Python Selenium库入门使用,图文详细。附网页爬虫、web自动化操作等实战操作。
文章目录
- 前言
- 1 创建conda环境安装Selenium库
- 2 浏览器驱动下载(以Chrome和Edge为例)
- 3 基础使用(以Chrome为例演示)
- 3.1 与浏览器相关的操作
- 3.1.1 打开/关闭浏览器
- 3.1.2 访问指定域名的网页
- 3.1.3 控制浏览器的窗口大小
- 3.1.4 前进/后退/刷新页面
- 3.1.5 获取网页基本信息
- 3.1.6 打开新窗口、窗口切换
- 3.1.7 其他设置(隐藏窗口、禁用GPU加速、禁用沙盒、禁用共享内存)
- 3.2 定位并访问、操作网页元素
- 3.2.1 通过XPath定位网页元素(CSDN首页为例)
- 3.2.2 点击元素
- 3.2.3 清空输入框、输入文本
- 3.2.4 获取元素信息(文本、属性、标签名、大小、位置、是否显示、是否启用)
- 3.2.5 对元素执行鼠标操作(悬停、左键点击、右键点击、双击)
- 3.2.6 对元素执行键盘操作(输入字母、空格、制表符、回车、Ctrl+...)
- 3.3 滚轮操作
- 3.4 延时等待
- 4 实战
- 4.1 实战一:自动化搜索并统计打印结果
- 4.2 实战二:知网论文信息查询
前言
- 本文介绍Windows系统下Python的Selenium库的使用,并且附带网页爬虫、web自动化操作等实战教程,图文详细,内容全面。如有错误欢迎指正,有相关问题欢迎评论私信交流。
- 什么是Selenium库:Selenium是一个用于Web应用程序测试和网页爬虫的自动化测试工具。它可以驱动浏览器执行特定的行为,模拟真实用户操作网页的场景。
- Selenium的常见用途:
- 网络爬虫:从动态网页获取信息、采集社交平台的公开信息等,并通过程序自动处理保存。
- 自动化操作:自动完成重复的表单输入、验证网站各项功能是否正常运行、验证不同浏览器的表现等
- 官方教程文档:官方教程文档
1 创建conda环境安装Selenium库
- conda创建一个新的python环境:
conda create -n selenium python=3.11
- 激活创建的python环境:
conda activate selenium
- 安装selenium:
pip install selenium
2 浏览器驱动下载(以Chrome和Edge为例)
- 驱动的作用:驱动充当Selenium代码和浏览器之间的翻译器,其提供了统一的接口来控制不同的浏览器
- Selenium程序、驱动、浏览器之间的关系
Selenium程序 → 浏览器驱动 → 浏览器↑ ↑ ↑
发送命令 → 转换命令 → 执行操作↓ ↓ ↓
接收结果 ← 转换结果 ← 返回结果
- 下载Chrome浏览器驱动:
- 查看Chrome版本信息(打开Chrome浏览器 → 点击右上角三个点 → 设置 → 关于Chrome):


我这里版本是131.0.6778.265(正式版本) - 进入下载页面,选择与Chrome版本最接近的驱动版本复制链接进行下载:
选择与Chrome版本最接近的驱动版本,复制操作系统对应的驱动的链接

在浏览器地址栏输入上述链接回车,浏览器会自动下载驱动

下载完成会得到这样一个压缩文件,这里面就是驱动:

解压压缩包得到这样三个文件,记住驱动文件夹的位置:

- 查看Chrome版本信息(打开Chrome浏览器 → 点击右上角三个点 → 设置 → 关于Chrome):
- 下载Edge浏览器驱动
-
查看Edge版本信息(打开Edge浏览器 → 点击右上角三个点 → 设置 → 关于Microsoft Edge):


我这儿版本是131.0.2903.146 -
进入下载页面,选择与Edge版本最接近的版本点击对应的下载按钮即可:

得到如下压缩包:

解压后得到如下文件,记住驱动的位置:

-
3 基础使用(以Chrome为例演示)
3.1 与浏览器相关的操作
3.1.1 打开/关闭浏览器
- webdriver.Chrome():初始化并打开浏览器
- quit():关闭浏览器
# 导入必要的库
from selenium import webdriver # Selenium的核心包
from selenium.webdriver.chrome.service import Service # Chrome驱动服务类# 设置ChromeDriver路径
# driver_path指定了ChromeDriver可执行文件的本地路径
# Service类用于创建ChromeDriver服务实例
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化Chrome浏览器
# webdriver.Chrome()会启动一个新的Chrome浏览器实例
# service参数告诉Selenium使用哪个ChromeDriver服务
browser = webdriver.Chrome(service=service)# 关闭浏览器
# quit()方法会完全关闭浏览器及其所有相关进程
browser.quit()
3.1.2 访问指定域名的网页
- get():打开网页
# 导入和初始化部分与3.1相同
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Servicedriver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)
browser = webdriver.Chrome(service=service)# 使用get()方法访问指定URL
# get()方法会等待页面加载完成后才继续执行后续代码
browser.get("https://www.baidu.com")# time.sleep()添加延时
# 程序会在此处暂停5秒,方便观察页面加载情况
# 注意:在实际项目中应该使用显式等待或隐式等待替代sleep
time.sleep(5)# 关闭浏览器
browser.quit()
3.1.3 控制浏览器的窗口大小
- set_window_size():设置窗口的固定长宽
- maximize_window():最大化窗口
- minimize_window():最小化窗口
- fullscreen_window():全屏显示窗口
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)# 打开百度
browser.get("https://www.baidu.com")# 方法1:设置固定大小
browser.set_window_size(800, 600) # 设置为800x600像素
time.sleep(2) # 等待2秒观察效果# 方法2:最大化窗口
browser.maximize_window()
time.sleep(2)# 方法3:最小化窗口
browser.minimize_window()
time.sleep(2)# 方法4:全屏显示
browser.fullscreen_window()
time.sleep(2)# 获取当前窗口大小
window_size = browser.get_window_size()
print(f"当前窗口大小:宽度={window_size['width']}px,高度={window_size['height']}px")# 关闭浏览器
browser.quit()
3.1.4 前进/后退/刷新页面
- back():后退
- forward():前进
- refresh():刷新
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)# 访问第一个页面:百度
browser.get("https://www.baidu.com")
time.sleep(2) # 等待页面加载# 访问第二个页面:必应
browser.get("https://www.bing.com")
time.sleep(2)# 后退到百度
browser.back()
time.sleep(2)
print("当前页面标题:", browser.title) # 显示当前页面标题,验证是否回到百度# 前进到必应
browser.forward()
time.sleep(2)
print("当前页面标题:", browser.title) # 显示当前页面标题,验证是否前进到必应# 刷新当前页面
browser.refresh()
time.sleep(2)# 关闭浏览器
browser.quit()
3.1.5 获取网页基本信息
- title():获取网页标题
- current_url():获取当前网址
- name():获取浏览器名称
- page_source():获取页面源码
- window_handles():获取所有窗口句柄
- current_window_handle():获取当前窗口句柄
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)# 访问百度
browser.get("https://www.baidu.com")
time.sleep(2) # 等待页面加载# 1. 获取网页标题
title = browser.title
print("网页标题:", title)# 2. 获取当前网址
current_url = browser.current_url
print("当前网址:", current_url)# 3. 获取浏览器名称
browser_name = browser.name
print("浏览器名称:", browser_name)# 4. 获取页面源码(前50个字符)
page_source = browser.page_source
print("页面源码(前50个字符):", page_source[:50])# 5. 获取当前窗口句柄
current_handle = browser.current_window_handle
print("当前窗口句柄:", current_handle)# 6. 获取所有窗口句柄
all_handles = browser.window_handles
print("所有窗口句柄:", all_handles)# 7. 获取浏览器的能力(capabilities)
capabilities = browser.capabilities
print("浏览器版本:", capabilities.get('browserVersion', 'Unknown'))
print("浏览器名称:", capabilities.get('browserName', 'Unknown'))
print("平台名称:", capabilities.get('platformName', 'Unknown'))# 关闭浏览器
browser.quit()
3.1.6 打开新窗口、窗口切换
在Selenium中,我们可以通过以下方法实现窗口切换:
- window_handles:获取所有窗口句柄
- current_window_handle:获取当前窗口句柄
- switch_to.window():切换到指定窗口
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import time# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.baidu.com")try:# 1. 获取初始窗口句柄main_window = browser.current_window_handleprint("主窗口句柄:", main_window)# 2. 打开新窗口(点击链接在新窗口打开)browser.execute_script("window.open('https://www.bing.com', '_blank');")time.sleep(2)# 3. 获取所有窗口句柄all_handles = browser.window_handlesprint("所有窗口句柄:", all_handles)# 4. 切换到新窗口(最后打开的窗口)browser.switch_to.window(all_handles[-1])print("当前页面标题:", browser.title) # 应显示必应的标题time.sleep(2)# 5. 切回主窗口browser.switch_to.window(main_window)print("切回主窗口,当前页面标题:", browser.title) # 应显示百度的标题time.sleep(2)# 6. 遍历所有窗口示例print("\n遍历所有窗口:")for handle in all_handles:browser.switch_to.window(handle)print(f"窗口句柄: {handle}")print(f"页面标题: {browser.title}")print(f"当前URL: {browser.current_url}")print("---")time.sleep(1)except Exception as e:print(f"发生错误: {e}")finally:browser.quit()

