【C】初阶数据结构3 -- 单链表
之前在顺序表那一篇文章中,提到顺序表具有的缺点,比如头插,头删时间复杂度为O(n),realloc增容有消耗等。而在链表中,这些问题将得到解决。所以在这一篇文章里,我们将会讲解链表的定义与性质,以及最简单的链表 -- 单链表的结构,以及基础方法的实现。
目录
1 链表
1) 链表的概念
2) 结点(节点)
3) 链表结点的结构
4) 链表的性质
2 单链表
1) 单链表的头插、尾插
2) 单链表的头删、尾删
3) 单链表在指定位置之前、之后插入数据
重点一 链表1 链表
1) 链表的概念
链表是一种物理结构上非连续、非顺序的存储结构,数据元素的逻辑结构通过链表中的指针链接
次序实现的一个链表(这里举例为单链表)的逻辑结构如图所示:

2) 结点(节点)
从上面那个链表的结构的图来看,结点就是指上面那个链表中每个独立存在的一个方块,所以一个结点里面包含了两部分内容,一个是这个结点里面存储的数据域,另一个是指向在一个结点的指针域,用来找到下一个结点,然后这里的plist是一个指向链表中第一个结点的指针,里面存储的是第一个结点的地址,可以通过plist来找到后面的结点,从结点的结构来看,知道了plist,也就是链表第一个结点的地址,我们就可以顺着结点中的指针,依次找到每一个结点。
3) 链表结点的结构
上面知道了结点的定义,结点的结构就很容易实现了,就是一个保存结点数据的数据域,还有一个指向下一个结点的指针:
#typedef int ListDataType;
typedef struct ListNode
{ListDataType data;//结点数据struct ListNode* next;//指向下一个结点的指针
}ListNode;4) 链表的性质
(1) 由于链表每个结点都是独立的一块空间,结点之间是通过指针连在一起,所以链表在物理结构上不一定是连续的,但是在逻辑结构上是连续的,所以是属于线性表的(2) 每个结点是动态开辟的,而动态开辟的空间都是在内存里一个叫做堆区的空间开辟的(3) 由于每个结点是独立申请的,所以每个结点的物理地址不一定连续
重点二 单链表2 单链表
单链表是链表的一种,其结点的结构就是上面那个图那样,每个结点里面就只有一个数据域,还有指向下一个结点的指针域,所以对于单链表来说,只能通过前面的结点找到后面的结点,是不能通过后面的结点找到后面的结点的。
单链表的结构:
typedef int SLTDataType;//singal list node -- 单链表结点typedef struct SListNode
{SLTDataType data;//结点的数据struct SListNode* next;//指向下一个结点的指针
}SLTNode;对于一个单链表来说,它的基础方法有链表的头插,头删,尾插,尾删,打印,查找,在指定位置之前插入数据,删除pos(这里的pos是一个节点的地址)结点,在指定位置之后插入数据,删除pos之后的节点, 销毁链表,同样,我们先讲解每一种方法的画图实现,之后再附上代码。
1) 单链表的头插、尾插
既然是插入结点,那么就肯定会需要新开辟一个结点,而且只要插入结点就需要开辟新结点,所以可以把开辟新结点写成一个函数(buyNode),开辟新结点的功能也很容易实现,只要用malloc函数动态开辟出一个结点大小的空间,然后再让结点的data值赋值为想要开辟新结点的值,然后再让next指针为NULL,就开辟出了一个新结点。
链表的头插的实现如图:

但是我们在实现头插的过程中,发现phead(形参,链表的头节点)会改变指向,会从指向旧链表的头节点改为指向插入的新结点,要想让传过来的实参头插后链表新的首节点,这里必须改变实参(也就是原来链表头节点指针的指向,形参改变影响实参),所以这里必须传指针变量的地址,也就是二级指针。
尾插的实现也类似,如图:

