Elasticsearch实战指南:从入门到高效使用
Elasticsearch实战指南:从入门到高效使用
1. 引言:Elasticsearch是什么?
Elasticsearch是一个分布式、RESTful风格的搜索和分析引擎,广泛应用于全文搜索、日志分析、实时数据分析等场景。它的核心特点包括:
- 高性能:支持海量数据的快速检索。
- 分布式:易于扩展,支持高可用性。
- 灵活:支持结构化、非结构化数据的搜索和分析。
今天,我们将从安装配置到实际应用,带你全面掌握Elasticsearch。
2. 安装与配置
2.1 安装Elasticsearch
以下是在Linux系统上安装Elasticsearch的步骤:
- 下载并解压:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.15.2-linux-x86_64.tar.gz tar -xzf elasticsearch-7.15.2-linux-x86_64.tar.gz cd elasticsearch-7.15.2/ - 启动Elasticsearch:
./bin/elasticsearch - 验证安装:
访问http://localhost:9200,如果看到以下信息,说明安装成功:{"name" : "your-node-name","cluster_name" : "elasticsearch","version" : {"number" : "7.15.2"} }
2.2 安装Kibana
Kibana是Elasticsearch的可视化工具,用于数据探索和可视化。
- 下载并解压:
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.15.2-linux-x86_64.tar.gz tar -xzf kibana-7.15.2-linux-x86_64.tar.gz cd kibana-7.15.2-linux-x86_64/ - 启动Kibana:
./bin/kibana - 访问Kibana:
打开浏览器,访问http://localhost:5601。
3. 核心概念
3.1 索引(Index)
索引是Elasticsearch中存储数据的地方,类似于数据库中的表。
3.2 文档(Document)
文档是索引中的基本数据单元,类似于表中的一行记录。
3.3 映射(Mapping)
映射定义了索引中字段的类型和属性,类似于表结构。
3.4 分片与副本
- 分片(Shard):索引被分成多个分片,分布在不同节点上。
- 副本(Replica):每个分片可以有多个副本,用于提高可用性和性能。
4. 基本操作
4.1 创建索引
curl -X PUT "localhost:9200/my_index" -H 'Content-Type: application/json' -d'
{"settings": {"number_of_shards": 3,"number_of_replicas": 1}
}'
4.2 添加文档
curl -X POST "localhost:9200/my_index/_doc/1" -H 'Content-Type: application/json' -d'
{"name": "John","age": 25,"city": "New York"
}'
4.3 查询文档
curl -X GET "localhost:9200/my_index/_search" -H 'Content-Type: application/json' -d'
{"query": {"match": {"city": "New York"}}
}'
4.4 删除索引
curl -X DELETE "localhost:9200/my_index"
5. 高级查询技巧
5.1 全文搜索
使用match查询进行全文搜索:
{"query": {"match": {"description": "quick brown fox"}}
}
5.2 精确匹配
使用term查询进行精确匹配:
{"query": {"term": {"status": "active"}}
}
5.3 范围查询
使用range查询进行范围过滤:
{"query": {"range": {"age": {"gte": 18,"lte": 30}}}
}
5.4 聚合查询
使用aggregations进行数据分析:
{"aggs": {"avg_age": {"avg": {"field": "age"}}}
}
6. 实战案例:日志分析
6.1 需求描述
我们需要分析Nginx日志,统计每个IP的访问次数和总流量。
6.2 数据准备
假设Nginx日志已经导入Elasticsearch,索引名为nginx_logs。
6.3 查询实现
{"size": 0,"aggs": {"group_by_ip": {"terms": {"field": "client_ip.keyword"},"aggs": {"total_bytes": {"sum": {"field": "bytes_sent"}}}}}
}
6.4 查询结果
{"aggregations": {"group_by_ip": {"buckets": [{"key": "192.168.1.1","doc_count": 100,"total_bytes": {"value": 102400}},{"key": "192.168.1.2","doc_count": 80,"total_bytes": {"value": 81920}}]}}
}
7. 性能优化技巧
7.1 合理设置分片和副本
- 分片数应根据数据量和集群规模设置,通常每个分片大小控制在10GB-50GB。
- 副本数可以提高可用性,但会增加存储和计算开销。
7.2 使用批量操作
批量操作可以减少网络开销,提升写入性能。
curl -X POST "localhost:9200/my_index/_bulk" -H 'Content-Type: application/json' -d'
{ "index" : { "_id" : "1" } }
{ "name": "John", "age": 25 }
{ "index" : { "_id" : "2" } }
{ "name": "Alice", "age": 30 }
'
7.3 使用索引模板
索引模板可以自动为新索引应用预定义的设置和映射。
PUT _template/my_template
{"index_patterns": ["logs-*"],"settings": {"number_of_shards": 3,"number_of_replicas": 1},"mappings": {"properties": {"timestamp": { "type": "date" },"message": { "type": "text" }}}
}
8. 总结
Elasticsearch是一个功能强大的搜索和分析引擎,广泛应用于日志分析、全文搜索、实时数据分析等场景。通过掌握其核心概念、基本操作和高级查询技巧,我们可以轻松应对各种数据处理需求。
相关文章:

Elasticsearch实战指南:从入门到高效使用
Elasticsearch实战指南:从入门到高效使用 1. 引言:Elasticsearch是什么? Elasticsearch是一个分布式、RESTful风格的搜索和分析引擎,广泛应用于全文搜索、日志分析、实时数据分析等场景。它的核心特点包括: 高性能&…...

Open FPV VTX开源之嵌入式OSD配置
Open FPV VTX开源之嵌入式OSD配置 1. 源由2. 安装3. 配置步骤一:备份/etc/telemetry.conf步骤二:修改/etc/telemetry.conf步骤三:配置时区步骤四:重启摄像头 4. 实测5. 参考资料 1. 源由 穿越机模拟图传延迟通常在10ms左右。 最…...

2Hive表类型
2Hive表类型 1 Hive 数据类型2 Hive 内部表3 Hive 外部表4 Hive 分区表5 Hive 分桶表6 Hive 视图 1 Hive 数据类型 Hive的基本数据类型有:TINYINT,SAMLLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE&a…...
)
计算机网络之---公钥基础设施(PKI)
公钥基础设施 公钥基础设施(PKI,Public Key Infrastructure) 是一种用于管理公钥加密的系统架构,它通过结合硬件、软件、策略和标准来确保数字通信的安全性。PKI 提供了必要的框架,用于管理密钥对(包括公钥…...

EF Core执行原生SQL语句
目录 EFCore执行非查询原生SQL语句 为什么要写原生SQL语句 执行非查询SQL语句 有SQL注入漏洞 ExecuteSqlInterpolatedAsync 其他方法 执行实体相关查询原生SQL语句 FromSqlInterpolated 局限性 执行任意原生SQL查询语句 什么时候用ADO.NET 执行任意SQL Dapper 总…...

GaussDB分布式数据倾斜处理
常规数据倾斜巡检 在库中表个数少于1W的场景,直接使用倾斜视图查询当前库内所有表的数据倾斜情况 SELECT * FROM pgxc_get_table_skewness ORDER BY totalsize DESC;在库中表个数非常多(至少大于1W)的场景,因PGXC_GET_TABLE_SKEWN…...

代码随想录Day34 | 62.不同路径,63.不同路径II,343.整数拆分,96.不同的二叉搜索树
代码随想录Day34 | 62.不同路径,63.不同路径II,343.整数拆分,96.不同的二叉搜索树 62.不同路径 动态规划第二集: 比较标准简单的一道动态规划,状态转移方程容易想到 难点在于空间复杂度的优化,详见代码 class Solution {public int uniq…...

vue.js辅助函数-mapMutations
在Vue.js中,使用辅助函数可以更方便地使用Vuex的mutation。而mapMutations就是Vuex提供的一个辅助函数,它可以将mutation映射到组件的methods中,使得我们可以在组件中直接调用mutation,而不需要手动进行commit。 mapMutations函数…...

