Hive SQL 执行计划解析
Hive SQL 执行计划解析
一、 explain用法
1. SQL 查询
EXPLAIN SELECT SUM(view_dsp) AS view_sum
FROM ads.table_a
WHERE p_day = '2025-01-06';
2. 执行计划
STAGE DEPENDENCIES:Stage-1 is a root stageStage-0 depends on stages: Stage-1STAGE PLANS:Stage: Stage-1Map ReduceMap Operator Tree:TableScanalias: table_aStatistics: Num rows: 58083 Data size: 13900518 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: view_dsp (type: bigint)outputColumnNames: view_dspStatistics: Num rows: 58083 Data size: 13900518 Basic stats: COMPLETE Column stats: NONEGroup By Operatoraggregations: sum(view_dsp)mode: hashoutputColumnNames: _col0Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONEReduce Output Operatorsort order:Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONEvalue expressions: _col0 (type: bigint)Reduce Operator Tree:Group By Operatoraggregations: sum(VALUE._col0)mode: mergepartialoutputColumnNames: _col0Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONEtable:input format: org.apache.hadoop.mapred.TextInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeStage: Stage-0Fetch Operatorlimit: -1Processor Tree:ListSink
3. 执行计划释义
1. STAGE DEPENDENCIES
- Stage-1:根 Stage。
- Stage-0:依赖于 Stage-1,Stage-1 执行完成后执行 Stage-0。
2. STAGE PLANS
Stage: Stage-1
- Map Reduce:MR 执行计划分为两部分。
- Map Operator Tree:MAP 端的执行计划树。
- TableScan:表扫描操作,Map 端第一个操作是加载表。
alias:表名(table_a)。Statistics:表统计信息,包含表中数据条数、数据大小等。
Num rows: 58083:数据行数。Data size: 13900518:数据大小。Basic stats: COMPLETE:基本统计信息完整。Column stats: NONE:列统计信息未收集。- Select Operator:选取操作。
expressions:需要的字段名称及字段类型(view_dsp (type: bigint))。outputColumnNames:输出的列名称(view_dsp)。Statistics:表统计信息,与 TableScan 相同。- Group By Operator:分组聚合操作。
aggregations:Map 端聚合函数信息(sum(view_dsp))。mode:聚合模式,值为hash,表示随机聚合(Hash Partition)。outputColumnNames:聚合之后输出列名(_col0)。Statistics:表统计信息,包含分组聚合之后的数据条数、数据大小等。
Num rows: 1:聚合后的数据行数。Data size: 8:聚合后的数据大小。Basic stats: COMPLETE:基本统计信息完整。Column stats: NONE:列统计信息未收集。- Reduce Output Operator:Reduce 输出操作。
sort order:值为空,表示不排序。Statistics:表统计信息,与 Group By Operator 相同。value expressions:聚合后的输出字段名称及字段类型(_col0 (type: bigint))。- Reduce Operator Tree:Reduce 端的执行计划树。
- Group By Operator:分组聚合操作。
aggregations:Reduce 端聚合函数信息(sum(VALUE._col0))。mode:全局聚合模式,值为mergepartial,表示部分合并聚合。outputColumnNames:全局聚合之后输出列名(_col0)。Statistics:表统计信息,包含全局聚合之后的数据条数、数据大小等。
Num rows: 1:全局聚合后的数据行数。Data size: 8:全局聚合后的数据大小。Basic stats: COMPLETE:基本统计信息完整。Column stats: NONE:列统计信息未收集。- File Output Operator:文件输出操作。
compressed:是否压缩,值为false,表示不压缩。Statistics:表统计信息,与 Group By Operator 相同。table:输出表的格式信息。
input format:输入文件格式化方式(org.apache.hadoop.mapred.TextInputFormat)。output format:输出文件格式化方式(org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat)。serde:序列化方式(org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe)。Stage: Stage-0
- Fetch Operator:数据提取操作。
limit:值为-1,表示不限制条数。- Processor Tree:处理器树。
- ListSink:数据输出到客户端。
二、explain dependency用法
1. SQL 查询
EXPLAIN DEPENDENCY
SELECT COUNT(*)
FROM ads.table_a
WHERE p_day = '2025-01-06';
- 作用:查询表
ads.table_a中p_day = '2025-01-06'的数据行数。 EXPLAIN DEPENDENCY:用于查看查询的依赖信息,包括输入表的分区和表信息。
2. 输出
{"input_partitions": [{"partitionName": "ads@table_a@p_day=2025-01-06/p_hour=00"},{"partitionName": "ads@table_a@p_day=2025-01-06/p_hour=01"},{"partitionName": "ads@table_a@p_day=2025-01-06/p_hour=02"},....},{"partitionName": "ads@table_a@p_day=2025-01-06/p_hour=23"}],"input_tables": [{"tabletype": "MANAGED_TABLE","tablename": "ads@table_a"}]
}
3. 解析
输出是一个 JSON 格式的结果,包含两部分:
input_partitions:查询依赖的分区信息。input_tables:查询依赖的表信息。
input_partitions
"input_partitions": [{"partitionName": "ads@table_a@p_day=2025-01-06/p_hour=00"},{"partitionName": "ads@table_a@p_day=2025-01-06/p_hour=01"},...{"partitionName": "ads@table_a@p_day=2025-01-06/p_hour=23"}]
- 含义:查询依赖的分区列表。
- 分区格式:
ads@table_a@p_day=2025-01-06/p_hour=XX。ads:数据库名。table_a:表名。p_day=2025-01-06:分区键及其值(按天分区)。p_hour=XX:子分区键及其值(按小时分区,XX为 00 到 23)。
- 说明:
- 查询涉及
p_day = '2025-01-06'这一天的所有小时分区(共 24 个分区)。 - 每个分区对应一个小时的子分区(如
p_hour=00到p_hour=23)。
- 查询涉及
input_tables
"input_tables": [{"tabletype": "MANAGED_TABLE","tablename": "ads@table_a"}]
- 含义:查询依赖的表信息。
- 字段解析:
tabletype:表类型,MANAGED_TABLE表示这是一个 Hive 管理的内部表。tablename:表名,格式为数据库名@表名(ads@table_a)。
通过分析
EXPLAIN DEPENDENCY的输出,可以更好地理解查询的输入数据来源,从而优化查询性能和资源使用。
三、explain authorization用法
1. SQL 查询
EXPLAIN AUTHORIZATION
SELECT COUNT(*)
FROM ads.table_a
WHERE p_day = '2025-01-06';
- 作用:查询表
ads.table_a中p_day = '2025-01-06'的数据行数。 EXPLAIN AUTHORIZATION:用于查看查询的权限信息,包括输入表、分区、输出路径以及当前用户和操作类型。
2. 输出
INPUTS:ads@table_aads@table_a@p_day=2025-01-06/p_hour=00ads@table_a@p_day=2025-01-06/p_hour=01...ads@table_a@p_day=2025-01-06/p_hour=23
OUTPUTS:hdfs://apple/tmp/hive/ads/37fa21fb-bafb-49b8-a703-f48f1edcade9/hive_2025-01-20_18-50-55_722_2728294902974034323-1/-mr-10000
CURRENT_USER:ads
OPERATION:QUERY
3. 解析
输出分为以下几个部分:
INPUTS
ads@table_a
ads@table_a@p_day=2025-01-06/p_hour=00
ads@table_a@p_day=2025-01-06/p_hour=01
...
ads@table_a@p_day=2025-01-06/p_hour=23
- 含义:查询依赖的输入表和分区。
- 格式:
ads@table_a:数据库名和表名。ads@table_a@p_day=2025-01-06/p_hour=XX:分区信息,p_day是按天分区,p_hour是按小时分区。
- 说明:
- 查询涉及
ads.table_a表。 - 查询涉及
p_day = '2025-01-06'这一天的 24 个小时分区(p_hour=00到p_hour=23)。
- 查询涉及
OUTPUTS
hdfs://apple/tmp/hive/ads/37fa21fb-bafb-49b8-a703-f48f1edcade9/hive_2025-01-20_18-50-55_722_2728294902974034323-1/-mr-10000
- 含义:查询结果的输出路径。
- 格式:HDFS 路径,表示查询的临时输出文件。
- 说明:
- 查询结果会被写入这个临时路径。
- 路径中包含时间戳和唯一标识符,用于区分不同的查询任务。
CURRENT_USER
ads
- 含义:当前执行查询的用户。
- 说明:
- 当前用户是
ads,表示查询是以ads用户的权限执行的。
- 当前用户是
OPERATION
QUERY
- 含义:当前操作的类型。
- 说明:
- 操作类型是
QUERY,表示这是一个查询操作。
- 操作类型是
通过分析
EXPLAIN AUTHORIZATION的输出,可以更好地理解查询的权限需求和执行逻辑,从而优化查询性能和权限管理。
相关文章:

