Domain Adaptation(李宏毅)机器学习 2023 Spring HW11 (Boss Baseline)

1. 领域适配简介
领域适配是一种迁移学习方法,适用于源领域和目标领域数据分布不同但学习任务相同的情况。具体而言,我们在源领域(通常有大量标注数据)训练一个模型,并希望将其应用于目标领域(通常只有少量或没有标注数据)。然而,由于这两个领域的数据分布不同,模型在目标领域上的性能可能会显著下降。领域适配技术的目标是通过对模型进行适配,缩小源领域与目标领域之间的差距,从而提升模型在目标领域的表现。

以数字识别为例,如果我们的源数据是灰度图像,并且在这些数据上训练模型,我们可以预期模型会取得相当不错的效果。然而,如果我们将这个在灰度图像上训练的模型用于分类彩色图像,模型的表现可能会较差。这是因为这两个数据集之间存在领域转移。
领域适配方法可以根据目标领域中标签的可用性进行分类:
-
有监督领域适配:源领域和目标领域都有标注数据。这种情况较为少见,因为领域适配的主要动机是目标领域标签的稀缺性。
-
无监督领域适配:源领域有标注数据,而目标领域没有标注数据。这是最常见且最具挑战性的情况。
-
半监督领域适配:源领域有标注数据,目标领域则只有少量标注数据。

我们的博客和作业主要关注目标领域缺乏标注数据的场景。
解决这个问题的基本概念如下:我们旨在找到一个特征提取器,它能够接收输入数据并输出特征空间。这个特征提取器应该能够滤除领域特定的变化,同时保留不同领域之间共享的特征。例如,在以下的示例中,特征提取器应该能够忽略图像的颜色,对于相同的数字,不论其颜色如何,都能生成具有相同分布的特征。

研究人员提出了许多方法,其中对抗学习方法是最常见且最有效的技术之一。

我们将一个标准网络分为两部分:特征提取器和标签预测器。在训练过程中,我们以标准的有监督方式在源领域数据上训练整个网络。对于目标领域数据,我们只使用特征提取器提取特征,并采用技术手段将目标领域的特征与源领域的特征对齐。

具体来说,我们设计了一个新的领域分类器,它是一个二分类器,输入特征向量并判断输入数据是来自源领域还是目标领域。另一方面,特征生成器的设计目的是“欺骗”领域分类器,使其无法正确区分来源领域。

如果我们仔细思考上述方法,我们可以直观地理解,尽管对抗训练可以使源领域和目标领域的整体分布更加相似,如下图左侧所示,但这种分布可能并不适合或不适用于机器学习任务。理想情况下,我们期望获得右侧图像所示的分布。

当然,已有大量论文提出了针对这一问题的解决方法。为了在这次作业中通过strong 和 boss baseline,我们需要深入相关文献,并采用合适的方法。在作业中,我将介绍更多相关的论文和技术。
2. Homework Results and Analysis
作业 11 聚焦于领域适配。给定真实图像(带标签)和涂鸦(无标签),任务是利用领域适配技术训练一个网络,能够准确预测绘制图像的标签。

数据集设置:
-
标签:10个类别(编号从0到9),如以下图片所示。
-
训练集:5000张 (32, 32) RGB 真实图像(带标签)。
-
测试集:100000张 (28, 28) 灰度绘制图像。

baseline 的门槛 在 Kaggle 上的数值为:
| Baseline | Public | Private |
|---|---|---|
| Simple | Score >= 0.44280 | Score >= 0.44012 |
| Medium | Score >= 0.65994 | Score >= 0.65928 |
| Strong | Score >= 0.75342 | Score >= 0.75518 |
| Boss | Score >= 0.81072 | Score >= 0.80794 |
像往常一样,助教会提供关于如何超越各种基准模型的指导。