3.1.7 其他设置(隐藏窗口、禁用GPU加速、禁用沙盒、禁用共享内存)
- add_argument():添加一些其他设置选项。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options # 导入 Options# 配置无头浏览器、禁用GPU加速、禁用沙盒、禁用共享内存
chrome_options = Options()
chrome_options.add_argument('--headless') # 启用无头模式
chrome_options.add_argument('--disable-gpu') # 禁用GPU加速
chrome_options.add_argument('--no-sandbox') # 禁用沙盒
chrome_options.add_argument('--disable-dev-shm-usage') # 禁用共享内存# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器时传入配置
browser = webdriver.Chrome(service=service, options=chrome_options)try:# 设置隐式等待时间browser.implicitly_wait(10)# 打开必应搜索页面browser.get("https://www.bing.com")print("已打开必应搜索页面")except Exception as e:print(f"发生错误: {e}")finally:browser.quit()print("浏览器已关闭")
3.2 定位并访问、操作网页元素
- 网页元素是构成网页的基本组成部分,是HTML文档中的各种标签所创建的对象。在自动化测试和网页操作中,我们需要定位元素以便进行交互操作,获取其相关信息。
- Selenium定位网页元素的方法:
- ID定位:find_element(By.ID, “element-id”)
- 名称定位:find_element(By.NAME, “element-name”)
- 类名定位:find_element(By.CLASS_NAME, “class-name”)
- 标签名定位:find_element(By.TAG_NAME, “tag-name”)
- XPath定位:find_element(By.XPATH, “//xpath-expression”)
- CSS选择器定位:find_element(By.CSS_SELECTOR, “css-selector”)
- 链接文本定位:find_element(By.LINK_TEXT, “link-text”)
- 部分链接文本定位:find_element(By.PARTIAL_LINK_TEXT, “partial-text”)
3.2.1 通过XPath定位网页元素(CSDN首页为例)
XPath是一种在XML和HTML文档中查找元素的强大语言,其结合浏览器不用去看网页源码就能很方便的定位网页元素。
-
首先通过浏览器打开需要定位的元素所在的网页:

-
按F12进入开发者模式,点击图中开发者窗口左上角的图标,点击元素,这时鼠标滑过网页的每一个元素下面的源码都会快速定位到该元素的对应源码


-
这时我们把鼠标移动到需要定位的元素上面,点击鼠标左键,然后鼠标移动到该元素的源码部分,鼠标右键单击打开菜单,在菜单中选择复制-复制XPath(或者复制完整 XPath)即可得到该元素的XPath


-
有了元素的XPath,便可以通过selenium的find_element方法获取这个元素,随后对其进行交互操作、获取相关信息等。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Servicedef locate_search_button():# 设置 ChromeDriver 的路径driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"service = Service(driver_path)# 初始化 Chrome 浏览器并打开browser = webdriver.Chrome(service=service)browser.get("https://www.csdn.net/")# 通过xpath定位搜索按钮element = browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]/span')# 打印元素文本print("找到搜索按钮,文本内容:", element.text)# 关闭浏览器browser.quit()if __name__ == "__main__":locate_search_button()

3.2.2 点击元素
- click():点击元素
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try:# 定位并点击搜索按钮search_button = browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]')search_button.click()print("成功点击搜索按钮")except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2) # 等待2秒看效果browser.quit()

3.2.3 清空输入框、输入文本
- clear():清空输入框
- send_keys():输入文本
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try: # 定位搜索框search_input = browser.find_element(By.XPATH, '//*[@id="toolbar-search-input"]')# 清空输入框search_input.clear()# 输入文本search_input.send_keys("Python Selenium")print("成功输入文本")except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2) # 等待2秒看效果browser.quit()


3.2.4 获取元素信息(文本、属性、标签名、大小、位置、是否显示、是否启用)
- text():获取元素文本
- get_attribute():获取元素某些属性
- tag_name():获取元素标签名
- size():获取元素大小
- location():获取元素位置
- is_displayed():判断元素是否显示
- is_enabled():判断元素是否启用
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try:# 定位搜索按钮element = browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]')# 获取元素的各种属性print("元素文本:", element.text)print("class属性:", element.get_attribute("class"))print("标签名:", element.tag_name)print("元素大小:", element.size)print("元素位置:", element.location)print("是否显示:", element.is_displayed())print("是否启用:", element.is_enabled())except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2)browser.quit()

