基于EasyExcel实现通用版一对一、一对多、多层嵌套结构数据导出并支持自动合并单元格
接口功能
通用
支持一对一数据结构导出
支持一对多数据结构导出
支持多层嵌套数据结构导出
支持单元格自动合并
原文来自:https://blog.csdn.net/qq_40980205/article/details/136564176
新增及修复
基于我自己的使用场景,新增并能修复一下功能:
- 修复了只有单条一对一数据无法导出问题;
- 修复了多层嵌套数据结构中存在某个嵌套集合为空无法导出问题;
- 修复了只有一条一对多数据导出时报错问题;
完整源码解析
- @MyExcelProperty 作用到导出字段上面,表示这是Excel的一列
- @MyExcelCollection 表示一个集合,主要针对一对多的导出,比如一个老师对应多个科目,科目就可以用集合表示
- @MyExcelEntity 表示一个还存在嵌套关系的导出实体
property为基本数据类型的注解类
package com.example.excel.annotation;import java.lang.annotation.*;@Inherited
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface MyExcelProperty {String name() default "";int index() default Integer.MAX_VALUE;}
property为集合的注解类
package com.example.excel.annotation;import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface MyExcelCollection {String name();
}
property为实体对象的注解类
package com.example.excel.annotation;import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface MyExcelEntity {String name() default "";
}
导出参数类
package com.example.excel.excel;import lombok.Data;
import lombok.experimental.Accessors;@Data
@Accessors(chain = true)
public class ExportParam {private String fieldName;private String columnName;private Integer order;
}
导出实体类
package com.example.excel.excel;import lombok.Data;import java.util.List;
import java.util.Map;@Data
public class ExportEntity {/*** 导出参数*/private List<ExportParam> exportParams;/*** 平铺后的数据*/private List<Map<String,Object>> data;/*** 每列的合并行数组*/private Map<String, List<Integer[]>> mergeRowMap;
}
导出工具类
package com.example.excel.excel;import com.alibaba.excel.EasyExcel;
import com.example.excel.annotation.MyExcelCollection;
import com.example.excel.annotation.MyExcelEntity;
import com.example.excel.annotation.MyExcelProperty;
import com.google.common.base.Preconditions;
import com.google.common.collect.Lists;
import jakarta.servlet.http.HttpServletResponse;
import org.apache.commons.collections4.CollectionUtils;
import org.apache.commons.lang3.StringUtils;import java.io.IOException;
import java.lang.reflect.Field;
import java.lang.reflect.ParameterizedType;
import java.net.URLEncoder;
import java.util.*;
import java.util.stream.Collectors;public class MyExcelUtil {private final String DELIMITER = ".";/*** @param sourceData 导出数据源* @param fileName 导出文件名* @param response*/public void exportData(Collection<Object> sourceData, String sheetName, HttpServletResponse response) {if (CollectionUtils.isEmpty(sourceData)) return;ExportEntity exportEntity = flattenObject(sourceData);List<String> columnList = exportEntity.getExportParams().stream().sorted(Comparator.comparing(ExportParam::getOrder)).map(ExportParam::getFieldName).collect(Collectors.toList());List<List<Object>> exportDataList = new ArrayList<>();//导出数据集for (Map<String, Object> objectMap : exportEntity.getData()) {List<Object> data = new ArrayList<>();columnList.stream().forEach(columnName -> {data.add(objectMap.get(columnName));});exportDataList.add(data);}List<List<String>> headList = columnList.stream().map(Lists::newArrayList).collect(Collectors.toList());try {response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");response.setCharacterEncoding("utf-8");EasyExcel.write(response.getOutputStream()).sheet(sheetName).head(headList).registerWriteHandler(new MergeStrategy(exportEntity)).registerWriteHandler(new HeadHandler(exportEntity)).doWrite(exportDataList);} catch (IOException e) {e.printStackTrace();}}public ExportEntity flattenObject(Collection<Object> sourceData) {Map<String, List<Integer[]>> mergeMap = new HashMap<>();Class aClass = sourceData.stream().findFirst().get().getClass();List<ExportParam> exportParams = getAllExportField(aClass, "");Preconditions.checkArgument(!exportParams.isEmpty(), "export field not found !");List<Map<String, Object>> target = new ArrayList<>();Integer startRow = 0;for (Object sourceDataLine : sourceData) {List<Map<String, Object>> flatData = flattenObject(sourceDataLine, "", startRow, mergeMap);startRow += flatData.size();target.addAll(flatData);}ExportEntity exportEntity = new ExportEntity();exportEntity.setExportParams(exportParams);exportEntity.setData(target);exportEntity.setMergeRowMap(mergeMap);return exportEntity;}/*** @param data 数据行* @param preNode 上一层级字段名* @param startRow 当前数据行所在行数* @param mergeMap 各字段合并行数组* @return*/private List<Map<String, Object>> flattenObject(Object data, String preNode, Integer startRow, Map<String, List<Integer[]>> mergeMap) {List<Map<String, Object>> flatList = new ArrayList<>();if (null == data) return flatList;Class<?