深度学习电影推荐-CNN算法

文章目录
- 前言
- 视频演示效果
- 1.数据集
- 环境配置安装教程与资源说明
- 1.1 ML-1M 数据集概述
- 1.1.1数据集内容
- 1.1.2. 数据集规模
- 1.1.3. 数据特点
- 1.1.4. 文件格式
- 1.1.5. 应用场景
- 2.模型架构
- 3.推荐实现
- 3.1 用户数据
- 3.2 电影数据
- 3.3 评分数据
- 3.4 数据预处理
- 3.5实现数据预处理
- 3.6 加载数据并保存到本地
- 3.7从本地读取数据
- 4 模型设计
- 4.1 概述
- 4.2 文本卷积网络
- 辅助函数
- 构建神经网络
- 定义User的嵌入矩阵
- 将User的嵌入矩阵一起全连接生成User的特征
- 定义Movie ID的嵌入矩阵
- 对电影类型的多个嵌入向量做加和
- Movie Title的文本卷积网络实现
- 将Movie的各个层一起做全连接
- 生成Movie特征矩阵
- 生成User特征矩阵
- 开始推荐电影
- 结论
前言
随着互联网和流媒体平台的快速发展,用户可以随时访问海量的电影资源。然而,如何帮助用户在繁杂的选择中快速找到符合其兴趣的电影,成为了一个重要且具有挑战性的问题。推荐系统作为解决信息过载的重要工具,在电影行业得到了广泛应用。近年来,深度学习技术的崛起为推荐系统的构建提供了新的方法和更高的精度,其强大的特征提取能力和非线性建模能力使电影推荐系统更加智能化和个性化。
MovieLens 1M(简称 ML-1M)是电影推荐领域最常用的公开数据集之一,包含约6000名用户对3900多部电影的100万条评分记录。该数据集提供了用户的基本信息(如年龄、性别、职业等)、电影的元数据(如标题、类型、年份等)以及用户对电影的评分。这些信息为电影推荐系统的研究提供了丰富的实验数据。基于 ML-1M 数据集,研究者可以开发和验证各种推荐算法,同时通过标准化的数据便于不同方法的横向比较。
传统的推荐方法,如基于协同过滤和矩阵分解的技术,在处理稀疏数据和冷启动问题时表现有限。而深度学习方法以其在高维数据中的强大建模能力,能够挖掘用户和电影之间的复杂非线性关系,并捕捉多模态数据的深层特征。例如,通过神经网络构建用户和电影的嵌入向量,深度学习方法可以对用户行为和电影内容进行联合建模;通过融合用户的评分历史和电影的文本信息、图像特征等多源数据,可以显著提升推荐结果的精准度和多样性。
本研究以 ML-1M 数据集为基础,探索深度学习技术在电影推荐中的应用。研究目标包括:构建高效的深度学习模型,挖掘用户行为模式;融合电影的多模态信息,提升推荐系统的准确性;以及优化推荐策略,为用户提供个性化的观影建议。本研究不仅具有理论意义,也为实际推荐系统的开发提供了宝贵的参考。
视频演示效果
深度学习实战电影推荐系统
觉得不错的小伙伴,感谢点赞、关注加收藏哦!更多干货内容持续更新…
1.数据集
环境配置安装教程与资源说明

离线安装配置文件说明
1.1 ML-1M 数据集概述
MovieLens 1M(简称 ML-1M)数据集是由明尼苏达大学的 GroupLens 研究团队发布的一个电影推荐系统研究数据集,是推荐算法开发和评估领域的经典数据集之一。该数据集包含 100 万条电影评分记录,为研究电影推荐系统提供了标准化和高质量的数据资源。以下是 ML-1M 数据集的详细概述:
1.1.1数据集内容
ML-1M 数据集包括以下几部分信息:
- 用户数据:
- 用户唯一 ID。
- 性别(Male 或 Female)。
- 年龄段(如 18-24、25-34 等)。
- 职业编号(对应具体职业类别)。
- 电影数据:
- 电影唯一 ID。
- 电影标题及其上映年份。
- 电影的分类标签(如动作、喜剧、科幻等)。
- 评分数据:
- 用户对电影的评分,范围为 1 到 5 的整数。
- 评分的时间戳,用于分析评分的时间分布和用户行为模式。
1.1.2. 数据集规模
- 用户数量:6,040 名用户。
- 电影数量:3,900 多部电影。
- 评分数量:1,000,209 条评分。
1.1.3. 数据特点
- 稀疏性:尽管数据集包含大量评分记录,但与可能的评分总量相比(即用户数 × 电影数),实际评分所占比例较小,表现出典型的稀疏性问题。
- 时间维度:评分记录带有时间戳信息,可以分析用户行为的时间动态。
- 多样性:用户和电影的元数据涵盖了性别、年龄、职业、类型等多个维度,为推荐算法提供了丰富的上下文信息。
1.1.4. 文件格式
ML-1M 数据集通常以分隔符文本文件(如 CSV 或 TXT)形式存储,包括以下文件:
users.dat:包含用户的基本信息。movies.dat:包含电影的基本信息。ratings.dat:包含用户的评分记录。
1.1.5. 应用场景
ML-1M 数据集广泛应用于以下研究方向:
- 推荐系统算法开发:用于测试协同过滤、矩阵分解、深度学习等推荐算法的性能。
- 用户行为建模:分析用户的观影习惯、兴趣动态和评分模式。
- 冷启动问题研究:通过新用户或新电影的推荐,解决数据稀疏性问题。
- 多模态融合:结合文本、图像、时间序列等信息,优化推荐效果。
ML-1M 数据集因其数据结构清晰和实验价值高,成为推荐系统研究的重要基准,许多先进的算法和模型均在该数据集上进行了验证。
2.模型架构