3.2.5 对元素执行鼠标操作(悬停、左键点击、右键点击、双击)
使用 ActionChains 类可以对元素执行以下鼠标操作:
- move_to_element():鼠标悬停
- click():鼠标左键点击
- context_click():鼠标右键点击
- double_click():鼠标双击
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.action_chains import ActionChains# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try:# 定位搜索按钮element = browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]')# 创建 ActionChains 对象actions = ActionChains(browser)# 鼠标悬停actions.move_to_element(element).perform()print("执行鼠标悬停")time.sleep(1)# 鼠标点击actions.click(element).perform()print("执行鼠标点击")time.sleep(1)# 鼠标右键actions.context_click(element).perform()print("执行鼠标右键")time.sleep(1)# 双击actions.double_click(element).perform()print("执行鼠标双击")except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2)browser.quit()

3.2.6 对元素执行键盘操作(输入字母、空格、制表符、回车、Ctrl+…)
使用 Keys 类可以执行以下键盘操作:
- send_keys():输入文本
- Keys.BACK_SPACE:退格键
- Keys.SPACE:空格键
- Keys.TAB:制表键
- Keys.ENTER/Keys.RETURN:回车键
- Keys.CONTROL + ‘a’:全选(Ctrl+A)
- Keys.CONTROL + ‘c’:复制(Ctrl+C)
- Keys.CONTROL + ‘v’:粘贴(Ctrl+V)
- Keys.CONTROL + ‘x’:剪切(Ctrl+X)
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try: # 定位搜索框search_input = browser.find_element(By.XPATH, '//*[@id="toolbar-search-input"]')# 1. 基本输入search_input.send_keys("Python")print("输入文本:Python")time.sleep(1)# 2. 空格search_input.send_keys(Keys.SPACE)search_input.send_keys("Selenium")print("输入空格和文本:Python Selenium")time.sleep(1)# 3. 全选文本 (Ctrl+A)actions = ActionChains(browser)actions.key_down(Keys.CONTROL).send_keys('a').key_up(Keys.CONTROL).perform()print("全选文本")time.sleep(1)# 4. 复制文本 (Ctrl+C)actions.key_down(Keys.CONTROL).send_keys('c').key_up(Keys.CONTROL).perform()print("复制文本")time.sleep(1)# 5. 删除文本(退格键)search_input.send_keys(Keys.BACK_SPACE)print("删除文本")time.sleep(1)# 6. 粘贴文本 (Ctrl+V)actions.key_down(Keys.CONTROL).send_keys('v').key_up(Keys.CONTROL).perform()print("粘贴文本")time.sleep(1)# 7. 制表键search_input.send_keys(Keys.TAB)print("按下Tab键")time.sleep(1)# 8. 回车搜索search_input.send_keys(Keys.RETURN)print("按下回车键执行搜索")except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2)browser.quit()

3.3 滚轮操作
- 最常用且最可靠的方法是使用 JavaScript 来控制滚动
- execute_script():执行JavaScript脚本
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try:# 1. 滚动到页面底部browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")print("滚动到页面底部")time.sleep(1)# 2. 滚动到页面顶部browser.execute_script("window.scrollTo(0, 0);")print("滚动到页面顶部")time.sleep(1)# 3. 向下滚动500像素browser.execute_script("window.scrollBy(0, 500);")print("向下滚动500像素")time.sleep(1)# 4. 使用 PageDown 键滚动actions = ActionChains(browser)actions.send_keys(Keys.PAGE_DOWN).perform()print("使用 PageDown 键滚动")time.sleep(1)# 5. 滚动到特定元素try:element = browser.find_element(By.CLASS_NAME, "toolbar-container")browser.execute_script("arguments[0].scrollIntoView();", element)print("滚动到特定元素位置")time.sleep(1)except Exception as e:print(f"未找到目标元素: {e}")# 6. 平滑滚动到底部browser.execute_script("""window.scrollTo({top: document.body.scrollHeight,behavior: 'smooth'});""")print("平滑滚动到底部")time.sleep(2)# 7. 模拟无限滚动加载last_height = browser.execute_script("return document.body.scrollHeight")scroll_attempts = 3 # 限制滚动次数,避免无限循环for i in range(scroll_attempts):browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")print(f"执行第 {i+1} 次滚动加载")time.sleep(2)new_height = browser.execute_script("return document.body.scrollHeight")if new_height == last_height:print("已到达页面底部")breaklast_height = new_heightexcept Exception as e:print(f"发生错误: {e}")finally:time.sleep(2)browser.quit()

3.4 延时等待
- implicitly_wait:设置隐式等待时间。隐式等待是一个全局设置,设置后对整个浏览器会话中的所有操作都生效;它告诉WebDriver在查找元素时,如果元素不存在,应该等待多长时间;在设定的时间内,WebDriver会定期重试查找元素的操作。
- WebDriverWait:创建显式等待对象。它允许我们设置最长等待时间和检查的时间间隔;与隐式等待不同,显式等待可以针对特定元素设置具体的等待条件;它提供了更精确的等待控制。
- until:等待直到条件满足。它接受一个期望条件(EC)作为参数,在超时之前反复检查该条件是否满足;如果条件满足则返回结果,如果超时则抛出TimeoutException异常。
- until_not:等待直到条件不满足。与until相反,它等待一个条件变为false;常用于等待某个元素消失或某个状态结束的场景。
- expected_conditions:预定义的期望条件集合。包含多种常用的等待条件,如:
- presence_of_element_located:等待元素在DOM中出现
- visibility_of_element_located:等待元素可见
- element_to_be_clickable:等待元素可点击
- all_of:等待多个条件同时满足
- poll_frequency:设置轮询频率。定义了在显式等待过程中检查条件的时间间隔;默认是0.5秒检查一次;可以根据实际需求调整以优化性能。
- ignored_exceptions:设置要忽略的异常。在等待过程中可以指定某些异常被忽略而继续等待;常用于处理特定的临时性错误,如StaleElementReferenceException。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)try:# 1. 设置隐式等待时间(全局设置)browser.implicitly_wait(10)print("设置隐式等待时间:10秒")# 打开测试网页browser.get("https://www.csdn.net/")# 2. 显式等待 - 等待特定元素可见try:search_input = WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.ID, "toolbar-search-input")))print("成功找到搜索框元素")except TimeoutException:print("等待搜索框超时")# 3. 显式等待 - 等待元素可点击try:login_button = WebDriverWait(browser, 5).until(EC.element_to_be_clickable((By.CLASS_NAME, "login-btn")))print("登录按钮可以点击")except TimeoutException:print("等待登录按钮可点击超时")# 4. 自定义等待条件def custom_condition(driver):element = driver.find_element(By.CLASS_NAME, "toolbar-container")return element.is_displayed() and element.get_attribute("style") != "display: none;"try:WebDriverWait(browser, 8).until(custom_condition)print("自定义条件满足")except TimeoutException:print("等待自定义条件超时")# 5. 多条件组合等待try:# 等待多个条件都满足wait = WebDriverWait(browser, 10)condition = wait.until(EC.all_of(EC.presence_of_element_located((By.CLASS_NAME, "toolbar-container")),EC.visibility_of_element_located((By.ID, "toolbar-search-input"))))print("多个条件都满足")except TimeoutException:print("等待多个条件超时")# 6. 使用until_not等待条件不成立try:# 等待加载动画消失loading_spinner = WebDriverWait(browser, 5).until_not(EC.presence_of_element_located((By.CLASS_NAME, "loading-spinner")))print("加载动画已消失")except TimeoutException:print("等待加载动画消失超时")# 7. 带有轮询间隔的等待try:# 设置轮询间隔为0.5秒wait = WebDriverWait(browser, timeout=10, poll_frequency=0.5)element = wait.until(EC.presence_of_element_located((By.CLASS_NAME, "toolbar-container")))print("使用自定义轮询间隔成功找到元素")except TimeoutException:print("使用自定义轮询间隔等待超时")# 8. 忽略特定异常的等待try:# 忽略 StaleElementReferenceException 异常wait = WebDriverWait(browser, 10, ignored_exceptions=[NoSuchElementException])element = wait.until(EC.presence_of_element_located((By.ID, "toolbar-search-input")))print("忽略特定异常后成功找到元素")except TimeoutException:print("忽略特定异常后等待超时")except Exception as e:print(f"发生错误: {e}")finally:time.sleep(2)browser.quit()

