据库完整性主要包括实体完整性、参照完整性和用户定义完整性。以下是详细的复习内容: 1. 数据库完整性概述 数据库完整性是指一组规则,这…...

【机器学习:一、机器学习简介】
机器学习是当前人工智能领域的重要分支,其目标是通过算法从数据中提取模式和知识,并进行预测或决策。以下从 机器学习概述、有监督学习 和 无监督学习 三个方面进行介绍。 机器学习概述 机器学习定义 机器学习(Machine Learning࿰…...

网关的主要类型和它们的特点
网关,作为网络通信的关键节点,根据其应用场景和功能特点,可以分为多种类型。 1.协议网关 特点: • 协议转换:协议网关的核心功能是转换不同网络之间的通信协议。例如,它可以将IPv4协议的数据包转换为IPv6协…...

NDA:Non-Disclosure Agreement
NDA 是 Non-Disclosure Agreement 的缩写,中文通常翻译为“保密协议”或“非披露协议”。其含义是:在协议约束下,协议的签署方有义务对协议中规定的信息或内容保密,不能向协议之外的第三方披露。 通常,NDA适用于以下场…...
)
方正畅享全媒体新闻采编系统 imageProxy.do 任意文件读取漏洞复现(附脚本)
0x01 产品描述: 方正畅享全媒体新闻生产系统是以内容资产为核心的智能化融合媒体业务平台,融合了报、网、端、微、自媒体分发平台等全渠道内容。该平台由协调指挥调度、数据资源聚合、融合生产、全渠道发布、智能传播分析、融合考核等多个平台组成,贯穿新闻生产策、采、编、…...

OpenHarmony通过挂载镜像来修改镜像内容,RK3566鸿蒙开发板演示
在测试XTS时会遇到修改产品属性、SElinux权限、等一些内容,修改源码再编译很费时。今天为大家介绍一个便捷的方法,让OpenHarmony通过挂载镜像来修改镜像内容!触觉智能Purple Pi OH鸿蒙开发板演示。搭载了瑞芯微RK3566四核处理器,树…...

代理模式和适配器模式有什么区别
代理模式(Proxy Pattern)和适配器模式(Adapter Pattern)是两种结构型设计模式,它们看似相似,但在设计意图、使用场景以及功能上有一些显著的区别。下面是它们的主要区别: 1. 目的与意图 代理模…...
报名公告)
2025年度全国会计专业技术资格考试 (甘肃考区)报名公告
2025年度全国会计专业技术资格考试 (甘肃考区)报名公告 按照财政部、人力资源和社会保障部统一安排,2025年度全国会计专业技术初级、中级、高级资格考试报名即将开始,现将甘肃考区有关事项通知如下: 一、报名条件 …...
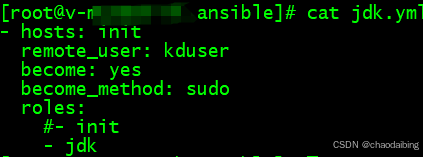
ansible-playbook 搭建JDK
文件目录结构 main.yml #首先检测有无java,没有才会安装,有了就直接跳过 - name: Create installation directoryfile: path/var/www/ statedirectory- name: Check javashell: . /etc/profile && java -versionregister: resultignore_errors…...
数据结构(ing)
学习内容 指针 指针的定义: 指针是一种变量,它的值为另一个变量的地址,即内存地址。 指针在内存中也是要占据位置的。 指针类型: 指针的值用来存储内存地址,指针的类型表示该地址所指向的数据类型并告诉编译器如何解…...

杰盛微 JSM4056 1000mA单节锂电池充电器芯片 ESOP8封装
JSM4056 1000mA单节锂电池充电器芯片 JSM4056是一款单节锂离子电池恒流/恒压线性充电器,简单的外部应用电路非常适合便携式设备应用,适合USB电源和适配器电源工作,内部采用防倒充电路,不需要外部隔离二极管。热反馈可对充电电流进…...
)
webpack5基础(上篇)
一、基本配置 在开始使用 webpack 之前,我们需要对 webpack 的配置有一定的认识 1、5大核心概念 1)entry (入口) 指示 webpack 从哪个文件开始打包 2)output(输出) 制视 webpack 打包完的…...

快速理解MIMO技术
引言 在无线通信领域,MIMO(Multiple-Input Multiple-Output,多输入多输出)技术是一项革命性的进步,它通过在发射端和接收端同时使用多个天线,极大地提高了通信系统的容量、可靠性和覆盖范围。本文简要阐释其…...

