最长递增子序列问题(Longest Increasing Subsequence),动态规划法解决,贪心算法 + 二分查找优化
问题描述:在一个大小乱序的数列中,找到一个最大长度的递增子序列,子序列中的数据在原始数列中的相对位置保持不变,可以不连续,但必须递增。
输入描述:
第一行输入数列的长度 n。(1 <= n <= 200)
第二行输入数列的数据:a1 a2 a3 ... ... ,每个数据之间用空格隔开。(1 <= ai <= 350)
输出:
输出最大递增子序列的长度。
示例:
输入:
6
2 5 1 5 4 5
输出:
3
说明:
最大递增子序列可以是 {2,4,5} 也可以是 {1,4,5},所以最大递增子序列的长度为 3.
输出 3
动态规划法
可以使用 动态规划 的思想来设计该算法。定义数组 dp[n],dp[i] 表示以第 i 个元素结尾的最长递增子序列的长度。(有关动态规划,参考往期文章 【一篇小短文,理解动态规划问题 DP (Dynamic Programming)】)
两个 for 循环嵌套,外层循环遍历数组中的第 i 个元素,内层循环遍历第 i 个元素之前的所有元素。
每次内层循环结束,则计算出当前 第 i 个元素结尾的最长递增子序列长度。
后面的每次循环都基于前面已经解决的子问题。
状态转移方程:
arr是长度为n的数组,arr[i]表示第i个元素。dp[i]为以arr[i]结尾的最长递增子序列的长度。
对于每个元素 arr[i],它的递增子序列可以通过之前的元素 arr[0], arr[1], ..., arr[i-1] 来扩展,因此我们可以利用之前的状态来更新 dp[i]。
转移方程为:
d p [ i ] = max ( d p [ i ] , d p [ j ] + 1 ) for 0 ≤ j < i and a r r [ i ] > a r r [ j ] dp[i] = \max(dp[i], dp[j] + 1) \quad \text{for} \quad 0 \leq j < i \quad \text{and} \quad arr[i] > arr[j] dp[i]=max(dp[i],dp[j]+1)for0≤j<iandarr[i]>arr[j]
即,对于每个 i,我们检查所有 j (j 小于 i),如果 arr[i] 大于 arr[j],那么 arr[i] 可以作为以 arr[j] 结尾的递增子序列的后继,从而更新 dp[i]。
C语言代码实现:
#include <stdio.h>
#include <stdlib.h>int main() {int n;scanf("%d", &n); // 接收数据 nint *arr = (int*)malloc(sizeof(int) * n); // 动态申请 n 个 int 型数据,数组 arr[n]int *dp = (int*)malloc(sizeof(int) * n); // 动态申请数组 dp[n]for (int i = 0; i < n; i++) {scanf("%d", (arr + i)); //接收数组数据*(dp + i) = 1; //初始化 dp 数组,即每个 arr[i] 结尾的数据至少可以形成一个以自身为结尾的递增子序列,长度为1}//进行动态规划for (int i = 1; i < n; i++) {for (int j = 0; j < i; j++) {if (arr[i] > arr[j]) {dp[i] = dp[i] > dp[j] + 1 ? dp[i] : dp[j] + 1;}}}int maxlength = 1;for (int i = 0; i < n; i++) { //遍历 dp[i] 找到最大的一个if (dp[i] > maxlength)maxlength = dp[i];}printf("%d", maxlength); //输出最大递增子序列的长度。free(arr); // 释放 arr 内存free(dp);return 0;
}
如果 arr[i] > arr[j],则可以构成以递增关系,dp[j] 保存的是以 arr[j] 结尾的最大递增子序列的长度。dp[j] + 1 是因为当前找到的第 i 个元素也被算进来。dp[i] = dp[i] > dp[j] + 1 ? dp[i] : dp[j] + 1; 条件运算符,选择较大的一个更新 dp[i] 的值。
以输入的数据 4 3 1 2 5 6 为例,代码的执行过程:
1. 外层循环 i = 1:
-
arr[1] = 3查看i前面的元素:j = 0,arr[0] = 4,因为arr[1] (3)小于arr[0] (4),无法构成递增子序列,所以dp[1]保持为 1。
dp = [1, 1, 1, 1, 1, 1]
2. 外层循环 i = 2:
-
arr[2] = 1查看i前面的元素:j = 0,arr[0] = 4,arr[2] (1)小于arr[0] (4),无法构成递增子序列,dp[2]保持为 1。j = 1,arr[1] = 3,arr[2] (1)小于arr[1] (3),无法构成递增子序列,dp[2]保持为 1。
dp = [1, 1, 1, 1, 1, 1]
3. 外层循环 i = 3:
-
arr[3] = 2查看i前面的元素:j = 0,arr[0] = 4,arr[3] (2)小于arr[0] (4),无法构成递增子序列,dp[3]保持为 1。j = 1,arr[1] = 3,arr[3] (2)小于arr[1] (3),无法构成递增子序列,dp[3]保持为 1。j = 2,arr[2] = 1,arr[3] (2)大于arr[2] (1),我们可以在arr[2]后面加上arr[3],更新dp[3] = dp[2] + 1 = 2。
dp = [1, 1, 1, 2, 1, 1]
4. 外层循环 i = 4:
-
