PyTorch 中 coalesce() 函数详解与应用示例
PyTorch 中 coalesce() 函数详解与应用示例
coalesce: 美 [ˌkoʊəˈlɛs] 合并;凝聚;联结,注意发音
引言
在 PyTorch 中,稀疏张量(Sparse Tensor)是一种高效存储和操作稀疏数据的方式。稀疏张量主要用于需要处理大量零元素的场景,例如图神经网络(GNN)和大型矩阵操作。本文将深入解析 coalesce() 函数的用法,并结合代码示例进行演示。
coalesce() 函数简介
coalesce() 是 PyTorch 稀疏张量的一个成员函数,主要用于去重和合并重复索引的元素。在稀疏张量中,可能存在重复的坐标位置,coalesce() 可以将这些重复的坐标进行合并,并对相同索引的值进行累加。
语法
sparse_tensor.coalesce()
功能
- 去重合并索引:将具有重复索引的元素合并为一个,值相加。
- 输出稀疏张量:返回新的 coalesced 稀疏张量,减少存储开销并优化计算效率。
使用示例
基本示例
import torch# 创建一个稀疏张量
indices = torch.tensor([[0, 1, 1], [2, 0, 0]]) # 表示坐标
values = torch.tensor([3.0, 4.0, 5.0]) # 对应值
sparse_tensor = torch.sparse_coo_tensor(indices, values, (2, 3))print("未合并之前:")
print(sparse_tensor)# 使用 coalesce() 合并重复索引
coalesced_tensor = sparse_tensor.coalesce()print("合并之后:")
print(coalesced_tensor)
输出结果:
未合并之前:
tensor(indices=tensor([[0, 1, 1],[2, 0, 0]]),values=tensor([3., 4., 5.]),size=(2, 3), nnz=3, layout=torch.sparse_coo)
合并之后:
tensor(indices=tensor([[0, 1],[2, 0]]),values=tensor([3., 9.]),size=(2, 3), nnz=2, layout=torch.sparse_coo)
可以看到,坐标 [1, 0] 重复出现了两次,值 4.0 和 5.0 被合并成了 9.0。
这个例子的具体解析如下
在这个例子中,indices 和 values 用来创建一个稀疏张量,表示了一个 2x3 的张量。下面逐步解释如何合并重复的索引,并解释每个元素的含义。
初始稀疏张量:
indices = torch.tensor([[0, 1, 1], [2, 0, 0]])
values = torch.tensor([3.0, 4.0, 5.0])
indices 表示张量中非零元素的坐标,每一列表示一个非零元素的坐标:
- 第一列
[0, 2]代表位置 (0, 2),即第一行第三列。 - 第二列
[1, 0]代表位置 (1, 0),即第二行第一列。 - 第三列
[1, 0]代表位置 (1, 0),即第二行第一列。
values 是这些坐标位置对应的值:
- 位置 (0, 2) 的值是 3.0。
- 位置 (1, 0) 的值是 4.0。
- 位置 (1, 0) 的值是 5.0。
因此,张量的稀疏表示为:
[[0, 0, 3.0],[4.0 + 5.0, 0, 0]]
也就是说,第二行的第一列包含两个非零元素:4.0 和 5.0。
使用 coalesce() 合并重复索引:
coalesced_tensor = sparse_tensor.coalesce()
coalesce() 会合并重复的索引,并将它们的值相加。具体地:
- 对于位置 (1, 0),它有两个非零值 4.0 和 5.0,因此它们会被合并为 9.0。
- 位置 (0, 2) 保持为 3.0,因为它是唯一的非零元素。
所以,合并之后的张量变为:
[[0, 0, 3.0],[9.0, 0, 0]]
合并后的稀疏张量:
tensor(indices=tensor([[0, 1],[2, 0]]),values=tensor([3., 9.]),size=(2, 3), nnz=2, layout=torch.sparse_coo)
indices表示合并后的非零元素的坐标。只有两个非零元素:一个位于 (0, 2),另一个位于 (1, 0)。values表示这些坐标位置的值:3.0 和 9.0。nnz=2表示非零元素的数量(合并后的张量有两个非零元素)。
总结:
合并后的稀疏张量仍然是一个 2x3 张量,但是它去掉了重复的索引,并将重复索引位置的值进行了求和。
用于 FP16 梯度处理
在混合精度训练(AMP)中,如果需要处理 FP16 精度的稀疏梯度,可能会遇到重复索引问题。例如,在分布式训练中累积梯度时,需要确保梯度不会因为重复索引而导致计算错误。因此,我们可以利用 coalesce() 来合并梯度。
以下是一个示例代码片段:
import torch# 模拟 FP16 的稀疏梯度
indices = torch.tensor([[0, 1, 1], [2, 0, 0]])
values = torch.tensor([0.5, 0.25, 0.25], dtype=torch.float16)
grad = torch.sparse_coo_tensor(indices, values, (2, 3), dtype=torch.float16)# 合并梯度