2.1 Simple Baseline
使用助教提供的默认代码足以通过 simple baseline。
2.2 Medium Baseline
通过增加训练轮数并调整超参数 lambda,可以通过 medium baseline。
num_epochs = 800
# train 800 epochswith Progress(TextColumn("[progress.description]{task.description}"),BarColumn(),TextColumn("[progress.percentage]{task.percentage:>3.0f}%"),TimeRemainingColumn(),TimeElapsedColumn()) as progress:epoch_tqdm = progress.add_task(description="epoch progress", total=num_epochs)for epoch in range(num_epochs):train_D_loss, train_F_loss, train_acc = train_epoch(source_dataloader, target_dataloader, progress, lamb=0.6)progress.advance(epoch_tqdm, advance=1)if epoch == 10:torch.save(feature_extractor.state_dict(), f'extractor_model_early.bin')torch.save(label_predictor.state_dict(), f'predictor_model_early.bin')elif epoch == 100:torch.save(feature_extractor.state_dict(), f'extractor_model_mid.bin')torch.save(label_predictor.state_dict(), f'predictor_model_mid.bin')torch.save(feature_extractor.state_dict(), f'extractor_model.bin')torch.save(label_predictor.state_dict(), f'predictor_model.bin')print('epoch {:>3d}: train D loss: {:6.4f}, train F loss: {:6.4f}, acc {:6.4f}'.format(epoch, train_D_loss, train_F_loss, train_acc))
2.3 Strong Baseline
助教建议了几篇论文来提升性能并通过strong baseline。其中,我发现以下这篇论文特别有趣:《Minimum Class Confusion for Versatile Domain Adaptation》(Jin, Ying, et al.)(链接)。
他们“提出了一种新颖的损失函数:Minimum Class Confusion(MCC)。它可以被描述为一种新颖且多功能的领域适配方法,无需显式进行领域对齐,且具有较快的收敛速度。此外,它还可以作为一种通用正则化器,与现有的领域适配方法正交且互补,从而进一步加速和改善这些已有的竞争性方法。”(Jin, Ying, et al.,p. 3)

MCC 的计算过程如下:
给定以下变量:
-
:网络输出的目标领域数据的logits(即网络分类器的输出)。
-
:一个温度参数,用于缩放logits,使其更加平滑并增大类别分布之间的差异。
-
:目标领域经温度平滑后的预测结果,表示通过softmax得到的概率分布。
-
:熵函数,用于衡量每个样本的预测不确定性。
MCC步骤1:目标领域logits的温度缩放:
目标领域的logits 通过温度进行缩放,以平滑分类概率:
其中, 用于拉伸预测的概率分布,防止模型过于自信。
MCC步骤2:计算Softmax输出:
将经过温度缩放的logits通过softmax函数得到目标领域预测的概率分布 :
此处, 是一个
的矩阵,其中
是目标领域样本的数量,
是分类的类别数。
MCC步骤3:计算样本熵权重:
每个样本的熵 使用以下公式计算:
相关文章:
Domain Adaptation(李宏毅)机器学习 2023 Spring HW11 (Boss Baseline)
1. 领域适配简介 领域适配是一种迁移学习方法,适用于源领域和目标领域数据分布不同但学习任务相同的情况。具体而言,我们在源领域(通常有大量标注数据)训练一个模型,并希望将其应用于目标领域(通常只有少量或没有标注数据)。然而,由于这两个领域的数据分布不同,模型在…...

在php中,Fiber、Swoole、Swow这3个协程都是如何并行运行的?
文章精选推荐 1 JetBrains Ai assistant 编程工具让你的工作效率翻倍 2 Extra Icons:JetBrains IDE的图标增强神器 3 IDEA插件推荐-SequenceDiagram,自动生成时序图 4 BashSupport Pro 这个ides插件主要是用来干嘛的 ? 5 IDEA必装的插件&…...

SQLite PRAGMA
SQLite的PRAGMA命令是一种特殊的命令,用于在SQLite环境中控制各种环境变量和状态标志。PRAGMA值可以被读取,也可以根据需求进行设置【0†source】。 PRAGMA命令的语法格式如下: 要查询当前的PRAGMA值,只需提供该PRAGMA的名字&am…...

使用python调用JIRA6 REST API及遇到的问题
JIRA认证方式简述 JIRA接口调用有两种认证方式访问Jira Rest API,基本认证⽅式(⽤户名和密码)和OAuth1认证方式。 基本认证⽅式:因为⽤户名和密码会被浏览器重复地请求和发送,即使采⽤ SSL/TLS 发送,也会有安全隐患,…...

