使用sql查询excel内容
1. 简介
我们在前面的文章中提到了calcite支持csv和json文件的数据源适配, 其实就是将文件解析成表然后以文件夹为schema, 然后将生成的schema注册到RootSehema(RootSchema是所有数据源schema的parent,多个不同数据源schema可以挂在同一个RootSchema下)下, 最终使用calcite的特性进行sql的解析查询返回.
但其实我们的数据文件一般使用excel进行存储,流转, 但很可惜, calcite本身没有excel的适配器, 但其实我们可以模仿calcite-file, 自己搞一个calcite-file-excel, 也可以熟悉calcite的工作原理.
2. 实现思路
因为excel有sheet的概念, 所以可以将一个excel解析成schema, 每个sheet解析成table, 实现步骤如下:
-
实现
SchemaFactory重写create方法: schema工厂 用于创建schema -
继承
AbstractSchema: schema描述类 用于解析excel, 创建table(解析sheet) -
继承
AbstractTable, ScannableTable: table描述类 提供字段信息和数据内容等(解析sheet data)
3. Excel样例
excel有两个sheet页, 分别是user_info 和 role_info如下:


ok, 万事具备.
4. Maven
<dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.3</version>
</dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>5.2.3</version>
</dependency><dependency><groupId>org.apache.calcite</groupId><artifactId>calcite-core</artifactId><version>1.37.0</version>
</dependency>5. 核心代码
5.1 SchemaFactory
package com.ldx.calcite.excel;import com.google.common.collect.Lists;
import org.apache.calcite.schema.Schema;
import org.apache.calcite.schema.SchemaFactory;
import org.apache.calcite.schema.SchemaPlus;
import org.apache.commons.lang3.ObjectUtils;
import org.apache.commons.lang3.StringUtils;import java.io.File;
import java.util.List;
import java.util.Map;/*** schema factory*/
public class ExcelSchemaFactory implements SchemaFactory {public final static ExcelSchemaFactory INSTANCE = new ExcelSchemaFactory();private ExcelSchemaFactory(){}@Overridepublic Schema create(SchemaPlus parentSchema, String name, Map<String, Object> operand) {final Object filePath = operand.get("filePath");if (ObjectUtils.isEmpty(filePath)) {throw new NullPointerException("can not find excel file");}return this.create(filePath.toString());}public Schema create(String excelFilePath) {if (StringUtils.isBlank(excelFilePath)) {throw new NullPointerException("can not find excel file");}return this.create(new File(excelFilePath));}public Schema create(File excelFile) {if (ObjectUtils.isEmpty(excelFile) || !excelFile.exists()) {throw new NullPointerException("can not find excel file");}if (!excelFile.isFile() || !isExcelFile(excelFile)) {throw new RuntimeException("can not find excel file: " + excelFile.getAbsolutePath());}return new ExcelSchema(excelFile);}protected List<String> supportedFileSuffix() {return Lists.newArrayList("xls", "xlsx");}private boolean isExcelFile(File excelFile) {if (ObjectUtils.isEmpty(excelFile)) {return false;}final String name = excelFile.getName();return StringUtils.endsWithAny(name, this.supportedFileSuffix().toArray(new String[0]));}
}schema中有多个重载的create方法用于方便的创建schema, 最终将excel file 交给ExcelSchema创建一个schema对象
5.2 Schema
package com.ldx.calcite.excel;import org.apache.calcite.schema.Table;
import org.apache.calcite.schema.impl.AbstractSchema;
import org.apache.commons.lang3.ObjectUtils;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.ss.usermodel.WorkbookFactory;
import org.testng.collections.Maps;import java.io.File;
import java.util.Iterator;
import java.util.Map;/*** schema*/
public class ExcelSchema extends AbstractSchema {private final File excelFile;private Map<String, Table> tableMap;public ExcelSchema(File excelFile) {this.excelFile = excelFile;}@Overrideprotected Map<String, Table> getTableMap() {if (ObjectUtils.isEmpty(tableMap)) {tableMap = createTableMap();}return tableMap;}private Map<String, Table> createTableMap() {final Map<String, Table> result = Maps.newHashMap();try (Workbook workbook = WorkbookFactory.create(excelFile)) {final Iterator<Sheet> sheetIterator = workbook.sheetIterator();while (sheetIterator.hasNext()) {final Sheet sheet = sheetIterator.next();final ExcelScannableTable excelScannableTable = new ExcelScannableTable(sheet, null);result.put(sheet.getSheetName(), excelScannableTable);}}catch (Exception ignored) {}return result;}