> aClass = data.getClass();//获取不为null的excel导出字段List<Field> collectionFields = new ArrayList<>();List<Field> entityFields = new ArrayList<>();List<Field> propertyFields = new ArrayList<>();for (Field field : aClass.getDeclaredFields()) {Object value = getFieldValue(field, data);if (null == value) continue;if (isCollection(field)) {collectionFields.add(field);} else if (isEntity(field)) {entityFields.add(field);} else if (isProperty(field)) {propertyFields.add(field);}}List<Map<String, Object>> entityFlatData = flattenEntityFields(entityFields, data, preNode, startRow, mergeMap);List<List<Map<String, Object>>> collectionFlatData = flattenCollectionFields(collectionFields, data, preNode, startRow, mergeMap);Map<String, Object> objectMap = Collections.emptyMap();if (collectionFields.isEmpty() && entityFields.isEmpty()) {objectMap = flattenPropertyFields(propertyFields, data, preNode);}if (collectionFlatData.isEmpty() && entityFlatData.isEmpty()) {objectMap = flattenPropertyFields(propertyFields, data, preNode);}if (!objectMap.isEmpty()) {flatList.add(objectMap);}//当前层级所有平铺列表List<List<Map<String, Object>>> allFlatData = Lists.newArrayList();if (!entityFlatData.isEmpty()) {allFlatData.add(entityFlatData);}if (!collectionFlatData.isEmpty()) {allFlatData.addAll(collectionFlatData);}List<Map<String, Object>> mergeList = mergeList(data, allFlatData, propertyFields, preNode, startRow, mergeMap);if (!mergeList.isEmpty()) {flatList.addAll(mergeList);}return flatList;}/*** @param preNode 上一层级字段名* @param fieldName 当前字段名* @return*/private String buildPreNode(String preNode, String fieldName) {StringBuffer sb = new StringBuffer();return StringUtils.isEmpty(preNode) ? fieldName : sb.append(preNode).append(DELIMITER).append(fieldName).toString();}/*** @param mergeFields 需要合并的字段* @param preNode 上一层级字段名* @param mergeStartRow 合并开始行* @param mergeEndRow 合并结束行* @param mergeMap 各字段合并行数组*/private void buildMerge(List<Field> mergeFields, String preNode, Integer mergeStartRow, Integer mergeEndRow, Map<String, List<Integer[]>> mergeMap) {for (int k = 0; k < mergeFields.size(); k++) {String fieldName = buildPreNode(preNode, mergeFields.get(k).getName());List<Integer[]> list = mergeMap.get(fieldName);if (null == list) {mergeMap.put(fieldName, new ArrayList<>());}Integer[] rowInterval = new Integer[2];//合并开始行rowInterval[0] = mergeStartRow;//合并结束行rowInterval[1] = mergeEndRow;mergeMap.get(fieldName).add(rowInterval);}}private List<Map<String, Object>> flattenEntityFields(List<Field> entityFields, Object data, String preNode, Integer startRow, Map<String, List<Integer[]>> mergeMap) {List<Map<String, Object>> entityFlatData = Lists.newArrayList();for (Field entityField : entityFields) {entityFlatData = flattenObject(getFieldValue(entityField, data), buildPreNode(preNode, entityField.getName()), startRow, mergeMap);}return entityFlatData;}private List<List<Map<String, Object>>> flattenCollectionFields(List<Field> collectionFields, Object data, String preNode, Integer startRow, Map<String, List<Integer[]>> mergeMap) {List<List<Map<String, Object>>> collectionFlatData = Lists.newArrayList();for (Field collectionField : collectionFields) {Collection collectionValue = (Collection) getFieldValue(collectionField, data);//当前集合字段平铺而成的数据列表List<Map<String, Object>> collectionObjectValue = new ArrayList<>();//间隔行数Integer row = 0;for (Object value : collectionValue) {List<Map<String, Object>> flatData = flattenObject(value, buildPreNode(preNode, collectionField.getName()), startRow + row, mergeMap);if (!flatData.isEmpty()) {collectionObjectValue.addAll(flatData);//下条数据的起始间隔行row += flatData.size();}}if (!collectionObjectValue.isEmpty()) {collectionFlatData.add(collectionObjectValue);}}return collectionFlatData;}private Map<String, Object> flattenPropertyFields(List<Field> propertyFields, Object data, String preNode) {Map<String, Object> flatMap = new HashMap<>();for (Field field : propertyFields) {flatMap.put(buildPreNode(preNode, field.getName()), getFieldValue(field, data));}return flatMap;}private List<Map<String, Object>> mergeList(Object data, List<List<Map<String, Object>>> allFlatData, List<Field> propertyFields, String preNode, Integer startRow, Map<String, List<Integer[]>> mergeMap) {List<Map<String, Object>> flatList = new ArrayList<>();//当前层级下多个集合字段的最大长度即为当前层级其他字段的合并行数Integer maxSize = 0;for (List<Map<String, Object>> list : allFlatData) {maxSize = Math.max(maxSize, list.size());}//记录集合同层级其他字段的合并行数if (maxSize > 0) {buildMerge(propertyFields, preNode, startRow, startRow + maxSize, mergeMap);}//需要合并if (maxSize > 1) {//重新构建平铺的listList<Map<String, Object>> mergeFlatData = new ArrayList<>(maxSize);for (int i = 0; i < maxSize; i++) {mergeFlatData.add(new HashMap<>());}for (List<Map<String, Object>> flatData : allFlatData) {for (int i = 0; i < flatData.size(); i++) {Map<String, Object> flatMap = new HashMap<>();flatMap.putAll(flatData.get(i));//添加同层级字段值if (CollectionUtils.isNotEmpty(propertyFields)) {for (Field field : propertyFields) {flatMap.put(buildPreNode(preNode, field.getName()), getFieldValue(field, data));}}mergeFlatData.get(i).putAll(flatMap);}}flatList.addAll(mergeFlatData);} else {for (List<Map<String, Object>> list : allFlatData) {flatList.addAll(list);}}return flatList;}/*** @param clazz 导出类* @param preNode 上一层级字段名* @return*/private List<ExportParam> getAllExportField(Class<?> clazz, String preNode) {List<ExportParam> exportFields = new ArrayList<>();for (Field declaredField : clazz.getDeclaredFields()) {MyExcelProperty myExcelProperty = declaredField.getDeclaredAnnotation(MyExcelProperty.class);MyExcelEntity myExcelEntity = declaredField.getDeclaredAnnotation(MyExcelEntity.class);MyExcelCollection myExcelCollection = declaredField.getDeclaredAnnotation(MyExcelCollection.class);String fieldName = buildPreNode(preNode, declaredField.getName());if (null != myExcelProperty) {ExportParam exportParam = new ExportParam().setFieldName(fieldName).setColumnName(myExcelProperty.name()).setOrder(myExcelProperty.index());exportFields.add(exportParam);} else if (null != myExcelEntity) {exportFields.addAll(getAllExportField(declaredField.getType(), fieldName));} else if (null != myExcelCollection) {boolean isCollection = Collection.class.isAssignableFrom(declaredField.getType());if (!isCollection) continue;ParameterizedType pt = (ParameterizedType) declaredField.getGenericType();Class<?> clz = (Class<?>) pt.getActualTypeArguments()[0];exportFields.addAll(getAllExportField(clz, fieldName));}}return exportFields;}private boolean isProperty(Field field) {return null != field.getDeclaredAnnotation(MyExcelProperty.class) ? true : false;}private boolean isEntity(Field field) {return null != field.getDeclaredAnnotation(MyExcelEntity.class) ? true : false;}private boolean isCollection(Field field) {boolean isCollection = Collection.class.isAssignableFrom(field.getType());return isCollection && null != field.getAnnotation(MyExcelCollection.class) ? true : false;}private Object getFieldValue(Field field, Object sourceObject) {Object fieldValue;try {field.setAccessible(true);fieldValue = field.get(sourceObject);} catch (IllegalAccessException e) {throw new RuntimeException(e);}return fieldValue;}}
单元格合并策略
```java
package com.example.excel.excel;import com.alibaba.excel.metadata.Head;
import com.alibaba.excel.write.merge.AbstractMergeStrategy;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.util.CellRangeAddress;
