重构(4)
(一)添加解释性变量,使得代码更容易理解,更容易调试,也可以方便功能复用
解释性的变量
总价格为商品总价(单价*数量)-折扣(超过100个以上的打9折)+邮费(原价的10%,50元封顶)double getTotalPrice()
{return price * quantity - max(0, quantity - 100) * price - min(quantity * price * 0.1, 50);
}double getTotalPrice()
{double baseTotalPrice = price * quantity;double discountPrice = max(0, quantity - 100) * price;double postPrice = min(quantity * price * 0.1, 50);return baseTotalPrice - discountPrice + postPrice;
}(二)函数中bool类型的参数的优化
就是把bool给剥离出来,构成单一职责
1.原始未优化
double calcFinalAmount(double originAmount, bool isChild)
{if(isChild){return originAmount * 0.5;}else{return originAmount;}
}2.代码简单优化
//职责不单一
double calcFinalAmount(double originAmount, bool isChild)
{double discount = isChild ? 0.5 : 1;return originAmount * discount;
}
3.根源变量单一职责
//单一职责,根源可变变量划分
double getDiscount(bool isChild)
{return isChild ? 0.5 : 1;
}
double calcFinalAmount(double originAmount, bool isChild)
{double discount = getDiscount(isChild);return originAmount * discount;
}4.功能单一职责
//单一职责,功能划分
double calcFinalAmountForChild(double originAmount, bool isChild)
{return originAmount * 0.5;
}
double calcFinalAmountForAdult(double originAmount, bool isChild)
{return originAmount;
}(三)令人抓狂的字符串组合
硬拼接---->变成格式化拼接
//硬拼接
std::string userInfo = "user info:" + "id: " + userId.to_string() + "Name: " + user.Name());
//格式化拼接
char data[200];
sprintf(data, "user info : id : %s, Name : %s", userId.to_string(), user.Name());(四)函数复用性优化
struct Users
{int status;
};
// 函数复用性很差
Users queryUserStatusIs10();
Users queryUserStatusIs5();
// 改善复用性之后
Users queryUsersByStatus(int status);(五)避免魔法数字
1.未优化
std::string getUserStrType()
{// 1--- child 2---adult 3---elderint userType = 0;if (userType == 0){return "child";}else if (userType == 1){return "adult";}else if (userType == 2){return "elder";}
}优化:
enum UserType
{CHILD,ADULT,ELDER,
};std::string getUserStrType()
{// 1--- child 2---adult 3---elderUserType ut = UserType::CHILD;if (ut == UserType::CHILD){return "child";}else if (ut == UserType::ADULT){return "adult";}else if (ut == UserType::ELDER){return "elder";}
}(六)长函数分解优化(注释驱动原则)
每当刚觉要用注释来说明解释用途的时候,这时候就需要把它抽离出来做成一个单独的函数。简单来说就是要进行功能划分,满足单一职责原则。
优化之前:
void calcMoney()
{//1. 计算总金额,如果是vip,则打95折(代码块)//2. 根据金额生成付款码{代码块)//3. 初始化付款任务{代码块)
}优化后:
double calcSumMoney();
double generateRandomCoded(double sumPrice);
bool initTask();void calcMoney()
{//1. 计算总金额,如果是vip,则打95折(函数)double sumPrice = calcSumMoney();//2. 根据金额生成付款码{代码块)generateRandomCoded(sumPrice);//3. 初始化付款任务initTask();
}(七)复用函数的提炼
(八)多参数函数的优化
把参数封装到结构体中。参数有可能传入错误,顺序错误,采用结构体的方法可以避免这种问题,总结来说,当参数大于等于4个,就可以采用这种方式。
1.未优化
int queryResultFromServer(strName, queryId, userID, userRegion, bIsNewVersion);2.优化之后
可以把前4个参数,放到一个对象里面,比如结构体里面。
struct Obj
{std::string strName;int queryId;int userID;int userRegion;bool bIsNewVersion;
};
int queryResultFromServer(Obj obj);
(九)查询代替临时变量
优化前:
double getPrice()
{double basePrice = quantity * itemPrice;double discount = 1.0;if (basePrice > 1000){discount = 0.95;}return basePrice * discount;
}优化后:
//分解为
double getBasePrice()