【RTD MCAL 篇3】 K312 MCU时钟系统配置
【RTD MCAL 篇3】 K312 MCU时钟系统配置 一,文档简介二, 时钟系统理论与配置2.1 K312 时钟系统2.1.1 PLL2.1.2 MUX_0系统2.1.3 MUX_6 时钟输出2.1.4 option B推荐方案 2.2 EB 配置2.2.1 General 配置2.2.2 McuClockSettingConfig配置2.2.2.1 McuFIRC配置…...

探索Docker Compose:轻松管理多容器应用
探索Docker Compose:轻松管理多容器应用 在现代软件开发中,容器化已经成为构建、部署和扩展应用的主流方式。而Docker Compose作为Docker生态系统的重要组成部分,可以简化多容器应用的管理。本文将深入探讨Docker Compose的核心功能及应用场…...

计算机网络 (18)使用广播信道的数据链路层
一、广播信道的基本概念 广播信道是一种允许一个发送者向多个接收者发送数据的通信信道。在计算机网络中,广播信道通常用于局域网(LAN)内部的主机之间的通信。这种通信方式的主要优点是可以节省线路,实现资源共享。 二、广播信道数…...

【vLLM 学习】欢迎来到 vLLM!
vLLM 是一款专为大语言模型推理加速而设计的框架,实现了 KV 缓存内存几乎零浪费,解决了内存管理瓶颈问题。 更多 vLLM 中文文档及教程可访问 →https://vllm.hyper.ai/ vLLM 是一个快速且易于使用的库,专为大型语言模型 (LLM) 的推理和部署…...

现代网络基础设施中的 TCP 握手之下
TCP 3 次握手 在最简单的形式中,TCP 三次握手很容易理解,并且有 大量在线材料都在讨论这个问题。(如果你能读懂 Chinease,你可以看看我之前的一篇文章。 然而,在实际中理解、练习和解决 TCP 问题 世界是另一回事。随…...

GRAPE——RLAIF微调VLA模型:通过偏好对齐提升机器人策略的泛化能力(含24年具身模型汇总)
前言 24年具身前沿模型大汇总 过去的这两年,工作之余,我狂写大模型与具身的文章,加之具身大火,每周都有各种朋友通过CSDN私我及我司「七月在线」寻求帮助/指导(当然,也欢迎各大开发团队与我司合作共同交付)…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案
如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX 还在为本地音乐库缺少歌词而烦恼吗࿱…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

DIY智能USB充电器:基于电流检测与双稳态继电器的零功耗节能方案
1. 项目概述:打造一款智能、节能的USB手机充电器作为一名电子爱好者,我经常折腾各种电源项目。市面上很多手机充电器,包括一些原装货,都存在一个通病:手机充满电后,充电器依然插在插座上,内部电…...

3PEAK思瑞浦 TPA6531-S5TR SOT23-5 运算放大器
特性 供电电压:1.75V至5.5V 偏移电压:1.5mV(最大值) 最大可调工作频率:300kHz,斜率:0.15V/us 轨到轨输入和输出 0.1赫兹至10赫兹电压噪声:1伏峰值 开关电源时无显著输出抖动 低功耗:每通道最大25安培 工作温度范围:-40C至125C...

昇腾NPU模型服务化——从离线模型到高可用推理服务
模型训练完只是第一步。真正产生业务价值的是把模型部署成724小时在线服务——毫秒级延迟、支持动态Batching、能扛住流量洪峰,且具备高可用性。 这篇将手把手教你基于昇腾NPU构建生产级模型推理服务,涵盖框架选型、服务化架构、动态Batching优化、热加载…...

纯硬件实现I2C协议:从逻辑门到传感器通信的深度实践
1. 项目概述:用纯硬件“解剖”I2C总线很多朋友在玩传感器,尤其是温湿度传感器时,都绕不开I2C这个通信协议。市面上绝大多数的教程和方案,都会告诉你:找个单片机(比如Arduino、STM32),…...
)
仅限首批200位架构师获取:DeepSeek-DDD联合建模工作坊实录(含领域事件风暴原始会议录像+决策日志)
更多请点击: https://kaifayun.com 第一章:DeepSeek领域驱动设计的范式演进与本质洞察 DeepSeek作为面向大规模智能体协同与复杂业务语义建模的新一代AI原生架构,其领域驱动设计(DDD)实践已突破传统分层单体范式&…...

3分钟掌握抖音视频批量下载:解放双手的素材收集革命
3分钟掌握抖音视频批量下载:解放双手的素材收集革命 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为一个个手动保存抖音视频而烦恼吗?想要高效收集创作者素材却苦于没有合适的…...