朴素贝叶斯分类器
目录
一、生成模型(学习)(Generative Model) vs 判别模型(学习)(Discriminative Model)
1、官方说明
2、通俗理解
3、举例
二、生成学习算法
1、数学符号说明
2、贝叶斯公式
三、朴素贝叶斯分类器
1、离散型特征
特殊情况
2、连续型特征
四、代码实现连续型特证朴素贝叶斯分类器
1、算法流程
2、数据集选择
3、需要安装的 Python 库
4、手动实现(分步骤代码)
1)收集训练样本
2) 计算各类别的先验概率
3) 计算每个类别下各特征属性 的条件概率
4) 计算后验概率并将待分类样本归类到后验概率最大的类别中
5、手动实现(整体代码)
6、使用 sklearn 库实现
一、生成模型(学习)(Generative Model) vs 判别模型(学习)(Discriminative Model)
结论:贝叶斯分类器是生成模型
1、官方说明
生成模型对联合概率 p(x, y)建模, 判别模型对条件概率 p(y | x)进行建模。
2、通俗理解
生成模型重点在于“生成”过程。比如你想做一道菜,生成模型就像是在研究各种食材(x)和菜的口味(y)同时出现的“配方”,它试图去了解整个“烹饪过程”中,食材和口味是如何一起搭配出现的,是从整体上把握“食材+口味”这个组合出现的概率。
判别模型重点在于评判。还是用做菜举例,判别模型就像是在已经知道食材(x)的情况下,去评判这道菜会是什么口味(y)。它不关心整个“烹饪过程”,只关心在给定食材这个前提下,不同口味出现的可能性,是从结果导向的角度,去判断在x出现的情况下,y出现的概率。
3、举例
以水果分类问题为例
判别学习算法:如果我们要找到一条直线把两类水果分开, 这条直线可以称作边界, 边界的两边是不同类别的水果;
生成学习算法:如果我们分别为樱桃和猕猴桃生成一个模型来描述他们的特征, 当要判断一个新的样本是什么水果时, 可以将该样本带入两种水果的模型, 比较看新的样本是更像樱桃还是更像猕猴桃。
二、生成学习算法
以水果分类问题为例
1、数学符号说明
y = 0:样本是樱桃
y = 1:样本是猕猴桃
p(y):类的先验概率, 表示每一类出现的概率。
p(x | y):样本出现的条件概率
- p(x | y=0)对樱桃的特征分布建模,
- p(x | y=1)对猕猴桃的特征分布建模。
p(y | x):类的后验概率
注:
- 先验概率:就是在没看到具体证据之前,基于已有经验或知识对事件发生概率的初步判断。
- 后验概率:就是在看到具体证据之后,结合先验概率和新证据,对事件发生概率的更新判断。
2、贝叶斯公式
计算出样本属于每一类的概率:

分类问题只需要预测类别, 只需要比较样本属于每一类的概率, 选择概率值最大的那一类即可, 因此, 分类器的判别函数表示为:

因为p(y)p(x | y)=p(x , y),而p(x)是一个常数,故贝叶斯公式计算公式计算需要p(x , y)值,它对联合概率进行建模, 与生成模型的定义一致, 因此是生成学习算法
三、朴素贝叶斯分类器
假设特征向量的分量之间相互独立
样本的特征向量 x,根据条件概率公式可知该样本属于某一类ci的概率为:

由于假设特征向量各个分量相互独立, 因此有:

是特征向量 x 的各个分量, p(x)对于所有类别来说都是相等的, 因此用一个常数 Z 来表示。
1、离散型特征
计算公式:

特殊情况
在计算条件概率时, 如果
为 0, 即特征分量的某个取值在某一类训练样本中一次都没出现, 则会导致特征分量取到这个值时的预测函数为 0。 可以使用拉普拉斯平滑(Laplace smoothing) 来处理这种情况。
具体做法就是给分子和分母同时加上一个正整数, 给分子加上 1, 分母加上特征分量取值的 k 种情况,这样就可以保证所有类的条件概率之和还是 1, 并且避免了预测结果为 0 的情况。

类 出现的概率为:

最终分类判别函数可以写成:

2、连续型特征
假设特征向量的分量服从一维正态分布
计算公式:

样本属于某一类 的概率:

最终分类判别函数可以写成:

上述两种特征唯一区别在于计算方法不一样
四、代码实现连续型特证朴素贝叶斯分类器
1、算法流程
(1) 收集训练样本;
(2) 计算各类别的先验概率 ;
(3) 计算每个类别下各特征属性 xj的条件概率 ;
(4) 计算后验概率 ;
(5) 将待分类样本归类到后验概率最大的类别中。
2、数据集选择
iris 数据集。包含 150 个数据样本, 分为 3 类, 每类 50 个数据, 每个数据包含 4个属性, 即特征向量的维数为 4。
3、需要安装的 Python 库
numPy:数值计算库
pandas:数据操作和分析库
sklearn:机器学习的 Python 库
pip install numpy
pip install pandas
pip install scikit-learn4、手动实现(分步骤代码)
1)收集训练样本
def loadData(filepath):""":param filepath: csv:return: list"""data_df = pd.read_csv(filepath)data_list = np.array(data_df) data_list = data_list.tolist() # 将pandas DataFrame转换成Numpy的数组再转换成列表print("Loaded {0} samples successfully.".format(len(data_list)))return data_list# 按ratio比例划分训练集与测试集
def splitData(data_list, ratio):""":param data_list:all data with list type:param ratio: train date's ratio:return: list type of trainset and testset"""train_size = int(len(data_list) * ratio)random.shuffle(data_list) #随机打乱列表元素trainset = data_list[:train_size]testset = data_list[train_size:]return trainset, testset# 按类别划分数据
def seprateByClass(dataset):""":param dataset: train data with list type:return: seprate_dict:separated data by class;info_dict:Number of samples per class(category)"""seprate_dict = {}info_dict = {}for vector in dataset:if vector[-1] not in seprate_dict:seprate_dict[vector[-1]] = []info_dict[vector[-1]] = 0seprate_dict[vector[-1]].append(vector)info_dict[vector[-1]] += 1return seprate_dict, info_dict主函数中调用
data_list = loadData('IrisData.csv')trainset, testset = splitData(data_list, 0.7)dataset_separated, dataset_info = seprateByClass(trainset)2) 计算各类别的先验概率
def calulateClassPriorProb(dataset, dataset_info):"""calculate every class's prior probability:param dataset: train data with list type:param dataset_info: Number of samples per class(category):return: dict type with every class's prior probability"""dataset_prior_prob = {}sample_sum = len(dataset)for class_value, sample_nums in dataset_info.items():dataset_prior_prob[class_value] = sample_nums / float(sample_sum)return dataset_prior_prob主函数中调用
prior_prob = calulateClassPriorProb(trainset, dataset_info)3) 计算每个类别下各特征属性 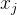 的条件概率
的条件概率
先计算均值和方差
def mean(number_list):number_list = [float(x) for x in number_list] # str to numberreturn sum(number_list) / float(len(number_list))def var(number_list):number_list = [float(x) for x in number_list]avg = mean(number_list)var = sum([math.pow((x - avg), 2) for x in number_list]) / float(len(number_list))return var# 计算每个属性的均值和方差
def summarizeAttribute(dataset):"""calculate mean and var of per attribution in one class:param dataset: train data with list type:return: len(attribution)'s tuple ,that's (mean,var) with per attribution"""dataset = np.delete(dataset, -1, axis=1) # delete label# zip函数将数据样本按照属性分组为一个个列表,然后可以对每个属性计算均值和标准差。summaries = [(mean(attr), var(attr)) for attr in zip(*dataset)]return summaries# 按类别提取数据特征
def summarizeByClass(dataset_separated):"""calculate all class with per attribution:param dataset_separated: data list of per class:return: num:len(class)*len(attribution){class1:[(mean1,var1),(),...],class2:[(),(),...]...}"""summarize_by_class = {}for classValue, vector in dataset_separated.items():summarize_by_class[classValue] = summarizeAttribute(vector)return summarize_by_class #返回的是某类别各属性均值方差的列表主函数中调用 :
summarize_by_class = summarizeByClass(dataset_separated)计算条件概率
def calculateClassProb(input_data, train_Summary_by_class):"""calculate class conditional probability through multiplyevery attribution's class conditional probability per class:param input_data: one sample vectors:param train_Summary_by_class: every class with every attribution's (mean,var):return: dict type , class conditional probability per class of this input data belongs to which class"""prob = {}p = 1for class_value, summary in train_Summary_by_class.items():prob[class_value] = 1for i in range(len(summary)):mean, var = summary[i]x = input_data[i]exponent = math.exp(math.pow((x - mean), 2) / (-2 * var))p = (1 / math.sqrt(2 * math.pi * var)) * exponentprob[class_value] *= preturn prob4) 计算后验概率并将待分类样本归类到后验概率最大的类别中
主函数中使用
# 下面对测试集进行预测correct = 0 # 预测的准确率for vector in testset:input_data = vector[:-1]label = vector[-1]prob = calculateClassProb(input_data, summarize_by_class)result = {}for class_value, class_prob in prob.items():p = class_prob * prior_prob[class_value]result[class_value] = ptype = max(result, key=result.get)print(vector)print(type)if type == label:correct += 1print("predict correct number:{}, total number:{}, correct ratio:{}".format(correct, len(testset), correct / len(testset)))
5、手动实现(整体代码)
# 导入需要用到的库
import pandas as pd
import numpy as np