{return quantity* itemPrice;
}
double getDiscount()
{return getBasePrice() > 1000 ? 0.95 :0.98;
}
double getPrice()
{return getBasePrice() * getDiscount();
}(十)数组的错误使用(属性字段)
数字改成结构体或者类,并且字段用函数来查询
class Person
{
public:Person(int age, std::string name, std::string country){m_age = age;m_name = name;m_country = country;}int getAge(){return m_age;;}std::string getName(){return m_name;}std::string getCountry(){return m_country;}private:int m_age;std::string m_name;std::string m_country;
};void printInfo(Person& person)
{printf("name: %s, age: %d, country: %s", person.getName(), person.getAge(), person.getCountry());
}
(十一)函数的副作用
1.修改任何外部的变量、对象属性和数据结构;
2.控制台输入和输出交互;
3.文件操作和网络操作
4.抛出异常或者错误终止;
//错误写法
void getMaxScore()
{arrScore = arrScore.sort();return arrScore[0];
}传入同一个参数,得到的结果不同,这就是非纯函数,一般不能用的。
(十二) 判断函数的命名
1) is/can/could/should/need +[名词】 + 形容词,比如 isUserNotExists(); isUserIdAndAgeValid();
2) isUserValid,正逻辑, isUserNotValid,就是反逻辑。尽量使用正逻辑;
3)isUserNameAndIdValid();应该改拆成 isUserAgeValid(); isUserNameValid();,功能单一,使用起来易于扩展
(十三)硬编码,变量写死
1)把硬编码改成 常量+ 变量的字符串拼接。
2)定义成全局常量
(十四)变量命名
1)int days 写成 int elapsedTimesInDays; 什么的天;
2) 命名次数,times, 改成 timesOfRequestRetry; 究竟是对于什么的次数。
3)flag,,,改成isProcessFinished;
4)createdFiles;
(十五)区分命名
1)数字命名
//数字命名,
void copyChars(char a1[], char a2[]);
//改成
void copyChars(char src[], char dst[]);
2)无意义的命名
class Product; class ProductInfo; class ProductData;
3)strName, 这时候添加类型名是多余的;
bIsAgeValid中的b就是多余的。
如果变量中类型名是多余的,那就不要类型名。
(十六)避免误导
1)缩写误导
Rgb2Gray(0正确,
setDataSta(), 这个sta就难以理解了,不是一个通用的简写方法。
queryUserAdd(); add作者想表达是地址,但是现在用add会给人带来误导。
用简写就用通用的简写,大众不认可的不要用,不认可的情况下就用全写。
2)多义词误导
bool setMonitorTime(); 设置监视持续多少时间? 开始时间? 监控次数?等等;
queryRegistryContent(); register是注册表吗?
3)变量类型误导
class Account;
Account[] accountList, 这时候大家可能认为它是list的类型,容易搞混淆。
4)外形相似误导
xyzControllerForHnadlingOfString() 和 xyzControllerForStorageOfString();
这样不仔细看,还以为是同一个函数。
0和o比较相似; l和i和1也比较相似;
(十七)函数中动词选用指南
1)避免滥用通用词
getTotalAmount(); get此滥用。
addCharacter(); 添加一个字符,困惑,添加到头部还是尾部?
一些词汇,创建(create,init,load),销毁(destroy,release,uninit,deinit),动词(get,fetch,load,read,write,find、serach,receive,pull),(set, write,put,push),更新(update,reset,refresh),添加/移除(add,remove,append,insert,delete);启动/停止(start,open,launch, close,stop,finish);
(十八)函数命名动词选取
filter,mergeBy,contact, split, deduplicate, reverse, sort,fill,parse, analysis, format,convert,ensure,
(十九)代码review
1)注意
无意义的注释,过多篇幅的注释,修改代码不更新注释导致无法理解;清晰的代码是不需要过多的注释说明的,
基础的功能应该封装成代码。
函数过长,功能应该被划分。
重复代码不做复用。
按照职责设计和提炼函数,尽量做到函数的单一职责。
相同逻辑的代码积极复用。
2)典型问题
定义的时候不考虑解耦;
使用常量代替应该动态使用的内容。
3)能够在运行的时候获取的内容,不应该写死。
相关文章:
)
重构(4)
(一)添加解释性变量,使得代码更容易理解,更容易调试,也可以方便功能复用 解释性的变量 总价格为商品总价(单价*数量)-折扣(超过100个以上的打9折)邮费(原价的…...
神经网络|(三)线性回归基础知识
【1】引言 前序学习进程中,已经对简单神经元的工作模式有所了解,这种二元分类的工作机制,进一步使用sigmoid()函数进行了平滑表达。相关学习链接为: 神经网络|(一)加权平均法,感知机和神经元-CSDN博客 神经网络|(二…...
deepseek R1 高效使用学习
直接提问 1、可以看到思考过程,可以当个学习工具 2、高效简介代码prompt <context> You are an expert programming AI assistant who prioritizes minimalist, efficient code. You plan before coding, write idiomatic solutions, seek clarification …...

