Autoencoder(李宏毅)机器学习 2023 Spring HW8 (Boss Baseline)

1. Autoencoder 简介
Autoencoder是一种用于学习数据高效压缩表示的人工神经网络。它由两个主要部分组成:
Encoder
-
编码器将输入数据映射到一个更小的、低维空间中的压缩表示,这个空间通常称为latent space或bottleneck。
-
这一过程可以看作是数据压缩,去除冗余信息,仅保留最重要的特征。
Decoder
-
解码器从潜在表示中重构原始输入数据。
-
理想情况下,解码器的输出应尽可能接近原始输入。

2. Autoencoder的种类
2.1 Vanilla Autoencoder

vanilla autoencoder是最简单形式的自动编码器,旨在通过瓶颈层尽可能准确地重构输入数据。它是更高级自动编码器变体的基础。
Vanilla autoencoder的训练目标是最小化输入 和输出
之间的重构损失. 常见的损失函数包括:
均方误差(MSE):适用于连续数据。
二元交叉熵损失(Binary Cross-Entropy Loss): 适用于二元数据。
2.2 Denoising Autoencoder

Denoising autoencoder (DAE) 是一种自动编码器变体,它专门训练从受损(有噪声)的输入中重构干净的输入数据。这使其成为学习有意义特征和执行数据去噪任务的强大工具。
原始输入数据通过添加噪声或引入干扰被人为破坏,生成带噪输入。常见的破坏类型包括:
-
高斯噪声:在输入数据中添加随机噪声。
-
椒盐噪声:随机翻转图像中的像素值。
-
遮掩噪声:将输入的随机部分设为零。
-
随机失活噪声:随机丢弃部分特征。
与基础型自动编码器类似,常用的损失函数包括均方误差(MSE)和二元交叉熵损失(Binary Cross-Entropy Loss)。
2.3 变分自动编码器 Variational Autoencoder (VAE)

变分自动编码器(VAE)是一种用于学习数据概率表示的自动编码器。与标准自动编码器将数据编码为固定的潜在表示不同,VAE 将数据编码为潜在空间中的一个分布(通常是高斯分布)。这使得 VAE 在生成任务中尤其有用。
VAE 的三个主要组成部分:
编码器(Encoder)
-
编码器将输入数据
映射到潜在分布
.。
-
对于每个潜在变量,编码器输出两个参数:
-
均值(
)
-
标准差(
)
-
潜在空间(Latent Space)
-
表示输入数据的压缩概率分布。
-
潜在空间中的变量
通过以下公式采样:
其中
。这种操作称为重参数化技巧(reparameterization trick),它允许通过随机采样过程进行反向传播。
解码器(Decoder)
-
解码器将潜在变量
。
-
它尝试从潜在表示中重构输入数据
。
2.3.1 损失函数
VAE 的损失函数由两部分组成:
重构损失
-
它衡量重构数据与原始数据的匹配程度。
-
我们通常使用二元交叉熵或均方误差。
KL 散度
-
它使潜在空间分布
, 通常是标准高斯分布
.
-
定义为:
该项正则化潜在空间,确保插值平滑且具有意义。
总损失公式为:
2.3.2 证据下界 Evidence Lower Bound (ELBO)
在变分自动编码器(VAE)中,核心目标是最大化输入数据的边际似然 ,即尽可能解释数据。为此,一个重要的数学工具是证据下界(ELBO)。
2.3.2.1 什么是 ELBO?
ELBO 是通过变分推断近似数据边际似然
相关文章:
Autoencoder(李宏毅)机器学习 2023 Spring HW8 (Boss Baseline)
1. Autoencoder 简介 Autoencoder是一种用于学习数据高效压缩表示的人工神经网络。它由两个主要部分组成: Encoder 编码器将输入数据映射到一个更小的、低维空间中的压缩表示,这个空间通常称为latent space或bottleneck。 这一过程可以看作是数据压缩,去除冗余信息,仅保留…...

深入探索 ScottPlot.WPF:在 Windows 桌面应用中绘制精美图表的利器
一、ScottPlot.WPF 简介 ScottPlot.WPF 是基于 ScottPlot 绘图库专门为 Windows Presentation Foundation (WPF) 框架量身定制的强大绘图组件。它无缝集成到 WPF 应用程序中,为开发者提供了一种简洁、高效的方式来可视化数据,无论是科学研究中的实验数据展示、金融领域的行情…...