基于STM32的智能电表可视化设计:ESP8266、AT指令集、python后端Flask(代码示例)
一、项目概述 随着智能家居的普及,智能电表作为家庭用电管理的重要工具,能够实时监测电流、电压及功率,并将数据传输至后台进行分析和可视化。本项目以STM32C8T6为核心,结合交流电压电流监测模块、ESP8266 Wi-Fi模块、OLED显示屏…...

图片和短信验证码(头条项目-06)
1 图形验证码接口设计 将后端⽣成的图⽚验证码存储在redis数据库2号库。 结构: {img_uuid:0594} 1.1 创建验证码⼦应⽤ $ cd apps $ python ../../manage.py startapp verifications # 注册新应⽤ INSTALLED_APPS [django.contrib.admin,django.contrib.auth,…...

2501,wtl显示html
原文 在MFC程序中有专门封装的CHTMLView来显示超文本文件,如果在对话框中显示网页可用CDHTMLDialog,甚至可实现多页超文本向导风格的对话框,但是在WTL中却没有单独封装超文本的对应控件,这是因为COM组件的使用和编写本来就是ATL的强项,WTL扩展的是ATL欠缺的桌面应用的功能部分…...

嵌入式C语言:什么是指针?
目录 一、指针的基本概念 1.1. 定义指针 1.2. 赋值给指针 1.3. 解引用指针 1.4. 指针运算 1.5. 空指针 1.6. 函数参数 1.7. 数组和指针 1.8. 示例代码 二、指针在内存中的表示 2.1. 内存地址存储 2.2. 内存模型 2.3. 指针与硬件交互 2.4. 示例代码 三 、指针的重…...

解锁 KaiwuDB 数据库工程师,开启进阶之路
解锁 KaiwuDB 数据库工程师试题,开启进阶之路 一、KaiwuDB 数据库全方位洞察 (一)核心特性深度解析 原生分布式架构:摒弃传统集中式存储的局限,KaiwuDB 采用原生分布式架构,将数据分散存于多个节点。这不仅能有效避免单点故障风险,保障数据的高可用性,还能凭借并行处…...

ffmpeg7.0 aac转pcm
#pragma once #define __STDC_CONSTANT_MACROS #define _CRT_SECURE_NO_WARNINGSextern "C" { #include "libavcodec/avcodec.h" }//缓冲区大小(缓存5帧数据) #define AUDIO_INBUF_SIZE 40960 /*name depthu8 8s16 …...

【Pandas】pandas Series rdiv
Pandas2.2 Series Binary operator functions 方法描述Series.add()用于对两个 Series 进行逐元素加法运算Series.sub()用于对两个 Series 进行逐元素减法运算Series.mul()用于对两个 Series 进行逐元素乘法运算Series.div()用于对两个 Series 进行逐元素除法运算Series.true…...

线程安全问题介绍
文章目录 **什么是线程安全?****为什么会出现线程安全问题?****线程安全问题的常见场景****如何解决线程安全问题?**1. **使用锁**2. **使用线程安全的数据结构**3. **原子操作**4. **使用volatile关键字**5. **线程本地存储**6. **避免死锁*…...

为AI聊天工具添加一个知识系统 之27 支持边缘计算设备的资源存储库及管理器
本文问题 现在我们回到 ONE/TWO/TREE 的资源存储库 的设计--用来指导 足以 支持 本项目(为AI聊天工具增加一套知识系统)的 核心能力 “语言处理” 中 最高难度系数的“自然语言处理” 中最具挑战性的“含糊性” 问题的解决。--因为足以解决 自然语言中最…...

初识verilog HDL
为什么选择用Verilog HDL开发FPGA??? 硬件描述语言(Hardware Descriptipon Lagnuage,HDL)通过硬件的方式来产生与之对应的真实的硬件电路,最终实现所设计的预期功能,其设计方法与软件…...
VS2015 + OpenCV + OnnxRuntime-Cpp + YOLOv8 部署
近期有个工作需求是进行 YOLOv8 模型的 C 部署,部署环境如下 系统:WindowsIDE:VS2015语言:COpenCV 4.5.0OnnxRuntime 1.15.1 0. 预训练模型保存为 .onnx 格式 假设已经有使用 ultralytics 库训练并保存为 .pt 格式的 YOLOv8 模型…...
Notepad++上NppFTP插件的安装和使用教程
一、NppFTP插件下载 图示是已经安装好了插件。 在搜索框里面搜NppFTP,一般情况下,自带的下载地址容易下载失败。这里准备了一个下载连接:Release v0.29.10 ashkulz/NppFTP GitHub 这里我下载的是x86版本 下载好后在nodepad的插件里面选择打…...

