AIGC视频扩散模型新星:Video 版本的SD模型
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍慕尼黑大学携手 NVIDIA 等共同推出视频生成模型 Video LDMs。NVIDIA 在 AI 领域的卓越成就家喻户晓,而慕尼黑大学同样不容小觑,他们深度参与了最初 SD 系列图像生成模型的研发,在扩散模型领域,展现出了强劲实力 。

🌺优质专栏回顾🌺:
- 机器学习笔记
- 深度学习笔记
- 多模态论文笔记
- AIGC—图像
文章目录
- 论文
- 摘要
- 1. 引言
- 贡献
- 2. 背景
- 扩散模型(DMs)
- 潜在扩散模型(LDMs)
- 3. 潜在视频扩散模型
- 3.1 将潜在图像转变为视频生成器
- 3.1.1 时间自动编码器微调
- 3.2 长视频生成的预测模型
- 3.3 高帧率的时间插值
- 3.4 超分辨率模型的时间微调
- 总结
- 4. 实验
- 数据集
- 评估指标
- 模型架构和采样
- 4.1 高分辨率驾驶视频合成
- 4.1.1 消融研究
- 4.1.2 驾驶场景模拟
- 4.2 使用稳定扩散的文本到视频
- 4.2.1 使用DreamBooth的个性化文本到视频
- 5. 结论
论文
论文地址:https://arxiv.org/pdf/2304.08818
项目地址:https://research.nvidia.com/labs/toronto-ai/VideoLDM/
摘要
在图像生成领域,潜在扩散模型(LDMs)取得了重大成功,通过在低维潜在空间中训练扩散模型,避免了过高的计算需求的同时,能够实现高质量的图像合成
本文中,作者将LDM范式应用于高分辨率视频生成领域。过程如下:
- 首先仅在图像上预训练一个LDM;
- 然后,通过在潜在空间扩散模型中引入时间维度;
- 在编码后的图像序列(即视频)上进行微调,将图像生成器转变为视频生成器。
- 对扩散模型的上采样器进行时间对齐,将它们转变为时间一致的视频超分辨率模型。
本文中,作者专注于两个实际相关的应用:野外驾驶数据的模拟和基于文本到视频建模的创意内容创作。
这种情况下,可以通过训练一个时间对齐模型,结合预训练图像LDM(如SD系列模型),转变为一个高效且表现力强的文本到视频模型。
1. 引言
1.图像生成模型发展:因基础建模方法突破,图像生成模型备受关注,强大模型基于生成对抗网络、自回归变换器和扩散模型构建,其中扩散模型优势明显,训练目标稳健可扩展且,并且通常比基于变换器的模型参数更少。
2. 视频建模现状:图像领域进展巨大,但视频建模滞后。原因是视频数据训练成本高且缺乏合适数据集,多数视频合成工作只能生成低分辨率短视频,包括之前的视频扩散模型。
3. 研究内容:本文将视频模型应用于实际,生成高分辨率长视频,聚焦两个实际相关问题:一是高分辨率真实世界驾驶数据的视频合成,可用于自动驾驶模拟;二是用于创意内容生成的文本引导视频合成。
4. 研究基础与模型提出:本文基于潜在扩散模型(LDMs)展开研究,提出Video LDMs,将其应用于高分辨率视频生成任务,LDMs可减轻高分辨率图像训练的计算负担。
5. 模型构建方法:
先在大规模图像数据集在图像上预训练Video LDMs(或用现有预训练图像LDMs)。通过在潜在空间DM引入时间维度,固定预训练空间层的同时仅在编码后的图像序列(即视频)上训练这些时间层,将LDM图像生成器转变为视频生成器(图2);

图2. 时间视频微调。我们将预训练的图像扩散模型转变为时间一致的视频生成器。最初,模型合成的一批不同样本是相互独立的。在时间视频微调后,样本在时间上对齐,形成连贯的视频。图中可视化了一个一维玩具分布的扩散模型在微调前后的随机生成过程。为清晰起见,该图对应于像素空间中的对齐。在实践中,我们在LDM的潜在空间中进行对齐,并在应用LDM的解码器后获得视频(见图3)。我们还在像素或潜在空间中对扩散模型上采样器进行视频微调(第3.4节)。
-
微调LDM解码器:在像素空间中实现时间一致性(图3);

