6. 马科维茨资产组合模型+政策意图AI金融智能体(DeepSeek-V3)增强方案(理论+Python实战)
目录
- 0. 承前
- 1. 幻方量化 & DeepSeek
- 1.1 What is 幻方量化
- 1.2 What is DeepSeek
- 2. 重写AI金融智能体函数
- 3. 汇总代码
- 4. 反思
- 4.1 不足之处
- 4.2 提升思路
- 5. 启后
0. 承前
本篇博文是对上一篇文章,链接:
5. 马科维茨资产组合模型+政策意图AI金融智能体(Qwen-Max)增强方案(理论+Python实战)
的AI金融智能体更改为幻方量化DeepSeek-V3的尝试。
唯一区别之处在于上文中的get_ai_weights函数,如果需要整体金融工程的思路流程,可以在上文直接跳转,本文中会直接给出修改地方,与能够直接运行的汇总代码。
本文主旨:
- 用文章向大家展示低耦合开发的优点,如本文与上一篇文章的转换只需要重写一个函数即可;
- 使用实际代码,向大家展示最常用的AI金融智能体接口:openai、dashcode;
如果想更加全面清晰地了解金融资产组合模型进化论的体系架构,可参考:
0. 金融资产组合模型进化全图鉴
1. 幻方量化 & DeepSeek
1.1 What is 幻方量化
幻方量化(High-Flyer Quant)是中国领先的量化投资机构之一,成立于2008年,专注于利用人工智能(AI)和机器学习技术进行量化投资。其名称“幻方”源自古代数学中的幻方矩阵,象征着数学与科学的逻辑魅力。幻方量化的核心业务是通过大数据分析、深度学习模型和强大的计算能力,开发量化交易策略,为投资者提供资产管理服务。
1.2 What is DeepSeek
-
低成本训练:DeepSeek通过创新的算法和硬件优化,大幅降低了模型训练成本。例如,其最新模型DeepSeek-V3的训练成本仅为557万美元,远低于OpenAI等巨头的数十亿美元投入。
-
创新架构:DeepSeek采用了MLA(多头潜在注意力机制)和DeepSeekMoE(混合专家模型)等创新架构,显著提升了模型的训练效率和推理性能。
-
高性能表现:DeepSeek-V3在多项基准测试中表现优异,尤其在数学推理、代码生成和中文处理能力上超越了众多开源和闭源模型,甚至与GPT-4等顶尖模型媲美。
2. 重写AI金融智能体函数
登录DeepSeek官网获取 api,并使用OpenAI格式的对话函数。代码实现:
def get_ai_weights(character, policy_info, updated_result, api_key):# 定义发送对话内容messages = [{'role': 'system', 'content': character},{'role': 'user', 'content': policy_info},{'role': 'user', 'content': json.dumps(updated_result, ensure_ascii=False)}]client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com")response = client.chat.completions.create(model="deepseek-chat",messages=messages,stream=False)# 提取content内容content = response.choices[0].message.content# 将JSON字符串转换为Python字典portfolio_weights = json.loads(content)# 对AI输出结果进行归一化weights_sum = sum(portfolio_weights.values())portfolio_weights = {key: value/weights_sum for key, value in portfolio_weights.items()}# 将字典中的值修改为6位小数portfolio_weights = {k: round(v, 6) for k, v in portfolio_weights.items()}return portfolio_weights
3. 汇总代码
import tushare as ts
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
from scipy.optimize import minimize
import backtrader as bt
import statsmodels.api as sm
import os
import json
import dashscope# 参数集##############################################################################
ts.set_token('token')
pro = ts.pro_api()
industry = '银行'
end_date = '20240101'
years = 5 # 数据时长
risk_free_rate = 0.03 # 无风险利率参数
top_holdings = 10 # 持仓数量参数
index_code = '000300.SH' # 市场指数代码参数
api_key='sk-api_key' # DeepSeek-V3 APIcharacter = f'''
你是一名专业的金融数据与政策分析师,擅长解读金融市场动态和政策导向,并据此调整资产组合的权重分布,以优化投资策略。你的主要任务是对给定的资产组合进行权重调整,确保:
1. 权重之和精确为1;
2. 每个资产调整后的权重只能在原有基础上增减最多10%;
3. 每个资产调整完毕后,如果权重之和不等于1,则归一化使权重之和精确为1;
4. 数据对应的日期是{end_date},在思考过程中,切勿根据该日期之后的信息进行思考。
5. 输出的数据格式需与输入保持一致,仅提供数据而不做额外解释;当你接收到具体的资产组合及其权重时,请根据最新的金融数据和政策信息对其进行合理调整。
'''# 通过工作流获取的政策信息
policy_info = '''
| 日期 | 政策简述 |
|------|----------|
| 2023-12-29 | 央行发布《关于优化商业银行存款利率监管有关事项的通知》,取消定期存款利率浮动上限,允许银行自主协调存贷款利率 |
| 2023-11-17 | 央行、银保监会联合发布《关于做好当前商业银行房地产贷款投放管理的通知》,优化房地产信贷政策,支持刚性和改善性住房需求 |
| 2023-09-25 | 银保监会发布《关于进一步加强银行业金融机构流动性风险管理的通知》,要求银行加强流动性风险管理,完善风险监测预警机制 |
| 2023-08-31 | 央行、银保监会宣布下调全国首套住房贷款利率下限,各地可自主决定下调幅度,二套房贷款利率政策与首套相同 |
| 2023-07-21 | 十四届全国人大常委会第四次会议表决通过《中华人民共和国金融稳定法》,建立健全金融风险防范化解制度体系 |
'''
# 参数集##############################################################################def get_industry_stocks(industry):"""获取指定行业的股票列表"""df = pro.stock_basic(fields=["ts_code", "name", "industry"])industry_stocks = df[df["industry"]==industry].copy()industry_stocks.sort_values(by='ts_code', inplace=True)industry_stocks.reset_index(drop=True, inplace=True)return industry_stocks['ts_code'].tolist()def get_data(code_list, end_date, years):"""获取指定行业名称的历史收盘价数据"""ts_code_list = code_listend_date_dt = datetime.strptime(end_date, '%Y%m%d')start_date_dt = end_date_dt - timedelta(days=years*365)start_date = start_date_dt.strftime('%Y%m%d')all_data = []for stock in ts_code_list:df = pro.daily(ts_code=stock, start_date=start_date, end_date=end_date)all_data.append(df)combined_df = pd.concat(all_data).sort_values(by=['ts_code', 'trade_date'])combined_df.reset_index(drop=True, inplace=True)combined_df.rename(columns={'trade_date': 'date'}, inplace=True)return combined_dfdef get_market_data(index_code='000300.SH', start_date=None, end_date=None):"""获取市场指数数据用于计算贝塔"""df_market = pro.index_daily(ts_code=index_code,start_date=start_date,end_date=end_date,fields=['trade_date', 'close'])df_market['date'] = pd.to_datetime(df_market['trade_date'])df_market.set_index('date', inplace=True)df_market = df_market.sort_index()monthly_last_close = df_market['close'].resample('M').last()monthly_log_returns = np.log(monthly_last_close).diff().dropna()return monthly_log_returnsdef get_factor_data(stock_codes, start_date=None, end_date=None):"""获取指定股票的因子数据(市值和PB)"""all_factor_data = []for stock in stock_codes:try:df = pro.daily_basic(ts_code=stock,start_date=start_date,end_date=end_date,fields=['ts_code', 'trade_date', 'total_mv', 'pb'])all_factor_data.append(df)except Exception as e:print(f"获取股票 {stock} 的因子数据失败: {str(e)}")continuefactor_data = pd.concat(all_factor_data, ignore_index=True)factor_data['trade_date'] = pd.to_datetime(factor_data['trade_date'])return factor_datadef get_fina_data(stock_codes, start_date=None, end_date=None):"""获取指定股票的财务指标数据(ROE和资产增长率)"""all_fina_data = []for stock in stock_codes:try:df = pro.fina_indicator(ts_code=stock,start_date=start_date,end_date=end_date,fields=['ts_code', 'end_date', 'roe_dt', 'assets_yoy', 'update_flag'])all_fina_data.append(df)except Exception as e:print(f"获取股票 {stock} 的财务数据失败: {str(e)}")continue# 合并数据fina_data = pd.concat(all_fina_data, ignore_index=True)# 处理update_flag,保留最新数据fina_data = (fina_data.groupby(['ts_code', 'end_date']).agg({'roe_dt': 'first','assets_yoy': 'first','update_flag': 'max'}).reset_index())# 将end_date转换为datetimefina_data['end_date'] = pd.to_datetime(fina_data['end_date'])# 创建季度到月度的映射monthly_data = []for _, row in fina_data.iterrows():quarter_end = row['end_date']if quarter_end.month == 3: # Q1months = [quarter_end + pd.DateOffset(months=i) for i in range(1, 4)]elif quarter_end.month == 6: # Q2months = [quarter_end + pd.DateOffset(months=i) for i in range(1, 4)]elif quarter_end.month == 9: # Q3months = [quarter_end + pd.DateOffset(months=i) for i in range(1, 4)]else: # Q4months = [quarter_end + pd.DateOffset(months=i) for i in range(1, 4)]for month in months:monthly_data.append({'ts_code': row['ts_code'],'trade_date': month,'roe_dt': row['roe_dt'],'assets_yoy': row['assets_yoy']})monthly_df = pd.DataFrame(monthly_data)return monthly_dfdef calculate_monthly_log_returns(df):"""计算每月的对数收益率"""df['date'] = pd.to_datetime(df['date'])monthly_last_close = df.groupby(['ts_code', pd.Grouper(key='date', freq='M')])['close'].last().unstack(level=-1)monthly_log_returns = np.log(monthly_last_close).diff().dropna()return monthly_log_returns.Tdef calculate_expected_returns(monthly_log_returns):"""使用Fama-French五因子模型计算各股票的预期收益率"""start_date = monthly_log_returns.index.min().strftime('%Y%m%d')end_date = monthly_log_returns.index.max().strftime('%Y%m%d')# 获取财务数据时,将start_date往前推一个季度,以确保有完整的季度数据fina_start_date = (datetime.strptime(start_date, '%Y%m%d') - timedelta(days=90)).strftime('%Y%m%d')# 获取市场收益率market_returns = get_market_data(index_code, start_date, end_date)# 获取股票的市值和PB数据stock_data = get_factor_data(monthly_log_returns.columns.tolist(),start_date,end_date)# 获取财务指标数据,使用提前的start_datefina_data = get_fina_data(monthly_log_returns.columns.tolist(),fina_start_date,end_date)# 确保所有数据的日期对齐aligned_dates = monthly_log_returns.index.intersection(market_returns.index)market_returns = market_returns[aligned_dates]stock_returns = monthly_log_returns.loc[aligned_dates].copy() # 使用copy()避免SettingWithCopyWarningdef calculate_size_factor(date):date_data = stock_data[stock_data['trade_date'].dt.to_period('M') == date.to_period('M')]median_mv = date_data['total_mv'].median()small_returns = stock_returns.loc[date, date_data[date_data['total_mv'] <= median_mv]['ts_code']]big_returns = stock_returns.loc[date, date_data[date_data['total_mv'] > median_mv]['ts_code']]return small_returns.mean() - big_returns.mean()def calculate_value_factor(date):date_data = stock_data[stock_data['trade_date'].dt.to_period('M') == date.to_period('M')]# 创建date_data的副本并计算bm_ratiodate_data = date_data.copy()date_data.loc[:, 'bm_ratio'] = 1 / date_data['pb']median_bm = date_data['bm_ratio'].median()high_returns = stock_returns.loc[date, date_data[date_data['bm_ratio'] > median_bm]['ts_code']]low_returns = stock_returns.loc[date, date_data[date_data['bm_ratio'] <= median_bm]['ts_code']]return high_returns.mean() - low_returns.mean()def calculate_profitability_factor(date):date_data = fina_data[fina_data['trade_date'].dt.to_period('M') == date.to_period('M')]median_roe = date_data['roe_dt'].median()robust_returns = stock_returns.loc[date, date_data[date_data['roe_dt'] > median_roe]['ts_code']]weak_returns = stock_returns.loc[date, date_data[date_data['roe_dt'] <= median_roe]['ts_code']]return robust_returns.mean() - weak_returns.mean()def calculate_investment_factor(date):date_data = fina_data[fina_data['trade_date'].dt.to_period('M') == date.to_period('M')]median_growth = date_data['assets_yoy'].median()conservative_returns = stock_returns.loc[date, date_data[date_data['assets_yoy'] <= median_growth]['ts_code']]aggressive_returns = stock_returns.loc[date, date_data[date_data['assets_yoy'] > median_growth]['ts_code']]return conservative_returns.mean() - aggressive_returns.mean()# 计算每个月的因子收益smb_factor = pd.Series([calculate_size_factor(date) for date in aligned_dates], index=aligned_dates)hml_factor = pd.Series([calculate_value_factor(date) for date in aligned_dates], index=aligned_dates)rmw_factor = pd.Series([calculate_profitability_factor(date) for date in aligned_dates], index=aligned_dates)cma_factor = pd.Series([calculate_investment_factor(date) for date in aligned_dates], index=aligned_dates)# 使用OLS回归计算每个股票的因子载荷factor_loadings = {}for stock in stock_returns.columns:X = sm.add_constant(pd.concat([market_returns - risk_free_rate,smb_factor,hml_factor,rmw_factor,cma_factor], axis=1))y = stock_returns[stock] - risk_free_ratemodel = sm.OLS(y, X).fit()factor_loadings[stock] = model.params[1:]# 计算因子风险溢价market_premium = market_returns.mean() - risk_free_ratesmb_premium = smb_factor.mean()hml_premium = hml_factor.mean()rmw_premium = rmw_factor.mean()cma_premium = cma_factor.mean()# 使用FF5模型计算预期收益率expected_returns = pd.Series({stock: (risk_free_rate +loadings.iloc[0] * market_premium +loadings.iloc[1] * smb_premium +loadings.iloc[2] * hml_premium +loadings.iloc[3] * rmw_premium +loadings.iloc[4] * cma_premium)for stock, loadings in factor_loadings.items()})return expected_returnsdef calculate_covariance_matrix(monthly_log_returns):"""计算收益率协方差矩阵"""return monthly_log_returns.cov()def portfolio_performance(weights, mean_returns, cov_matrix):"""计算投资组合的表现"""returns = np.sum(mean_returns * weights)std_dev = np.sqrt(np.dot(weights.T, np.dot(cov_matrix, weights)))return returns, std_devdef negative_sharpe_ratio(weights, mean_returns, cov_matrix, risk_free_rate):"""计算负夏普比率"""p_ret, p_std = portfolio_performance(weights, mean_returns, cov_matrix)sharpe_ratio = (p_ret - risk_free_rate) / p_stdreturn -sharpe_ratiodef max_sharpe_ratio(mean_returns, cov_matrix, risk_free_rate):"""计算最大夏普比率的投资组合权重"""num_assets = len(mean_returns)args = (mean_returns, cov_matrix, risk_free_rate)constraints = ({'type': 'eq', 'fun': lambda x: np.sum(x) - 1})bounds = tuple((0, 1) for asset in range(num_assets))result = minimize(negative_sharpe_ratio, num_assets*[1./num_assets], args=args,method='SLSQP', bounds=bounds, constraints=constraints)return result.xdef calculate_top_holdings_weights(optimal_weights, monthly_log_returns_columns, top_n):"""计算前N大持仓的权重占比"""result_dict = {asset: weight for asset, weight in zip(monthly_log_returns_columns, optimal_weights)}top_n_holdings = sorted(result_dict.items(), key=lambda item: item[1], reverse=True)[:top_n]top_n_sum = sum(value for _, value in top_n_holdings)updated_result = {key: value / top_n_sum for key, value in top_n_holdings}return updated_resultdef get_ai_weights(character, policy_info, updated_result, api_key):# 定义发送对话内容messages = [{'role': 'system', 'content': character},{'role': 'user', 'content': policy_info},{'role': 'user', 'content': json.dumps(updated_result, ensure_ascii=False)}]client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com")response = client.chat.completions.create(model="deepseek-chat",messages=messages,stream=False)# 提取content内容content = response.choices[0].message.content# 将JSON字符串转换为Python字典portfolio_weights = json.loads(content)# 对AI输出结果进行归一化weights_sum = sum(portfolio_weights.values())portfolio_weights = {key: value/weights_sum for key, value in portfolio_weights.items()}# 将字典中的值修改为6位小数portfolio_weights = {k: round(v, 6) for k, v in portfolio_weights.items()}return portfolio_weightsdef main():# 获取数据code_list = get_industry_stocks(industry)df = get_data(code_list, end_date, years)# 计算每月的对数收益率monthly_log_returns = calculate_monthly_log_returns(df)# 使用FF5模型计算预期收益率mean_returns = calculate_expected_returns(monthly_log_returns)# 计算收益率协方差矩阵cov_matrix = calculate_covariance_matrix(monthly_log_returns)# 优化权重optimal_weights = max_sharpe_ratio(mean_returns, cov_matrix, risk_free_rate)# 计算前N大持仓权重updated_result = calculate_top_holdings_weights(optimal_weights,monthly_log_returns.columns,top_holdings)# 计算AI调仓后的持仓权重updated_result = get_ai_weights(character, policy_info, updated_result, api_key)# 打印更新后的资产占比print(f"\n{end_date}最优资产前{top_holdings}占比:")print(updated_result)if __name__ == "__main__":main()
运行结果:
AI金融智能(DeepSeek-V3)体调仓后权重:
{'601398.SH': 0.166525, '601328.SH': 0.165165, '600919.SH': 0.134011, '600036.SH': 0.112955, '601169.SH': 0.092157,
'600016.SH': 0.086663, '601166.SH': 0.084316, '601288.SH': 0.062868, '600908.SH': 0.053454, '600926.SH': 0.041885}
与Qwen-Max进行对比:
| 股票代码 | 股票占比(Qwen-Max) | 股票占比(DeepSeek-V3) |
|---|---|---|
| 601398.SH | 0.163025 | 0.166525 |
| 601328.SH | 0.161623 | 0.165165 |
| 600919.SH | 0.129252 | 0.134011 |
| 600036.SH | 0.107372 | 0.112955 |
| 601169.SH | 0.095764 | 0.092157 |
| 600016.SH | 0.090046 | 0.086663 |
| 601166.SH | 0.087606 | 0.084316 |
| 601288.SH | 0.065323 | 0.062868 |
| 600908.SH | 0.055541 | 0.053454 |
| 600926.SH | 0.044449 | 0.041885 |
DeepSeek-V3相较于Qwen-Max,通过保守的风格调整资产权重,降低高波动性资产的占比,保持重点资产的较高权重,展现出较低的风险偏好和对稳健收益的追求。它注重分散化投资和长期价值,旨在实现投资组合的稳定增长,适合寻求风险控制与稳定回报的投资者。
其他尝试:或许我们能够直接在人设提示词工程,让AI金融智能体更加趋向于高波动&高收益。
4. 反思
4.1 不足之处
- 政策信息获取:获取政策信息方案仍为半手动
- AI逻辑缜密度:AI可能未能完全按照提示词工程执行
4.2 提升思路
- 更换提示词工程
- 工作流接入金融工程内部,实现真正全自动
5. 启后
-
优化,(思路):,可参考下一篇文章:
pass -
量化回测实现,可参考下一篇文章:
pass
相关文章:
增强方案(理论+Python实战))
6. 马科维茨资产组合模型+政策意图AI金融智能体(DeepSeek-V3)增强方案(理论+Python实战)
目录 0. 承前1. 幻方量化 & DeepSeek1.1 What is 幻方量化1.2 What is DeepSeek 2. 重写AI金融智能体函数3. 汇总代码4. 反思4.1 不足之处4.2 提升思路 5. 启后 0. 承前 本篇博文是对上一篇文章,链接: 5. 马科维茨资产组合模型政策意图AI金融智能体(Qwen-Max)增…...