arr[4] = 5查看i前面的元素:j = 0,arr[0] = 4,arr[4] (5)大于arr[0] (4),我们可以在arr[0]后面加上arr[4],更新dp[4] = dp[0] + 1 = 2。j = 1,arr[1] = 3,arr[4] (5)大于arr[1] (3),我们可以在arr[1]后面加上arr[4],更新dp[4] = dp[1] + 1 = 2(不需要更新,dp[4]仍然为 2)。j = 2,arr[2] = 1,arr[4] (5)大于arr[2] (1),我们可以在arr[2]后面加上arr[4],更新dp[4] = dp[2] + 1 = 2(不需要更新,dp[4]仍然为 2)。j = 3,arr[3] = 2,arr[4] (5)大于arr[3] (2),我们可以在arr[3]后面加上arr[4],更新dp[4] = dp[3] + 1 = 3。
dp = [1, 1, 1, 2, 3, 1]
5. 外层循环 i = 5:
-
arr[5] = 6查看i前面的元素:j = 0,arr[0] = 4,arr[5] (6)大于arr[0] (4),我们可以在arr[0]后面加上arr[5],更新dp[5] = dp[0] + 1 = 2。j = 1,arr[1] = 3,arr[5] (6)大于arr[1] (3),我们可以在arr[1]后面加上arr[5],更新dp[5] = dp[1] + 1 = 2(不需要更新,dp[5]仍然为 2)。j = 2,arr[2] = 1,arr[5] (6)大于arr[2] (1),我们可以在arr[2]后面加上arr[5],更新dp[5] = dp[2] + 1 = 2(不需要更新,dp[5]仍然为 2)。j = 3,arr[3] = 2,arr[5] (6)大于arr[3] (2),我们可以在arr[3]后面加上arr[5],更新dp[5] = dp[3] + 1 = 3。j = 4,arr[4] = 5,arr[5] (6)大于arr[4] (5),我们可以在arr[4]后面加上arr[5],更新dp[5] = dp[4] + 1 = 4。
dp = [1, 1, 1, 2, 3, 4]
最终结果:
- 最终
dp数组为[1, 1, 1, 2, 3, 4],表示每个位置上以该元素为结尾的最长递增子序列的长度。 - 最长递增子序列的长度是
4,即dp数组中的最大值。
使用动态规划方法解决该问题,由于使用了双层 for 循环嵌套,所以代码的时间复杂度为 O ( n 2 ) \text{O}(n^2) O(n2),适用于中小规模数据。
贪心算法 + 二分查找
贪心算法(Greedy Algorithm) 是一种在求解问题时采取局部最优解的策略,目的是通过一步一步地做出选择,期望通过局部最优选择达到全局最优。换句话说,贪心算法在每一步都选择当前看起来最好的(最优的)选项,而不考虑这些选择是否会影响到后续的决策。
贪心算法的特点:
- 局部最优选择:每次决策时,选择当前最优解,假设局部最优能够带来全局最优解。
- 不回溯:一旦作出选择,就不会改变或回头考虑先前的选择。贪心算法通常不需要回溯到前一步的决策。
- 无法保证全局最优解:贪心算法的一个缺点是它并不总是能找到全局最优解,因为局部最优并不意味着全局最优。但是,对于某些问题,贪心算法能够给出全局最优解。
贪心算法工作步骤:
- 选择:在当前状态下做出一个选择,使得该选择是局部最优的。
- 可行性检查:检查当前的选择是否符合问题的约束。
- 解决子问题:做出选择后,递归地解决问题的子问题。
- 结束条件:当没有更多的选择可做时,结束算法。
C语言实现:
#include <stdio.h>
#include <stdlib.h>// 二分查找函数,返回尾部元素的位置
int binarySearch(int* tails, int size, int target) {int left = 0, right = size - 1;while (left <= right) {int mid = left + (right - left) / 2;if (tails[mid] < target) {left = mid + 1;} else {right = mid - 1;}}return left;
}int main() {int n;scanf("%d", &n);int* arr = (int*)malloc(n * sizeof(int));int index = 0;while (scanf("%d", (arr + index++)) != EOF);// tails 数组,表示递增子序列的尾部元素int* tails = (int*)malloc(n * sizeof(int));int size = 0; // 记录递增子序列的长度// 贪心 + 二分查找for (int i = 0; i < n; i++) {int pos = binarySearch(tails, size, arr[i]);tails[pos] = arr[i]; // 更新尾部元素if (pos == size) {size++; // 如果当前位置是尾部的最末位置,子序列的长度加1}}printf("%d\n", size); // 输出最长递增子序列的长度free(arr);free(tails);return 0;
}
代码解释:
// 输入部分int n;scanf("%d", &n);int* arr = (int*)malloc(n * sizeof(int)); //申请数组内存int index = 0;while (scanf("%d", (arr + index++)) != EOF); //使用指针操纵数组 arr ,一直读到 End Of File (EOF)
初始化 tails 数组:
int* tails = (int*)malloc(n * sizeof(int));
int size = 0; // 记录递增子序列的长度