import org.springframework.util.CollectionUtils;import java.util.List;public class MergeStrategy extends AbstractMergeStrategy {private ExportEntity exportEntity;public MergeStrategy(ExportEntity exportEntity) {this.exportEntity = exportEntity;}@Overrideprotected void merge(Sheet sheet, Cell cell, Head head, Integer relativeRowIndex) {//mergeMap需要加上head的行数String fieldName = head.getHeadNameList().get(0);List<Integer[]> mergeRow = exportEntity.getMergeRowMap().get(fieldName);if (CollectionUtils.isEmpty(mergeRow)) return;int currentColumnIndex = cell.getColumnIndex();int currentRowIndex = cell.getRowIndex();//表头所占行数int headHeight = head.getHeadNameList().size();for (int i = 0; i < mergeRow.size(); i++) {if (currentRowIndex == mergeRow.get(i)[1] + headHeight - 1) {sheet.addMergedRegion(new CellRangeAddress(mergeRow.get(i)[0] + headHeight, mergeRow.get(i)[1] + headHeight - 1,currentColumnIndex, currentColumnIndex));}}}}
表头导出处理
```java
package com.example.excel.excel;import com.alibaba.excel.metadata.Head;
import com.alibaba.excel.metadata.data.WriteCellData;
import com.alibaba.excel.write.handler.CellWriteHandler;
import com.alibaba.excel.write.metadata.holder.WriteSheetHolder;
import com.alibaba.excel.write.metadata.holder.WriteTableHolder;
import org.apache.poi.ss.usermodel.Cell;import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;public class HeadHandler implements CellWriteHandler {private ExportEntity exportEntity;public HeadHandler(ExportEntity exportEntity) {this.exportEntity = exportEntity;}@Overridepublic void afterCellDispose(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder,List<WriteCellData<?>> cellDataList, Cell cell, Head head, Integer relativeRowIndex, Boolean isHead) {if (!isHead) return;List<String> headNameList = head.getHeadNameList();Map<String, String> collect = exportEntity.getExportParams().stream().collect(Collectors.toMap(ExportParam::getFieldName, ExportParam::getColumnName));cell.setCellValue(collect.get(headNameList.get(0)));}
}
导出示例
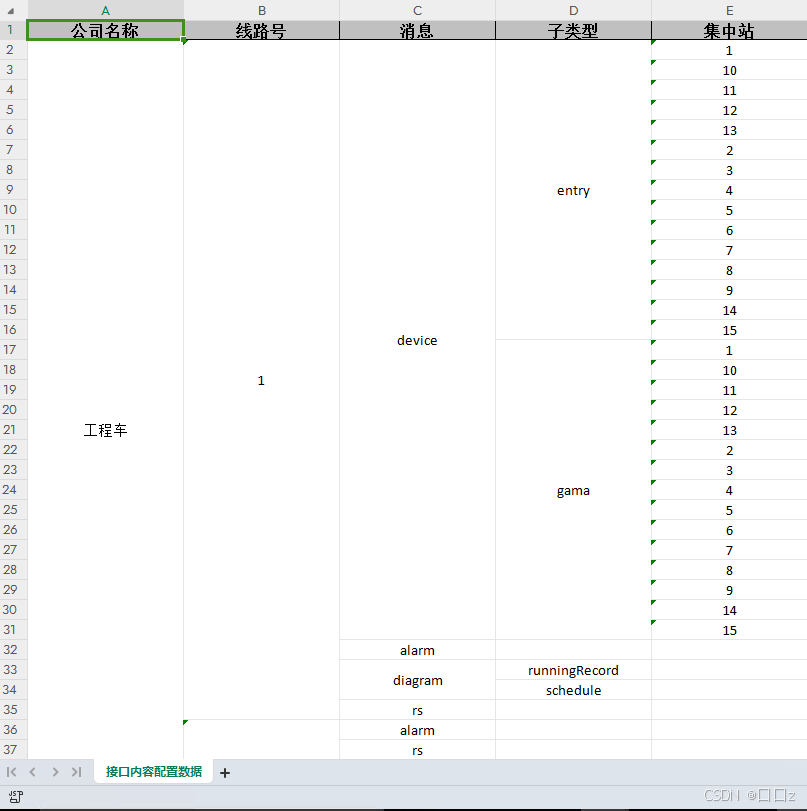
被导出实体
public class CompanyConfigEnntity{@MyExcelProperty(name = "公司名称")private String companyName;@MyExcelCollection(name = "线路配置")private List<LineConfigEntity> lineConfigs;}public class LineConfigEntity{@MyExcelProperty(name = "线路号")private String lineNumber;@MyExcelCollection(name = "消息配置")private List<MsgConfigEntity> msgConfigs;}public class MsgConfigEntity{@MyExcelProperty(name = "消息类型")private String msgType;@MyExcelCollection(name = "子类型配置")private List<SubTypeConfigEntity> subTypeConfigs;}public class SubTypeConfigEntity{@MyExcelProperty(name = "子类型")private String subType;@MyExcelCollection(name = "集中站配置")private List<RtuConfigEntity> rtuConfigs;}
public class RtuConfigEntity{@MyExcelProperty(name = "集中站号")private String rtuNumber;}接口调用
@RestController
@ReqeutMapping("/companyConfig/companyConfig")
public class CompanyConfigController{@AutoWiredprivate CompanyConfigService companyConfigService;@PostMappinng("/export")public void expooort(HttpServletResponse response){List<CompanyConfigEnityt> list = companyConfigService.queryAll();new MyExcelUtil().exportData(list, "公司配置内容数据", resposne);}
}效果展示
相关文章:
基于EasyExcel实现通用版一对一、一对多、多层嵌套结构数据导出并支持自动合并单元格
接口功能 通用 支持一对一数据结构导出 支持一对多数据结构导出 支持多层嵌套数据结构导出 支持单元格自动合并 原文来自:https://blog.csdn.net/qq_40980205/article/details/136564176 新增及修复 基于我自己的使用场景,新增并能修复一下功能&#x…...

Java堆内存分析
(一)、线上查看堆内存统计 # 命令用于打印堆内存中每个类的实例数量及其占用的内存,并且只包括活动对象(即存活的对象) jmap -histo:live <pid># 输出到文件方便查看 jmap -histo:live 12345 > aaa.txt(二)、下载dump文件࿰…...
maven高级(day15)
Maven 是一款构建和管理 Java 项目的工具 分模块设计与开发 所谓分模块设计,顾名思义指的就是我们在设计一个 Java 项目的时候,将一个 Java 项目拆分成多 个模块进行开发。 分模块设计我们在进行项目设计阶段,就可以将一个大的项目拆分成若干…...
:乘法器)
计算机组成原理(九):乘法器
乘法器原理 乘法器的工作原理可以用二进制乘法来说明。二进制乘法和十进制乘法类似,通过部分积的累加得到结果。 部分积的生成 在二进制乘法中,每一位的乘积是两个二进制数位的 与运算(0 0 0,1 0 0,0 1 0&…...

python【输入和输出】
Python 有三种输出值的方式: 表达式语句print() 函数使用文件对象的 write() 方法,标准输出文件可以用 sys.stdout 引用。 ① 将输出的值转成字符串,可以使用 repr() 或 str() 函数来实现: str(): 函数返回一个用户易…...
)
2024年华为OD机试真题-判断一组不等式是否满足约束并输出最大差-Python-OD统一考试(E卷)
最新华为OD机试考点合集:华为OD机试2024年真题题库(E卷+D卷+C卷)_华为od机试题库-CSDN博客 每一题都含有详细的解题思路和代码注释,精编c++、JAVA、Python三种语言解法。帮助每一位考生轻松、高效刷题。订阅后永久可看,发现新题及时跟新。 题目描述: 给定一组不等式…...
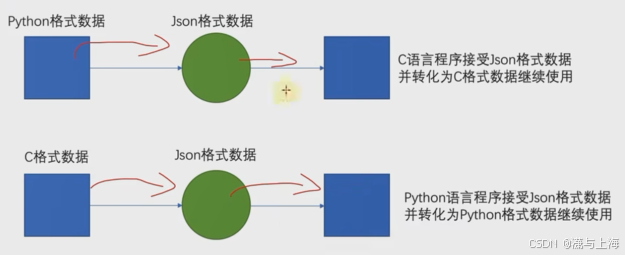
【json】
JSON JSON是一种轻量级的,按照指定的格式去组织和封装数据的数据交互格式。 本质上是一个带有特定格式的字符串(py打印json时认定为str类型) 在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互,类似于计算机普通话 python与json关系及相互转换…...