4 实战
4.1 实战一:自动化搜索并统计打印结果
- 本代码演示打开bing搜索界面搜索关键词“CSDN”,获取搜索结果并打印每个结果的基本信息。
- 代码思路:
- 使用
get()方法打开bing搜索界面 - 使用
find_element()方法定位搜索输入框元素 - 使用
send_keys()方法输入关键字和回车按键执行搜索 - 使用
find_elements()方法通过"b_algo"类名进行筛选,查看搜索界面源码可以知道搜索结果元素都是"b_algo"类。 - 综合使用
find_element()、text()、get_attribute()方法获取每个搜索结果的标题、链接、描述等信息,所使用的属性值、类名也是通过查看源码获得的,通过前文介绍的元素定位方法可以很容易的知道。
- 使用
- 注意:由于不同搜索结果之间存在一定的差异,所以不一定每一个搜索结果都能获得完整的信息,这个需要自己结合源码对示例代码进行修改。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)try:# 设置隐式等待时间browser.implicitly_wait(10)# 打开必应搜索页面browser.get("https://www.bing.com")print("已打开必应搜索页面")# 查找搜索框并输入关键词search_input = browser.find_element(By.ID, "sb_form_q")search_input.send_keys("CSDN")search_input.send_keys(Keys.RETURN)print("已输入搜索关键词:CSDN")# 稍等待搜索结果加载time.sleep(2)# 获取搜索结果search_results = browser.find_elements(By.CLASS_NAME, "b_algo")print(f"\n找到 {len(search_results)} 条搜索结果:\n")# 打印搜索结果for index, result in enumerate(search_results, 1):try:# 获取标题和链接title_element = result.find_element(By.CSS_SELECTOR, "h2 a")title = title_element.textlink = title_element.get_attribute("href")# 获取描述 (直接获取 b_caption 的文本内容)description = result.find_element(By.CLASS_NAME, "b_caption").text# 打印结果print(f"结果 {index}:")print(f"标题: {title}")print(f"链接: {link}")print(f"描述: {description}")print("-" * 80)except Exception as e:print(f"处理第 {index} 条结果时出错: {str(e)}")continueexcept Exception as e:print(f"发生错误: {e}")finally:# 等待一段时间后关闭浏览器time.sleep(2)browser.quit()print("浏览器已关闭")