3.推荐实现
本项目使用的是MovieLens 1M 数据集,包含6000个用户在近4000部电影上的1亿条评论。
数据集分为三个文件:用户数据users.dat,电影数据movies.dat和评分数据ratings.dat。
3.1 用户数据
分别有用户ID、性别、年龄、职业ID和邮编等字段。
数据中的格式:UserID::Gender::Age::Occupation::Zip-code
-
Gender is denoted by a “M” for male and “F” for female
-
Age is chosen from the following ranges:
- 1: “Under 18”
- 18: “18-24”
- 25: “25-34”
- 35: “35-44”
- 45: “45-49”
- 50: “50-55”
- 56: “56+”
-
Occupation is chosen from the following choices:
- 0: “other” or not specified
- 1: “academic/educator”
- 2: “artist”
- 3: “clerical/admin”
- 4: “college/grad student”
- 5: “customer service”
- 6: “doctor/health care”
- 7: “executive/managerial”
- 8: “farmer”
- 9: “homemaker”
- 10: “K-12 student”
- 11: “lawyer”
- 12: “programmer”
- 13: “retired”
- 14: “sales/marketing”
- 15: “scientist”
- 16: “self-employed”
- 17: “technician/engineer”
- 18: “tradesman/craftsman”
- 19: “unemployed”
- 20: “writer”
users_title = [‘UserID’, ‘Gender’, ‘Age’, ‘OccupationID’, ‘Zip-code’]
users = pd.read_table(‘./ml-1m/users.dat’, sep=‘::’, header=None, names=users_title, engine = ‘python’)
users.head()
可以看出UserID、Gender、Age和Occupation都是类别字段,其中邮编字段是我们不使用的。
3.2 电影数据
分别有电影ID、电影名和电影风格等字段。
数据中的格式:MovieID::Title::Genres
-
Titles are identical to titles provided by the IMDB (including
year of release) -
Genres are pipe-separated and are selected from the following genres:
- Action
- Adventure
- Animation
- Children’s
- Comedy
- Crime
- Documentary
- Drama
- Fantasy
- Film-Noir
- Horror
- Musical
- Mystery
- Romance
- Sci-Fi
- Thriller
- War
- Western
movies_title = [‘MovieID’, ‘Title’, ‘Genres’]
movies = pd.read_table(‘./ml-1m/movies.dat’, sep=‘::’, header=None, names=movies_title, engine = ‘python’)
movies.head()
MovieID是类别字段,Title是文本,Genres也是类别字段
3.3 评分数据
分别有用户ID、电影ID、评分和时间戳等字段。
数据中的格式:UserID::MovieID::Rating::Timestamp
- UserIDs range between 1 and 6040
- MovieIDs range between 1 and 3952
- Ratings are made on a 5-star scale (whole-star ratings only)
- Timestamp is represented in seconds since the epoch as returned by time(2)
- Each user has at least 20 ratings
ratings_title = [‘UserID’,‘MovieID’, ‘Rating’, ‘timestamps’]
ratings = pd.read_table(‘./ml-1m/ratings.dat’, sep=‘::’, header=None, names=ratings_title, engine = ‘python’)
ratings.head()
评分字段Rating就是我们要学习的targets,时间戳字段我们不使用。
3.4 数据预处理
- UserID、Occupation和MovieID不用变。
- Gender字段:需要将‘F’和‘M’转换成0和1。
- Age字段:要转成7个连续数字0~6。
- Genres字段:是分类字段,要转成数字。首先将Genres中的类别转成字符串到数字的字典,然后再将每个电影的Genres字段转成数字列表,因为有些电影是多个Genres的组合。
- Title字段:处理方式跟Genres字段一样,首先创建文本到数字的字典,然后将Title中的描述转成数字的列表。另外Title中的年份也需要去掉。
- Genres和Title字段需要将长度统一,这样在神经网络中方便处理。空白部分用‘< PAD >’对应的数字填充。
3.5实现数据预处理
def load_data():"""Load Dataset from File"""#读取User数据users_title = ['UserID', 'Gender', 'Age', 'JobID', 'Zip-code']users = pd.read_table('./ml-1m/users.dat', sep='::', header=None, names=users_title, engine = 'python')# 保留以下特征users = users.filter(regex='UserID|Gender|Age|JobID')users_orig = users.values#改变User数据中性别和年龄gender_map = {'F':0, 'M':1}users['Gender'] = users['Gender'].map(gender_map)age_map = {val:ii for ii,val in enumerate(set(users['Age']))}users['Age'] = users['Age'].map(age_map)#读取Movie数据集movies_title = ['MovieID', 'Title', 'Genres']movies = pd.read_table('./ml-1m/movies.dat', sep='::', header=None, names=movies_title, engine = 'python')movies_orig = movies.values#将Title中的年份去掉pattern = re.compile(r'^(.*)\((\d+)\)$')title_map = {val:pattern.match(val).group(1) for ii,val in enumerate(set(movies['Title']))}movies['Title'] = movies['Title'].map(title_map)#电影类型转数字字典genres_set = set()for val in movies['Genres'].str.split('|'):genres_set.update(val)genres_set.add('<PAD>')# 将类型进行编号genres2int = {val:ii for ii, val in enumerate(genres_set)}#将电影类型转成等长数字列表genres_map = {val:[genres2int[row] for row in val.split('|')] for ii,val in enumerate(set(movies['Genres']))}# 将每个样本的电影类型数字列表处理成相同长度,长度不够用<PAD>填充for key in genres_map:for cnt in range(max(genres2int.values()) - len(genres_map[key])):genres_map[key].insert(len(genres_map[key]) + cnt,genres2int['<PAD>'])movies['Genres'] = movies['Genres'].map(genres_map)#电影Title转数字字典title_set = set()for val in movies['Title'].str.split():title_set.update(val)title_set.add('<PAD>')title2int = {val:ii for ii, val in enumerate(title_set)}#将电影Title转成等长数字列表,长度是15title_count = 15title_map = {val:[title2int[row] for row in val.split()] for ii,val in enumerate(set(movies['Title']))}for key in title_map:for cnt in range(title_count - len(title_map[key])):title_map[key].insert(len(title_map[key]) + cnt,title2int['<PAD>'])movies['Title'] = movies['Title'].map(title_map)#读取评分数据集ratings_title = ['UserID','MovieID', 'ratings', 'timestamps']ratings = pd.read_table('./ml-1m/ratings.dat', sep='::', header=None, names=ratings_title, engine = 'python')ratings = ratings.filter(regex='UserID|MovieID|ratings')#合并三个表data = pd.merge(pd.merge(ratings, users), movies)#将数据分成X和y两张表target_fields = ['ratings']features_pd, targets_pd = data.drop(target_fields, axis=1), data[target_fields]features = features_pd.valuestargets_values = targets_pd.valuesreturn title_count, title_set, genres2int, features, targets_values, ratings, users, movies, data, movies_orig, users_orig