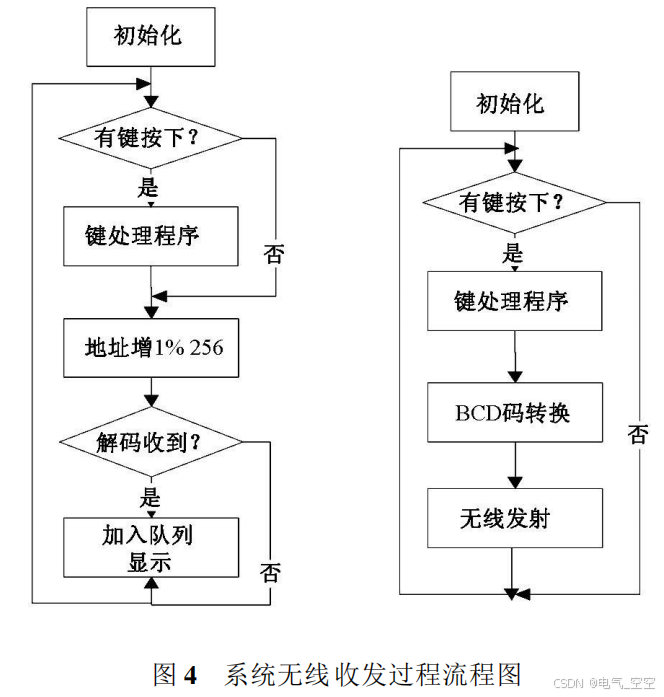
基于单片机的无线智能窗帘控制器的设计
摘 要 : 本文以单片机为控制核心 , 基于 PT2262/ 2272 无线收发模块 , 实现了窗帘的无线远程智能控制 . 该控制器通过高频无线收发模块实现了遥控窗帘的开合控制; 根据外部光线强弱实现自动开关窗帘 ; 根据设定时间自动完成开关过程; 通过语音播报当前环境温湿度信息以…...
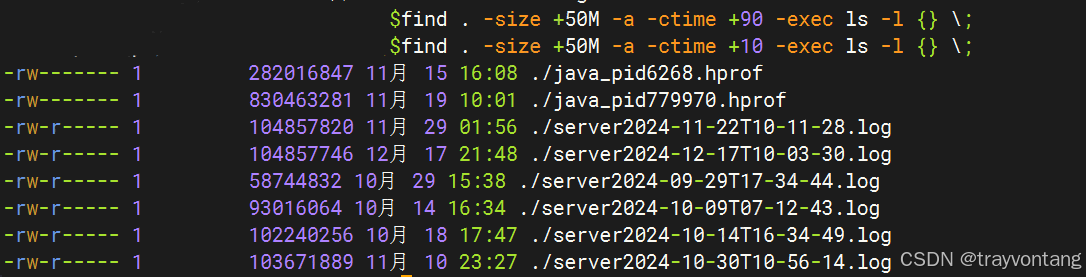
磁盘满造成业务异常问题排查
最近遇到一个因为磁盘满导致的问题,分享一下,希望能够帮助到以后遇到同样问题的朋友。 早上突然收到业务老师反馈说:上传文件不能正常上传了。 想想之前都好好的,最近又没有更新,为什么突然不能使用了呢?…...
)
C++例程:使用I/O模拟IIC接口(6)
完整的STM32F405代码工程I2C驱动源代码跟踪 一)myiic.c #include "myiic.h" #include "delay.h" #include "stm32f4xx_rcc.h" //初始化IIC void IIC_Init(void) { GPIO_InitTypeDef GPIO_InitStructure;RCC_AHB1PeriphCl…...
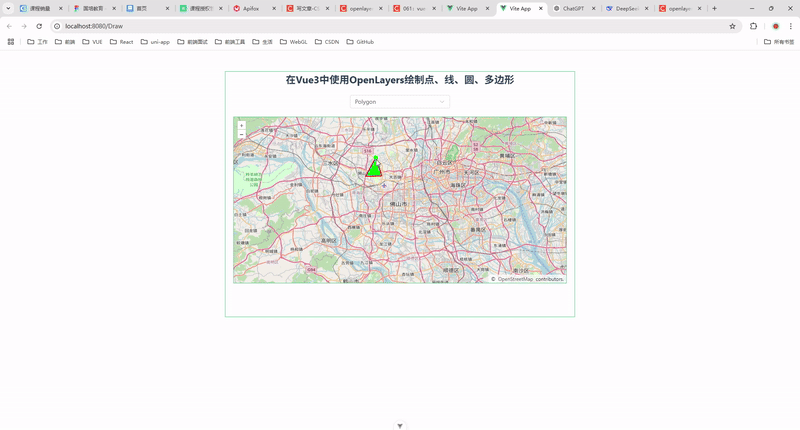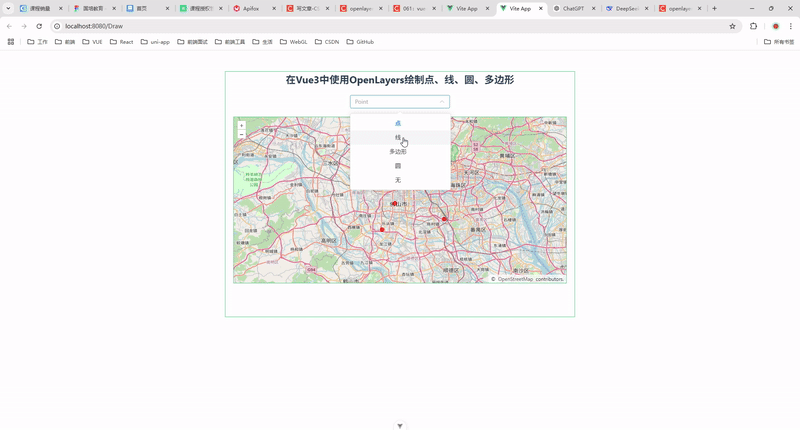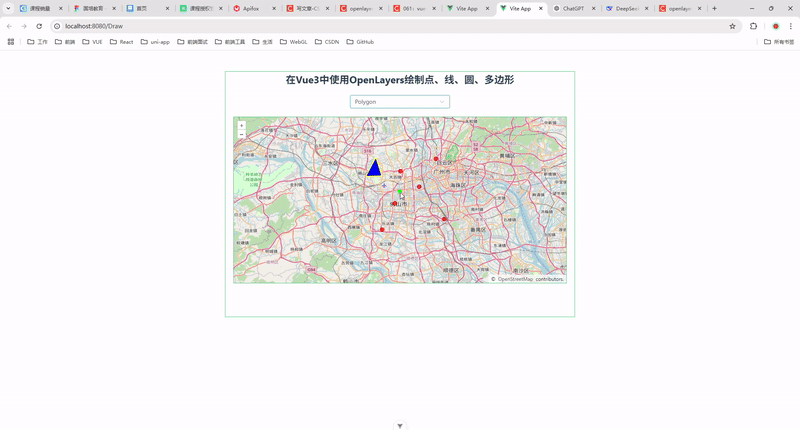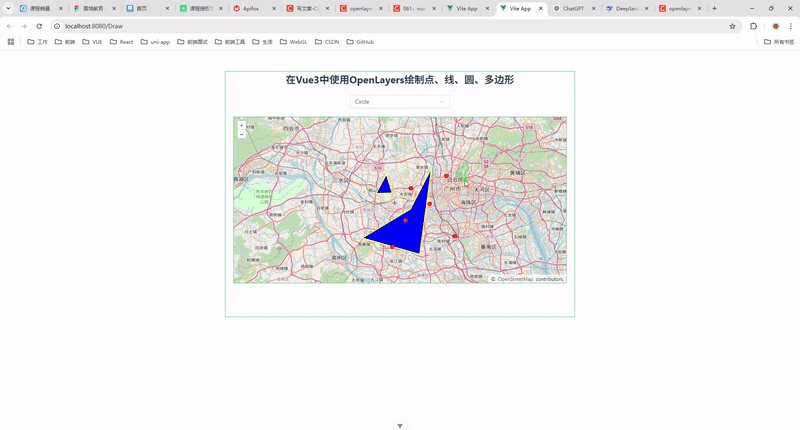
58.在 Vue 3 中使用 OpenLayers 绘制点、线、圆、多边形