图3. 上:在时间解码器微调期间,我们使用固定的编码器处理视频序列,该编码器独立处理帧,并强制跨帧进行时间连贯的重建。我们还使用了一个视频感知判别器。下:在LDMs中,一个扩散模型在潜在空间中进行训练。它合成潜在特征,然后通过解码器将其转换为图像。请注意,下图是针对单个帧的可视化;关于生成时间一致的帧序列的视频微调框架,请见图2。
为了进一步提高空间分辨率,我们还对像素空间和潜在DM上采样器进行时间对齐,这些上采样器广泛用于图像超分辨率,将它们转变为时间一致的视频超分辨率模型。
-
模型优势与实验成果:Video LDMs 能够以计算和内存高效的方式生成全局连贯且长的视频。作者对方法进行了消融实验,实现了最先进的视频质量,并合成了长达几分钟的视频。
-
研究意义:通过对稳定扩散(Stable Diffusion)进行视频微调,将其转变为一个高效且强大的文本到视频生成器,分辨率高达1280×2048。由于在这种情况下我们只需要训练时间对齐层,因此可以使用相对较小的带字幕视频训练集。
贡献
- 提出高效视频生成方法:基于LDMs设计出训练高分辨率、长期一致视频生成模型的高效方式。核心在于借助预训练的图像扩散模型(DMs),插入能让图像在时间上保持一致的时间层,进而将其转化为视频生成器(相关原理参考图2和图3)。
- 优化超分辨率DMs:对常见的超分辨率DMs进行时间微调,提升其在视频处理中的性能表现。
- 驾驶场景视频合成突破:在真实驾驶场景视频的高分辨率合成领域达到当前最优水平,能够生成长达数分钟的视频,满足实际应用中对长时间、高质量驾驶场景模拟等的需求。
- 拓展文本到视频应用:成功将公开的稳定扩散文本到图像LDM改造为功能强大、表现力丰富的文本到视频LDM,极大拓展了模型的应用范围,为文本驱动的视频创作提供有力工具。
- 时间层的通用性验证:验证了学习到的时间层具有通用性,可以和不同的图像模型检查点(如DreamBooth)结合,为个性化视频生成等更多创新应用提供了可能 。
2. 背景
扩散模型(DMs)
扩散模型(DMs)的核心原理,建模与训练方法是DMs通过迭代去噪学习对数据分布 p d a t a ( x ) p_{data}(x) pdata(x)建模,使用去噪分数匹配法训练。过程如下:
- 扩散过程:给定样本 x ∼ p d a t a x \sim p_{data} x∼pdata,构建扩散后的输入 x τ = α τ x + σ τ ϵ x_{\tau}=\alpha_{\tau}x+\sigma_{\tau}\epsilon xτ=ατx+στϵ,其中 ϵ ∼ N ( 0 , I ) \epsilon \sim N(0, I) ϵ∼N(0,I); α τ \alpha_{\tau} ατ和 σ τ \sigma_{\tau} στ定义了一个噪声调度,通过扩散时间 T T T进行参数化,使得对数信噪比 λ τ = log ( α τ 2 / σ τ 2 ) \lambda_{\tau}=\log(\alpha_{\tau}^{2}/\sigma_{\tau}^{2}) λτ=log(ατ2/στ2)单调递减。
- 去噪器优化:去噪器模型 f θ f_{\theta} fθ以扩散后的 x τ x_{\tau} xτ为输入,通过最小化 E x ∼ p d a t a , τ ∼ p τ , ϵ ∼ N ( 0 , I ) [ ∥ y − f θ ( x τ ; c , τ ) ∥ 2 2 ] \mathbb{E}_{x \sim p_{data}, \tau \sim p_{\tau}, \epsilon \sim \mathcal{N}(0, I)}[\left\| y - f_{\theta}(x_{\tau}; c, \tau) \right\|_{2}^{2}] Ex∼pdata,τ∼pτ,ϵ∼N(0,I)[∥y−fθ(xτ;c,τ)∥22]进行优化,其中 c c c是可选的条件信息,例如文本提示,目标向量 y y y要么是随机噪声 ϵ \epsilon ϵ,要么是 v = α τ ϵ − σ τ x v = \alpha_{\tau}\epsilon - \sigma_{\tau}x v=ατϵ−στx。后一种目标(通常称为 v v v预测)是在渐进蒸馏的背景下引入的[73],在经验上通常能使模型更快收敛(在此,我们同时使用这两种目标)。此外, p τ p_{\tau} pτ是扩散时间 τ \tau τ上的均匀分布。 v = α τ ϵ − σ τ x v=\alpha_{\tau}\epsilon - \sigma_{\tau}x v=ατϵ−στx,研究中同时使用这两种目标, p τ p_{\tau} pτ是扩散时间 τ \tau τ上的均匀分布。
扩散模型的核心其实是前向扩散加入噪声以及反向扩散学习/预测前向扩散加入的噪声,并且去除噪声,进而生成的过程,扩散过程可以在连续时间框架中通过随机微分方程来描述【论文:Score-based generative modeling through stochastic differential equations】(也可参考图 2 和图 3 中的框架),但在实践中可以使用固定的离散化方法(DDPM)。
DDPM参考:Diffusion Model 原理
TODO:Score-based generative modeling through stochastic differential equations