Unity自学之旅05
Unity自学之旅05 Unity学习之旅⑤📝 AI基础与敌人行为🥊 AI导航理论知识(基础)开始实践 🎃 敌人游戏机制追踪玩家攻击玩家子弹碰撞完善游戏失败条件 🤗 总结归纳 Unity学习之旅⑤ 📝 AI基础与敌…...

linux中关闭服务的开机自启动
引言 systemctl 是 Linux 系统中用于管理 systemd 服务的命令行工具。它可以用来启动、停止、重启服务,管理服务的开机自启动,以及查看服务的状态等。 什么是 systemd? systemd 是现代 Linux 发行版中默认的 初始化系统(init sys…...

Python----Python高级(文件操作open,os模块对于文件操作,shutil模块 )
一、文件处理 1.1、文件操作的重要性和应用场景 1.1.1、重要性 数据持久化: 文件是存储数据的一种非常基本且重要的方式。通过文件,我们可 以将程序运行时产生的数据永久保存下来,以便将来使用。 跨平台兼容性: 文件是一种通用…...

ubuntu黑屏问题解决
重启Ubuntu后,系统自动进入tty1,无法进入桌面。想到前几天安装了一些主题之类的,然后今天才重启,可能是这些主题造成冲突或者问题了把。 这里直接重新安装ubuntu-desktop解决: 更新源: sudo apt-get upd…...