React中的useMemo 和 useEffect 哪个先执行?
在 React 组件的渲染过程中,useMemo 和 useEffect 的执行顺序是不同的。具体来说: useMemo 先执行:useMemo 是在 渲染阶段 执行的,它的作用是缓存计算结果,确保在渲染过程中可以直接使用缓存的值。 useEffect 后执行&…...
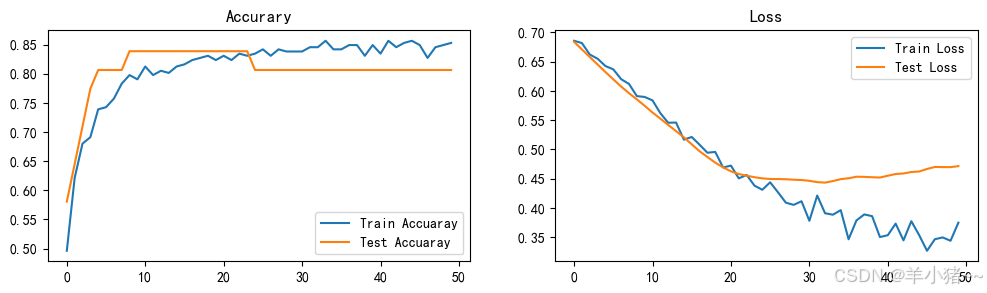
错误修改系列---基于RNN模型的心脏病预测(pytorch实现)
前言 前几天发布了pytorch实现,TensorFlow实现为:基于RNN模型的心脏病预测(tensorflow实现),但是一处繁琐地方 一处错误,这篇文章进行修改,修改效果还是好了不少;源文章为:基于RNN模型的心脏病…...
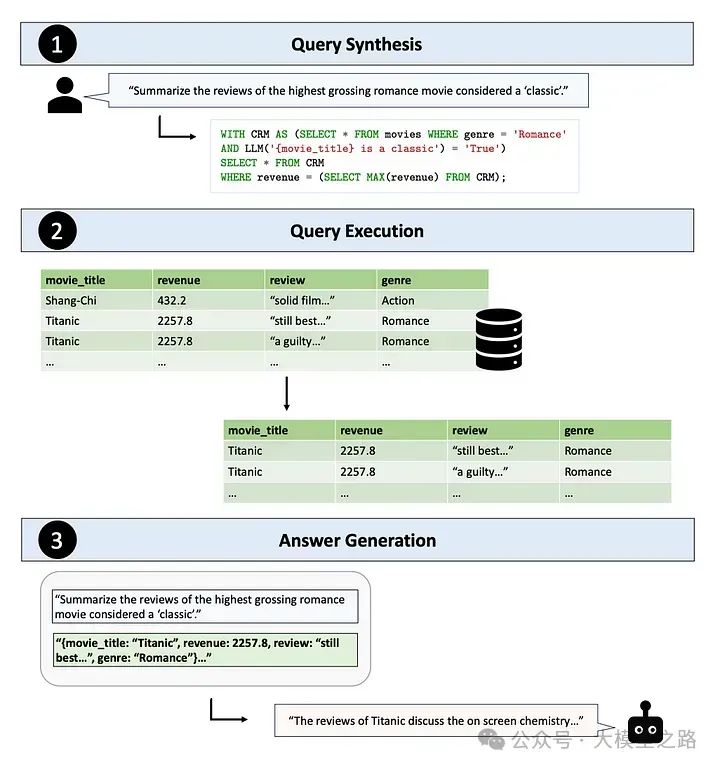
Table-Augmented Generation(TAG):Text2SQL与RAG的升级与超越
当下AI与数据库的融合已成为推动数据管理和分析领域发展的重要力量。传统的数据库查询方式,如结构化查询语言(SQL),要求用户具备专业的数据库知识,这无疑限制了非专业人士对数据的访问和利用。为了打破这一壁垒&#x…...
)
Stable Diffusion本地部署教程(附安装包)
想使用Stable Diffusion需要的环境有哪些呢? python3.10.11(至少也得3.10.6以上):依赖python环境NVIDIA:GPUgit:从github上下载包(可选,由于我已提供安装包,你可以不用git)Stable Diffusion安装包工具包: NVIDIA:https://developer.nvidia.com/cuda-toolkit-archiv…...

【物联网原理与运用】知识点总结(上)
目录 名词解释汇总 第一章 物联网概述 1.1物联网的基本概念及演进 1.2 物联网的内涵 1.3 物联网的特性——泛在性 1.4 物联网的基本特征与属性(五大功能域) 1.5 物联网的体系结构 1.6 物联网的关键技术 1.7 物联网的应用领域 第二章 感知与识别技术 2.1 …...
JuiceFS 2024:开源与商业并进,迈向 AI 原生时代
即将过去的 2024 年,是 JuiceFS 开源版本推出的第 4 年,企业版的第 8 个年头。回顾过去这一年,JuiceFS 社区版依旧保持着快速成长的势头,GitHub 星标突破 11.1K,各项使用指标增长均超过 100%,其中文件系统总…...