Kotlin | Android Provider 的实现案例
目标 使用 Android Room 实现持久化库。 代码 Kotlin 代码编写 DemoDatabase,在build生成 DemoDatabase_Impl 疑问 Provider的数据会存在设备吗? 内部存储: 当使用 Room 创建数据库(如 DemoDatabase),数据库文件通常…...

频域自适应空洞卷积FADC详解
定义与原理 在探讨FADC的核心策略之前,我们需要深入了解其定义和工作原理。FADC是一种创新性的卷积技术,旨在克服传统空洞卷积的局限性。其核心思想是从 频谱分析的角度 改进空洞卷积,通过 动态调整膨胀率 来平衡有效带宽和感受野大小。 FADC的工作原理可以从以下几个方面…...
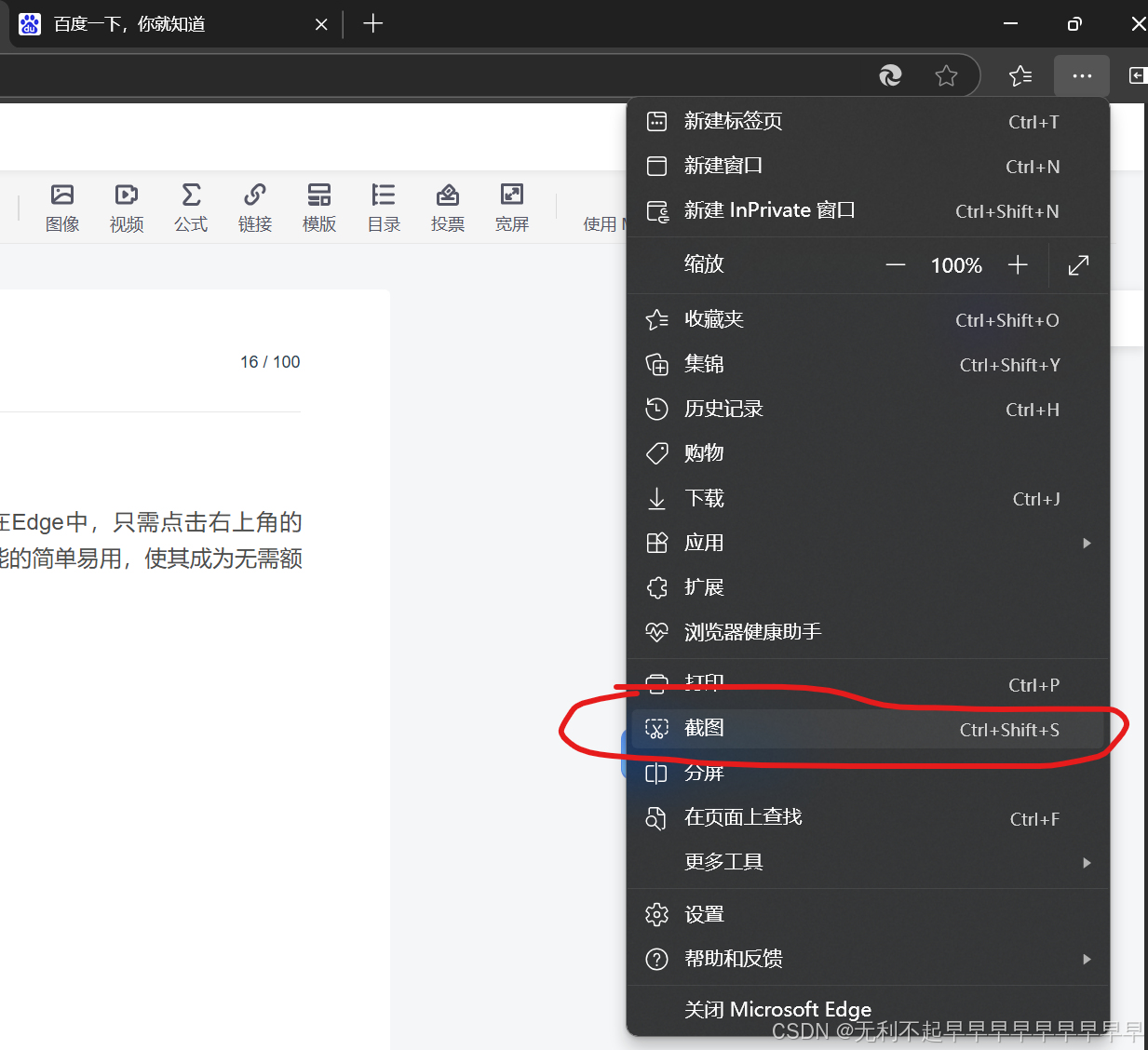
Edge浏览器内置的截长图功能
Edge浏览器内置截图功能 近年来,Edge浏览器不断更新和完善,也提供了长截图功能。在Edge中,只需点击右上角的“...”,然后选择“网页捕获”->“捕获整页”,即可实现长截图。这一功能的简单易用,使其成为…...