最大扩散时间通常选择为使得输入数据完全被扰动为高斯随机噪声,并且可以从这种高斯噪声初始化一个迭代生成去噪过程,该过程使用学习到的去噪器 f θ f_{\theta} fθ来合成新的数据。在此,作者使用 p τ ∼ U { 0 , 1000 } p_{\tau} \sim U\{0, 1000\} pτ∼U{0,1000},并依赖于方差保持噪声调度,对于该调度, σ τ 2 = 1 − α τ 2 \sigma_{\tau}^{2}=1-\alpha_{\tau}^{2} στ2=1−ατ2。
在本文的研究中,作者设定 p τ ∼ U { 0 , 1000 } p_{\tau} \sim U\{0, 1000\} pτ∼U{0,1000},这意味着扩散时间 τ \tau τ是在0到1000这个区间内均匀分布的随机变量。这种均匀分布决定了在扩散过程中,不同扩散时间被选取的概率是相等的。
同时,作者采用了方差保持噪声调度策略。在这种策略下,有一个重要的公式 σ τ 2 = 1 − α τ 2 \sigma_{\tau}^{2}=1-\alpha_{\tau}^{2} στ2=1−ατ2。这个公式定义了噪声强度随时间的变化关系, σ τ \sigma_{\tau} στ代表在扩散时间为 τ \tau τ时添加的噪声标准差,它决定了噪声的强度,而 α τ \alpha_{\tau} ατ则与扩散过程的其他特性相关。随着 τ \tau τ在0到1000之间取值变化, α τ \alpha_{\tau} ατ和 σ τ \sigma_{\tau} στ也会相应改变,从而调整噪声强度。例如,在扩散初期, τ \tau τ可能取较大值, σ τ \sigma_{\tau} στ较大,添加的噪声较多,数据被扰动得更剧烈;随着扩散进行, τ \tau τ逐渐减小, σ τ \sigma_{\tau} στ变小,噪声强度降低,去噪器 f θ f_{\theta} fθ逐步将数据恢复成有意义的内容(详细信息见附录F和H)。
潜在扩散模型(LDMs)
上节介绍的扩散模型实际上是在像素空间进行的。而潜在扩散模型(LDMs)在计算和内存效率上优于像素空间扩散模型(DMs),简要介绍如下:
- 提升效率的原理:先训练压缩模型,把输入图像转换到复杂度较低的空间低维潜在空间,在此空间可高保真重建原始数据,以此提升计算和内存效率。
- 实现方式:实际通过正则化自动编码器(在传统自动编码器基础上引入正则化项,抑制模型过拟合,提升泛化能力)实现,该编码器包含编码器模块 ϵ \epsilon ϵ 和解码器 D D D ,通过 x ^ = D ( ϵ ( x ) ) ≈ x \hat{x}=D(\epsilon(x)) \approx x x^=D(ϵ(x))≈x重建输入图像(见图3)。
- 确保重建质量的方法:在自动编码器训练时添加对抗目标,利用基于补丁的判别器来确保逼真的重建效果。
- 潜在空间DM的优势:在压缩的潜在空间训练DM,公式(1)中的 x x x用潜在表示 z = ϵ ( x ) z = \epsilon(x) z=ϵ(x)替代。相比于像素空间DMs,潜在空间DM的参数数量和内存消耗通常更少。
为了确保逼真的重建,可以在自动编码器训练中添加对抗目标[65],这可以使用基于补丁的判别器来实现[35]。然后,可以在压缩的潜在空间中训练一个DM,并且公式(1)中的 x x x被其潜在表示 z = ϵ ( x ) z = \epsilon(x) z=ϵ(x)所取代。与具有相似性能的相应像素空间DMs相比,这种潜在空间DM在参数数量和内存消耗方面通常较小。
SD系列模型就是在潜在空间进行扩散的,详情可以参考历史文章:SD系列专栏
3. 潜在视频扩散模型
本部分介绍对预训练的图像LDMs(以及DM上采样器)进行视频微调,以实现高分辨率视频合成。
作者假设获取到一个视频数据集 p d a t a p_{data} pdata,使得 x ∈ R T × 3 × H ˉ × W ˉ x \in \mathbb{R}^{T×3×\bar{H}×\bar{W}} x∈RT×3×Hˉ×Wˉ, x ∼ p d a t a x \sim p_{data} x∼pdata是一个包含 T T T个RGB帧的序列,帧的高度和宽度分别为 H ~ \tilde{H} H~和 W ˉ \bar{W} Wˉ。
3.1 将潜在图像转变为视频生成器
转变思路如下:
- 高效训练思路:高效训练视频生成模型的关键在于重用预训练且固定的图像生成模型(由参数 θ \theta θ参数化的LDM)。
- 模型现有结构:构成图像LDM并处理像素维度输入的神经网络层为空间层 l θ i l_{\theta}^{i} lθi( i i i是层索引)。
- 现有模型局限:虽能高质量合成单帧,但直接用于渲染 T T T个连续帧视频会失败,原因是模型无时间感知能力。
- 改进措施:引入额外时间神经网络层 l ϕ i l_{\phi}^{i} lϕi,与空间层 l θ i l_{\theta}^{i} lθi交错排列,学习以时间一致的方式对齐单个帧。
- 最终模型构成:额外时间层 { l ϕ i } i = 1 L \{l_{\phi}^{i}\}_{i = 1}^{L} {lϕi}i=1L定义了视频感知时间骨干网络,完整模型 f θ , ϕ f_{\theta, \phi} fθ,ϕ由空间层和时间层组合而成,如图4。