Hive SQL 执行计划解析
Hive SQL 执行计划解析 一、 explain用法 1. SQL 查询 EXPLAIN SELECT SUM(view_dsp) AS view_sum FROM ads.table_a WHERE p_day 2025-01-06;2. 执行计划 STAGE DEPENDENCIES:Stage-1 is a root stageStage-0 depends on stages: Stage-1STAGE PLANS:Stage: Stage-1Map …...
热更新杂乱记
热更新主要有一个文件的MD5值的比对过程,期间遇到2个问题,解决起来花费了一点时间 1. png 和 plist 生成zip的时候再生成MD5值会发生变动。 这个问题解决起来有2种方案: (1).第一个方案是将 png和plist的文件时间改…...
博客搭建 — GitHub Pages 部署
关于 GitHub Pages GitHub Pages 是一项静态站点托管服务,它直接从 GitHub 上的仓库获取 HTML、CSS 和 JavaScript 文件,通过构建过程运行文件,然后发布网站。 本文最终效果是搭建出一个域名为 https://<user>.github.io 的网站 创建…...
翻译:How do I reset my FPGA?
文章目录 背景翻译:How do I reset my FPGA?1、Understanding the flip-flop reset behavior2、Reset methodology3、Use appropriate resets to maximize utilization4、Many options5、About the author 背景 在写博客《复位信号的同步与释放(同步复…...

