Single Shot MultiBox Detector(SSD)
文章目录
- 摘要
- Abstract
- 1. 引言
- 2. 框架
- 2.1 网络结构
- 2.2 损失函数
- 2.3 训练细节
- 3. 创新点和不足
- 3.1 创新点
- 3.2 不足
- 参考
- 总结
摘要
与Faster R-CNN相比,SSD是一个真正的单阶段多目标检测模型,同时也是一个全卷积网络,不仅检测准确率高,而且检测速度快。SSD显著的优点是使用卷积从不同尺寸的特征图上预测不同尺度、横纵比锚点区域的类别概率分布和偏移量,如此SSD能利用低层特征图较小的感受野和高层特征图较大的感受野来分别检测小物体和大物体。此外,SSD也消除了对候选区域的缩放。尽管SSD有这些优点,但是它也有一个显著的问题——相较于大物体,小物体的检测正确率低。SSD提出了一个解决办法,把图片缩放成 512 × 512 512\times512 512×512再进行检测,如此能提升小物体的检测准确率,但是仍有改进的空间。
Abstract
Compared to Faster R-CNN, SSD is a true single-stage multi-object detection model and also a fully convolutional network, which not only achieves high detection accuracy but also fast detection speed. A significant advantage of SSD is its use of convolution to predict the class probability distribution and offset of anchor boxes with different scales and aspect ratios from feature maps of different sizes. This allows SSD to detect small objects using the smaller receptive fields of lower-level feature maps and large objects using the larger receptive fields of higher-level feature maps. Moreover, SSD eliminates the need for scaling candidate regions. Despite these advantages, SSD has a significant issue—its detection accuracy for small objects is lower than for large objects. SSD proposed a solution by resizing images to 512 × 512 512 \times 512 512×512 for detection, which improves the detection accuracy for small objects, but there is still room for improvement.
1. 引言
以前,先进的目标检测系统都是下面方法的变种:假设边界框、重采样每个框中的像素或特征和应用高质量的分类器。自从选择性搜索和Faster R-CNN在目标检测数据集上取得领先的效果以来,这个管道一直盛行于目标检测。尽管检测正确率很高,但是这些方法的计算量对于嵌入式系统来说还是太大了。即使在高端硬件上,这些方法对于实时检测来说还是太慢了。为了解决上述的问题,研究人员提出了第一个基于单个神经网络模型的物体检测器——SSD。它不需要对边界框内的像素或特征进行重采样,而且达到了和以前方法一样的检测准确率。
2. 框架
2.1 网络结构
下图是SSD300的结构。
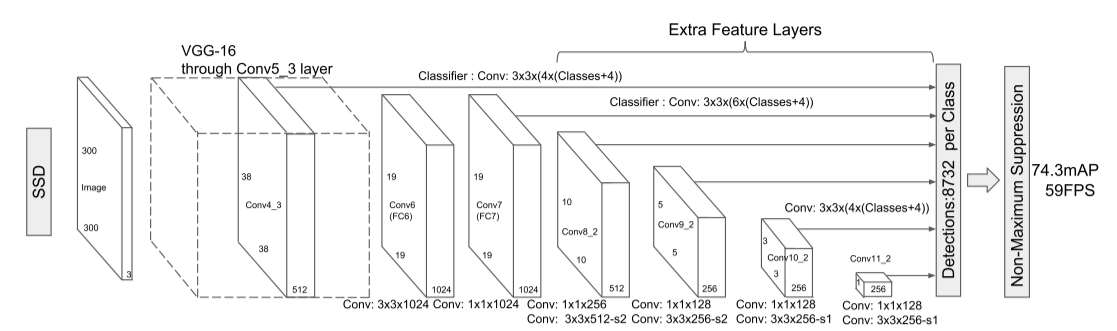
| 编号 | 类型 | 输入尺寸(H,W,C) | 卷积核/池化核 | 输出尺寸(H,W,C) | 激活函数 |
|---|---|---|---|---|---|
| 输入层 | - | 300 × 300 × 3 300\times300\times3 300×300×3 | - | 300 × 300 × 3 300\times300\times3 300×300×3 | - |
| C1 | 卷积层 | 300 × 300 × 3 300\times300\times3 300×300×3 | 64个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 300 × 300 × 64 300\times300\times64 300×300×64 | ReLU |
| C2 | 卷积层 | 300 × 300 × 64 300\times300\times64 300×300×64 | 64个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 300 × 300 × 64 300\times300\times64 300×300×64 | ReLU |
| S3 | 池化层 | 300 × 300 × 64 300\times300\times64 300×300×64 | 2 × 2 2\times2 2×2最大池化核,步长为2 | 150 × 150 × 64 150\times150\times64 150×150×64 | - |
| C4 | 卷积层 | 150 × 150 × 64 150\times150\times64 150×150×64 | 128个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 150 × 150 × 128 150\times150\times128 150×150×128 | ReLU |