C#,动态规划问题中基于单词搜索树(Trie Tree)的单词断句分词( Word Breaker)算法与源代码
1 分词 分词是自然语言处理的基础,分词准确度直接决定了后面的词性标注、句法分析、词向量以及文本分析的质量。英文语句使用空格将单词进行分隔,除了某些特定词,如how many,New York等外,大部分情况下不需要考虑分词…...

计算机网络(六)应用层
6.1、应用层概述 我们在浏览器的地址中输入某个网站的域名后,就可以访问该网站的内容,这个就是万维网WWW应用,其相关的应用层协议为超文本传送协议HTTP 用户在浏览器地址栏中输入的是“见名知意”的域名,而TCP/IP的网际层使用IP地…...

上海亚商投顾:沪指探底回升微涨 机器人概念股午后爆发
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 市场全天探底回升,沪指盘中跌超1.6%,创业板指一度跌逾3%,午后集体拉升翻红…...

conda相关操作
conda 是一个开源的包管理和环境管理工具,主要用于 Python 和数据科学领域。它可以帮助用户安装、更新、删除和管理软件包,同时支持创建和管理虚拟环境。以下是关于 conda 的所有常见操作: 1. 安装 Conda Conda 通常通过安装 Anaconda 或 Mi…...
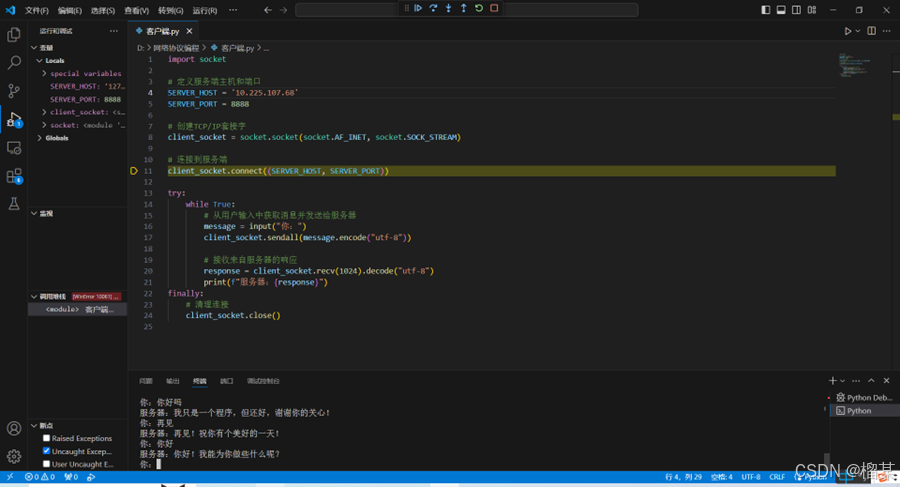
使用TCP协议实现智能聊天机器人
实验目的与要求 本实验是程序设计类实验,要求使用原始套接字编程,掌握TCP/IP协议与网络编程Sockets通信模型,并根据教师给定的任务要求,使用TCP协议实现智能聊天机器人。 (1)熟悉标准库socket 的用法。 …...

PHP二维数组去除重复值
Date: 2025.01.07 20:45:01 author: lijianzhan PHP二维数组内根据ID或者名称去除重复值 代码示例如下: // 假设 data数组如下 $data [[id > 1, name > Type A],[id > 2, name > Type B],[id > 1, name > Type A] // 重复项 ];// 去重方法 $dat…...

2025年01月11日Github流行趋势
项目名称:xiaozhi-esp32 项目地址url:https://github.com/78/xiaozhi-esp32项目语言:C历史star数:2433今日star数:321项目维护者:78, MakerM0, whble, nooodles2023, Kevincoooool项目简介:构建…...

备战蓝桥杯 队列和queue详解
目录 队列的概念 队列的静态实现 总代码 stl的queue 队列算法题 1.队列模板题 2.机器翻译 3.海港 双端队列 队列的概念 和栈一样,队列也是一种访问受限的线性表,它只能在表头位置删除,在表尾位置插入,队列是先进先出&…...