3.6 加载数据并保存到本地
- title_count:Title字段的长度(15)
- title_set:Title文本的集合
- genres2int:电影类型转数字的字典
- features:是输入X
- targets_values:是学习目标y
- ratings:评分数据集的Pandas对象
- users:用户数据集的Pandas对象
- movies:电影数据的Pandas对象
- data:三个数据集组合在一起的Pandas对象
- movies_orig:没有做数据处理的原始电影数据
- users_orig:没有做数据处理的原始用户数据
title_count, title_set, genres2int, features, targets_values, \ratings, users, movies, data, movies_orig, users_orig = load_data()with open('./processed_data/preprocess.pkl', 'wb') as f:pickle.dump((title_count, title_set, genres2int, features, targets_values, ratings, users, movies, data, movies_orig, users_orig), f)
3.7从本地读取数据
with open('./processed_data/preprocess.pkl', mode='rb') as f:title_count, title_set, genres2int, features, \targets_values, ratings, users, movies, data, movies_orig, users_orig = pickle.load(f)4 模型设计
4.1 概述
通过研究数据集中的字段类型,我们发现有一些是类别字段,通常的处理是将这些字段转成one hot编码,但是像UserID、MovieID这样的字段就会变成非常的稀疏,输入的维度急剧膨胀,
所以在预处理数据时将这些字段转成了数字,我们用这个数字当做嵌入矩阵的索引,在网络的第一层使用了嵌入层,维度是(N,32)和(N,16)。
这里的思想其实和 word2vec 比较类似。我们会对用户或者电影的每个属性都指定一个特征维度空间,这就好比我们在自然语言处理中对每个单词指定特征维度空间。从下面的代码中可以看到,我们将用到的属性的特征维度设置为了 32 或者 16.
电影类型的处理要多一步,有时一个电影有多个电影类型,这样从嵌入矩阵索引出来是一个(n,32)的矩阵,因为有多个类型嘛,我们要将这个矩阵求和,变成(1,32)的向量。
电影名的处理比较特殊,没有使用循环神经网络,而是用了文本卷积网络,下文会进行说明。
从嵌入层索引出特征以后,将各特征传入全连接层,将输出再次传入全连接层,最终分别得到(1,200)的用户特征和电影特征两个特征向量。
我们的目的就是要训练出用户特征和电影特征,在实现推荐功能时使用。得到这两个特征以后,就可以选择任意的方式来拟合评分了。我使用了两种方式,一个是上图中画出的将两个特征做向量乘法,将结果与真实评分做回归,采用MSE优化损失。因为本质上这是一个回归问题,另一种方式是,将两个特征作为输入,再次传入全连接层,输出一个值,将输出值回归到真实评分,采用MSE优化损失。
实际上第二个方式的MSE loss在0.8附近,第一个方式在1附近,5次迭代的结果。
4.2 文本卷积网络
将卷积神经网络用于文本,网络的第一层是词嵌入层,由每一个单词的嵌入向量组成的嵌入矩阵。下一层使用多个不同尺寸(窗口大小)的卷积核在嵌入矩阵上做卷积,窗口大小指的是每次卷积覆盖几个单词。这里跟对图像做卷积不太一样,图像的卷积通常用2x2、3x3、5x5之类的尺寸,而文本卷积要覆盖整个单词的嵌入向量,所以尺寸是(单词数,向量维度),比如每次滑动3个,4个或者5个单词。第三层网络是max pooling得到一个长向量,最后使用dropout做正则化,最终得到了电影Title的特征。
辅助函数
import tensorflow as tf
import os
import pickledef save_params(params):"""Save parameters to file"""with open('params.p', 'wb') as f:pickle.dump(params, f)def load_params():"""Load parameters from file"""with open('params.p', mode='rb') as f:return pickle.load(f)
构建神经网络
定义User的嵌入矩阵
def get_user_embedding(uid, user_gender, user_age, user_job):with tf.name_scope("user_embedding"):# 下面的操作和情感分析项目中的单词转换为词向量的操作本质上是一样的# 用户的特征维度设置为 32# 先初始化一个非常大的用户矩阵# tf.random_uniform 的第二个参数是初始化的最小值,这里是-1,第三个参数是初始化的最大值,这里是1uid_embed_matrix = tf.Variable(tf.random_uniform([uid_max, embed_dim], -1, 1), name = "uid_embed_matrix")# 根据指定用户ID找到他对应的嵌入层uid_embed_layer = tf.nn.embedding_lookup(uid_embed_matrix, uid, name = "uid_embed_layer")# 性别的特征维度设置为 16
将User的嵌入矩阵一起全连接生成User的特征
def get_user_feature_layer(uid_embed_layer, gender_embed_layer, age_embed_layer, job_embed_layer):with tf.name_scope("user_fc"):#第一层全连接# tf.layers.dense 的第一个参数是输入,第二个参数是层的单元的数量uid_fc_layer = tf.layers.dense(uid_embed_layer, embed_dim, name = "uid_fc_layer", activation=tf.nn.relu)gender_fc_layer = tf.layers.dense(gender_embed_layer, embed_dim, name = "gender_fc_layer", activation=tf.nn.relu)age_fc_layer = tf.layers.dense(age_embed_layer, embed_dim, name ="age_fc_layer", activation=tf.nn.relu)job_fc_layer = tf.layers.dense(job_embed_layer, embed_dim, name = "job_fc_layer", activation=tf.nn.relu)#第二层全连接# 将上面的每个分段组成一个完整的全连接层user_combine_layer = tf.concat([uid_fc_layer, gender_fc_layer, age_fc_layer, job_fc_layer], 2) #(?, 1, 128)# 验证上面产生的 tensorflow 是否是 128 维度的print(user_combine_layer.shape)# tf.contrib.layers.fully_connected 的第一个参数是输入,第二个参数是输出# 这里的输入是user_combine_layer,输出是200,是指每个用户有200个特征# 相当于是一个200个分类的问题,每个分类的可能性都会输出,在这里指的就是每个特征的可能性user_combine_layer = tf.contrib.layers.fully_connected(user_combine_layer, 200, tf.tanh) #(?, 1, 200)user_combine_layer_flat = tf.reshape(user_combine_layer, [-1, 200])return user_combine_layer, user_combine_layer_flat
定义Movie ID的嵌入矩阵
def get_movie_id_embed_layer(movie_id):with tf.name_scope("movie_embedding"):movie_id_embed_matrix = tf.Variable(tf.random_uniform([movie_id_max, embed_dim], -1, 1), name = "movie_id_embed_matrix")movie_id_embed_layer = tf.nn.embedding_lookup(movie_id_embed_matrix, movie_id, name = "movie_id_embed_layer")return movie_id_embed_layer
对电影类型的多个嵌入向量做加和
def get_movie_categories_layers(movie_categories):with tf.name_scope("movie_categories_layers"):movie_categories_embed_matrix = tf.Variable(tf.random_uniform([movie_categories_max, embed_dim], -1, 1), name = "movie_categories_embed_matrix")movie_categories_embed_layer = tf.nn.embedding_lookup(movie_categories_embed_matrix, movie_categories, name = "movie_categories_embed_layer")if combiner == "sum":movie_categories_embed_layer = tf.reduce_sum(movie_categories_embed_layer, axis=1, keep_dims=True)# elif combiner == "mean":return movie_categories_embed_layer
Movie Title的文本卷积网络实现