图4. 左:我们通过插入时间层,将预训练的潜在扩散模型(LDM)转变为视频生成器,这些时间层能够学习将帧对齐为在时间上连贯一致的序列。在优化过程中,图像骨干网络 θ \theta θ保持固定,仅训练时间层 l ϕ x l_{\phi}^{x} lϕx的参数 ϕ \phi ϕ,参见公式(2)。右:在训练期间,基础模型 θ \theta θ将长度为 T T T的输入序列解释为一批图像。对于时间层 l ϕ i l_{\phi}^{i} lϕi,这些批次的图像被重新整形为视频格式。它们的输出 z ′ z' z′会与空间层的输出 z z z相结合,结合时使用一个可学习的融合参数 α \alpha α。在推理过程中,跳过时间层(即 α ϕ i = 1 \alpha_{\phi}^{i}=1 αϕi=1)可得到原始的图像模型。为便于说明,图中仅展示了一个U型网络模块。 B B B表示批量大小, T T T表示序列长度, c c c表示输入通道数, H H H和 W W W表示输入的空间维度。当训练预测模型时(第3.2节), c s cs cs是可选的上下文帧条件。
我们从按帧编码的输入视频 ϵ ( x ) = z ∈ R T × C × H × W \epsilon(x)=z \in \mathbb{R}^{T×C×H×W} ϵ(x)=z∈RT×C×H×W开始,其中 C C C是潜在通道的数量, H H H和 W W W是潜在空间的空间维度。空间层将视频视为一批独立的图像(通过将时间轴转换为批量维度来实现),对于每个时间混合层 l ϕ i l_{\phi}^{i} lϕi,我们按如下方式将其重新调整为视频维度(使用 einops [64] 表示法):
z ′ ← rearrange ( z , ( b t ) c h w → b c t h w ) z' \leftarrow \text{rearrange}(z, (b \ t) \ c \ h \ w \to b \ c \ t \ h \ w) z′←rearrange(z,(b t) c h w→b c t h w)
z ′ ← l ϕ i ( z ′ , c ) z' \leftarrow l_{\phi}^{i}(z', c) z′←lϕi(z′,c)
z ′ ← rearrange ( z ′ , b c t h w → ( b t ) c h w ) z' \leftarrow \text{rearrange}(z', b \ c \ t \ h \ w \to (b \ t) \ c \ h \ w) z′←rearrange(z′,b c t h w→(b t) c h w)
这里为了表述清晰,引入了批量维度 b b b。
- 空间层在批量维度 b b b中独立处理所有 B ⋅ T B \cdot T B⋅T个已编码的视频帧;
- 时间层 l ϕ i ( z ′ , c ) l_{\phi}^{i}(z', c) lϕi(z′,c)则在新的时间维度 t t t中处理整个视频。
- c c c是(可选的)条件信息,比如文本提示。
- 在每个时间层之后,输出 z ′ z' z′会与 z z z按照 α ϕ i z + ( 1 − α ϕ i ) z ′ \alpha_{\phi}^{i}z + (1 - \alpha_{\phi}^{i})z' αϕiz+(1−αϕi)z′的方式进行组合; α ϕ i ∈ [ 0 , 1 ] \alpha_{\phi}^{i} \in [0, 1] αϕi∈[0,1] 表示一个(可学习的)参数(另见附录D)。
在实际应用中,作者实现了两种不同类型的时间混合层(见图4):
- 时间注意力机制;
- 基于三维卷积的残差块。我们使用正弦嵌入[28, 89] 为模型提供时间位置编码。
使用与基础图像模型相同的噪声调度来训练视频感知时间主干网络。重要的是,固定空间层 l θ i l_{\theta}^{i} lθi,仅通过以下公式优化时间层 l ϕ i l_{\phi}^{i} lϕi:
a r g m i n ϕ E x ∼ p d a t a , τ ∼ p τ , ϵ ∼ N ( 0 , I ) [ ∥ y − f θ , ϕ ( z τ ; c , τ ) ∥ 2 2 ] (2) \underset{\phi}{arg min } \mathbb{E}_{x \sim p_{data}, \tau \sim p_{\tau}, \epsilon \sim \mathcal{N}(0, I)}[\left\| y - f_{\theta, \phi}(z_{\tau}; c, \tau) \right\|_{2}^{2}] \tag{2} ϕargminEx∼pdata,τ∼pτ,ϵ∼N(0,I)[∥y−fθ,ϕ(zτ;c,τ)∥22](2)
其中 z T z_{T} zT表示扩散后的编码 z = ϵ ( x ) z = \epsilon(x) z=ϵ(x)。通过这种方式,只需跳过时间块(例如,为每一层设置 α ϕ i = 1 \alpha_{\phi}^{i}=1 αϕi=1),就可以保留原生的图像生成能力。这种策略的一个关键优势是,可以使用巨大的图像数据集来预训练空间层,而通常不太容易获得的视频数据则可以用于专注训练时间层。
3.1.1 时间自动编码器微调
基于预训练图像LDMs构建的视频模型,虽然提高了效率,但LDM的自动编码器仅在图像上进行了训练,在对时间连贯的图像序列进行编码和解码时会导致闪烁伪影。
为了解决这个问题,作者为自动编码器的解码器引入了额外的时间层,并且使用由三维卷积构建的(基于图像块的)时间判别器,在视频数据上对这些时间层进行微调,见图3。需要注意的是,编码器与在图像训练时保持不变,这样一来,在潜在空间中对已编码视频帧进行操作的图像扩散模型就可以重复使用。这一步对于取得良好结果至关重要。
3.2 长视频生成的预测模型
局限性
尽管第3.1节中描述的方法在生成短视频序列方面效率很高,但在合成非常长的视频时却存在局限性。
解决方案
因此,作者还会在给定一定数量(最初的) S S S个上下文帧的情况下,将模型训练为预测模型,通过引入一个时间二进制掩码 m S m_{S} mS来实现这个目标,该掩码会遮蔽模型需要预测的 T − S T - S T−S帧,其中 T T T是如第3.1节中所述的总序列长度。我们将这个掩码和掩码后的编码视频帧输入模型进行条件设定。
具体实现
这些帧通过潜在扩散模型(LDM)的图像编码器 ϵ \epsilon ϵ进行编码,然后与掩码相乘,接着在经过一个可学习的下采样操作处理后,(按通道与掩码进行连接)被输入到时间层 l ϕ i l_{\phi}^{i} lϕi中,见图4。设 c S = ( m S ∘ z , m S ) c_{S}=(m_{S} \circ z, m_{S}) cS=(mS∘z,mS)表示掩码和经过掩码处理(编码后)的图像在空间上连接后的条件信息。那么,公式(2)中的目标函数可表示为:
E x ∼ p d a t a , m S ∼ p S , τ ∼ p τ , ϵ [ ∥ y − f θ , ϕ ( z τ ; c S , c , τ ) ∥ 2 2 ] , ( 3 ) \mathbb{E}_{x \sim p_{data }, m_{S} \sim p_{S}, \tau \sim p_{\tau}, \epsilon}\left[\left\| y-f_{\theta, \phi}\left(z_{\tau} ; c_{S}, c, \tau\right)\right\| _{2}^{2}\right], (3) Ex∼pdata,mS∼pS,τ∼pτ,ϵ[∥y−fθ,ϕ(zτ;cS,c,τ)∥22],(3)