Linux 进程环境变量:深入理解与实践指南
🌟 快来参与讨论💬,点赞👍、收藏⭐、分享📤,共创活力社区。🌟 🚩用通俗易懂且不失专业性的文字,讲解计算机领域那些看似枯燥的知识点🚩 在 Linux 系统里…...
Linux探秘坊-------5.git
1.git介绍 1.版本控制器 为了能够更⽅便我们管理这些不同版本的⽂件,便有了版本控制器。所谓的版本控制器,就是能让你了解到⼀个⽂件的历史,以及它的发展过程的系统。通俗的讲就是⼀个可以记录⼯程的每⼀次改动和版本迭代的⼀个管理系统&am…...

Linux中的几个基本指令(二)
文章目录 1、cp指令例一:例二:例三:例四:例五: 2、mv 指令例一:例二: 3、cat指令例一: 4、tac指令5、which指令6、date指令时间戳:7、zip指令 今天我们继续学习Linux下的…...
)
Java入门笔记(1)
引言 在计算机编程的广袤宇宙中,Java无疑是一颗格外耀眼的恒星。那么,Java究竟是什么呢? Java是美国Sun公司(Stanford University Network)在1995年推出的一门计算机高级编程语言。曾经辉煌的Sun公司在2009年被Oracle&…...

设计模式的艺术-开闭原则
原则使用频率图(仅供参考) 1.如何理解开闭原则 简单来说,开闭原则指的是 “对扩展开放,对修改关闭”。 当软件系统需要增加新的功能时,应该通过扩展现有代码的方式来实现,而不是去修改已有的代码。 例如我…...
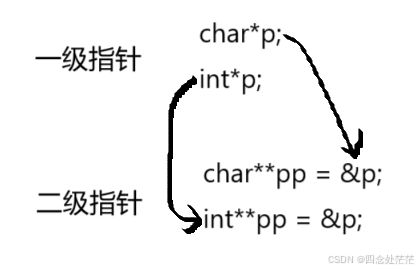
【C语言系列】深入理解指针(3)
深入理解指针(3) 一、字符指针变量二、数组指针变量2.1数组指针变量是什么?2.2数组指针变量怎么初始化? 三、二维数组传参的本质四、函数指针变量4.1函数指针变量的创建4.2函数指针变量的使用4.3两段有趣的代码4.4 typedef关键字 …...