在第二步里面,需要通过头节点来找到尾节点,通过头节点找到尾节点的实现思路为:先创建一个节点指针变量 ptail 指向首结点,之后再让循环判断 ptail 的next指针为不为NULL,如果不为NULL,那就让ptail走向下一个结点(注意,这里判断条件不能是ptail为不为NULL,如何是这个判断条件,那么ptail就会走向NULL,后面势必会造成对NULL指针的解引用),代码为:
SLTNode* ptail = phead;
while (ptail->next != NULL)
{ptail = ptail->next;
}那么尾插是否需要传二级指针呢?
其实不管是头插还是尾插,都需要考虑一种特殊情形,那就是链表为空的情况(就是指向头结点的指针为NULL),如果链表为空,上面的两种情况都会造成对空指针的解引用,所以如果链表为空,那就让指向头节点的指针指向新开辟的结点newnode就可以了,但是这里改变的只是形参,所以如果想要让实参也变为指向newnode的指针,就必须传指针的地址,也就是二级指针了。(这里如果看不懂的话,可以看下面的代码理解一下)。
所以上面找尾节点的代码应该为:
//传过来的二级指针为SLTNode** pphead,指向头节点的指针为*pphead
SLTNode* ptail = *pphead;
while (ptail != NULL)
{ptail = ptail->next;
}2) 单链表的头删、尾删
既然是删除结点,那么就需要判断链表为不为空,也就是判断传过来的指向首节点的指针为不为NULL,如果为NULL,就不能删除结点。
头删的过程如图:
头删也需要注意传递的参数也需要是二级指针(因为形参的改变要影响实参) 。
尾删的过程如下:
寻找prev和ptail的代码如下:
//传过来的为二级指针**pphead
SLTNode* ptail = *pphead, *prev = NULL;
while (ptail->next != NULL)
{prev = ptail;ptail = ptail->next;
}头删和尾删的时候需要注意一种极端情况,那就是只有一个结点的情况((*pphead)->next == NULL),如果只有一个结点,那么prev指针就是NULL指针,那么就会出现NULL指针的解引用,但是对于头删的代码来说,就不会出现这种情况(可以结合下面的代码)。所以尾删只有一个结点的情况需要特殊处理,其实删除只有一个结点的链表尾删和头删都是一样的,所以链表只有一个结点时,尾删也就是头删。
3) 单链表在指定位置之前、之后插入数据
同样的,既然是插入数据,就需要和头插、尾插一样开辟新的节点(这里与头插、尾插开辟新节点逻辑相同,不再赘述)。这里的位置指的是一个节点,这里叫做pos节点,那么实现逻辑如下图所示:
在pos节点之前插入数据:

找到pos节点之前的prev节点的逻辑类似于尾插中找到尾节点,具体逻辑为:先将prev节点指定为首节点,如果prev的next指针不指向pos节点,那就让prev走到它的next指针,写成代码为:
//*pphead为首节点
SLTNode* prev = *pphead;while(prev->next != pos)
{prev = prev->next;
}
我们来考虑一下特殊情况,那就是如果pos节点就是首节点的话(pos == *pphead),如果继续按照这个逻辑的话,prev节点是首届点,而pos节点也是首节点,那么prev的next指针始终不等于pos,所以最终会造成对NULL指针的解引用,所以如果pos是首节点,这时候需要特殊处理一下,仅需要调用一下头插的函数就可以了(可以结合下面代码思考一下)。
在pos节点之后插入数据:

我们再来考虑一下特殊情况,就是如果pos是尾节点的情况,如果再按这个逻辑的话,会发现是没有问题的,不会出现对于NULL指针的解引用情况。但是有一个点需要注意,就是在第二步里面,一定要先让newnode的next指针先改变,再让pos的next指针改变,因为pos的next指针如果先改变的话,那就找不到pos的下一个节点了,且newnode会指向自己的。
还有就是我们可以看到在pos节点之后插入数据,实现逻辑是没有用到首节点的,所以对于该函数实现的时候,只需要传pos参数和插入的数据 X 两个参数就可以了。
那么在指定位置之前和之后插入数据是否需要判断单链表是否为空呢?实际上是不需要的,因为在pos节点之前、之后插入数据就保证了该单链表是非空的,所以只需要判断pos节点是否为NULL就可以了。
4) 删除指定位置(pos)节点,删除指定位置(pos)之后的节点
既然是删除节点,那就需要判断链表是否为空(判断逻辑与头删、尾删相同,不再赘述),这两个方法实现逻辑如下:
删除pos节点:
我们来考虑一下特殊情况,那就是如果pos节点是首节点、尾节点时。如果pos是尾节点,根据这个逻辑来实现的话,发现是没有问题的;但是如果pos是首节点,那么根据我们之前找prev节点的逻辑,会出现对NULL指针的解引用的,所以pos是首节点的情况需要特殊处理一下,只需要调用一下头删的代码就可以了。
删除pos节点之后的节点:

该方法的实现时有一个地方需要注意,就是要删除的节点,也就是pos的下一个节点不能为NULL,且该方法的实现只需要传递一个pos参数就可以了。
5) 打印、查找、销毁
打印函数和查找函数的逻辑比较好实现,只要遍历整个单链表,然后打印每个节点的值或者比较节点的值要和查找的值相不相等就可以了,如果查找到了就返回对应节点的地址,如果没有查找到,就返回NULL。
销毁链表也很简单,只要从首节点开始遍历,然后销毁每一个节点就可以了,只不过需要注意在释放当前节点之前,需要先把下一个节点的地址存起来,避免找不到下一个节点了。
6) 代码实现
SList.h:
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>typedef int SLTDataType;//singal list node -- 单链表结点typedef struct SListNode
{SLTDataType data;//结点的数据struct SListNode* next;//指向下一个结点的指针
}SLTNode;//打印
void SLTPrint(SLTNode* phead);
//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x);
//头删
void SLTPopFront(SLTNode** pphead);
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);
//尾删
void SLTPopBack(SLTNode** pphead);
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
//在指定位置之前插入数据
void SLTInsert(SLTDataType** pphead, SLTNode* pos, SLTDataType x);
//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos);
//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos);
//销毁链表
void SLTDestroy(SLTNode** pphead);SList.c文件:
#include"SList.h"//开辟结点的函数
SLTNode* buyNode(SLTDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));//开辟失败if (newnode == NULL){perror("malloc fail!\n");//打印错误信息exit(1);}newnode->data = x;newnode->next = NULL;return newnode;
}//打印
void SLTPrint(SLTNode* phead)
{SLTNode* pcur = phead;while (pcur){printf("%d->", pcur->data);pcur = pcur->next;}printf("NULL\n");
}//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{assert(pphead);//传过来的不能是空指针if ((*pphead) == NULL){*pphead = buyNode(x);}else{SLTNode* newnode = buyNode(x);//让新开辟的结点next指针指向链表第一个结点newnode->next = *pphead;//再让指向第一个结点的指针指向新开辟的结点*pphead = newnode;}
}//头删
void SLTPopFront(SLTNode** pphead)
{//传过来的指针不能为空,并且链表不能为空assert(pphead && *pphead);//得先让首结点指向首结点的下一个结点,要不然会成野指针SLTNode* next = (*pphead)->next;free(*pphead);*pphead = next;
}//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{assert(pphead);//如果是空链表的话,就让指针指向新的结点if (*pphead == NULL){*pphead = buyNode(x);}//链表不为空,得先找到尾节点else{SLTNode* ptail = *pphead;while (ptail->next){ptail = ptail->next;}//ptail为尾结点SLTNode* newnode = buyNode(x);ptail->next = newnode;}
}
//尾删
void SLTPopBack(SLTNode** pphead)
{//传过来的地址不能为NULL并且链表为空assert(pphead && *pphead);//如果链表中只有一个结点,那就是头删除if ((*pphead)->next == NULL){SLTPopFront(pphead);}else{//得先找到尾节点和尾节点的前一个结点SLTNode* ptail = *pphead;SLTNode* prev = NULL;while (ptail->next){prev = ptail;ptail = ptail->next;}prev->next = NULL;free(ptail);ptail = NULL;}