import random
import math# 载入数据集
def loadData(filepath):""":param filepath: csv:return: list"""data_df = pd.read_csv(filepath)data_list = np.array(data_df) # 将pandas DataFrame转换成Numpy的数组再转换成列表data_list = data_list.tolist()print("Loaded {0} samples successfully.".format(len(data_list)))return data_list# 划分训练集与测试集
def splitData(data_list, ratio):""":param data_list:all data with list type:param ratio: train date's ratio:return: list type of trainset and testset"""train_size = int(len(data_list) * ratio)random.shuffle(data_list) #随机打乱列表元素trainset = data_list[:train_size]testset = data_list[train_size:]return trainset, testset# 按类别划分数据
def seprateByClass(dataset):""":param dataset: train data with list type:return: seprate_dict:separated data by class;info_dict:Number of samples per class(category)"""seprate_dict = {}info_dict = {}for vector in dataset:if vector[-1] not in seprate_dict:seprate_dict[vector[-1]] = []info_dict[vector[-1]] = 0seprate_dict[vector[-1]].append(vector)info_dict[vector[-1]] += 1return seprate_dict, info_dict# 计算先验概率
def calulateClassPriorProb(dataset, dataset_info):"""calculate every class's prior probability:param dataset: train data with list type:param dataset_info: Number of samples per class(category):return: dict type with every class's prior probability"""dataset_prior_prob = {}sample_sum = len(dataset)for class_value, sample_nums in dataset_info.items():dataset_prior_prob[class_value] = sample_nums / float(sample_sum)return dataset_prior_prob# 计算均值的函数
def mean(number_list):number_list = [float(x) for x in number_list] # str to numberreturn sum(number_list) / float(len(number_list))# 计算方差的函数
def var(number_list):number_list = [float(x) for x in number_list]avg = mean(number_list)var = sum([math.pow((x - avg), 2) for x in number_list]) / float(len(number_list))return var# 计算每个属性的均值和方差
def summarizeAttribute(dataset):"""calculate mean and var of per attribution in one class:param dataset: train data with list type:return: len(attribution)'s tuple ,that's (mean,var) with per attribution"""dataset = np.delete(dataset, -1, axis=1) # delete label# zip函数将数据样本按照属性分组为一个个列表,然后可以对每个属性计算均值和标准差。summaries = [(mean(attr), var(attr)) for attr in zip(*dataset)]return summaries# 按类别提取数据特征
def summarizeByClass(dataset_separated):"""calculate all class with per attribution:param dataset_separated: data list of per class:return: num:len(class)*len(attribution){class1:[(mean1,var1),(),...],class2:[(),(),...]...}"""summarize_by_class = {}for classValue, vector in dataset_separated.items():summarize_by_class[classValue] = summarizeAttribute(vector)return summarize_by_class #返回的是某类别各属性均值方差的列表# 计算条件概率
def calculateClassProb(input_data, train_Summary_by_class):"""calculate class conditional probability through multiplyevery attribution's class conditional probability per class:param input_data: one sample vectors:param train_Summary_by_class: every class with every attribution's (mean,var):return: dict type , class conditional probability per class of this input data belongs to which class"""prob = {}p = 1for class_value, summary in train_Summary_by_class.items():prob[class_value] = 1for i in range(len(summary)):mean, var = summary[i]x = input_data[i]exponent = math.exp(math.pow((x - mean), 2) / (-2 * var))p = (1 / math.sqrt(2 * math.pi * var)) * exponentprob[class_value] *= preturn probif __name__ == '__main__':data_list = loadData('IrisData.csv')trainset, testset = splitData(data_list, 0.7)dataset_separated, dataset_info = seprateByClass(trainset)summarize_by_class = summarizeByClass(dataset_separated)prior_prob = calulateClassPriorProb(trainset, dataset_info)# 下面对测试集进行预测correct = 0 # 预测的准确率for vector in testset:input_data = vector[:-1]label = vector[-1]prob = calculateClassProb(input_data, summarize_by_class)result = {}for class_value, class_prob in prob.items():p = class_prob * prior_prob[class_value]result[class_value] = ptype = max(result, key=result.get)print(vector)print(type)if type == label:correct += 1print("predict correct number:{}, total number:{}, correct ratio:{}".format(correct, len(testset), correct / len(testset)))
6、使用 sklearn 库实现
from sklearn import datasets
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载iris数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7)# 初始化朴素贝叶斯分类器(这里使用高斯朴素贝叶斯)
gnb = GaussianNB()
# 使用训练集训练朴素贝叶斯分类器
gnb.fit(X_train, y_train)
# 使用测试集进行预测
y_pred = gnb.predict(X_test)
# 计算预测的准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy: {}".format(accuracy))
相关文章:
朴素贝叶斯分类器
目录 一、生成模型(学习)(Generative Model) vs 判别模型(学习)(Discriminative Model) 1、官方说明 2、通俗理解 3、举例 二、生成学习算法 1、数学符号说明 2、贝叶斯公式 …...