tails 数组用来存储当前所有递增子序列的尾部元素。在开始时,我们的递增子序列长度为 0,因此 size 初始为 0。
二分查找函数:
int binarySearch(int* tails, int size, int target) {int left = 0, right = size - 1; // 初始化左边界和右边界while (left <= right) { // 当搜索区间内有元素时,继续查找int mid = left + (right - left) / 2; // 计算中间位置if (tails[mid] < target) { // 如果 mid 位置的元素小于 targetleft = mid + 1; // 说明 target 可能在 mid 右边,所以更新左边界} else { // 如果 mid 位置的元素大于或等于 targetright = mid - 1; // 说明 target 可能在 mid 左边,所以更新右边界}}return left; // 返回插入位置
}
通过二分查找在一个有序的数组 tails 中找到一个位置,使得如果插入 target,数组依然保持有序。函数的返回值是 target 应该插入的位置。
二分查找的基本思想是:通过反复折半查找范围来逐渐缩小搜索区间,从而提高查找效率。
binarySearch(int *tails, int size, int target)二分查找函数,目的是找到tails中第一个大于或等于target的位置。tails[mid] < target时,表示target可以放到mid右边,因此我们将left移动到mid + 1。tails[mid] >= target时,表示我们要寻找更小的值,因此将right移动到mid - 1。- 最终返回的
left就是target应该插入的位置。
遍历数组并更新 tails 数组:
for (int i = 0; i < n; i++) {int pos = binarySearch(tails, size, arr[i]);tails[pos] = arr[i]; // 更新尾部元素if (pos == size) {size++; // 如果当前位置是尾部的最末位置,子序列的长度加1}
}
- 对于每个输入数组
arr[i],我们通过二分查找找出它应该插入tails数组的位置pos。 - 如果
tails[pos]是该元素,说明我们已经可以更新该位置的尾部元素,否则我们在tails数组中找到一个位置并将其更新为arr[i]。 - 如果
pos等于当前tails数组的长度(即size),意味着我们发现了一个比当前tails数组中的任何尾部元素都要大的元素,此时可以将tails数组的长度加 1,表示找到了一个新的递增子序列的末尾。
算法的核心思想
- 贪心算法:
- 我们试图尽可能让每个新元素扩展已有的递增子序列,或者替换掉某个尾部元素,以便为后续的更大的元素腾出空间。
- 通过不断更新
tails数组,我们能确保tails数组中保持着当前所有递增子序列的最小尾部元素。这样,tails数组越长,代表最长递增子序列的长度越长。
- 二分查找:
- 我们用二分查找来快速找到
tails数组中第一个大于或等于当前元素的位置。这是该算法的关键,利用二分查找来确保每次更新tails数组的时间复杂度为O(log n),从而把总的时间复杂度降到了O(n log n)。
- 我们用二分查找来快速找到
例子分析
假设输入序列为:4, 3, 1, 2, 5, 6
- 初始化:
arr = [4, 3, 1, 2, 5, 6]tails = [],size = 0
- 第 1 个元素 4:
binarySearch(tails, 0, 4)返回位置0(tails为空,4应该放到第一个位置)。- 更新
tails = [4],size = 1。
- 第 2 个元素 3:
binarySearch(tails, 1, 3)返回位置0(tails[0] = 4,3比它小,插入位置是0)。- 更新
tails = [3],size = 1。
- 第 3 个元素 1:
binarySearch(tails, 1, 1)返回位置0(tails[0] = 3,1比它小,插入位置是0)。- 更新
tails = [1],size = 1。
- 第 4 个元素 2:
binarySearch(tails, 1, 2)返回位置1(tails[0] = 1,2比它大,插入位置是1)。- 更新
tails = [1, 2],size = 2。
- 第 5 个元素 5:
binarySearch(tails, 2, 5)返回位置2(tails[0] = 1,tails[1] = 2,5比它们都大,插入位置是2)。- 更新
tails = [1, 2, 5],size = 3。
- 第 6 个元素 6:
binarySearch(tails, 3, 6)返回位置3(tails[0] = 1,tails[1] = 2,tails[2] = 5,6比它们都大,插入位置是3)。- 更新
tails = [1, 2, 5, 6],size = 4。
最后,tails = [1, 2, 5, 6],最长递增子序列的长度是 4。
第二个算法的时间复杂度为 O ( n ⋅ log n ) \text{O}(n \cdot \text{log}\ n) O(n⋅log n) ,适用于大规模数据。在输出最大递增子序列的长度的同时,也找出了具体的最大递增子序列 tails 。
END
相关文章:
,动态规划法解决,贪心算法 + 二分查找优化)
最长递增子序列问题(Longest Increasing Subsequence),动态规划法解决,贪心算法 + 二分查找优化
问题描述:在一个大小乱序的数列中,找到一个最大长度的递增子序列,子序列中的数据在原始数列中的相对位置保持不变,可以不连续,但必须递增。 输入描述: 第一行输入数列的长度 n。(1 < n < 200) 第二…...