IT面试求职系列主题-Jenkins
想成功求职,必要的IT技能一样不能少,先说说Jenkins的必会知识吧。 1) 什么是Jenkins Jenkins 是一个用 Java 编写的开源持续集成工具。它跟踪版本控制系统,并在发生更改时启动和监视构建系统。 2)Maven、Ant和Jenkins有什么区别…...
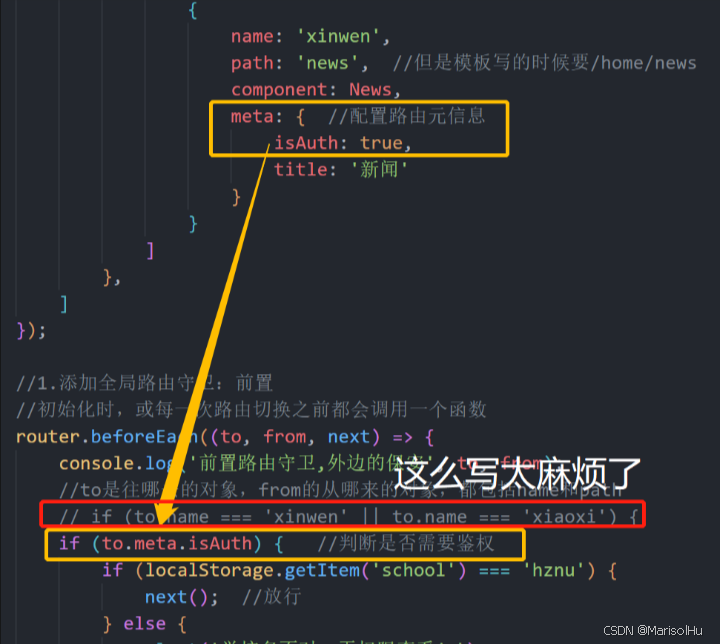
Vue篇-06
1、路由简介 vue-rooter:是vue的一个插件库,专门用来实现SPA应用 1.1、对SPA应用的理解 1、单页 Web 应用(single page web application,SPA)。 2、整个应用只有一个完整的页面 index.html。 3、点击页面中的导航链…...

mysql binlog 日志分析查找
文章目录 前言一、分析 binlog 内容二、编写脚本结果总结 前言 高效快捷分析 mysql binlog 日志文件。 mysql binlog 文件很大 怎么快速通过关键字查找内容 一、分析 binlog 内容 通过 mysqlbinlog 命令可以看到 binlog 解析之后的大概样子 二、编写脚本 编写脚本 search_…...

ubuntu 配置OpenOCD与RT-RT-thread环境的记录
1.git clone git://git.code.sf.net/p/openocd/code openocd 配置gcc编译环境 2. sudo gedit /etc/apt/source.list #cdrom sudo apt-get install git sudo apt-get install libtool-bin sudo apt-get install pkg-config sudo apt-install libusb-1.0-0-dev sudo apt-get…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

5A智慧景区建设|对标一流!巨有科技打造数智化标杆景区
5A级景区是中国旅游的最高标准,代表着服务与管理的顶尖水平。随着5A评审标准日益严苛,“智慧化”已成为核心硬性指标。然而,不少景区的智慧化建设陷入“重硬件、轻整合”的误区,系统林立、数据孤岛,投入巨大却效果不佳…...

掌握Umi-OCR:5分钟上手开源免费离线文字识别工具
掌握Umi-OCR:5分钟上手开源免费离线文字识别工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。…...

机器学习的最佳实践:这7个原则让你的模型更稳定
对于软件测试从业者而言,机器学习技术正在快速融入测试流程:从自动化测试用例生成、缺陷预测到测试环境异常检测,机器学习模型的稳定性直接决定了测试结果的可靠性——如果模型在测试环境波动、输入数据变化时性能骤降,不仅无法提…...

收藏|2026年大模型算法岗崛起!程序员小白入门高薪赛道全攻略
前些年,算法岗位一直稳居技术圈高薪行列,无数程序员争相入局,也成为计算机专业毕业生求职首选方向。 伴随大模型技术飞速迭代落地,行业就业格局迎来重大变革。如今含金量最高、人才缺口最大、长期发展潜力顶尖的岗位,已…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...

避坑指南:Unity动态加载模型时,TriLib插件材质丢失、缩放异常的5个常见问题解决
Unity动态加载模型避坑指南:TriLib插件材质丢失与缩放异常的深度解决方案当你在Unity项目中尝试使用TriLib插件动态加载外部模型时,是否遇到过这些令人抓狂的情况:模型加载后材质全部变成刺眼的粉红色,贴图神秘消失,或…...