Vue3组件设计模式:高可复用性组件开发实战
Vue3组件设计模式:高可复用性组件开发实战 一、前言 在Vue3中,组件设计和开发是非常重要的,它直接影响到应用的可维护性和可复用性。本文将介绍如何利用Vue3组件设计模式来开发高可复用性的组件,让你的组件更加灵活和易于维护。 二、单一职责…...

PHP 8.4 安装和升级指南
文章精选推荐 1 JetBrains Ai assistant 编程工具让你的工作效率翻倍 2 Extra Icons:JetBrains IDE的图标增强神器 3 IDEA插件推荐-SequenceDiagram,自动生成时序图 4 BashSupport Pro 这个ides插件主要是用来干嘛的 ? 5 IDEA必装的插件&…...

什么是 OpenResty
1、OpenResty简介 1.1 了解OpenResty OpenResty是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。 简单地说OpenRes…...
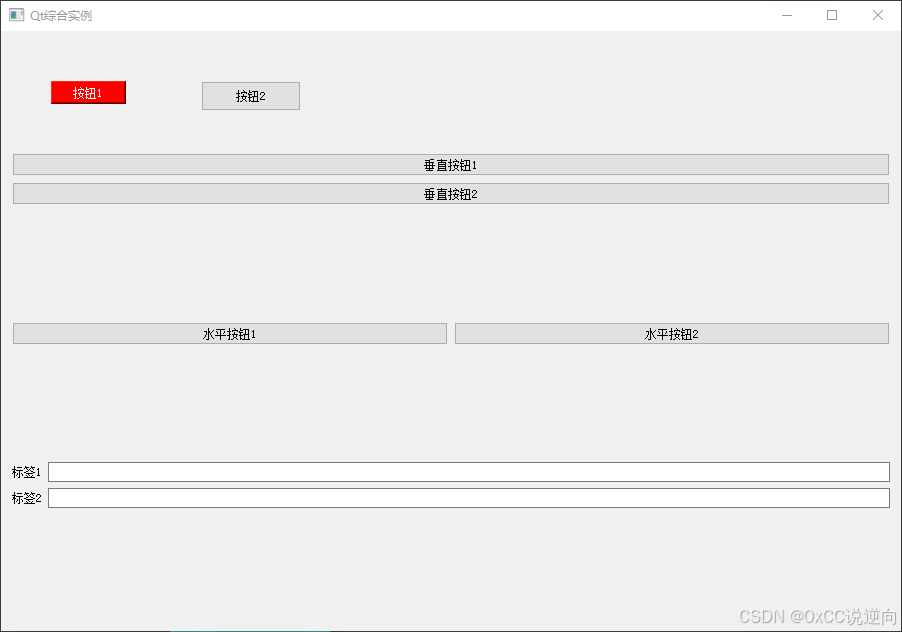
Windows图形界面(GUI)-QT-C/C++ - QT控件创建管理初始化
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 控件创建 包含对应控件类型头文件 实例化控件类对象 控件设置 设置父控件 设置窗口标题 设置控件大小 设置控件坐标 设置文本颜色和背景颜色 控件排版 垂直布局 QVBoxLayout …...

【计算机网络】lab8 DNS协议
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀计算机网络_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 1. 前言 2.…...

了解linux中的“of_property_read_u32()”
of_property_read_u32(node, "post-pwm-on-delay-ms",&data->post_pwm_on_delay); /*根据"post-pwm-on-delay-ms",从属性中查找并读取一个32位整数*/ /*读到一个32位整数,保存到data->post_pwm_on_delay中*/ of_property_read_u32…...

iOS - Objective-C 底层中的内存屏障
1. 基本实现 // objc-os.h 中的内存屏障实现 #define OSMemoryBarrier() __sync_synchronize()// ARM 架构特殊处理 static ALWAYS_INLINE void OSMemoryBarrierBeforeUnlock() { #if defined(__arm__) || defined(__arm64__)OSMemoryBarrier(); #endif } 2. 解锁前的内存屏…...