其中 p S p_{S} pS表示(分类的)掩码采样分布。在实际应用中,我们训练的预测模型会基于0个、1个或2个上下文帧来设置条件,这样就可以实现如下所述的无分类器引导。
推理过程
在推理时,为了生成长视频,我们可以迭代地应用采样过程,将最新的预测结果作为新的上下文。过程如下:
- 最初的第一个序列是通过基础图像模型合成单个上下文帧,然后基于该帧生成下一个序列。
- 之后,以两个上下文帧作为条件来对运动进行编码(附录中有详细信息)。
- 为了稳定这个过程,作者发现使用无分类器扩散引导(Classifier-free guidance)是有益的,在采样过程中,通过下式引导模型:
f θ , ϕ ′ ( z τ ; c S ) = f θ , ϕ ( z τ ) + s ⋅ ( f θ , ϕ ( z τ ; c S ) − f θ , ϕ ( z τ ) ) f_{\theta, \phi}'(z_{\tau}; c_{S}) = f_{\theta, \phi}(z_{\tau}) + s \cdot (f_{\theta, \phi}(z_{\tau}; c_{S}) - f_{\theta, \phi}(z_{\tau})) fθ,ϕ′(zτ;cS)=fθ,ϕ(zτ)+s⋅(fθ,ϕ(zτ;cS)−fθ,ϕ(zτ))
其中:- s ≥ 1 s \geq 1 s≥1表示引导尺度,为了可读性,这里省略了对 τ \tau τ和其他信息 c c c的显式条件设定。作者将这种引导方式称为上下文引导。
- 最终的结果 f θ , ϕ ′ ( z τ ; c S ) f_{\theta, \phi}'(z_{\tau}; c_{S}) fθ,ϕ′(zτ;cS) :将原始的无条件预测结果 f θ , ϕ ( z τ ) f_{\theta, \phi}(z_{\tau}) fθ,ϕ(zτ) 与经过条件调整的部分 s ⋅ ( f θ , ϕ ( z τ ; c S ) − f θ , ϕ ( z τ ) ) s \cdot (f_{\theta, \phi}(z_{\tau}; c_{S}) - f_{\theta, \phi}(z_{\tau})) s⋅(fθ,ϕ(zτ;cS)−fθ,ϕ(zτ))
相加。这意味着最终的结果是在原始预测结果的基础上,根据条件信息 c S c_{S} cS 的影响进行调整,调整的程度由引导尺度 s s s 控制。
这里其实和Transformer的自回归生成相似。上文中,帧和序列不一样,序列是指一系列按时间顺序排列的帧的集合,在第二步中的两个上下文帧的来源于前面已经得到的序列。
3.3 高帧率的时间插值
高分辨率视频需兼具高空间分辨率和高时间分辨率(高帧率)。为此,将其合成过程分为两部分:
- 第3.1和3.2节的过程可生成语义变化大的关键帧,但受内存限制,帧率较低。
- 引入一个额外的模型,其任务是在给定的关键帧之间进行插值。
为了实现这第二点,作者使用第 3.2 节中介绍的掩码 - 条件机制。然而,与预测任务不同的是,需要对插值的帧进行掩码处理 —— 除此之外,该机制保持不变,即图像模型被改进为视频插值模型。
在作者的的实验中,通过在两个给定的关键帧之间预测三帧,从而训练一个将帧率从 T 提升到 4T 的插值模型。为了实现更高的帧率,作者同时在 T 到 4T 和 4T 到 16T 的帧率范围内(使用不同帧率的视频)训练模型,并通过二元条件指定。
作者对预测和插值模型的训练方法受到了近期一些视频扩散模型的启发,这些模型也使用了类似的掩码技术(另见附录C)。
3.4 超分辨率模型的时间微调
为了将其分辨率提升到百万像素级别。作者从级联DMs(SDXL、CogView3等都是级联DMs模型)中获得灵感,使用一个DM将Video LDM的输出再放大4倍。主要做法如下:
- 在驾驶视频合成实验中,使用像素空间DM并将分辨率提升到512×1024;
- 对于文本到视频模型,我们使用LDM上采样器并将分辨率提升到1280×2048。
作者使用噪声增强和噪声水平条件,并通过下式训练超分辨率(SR) 模型 g θ , ϕ g_{\theta, \phi} gθ,ϕ(在图像或潜在空间上):
E x ∼ p d a t a , ( τ , τ γ ) ∼ p τ , ϵ ∼ N ( 0 , I ) [ ∥ y − g θ , ϕ ( x τ ; c τ γ , τ γ , τ ) ∥ 2 2 ] (5) \mathbb{E}_{x \sim p_{data}, (\tau, \tau_{\gamma}) \sim p_{\tau}, \epsilon \sim \mathcal{N}(0, I)}[\left\| y - g_{\theta, \phi}(x_{\tau}; c_{\tau_{\gamma}}, \tau_{\gamma}, \tau) \right\|_{2}^{2}] \tag{5} Ex∼pdata,(τ,τγ)∼pτ,ϵ∼N(0,I)[ y−gθ,ϕ(xτ;cτγ,τγ,τ) 22](5)
其中 c τ γ = α τ γ x + σ τ γ ϵ c_{\tau_{\gamma}} = \alpha_{\tau_{\gamma}}x + \sigma_{\tau_{\gamma}}\epsilon cτγ=ατγx+στγϵ, ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I),表示通过连接提供给模型的噪声低分辨率图像, τ γ \tau_{\gamma} τγ是根据噪声调度 α τ \alpha_{\tau} ατ、 σ τ \sigma_{\tau} στ添加到低分辨率图像上的噪声量。
- 噪声增强是指在训练过程中,人为地向输入数据(通常是低分辨率图像)添加噪声的过程。
- 噪声水平条件是指将噪声的水平(强度或数量)作为模型的一个输入条件。在公式中, τ \tau τ 和 τ γ \tau_{\gamma} τγ 就是噪声水平条件,它们是从分布 p τ p_{\tau} pτ 中采样得到的。
- 在上述超分辨率模型的训练公式中,噪声增强和噪声水平条件是相互关联的。首先通过噪声增强将噪声添加到低分辨率图像 x x x 中得到 x τ x_{\tau} xτ,同时使用噪声水平条件中的参数(如 α τ γ \alpha_{\tau_{\gamma}} ατγ 和 σ τ γ \sigma_{\tau_{\gamma}} στγ)计算条件变量 c τ γ c_{\tau_{\gamma}} cτγ,将噪声添加到原始图像上得到一个新的条件输入。这样,超分辨率模型 g θ , ϕ g_{\theta, \phi} gθ,ϕ会根据输入的噪声水平条件,学习在不同噪声环境下如何将低分辨率图像转换为高分辨率图像。
此外还有一个新的问题:独立对视频帧进行上采样会导致时间一致性较差。
- 解决方案:
- 使 SR 模型具有视频感知能力。
- 遵循第3.1节机制,利用空间层 l θ i l_{\theta}^{i} lθi 和时间层 l ϕ i l_{\phi}^{i} lϕi 对缩放器进行视频微调。
- 以长度为 T T T 的低分辨率序列为条件,逐帧连接低分辨率视频图像。
- 仅在图像块上高效训练缩放器,后续通过卷积应用模型。
总结
作者认为LDM与上采样器DM的结合对于高效的高分辨率视频合成是理想的。图5展示了第3.1节至第3.4节所有组件的模型:

图5. Video LDM架构。我们首先生成稀疏关键帧。然后使用相同的插值模型分两步进行时间插值以实现高帧率。这些操作都基于共享相同图像骨干网络的潜在扩散模型(LDMs)。最后,将潜在视频解码到像素空间,并可选地应用视频上采样器扩散模型。
- Video LDM的LDM组件:
- 利用压缩潜在空间进行视频建模。
- 优势:可使用大批次大小,能联合编码更多视频帧,利于长期视频建模,不会有过高的内存需求,因为所有视频预测和插值都在潜在空间中进行。
- 上采样器:
- 训练方式:高效的图像块方式。
- 效果:节省计算资源,降低内存消耗,因低分辨率条件无需捕捉长期时间相关性,无需预测和插值框架。
相关工作的讨论见附录C。
4. 实验
这部分请参考原文,此处只做简要介绍
数据集
- 用于驾驶场景视频生成和文本到视频任务,使用RDS数据集(683,060个8秒、512×1024、30fps视频,含昼夜标签、拥挤度注释、部分含边界框)、WebVid-10M数据集(1070万视频-字幕对,52,000视频小时,调整为320×512),以及附录I.2的山地自行车数据集。
评估指标
- 采用逐帧FID、FVD,因FVD不可靠,作者还进行了人工评估;文本到视频实验还评估CLIPSIM和IS(见附录G)。
模型架构和采样
- 图像LDM基于[65],使用卷积编码器/解码器,潜在空间DM架构基于[10]的U-Net;像素空间上采样器DM使用相同图像DM骨干网络,实验用DDIM采样,更多信息在附录。
更多架构、训练、评估、采样和数据集的详细信息见附录。
4.1 高分辨率驾驶视频合成
- 训练过程:
- 在RDS数据上训练Video LDM管道及4倍像素空间上采样器,基于昼夜和拥挤度条件,训练时随机丢弃标签实现不同合成方式。
- 先训练图像骨干LDM的空间层,再训练时间层。
- 性能对比:
- 以LVG为基线,Video LDM在128×256未使用上采样器时性能更优,添加条件可降FVD。
- 人工评估显示Video LDM样本在真实感方面更优,条件模型样本好于无条件样本。
- 上采样器比较:
- 视频微调上采样器与独立逐帧图像上采样对比,时间对齐对上采样器性能重要,独立上采样致FVD下降但FID稳定。
- 实验结果展示:
- 展示结合Video LDM和上采样器的条件样本,能生成长达数分钟、时间连贯的高分辨率驾驶视频,已验证5分钟结果在附录和补充视频。
4.1.1 消融研究
重点提炼:
- 在RDS数据集上对比较小的Video LDM与各种基线,结果在表1(右)及附录G。
- 不同模型设置的性能比较:
- 对预训练像素空间图像扩散模型应用时间微调策略,性能不如原Video LDM。
- 端到端LDM在RDS视频上从头学参(无图像预训练),FID和FVD大幅下降。
- 引入3D卷积时间层可输入上下文帧,性能优于仅用注意力机制的时间模型(同空间层和可训练参数)。
- 应用上下文引导可降FVD但增FID。
此外还做了如下操作:
- 分析对包含LDM框架[65]的压缩模型解码器进行视频微调的效果。
- 在RDS数据集上应用微调策略,对比重建视频/图像帧的FVD/FID分数。
- 结果表明视频微调使FVD/FID分数有数量级的提升(表3)。
4.1.2 驾驶场景模拟
省略,参考原文
4.2 使用稳定扩散的文本到视频
Video LDM方法:
- 无需先训练自己的图像LDM骨干网络,可利用现有图像LDM转变成视频生成器。
- 将稳定扩散转变为文本到视频生成器,使用WebVid-10M数据集训练时间对齐版本,对稳定扩散的空间层微调,插入时间对齐层和添加文本条件。
- 对稳定扩散潜在上采样器进行视频微调,支持4倍上采样,生成1280×2048分辨率视频,生成的视频含113帧,可渲染为不同帧率和时长的片段。
- 能生成超越训练数据的具有表现力和艺术性的视频,结合了图像模型风格与视频的运动和时间一致性。
评估结果:
- 在UCF-101和MSR-VTT评估零样本文本到视频生成,除Make-A-Video外优势显著,在UCF-101的IS指标上超Make-A-Video,Make-A-Video使用更多数据。
4.2.1 使用DreamBooth的个性化文本到视频
时间层转移测试:
- 探究Video LDM中图像LDM骨干网络上训练的时间层能否转移到其他模型检查点。
- 使用DreamBooth对稳定扩散的空间骨干网络(SD 1.4)在少量特定对象图像上微调,绑定身份与罕见文本标记。
- 将经过视频调整的稳定扩散中的时间层插入原始稳定扩散模型的新DreamBooth版本,用绑定标记生成视频,可生成个性化连贯视频并能捕捉训练图像身份,验证了时间层可推广到其他图像LDM,首次实现个性化文本到视频生成,更多结果在附录I。
5. 结论
下面是本文的核心:
- 模型提出:Video Latent Diffusion Models(Video LDMs)用于高效高分辨率视频生成。
- 关键设计:基于预训练图像扩散模型,并通过时间对齐层进行时间视频微调转化为视频生成器。
- 计算效率保证:利用LDMs,可与超分辨率DM结合并进行时间对齐。
- 应用成果:
- 合成长达数分钟高分辨率且时间连贯的驾驶场景视频。
- 将稳定扩散文本到图像LDM转变为文本到视频LDM并实现个性化文本到视频生成。
- 时间层特性:学习到的时间层可转移到不同模型检查点,利用这一点进行个性化文本到视频生成。
相关文章:
AIGC视频扩散模型新星:Video 版本的SD模型
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍慕尼黑大学携手 NVIDIA 等共同推出视频生成模型 Video LDMs。NVIDIA 在 AI 领域的卓越成就家喻户晓,而慕尼黑大学同样不容小觑,…...