智能化植物病害检测:使用深度学习与图像识别技术的应用
植物病害一直是农业生产中亟待解决的问题,它不仅会影响作物的产量和质量,还可能威胁到生态环境的稳定。随着人工智能(AI)技术的快速发展,尤其是深度学习和图像识别技术的应用,智能化植物病害检测已经成为一…...
)
vim基本命令(vi、工作模式、普通模式、插入模式、可视模式、命令行模式、复制、粘贴、插入、删除、查找、替换)
1. Vim的作用 1.1. 文本编辑 1.1.1. 基础文本编辑功能 Vim是一个功能强大的文本编辑器,它可以用来创建、修改和保存各种文本文件。无论是编写简单的文本笔记,还是复杂的代码文件,Vim都能胜任。例如,我们可以用它来编写Python脚…...

Qt 自动根据编译的dll或exe 将相关dll文件复制到目标文件夹
Qt 自动根据编译的dll或exe 将相关dll文件复制到目标文件夹 如果你在使用 windeployqt 时遇到错误 “windeployqt 不是内部或外部命令”,说明你的命令行环境没有正确配置 Qt 工具路径。windeployqt 是 Qt 工具的一部分,它用于自动将所有必要的 Qt 库和插…...

探索新能源汽车“芯”动力:AUTO TECH China 2025广州国际新能源汽车功率半导体技术展盛况空前
广州,2025年11月20日 —— 在全球新能源车市场蓬勃发展的背景下,AUTO TECH China 2025 广州国际新能源汽车功率半导体技术展览会将于2025年11月20-22日在广州保利世贸博览馆盛大开幕。此次展会作为亚洲领先的车用功率半导体技术专业盛会,本…...

Kafka权威指南(第2版)读书笔记
目录 Kafka生产者——向Kafka写入数据生产者概览创建Kafka生产者bootstrap.serverskey.serializervalue.serializer 发送消息到Kafka同步发送消息 Kafka生产者——向Kafka写入数据 不管是把Kafka作为消息队列、消息总线还是数据存储平台,总是需要一个可以往Kafka写…...

WORD转PDF脚本文件
1、在桌面新建一个文本文件,把下列代码复制到文本文件中。 On Error Resume Next Const wdExportFormatPDF 17 Set oWord WScript.CreateObject("Word.Application") Set fso WScript.CreateObject("Scripting.Filesystemobject") Set fdsf…...

electron 打包后的 exe 文件,运行后是空白窗口
一、代码相关问题 1. 页面加载失败 1.1 原因 在 Electron 应用中,若loadFile或loadURL方法指定的页面路径或 URL 错误,就无法正确加载页面,导致窗口空白。 1.2. 解决 仔细检查loadFile或loadURL方法中传入的路径或 URL 是否正确…...

数据库重连 - 方案
要解决 SQL Server 连接失效后导致的错误问题,可以考虑以下几种解决方案: 1. 连接池机制: 通过实现一个连接池,确保连接失效后可以重新建立连接,而不会直接导致整个程序出错。连接池可以帮助在连接中断时自动恢复连接,而不必每次手动重连。 例如,可以通过以下方式定期…...