前言 在现代 Web 开发中,地图功能已经成为许多应用的重要组成部分。OpenLayers 是一个强大的开源地图库,支持多种地图源和地图操作。结合 Vue 3 的响应式特性,我们可以轻松实现地图的交互功能。本文将详细介绍如何在 Vue 3 中使用 OpenLayer…...
如何快速上手一个鸿蒙工程
作为一名鸿蒙程序猿,当你换了一家公司,或者被交接了一个已有的业务。前辈在找你之前十分钟写了一个他都看不懂的交接文档,然后把一个鸿蒙工程交接给你了,说以后就是你负责了。之后几天你的状态大概就是下边这样的,一堆…...
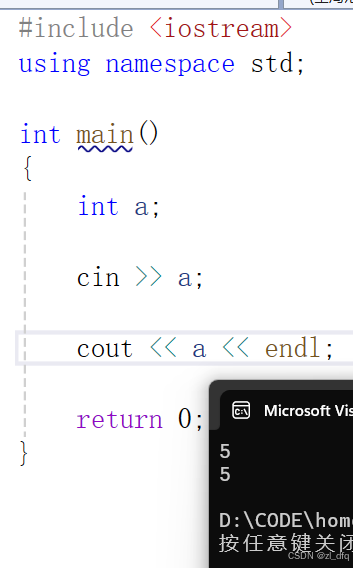
c++入门之 命名空间与输入输出
1、命名空间 1.1使用命名空间的原因 先看一个例子: #include <iostream>int round 0;int main() {printf("%d", round);return 0; }请问,这个程序能跑起来吗? 答案是否定的 原因是,当我们想创建一个全局变量 …...

GRE技术的详细解释
GRE(Generic Routing Encapsulation,通用路由封装)是一种隧道协议,主要用于在不同网络之间封装和传输其他网络层协议的数据包。它最常用于在IP网络上建立虚拟点到点的隧道连接,是实现VPN的一项关键技术。 下面从原理、…...
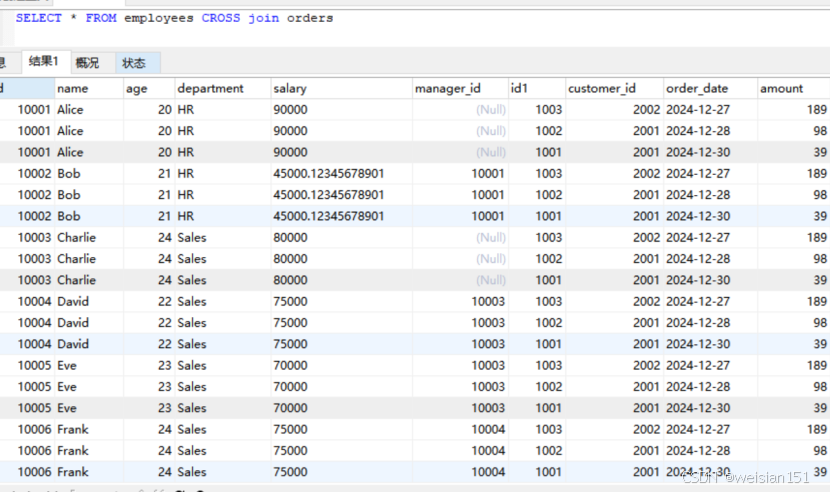
Mysql--基础篇--多表查询(JOIN,笛卡尔积)
在MySQL中,多表查询(也称为联表查询或JOIN操作)是数据库操作中非常常见的需求。通过多表查询,你可以从多个表中获取相关数据,并根据一定的条件将它们组合在一起。MySQL支持多种类型的JOIN操作,每种JOIN都有…...