}//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{assert(phead);SLTNode* pcur = phead;while (pcur){if (pcur->data == x)return pcur;pcur = pcur->next;}return NULL;
}//在指定位置之前插入数据
void SLTInsert(SLTDataType** pphead, SLTNode* pos, SLTDataType x)
{assert(pphead);assert(pos);//如果pos节点就是首节点if (pos == *pphead){//头插SLTPushFront(pphead, x);}//如果pos不是首节点else{SLTNode* prev = *pphead;SLTNode* newnode = buyNode(x);while (prev->next != pos){prev = prev->next;}prev->next = newnode;newnode->next = pos;}
}//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead && *pphead);assert(pos);//如果pos节点是首节点if (pos == *pphead){SLTPopFront(pphead);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;}}//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);SLTNode* newnode = buyNode(x);//一定得先让newnode->next = pos->next//再让pos->next = newnodenewnode->next = pos->next;pos->next = newnode;
}//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos)
{//pos的下一个结点不能为空,否则不能删除assert(pos && pos->next);SLTNode* del = pos->next;pos->next = del->next;free(del);del = NULL;
}//销毁链表
void SLTDestroy(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* pcur = *pphead;//先存下一个结点SLTNode* next = pcur->next;while (pcur){next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}test.c:
#include"SList.h"void Test()
{SLTNode* plist = NULL;测试头插/*SLTPushFront(&plist, 1);SLTPushFront(&plist, 2);SLTPushFront(&plist, 3);SLTPushFront(&plist, 4);SLTPrint(plist);*///测试头删//SLTPopFront(&plist);/*SLTPopFront(&plist);SLTPopFront(&plist);SLTPopFront(&plist);*///SLTPopFront(&plist);//测试尾插SLTPushBack(&plist, 1);SLTPushBack(&plist, 2);SLTPushBack(&plist, 3);SLTPushBack(&plist, 4);SLTPrint(plist);//测试尾删/*SLTPopBack(&plist);SLTPopBack(&plist);SLTPopBack(&plist);SLTPopBack(&plist);*///SLTPopBack(&plist);//测试查找/* SLTNode* pfind = SLTFind(plist, 10);if (pfind == NULL){printf("没找到\n");}else{printf("找到了\n");}*/SLTNode* pfind = SLTFind(plist, 1);if (pfind == NULL){printf("没找到\n");}else{printf("找到了\n");}//测试在指定位置之前插入数据//可以测试在1,2,4节点之前插入数据//SLTInsert(&plist, pfind, 5);//测试在指定节点之后插入数据//可以测试在1,2,4节点之后插入数据//SLTInsertAfter(pfind, 5);//测试删除pos节点//可以测试删除1,2,4节点//SLTErase(&plist, pfind);//测试删除pos之后的节点//可以测试删除1,2,3之后的节点//SLTEraseAfter(pfind);//可以使用调试测试销毁是否成功//如果销毁成功,下面打印结果就是NULLSLTDestroy(&plist);//打印SLTPrint(plist);
}int main()
{Test();return 0;
}单链表是链表里面结构最简单的一种链表,链表共分为8类(在双向链表里面会讲解),但是由于结构最简单,所以遍历只能从头开始遍历且在方法实现中涉及的细节点很多。同时,单链表中为什么传二级指针也需要自己理解。总之,如果刚开始学习单链表,并不会很容易理解;但是,一旦理解了,相信会对指针的理解更加深刻。
相关文章:
【C】初阶数据结构3 -- 单链表
之前在顺序表那一篇文章中,提到顺序表具有的缺点,比如头插,头删时间复杂度为O(n),realloc增容有消耗等。而在链表中,这些问题将得到解决。所以在这一篇文章里,我们将会讲解链表的定义与性质,以及…...