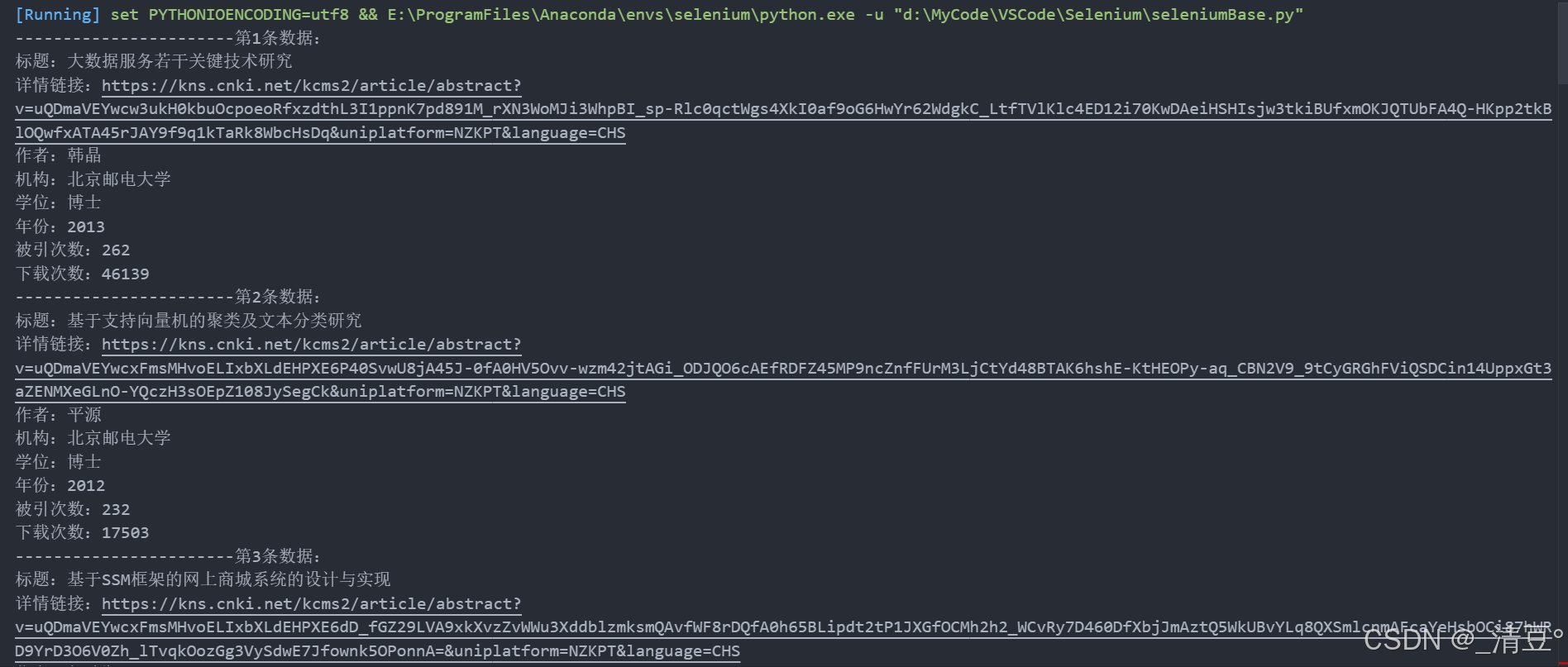
4.2 实战二:知网论文信息查询
- 本代码演示打开知网高级检索界面,通过设置学科专业(计算机)和学校单位(北京邮电大学)进行论文检索,并按下载量排序获取前20条论文的详细信息。
- 代码思路:
- 使用get()方法打开知网高级检索界面
- 使用maximize_window()方法将窗口最大化,确保所有元素可见
- 通过XPATH定位并点击"学科专业导航",清除已选学科,展开工学类别并选中计算机专业
- 使用send_keys()方法在学校单位输入框中填入"北京邮电大学"
- 点击检索按钮开始搜索
- 点击下载量排序选项,对结果进行排序
- 使用execute_script()方法控制页面向下滚动700像素
- 使用循环遍历前20条搜索结果,通过XPATH定位每条论文的各项信息
- 注意事项:
- 代码中使用了多处time.sleep()来确保页面加载完成,实际使用时可根据网络情况调整等待时间
- XPATH路径的获取是通过浏览器开发者工具复制得到,需要注意网页结构变化可能导致定位失效
- 使用try-except结构进行异常处理,确保程序运行的稳定性
- 最后使用quit()方法关闭浏览器,释放资源
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器
browser = webdriver.Chrome(service=service)try:# 设置隐式等待时间browser.implicitly_wait(10)browser.get("https://epub.cnki.net/kns/advsearch?classid=RDS33BAY")time.sleep(1)# 窗口最大化browser.maximize_window()time.sleep(1)# 点击学科专业导航browser.find_element(By.XPATH, '//*[@id="XuekeNavi_Div"]/div/div/div/div/div[1]/a[2]').click()time.sleep(1)# 点击清除取消所有选中的学科browser.find_element(By.XPATH, '//*[@id="XuekeNavi_Div"]/div/div/div/div/div[2]/a[2]').click()time.sleep(1)# 点击展开工学browser.find_element(By.XPATH, '//*[@id="08"]').click()time.sleep(1)# 点击选中计算机browser.find_element(By.XPATH, '//*[@id="9UG2UB8R"]/li[8]/ul/li[12]/div/i[2]').click()time.sleep(1)# 往学校单位输入框填写内容browser.find_element(By.XPATH, '//*[@id="inputAndSelect"]/input').send_keys("北京邮电大学")time.sleep(1)# 点击检索按钮browser.find_element(By.XPATH, "/html/body/div[2]/div[3]/div/div[3]/div[1]/div[2]/div[1]/div[9]").click()time.sleep(1)# 点击按照下载量排序browser.find_element(By.XPATH, '//*[@id="orderList"]/li[6]').click()time.sleep(1)# 向下翻动700pxbrowser.execute_script("window.scrollBy(0, 700);")time.sleep(1)for i in range(20):title = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[2]/a',).textdetail_link = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[2]/a',).get_attribute("href")author = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[3]/a',).textinstitution = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[4]/a/font',).textdegree = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[5]',).textyear = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[6]',).textcited_count = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[7]',).textdownload_count = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[8]',).textprint(f"-----------------------第{i+1}条数据:")print(f"标题:{title}")print(f"详情链接:{detail_link}")print(f"作者:{author}")print(f"机构:{institution}")print(f"学位:{degree}")print(f"年份:{year}")print(f"被引次数:{cited_count}")print(f"下载次数:{download_count}")except Exception as e:print(f"发生错误: {e}")finally:browser.quit()print("浏览器已关闭")
相关文章:
Python Selenium库入门使用,图文详细。附网页爬虫、web自动化操作等实战操作。
文章目录 前言1 创建conda环境安装Selenium库2 浏览器驱动下载(以Chrome和Edge为例)3 基础使用(以Chrome为例演示)3.1 与浏览器相关的操作3.1.1 打开/关闭浏览器3.1.2 访问指定域名的网页3.1.3 控制浏览器的窗口大小3.1.4 前进/后…...
【Uniapp-Vue3】使用defineExpose暴露子组件的属性及方法
如果我们想要让父组件访问到子组件中的变量和方法,就需要使用defineExpose暴露: defineExpose({ 变量 }) 子组件配置 父组件配置 父组件要通过onMounted获取到子组件的DOM 传递多个属性和方法 子组件 父组件...
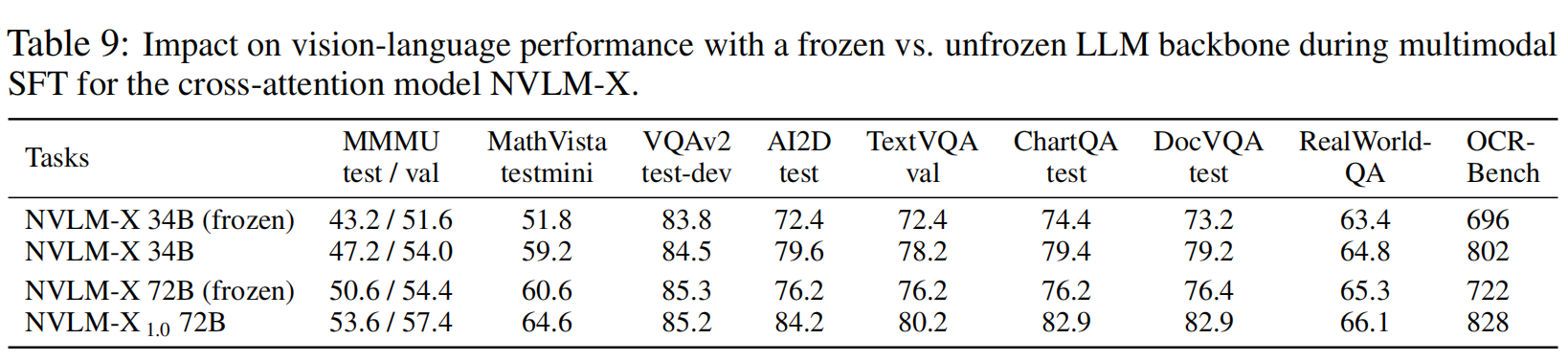
【多模态LLM】英伟达NVLM多模态大模型训练细节和数据集
前期笔者介绍了OCR-free的多模态大模型,可以参考:【多模态&文档智能】OCR-free感知多模态大模型技术链路及训练数据细节,其更偏向于训练模型对于密集文本的感知能力。本文看一看英伟达出品的多模态大模型NVLM-1.0系列,虽然暂未…...