GAN的应用
5、GAN的应用 GANs是一个强大的生成模型,它可以使用随机向量生成逼真的样本。我们既不需要知道明确的真实数据分布,也不需要任何数学假设。这些优点使得GANs被广泛应用于图像处理、计算机视觉、序列数据等领域。上图是基于GANs的实际应用场景对不同G…...

ARM指令追踪技术及TRCVICTLR寄存器详解
1. ARM指令追踪技术概述在嵌入式系统开发和调试过程中,指令追踪(Instruction Trace)是一项至关重要的技术。它通过硬件机制记录处理器的执行流程,为开发者提供程序运行的完整轨迹。ARM架构从v7开始引入嵌入式跟踪宏单元࿰…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

神经网络与深度学习 第3周课程总结
深度学习视觉应用课程总结 一、常用计算机视觉数据集数据集名称发布方/年份规模图像规格类别数主要用途核心特点MNIST美国国家标准与技术研究院60k训练10k测试2828灰度图10类(0-9手写数字)入门级图像分类最经典的手写数字识别基准数据集Fashion-MNISTZalando(2017)60k训练10k测…...

WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案
WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案 【免费下载链接】wtfautolayout The source code for Why The Failure, Auto Layout? 项目地址: https://gitcode.com/gh_mirrors/wt/wtfautolayout 在iOS开发中,Auto Layout是构建灵…...

真可用!美团数字人模型开源,MV、电商等统统拿下
美团开源的数字人视频生成框架 LongCat-Video-Avatar 刚刚更新到 1.5 版本。是真能用。这版更新把音频编码器换了,推理步数砍到8步,在770人、13240条主观评分的大规模评测里,雷达图面积全面领先。音频编码器换血,8步出图LongCat-V…...

零基础怎么学Agent?这个工程师考试内容拆给你看
站在 AI Agent(智能体)爆发的十字路口,很多既没有深厚算法背景、也没有丰富写代码经验的“小白”常常感到迷茫:动辄谈及的大模型交互、复杂的业务编排,零基础真的能学会吗? 事实上,智能体开发早…...

昇腾NPU模型服务化——从离线模型到高可用推理服务
模型训练完只是第一步。真正产生业务价值的是把模型部署成724小时在线服务——毫秒级延迟、支持动态Batching、能扛住流量洪峰,且具备高可用性。 这篇将手把手教你基于昇腾NPU构建生产级模型推理服务,涵盖框架选型、服务化架构、动态Batching优化、热加载…...

观察不同模型在统一 API 下的响应速度与输出风格差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在统一 API 下的响应速度与输出风格差异 在为大语言模型应用选择模型时,开发者通常会关注两个核心维度&am…...

3步开启Windows 11安卓应用新体验:WSA完整使用指南
3步开启Windows 11安卓应用新体验:WSA完整使用指南 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem for Android(简…...

终极Obsidian笔记模板指南:如何用kepano-obsidian构建你的第二大脑
终极Obsidian笔记模板指南:如何用kepano-obsidian构建你的第二大脑 【免费下载链接】kepano-obsidian My personal Obsidian vault template. A bottom-up approach to note-taking and organizing things I am interested in. 项目地址: https://gitcode.com/gh_…...