从 PostgreSQL 中挽救损坏的表
~/tmp-dir.dab4fd85-8b47-4d9a-b15c-18312ef61075 pg_dump -U postgres -h locathost www_p1 > wow_p1.sqlpg_dump:错误:转储表 “page_views” 的内容失败:PQgetResult() 失败。pg_dump:详细信息:来自服务器的错误…...

【Vue3 入门到实战】1. 创建Vue3工程
目录 编辑 1. 学习目标 2. 环境准备与初始化 3. 项目文件结构 4. 写一个简单的效果 5. 总结 1. 学习目标 (1) 掌握如何创建vue3项目。 (2) 了解项目中的文件的作用。 (3) 编辑App.vue文件,并写一个简单的效果。 2. 环境准备与初始化 (1) 安装 Node.js 和 …...

rtthread学习笔记系列(10/11) -- 系统定时器
文章目录 10. 系统定时器10.1 跳跃表[定时器跳表 (Skip List) 算法](https://www.rt-thread.org/document/site/#/rt-thread-version/rt-thread-standard/programming-manual/timer/timer?id定时器跳表-skip-list-算法) 10.2 硬件定时器10.2.1 初始化&&删除10.2.2 sta…...

mock服务-通过json定义接口自动实现mock服务
go-mock介绍 不管在前端还是后端开发过程中,当我们需要联调其他服务的接口,而这个服务还没法提供调用时,那我们就要用到mock服务,自己按接口文档定义一个临时接口返回指定数据,以供本地开发联调测试。 怎么快速启动一…...

像JSONDecodeError: Extra data: line 2 column 1 (char 134)这样的问题怎么解决
问题介绍 今天处理返回的 JSON 的时候,出现了下面这样的问题: 处理这种问题的时候,首先你要看一下当前的字符串格式是啥样的,比如我查看后发现是下面这样的: 会发现这个字符串中间没有逗号,也就是此时的J…...

C#版 软件开发6大原则与23种设计模式
开发原则和设计模式一直是软件开发中的圣经, 但是这仅仅适用于中大型的项目开发, 在小型项目的开发中, 这些规则会降低你的开发效率, 使你的工程变得繁杂. 所以只有适合你的才是最好的. 设计模式六大原则1. 单一职责原则(Single Responsibility Principle࿰…...

java8 springboot 集成javaFx 实现一个客户端程序
1. 先创建一个springboot 程序(此步骤不做流程展示) 2. 更改springboot的版本依赖和导入所需依赖 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.7</versio…...

MySQL(高级特性篇) 06 章——索引的数据结构
一、为什么使用索引 索引是存储引擎用于快速找到数据记录的一种数据结构,就好比一本教科书的目录部分,通过目录找到对应文章的页码,便可快速定位到需要的文章。MySQL中也是一样的道理,进行数据查找时,首先查看查询条件…...

PanWeidb-使用BenchmarkSQL对磐维数据库进行压测
本文提供PanweiDb使用BenchmarkSQL进行性能测试的方法和测试数据报告。 BenchmarkSQL,一个JDBC基准测试工具,内嵌了TPC-C测试脚本,支持很多数据库,如PostgreSQL、Oracle和Mysql等。 TPC-C是专门针对联机交易处理系统(OLTP系统)的规范,一般情况下我们也把这类系统称为业…...

AR 在高校实验室安全教育中的应用
AR应用APP可以内置实验室安全功能介绍,学习并考试(为满足教育部关于实验室人员准入条件),AR主模块。其中AR主模块应该包括图形标识码的扫描,生成相应模型,或者火灾、逃生等应急处置的路线及动画演示。考试采…...

微信小程序实现个人中心页面
文章目录 1. 官方文档教程2. 编写静态页面3. 关于作者其它项目视频教程介绍 1. 官方文档教程 https://developers.weixin.qq.com/miniprogram/dev/framework/ 2. 编写静态页面 mine.wxml布局文件 <!--index.wxml--> <navigation-bar title"个人中心" ba…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

echarts中heatmap鼠标滚动禁用缩放,向下滚动
配置如下效果如下...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

长期使用Token Plan套餐在项目开发中的成本观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在项目开发中的成本观察 在AI驱动的项目开发中,成本控制与预算管理是团队负责人必须面对的现实…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...

如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程
如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 在游戏开发、硬件调试和嵌入式系统研究中,与游戏手柄等专业输入设备进行深度交互一直…...