| C5 | 卷积层 | 150 × 150 × 128 150\times150\times128 150×150×128 | 128个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 150 × 150 × 128 150\times150\times128 150×150×128 | ReLU |
| S6 | 池化层 | 150 × 150 × 128 150\times150\times128 150×150×128 | 2 × 2 2\times2 2×2最大池化核,步长为2 | 75 × 75 × 128 75\times75\times128 75×75×128 | - |
| C7 | 卷积层 | 75 × 75 × 128 75\times75\times128 75×75×128 | 256个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 75 × 75 × 256 75\times75\times256 75×75×256 | ReLU |
| C8 | 卷积层 | 75 × 75 × 256 75\times75\times256 75×75×256 | 256个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 75 × 75 × 256 75\times75\times256 75×75×256 | ReLU |
| C9 | 卷积层 | 75 × 75 × 256 75\times75\times256 75×75×256 | 256个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 75 × 75 × 256 75\times75\times256 75×75×256 | ReLU |
| S10 | 池化层 | 75 × 75 × 256 75\times75\times256 75×75×256 | 2 × 2 2\times2 2×2最大池化核,步长为2,设置向上取整 | 38 × 38 × 256 38\times38\times256 38×38×256 | - |
| C11 | 卷积层 | 38 × 38 × 256 38\times38\times256 38×38×256 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 38 × 38 × 512 38\times38\times512 38×38×512 | ReLU |
| C12 | 卷积层 | 38 × 38 × 512 38\times38\times512 38×38×512 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 38 × 38 × 512 38\times38\times512 38×38×512 | ReLU |
| C13 | 卷积层 | 38 × 38 × 512 38\times38\times512 38×38×512 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 38 × 38 × 512 38\times38\times512 38×38×512 | ReLU |
| S14 | 池化层 | 38 × 38 × 512 38\times38\times512 38×38×512 | 2 × 2 2\times2 2×2最大池化核,步长为2 | 19 × 19 × 512 19\times19\times512 19×19×512 | - |
| C15 | 卷积层 | 19 × 19 × 512 19\times19\times512 19×19×512 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 19 × 19 × 512 19\times19\times512 19×19×512 | ReLU |
| C16 | 卷积层 | 19 × 19 × 512 19\times19\times512 19×19×512 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 19 × 19 × 512 19\times19\times512 19×19×512 | ReLU |
| C17 | 卷积层 | 19 × 19 × 512 19\times19\times512 19×19×512 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 19 × 19 × 512 19\times19\times512 19×19×512 | ReLU |
| S18 | 池化层 | 19 × 19 × 512 19\times19\times512 19×19×512 | 3 × 3 3\times3 3×3最大池化,步长为1,填充为1 | 19 × 19 × 512 19\times19\times512 19×19×512 | - |
| C19 | 卷积层 | 19 × 19 × 512 19\times19\times512 19×19×512 | 1024个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 19 × 19 × 1024 19\times19\times1024 19×19×1024 | ReLU |
| C20 | 卷积层 | 19 × 19 × 1024 19\times19\times1024 19×19×1024 | 1024个 1 × 1 1\times1 1×1卷积核,步长为1 | 19 × 19 × 1024 19\times19\times1024 19×19×1024 | ReLU |