阿里云服务器扩容系统盘后宝塔面板不显示扩容后的大小
解决方法步骤: 1. yum install cloud-utils-growpart xfsprogs -y 2.growpart /dev/vda 3 扩容系统盘的第3个分区 主要是这个命令1 3. fdisk -l 4. df -h 5. xfs_growfs /dev/vda3 主要是这个命令2 主要使用 df -Th 这个命令查看对应的文件系统类型 (1)、ext…...

c语言——【linux】多进程编程 【进程的创建,相关shell指令,进程状态切换,回收资源,守护进程等】
1.思维导图 2.进程的创建 函数原型:pid_t fork(void); 功能描述:以当前进程为父进程,创建一个子进程 进程链和进程扇的创建 3.多进程具体使用 3.1进程替换 exec 函数一族 int execl(const char *path, const char *arg, ... /* (char *) N…...

macos 搭建 ragflow 开发环境
ragflow 是一个很方便的本地 RAG 库。本文主要记录一下在本机的部署过程 1、总体架构说明 开发环境:macbook pro(m1),16G内存 512G固态 因本机的内存和硬盘比较可怜,所以在服务器上部署基础 docker 包,…...

信创改造-龙蜥操作系统搭载MySql、Tomcat等服务
龙蜥操作系统 Anolis OS 8 是 OpenAnolis 社区推出的完全开源、中立、开放的发行版,它支持多计算架构,也面向云端场景优化,兼容 CentOS 软件生态。Anolis OS 8 旨在为广大开发者和运维人员提供稳定、高性能、安全、可靠、开源的操作系统服务。…...

Java 数据结构 队列之双端队列 常用方法 示例代码 及其实现
目录 常用方法 示例代码 常见实现 Java中的双端队列(Deque,Double Ended Queue)是一种队列,它允许在队列的两端插入和删除元素。与普通队列(FIFO)不同,双端队列的元素可以从队列的两端进行添…...
)
从一次生产事故复盘:我们如何优雅地处理用户上传的‘异常’Excel文件(附Apache POI配置详解)
从生产事故到防御体系:构建Excel文件处理的工程化解决方案那天凌晨2点,我被一阵急促的告警声惊醒。监控系统显示,核心文件处理服务的错误率在10分钟内飙升到35%,大量用户上传的Excel文件无法正常解析。更糟糕的是,部分…...

机器学习与深度学习在地球物理勘探中的应用:基于电阻率数据预测极化率模型
1. 项目概述与核心价值在花岗岩这类地质条件复杂的地区搞勘探,最头疼的就是地下情况“看不清”。传统的电阻率(ERT)和激发极化(IP)联合反演,就像用一把刻度模糊的尺子去量一块表面坑洼不平的石头——面对高…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

别再把大模型当搜索框了:一文讲透 LLM 的基本原理、能力边界与局限性
写在前面很多人把大语言模型当成“会聊天的搜索引擎”,结果一上线就遇到幻觉、口径不稳、上下文丢失、成本失控。真正理解 LLM,要先抓住一句话:它是基于 Transformer 的概率生成模型,核心能力来自海量预训练、上下文学习与后训练对…...

观察不同模型在统一 API 下的响应速度与输出风格差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在统一 API 下的响应速度与输出风格差异 在为大语言模型应用选择模型时,开发者通常会关注两个核心维度&am…...

UnityExplorer:如何在游戏运行时实时调试和修改Unity项目
UnityExplorer:如何在游戏运行时实时调试和修改Unity项目 【免费下载链接】UnityExplorer An in-game UI for exploring, debugging and modifying IL2CPP and Mono Unity games. 项目地址: https://gitcode.com/gh_mirrors/un/UnityExplorer UnityExplorer是…...