three.js+WebGL踩坑经验合集:写在前面的话
笔者从2023年初开始参与一个基于three.js引擎的web项目的开发工作。本打算2024年春节就把期间踩过的坑写到博客上分享给大家,然而哪怕本专栏的各种构思和内容已经在笔者的脑海里翻滚了一年,得了严重拖延症患者的我还是一直拖到了现在,实在惭愧…...

利用Linux的工作队列(Workqueue)实现中断下半部的处理
本文代码在哪个基础上修改而成? 本文是在博文 https://blog.csdn.net/wenhao_ir/article/details/145228617 的代码基础上修改而成。 关于工作队列(Workqueue)的概念 工作队列(Workqueue)可以用于实现Linux的中断下半部的,之前在博文 https://blog.cs…...
LabVIEW处理复杂系统和数据处理
LabVIEW 是一个图形化编程平台,广泛应用于自动化控制、数据采集、信号处理、仪器控制等复杂系统的开发。它的图形化界面使得开发人员能够直观地设计系统和算法,尤其适合处理需要实时数据分析、高精度控制和复杂硬件集成的应用场景。LabVIEW 提供丰富的库…...
spring-springboot -springcloud
目录 spring: 动态代理: spring的生命周期(bean的生命周期): SpringMvc的生命周期: SpringBoot: 自动装配: 自动装配流程: Spring中常用的注解: Spring Boot中常用的注解: SpringCloud: 1. 注册中心: 2. gateway(网关): 3. Ribbon(负载均…...

DRG/DIP 2.0时代下基于PostgreSQL的成本管理实践与探索(下)
五、数据处理与 ETL 流程编程实现 5.1 数据抽取与转换(ETL) 在 DRG/DIP 2.0 时代的医院成本管理中,数据抽取与转换(ETL)是将医院各个业务系统中的原始数据转化为可供成本管理分析使用的关键环节。这一过程涉及从医院 HIS 系统中抽取患者诊疗数据,并对其进行格式转换、字…...

打造本地音乐库
文章目录 存储介质硬盘(NAS)媒体播放器(可视MP3、MP4)实体介质(CD光盘、黑胶片)注意事项为什么不使用在线音乐(App)和网盘打造一套HiFi系统的成本非常高 获取音乐正版音乐途径免费音…...

【2024 - 年终总结】叶子增长,期待花开
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 前言论博客创作保持2024的记录清单博客科研开源工作生活 总结与展望互动致谢参考 前言…...