Autodl安装tensorflow2.10.0记录
首先租用新实例(我选的是3080*2卡),由于基础镜像中没有2.10.0版本,选miniconda3的基础环境 创建虚拟环境:conda create --name xxx python3.8(环境名)激活虚拟环境:conda activate x…...

【Rust】常见集合
目录 思维导图 一、Rust常用集合 1. Rust标准库中的集合概述 2. 常用集合类型 2.1 向量(Vector) 2.2 字符串(String) 2.3 哈希映射(Hash Map) 二、向量(Vec) 1. 向量的概述…...
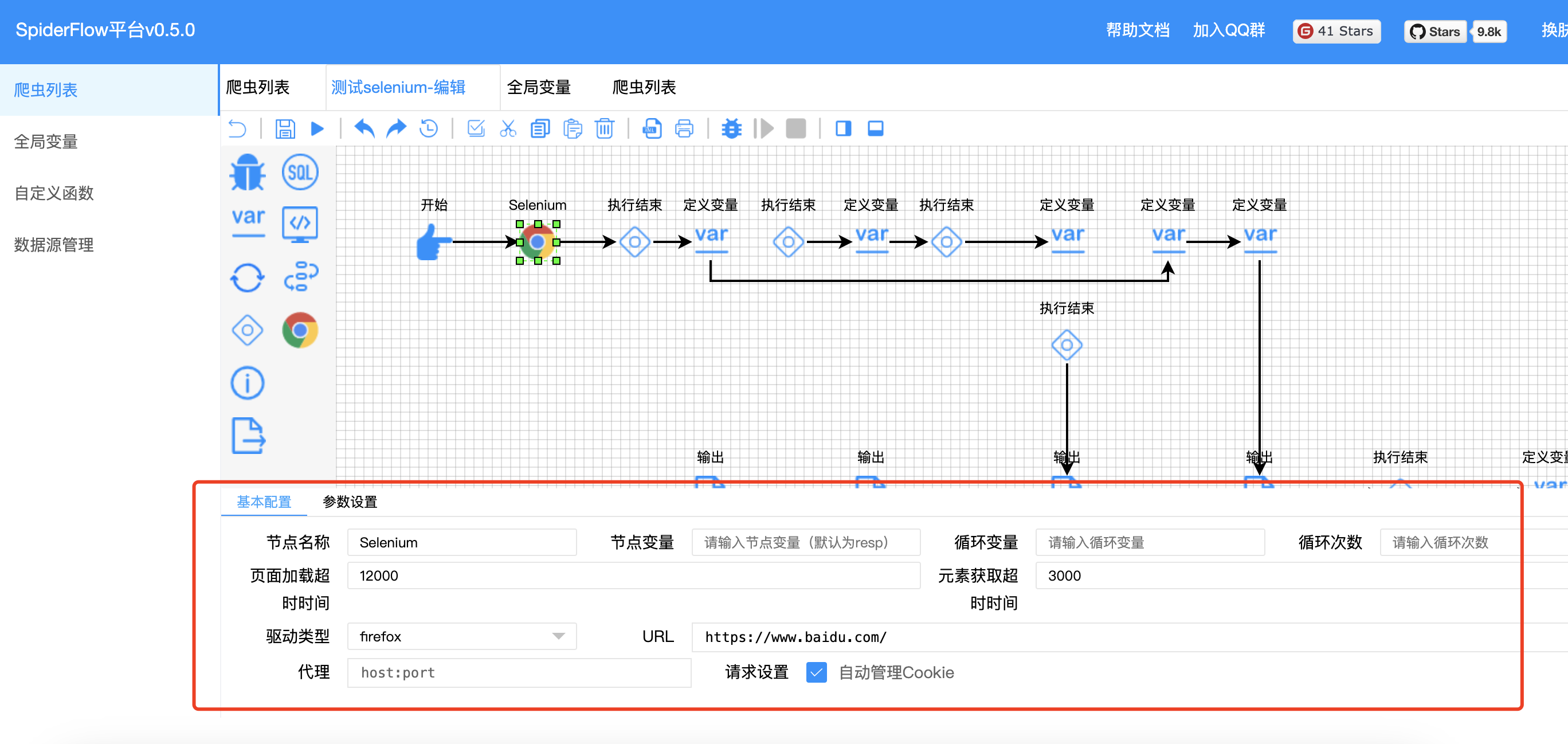
SpiderFlow平台v0.5.0之引入selenium插件
引入selenium插件 首先到码云下载插件点击下载编辑到本地并导入到工作空间或安装到maven库在spider-flow/spider-flow-web/pom.xml中引入插件 <!-- 引入selenium插件 --> <dependency><groupId>org.spiderflow</groupId><artifactId>spider-…...

git push命令
git push 常用命令 1. 拉取远程仓库最新数据 使用 git fetch git fetch作用: 获取远程仓库的最新数据(包括分支、标签等),但不会修改本地工作目录。 结果: 仅更新远程分支(如 origin/main)的…...

洛谷P1161
开灯 - 洛谷 代码区: #include<stdio.h> int ans[2000005]{1}; //1为关 int main(){int n;scanf("%d",&n);double arry[n][2];//此处最好用双精度浮点数,单精度浮点数的精确度够高对于此题来说,第一次没全对就是因为精度…...

Python脚本自动发送电子邮件
要编写一个Python脚本来自动发送电子邮件,你可以使用smtplib库来处理SMTP协议,以及email库来构建邮件内容。 安装必要的库 通常情况下,smtplib和email库是Python标准库的一部分,因此不需要额外安装。如果你使用的是较旧的Python版…...

vscode的安装与使用
下载 地址:https://code.visualstudio.com/ 安装 修改安装路径(不要有中文) 点击下一步,创建桌面快捷方式,等待安装 安装中文插件 可以根据自己的需要安装python和Jupyter插件...

sparkRDD教程之必会的题目
1.前期准备 (1)看看上一期的博客,最好跟着上一期的博客把sparkRDD的基本命令给熟练掌握后,再来做这篇文章的任务。 上一期的博客:sparkRDD教程之基本命令-CSDN博客 (2)新建文件task6.scala …...

Unity 2d描边基于SpriteRender,高性能的描边解决方案
目标 以Unity默认渲染管线为例,打造不需要图片内边距,描边平滑,高性能的描边解决方案 前言 在2d游戏中经常需要给2d对象添加描边,来突出强调2d对象 当你去网上查找2d描边shader,移植到项目里面,大概率会…...