}schema类读取Excel file, 并循环读取sheet, 将每个sheet解析成ExcelScannableTable并存储
5.3 Table
package com.ldx.calcite.excel;import com.google.common.collect.Lists;
import com.ldx.calcite.excel.enums.JavaFileTypeEnum;
import org.apache.calcite.DataContext;
import org.apache.calcite.adapter.java.JavaTypeFactory;
import org.apache.calcite.linq4j.Enumerable;
import org.apache.calcite.linq4j.Linq4j;
import org.apache.calcite.rel.type.RelDataType;
import org.apache.calcite.rel.type.RelDataTypeFactory;
import org.apache.calcite.rel.type.RelProtoDataType;
import org.apache.calcite.schema.ScannableTable;
import org.apache.calcite.schema.impl.AbstractTable;
import org.apache.calcite.sql.type.SqlTypeName;
import org.apache.calcite.util.Pair;
import org.apache.commons.lang3.ObjectUtils;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.checkerframework.checker.nullness.qual.Nullable;import java.util.List;/*** table*/
public class ExcelScannableTable extends AbstractTable implements ScannableTable {private final RelProtoDataType protoRowType;private final Sheet sheet;private RelDataType rowType;private List<JavaFileTypeEnum> fieldTypes;private List<Object[]> rowDataList;public ExcelScannableTable(Sheet sheet, RelProtoDataType protoRowType) {this.protoRowType = protoRowType;this.sheet = sheet;}@Overridepublic Enumerable<@Nullable Object[]> scan(DataContext root) {JavaTypeFactory typeFactory = root.getTypeFactory();final List<JavaFileTypeEnum> fieldTypes = this.getFieldTypes(typeFactory);if (rowDataList == null) {rowDataList = readExcelData(sheet, fieldTypes);}return Linq4j.asEnumerable(rowDataList);}@Overridepublic RelDataType getRowType(RelDataTypeFactory typeFactory) {if (ObjectUtils.isNotEmpty(protoRowType)) {return protoRowType.apply(typeFactory);}if (ObjectUtils.isEmpty(rowType)) {rowType = deduceRowType((JavaTypeFactory) typeFactory, sheet, null);}return rowType;}public List<JavaFileTypeEnum> getFieldTypes(RelDataTypeFactory typeFactory) {if (fieldTypes == null) {fieldTypes = Lists.newArrayList();deduceRowType((JavaTypeFactory) typeFactory, sheet, fieldTypes);}return fieldTypes;}private List<Object[]> readExcelData(Sheet sheet, List<JavaFileTypeEnum> fieldTypes) {List<Object[]> rowDataList = Lists.newArrayList();for (int rowIndex = 1; rowIndex <= sheet.getLastRowNum(); rowIndex++) {Row row = sheet.getRow(rowIndex);Object[] rowData = new Object[fieldTypes.size()];for (int i = 0; i < row.getLastCellNum(); i++) {final JavaFileTypeEnum javaFileTypeEnum = fieldTypes.get(i);Cell cell = row.getCell(i, Row.MissingCellPolicy.CREATE_NULL_AS_BLANK);final Object cellValue = javaFileTypeEnum.getCellValue(cell);rowData[i] = cellValue;}rowDataList.add(rowData);}return rowDataList;}public static RelDataType deduceRowType(JavaTypeFactory typeFactory, Sheet sheet, List<JavaFileTypeEnum> fieldTypes) {final List<String> names = Lists.newArrayList();final List<RelDataType> types = Lists.newArrayList();if (sheet != null) {Row headerRow = sheet.getRow(0);if (headerRow != null) {for (int i = 0; i < headerRow.getLastCellNum(); i++) {Cell cell = headerRow.getCell(i, Row.MissingCellPolicy.CREATE_NULL_AS_BLANK);String[] columnInfo = cell.getStringCellValue().split(":");String columnName = columnInfo[0].trim();String columnType = null;if (columnInfo.length == 2) {columnType = columnInfo[1].trim();}final JavaFileTypeEnum javaFileType = JavaFileTypeEnum.of(columnType).orElse(JavaFileTypeEnum.UNKNOWN);final RelDataType sqlType = typeFactory.createSqlType(javaFileType.getSqlTypeName());names.add(columnName);types.add(sqlType);if (fieldTypes != null) {fieldTypes.add(javaFileType);}}}}if (names.isEmpty()) {names.add("line");types.add(typeFactory.createSqlType(SqlTypeName.VARCHAR));}return typeFactory.createStructType(Pair.zip(names, types));}
}
table类中其中有两个比较关键的方法
scan: 扫描表内容, 我们这里将sheet页面的数据内容解析存储最后交给calcite