def get_movie_cnn_layer(movie_titles):#从嵌入矩阵中得到电影名对应的各个单词的嵌入向量with tf.name_scope("movie_embedding"):movie_title_embed_matrix = tf.Variable(tf.random_uniform([movie_title_max, embed_dim], -1, 1), name = "movie_title_embed_matrix")movie_title_embed_layer = tf.nn.embedding_lookup(movie_title_embed_matrix, movie_titles, name = "movie_title_embed_layer")# 为 movie_title_embed_layer 增加一个维度# 在这里是添加到最后一个维度,最后一个维度是channel# 所以这里的channel数量是1个# 所以这里的处理方式和图片是一样的movie_title_embed_layer_expand = tf.expand_dims(movie_title_embed_layer, -1)#对文本嵌入层使用不同尺寸的卷积核做卷积和最大池化pool_layer_lst = []for window_size in window_sizes:with tf.name_scope("movie_txt_conv_maxpool_{}".format(window_size)):# [window_size, embed_dim, 1, filter_num] 表示输入的 channel 的个数是1,输出的 channel 的个数是 filter_numfilter_weights = tf.Variable(tf.truncated_normal([window_size, embed_dim, 1, filter_num],stddev=0.1),name = "filter_weights")filter_bias = tf.Variable(tf.constant(0.1, shape=[filter_num]), name="filter_bias")# conv2d 是指用到的卷积核的大小是 [filter_height * filter_width * in_channels, output_channels]# 在这里卷积核会向两个维度的方向进行滑动# conv1d 是将卷积核向一个维度的方向进行滑动,这就是 conv1d 和 conv2d 的区别# strides 设置要求第一个和最后一个数字是1,四个数字的顺序要求默认是 NHWC,也就是 [batch, height, width, channels]# padding 设置为 VALID 其实就是不 PAD,设置为 SAME 就是让输入和输出的维度是一样的conv_layer = tf.nn.conv2d(movie_title_embed_layer_expand, filter_weights, [1,1,1,1], padding="VALID", name="conv_layer")# tf.nn.bias_add 将偏差 filter_bias 加到 conv_layer 上# tf.nn.relu 将激活函数设置为 relurelu_layer = tf.nn.relu(tf.nn.bias_add(conv_layer,filter_bias), name ="relu_layer")# tf.nn.max_pool 的第一个参数是输入# 第二个参数是 max_pool 窗口的大小,每个数值表示对每个维度的窗口设置# 第三个参数是 strides,和 conv2d 的设置是一样的# 这边的池化是将上面每个卷积核的卷积结果转换为一个元素# 由于这里的卷积核的数量是 8 个,所以下面生成的是一个具有 8 个元素的向量maxpool_layer = tf.nn.max_pool(relu_layer, [1,sentences_size - window_size + 1 ,1,1], [1,1,1,1], padding="VALID", name="maxpool_layer")pool_layer_lst.append(maxpool_layer)#Dropout层with tf.name_scope("pool_dropout"):# 这里最终的结果是这样的,# 假设卷积核的窗口是 2,卷积核的数量是 8# 那么通过上面的池化操作之后,生成的池化的结果是一个具有 8 个元素的向量# 每种窗口大小的卷积核经过池化后都会生成这样一个具有 8 个元素的向量# 所以最终生成的是一个 8 维的二维矩阵,它的另一个维度就是不同的窗口的数量# 在这里就是 2,3,4,5,那么最终就是一个 8*4 的矩阵,pool_layer = tf.concat(pool_layer_lst, 3, name ="pool_layer")max_num = len(window_sizes) * filter_num# 将这个 8*4 的二维矩阵平铺成一个具有 32 个元素的一维矩阵pool_layer_flat = tf.reshape(pool_layer , [-1, 1, max_num], name = "pool_layer_flat")dropout_layer = tf.nn.dropout(pool_layer_flat, dropout_keep_prob, name = "dropout_layer")return pool_layer_flat, dropout_layer
将Movie的各个层一起做全连接
def get_movie_feature_layer(movie_id_embed_layer, movie_categories_embed_layer, dropout_layer):with tf.name_scope("movie_fc"):#第一层全连接movie_id_fc_layer = tf.layers.dense(movie_id_embed_layer, embed_dim, name = "movie_id_fc_layer", activation=tf.nn.relu)movie_categories_fc_layer = tf.layers.dense(movie_categories_embed_layer, embed_dim, name = "movie_categories_fc_layer", activation=tf.nn.relu)#第二层全连接movie_combine_layer = tf.concat([movie_id_fc_layer, movie_categories_fc_layer, dropout_layer], 2) #(?, 1, 96)movie_combine_layer = tf.contrib.layers.fully_connected(movie_combine_layer, 200, tf.tanh) #(?, 1, 200)movie_combine_layer_flat = tf.reshape(movie_combine_layer, [-1, 200])return movie_combine_layer, movie_combine_layer_flat
生成Movie特征矩阵
loaded_graph = tf.Graph() #
movie_matrics = []
with tf.Session(graph=loaded_graph) as sess: ## Load saved modelloader = tf.train.import_meta_graph(load_dir + '.meta')loader.restore(sess, load_dir)# Get Tensors from loaded modeluid, user_gender, user_age, user_job, movie_id, movie_categories, movie_titles, targets, lr, dropout_keep_prob, _, movie_combine_layer_flat, __ = get_tensors(loaded_graph) #loaded_graphfor item in movies.values:categories = np.zeros([1, 18])categories[0] = item.take(2)titles = np.zeros([1, sentences_size])titles[0] = item.take(1)feed = {movie_id: np.reshape(item.take(0), [1, 1]),movie_categories: categories, #x.take(6,1)movie_titles: titles, #x.take(5,1)dropout_keep_prob: 1}movie_combine_layer_flat_val = sess.run([movie_combine_layer_flat], feed) movie_matrics.append(movie_combine_layer_flat_val)pickle.dump((np.array(movie_matrics).reshape(-1, 200)), open('movie_matrics.p', 'wb'))
movie_matrics = pickle.load(open('movie_matrics.p', mode='rb'))
生成User特征矩阵
将训练好的用户特征组合成用户特征矩阵并保存到本地
loaded_graph = tf.Graph() #
users_matrics = []
with tf.Session(graph=loaded_graph) as sess: ## Load saved modelloader = tf.train.import_meta_graph(load_dir + '.meta')loader.restore(sess, load_dir)# Get Tensors from loaded modeluid, user_gender, user_age, user_job, movie_id, movie_categories, movie_titles, targets, lr, dropout_keep_prob, _, __,user_combine_layer_flat = get_tensors(loaded_graph) #loaded_graphfor item in users.values:feed = {uid: np.reshape(item.take(0), [1, 1]),user_gender: np.reshape(item.take(1), [1, 1]),user_age: np.reshape(item.take(2), [1, 1]),user_job: np.reshape(item.take(3), [1, 1]),dropout_keep_prob: 1}user_combine_layer_flat_val = sess.run([user_combine_layer_flat], feed) users_matrics.append(user_combine_layer_flat_val)pickle.dump((np.array(users_matrics).reshape(-1, 200)), open('users_matrics.p', 'wb'))
users_matrics = pickle.load(open('users_matrics.p', mode='rb'))
开始推荐电影