HTTP详解——HTTP基础
HTTP 基本概念 HTTP 是超文本传输协议 (HyperText Transfer Protocol) 超文本传输协议(HyperText Transfer Protocol) HTTP 是一个在计算机世界里专门在 两点 之间 传输 文字、图片、音视频等 超文本 数据的 约定和规范 1. 协议 约定和规范 2. 传输 两点之间传输…...

MySQL教程之:输入查询
如上一节所述,确保您已连接到服务器。这样做本身不会选择任何要使用的数据库,但没关系。在这一点上,了解一下如何发出查询比直接创建表、加载数据和从中检索数据更重要。本节介绍输入查询的基本原则,使用几个查询,您可…...
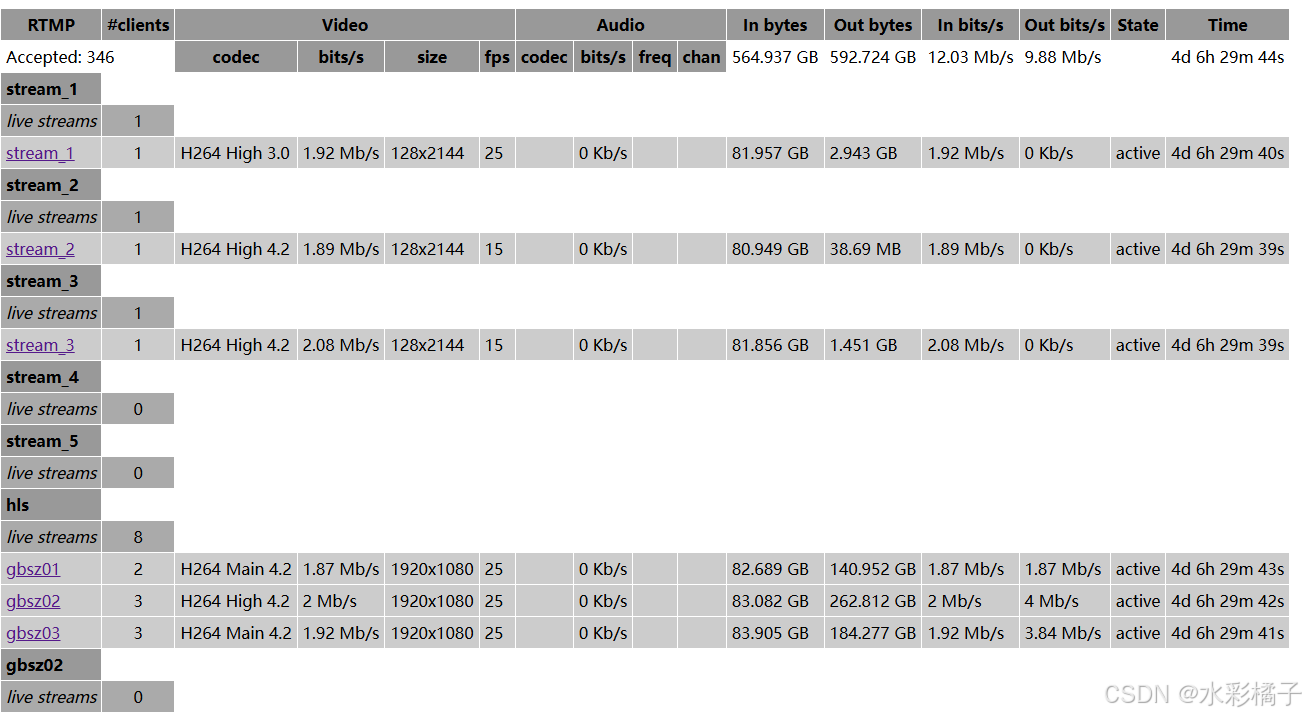
docker+ffmpeg+nginx+rtmp 拉取摄像机视频
1、构造程序容器镜像 app.py import subprocess import json import time import multiprocessing import socketdef check_rtmp_server(host, port, timeout5):try:with socket.create_connection((host, port), timeout):print(f"RTMP server at {host}:{port} is avai…...
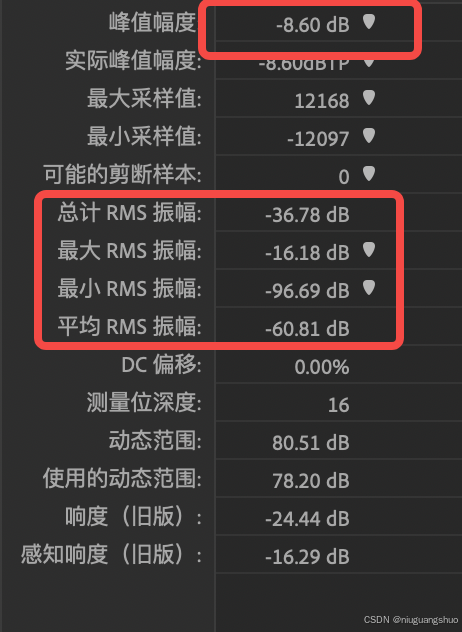