if grad.dtype == torch.float16:grad = grad.coalesce()print(grad)
输出结果:
tensor(indices=tensor([[0, 1],[2, 0]]),values=tensor([0.5000, 0.5000], dtype=torch.float16),size=(2, 3), nnz=2, layout=torch.sparse_coo)
在 AMP 训练过程中,这种操作确保梯度不会因为浮点精度或重复索引导致数值错误。
高级用法
1. 检查是否已合并
可以使用 is_coalesced() 函数检查稀疏张量是否已合并:
if not grad.is_coalesced():grad = grad.coalesce()
2. 支持更高维度操作
coalesce() 也支持高维稀疏张量。例如:
indices = torch.tensor([[0, 1, 1, 2], [2, 0, 0, 1], [1, 2, 2, 3]])
values = torch.tensor([1.0, 2.0, 3.0, 4.0])
sparse_tensor = torch.sparse_coo_tensor(indices, values, (3, 3, 4))
coalesced_tensor = sparse_tensor.coalesce()
print(coalesced_tensor)
Output
tensor(indices=tensor([[0, 1, 2],[2, 0, 1],[1, 2, 3]]),values=tensor([1., 5., 4.]),size=(3, 3, 4), nnz=3, layout=torch.sparse_coo)
分析这个稀疏张量的情况
稀疏张量的构建与合并过程:
indices 解析:
indices 是一个 3x4 的张量,表示四个非零元素的坐标。每一列代表一个坐标,分别是:
- 第一列
[0, 2, 1],表示位置 (0, 2, 1),即第一维索引 0,第二维索引 2,第三维索引 1。 - 第二列
[1, 0, 2],表示位置 (1, 0, 2),即第一维索引 1,第二维索引 0,第三维索引 2。 - 第三列
[1, 0, 2],表示位置 (1, 0, 2),即第一维索引 1,第二维索引 0,第三维索引 2。 - 第四列
[2, 1, 3],表示位置 (2, 1, 3),即第一维索引 2,第二维索引 1,第三维索引 3。
values 解析:
values 是一个长度为 4 的张量,表示在上述位置的值:
- 位置 (0, 2, 1) 的值为 1.0。
- 位置 (1, 0, 2) 的值为 2.0。
- 位置 (1, 0, 2) 的值为 3.0。
- 位置 (2, 1, 3) 的值为 4.0。
创建的稀疏张量:
稀疏张量的维度为 (3, 3, 4),并且非零元素位于:
- 位置 (0, 2, 1) 为 1.0。
- 位置 (1, 0, 2) 为 2.0。
- 位置 (1, 0, 2) 为 3.0(同样位置的两个值合并)。
- 位置 (2, 1, 3) 为 4.0。
使用 coalesce() 合并重复索引:
当调用 coalesce() 时,它会合并相同坐标上的值,将它们相加。因此,位置 (1, 0, 2) 的值 2.0 和 3.0 会合并为 5.0。
合并后的非零位置和值:
- 位置 (0, 2, 1) 的值为 1.0。
- 位置 (1, 0, 2) 的值为 5.0(2.0 + 3.0)。
- 位置 (2, 1, 3) 的值为 4.0。
输出整个张量:
现在我们可以构造一个完整的张量,其中非零位置的值已经被填充,而其他位置仍然是零。结果应为:
[[[ 0, 0, 0, 0],[ 0, 0, 0, 0],[ 0, 1, 0, 0]],[[ 0, 0, 5, 0],[ 0, 0, 0, 0],[ 0, 0, 0, 0]],[[ 0, 0, 0, 0],[ 0, 0, 0, 4],[ 0, 0, 0, 0]]]
解释:
- 位置 (0, 2, 1) 的值是 1.0。
- 位置 (1, 0, 2) 的值是 5.0(合并了 2.0 和 3.0)。
- 位置 (2, 1, 3) 的值是 4.0。
- 其他位置都为零。
因此,最终的输出张量是:
[[[ 0, 0, 0, 0],[ 0, 0, 0, 0],[ 0, 1, 0, 0]],[[ 0, 0, 5, 0],[ 0, 0, 0, 0],[ 0, 0, 0, 0]],[[ 0, 0, 0, 0],[ 0, 0, 0, 4],[ 0, 0, 0, 0]]]
这个结果就是在合并重复索引后得到的稀疏张量。
3. 在优化器中的应用
在梯度缩放优化器中,我们可以利用 coalesce() 保持梯度一致性:
for param in model.parameters():if param.grad is not None and param.grad.is_sparse:param.grad = param.grad.coalesce()
具体解释
在优化器中的应用中,coalesce() 的作用是在稀疏梯度(例如,在使用稀疏参数或稀疏更新的模型时)中合并相同位置上的梯度,以确保梯度的一致性。特别是在分布式训练或使用梯度累积时,多个梯度更新可能会产生相同位置上的不同梯度值。在这种情况下,调用 coalesce() 可以将相同位置的梯度值合并(加和),防止在更新参数时重复计算,从而提高训练效率并避免梯度值不一致。
具体应用场景:
在训练过程中,当某些参数的梯度是稀疏的(即只有少数位置的梯度非零),如果在多个阶段对这些位置进行更新,可能会出现多个梯度值对同一位置进行计算。此时,我们希望对相同位置的梯度值进行合并,以保证这些位置的最终梯度是正确的。这通常发生在使用稀疏矩阵操作时(如稀疏优化器、稀疏神经网络)。
通过调用 coalesce(),我们可以确保相同位置的梯度值加和到一起,避免因为重复计算导致的不一致问题。
数值模拟:
假设我们有一个包含两个参数的模型,且它们的梯度是稀疏的。我们将模拟以下场景:
- 初始稀疏梯度:设定一个稀疏梯度,并模拟两个步骤的梯度更新。
- 梯度合并前:在两个步骤中,我们对相同位置的参数更新了不同的梯度值。
- 梯度合并后:使用
coalesce()合并相同位置的梯度。
import torch# 假设模型有2个参数,每个参数的梯度是稀疏的
# 初始梯度
indices = torch.tensor([[0, 1], [1, 0]]) # 表示在位置 (0, 1) 和 (1, 0) 上有梯度
values = torch.tensor([1.0, 2.0]) # 对应位置的梯度
sparse_grad = torch.sparse_coo_tensor(indices, values, (2, 2))# 输出初始稀疏梯度
print("初始稀疏梯度:")
print(sparse_grad)# 模拟第二次更新,更新相同位置
indices_new = torch.tensor([[0, 1], [1, 0]]) # 仍然是相同的位置
values_new = torch.tensor([3.0, 4.0]) # 对应位置新的梯度
sparse_grad_new = torch.sparse_coo_tensor(indices_new, values_new, (2, 2))# 合并梯度
combined_grad = sparse_grad + sparse_grad_new # 两个稀疏梯度相加# 合并后的稀疏梯度
print("\n合并前的稀疏梯度:")
print(combined_grad)# 使用 coalesce() 合并相同位置的梯度
coalesced_grad = combined_grad.coalesce()# 合并后的稀疏梯度
print("\n合并后的稀疏梯度:")
print(coalesced_grad)
解释:
-
初始梯度:
我们定义了一个稀疏梯度sparse_grad,它在位置(0, 1)和(1, 0)具有梯度值 1.0 和 2.0。 -
第二次更新:
模拟了一个新的稀疏梯度sparse_grad_new,其中位置(0, 1)和(1, 0)的梯度分别更新为 3.0 和 4.0。 -
合并梯度:
在合并两个稀疏梯度时,直接将它们相加,得到combined_grad。此时,两个位置上的梯度被简单地加在一起,得到的梯度分别是 4.0(1.0 + 3.0)和 6.0(2.0 + 4.0)。 -
梯度合并(coalesce):
使用coalesce()方法后,任何相同位置的梯度会被合并。由于我们的梯度已经在上一步合并,coalesce()会确保这些位置的梯度值是正确的。如果存在重复的索引,coalesce()会将它们的值加和。
输出:
初始稀疏梯度:
tensor(indices=tensor([[0, 1],[1, 0]]),values=tensor([1., 2.]),size=(2, 2), nnz=2, layout=torch.sparse_coo)合并前的稀疏梯度:
tensor(indices=tensor([[0, 1],[1, 0]]),values=tensor([4., 6.]),size=(2, 2), nnz=2, layout=torch.sparse_coo)合并后的稀疏梯度:
tensor(indices=tensor([[0, 1],[1, 0]]),values=tensor([4., 6.]),size=(2, 2), nnz=2, layout=torch.sparse_coo)
结论:
- 合并前:我们看到
combined_grad中相同位置的梯度已经进行了加法操作,但这只是简单的相加,并没有执行任何额外的合并操作。 - 合并后:由于
coalesce()会将相同位置的梯度加和,这个操作确保了梯度在同一位置的值是一致的,避免了重复的更新。
通过这种方式,coalesce() 可以有效地帮助我们在稀疏梯度中保持一致性,确保在更新模型参数时不会出现梯度冲突或不一致的情况。
注意事项
- 自动合并限制:某些 PyTorch 操作可能不会自动对稀疏张量进行合并,因此需要手动调用
coalesce()。 - 内存优化:在大规模稀疏矩阵计算中,合并操作有助于减少内存开销,提高计算效率。
- 不可逆操作:
coalesce()会生成新的张量,如果需要保留原始数据,需提前备份。
结论
coalesce() 是处理稀疏张量中重复索引的重要工具,尤其适合需要处理混合精度训练的梯度更新场景。通过上述示例和应用场景,希望读者对该函数有更深入的理解,并能在实际项目中灵活应用。
后记
2025年1月2日19点29分于上海,在GPT4o mini的辅助下完成。
相关文章:
 函数详解与应用示例)
PyTorch 中 coalesce() 函数详解与应用示例
PyTorch 中 coalesce() 函数详解与应用示例 coalesce: 美 [ˌkoʊəˈlɛs] 合并;凝聚;联结,注意发音 引言 在 PyTorch 中,稀疏张量(Sparse Tensor)是一种高效存储和操作稀疏数据的方式。稀疏…...