Java 泛型的用法
1. 泛型类 泛型类是指在类定义时使用类型参数来指定类的类型。这样可以在类的内部使用这些类型参数来定义字段、方法的返回类型和参数类型。 public class Box<T> {private T t;public void set(T t) {this.t t;}public T get() {return t;} }在这个例子中,…...
人工智能与物联网:智慧城市的未来
引言 清晨6点,智能闹钟根据你的睡眠状态和天气情况,自动调整叫醒时间;窗帘缓缓打开,阳光洒满房间;厨房里的咖啡机已经为你准备好热饮,而无人驾驶公交车正按时抵达楼下站点。这不是科幻电影的场景ÿ…...

Python标准库之SQLite3
包含了连接数据库、处理数据、控制数据、自定义输出格式及处理异常的各种方法。 官方文档:sqlite3 --- SQLite 数据库的 DB-API 2.0 接口 — Python 3.13.1 文档 官方文档SQLite对应版本:3.13.1 SQLite主页:SQLite Home Page SQL语法教程&a…...
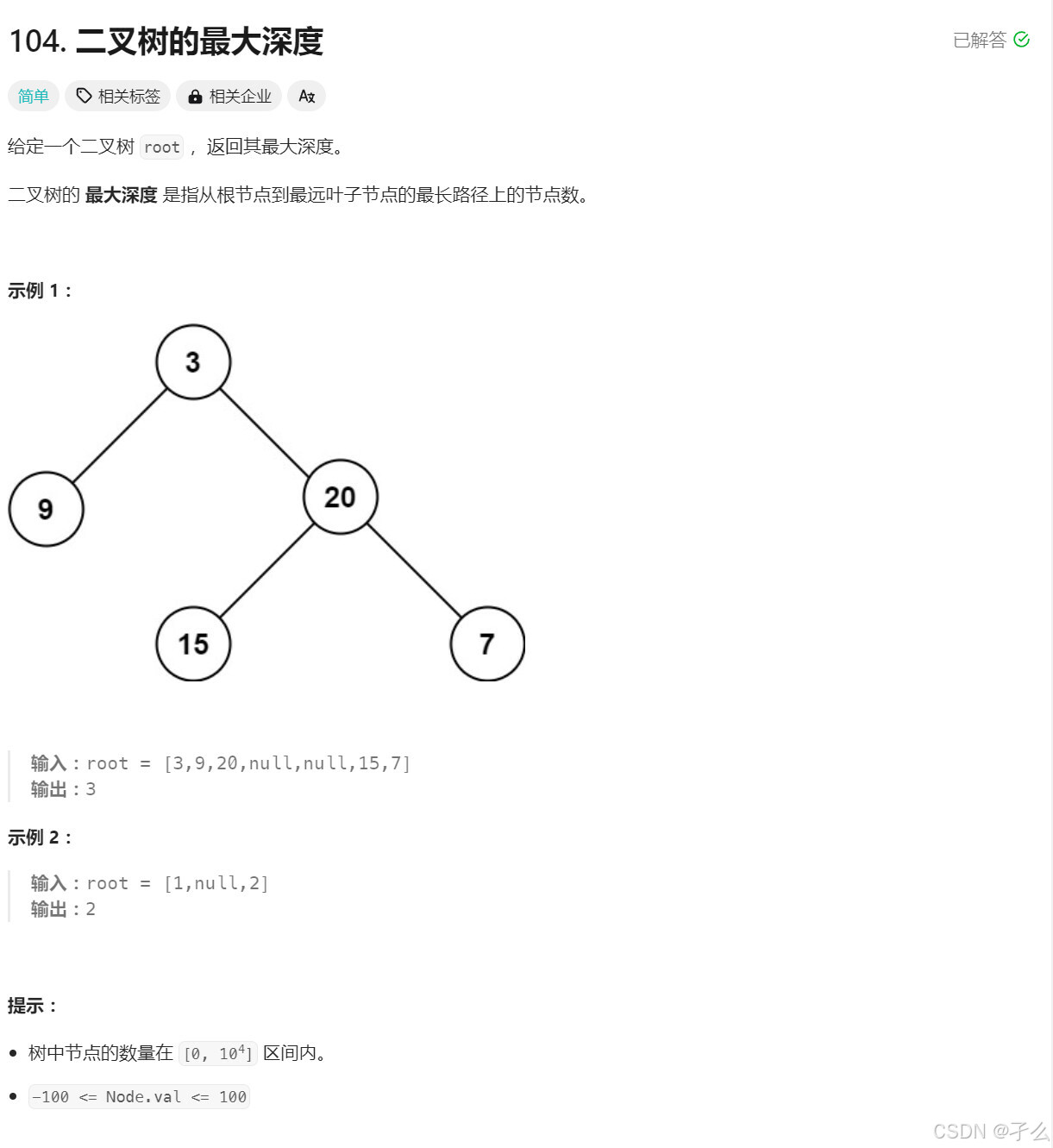
力扣 二叉树的最大深度
树的遍历,dfs与bfs基础。 题目 注意这种题要看根节点的深度是0还是1。 深度优先遍历dfs,通过递归分别计算左子树和右子树的深度,然后返回左右子树深度的最大值再加上 1。递归会一直向下遍历树,直到达到叶子节点或空节点。在回溯…...