结论
以上就是实现的常用的推荐功能,将网络模型作为回归问题进行训练,得到训练好的用户特征矩阵和电影特征矩阵进行推荐。
相关文章:
深度学习电影推荐-CNN算法
文章目录 前言视频演示效果1.数据集环境配置安装教程与资源说明1.1 ML-1M 数据集概述1.1.1数据集内容1.1.2. 数据集规模1.1.3. 数据特点1.1.4. 文件格式1.1.5. 应用场景 2.模型架构3.推荐实现3.1 用户数据3.2 电影数据3.3 评分数据3.4 数据预处理3.5实现数据预处理3.6 加载数据…...

【Git 】探索 Git 的魔法——git am 与补丁文件的故事
在日常的开发协作中,你可能会遇到这样的场景:某位热心的小伙伴发来一份 .patch 文件,让你把某个问题修复合并到项目中。如果你不知道如何优雅地接收并应用这份补丁,那么这篇文章就是为你准备的!让我们一起揭开 Git 的“…...

G1原理—5.G1垃圾回收过程之Mixed GC
大纲 1.Mixed GC混合回收是什么 2.YGC可作为Mixed GC的初始标记阶段 3.Mixed GC并发标记算法详解(一) 4.Mixed GC并发标记算法详解(二) 5.Mixed GC并发标记算法详解(三) 6.并发标记的三色标记法 7.三色标记法如何解决错标漏标问题 8.SATB如何解决错标漏标问题 9.重新梳…...