ubuntu进行C++的调试
方法一:gdb调试 作用: GDB 是 GNU 调试器,用于调试 C/C 程序。它可以在命令行中使用,提供强大的调试功能。 集成: GDB 可以独立于 VSCode 使用,你可以在终端中直接运行 GDB 来调试程序。 使用示例:编译程序时使用 -g 选项以包含调…...

【U8+】用友U8软件中,出入库流水输出excel的时候提示报表输出引擎错误。
【问题现象】 通过天联高级版客户端登录拥有U8后, 将出入库流水输出excel的时候,提示报表输出引擎错误。 进行报表输出时出现错误,错误信息:找不到“fd6eea8b-fb40-4ce4-8ab4-cddbd9462981.htm”。 如果您正试图从最近使用的文件列…...

NoSQL简介
NoSQL 的定义及特点 NoSQL(Not Only SQL)是一种非关系型数据库,设计之初为解决关系型数据库在扩展性、性能和多样化数据处理方面的局限性。NoSQL 支持多种数据模型,包括键值对、文档、列族和图形结构,广泛应用于大规模…...

XIAO Esp32 S3 网络摄像头——3音视频监控
1、介绍 之前分别介绍了音频和视频的接收,本文是整合了前2篇文章,实现了音视频的同时获取。 效果: 用xiao esp35 s3自制一个网络摄像头 2、适用场景广泛 家庭安防 无论是门前监控,还是室内安全,自制摄像头可以让你轻松把握每个角落,实时查看视频流,防止任何潜在风险。…...

题目解析与代码实现:You‘re Given a String
引言 本文将详细解读一道字符串处理题目 “You’re Given a String”,并用 Python 实现该题的解决方案,同时解析其核心算法逻辑。本文适合有一定基础的程序员,希望通过字符串算法提升能力的读者。 1. 题目描述 问题背景 题目给出了一个字符…...

Understanding the Lomb–Scargle Periodogram
本文目的:了解Lomb–Scargle Periodogram的原理 (用来估算不均匀采样数据的周期)参考文献Understanding the Lomb–Scargle Periodogram思路: 连续傅里叶变换 --> 离散傅里叶变换(均匀采样–> Classifical perio…...