| C21 | 卷积层 | 19 × 19 × 1024 19\times19\times1024 19×19×1024 | 256个 1 × 1 1\times1 1×1卷积核,步长为1 | 19 × 19 × 256 19\times19\times256 19×19×256 | ReLU |
| C22 | 卷积层 | 19 × 19 × 256 19\times19\times256 19×19×256 | 512个 3 × 3 3\times3 3×3卷积核,步长为2,填充为1 | 10 × 10 × 512 10\times10\times512 10×10×512 | ReLU |
| C23 | 卷积层 | 10 × 10 × 512 10\times10\times512 10×10×512 | 128个 1 × 1 1\times1 1×1卷积核,步长为1 | 10 × 10 × 128 10\times10\times128 10×10×128 | ReLU |
| C24 | 卷积层 | 10 × 10 × 128 10\times10\times128 10×10×128 | 256个 3 × 3 3\times3 3×3卷积核,步长为2,填充为1 | 5 × 5 × 256 5\times5\times256 5×5×256 | ReLU |
| C25 | 卷积层 | 5 × 5 × 256 5\times5\times256 5×5×256 | 128个 1 × 1 1\times1 1×1卷积核,步长为1 | 5 × 5 × 128 5\times5\times128 5×5×128 | ReLU |
| C26 | 卷积层 | 5 × 5 × 128 5\times5\times128 5×5×128 | 256个 3 × 3 3\times3 3×3卷积核,步长为1 | 3 × 3 × 256 3\times3\times256 3×3×256 | ReLU |
| C27 | 卷积层 | 3 × 3 × 256 3\times3\times256 3×3×256 | 128个 1 × 1 1\times1 1×1卷积核,步长为1 | 3 × 3 × 128 3\times3\times128 3×3×128 | ReLU |
| C28 | 卷积层 | 3 × 3 × 128 3\times3\times128 3×3×128 | 256个 3 × 3 3\times3 3×3卷积核,步长为1 | 1 × 1 × 256 1\times1\times256 1×1×256 | ReLU |
SSD在C13、C20、C22、C24、C26、C28应用卷积层来获取锚点区域的类别概率分布和偏移量。C20、C22、C24、C26、C28比C13多经历了两次池化,从而导致C13特征图中元素值的范围与其他层不同,因此C13在用卷积层计算类别概率分布和偏移量之前需要进行 L 2 L_2 L2正则化:在每个颜色通道上计算 L 2 L_2 L2范数,然后每个颜色通道上的元素除以该通道上的 L 2 L^2 L2范数,最后乘以一个初始值为20、可学习的缩放系数。
假设数据集中目标类别的个数为 c c c,C13在上述的 L 2 L_2 L2正则化后再应用一个卷积核大小为 3 × 3 3\times3 3×3、过滤器个数为 4 × ( c + 4 ) 4\times(c+4) 4×(c+4)的卷积层来获取概率分布和偏移量;C20、C22和C24分别应用一个卷积核大小为 3 × 3 3\times3 3×3、过滤器个数为 6 × ( c + 4 ) 6\times(c+4) 6×(c+4)的卷积层来获取概率分布和偏移量;C26应用一个卷积核大小为 3 × 3 3\times3 3×3、过滤器个数为 4 × ( c + 4 ) 4\times(c+4) 4×(c+4)的卷积层来获取概率分布和偏移量;C28应用一个卷积核大小为 1 × 1 1\times1 1×1、过滤器个数为 4 × ( c + 4 ) 4\times(c+4) 4×(c+4)的卷积层来获取概率分布和偏移量。
SSD中用来计算概率分布和偏移量的特征图拥有不同的尺寸,因此SSD设计了锚点区域的尺度,使其与特征图的实际尺寸无关。假设用来计算概率分布和偏移量的特征图有 m = 6 m=6 m=6个,每个特征图上锚点区域的尺度计算公式为:
s k = s m i n + s m a x − s m i n m − 1 ( k − 1 ) , k ∈ [ 1 , m ] . s_k=s_{min}+\frac{s_{max}-s_{min}}{m-1}(k-1), k\in [1, m]. sk=smin+m−1smax−smin(k−1),k∈[1,m].
其中 s m i n = 0.2 s_{min}=0.2 smin=0.2, s m a x = 0.9 s_{max}=0.9 smax=0.9。SSD使用了5种不同的横纵比 a r ∈ { 1 , 2 , 3 , 1 2 , 1 3 } a_r\in\{1, 2, 3, \frac{1}{2}, \frac{1}{3}\} ar∈{1,2,3,21,31},锚点区域的宽度和高度的计算公式为:
w k a = s k a r , h k a = s k a r . w_k^a=s_k\sqrt{a_r}, h_k^a=\frac{s_k}{\sqrt{a_r}}. wka=skar,hka=arsk.
此外,当横纵比为1时,额外增加了一种尺度 s k ′ = s k s k + 1 s_k'=\sqrt{s_ks_{k+1}} sk′=sksk+1。锚点区域的中心位置的公式为:
x = i + 0.5 ∣ f k ∣ , y = j + 0.5 ∣ f k ∣ . x=\frac{i+0.5}{|f_k|}, y=\frac{j+0.5}{|f_k|}. x=∣fk∣i+0.5,y=∣fk∣j+0.5.
其中 ∣ f k ∣ |f_k| ∣fk∣是第 k k k个特征图的边长, i , j ∈ [ 0 , ∣ f k ∣ ] i,j\in[0, |f_k|] i,j∈[0,∣fk∣]。
2.2 损失函数