Python中采用.add_subplot绘制子图的方法简要举例介绍
Python中采用.add_subplot绘制子图的方法简要举例介绍 目录 Python中采用.add_subplot绘制子图的方法简要举例介绍一、Python中绘制子图的方法1.1 add_subplot函数1.2 基本语法(1)add_subplot的核心语法(2)add_subplot在中编程中的…...

纯 Python、Django、FastAPI、Flask、Pyramid、Jupyter、dbt 解析和差异分析
一、纯 Python 1.1 基础概念 Python 是一种高级、通用、解释型的编程语言,以其简洁易读的语法和丰富的标准库而闻名。“纯 Python” 在这里指的是不依赖特定的 Web 框架或数据分析工具,仅使用 Python 原生的功能和标准库来开发应用程序或执行任务。 1.…...

C++实现有限元二维杆单元计算 Bar2D2Node类(纯自研 非套壳)
本系列文章致力于实现“手搓有限元,干翻Ansys的目标”,基本框架为前端显示使用QT实现交互,后端计算采用Visual Studio C。 QT软件界面 具体软件操作可查看下方视频哦。也可以点击这里直接跳转。 直接干翻Ansys?小伙自研有限元 1、…...

wx036基于springboot+vue+uniapp的校园快递平台小程序
开发语言:Java框架:springbootuniappJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包&#…...