getRowType: 获取字段信息, 我们这里默认使用第一条记录作为表头(row[0]) 并解析为字段信息, 字段规则跟csv一样 name:string, 冒号前面的是字段key, 冒号后面的是字段类型, 如果未指定字段类型, 则解析为UNKNOWN, 后续JavaFileTypeEnum会进行类型推断, 最终在结果处理时calcite也会进行推断
deduceRowType: 推断字段类型, 方法中使用JavaFileTypeEnum枚举类对java type & sql type & 字段值转化处理方法 进行管理
5.4 ColumnTypeEnum
package com.ldx.calcite.excel.enums;import lombok.Getter;
import lombok.extern.slf4j.Slf4j;
import org.apache.calcite.avatica.util.DateTimeUtils;
import org.apache.calcite.sql.type.SqlTypeName;
import org.apache.commons.lang3.ObjectUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.DateUtil;
import org.apache.poi.ss.util.CellUtil;import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.Optional;
import java.util.TimeZone;
import java.util.function.Function;/*** type converter*/
@Slf4j
@Getter
public enum JavaFileTypeEnum {STRING("string", SqlTypeName.VARCHAR, Cell::getStringCellValue),BOOLEAN("boolean", SqlTypeName.BOOLEAN, Cell::getBooleanCellValue),BYTE("byte", SqlTypeName.TINYINT, Cell::getStringCellValue),CHAR("char", SqlTypeName.CHAR, Cell::getStringCellValue),SHORT("short", SqlTypeName.SMALLINT, Cell::getNumericCellValue),INT("int", SqlTypeName.INTEGER, cell -> (Double.valueOf(cell.getNumericCellValue()).intValue())),LONG("long", SqlTypeName.BIGINT, cell -> (Double.valueOf(cell.getNumericCellValue()).longValue())),FLOAT("float", SqlTypeName.REAL, Cell::getNumericCellValue),DOUBLE("double", SqlTypeName.DOUBLE, Cell::getNumericCellValue),DATE("date", SqlTypeName.DATE, getValueWithDate()),TIMESTAMP("timestamp", SqlTypeName.TIMESTAMP, getValueWithTimestamp()),TIME("time", SqlTypeName.TIME, getValueWithTime()),UNKNOWN("unknown", SqlTypeName.UNKNOWN, getValueWithUnknown()),;// cell typeprivate final String typeName;// sql typeprivate final SqlTypeName sqlTypeName;// value convert funcprivate final Function<Cell, Object> cellValueFunc;private static final FastDateFormat TIME_FORMAT_DATE;private static final FastDateFormat TIME_FORMAT_TIME;private static final FastDateFormat TIME_FORMAT_TIMESTAMP;static {final TimeZone gmt = TimeZone.getTimeZone("GMT");TIME_FORMAT_DATE = FastDateFormat.getInstance("yyyy-MM-dd", gmt);TIME_FORMAT_TIME = FastDateFormat.getInstance("HH:mm:ss", gmt);TIME_FORMAT_TIMESTAMP = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss", gmt);}JavaFileTypeEnum(String typeName, SqlTypeName sqlTypeName, Function<Cell, Object> cellValueFunc) {this.typeName = typeName;this.sqlTypeName = sqlTypeName;this.cellValueFunc = cellValueFunc;}public static Optional<JavaFileTypeEnum> of(String typeName) {return Arrays.stream(values()).filter(type -> StringUtils.equalsIgnoreCase(typeName, type.getTypeName())).findFirst();}public static SqlTypeName findSqlTypeName(String typeName) {final Optional<JavaFileTypeEnum> javaFileTypeOptional = of(typeName);if (javaFileTypeOptional.isPresent()) {return javaFileTypeOptional.get().getSqlTypeName();}return SqlTypeName.UNKNOWN;}public Object getCellValue(Cell cell) {return cellValueFunc.apply(cell);}public static Function<Cell, Object> getValueWithUnknown() {return cell -> {if (ObjectUtils.isEmpty(cell)) {return null;}switch (cell.getCellType()) {case STRING:return cell.getStringCellValue();case NUMERIC:if (DateUtil.isCellDateFormatted(cell)) {// 如果是日期类型,返回日期对象return cell.getDateCellValue();}else {// 否则返回数值return cell.getNumericCellValue();}case BOOLEAN:return cell.getBooleanCellValue();case FORMULA:// 对于公式单元格,先计算公式结果,再获取其值try {return cell.getNumericCellValue();}catch (Exception e) {try {return cell.getStringCellValue();}catch (Exception ex) {log.error("parse unknown data error, cellRowIndex:{}, cellColumnIndex:{}", cell.getRowIndex(), cell.getColumnIndex(), e);return null;}}case BLANK:return "";default:return null;}};}public static Function<Cell, Object> getValueWithDate() {return cell -> {Date date = cell.getDateCellValue();if(ObjectUtils.isEmpty(date)) {return null;}try {final String formated = new SimpleDateFormat("yyyy-MM-dd").format(date);Date newDate = TIME_FORMAT_DATE.parse(formated);return (int) (newDate.getTime() / DateTimeUtils.MILLIS_PER_DAY);}catch (ParseException e) {log.error("parse date error, date:{}", date, e);}return null;};}public static Function<Cell, Object> getValueWithTimestamp() {return cell -> {Date date = cell.getDateCellValue();if(ObjectUtils.isEmpty(date)) {return null;}try {final String formated = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(date);Date newDate = TIME_FORMAT_TIMESTAMP.parse(formated);return (int) newDate.getTime();}catch (ParseException e) {log.error("parse timestamp error, date:{}", date, e);}return null;};}public static Function<Cell, Object> getValueWithTime() {return cell -> {Date date = cell.getDateCellValue();if(ObjectUtils.isEmpty(date)) {return null;}try {final String formated = new SimpleDateFormat("HH:mm:ss").format(date);Date newDate = TIME_FORMAT_TIME.parse(formated);return newDate.getTime();}catch (ParseException e) {log.error("parse time error, date:{}", date, e);}return null;};}
}该枚举类主要管理了java type& sql type & cell value convert func, 方便统一管理类型映射及单元格内容提取时的转换方法(这里借用了java8 function函数特性)
注: 这里的日期转换只能这样写, 即使用GMT的时区(抄的
calcite-file), 要不然输出的日期时间一直有时差...
6. 测试查询
package com.ldx.calcite;import com.ldx.calcite.excel.ExcelSchemaFactory;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.apache.calcite.config.CalciteConnectionProperty;
import org.apache.calcite.jdbc.CalciteConnection;
import org.apache.calcite.schema.Schema;
import org.apache.calcite.schema.SchemaPlus;
import org.apache.calcite.util.Sources;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.testng.collections.Maps;import java.net.URL;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Map;
import java.util.Properties;@Slf4j
public class CalciteExcelTest {private static Connection connection;private static SchemaPlus rootSchema;private static CalciteConnection calciteConnection;@BeforeAll@SneakyThrowspublic static void beforeAll() {Properties info = new Properties();// 不区分sql大小写info.setProperty(CalciteConnectionProperty.CASE_SENSITIVE.camelName(), "false");// 创建Calcite连接connection = DriverManager.getConnection("jdbc:calcite:", info);calciteConnection = connection.unwrap(CalciteConnection.class);// 构建RootSchema,在Calcite中,RootSchema是所有数据源schema的parent,多个不同数据源schema可以挂在同一个RootSchema下rootSchema = calciteConnection.getRootSchema();}@Test@SneakyThrowspublic void test_execute_query() {final Schema schema = ExcelSchemaFactory.INSTANCE.create(resourcePath("file/test.xlsx"));rootSchema.add("test", schema);// 设置默认的schemacalciteConnection.setSchema("test");final Statement statement = calciteConnection.createStatement();ResultSet resultSet = statement.executeQuery("SELECT * FROM user_info");printResultSet(resultSet);System.out.println("=========");ResultSet resultSet2 = statement.executeQuery("SELECT * FROM test.user_info where id > 110 and birthday > '2003-01-01'");printResultSet(resultSet2);System.out.println("=========");ResultSet resultSet3 = statement.executeQuery("SELECT * FROM test.user_info ui inner join test.role_info ri on ui.role_id = ri.id");printResultSet(resultSet3);}@AfterAll@SneakyThrowspublic static void closeResource() {connection.close();}private static String resourcePath(String path) {final URL url = CalciteExcelTest.class.getResource("/" + path);return Sources.of(url).file().getAbsolutePath();}public static void printResultSet(ResultSet resultSet) throws SQLException {// 获取 ResultSet 元数据ResultSetMetaData metaData = resultSet.getMetaData();// 获取列数int columnCount = metaData.getColumnCount();log.info("Number of columns: {}",columnCount);// 遍历 ResultSet 并打印结果while (resultSet.next()) {final Map<String, String> item = Maps.newHashMap();// 遍历每一列并打印for (int i = 1; i <= columnCount; i++) {String columnName = metaData.getColumnName(i);String columnValue = resultSet.getString(i);item.put(columnName, columnValue);}log.info(item.toString());}}
}测试结果如下:

文章转载自:张铁牛
原文链接:4. 使用sql查询excel内容 - 张铁牛 - 博客园
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构
相关文章:
使用sql查询excel内容
1. 简介 我们在前面的文章中提到了calcite支持csv和json文件的数据源适配, 其实就是将文件解析成表然后以文件夹为schema, 然后将生成的schema注册到RootSehema(RootSchema是所有数据源schema的parent,多个不同数据源schema可以挂在同一个RootSchema下)下, 最终使用…...

[Python学习日记-78] 基于 TCP 的 socket 开发项目 —— 模拟 SSH 远程执行命令
[Python学习日记-78] 基于 TCP 的 socket 开发项目 —— 模拟 SSH 远程执行命令 简介 项目分析 如何执行系统命令并拿到结果 代码实现 简介 在Python学习日记-77中我们介绍了 socket 基于 TCP 和基于 UDP 的套接字,还实现了服务器端和客户端的通信,本…...

电子应用设计方案101:智能家庭AI喝水杯系统设计
智能家庭 AI 喝水杯系统设计 一、引言 智能家庭 AI 喝水杯系统旨在为用户提供个性化的饮水提醒和健康管理服务,帮助用户养成良好的饮水习惯。 二、系统概述 1. 系统目标 - 精确监测饮水量和饮水频率。 - 根据用户的身体状况和活动量,智能制定饮水计划。…...