解决Linux切换用户后的命令提示符为-bashxx$的问题
1、问题描述 切换用户时,命令提示符为-bashxx$ 比如: [rootlocalhost ~]# su zhouxingchi bash-4.2$ ### 显示看着不正常的命令提示符 2、PS1变量 PS1变量就是我们的命令提示符的内容,当我们登录时会加载该变量,从而显示提…...
)
AMP 混合精度训练中的动态缩放机制: grad_scaler.py函数解析( torch._amp_update_scale_)
AMP 混合精度训练中的动态缩放机制 在深度学习中,混合精度训练(AMP, Automatic Mixed Precision)是一种常用的技术,它利用半精度浮点(FP16)计算来加速训练,同时使用单精度浮点(FP32…...
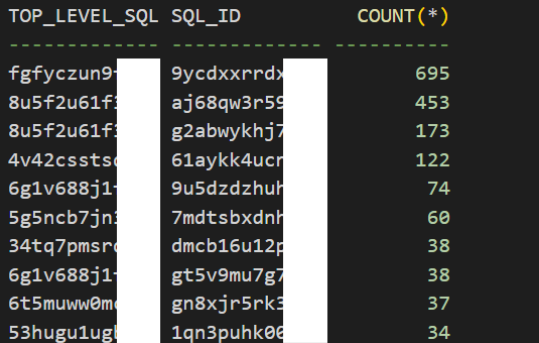
Oracle数据库如何找到 Top Hard Parsing SQL 语句?
有一个数据库应用程序存在过多的解析问题,因此需要找到产生大量硬解析的主要语句。 什么是硬解析 Oracle数据库中的硬解析(Hard Parse)是指在执行SQL语句时,数据库需要重新解析该SQL语句,并创建新的执行计划的过程。这…...

Mono里运行C#脚本25—mono_codegen
前面分析怎么样找到主函数Main的入口点功能,也就是说已经找到了这个函数的CIL代码。虽然找到了代码,但是还不能执行它的,因为它是一种虚拟机的代码。也就是说它是假的代码,不是现实世界存在的机器的代码,因此不能直接执行,必须经过后端编译器的再次编译才能真正运行它。下…...

flink cdc oceanbase(binlog模式)
接上文:一文说清flink从编码到部署上线 环境:①操作系统:阿里龙蜥 7.9(平替CentOS7.9);②CPU:x86;③用户:root。 预研初衷:现在很多项目有国产化的要求&#…...

【WPF】 数据绑定机制之INotifyPropertyChanged
INotifyPropertyChanged 是 WPF 中的一个接口,用于实现 数据绑定 中的 属性更改通知。它的主要作用是,当对象的某个属性值发生更改时,通知绑定到该属性的 UI 控件更新其显示内容。 以下是有关 INotifyPropertyChanged 的详细信息和实现方法&…...
为例及实战应用)
机器学习算法深度解析:以支持向量机(SVM)为例及实战应用
机器学习算法深度解析:以支持向量机(SVM)为例及实战应用 在当今数据驱动的时代,机器学习作为人工智能的一个核心分支,正以前所未有的速度改变着我们的生活与工作方式。从金融风控到医疗诊断,从自动驾驶到智…...

网络编程基础:连接Java的秘密网络
1 网络编程的重要性 网络编程允许Java应用程序与其他计算机或设备进行通信。这包括从简单的数据传输到复杂的分布式系统和Web服务。 2 Java网络编程的核心类 Java提供了多个类来支持网络编程: InetAddress:表示网络上的IP地址。 URL:表示统…...

无监督学习:自编码器(AutoEncoder)
自编码器:数据的净化之旅 引言 自编码器作为一种强大的特征学习方法,已经经历了从简单到复杂的发展历程。本文综述了多种类型的自编码器及其演进过程,强调了它们在数据降维、图像处理、噪声去除及生成模型等方面的关键作用。随着技术的进步…...

在不到 5 分钟的时间内将威胁情报 PDF 添加为 AI 助手的自定义知识
作者:来自 Elastic jamesspi 安全运营团队通常会维护威胁情报报告的存储库,这些报告包含由报告提供商生成的大量知识。然而,挑战在于,这些报告的内容通常以 PDF 格式存在,使得在处理安全事件或调查时难以检索和引用相关…...

Memcached prepend 命令
Memcached prepend 命令用于向已存在 key(键) 的 value(数据值) 前面追加数据 。 语法: prepend 命令的基本语法格式如下: prepend key flags exptime bytes [noreply] value参数说明如下: key:键值 key-value 结构中的 key&a…...