Unity中两个UGUI物体的锚点和中心点设置成不一样的,然后怎么使两个物体的位置一样?
一、问题复现 需求:go1物体和我想把go1的位置跟go2的位置一样,但是我通过物体的anchoredPosition以及position还有localposiiton都没有解决问题,使用上面的这三个属性的效果如下: 运行之后,可以看出,go1的…...

兼职全职招聘系统架构与功能分析
2015工作至今,10年资深全栈工程师,CTO,擅长带团队、攻克各种技术难题、研发各类软件产品,我的代码态度:代码虐我千百遍,我待代码如初恋,我的工作态度:极致,责任ÿ…...

HTML5 History API
在 HTML5 的 History API 中,pushState 和 replaceState 方法也可以接受一个 state 对象作为参数。这些方法允许你在改变浏览器路由时不重新加载页面,并且可以附加一些自定义数据。 state 返回在 history 栈顶的 任意 值的拷贝。 let currentState h…...

2025_1_22打卡
402. 移掉 K 位数字 - 力扣(LeetCode) 279. 完全平方数 - 力扣(LeetCode)...

Formality:不可读(unread)的概念
相关阅读 Formalityhttps://blog.csdn.net/weixin_45791458/category_12841971.html?spm1001.2014.3001.5482https://blog.csdn.net/weixin_45791458/category_12841971.html?spm1001.2014.3001.5482 在Formality中有时会遇到不可读(unread)这个概念,本文就将对此…...
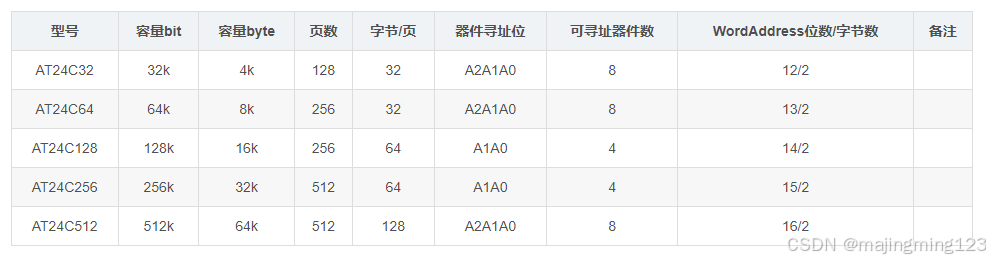
stm32f103C8T6和AT24C256链接
模拟IIC总线 myiic.c #ifndef __24CXX_H #define __24CXX_H #include "myiic.h" #define AT24C01 127 //1kbit1*1024/8128byte地址寻址范围为0-127 #define AT24C02 255 #define AT24C04 511 #define AT24C08 1023 #define AT24C16 2047 #define AT24C32 …...

5.SQLAlchemy对两张有关联关系表查询
问题 例如,一个用户可以有多个收获地址。 定义表如下: 用户表 地址表 一般情况,我们会先查询用户表,拿到用户id后,再到地址表中查询关联的地址数据。这样就要执行两次查询。 仅仅为了方便查询,需要一些属…...

2.2.1 语句结构
ST(Structured Text)语言是一种基于IEC 61131-3标准的高级文本编程语言,其语法规则严格且清晰。以下是ST语言中关于分号、注释和代码块的详细语法规则说明: 分号(;)作用:分号用于表示语句的结束。语法规则: 每个独立的语句必须以分号结尾。分号是语句的终止符,用于分隔…...

安当二代TDE透明加密技术与SMS凭据管理系统相结合的数据库安全解决方案
安当二代TDE透明加密技术与安当SMS凭据管理系统的结合,为企业提供了一套完整的数据库安全解决方案,涵盖字段级加密脱敏和动态凭据管理两大核心功能。以下是其实现方式和技术特点的详细说明: 一、安当二代TDE透明加密技术:字段级加…...

es的date类型字段按照原生格式进行分组聚合
PUT student2 { "mappings": {"properties": {"name": {"type": "text","analyzer": "standard" // 使用标准分析器,适合姓名字段},"birthday": {"type": "date&…...