vue学习路线
以下是一个详细的Vue学习路线: 一、基础入门 (一)环境搭建 1. 安装Node.js和npm:Vue项目依赖于Node.js环境,需从官网下载并安装最新版本的Node.js,npm会随Node.js一起安装。 2. 安装Vue CLI:V…...
Chainlink Automation(定时任务) 详细介绍及用法)
(15)Chainlink Automation(定时任务) 详细介绍及用法
Chainlink Automation 详细介绍 1. 什么是 Chainlink Automation? Chainlink Automation 是 Chainlink 提供的一个去中心化服务,专门用于自动化执行智能合约的链上操作。它允许开发者基于时间或特定条件(如链上或链下事件)触发智…...

从入门到精通:RabbitMQ的深度探索与实战应用
目录 一、RabbitMQ 初相识 二、基础概念速览 (一)消息队列是什么 (二)RabbitMQ 核心组件 三、RabbitMQ 基本使用 (一)安装与环境搭建 (二)简单示例 (三)…...

基于微信小程序高校订餐系统的设计与开发ssm+论文源码调试讲解
第4章 系统设计 一个成功设计的系统在内容上必定是丰富的,在系统外观或系统功能上必定是对用户友好的。所以为了提升系统的价值,吸引更多的访问者访问系统,以及让来访用户可以花费更多时间停留在系统上,则表明该系统设计得比较专…...

【vitePress】基于github快速添加评论功能(giscus)
一.添加评论插件 使用giscus来做vitepress 的评论模块,使用也非常的简单,具体可以参考:giscus 文档,首先安装giscus npm i giscus/vue 二.giscus操作 打开giscus 文档,如下图所示,填入你的 github 用户…...

PID 控制算法(二):C 语言实现与应用
在本文中,我们将用 C 语言实现一个简单的 PID 控制器,并通过一个示例来演示如何使用 PID 控制算法来调整系统的状态(如温度、速度等)。同时,我们也会解释每个控制参数如何影响系统的表现。 什么是 PID 控制器…...

Git本地搭建
Git本地搭建 (项目突然不给创建仓库了,为了方便管理项目只能自己本地搭建git服务) 为了在本地搭建Git环境并实现基本的Git操作,步骤如下: 安装Git软件 Windows:从Git官方网站下载并安装适用于Windows…...
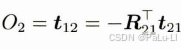
ORB-SLAM2源码学习:Initializer.cc⑧: Initializer::CheckRT检验三角化结果
前言 ORB-SLAM2源码学习:Initializer.cc⑦: Initializer::Triangulate特征点对的三角化_cv::svd::compute-CSDN博客 经过上面的三角化我们成功得到了三维点,但是经过三角化成功的三维点并不一定是有效的,需要筛选才能作为初始化地图点。 …...

leetcode 2239. 找到最接近 0 的数字
题目:2239. 找到最接近 0 的数字 - 力扣(LeetCode) 加班用手机刷水题,补个记录 1 class Solution { public:int findClosestNumber(vector<int>& nums) {int ret nums[0];for (int i 1; i < nums.size(); i) {if…...

Rust实现内网穿透工具:从原理到实现
目录 1.前言2.内网穿透原理3.丐版实现3.1 share3.2 server3.3 client3.4 测试4.项目优化4.1 工作空间4.2 代码合并4.3 无锁优化4.4 数据分离4.5 错误处理4.6 测试代码4.7 参数解析本篇原文为:Rust实现内网穿透工具:从原理到实现 更多C++进阶、rust、python、逆向等等教程,可…...