锚点区域的四元组为锚点区域中心坐标、宽和高。如果锚点区域与真实区域的IOU大于0.5,则锚点区域为该真实区域的正例,否则为负例。假设 x i j p = { 1 , 0 } x_{ij}^p=\{1, 0\} xijp={1,0}为第 i i i个锚点区域与第 j j j个类别为 p p p的真实区域的匹配程度,则SSD的损失函数为:
L ( x , c , l , g ) = 1 N ( L c o n f ( x , c ) + α L l o c ( x , l , g ) ) . L(x, c, l, g)=\frac{1}{N}(L_{conf}(x, c)+\alpha L_{loc}(x, l, g)). L(x,c,l,g)=N1(Lconf(x,c)+αLloc(x,l,g)).
其中 N N N是匹配的锚点区域的个数(如果 N = 0 N=0 N=0,则损失为0)。
定位损失为 L l o c ( x , l , g ) = ∑ i ∈ P o s N ∑ m ∈ { c x , c y , w , h } x i j k s m o o t h L 1 ( l i m − g ^ j m ) L_{loc}(x, l, g)=\displaystyle\sum_{i\in Pos}^N \sum_{m\in\{cx, cy, w, h\}}x_{ij}^k smooth_{L_1}(l_i^m-\hat{g}_j^m) Lloc(x,l,g)=i∈Pos∑Nm∈{cx,cy,w,h}∑xijksmoothL1(lim−g^jm),其中 g ^ j c x = g j c x − d i c x d i w \hat{g}_j^{cx}=\displaystyle\frac{g_j^{cx}-d_i^{cx}}{d_i^w} g^jcx=diwgjcx−dicx, g ^ j c y = g j c y − d i c y d i h \hat{g}_j^{cy}=\displaystyle\frac{g_j^{cy}-d_i^{cy}}{d_i^h} g^jcy=dihgjcy−dicy, g ^ j w = l o g ( g j w d i w ) \hat{g}_j^w=log(\displaystyle\frac{g_j^w}{d_i^w}) g^jw=log(diwgjw), g ^ j h = l o g ( g j h d i h ) \hat{g}_j^h=log(\displaystyle\frac{g_j^h}{d_i^h}) g^jh=log(dihgjh)。置信损失为 L c o n f ( x , c ) = − ∑ i ∈ P o s N x i j p l o g ( c ^ i p ) − ∑ i ∈ N e g l o g ( c ^ i 0 ) L_{conf}(x, c)=\displaystyle-\sum_{i\in Pos}^N x_{ij}^plog(\hat{c}_i^p)-\sum_{i\in Neg}log(\hat{c}_i^0) Lconf(x,c)=−i∈Pos∑Nxijplog(c^ip)−i∈Neg∑log(c^i0),其中 c ^ i p = e c i p ∑ p e c i p \hat{c}_i^p=\displaystyle\frac{e^{c_i^p}}{\displaystyle\sum_{p}e^{c_i^p}} c^ip=p∑ecipecip。
2.3 训练细节
在训练过程中,先根据上面提及的置信损失对所有类别是背景的锚点区域进行从高到低的排序,然后从中挑选损失最高的锚点区域,使得负例与正例的样本个数之比为 3 : 1 3:1 3:1。每次训练一轮后重复执行上述操作。
数据增强的操作:1. 使用完整的训练图片;2. 使用与所有物体的最小IOU为0.1、0.3、0.5、0.7或0.9的区域;3. 随机使用一个区域。上面提到的第2种和第3种区域的尺度为原训练图像的0.1倍到1倍,并且横纵比为 1 : 2 1:2 1:2和 2 : 1 2:1 2:1。所有采样后的图片都被重新缩放到固定尺寸,接着以0.5的概率进行水平翻转,最后在图像的对比度、亮度、颜色进行处理。
3. 创新点和不足
3.1 创新点
与基于R-CNN的目标检测模型相比,SSD是一个单阶段检测所有物体类别的模型,也消除了对候选区域的缩放。SSD最显著的优点是使用卷积从不同尺寸的特征图上预测不同尺度、横纵比锚点区域的类别概率分布和偏移量,如此SSD能利用低层特征图较小的感受野和高层特征图较大的感受野来分别检测小物体和大物体。此外,SSD也是一个全卷积网络,能在运行速度快的同时保证极高的检测准确率。
3.2 不足
SSD在检测小物体时的准确率小于检测大物体时的准确率。尽管SSD提出了一个解决办法——把图片的输入尺寸缩放成 512 × 512 512\times512 512×512,但是在小物体检测上仍然具有改进的空间。
参考
Wei Liu, Dragomir Anguelov, Dumitru Erhan, and et al. SSD: Single Shot MultiBox Detector.
总结
SSD以VGG16的卷积部分为基础网络,修改了VGG16卷积部分中最后一层池化层,并在后面添加了几层卷积层,最后在不同特征图上进行卷积来获取锚点区域的类别概率分布和偏移量。SD最显著的优点是使用卷积从不同尺寸的特征图上预测不同尺度、横纵比锚点区域的类别概率分布和偏移量,如此SSD能利用低层特征图较小的感受野和高层特征图较大的感受野来分别检测小物体和大物体。此外,SSD也是一个全卷积网络,能在运行速度快的同时保证极高的检测准确率。
相关文章:
Single Shot MultiBox Detector(SSD)
文章目录 摘要Abstract1. 引言2. 框架2.1 网络结构2.2 损失函数2.3 训练细节 3. 创新点和不足3.1 创新点3.2 不足 参考总结 摘要 与Faster R-CNN相比,SSD是一个真正的单阶段多目标检测模型,同时也是一个全卷积网络,不仅检测准确率高ÿ…...