Java如何实现反转义
Java如何实现反转义 前提 最近做的一个需求,是热搜词增加换一批的功能。功能做完自测后,交给了测试伙伴,但是测试第二天后就提了一个bug,出现了未知词 levis。第一眼看着像公司售卖的一个品牌-李维斯。然后再扒前人写的代码&…...

动态规划(路径问题)
62. 不同路径 62. 不同路径 - 力扣(LeetCode) 动态规划思想第一步:描述状态~ dp[i][j]:表示走到i,j位置时,一共有多少种方法~ 动态规划思想第二步:状态转移方程~ 动态规划思想第三步…...

python http调用视觉模型moondream
目录 一、什么是moondream 二、资源地址 三、封装了http进行接口请求 四、代码解析 解释 可能的改进 一、什么是moondream Moondream 是一个针对视觉生成任务的深度学习模型,专注于图像理解和生成,包括图像标注(captioning)、问题回答(Visual Question Answering,…...

Spark Streaming编程基础
文章目录 1. 流式词频统计1.1 Spark Streaming编程步骤1.2 流式词频统计项目1.2.1 创建项目1.2.2 添加项目依赖1.2.3 修改源目录1.2.4 添加scala-sdk库1.2.5 创建日志属性文件 1.3 创建词频统计对象1.4 利用nc发送数据1.5 启动应用,查看结果 2. 编程模型的基本概念3…...

深入 Flutter 和 Compose 的 PlatformView 实现对比,它们是如何接入平台控件
在上一篇《深入 Flutter 和 Compose 在 UI 渲染刷新时 Diff 实现对比》发布之后,收到了大佬的“催稿”,想了解下 Flutter 和 Compose 在 PlatformView 实现上的对比,恰好过去写过不少 Flutter 上对于 PlatformView 的实现,这次恰好…...

C# OpenCV机器视觉:红外体温检测
在一个骄阳似火的夏日,全球却被一场突如其来的疫情阴霾笼罩。阿强所在的小镇,平日里熙熙攘攘的街道变得冷冷清清,人们戴着口罩,行色匆匆,眼神中满是对病毒的恐惧。阿强作为镇上小有名气的科技达人,看着这一…...

FCA-FineDataLink认证
FCA-FineDataLink证书 Part.1:判断题 (总分:18分 得分:16) 第1题 判断题 数据同步只支持写入到已存在表,不支持自动建表(得分:2分 满分:2分) 正确答案:B 你的答案&…...

第19篇:python高级编程进阶:使用Flask进行Web开发
第19篇:python高级编程进阶:使用Flask进行Web开发 内容简介 在第18篇文章中,我们介绍了Web开发的基础知识,并使用Flask框架构建了一个简单的Web应用。本篇文章将深入探讨Flask的高级功能,涵盖模板引擎(Ji…...

js截取video视频某一帧为图片
1.代码如下 <template><div class"box"><div class"video-box"><video controls ref"videoRef" preload"true"src"https://qt-minio.ictshop.com.cn:9000/resource-management/2025/01/08/7b96ac9d957c45a…...

[云讷科技]Kerloud Falcon四旋翼飞车虚拟仿真空间发布
虚拟仿真环境作为一个独立的专有软件包提供给我们的客户,用于帮助用户在实际测试之前验证自身的代码,并通过在仿真引擎中添加新的场景来探索新的飞行驾驶功能。 环境要求 由于环境依赖关系,虚拟仿真只能运行在装有Ubuntu 18.04的Intel-64位…...