机器人传动力系统介绍
电驱动系统 无框力矩电机减速器:优点是功率密度高,可在有限空间产生大扭矩,使机器人关节运动有力灵活,如人形机器人四肢运动。缺点是系统复杂,成本高,减速器会降低传动效率.空心杯电机行星滚柱丝杆&#x…...
)
1161 Merging Linked Lists (25)
Given two singly linked lists L1a1→a2→⋯→an−1→an and L2b1→b2→⋯→bm−1→bm. If n≥2m, you are supposed to reverse and merge the shorter one into the longer one to obtain a list like a1→a2→bm→a3→a4→bm−1⋯. For ex…...
:在多个文件中共享全局常量)
内联变量(inline variables):在多个文件中共享全局常量
在 C17 中,引入了 内联变量(inline variables) 的概念,可以用于在多个文件中共享全局常量。内联变量允许在头文件中定义变量,而不会导致链接错误(如重复定义)。这种方式非常适合用于定义跨多个文…...
Jmeter进行http接口并发测试
目录: 1、Jmeter设置(1)设置请求并发数(2)设置请求地址以及参数(3)添加结果数 2、启动看结果 1、Jmeter设置 (1)设置请求并发数 (2)设置请求地址…...

力扣解题汇总_JAVA
文章目录 数学_简单13_罗马数字转整数66_ 加一9_回文数70_爬楼梯69_x的平方根509_斐波那契数列2235_两整数相加67_二进制求和415_字符串相加2413_最小偶倍数2469_温度转换704_二分查找(重点) 数组_简单1_两数之和88_合并两个有序数组 链表_简单21_合并两个有序链表203_移除链表…...