【深度学习】1.深度学习解决问题与应用领域
深度学习要解决的问题 一、图像识别相关问题 物体识别 背景和意义:在众多的图像中识别出特定的物体,例如在安防监控领域,识别出画面中的人物、车辆等物体类别。在自动驾驶技术中,车辆需要识别出道路上的行人、交通标志、其他车辆…...

文档解析:PDF里的复杂表格、少线表格如何还原?
PDF中的复杂表格或少线表格还原通常需要借助专业的工具或在线服务,以下是一些可行的方法: 方法一:使用在线PDF转换工具 方法二:使用桌面PDF编辑软件 方法三:通过OCR技术提取表格 方法四:手动重建表格 …...
深圳大学-计算机系统(3)-实验三取指和指令译码设计
实验目标 设计完成一个连续取指令并进行指令译码的电路,从而掌握设计简单数据通路的基本方法。 实验内容 本实验分成三周(三次)完成:1)首先完成一个译码器(30分);2)接…...

Java Swing 编程全面解析:从 AWT 到 Swing 的进化之路
目录 前言 一、AWT 简介 1. 什么是 AWT? 2. AWT 的基本组件 3. AWT 编程示例 二、Swing 的诞生与进化 1. Swing 的特点 2. Swing 和 AWT 的主要区别 3. Swing 的基本组件 三、Swing 编程的基础示例 四、Swing 的高级功能 1. 布局管理器 2. 事件监听 3…...

mysql数据库启动出现Plugin ‘FEEDBACK‘ is disabled.问题解决记录
本人出现该问题的环境是xampp,异常关机,再次在xampp控制面板启动mysql出现该问题。出现问题折腾数据库之前,先备份数据,将mysql目录下的data拷贝到其他地方,这很重要。 然后开始折腾。 查资料,会发现很多…...