HarmonyOS:通过(SQLite)关系型数据库实现数据持久化
一、场景介绍 关系型数据库基于SQLite组件,适用于存储包含复杂关系数据的场景,比如一个班级的学生信息,需要包括姓名、学号、各科成绩等,又或者公司的雇员信息,需要包括姓名、工号、职位等,由于数据之间有较…...

10. SpringCloud Alibaba Sentinel 规则持久化部署详细剖析
10. SpringCloud Alibaba Sentinel 规则持久化部署详细剖析 文章目录 10. SpringCloud Alibaba Sentinel 规则持久化部署详细剖析1. 规则持久化1.1 Nacos Server 配置中心-规则持久化实例 2. 最后: 1. 规则持久化 规则没有持久化的问题 如果 sentinel 流控规则没有…...

STM32更新程序OTA
STM32的OTA(Over-The-Air)更新程序是一种通过无线通信方式,为设备分发新软件、配置甚至更新加密密钥的技术。以下是关于STM32 OTA更新程序的详细介绍: 一、OTA升级流程 STM32的OTA升级流程通常包括以下几个关键步骤:…...
|稀土掘金-147.寻找独一无二的糖葫芦串、119.游戏队友搜索)
MarsCode青训营打卡Day10(2025年1月23日)|稀土掘金-147.寻找独一无二的糖葫芦串、119.游戏队友搜索
资源引用: 147.寻找独一无二的糖葫芦串 119.游戏队友搜索 今日小记: 回乡聚会陪家人,休息一天~ 稀土掘金-147.寻找独一无二的糖葫芦串(147.寻找独一无二的糖葫芦串) 题目分析: 给定n个长度为m的字符串表…...
 : 安装组件出错解决)
vue(33) : 安装组件出错解决
1. request to https://registry.npm.taobao.org/semver/download/semver-6.1.1.tgz?cache0&other_urlshttps%3A%2F%2Fregistry.npm.taobao.org%2Fsemver%2Fdownload%2Fsemver-6.1.1.tgz failed, reason: certificate has expired 这个错误提示表明你在尝试从https://reg…...

ChatGPT结合Excel辅助学术数据分析详细步骤分享!
目录 一.Excel在学术论文中的作用✔ 二.Excel的提示词✔ 三. 编写 Excel 命令 四. 编写宏 五. 执行复杂的任务 六. 将 ChatGPT 变成有用的 Excel 助手 一.Excel在学术论文中的作用✔ Excel作为一种广泛使用的电子表格软件,在学术论文中可以发挥多种重要作用&a…...
stm32f103 单片机(一)第一个工程
先看一个简单的 系统上已经安装好了keil5 与ARM包,也下载好了STM32固件库 新建一个工程,添加三个组 加入如下文件 在options 里作如下配置 准备在main.c 中写下第一个实验,点亮一个小灯。 像51单片机一样直接对引脚赋值是行不通的 在…...
云计算和服务器
一、云计算概述 ICT是世界电信协会在2001年的全球性会议上提出的综合性概念,ICT分为IT和CT,IT(information technology)信息技术,负责对数据生命周期的管理;CT(communication technology),负责数据的传输管理。 CT技术…...
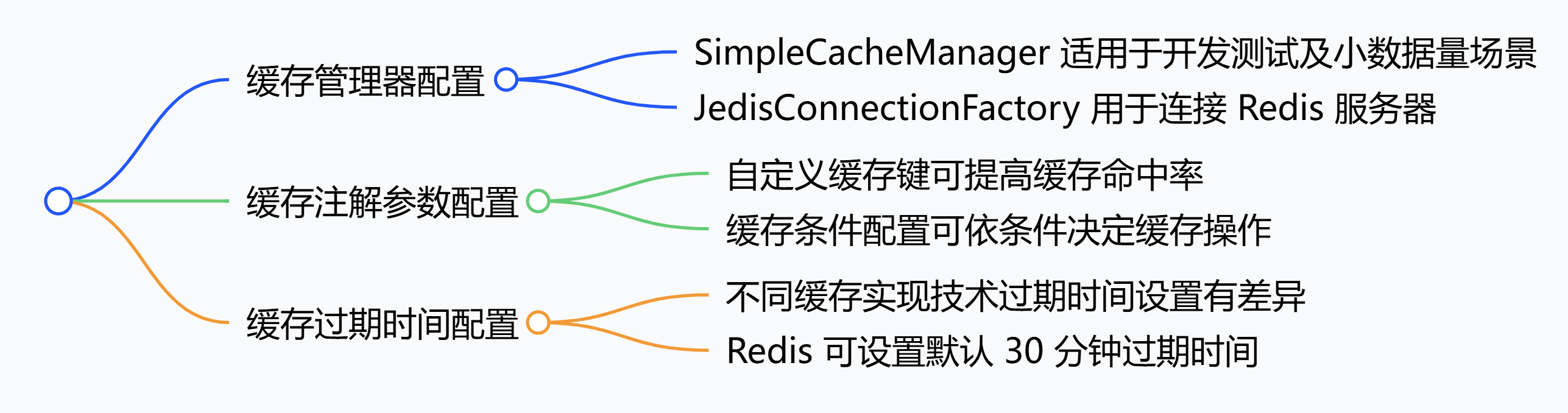
Spring 框架:配置缓存管理器、注解参数与过期时间
在 Spring 框架中,可通过多种方式配置缓存具体行为,常见配置方法如下。 1. 缓存管理器(CacheManager)配置 基于内存的缓存管理器配置(以SimpleCacheManager为例) SimpleCacheManager 是 Spring 提供的简单…...
Linux系统 C/C++编程基础——基于Qt的图形用户界面编程
ℹ️大家好,我是练小杰,今天周四了,距离除夕只有4天了,各位今年卫生都搞完了吗!😆 本文是接着昨天Linux 系统C/C编程的知识继续讲,基于Qt的图形用户界面编程概念及其命令,后续会不断…...

并发编程 - 线程同步(一)
经过前面对线程的尝试使用,我们对线程的了解又进一步加深了。今天我们继续来深入学习线程的新知识 —— 线程同步。 01、什么是线程同步 线程同步是指在多线程环境下,确保多个线程在同时使用共享资源时不会发生冲突或数据不一致问题的技术,保…...

PyTorch入门 - 为什么选择PyTorch?
PyTorch入门 - 为什么选择PyTorch? Entry to PyTorch - Why PyTorch? by JacksonML $ pip install pytorch安装完毕后,可以使用以下命令,导入第三方库。 $ import pytorch...
leetcode刷题记录(八十六)——84. 柱状图中最大的矩形
(一)问题描述 84. 柱状图中最大的矩形 - 力扣(LeetCode)84. 柱状图中最大的矩形 - 给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。求在该柱状图中,能够勾…...