Win10 VScode配置远程Linux开发环境
Windows VScode配置远程Linux开发环境 记录一下在Windows下VScode配置远程连接Linux环境进行开发的过程。 VScode的远程编程与调试的插件Remote Development,使用这个插件可以在很多情况下代替vim直接远程修改与调试服务器上的代码,搭配上VScode的语言…...

微信小程序校园自助点餐系统实战:从设计到实现
随着移动互联网的发展,越来越多的校园场景开始智能化、自助化。微信小程序凭借其轻量化、便捷性和强大的生态支持,成为了各类校园应用的首选工具之一。今天,我们将通过实际开发一个微信小程序“校园自助点餐系统”来展示如何设计和实现这样一…...
)
保姆级教程:从驱动到IDE,搞定MaixBit开发环境(附固件选择避坑指南)
保姆级教程:从驱动到IDE,搞定MaixBit开发环境(附固件选择避坑指南) 刚拿到MaixBit开发板的新手们,面对嵌入式AI开发可能会感到无从下手。别担心,这篇教程将带你从零开始,一步步完成开发环境的搭…...

Obsidian Dataview数据索引与查询引擎:构建智能知识库的完整技术方案
Obsidian Dataview数据索引与查询引擎:构建智能知识库的完整技术方案 【免费下载链接】obsidian-dataview A data index and query language over Markdown files, for https://obsidian.md/. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-dataview …...

如何用MTB Nodes轻松制作专业级ComfyUI动画:免费开源终极指南
如何用MTB Nodes轻松制作专业级ComfyUI动画:免费开源终极指南 【免费下载链接】comfy_mtb Animation oriented nodes pack for ComfyUI 项目地址: https://gitcode.com/gh_mirrors/co/comfy_mtb 想用ComfyUI创作惊艳动画却不知从何开始?MTB Nodes…...

【限时解密】2026奇点大会未公开PPT核心页:5大AI根因分析失效场景及防御性编码清单
第一章:2026奇点智能技术大会:AI代码根因分析 2026奇点智能技术大会(https://ml-summit.org) 本届大会首次将“AI代码根因分析”列为独立技术轨道,聚焦大模型驱动的自动化缺陷定位、语义级错误溯源与跨栈因果推理。不同于传统日志分析或符号…...

终极指南:三步快速打造你的英雄联盟智能助手ChampR
终极指南:三步快速打造你的英雄联盟智能助手ChampR 【免费下载链接】champr 🐶 Yet another League of Legends helper 项目地址: https://gitcode.com/gh_mirrors/ch/champr 还在为每次游戏都要手动查找出装符文而烦恼吗?还在因为版本…...

AI写专著高效之道:AI专著生成工具,20万字专著快速搞定
学术专著写作与AI工具应用 学术专著的主要价值在于其内容的条理清晰和逻辑严谨,但这一点在写作过程中常常是最大的挑战。与专注于单一话题的期刊论文不同,专著的撰写需要构建一个包括绪论、理论基础、核心研究、应用拓展及结论的完整体系。每个章节都应…...

3个步骤:如何用ParsecVDisplay为Windows创建高性能虚拟4K显示器
3个步骤:如何用ParsecVDisplay为Windows创建高性能虚拟4K显示器 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一款基于Parsec虚拟显示驱动技术的独…...

WeKnora入门教程:零基础搭建个人知识管理系统
WeKnora入门教程:零基础搭建个人知识管理系统 1. 引言 你是不是经常遇到这样的情况:电脑里存了几百个文档,想找某个资料时却像大海捞针?或者团队的知识分散在各个成员的电脑里,新人来了根本不知道从哪里学起…...

OFA模型与Dify平台集成:可视化构建无代码图像描述AI应用
OFA模型与Dify平台集成:可视化构建无代码图像描述AI应用 你有没有遇到过这样的场景?产品经理或运营同事拿着几张图片跑过来,问你能不能快速做一个“看图说话”的小工具,用来给商品图自动配文案,或者给活动海报生成描述…...

C++20中views的学习和使用
如你所知,C标准库从C98发布以来在机制层面一直没有较大变动。直到C20中range的引入,再次使得沉寂许久的C标准库再次焕发了生机。range 库主要作用于对具有范围的数据处理。对于确定范围的数据,在传统标准库中也有对应的处理方案。但 range 对…...