不同音频振幅dBFS计算方法
1. 振幅的基本概念 振幅是描述音频信号强度的一个重要参数。它通常表示为信号的幅度值,幅度越大,声音听起来就越响。为了更好地理解和处理音频信号,通常会将振幅转换为分贝(dB)单位。分贝是一个对数单位,能…...
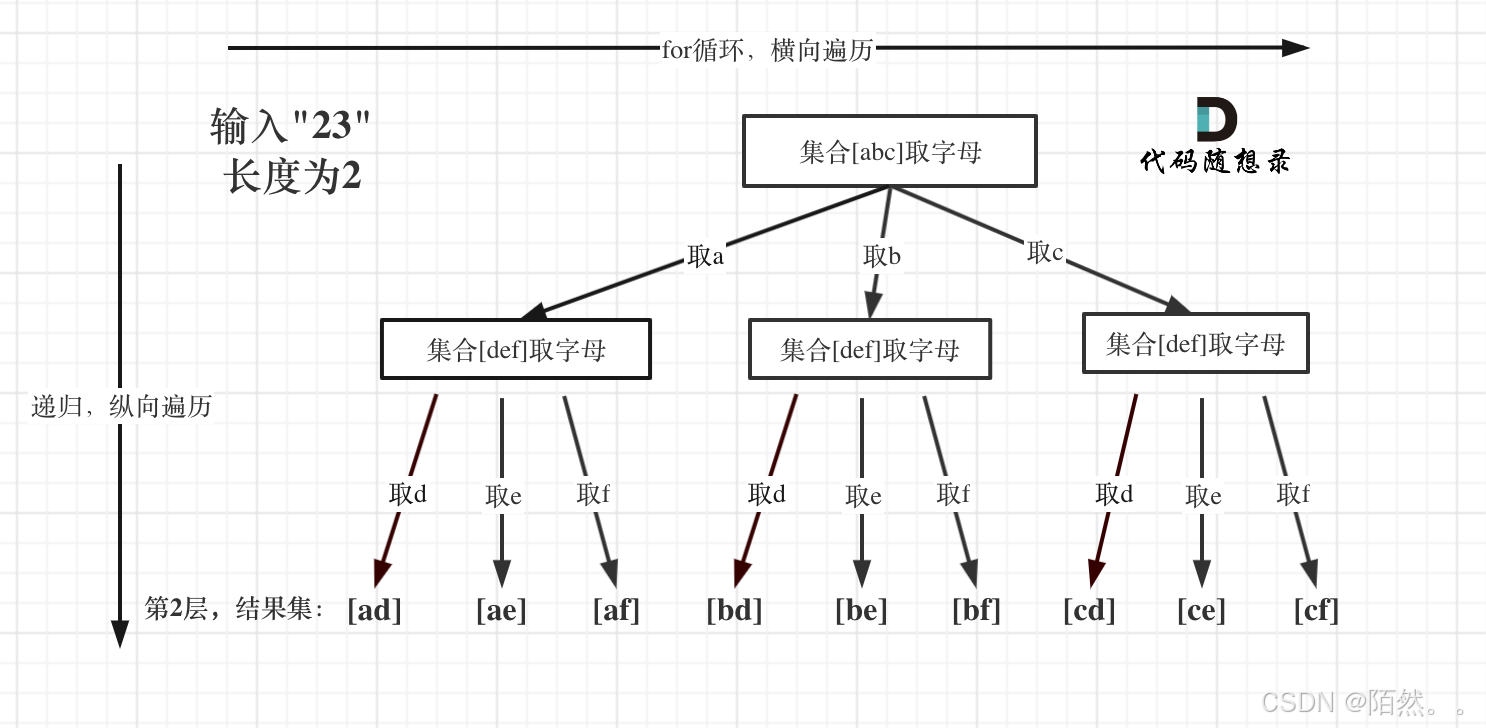
【17. 电话号码的字母组合 中等】
题目: 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。 示例 1: 输入:digits “23”…...
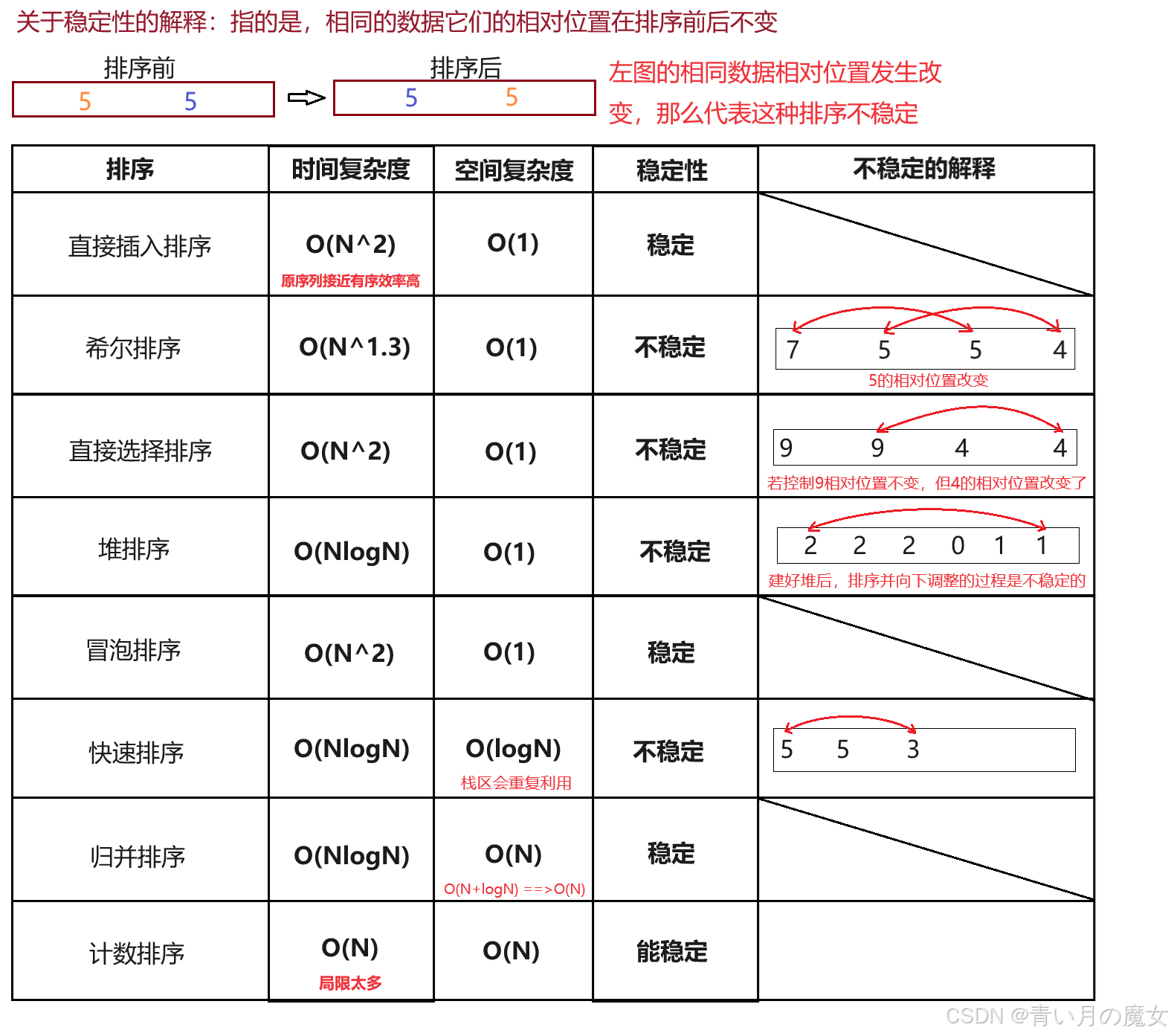
数据结构初阶---排序
一、排序相关概念与运用 1.排序相关概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的…...
【从0-1实现一个前端脚手架】
目录 介绍为什么需要脚手架?一个脚手架应该具备哪些功能? 脚手架实现初始化项目相关依赖实现脚手架 发布 介绍 为什么需要脚手架? 脚手架本质就是一个工具,作用是能够让使用者专注于写代码,它可以让我们只用一个命令…...
AI文章管理系统(自动生成图文分发到分站)
最近帮一个网上的朋友做了一套AI文章生成系统。他的需求是这样: 1、做一个服务端转接百度文心一言的生成文章的API接口。 2、服务端能注册用户,用户在服务端注册充值后可以获取一个令牌,这个令牌填写到客户端,客户端就可以根据客…...