ubuntu下安装编译cmake,grpc与protobuf
文章目录 install cmakeinstall grpcinstall protobuf注 install cmake sudo apt-get install -y g make libssl-devcd third_party/cmake-3.17.2./configuresudo make && make installcmake --version install grpc $ sudo apt-get install -y build-essential auto…...
SQL Prompt 插件
SQL Prompt 插件 注:SQL Prompt插件提供智能代码补全、SQL格式化、代码自动提示和快捷输入等功能,非常方便,可以自行去尝试体会。 1、问题 SSMS(SQL Server Management Studio)是SQL Server自带的管理工具,…...
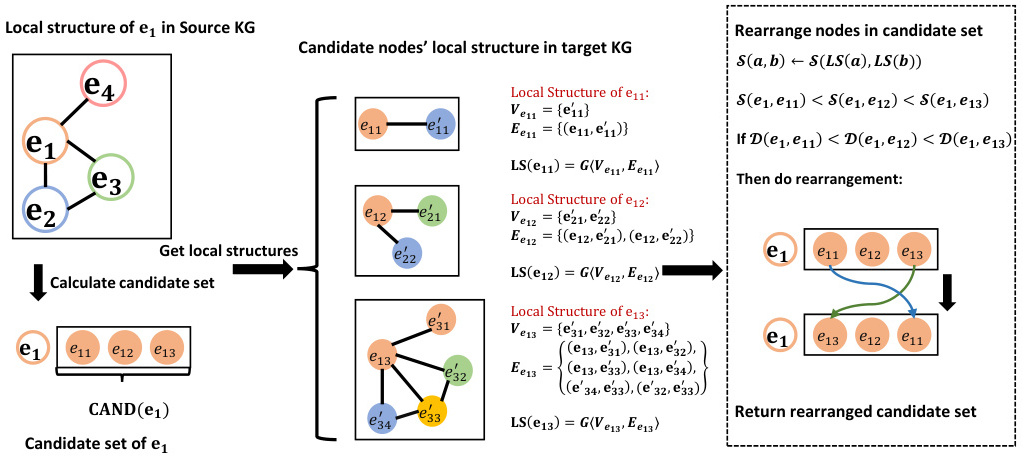
知识图谱抽取分析中,如何做好实体对齐?
在知识图谱抽取分析中,实体对齐是将不同知识图谱中的相同实体映射到同一表示空间的关键步骤。为了做好实体对齐,可以参考以下方法和策略: 基于表示学习的方法: 使用知识图谱嵌入技术,如TransE、GCN等,将实体…...

【Python通过UDP协议传输视频数据】(界面识别)
提示:界面识别项目 前言 随着网络通信技术的发展,视频数据的实时传输在各种场景中得到了广泛应用。UDP(User Datagram Protocol)作为一种无连接的协议,凭借其低延迟、高效率的特性,在实时性要求较高的视频…...
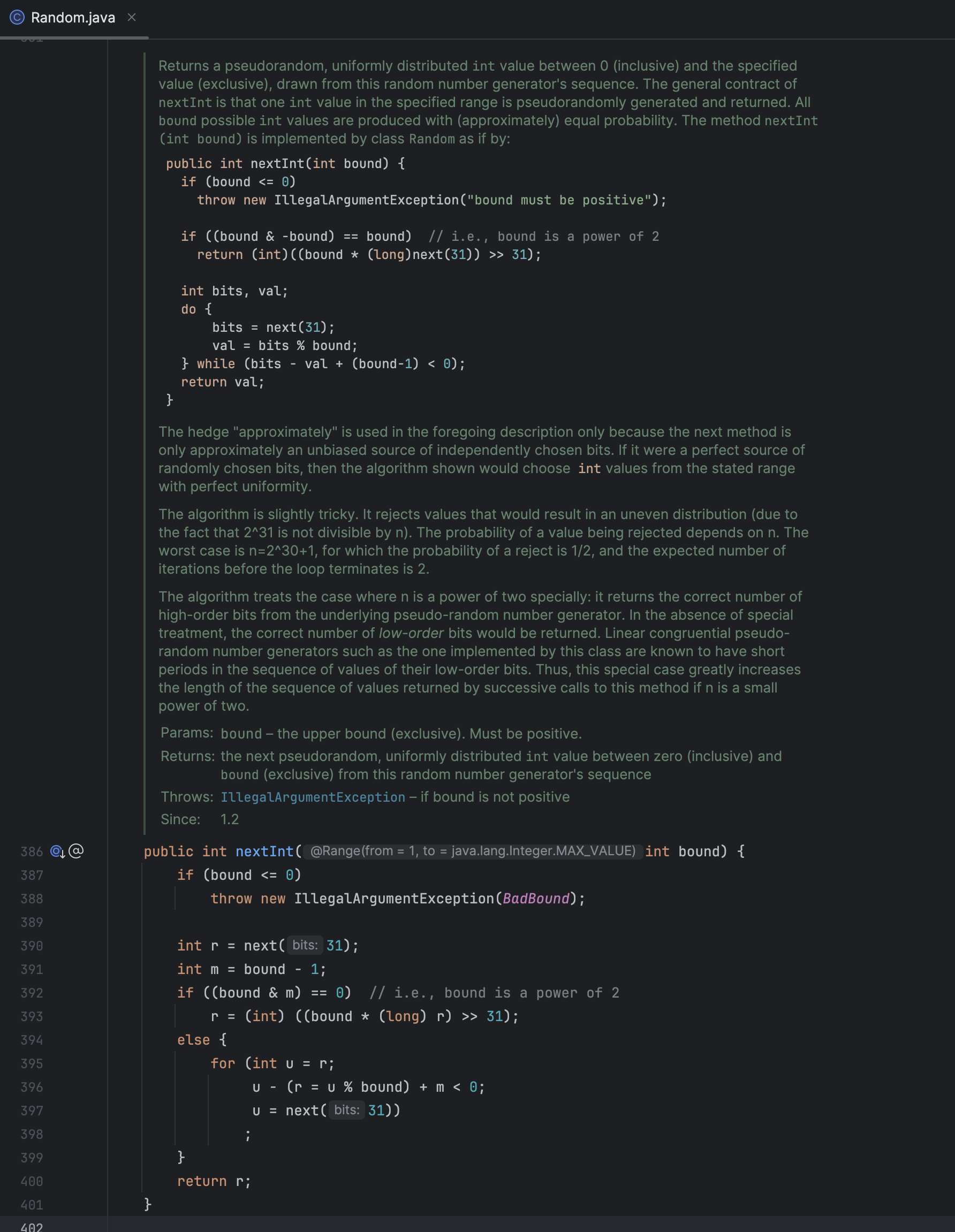
【伪随机数】关于排序算法自测如何生成随机数而引发的……
以 Random 开始 可能一开始,你只是写到了排序算法如何生成随机数 public static void main(String[] args) {Random random new Random();int[] nums new int[10];for (int i 0; i < nums.length; i) {nums[i] random.nextInt(100);}System.out.println(&q…...
是一种非参数统计方法)
核密度估计(Kernel Density Estimation, KDE)是一种非参数统计方法
一、核密度估计 核密度估计(Kernel Density Estimation, KDE)是一种非参数统计方法,用于估计随机变量的概率密度函数。它通过将每个数据点周围的核函数叠加,生成平滑的密度曲线。以下是其核心要点: 1. 基本概念 非参…...