kafka生产者专题(原理+拦截器+序列化+分区+数据可靠+数据去重+事务)
目录 生产者发送数据原理参数说明代码示例(同步发送数据)代码示例(异步) 异步和同步的区别同步发送定义与流程特点 异步发送定义与流程特点 异步回调描述代码示例 拦截器描述代码示例 消息序列化描述代码示例(自定义序…...

【React+TypeScript+DeepSeek】穿越时空对话机
引言 在这个数字化的时代,历史学习常常给人一种距离感。教科书中的历史人物似乎永远停留在文字里,我们无法真正理解他们的思想和智慧。如何让这些伟大的历史人物"活"起来?如何让历史学习变得生动有趣?带着这些思考&…...

公共数据授权运营系统建设手册(附下载)
在全球范围内,许多国家和地区已经开始探索公共数据授权运营的路径和模式。通过建立公共数据平台,推动数据的开放共享,促进数据的创新应用,不仅能够提高政府决策的科学性和公共服务的效率,还能够激发市场活力࿰…...

基于HTML和CSS的旅游小程序
一、技术基础 HTML(HyperText Markup Language):超文本标记语言,用于定义网页的内容和结构。在旅游小程序中,HTML用于搭建页面的基本框架,包括标题、段落、图片、链接等元素,以及用于交互的表单…...

maven之插件调试
当使用maven进行项目管理的时候,可能会碰到一些疑难问题。网上资料很少,可能会想着直接调试定位问题。这里以maven-compiler-plugin为例: (1)准备maven-compiler-plugin源码 进入maven 官网-》Maven Plugins-》找到对…...

SQL Sever 数据库损坏,只有.mdf文件,如何恢复?
SQL Sever 数据库损坏,只有.mdf文件,如何恢复 在SQL Server 2008中,如果只有MDF文件而没有LDF文件,附加数据库的过程会稍微复杂一些。以下是几种可能的方法 一、使用紧急模式重建日志文件 1、新建一个同名的数据库。 2、停止SQ…...

【AWS SDK PHP】This operation requests `sigv4a` auth schemes 问题处理
使用AWS SDK碰到的错误,其实很简单,要装个扩展库 保持如下 Fatal error: Uncaught Aws\Auth\Exception\UnresolvedAuthSchemeException: This operation requests sigv4a auth schemes, but the client currently supports sigv4, none, bearer, sigv4-…...

primevue的<Menu>组件
1.使用场景 2.代码 1.给你的menu组件起个引用名 2.<Menu>组件需要一个MenuItem[] 3.你要知道MenuItem[ ]的特殊的数据格式,就像TreeNode[ ]一样,数据格式不对是不渲染的。。。。 常用的属性就这几种,js语言和java不一样,J…...