Android GLSurfaceView 覆盖其它控件问题 (RK平台)
平台 涉及主控: RK3566 Android: 11/13 问题 在使用GLSurfaceView播放视频的过程中, 增加了一个播放控制面板, 覆盖在视频上方. 默认隐藏setVisibility(View.INVISIBLE);点击屏幕再显示出来. 然而, 在RK3566上这个简单的功能却无法正常工作. 通过缩小视频窗口可以看到, 实际…...
开源鸿蒙开发者社区记录
lava鸿蒙社区可提问 Laval社区 开源鸿蒙项目 OpenHarmony 开源鸿蒙开发者论坛 OpenHarmony 开源鸿蒙开发者论坛...
【Linux网络编程】传输层协议
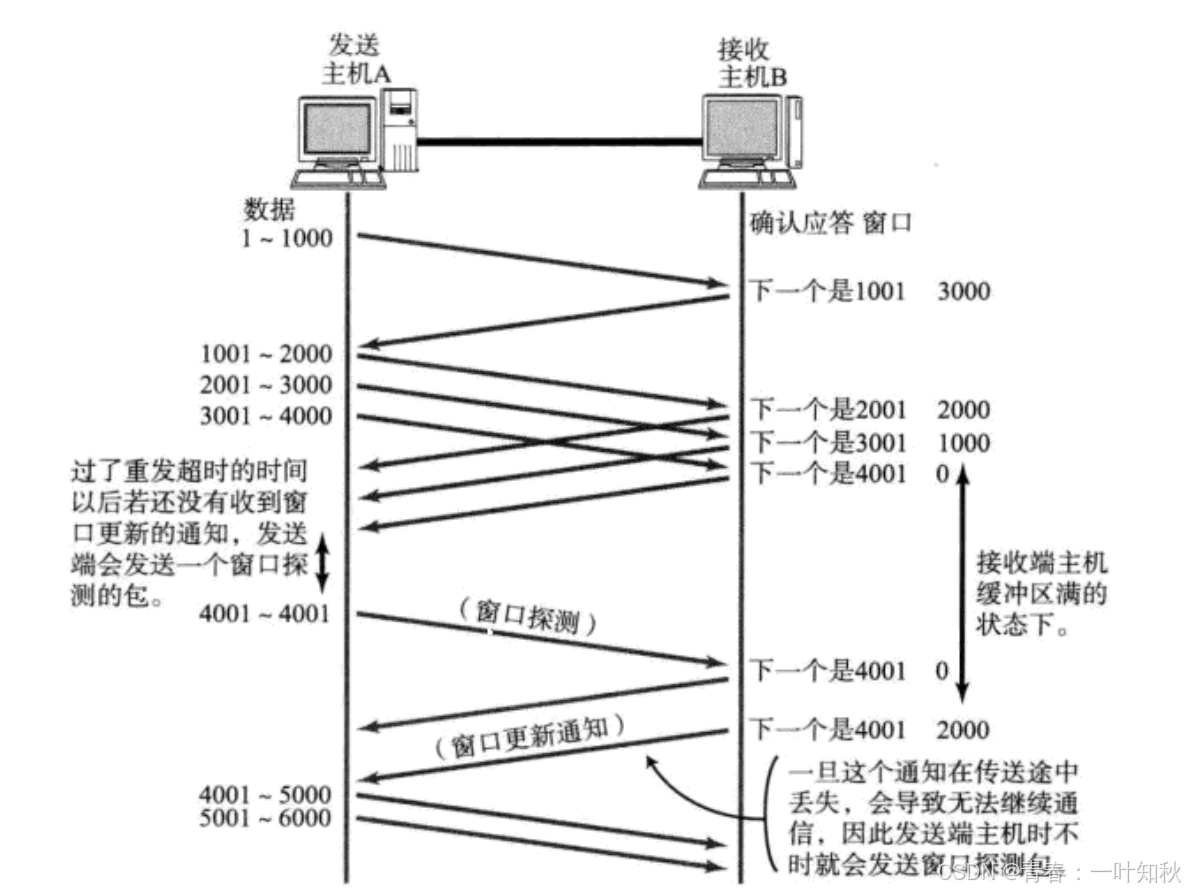
目录 一,传输层的介绍 二,UDP协议 2-1,UDP的特点 2-2,UDP协议端格式 三,TCP协议 3-1,TCP报文格式 3-2,TCP三次握手 3-3,TCP四次挥手 3-4,滑动窗口 3-5…...

10个非常基础的 Javascript 问题
Javascript是一种用于Web开发的编程语言。JavaScript在网络的客户端上运行。 根据MDN,JavaScript(通常缩写为JS)是一种轻量级的,解释性的,面向对象的语言,具有一流的功能,并且最著名的是Web页面…...

Mysql索引(学习自用)
目录 一、索引概述 优缺点 二、索引结构 1、索引数据结构 2、索引支持结构 3、B树 4、B树 5、hash索引 6、为啥采用B树索引 三、索引分类 四、索引语法 五、索引性能分析 5.1查看执行频率 5.2慢查询日志 5.3profiling 5.4explain 六、索引使用规则 6.1验证索…...

eniops库中reduce函数使用方法
reduce 是 eniops 中的一个常用函数,用于对张量进行降维操作。它允许你通过指定维度名称和操作类型(如求和、均值等)来简化张量的形状。 import eniops import torch# 创建一个示例张量 x torch.randn(2, 3, 4)# 使用 reduce 进行降维操作 …...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

Matlab,plot绘图如何添加边框
matlab生成的图——编辑(E)——坐标区属性(A)——框样式——Box,勾选效果:...

天文时序数据分析:机器学习评估、半监督学习与无监督方法实战
1. 项目概述:当机器学习遇见星空 处理海量的天文时序数据,比如来自Kepler、TESS这些“巡天巨眼”的光变曲线,早已不是靠人眼一张张图去翻的时代了。数据量太大,噪声复杂,信号微弱,传统方法常常力不从心。这…...