【k8s面试题2025】2、练气初期
在练气初期,灵气还比较稀薄,只能勉强在体内运转几个周天。 文章目录 简述k8s静态pod为 Kubernetes 集群移除新节点:为 K8s 集群添加新节点Kubernetes 中 Pod 的调度流程 简述k8s静态pod 定义 静态Pod是一种特殊类型的Pod,它是由ku…...

栈溢出原理
文章目录 前言一、基本示例二、分析栈1. 先不考虑gets函数的栈情况2. 分析gets函数的栈区情况 三、利用栈1. 构造字符串2. 利用漏洞 前言 栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。…...

Jmeter如何进行多服务器远程测试
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 JMeter是Apache软件基金会的开源项目,主要来做功能和性能测试,用Java编写。 我们一般都会用JMeter在本地进行测试,但是受到单…...

2.slf4j入口
文章目录 一、故事引入二、原理探究三、SLF4JServiceProvider四、总结 一、故事引入 故事要从下面这段代码说起 public class App {private static final Logger logger LoggerFactory.getLogger(App.class);public static void main( String[] args ) throws Exception {lo…...

初学stm32 --- CAN
目录 CAN介绍 CAN总线拓扑图 CAN总线特点 CAN应用场景 CAN物理层 CAN收发器芯片介绍 CAN协议层 数据帧介绍 CAN位时序介绍 数据同步过程 硬件同步 再同步 CAN总线仲裁 STM32 CAN控制器介绍 CAN控制器模式 CAN控制器模式 CAN控制器框图 发送处理 接收处理 接收过…...

软件测试—接口测试面试题及jmeter面试题
一,接口面试题 1.接口的作用 实现前后端的交互,实现数据的传输 2.什么是接口测试 接口测试就是对系统或组件之间的接口进行测试,主要是校验数据的交换、传递和控制管理过程,以及相互逻辑关系 3.接口测试必要性 1.可以发现很…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

AArch64内存管理:MAIR_EL3寄存器详解与应用
1. AArch64内存管理基础与MAIR_EL3寄存器定位 在Armv8-A/v9-A架构中,内存管理单元(MMU)通过多级页表实现虚拟地址到物理地址的转换。当处理器执行内存访问时,MMU会遍历页表条目(Translation Table Entry),其中包含两个关键信息:目…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...

开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣?
开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣? 关键词 AI Agent Harness Engineering、大语言模型编排(LLM Orchestration)、LangChain、AutoGPT、CrewAI、工具调用(Tool Calling)、多Agent协作、自主任务规划 摘要 随着大语言模型…...

Style-Bert-VITS2未来发展方向:从语音克隆到实时语音转换的技术演进路线
Style-Bert-VITS2未来发展方向:从语音克隆到实时语音转换的技术演进路线 【免费下载链接】Style-Bert-VITS2 Style-Bert-VITS2: Bert-VITS2 with more controllable voice styles. 项目地址: https://gitcode.com/gh_mirrors/st/Style-Bert-VITS2 Style-Bert…...

Claude Agent SDK 从 0 到 1 快速上手教程
Claude Agent SDK 从 0 到 1 快速上手教程 什么是 Claude Agent SDK? Claude Agent SDK 是 Anthropic 官方推出的用于构建 AI 智能体的开发工具包。它基于 Claude Code 构建,让开发者能够以编程方式创建、扩展和定制由 Claude 驱动的应用程序。与简单的聊天机器人不同,基于…...

使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点 在团队协作或管理多个AI应用项目时,一个常见的痛点是每个…...

实战教程:5步构建基于YOLOv5的FPS游戏智能瞄准系统
实战教程:5步构建基于YOLOv5的FPS游戏智能瞄准系统 【免费下载链接】FPSAutomaticAiming 基于yolov5的FPS游戏AI。 项目地址: https://gitcode.com/gh_mirrors/fp/FPSAutomaticAiming FPSAutomaticAiming是一个基于YOLOv5深度学习算法的FPS游戏自动瞄准系统&…...