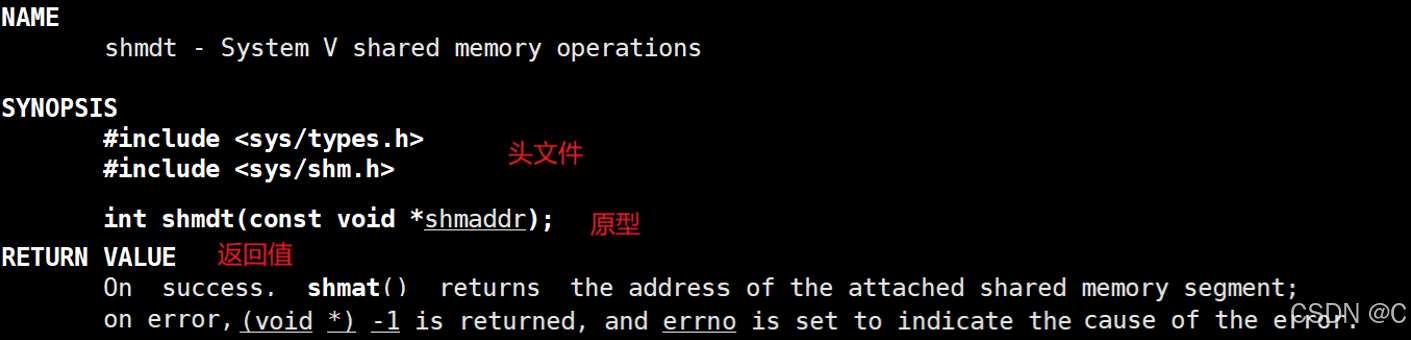
Linux_进程间通信_共享内存
什么是共享内存? 对于两个进程,通过在内存开辟一块空间(操作系统开辟的),进程的虚拟地址通过页表映射到对应的共享内存空间中,进而实现通信;物理内存中的这块空间,就叫做共享内存。…...

MMAUD:面向现代微型无人机威胁的全面多模态反无人机数据集
摘要 https://arxiv.org/pdf/2402.03706 针对小型无人机(UAV)不断演变的挑战(其具备运输有害载荷或独立造成破坏的潜力),我们推出了 MMAUD:一个全面的多模态反无人机数据集。MMAUD 通过专注于无人机检测、无…...
)
别再只跑测试了!用KAIR库从零训练你自己的SwinIR超分模型(附DIV2K/Flickr2K数据集处理避坑指南)
从测试到训练:SwinIR超分模型实战进阶指南 当你第一次用SwinIR的预训练模型将模糊照片变得清晰时,那种惊艳感可能让你跃跃欲试想训练自己的模型。但面对几十GB的数据集和复杂的训练配置,很多开发者停在了"只跑测试"的阶段。本文将带…...
)
手把手教你给M301H-BYT盒子刷当贝纯净桌面(附Hi3798芯片短接点位图)
从零开始:M301H-BYT盒子刷机实战指南 家里的老旧电视盒子用久了总是卡顿、存储不足,还限制应用安装?今天我们就来彻底解决这个问题。本文将手把手教你如何为M301H-BYT盒子刷入当贝纯净桌面系统,让你的老设备重获新生。不同于简单的…...

3步彻底解决Windows程序启动失败:VisualCppRedist AIO终极修复指南
3步彻底解决Windows程序启动失败:VisualCppRedist AIO终极修复指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否遇到过新安装的软件无法启动…...

从点击到意图:鸿蒙 App 的 AI 进化
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

别再死记硬背了!用Pointer Network让AI学会‘抄作业’,搞定文本摘要和对话生成
别再死记硬背了!用Pointer Network让AI学会‘抄作业’,搞定文本摘要和对话生成 想象一下,当你面对一篇冗长的技术文档时,最有效的学习方法是什么?不是逐字背诵,而是用荧光笔划出关键概念——这正是Pointer …...

告别文档踩坑:手把手教你用OkHttp和Gson解析OneNET API返回的复杂JSON数据
告别文档踩坑:手把手教你用OkHttp和Gson解析OneNET API返回的复杂JSON数据 在Android开发中,处理网络请求和JSON数据解析是每个开发者都必须掌握的基本技能。然而,当面对像OneNET这样的物联网平台返回的复杂嵌套JSON结构时,即使是…...
)
从物理模型到代码:用MATLAB类轻松构建你的第一个仿真对象(比如弹簧振子)
从物理模型到代码:用MATLAB类轻松构建你的第一个仿真对象 理工科研究者常面临一个核心挑战:如何将复杂的物理系统转化为可计算的数学模型?以弹簧振子为例,这个看似简单的力学系统蕴含着丰富的物理规律。传统脚本式编程往往导致代码…...

12306智能抢票助手终极指南:5步实现自动化抢票,告别手动刷票烦恼
12306智能抢票助手终极指南:5步实现自动化抢票,告别手动刷票烦恼 【免费下载链接】12306 12306智能刷票,订票 项目地址: https://gitcode.com/gh_mirrors/12/12306 还在为节假日抢不到火车票而烦恼吗?😫 12306智…...

拒绝封闭技术栈绑架:MyEMS 开源能源管理平台的架构中立性与兼容性设计
在企业数字化转型的深水区,能源管理系统正从单一的计量工具演变为支撑生产运营的核心基础设施。然而,当我们审视这一领域的技术现状时,不难发现一个令人警惕的现象:大量商业能源管理软件正通过封闭的技术栈、私有的通信协议和紧耦…...