python 统计相同像素值个数
目录 python 统计相同像素值个数 最大值附近的值 python 统计相同像素值个数 import cv2 import numpy as np import time from collections import Counter# 读取图像 image cv2.imread(mask16.jpg)# 将图像转换为灰度图像 gray_image cv2.cvtColor(image, cv2.COLOR_BGR2…...
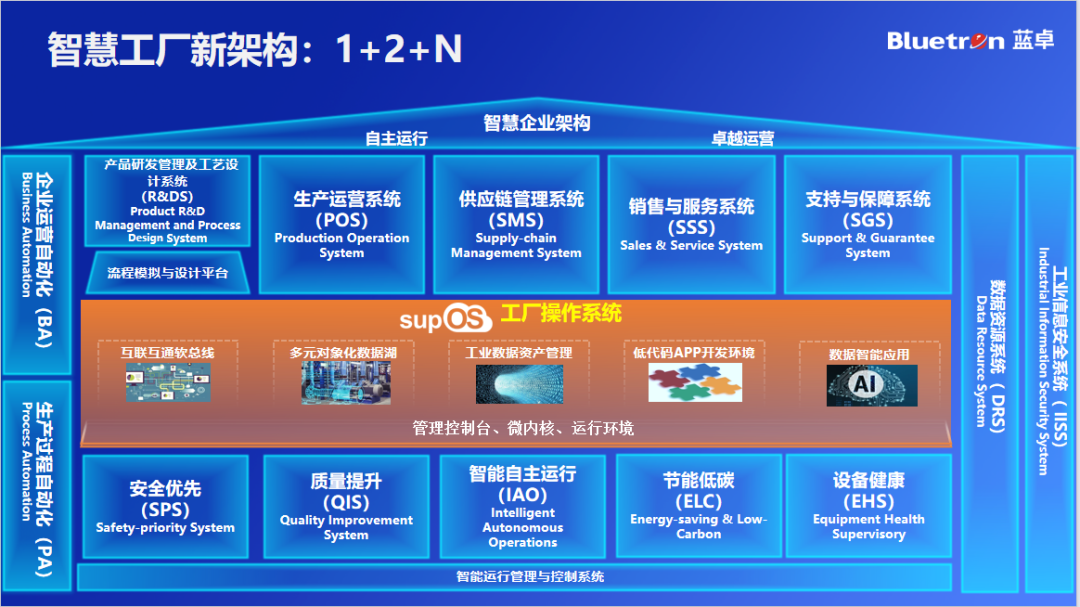
蓝卓“1+2+N”智慧工厂架构,让工业智能更简单
面对复杂的工业环境、海量的数据以及多样化的业务需求,如何实现智能化转型,让工业智能触手可及,成为了众多企业面临的难题。蓝卓以创新精神为引领,推出了“12N”智慧工厂架构,旨在简化工业智能的实现路径,让…...

12、MySQL锁相关知识
目录 1、全局锁和表锁使用场景 2、行锁的意义 3、为什么说间隙锁解决了快照的幻读? 4、RR隔离级别产生幻读的场景 5、详解元数据锁(MDL)作用以及如何减少元数据锁 6、出现死锁场景 7、查看MySQL锁情况 8、自增锁 1、全局锁和表锁使用场景 全局锁 备份数据库:当需要…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

机器学习与SHAP在教育公平研究中的应用:精准定位学业困境根源
1. 项目概述:当机器学习遇见教育公平,我们如何精准定位学业困境的根源?在拉丁美洲的教育研究领域,一个长期困扰政策制定者和研究者的核心问题是:究竟是什么因素,在复杂的社会经济背景下,系统性地…...

Gofile批量下载自动化工具:5步实现高效文件管理解决方案
Gofile批量下载自动化工具:5步实现高效文件管理解决方案 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在当今数字化工作环境中,技术团队经常需要从…...

基于IRS2092的200W D类功放设计:从PWM原理到保护电路实战
1. 项目概述与核心思路折腾音响功放,从经典的AB类玩到D类,感觉就像是从燃油车换到了电动车,动力响应和效率完全是两个维度。这次要聊的这块“200W Class-D Audio Power Amplifier [150115]”单板功放,就是一个非常典型的D类功放设…...

概率论:常见分布的期望与方差、中心极限定理、切比雪夫不等式
目录 一、0、1分布 二、二项分布 三、泊松分布 四、均匀分布 五、指数分布 六、正态分布 七、中心极限定理及其应用 (1)中心极限定理的定义 (2)使用示例 八、切比雪夫不等式 (1)切比雪夫不…...

KMS智能激活工具:如何一键永久激活Windows和Office的完整指南
KMS智能激活工具:如何一键永久激活Windows和Office的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office激活问题而烦恼吗?每次系统重装后都要…...

如何用500KB工具完全替代AWCC:AlienFX Tools终极指南
如何用500KB工具完全替代AWCC:AlienFX Tools终极指南 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 你是否厌倦了Alienware Command Cente…...

Frida Spawn与Attach模式深度解析:Android加固对抗决策指南
1. 为什么刚学Frida的人总在Spawn和Attach之间反复横跳? “Frida Hook跑不起来”——这是我过去三年在安全技术社区、逆向学习群、CTF训练营里听到最多的一句抱怨。但真正拆开看,90%的问题根本不是代码写错了,也不是目标App加固太强ÿ…...