利用Deeplearning4j进行 图像识别
目录 图像识别简介 神经网络 感知器 前馈神经网络 自动编码器 受限玻尔兹曼机 深度卷积网络 理解图像内容以及图像含义方面,计算机遇到了很大困难。本章先介绍计算机理解图像教育方面 遇到的难题,接着重点讲解一个基于深度学习的解决方法。我们会…...

练习题:37
目录 Python题目 题目 题目分析 套接字概念剖析 通信原理分析 服务器 - 客户端连接建立过程: 基于套接字通信的底层机制: 代码实现 基于 TCP 的简单服务器 - 客户端通信示例 服务器端代码(tcp_server.py) 客户端代码&a…...

Unity热更文件比较工具类
打包出来的热更文件,如果每次都要全部上传到CDN文件服务器,不进耗费时间长,还浪费流量。 所以让AI写了个简单的文件比较工具类,然后修改了一下可用。记录一下。 路径可自行更改。校验算法这里使用的是MD5,如果使用SH…...

【hustoj注意事项】函数返回值问题
原文 https://lg.h-fmc.cn/index.php/BC/27.html 问题回顾 此题目选自HFMC_OJ:4312: 简单递归操作 hustoj测试 此问题错误的代码是 #include<bits/stdc.h> using namespace std; int a[10000];int n; int b[10000]{0}; int pailie(int deep) {int i; for(…...

实现一个通用的树形结构构建工具
文章目录 1. 前言2. 树结构3. 具体实现逻辑3.1 TreeNode3.2 TreeUtils3.3 例子 4. 小结 1. 前言 树结构的生成在项目中应该都比较常见,比如部门结构树的生成,目录结构树的生成,但是大家有没有想过,如果在一个项目中有多个树结构&…...

数势科技:解锁数据分析 Agent 的智能密码(14/30)
一、数势科技引领数据分析变革 在当今数字化浪潮中,数据已然成为企业的核心资产,而数据分析则是挖掘这一资产价值的关键钥匙。数势科技,作为数据智能领域的领军者,以其前沿的技术与创新的产品,为企业开启了高效数据分析…...

机器学习之过采样和下采样调整不均衡样本的逻辑回归模型
过采样和下采样调整不均衡样本的逻辑回归模型 目录 过采样和下采样调整不均衡样本的逻辑回归模型1 过采样1.1 样本不均衡1.2 概念1.3 图片理解1.4 SMOTE算法1.5 算法导入1.6 函数及格式1.7 样本类别可视化理解 2 下采样2.1 概念2.2 图片理解2.3 数据处理理解2.4 样本类别可视化…...

解决 ssh connect to host github.com port 22 Connection timed out
一、问题描述 本地 pull/push 推送代码到 github 项目报 22 端口连接超时,测试连接也是 22 端口连接超时 ssh 密钥没问题、也开了 Watt Toolkit 网络是通的,因此可以强制将端口切换为 443 二、解决方案 1、测试连接 ssh -T gitgithub.com意味着无法通…...

mybatis/mybatis-plus中mysql报错
文章目录 一、sql执行正常,mybatis报错二、sql执行正常,mybatis-plus报错直接改变字段利用mybatis-plus特性处理 总结 一、sql执行正常,mybatis报错 Caused by: net.sf.jsqlparser.parser.ParseException: Encountered unexpected token: "ur" <K_ISOLATION>a…...
实现(基本))
在ros2 jazzy和gazebo harmonic下的建图导航(cartographer和navigation)实现(基本)
我的github分支!!! 你可以在这里找到相对应的源码。 DWDROME的MOGI分支 来源于!! MOGI-ROS/Week-3-4-Gazebo-basics 学习分支整理日志 分支概述 这是一个用于个人学习的新分支,目的是扩展基本模型并添加…...

《Rust权威指南》学习笔记(五)
高级特性 1.在Rust中,unsafe是一种允许绕过Rust的安全性保证的机制,用于执行一些Rust默认情况下不允许的操作。unsafe存在的原因是:unsafe 允许执行某些可能被 Rust 的安全性检查阻止的操作,从而可以进行性能优化,如手…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...