2025年大模型对智能硬件发展的助力与创新创意
随着人工智能(AI)技术,尤其是大模型的快速进步,智能硬件领域正在经历前所未有的变革。到2025年,大模型不仅能为智能硬件提供强大的算法支持,还能通过数据处理、智能决策和系统集成等方面的创新,推动硬件设备的性能提升和功能拓展。本文将从多个维度分析大模型对智能硬件…...
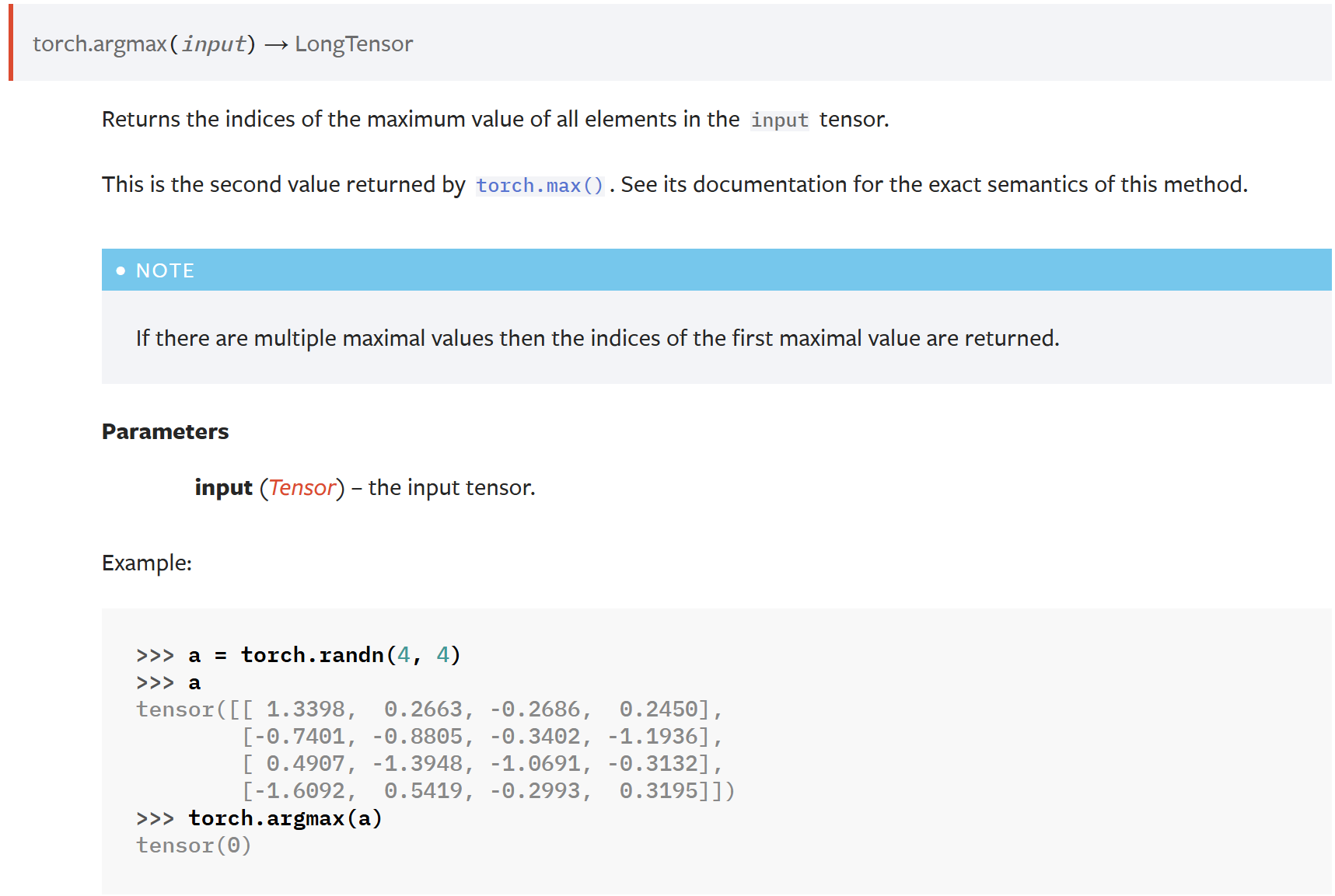
Tensor 基本操作1 unsqueeze, squeeze, softmax | PyTorch 深度学习实战
本系列文章 GitHub Repo: https://github.com/hailiang-wang/pytorch-get-started 目录 创建 Tensor常用操作unsqueezesqueezeSoftmax代码1代码2代码3 argmaxitem 创建 Tensor 使用 Torch 接口创建 Tensor import torch参考:https://pytorch.org/tutorials/beginn…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

基于2D工程图几何特征与梯度提升模型的制造成本智能预测
1. 项目概述:从图纸到报价的智能革命在制造业,尤其是像汽车零部件这样的离散制造领域,报价速度直接决定了订单的生死。传统上,拿到一张新的2D工程图(DWG格式),成本工程师需要花上几天甚至几周时…...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...

Lampiao 靶场
Lampiao 靶场完整渗透解析一、靶场环境信息攻击机(Kali)IP:192.168.146.128靶机 IP:192.168.146.129目标:获取靶机 root 权限与 flag二、步骤 1:信息收集(端口与服务扫描)nmap -p- -…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

2026年,揭秘那些真正安全的原生态食材厂家你不可不知的秘密
随着人们生活水平的提升以及对健康的日益重视,选择真正安全的原生态食材已经成为许多人购买食物的标准。但市场的繁杂使得甄别真正安全的食材厂家变得愈加困难。今天,我将通过几个关键角度,为大家揭秘那些真正安全的原生态食材厂家的秘密&…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

从零构建FOC轮腿机器人:开源平衡机器人完整指南
从零构建FOC轮腿机器人:开源平衡机器人完整指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software development. | 一个…...