高频次UDP 小包丢包分析
目录 背景测试方法测试结果case1: (经过多级交换机)case2: 长时测试(经过多级交换机)case3: 长时测试(设备直联)可能原因分析解决方法背景 UDP作为面向非连接的传输协议,并不能保证可靠交付。本文编写代码测试设备之间UDP小包传输的可靠性。 测试方法 发送侧基于豆包…...

科目四考试内容
一、考试内容 科目四考试主要包含以下五个方面的内容: 法律法规与规章制度:理解并掌握道路交通规则,涉及交通信号、标志、标线以及相关设施的运用。综合判断与案例分析:培养学员应对复杂交通情况的能力,学会识别违法…...
公务员录用考试 《申论》真题详解)
2015 年 4 月多省(区、市)公务员录用考试 《申论》真题详解
一)“给定资料1~2”反映了人们在过去的工作和生活方面形成的很多“惯例”或“习惯做法”正在悄然改变。请分析导致这种改变发生的主要原因。(20分) 一、给定资料 材料1: 互联网的日益普及和开发利用,不断为人…...

四、CSS效果
一、box-shadow box-shadow:在元素的框架上添加阴影效果 /* x 偏移量 | y 偏移量 | 阴影颜色 */ box-shadow: 60px -16px teal; /* x 偏移量 | y 偏移量 | 阴影模糊半径 | 阴影颜色 */ box-shadow: 10px 5px 5px black; /* x 偏移量 | y 偏移量 | 阴影模糊半径 | 阴影扩散半…...

全面评测 DOCA 开发环境下的 DPU:性能表现、机器学习与金融高频交易下的计算能力分析
本文介绍了我在 DOCA 开发环境下对 DPU 进行测评和计算能力测试的一些真实体验和记录。在测评过程中,我主要关注了 DPU 在高并发数据传输和深度学习场景下的表现,以及基本的系统性能指标,包括 CPU 计算、内存带宽、多线程/多进程能力和 I/O 性…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

内存占用3KB!极致瘦身释放MCU无限可能
极致小体积,给工业领域带来了无限的可能:更低硬件成本,更小芯片体积,更低功耗,更高可靠性,让每一颗小MCU都拥有大系统的完整能力。 https://www.bilibili.com/video/BV1eZLi6PEjc/?spm_id_from333.1387.ho…...

如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案
如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX 还在为本地音乐库缺少歌词而烦恼吗࿱…...
:3类高危使用场景+2个监管红线预警)
Claude SWOT分析(内部风控文档流出版):3类高危使用场景+2个监管红线预警
更多请点击: https://intelliparadigm.com 第一章:Claude SWOT分析(内部风控文档流出版):3类高危使用场景2个监管红线预警 高危使用场景识别 在企业级AI应用中,Claude模型若未经严格风控适配,…...

Keil µVision反汇编窗口内容导出方案与调试技巧
1. 问题背景与需求解析在嵌入式开发过程中,调试环节往往占据大量时间。Keil Vision作为业界广泛使用的集成开发环境(IDE),其调试器功能强大但某些细节功能仍有提升空间。最近我在使用C251架构开发汽车电子控制单元时,就遇到了一个看似简单却影…...

LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案
LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_mirror…...

机器学习力场攻克Peierls相变动力学:从对称性描述符到畴生长标度律
1. 项目概述:当机器学习遇见Peierls相变在凝聚态物理和材料科学的前沿,我们常常被一个核心问题所困扰:如何精确地模拟那些由电子和晶格(原子)强烈耦合所驱动的复杂动力学过程?这类系统,比如电荷…...

HS2-HF Patch:3分钟解锁Honey Select 2完整游戏体验的技术指南
HS2-HF Patch:3分钟解锁Honey Select 2完整游戏体验的技术指南 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF Patch是专为Honey Select 2 L…...

抖音内容自动化采集与管理的技术实现方案
抖音内容自动化采集与管理的技术实现方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批量下载工具&am…...