Jetson nano 安装 PCL 指南
本指南帮助 ARM64 架构的 Jetson Nano 安装 PCL(点云库)。 安装步骤 第一步:安装依赖 在终端中运行以下命令,安装 PCL 所需的依赖: sudo apt-get update sudo apt-get install git build-essential linux-libc-dev s…...

go-zero框架基本配置和错误码封装
文章目录 加载配置信息配置 env加载.env文件配置servicecontext 查询数据生成model文件执行查询操作 错误码封装配置拦截器错误码封装 接上一篇:《go-zero框架快速入门》 加载配置信息 配置 env 在项目根目录下新增 .env 文件,可以配置当前读取哪个环…...
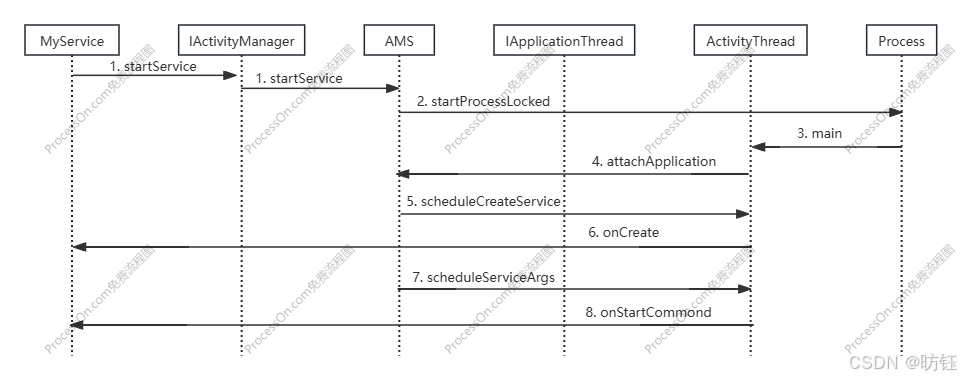
Android中Service在新进程中的启动流程2
目录 1、Service在客户端的启动入口 2、Service启动在AMS的处理 3、Service在新进程中的启动 4、Service与AMS的关系再续 上一篇文章中我们了解了Service在新进程中启动的大致流程,同时认识了与客户端进程交互的接口IApplicationThread以及与AMS交互的接口IActi…...
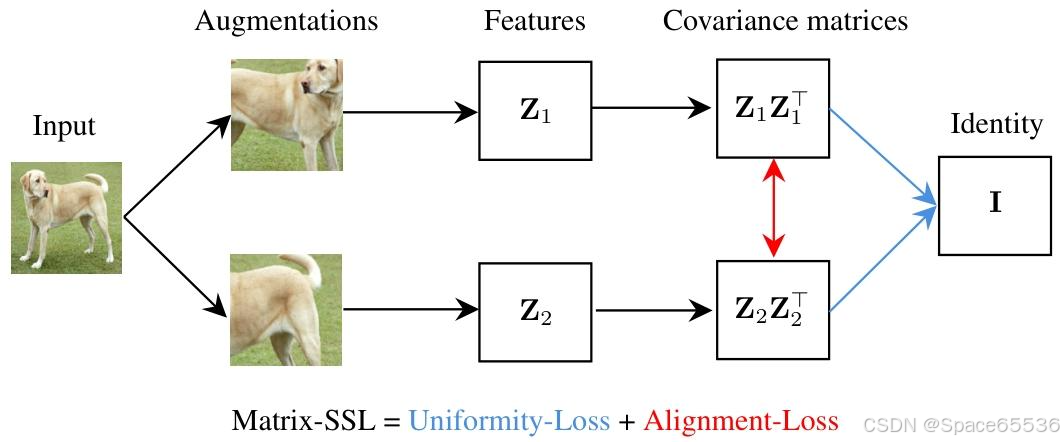
论文速读|Matrix-SSL:Matrix Information Theory for Self-Supervised Learning.ICML24
论文地址:Matrix Information Theory for Self-Supervised Learning 代码地址:https://github.com/yifanzhang-pro/matrix-ssl bib引用: article{zhang2023matrix,title{Matrix Information Theory for Self-Supervised Learning},author{Zh…...
)
ubunut22.04安装docker(基于阿里云 Docker 镜像源安装 Docker)
安装 更新包管理器: sudo apt update 安装 Docker 的依赖包 sudo apt install apt-transport-https ca-certificates curl gnupg lsb-release添加阿里云 Docker 镜像源 GPG 密钥: curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gp…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...

碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理
碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...

告别鼠标点击,微博图片批量下载的轻松方案
告别鼠标点击,微博图片批量下载的轻松方案 【免费下载链接】weiboPicDownloader Download weibo images without logging-in 项目地址: https://gitcode.com/gh_mirrors/we/weiboPicDownloader 还记得那个周末的下午吗?你喜欢的博主发布了九宫格美…...