STM32_SD卡的SDIO通信_基础读写
本篇将使用CubeMXKeil, 创建一个SD卡读写的工程。 目录 一、SD卡要点速读 二、SDIO要点速读 三、SD卡座接线原理图 四、CubeMX新建工程 五、CubeMX 生成 SD卡的SDIO通信部分 六、Keil 编辑工程代码 七、实验效果 实现效果,如下图: 一、SD卡 速读…...

【Docker】私有Docker仓库的搭建
一、准备工作 确保您的系统已安装Docker。如果没有安装,请参考Docker官方文档进行安装。 准备一个用于存储仓库数据的目录,例如/registry_data/。 二、拉取官方registry镜像 首先,我们需要从Docker Hub拉取官方的registry镜像。执行以下命…...

linux 管道符、重定向与环境变量
1. 输入输出重定向 在linux工作必须掌握的命令一文中,我们已经掌握了几乎所有基础常用的Linux命令,那么接下来的任务就是把多个命令适当的组合到一起,使其协同工作,会更高效的处理数据,做到这一点就必须搞清楚命令的输…...

Ansible fetch模块详解:轻松从远程主机抓取文件
在自动化运维的过程中,我们经常需要从远程主机下载文件到本地,以便进行分析或备份。Ansible的fetch模块正是为了满足这一需求而设计的,它可以帮助我们轻松地从远程主机获取文件,并将其保存到本地指定的位置。在这篇文章中…...
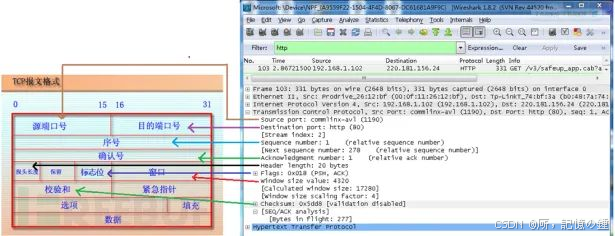
wireshark工具简介
目录 1 wireshark介绍 2 wireshark抓包流程 2.1 选择网卡 2.2 停止抓包 2.3 保存数据 3 wireshark过滤器设置 3.1 显示过滤器的设置 3.2 抓包过滤器 4 wireshark的封包列表与封包详情 4.1 封包列表 4.2 封包详情 参考文献 1 wireshark介绍 wireshark是非常流行的网络…...

51单片机——按键控制LED流水灯
引言 在电子制作和嵌入式系统学习中,51 单片机是一个经典且入门级的选择。按键控制 LED 流水灯是 51 单片机的一个基础应用,通过这个实例,我们可以深入了解单片机的输入输出控制原理。 51 单片机简介 51 单片机是对所有兼容 Intel 8051 指…...

【opencv】第9章 直方图与匹配
第9章 直方图与匹配 9.1 图像直方图概述 直方图广泛运用于很多计算机视觉运用当中,通过标记帧与帧之间显著的边 缘和颜色的统计变化,来检测视频中场景的变化。在每个兴趣点设置一个有相近 特征的直方图所构成“标签”,用以确定图像中的兴趣点。边缘、色…...

HTML5 Web Worker 的使用与实践
引言 在现代 Web 开发中,用户体验是至关重要的。如果页面在执行复杂计算或处理大量数据时变得卡顿或无响应,用户很可能会流失。HTML5 引入了 Web Worker,它允许我们在后台运行 JavaScript 代码,从而避免阻塞主线程,保…...

MVCC底层原理实现
MVCC的实现原理 了解实现原理之前,先理解下面几个组件的内容 1、 当前读和快照读 先普及一下什么是当前读和快照读。 当前读:读取数据的最新版本,并对数据进行加锁。 例如:insert、update、delete、select for update、 sele…...

基于ESP32-IDF驱动GPIO输出控制LED
基于ESP32-IDF驱动GPIO输出控制LED 文章目录 基于ESP32-IDF驱动GPIO输出控制LED一、点亮LED3.1 LED电路3.2 配置GPIO函数gpio_config()原型和头文件3.3 设置GPIO引脚电平状态函数gpio_set_level()原型和头文件3.4 代码实现并编译烧录 一、点亮LED 3.1 LED电路 可以看到&#x…...