信凯科技业绩波动明显:毛利率远弱行业,资产负债率偏高
《港湾商业观察》施子夫 1月8日,深交所官网显示,浙江信凯科技集团股份有限公司(以下简称“信凯科技”)主板IPO提交注册。 自2022年递交上市申请,信凯科技的IPO之路已走过两年光景,尽管提交注册࿰…...

js基础---var与let的区别以及const的使用
js基础—var与let的区别以及const的使用 var与let的区别 在较旧的JavaScript,使用关键字var来声明变量,而不是let。var现在开发中一般不再使用它,只是我们可能再老版程序中看到它。let的出现为了解决var的一些问题。 var 声明存在以下三种问…...

用css和html制作太极图
目录 css相关参数介绍 边距 边框 伪元素选择器 太极图案例实现、 代码 效果 css相关参数介绍 边距 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title><style>*{margin: 0;padding: 0;}div{width: …...

OJ12:160. 相交链表
目录 题目思路分析代码展示 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 示例 1: 输入:intersectVal 8, listA [4,1,8,4,5], listB [5,…...

软件工程和项目管理领域 - CMMI 极简理解
CMMI 概述 CMMI 全称为 Capability Maturity Model Integration,即能力成熟度模型集成 CMMI 是由美国卡内基梅隆大学软件工程研究所(SEI)开发的一套综合性管理模型 CMMI 是一种用于评估和改进组织在软件开发和维护方面过程能力的国际标准 …...

C# 线程基础之 线程同步
线程同步的手段很多 lock 是通过内存索引块 0 1 切换 进行互斥的实现 互斥量 信号量 事件消息 其实意思就是 一个 标记量 通过这个标记 来进行类似的互斥手段 具体方式的分析 代码在后 1.互斥量 Mutex 作用 非常类似lock 一个Mutex 名称来代替 lock的引用对象 2.信号量 Semaph…...

[c语言日寄]c语言也有“回”字的多种写法——整数交换的三种方式
大家好啊,在今天的快乐刷题中,我们遇到了这样一道题目: 题目 写出 三种不同方式的 交换两个整数变量的 函数 交换变量的三种解法 常规方式 想要交换两个变量很简单,第一种方式就是新建一个临时变量,具体流程如下&…...

RocketMQ 知识速览
文章目录 一、消息队列对比二、RocketMQ 基础1. 消息模型2. 技术架构3. 消息类型4. 消费者类型5. 消费者分组和生产者分组 三、RocketMQ 高级1. 如何解决顺序消费和重复消费2. 如何实现分布式事务3. 如何解决消息堆积问题4. 如何保证高性能读写5. 刷盘机制 (topic 模…...

优化 Azure Synapse Dedicated SQL Pool中的 SQL 执行性能的经验方法
在 Azure Synapse Dedicated SQL Pool中优化 SQL 执行涉及了解底层体系结构(例如分布和分区)、查询优化(例如避免不必要的子查询和联接),以及利用具体化视图和 PolyBase 等工具进行高效数据加载。 1.有效使用分布和分…...
)
详解英语单词“pro bono”:公益服务的表达(中英双语)
中文版 详解英语单词“pro bono”:公益服务的表达 一、词义解释 “Pro bono” 是一个源自拉丁语的短语,完整表达为 “pro bono publico”,意思是“为了公众利益”(for the public good)。在现代英语中,它…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

电容损坏深度诊断,从外观到 ESR精准区分容衰与漏电
在 PCB 故障中,电容损坏占比超 40%,是当之无愧的 “头号杀手”。很多工程师仅靠 “鼓包漏液” 判断电容好坏,殊不知80% 的电容损坏是隐性的—— 外观平整但容值衰减、ESR 升高、轻微漏电,导致供电不稳、系统重启、噪声增大&#x…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

什么情况下会核销贷款
贷款核销的核心前提是:贷款被认定为 “损失类” 且经 “穷尽追偿” 仍无法收回,银行按监管与会计规则从账面冲销,但债权不消灭、仍可追偿。一、核心认定条件(满足其一即可)破产 / 注销 / 吊销:借款人和担保…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...
)
为什么你的DeepSeek总漏检重构后代码?4步反混淆预处理法(附LLM辅助去装饰器Python脚本)
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

5分钟掌握res-downloader:跨平台资源下载的终极指南
5分钟掌握res-downloader:跨平台资源下载的终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否经常在…...

在多模型聚合场景下利用Taotoken实现API调用的自动降级与容灾
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型聚合场景下利用Taotoken实现API调用的自动降级与容灾 对于依赖大模型API的生产系统而言,服务的连续性与稳定性…...