【Leetcode 每日一题】3270. 求出数字答案
问题背景 给你三个 正 整数 n u m 1 num_1 num1, n u m 2 num_2 num2 和 n u m 3 num_3 num3。 数字 n u m 1 num_1 num1, n u m 2 num_2 num2 和 n u m 3 num_3 num3 的数字答案 k e y key key 是一个四位数,定义如下&…...
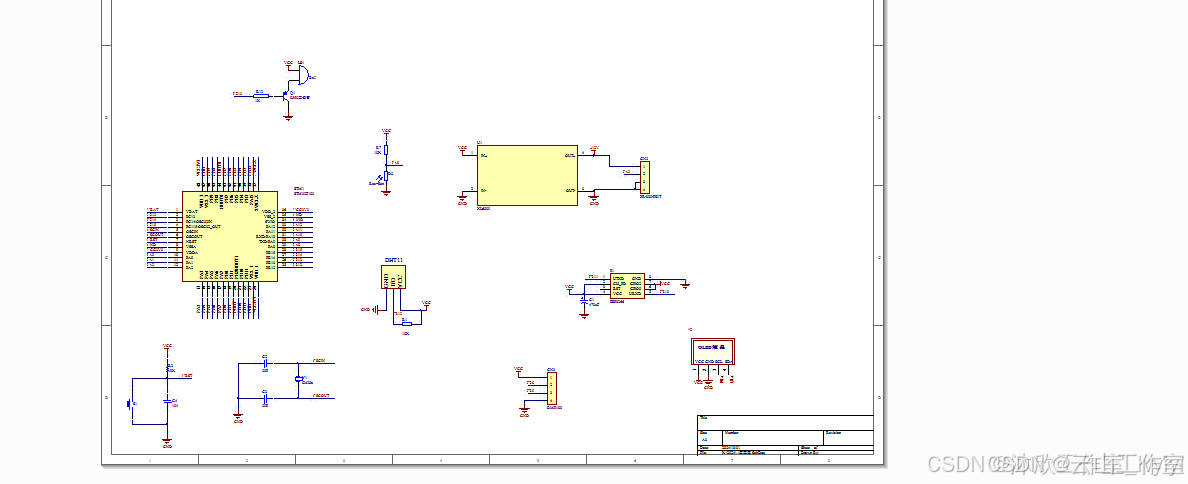
基于单片机的无线气象仪系统设计(论文+源码)
1系统方案设计 如图2.1所示为无线气象仪系统设计框架。系统设计采用STM32单片机作为主控制器,结合DHT11温湿度传感器、光敏传感器、BMP180气压传感器、PR-3000-FS-N01风速传感器实现气象环境的温度、湿度、光照、气压、风速等环境数据的检测,并通过OLED1…...

【数据库】Mysql精简回顾复习
一、概念 数据库(DB):数据存储的仓库数据库管理系统(DBMS):操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,是一套标准关系型数据库(RDBMS)&…...

深入理解 HTTP 的 GET、POST 方法与 Request 和 Response
HTTP 协议是构建 Web 应用的基石,GET 和 POST 是其中最常用的请求方法。无论是前端开发、后端开发,还是接口测试,对它们的深入理解都显得尤为重要。在本文中,我们将介绍 GET 和 POST 方法,以及 Request 和 Response 的…...

MySQL 中联合索引相比单索引性能提升在哪?
首先我们要清楚所以也是要占用磁盘空间的,随着表中数据量越来越多,索引的空间也是随之提升的,因而单表不建议定义过多的索引,所以使用联合索引可以在一定程度上可以减少索引的空间占用其次,使用联合索引的情况下&#…...
第34天:安全开发-JavaEE应用反射机制攻击链类对象成员变量方法构造方法
时间轴: Java反射相关类图解: 反射: 1、什么是 Java 反射 参考: https://xz.aliyun.com/t/9117 Java 提供了一套反射 API ,该 API 由 Class 类与 java.lang.reflect 类库组成。 该类库包含了 Field 、 Me…...

C++笔记之数据单位与C语言变量类型和范围
C++笔记之数据单位与C语言变量类型和范围 code review! 文章目录 C++笔记之数据单位与C语言变量类型和范围一、数据单位1. 数据单位表:按单位的递增顺序排列2. 关于换算关系的说明3. 一般用法及注意事项4. 扩展内容5. 理解和使用建议二、C 语言变量类型和范围基本数据类型标准…...

算法-拆分数位后四位数字的最小和
力扣题目2160. 拆分数位后四位数字的最小和 - 力扣(LeetCode) 给你一个四位 正 整数 num 。请你使用 num 中的 数位 ,将 num 拆成两个新的整数 new1 和 new2 。new1 和 new2 中可以有 前导 0 ,且 num 中 所有 数位都必须使用。 …...

Python 管理 GitHub Secrets 和 Workflows
在现代软件开发中,自动化配置管理变得越来越重要。本文将介绍如何使用 Python 脚本来管理 GitHub 仓库的 Secrets 和 Workflows,这对于需要频繁更新配置或管理多个仓库的团队来说尤为有用。我们将分三个部分进行讨论:设置 GitHub 权限、创建 GitHub Secret 和创建 GitHub Wo…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...

Blender渲染通道完全指南:如何像电影后期一样,分离出深度、阴影与反射图
Blender渲染通道完全指南:影视级后期制作的深度解析在数字内容创作领域,Blender已经从一个简单的3D建模工具成长为能够处理复杂视觉特效的全流程解决方案。对于追求影视级质量的中高级用户而言,掌握渲染通道技术是提升作品专业度的关键一步。…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

PCL 法向量夹角剔除错误匹配点对【2026最新版】
目录 一、 算法简介 1、主要函数 2、参考文献 二、 代码实现 三、 结果展示 四、 参考链接 博客长期更新,本文最新更新时间为:2026年5月24日。代码在PCL1.15.1中测试通过 一、 算法简介 在三维点云配准中,对应点(correspondence)的准确性直接决定了配准算法的精度和鲁棒性…...

淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理
淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taoji…...

从零构建FOC轮腿机器人:开源平衡机器人完整指南
从零构建FOC轮腿机器人:开源平衡机器人完整指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software development. | 一个…...

昇腾CANN cmake 实战:CANN CMake 构建系统——跨平台编译配置与模块化管理
8 个 CANN 仓库各需独立构建(ops-transformer/ops-nn/hccl/ge/…)→ 手写 8 套 CMakeLists.txt(CANN 路径判断、跨 NPU 型号编译、第三方库兼容)。cmake 仓库提供统一的 FindCANN.cmake CANNConfig.cmake 模板——任何仓库只需 f…...

从XAI到HXAI:构建以人为中心的可解释AI框架与实践
1. 项目概述:从“黑箱”到“白盒”,构建可信AI的演进之路在机器学习项目里摸爬滚打了十几年,我见过太多因为模型“说不清道不明”而引发的信任危机。一个在测试集上表现完美的信用评分模型,可能因为无法向风控专家解释“为什么拒绝…...
)
为什么你的DeepSeek总漏检重构后代码?4步反混淆预处理法(附LLM辅助去装饰器Python脚本)
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...