【优选算法】9----长度最小的子数组
----------------------------------------begin-------------------------------------- 铁子们,前面的双指针算法篇就算告一段落啦~ 接下来是我们的滑动窗口篇,不过有一说一,算法题就跟数学题一样,只要掌握方法,多做…...

LabVIEW太阳能照明监控系统
在公共照明领域,传统的电力照明系统存在高能耗和维护不便等问题。利用LabVIEW开发太阳能照明监控系统,通过智能控制和实时监测,提高能源利用效率,降低维护成本,实现照明系统的可持续发展。 项目背景 随着能源危机…...

MongoDB中单对象大小超16M的存储方案
在 MongoDB 中,单个文档的大小限制为 16MB。如果某个对象(文档)的大小超过 16MB,可以通过以下几种方案解决: 1. 使用 GridFS 适用场景:需要存储大文件(如图像、视频、文档等)。 原…...

三维激光扫描-用智能检测系统提升效率
当下,企业对生产效率和质量控制的要求越来越高。传统的检测方法往往难以满足高精度、快速响应的需求。三维激光扫描技术结合智能检测系统,为工业检测带来了革命性的变革。 传统检测方法的局限性 传统检测方法主要依赖于人工测量和机械检测工具…...

css遇到的一些问题
1.vw单位,在PC端vw单位是包含右侧滚轮的宽度,而在移动端不会包含滚轮的长度,在PC端运用vw单位进行居中对齐,会比实际偏左盒子偏右一点,因为内容区域并不包含滚轮。 2.运用媒体查询进行响应式布局式,媒体查询…...

【langgraph】ubuntu安装:langgraph:未找到命令
langgraph 在ubuntu24.04 参考:langgraph运行:报错: (05_ep_dev) root@k8s-master-pfsrv:/home/zhangbin/perfwork/01_ai/05_ep_dev/expert# langgraph dev langgraph:未找到命令查看langraph的安装情况 pip show langgraph...

mysql 学习2 MYSQL数据模型,mysql内部可以创建多个数据库,一个数据库中有多个表;表是真正放数据的地方,关系型数据库 。
在第一章中安装 ,启动mysql80 服务后,连接上了mysql,那么就要 使用 SQL语句来 操作mysql数据库了。那么在学习 SQL语言操作 mysql 数据库 之前,要对于 mysql数据模型有一个了解。 MYSQL数据模型 在下图中 客户端 将 SQL语言&…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...
)
别再手动点菜单了!用这招让Cadence Virtuoso Schematic效率翻倍(附Net高亮快捷键配置)
电路设计效率革命:Cadence Virtuoso Schematic高阶快捷键配置指南 在集成电路设计的浩瀚宇宙中,Cadence Virtuoso如同设计师手中的光刻机,每一次精准操作都直接影响最终芯片的性能与可靠性。然而,当面对数百个晶体管组成的复杂模…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...

【2026最新】应对Turnitin查重:实测5大英文查降AI宝藏工具,一站式搞定初稿
现在的英文初稿,无论是期刊文章、SCI 还是普通的 Course Essay,基本都需要评估内容的原创度,进行文章 AI 率检测。很多伙伴以为纯手敲就能过,结果一查数据依然不尽如人意。 针对英文内容,咱们必须使用专门的英文检测和…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

别再死记公式了!用Python手写一个卷积层,彻底搞懂CNN里的‘卷’是怎么算的
用Python手写卷积层:从零理解CNN的"卷"运算 当你第一次看到卷积神经网络(CNN)的数学公式时,那些复杂的符号和下标是否让你望而却步?作为计算机视觉领域的基石,CNN的核心在于理解卷积运算的本质。本文将带你用NumPy从零实…...

收藏干货|2026 版双非零基础入局大模型开发,RAG 与 Agent 就业上岸全攻略
日常总能收到不少初学伙伴的私信,大家普遍都有同一个疑惑:二本及普通院校学历,零基础入门 RAG、Agent 大模型应用开发,究竟能不能顺利入职?行业后续发展前景又如何? 本篇 2026 年全新内容,不空谈…...

AVR+ESP8266双核架构打造独立WiFi天气显示器:从硬件设计到软件实现
1. 项目概述:一个独立WiFi天气显示器的诞生几年前,我琢磨着在书桌上放一个能实时显示天气信息的小玩意儿,市面上成品要么功能单一,要么价格不菲,要么数据源依赖复杂的服务器。于是,我决定自己动手ÿ…...