Hadoop•搭建完全分布式集群
听说这里是目录哦
- 一、安装Hadoop🥕
- 二、配置Hadoop系统环境变量🥮
- 三、验证Hadoop系统环境变量是否配置成功🧁
- 四、修改Hadoop配置文件🍭
- 五、分发Hadoop安装目录🧋
- 六、分发系统环境变量文件🍨
- 七、格式化HDFS文件系统🍰
- 八、启动Hadoop🎂
- 九、查看Hadoop运行状态🍬
- 搭建时遇到的问题⚠️
- logs does not exist. Creating
- secondary namenode等丢失(jps时看不到)
- 能量站😚
前提是集群里的虚拟机间实现了免密登录以及JDK的成功安装(执行
java -version查看JDK版本号)。【可以参考
Hadoop•FinalShell连接VMware&免密登录和
Hadoop•安装JDK】【这里是以test为主结点、test1和test2为从结点。如果看到node了,就是我忘改了,node的是以node1为主结点、node2和node3为从结点。怕真出现了会迷惑,还是谨慎一点点~😗】
一、安装Hadoop🥕
三台机子的JDK和Hadoop版本必须一致
- 电脑下载Hadoop安装包(需要该安装包可以在文章下面评论
1,如果宝贝是学生,你们老师应该会给,命令记得要根据安装包名字对应更改哦😚) - 用FinalShell直接上传到虚拟机,用
mv命令移动到所需文件夹。如mv /jdk-8u271-linux-x64.tar.gz /export/software,即mv /要移动文件的名字/要移动到的文件夹(如果显示没有那个文件或目录,“Hadoop•安装JDK”里有解决办法) - 将位于
/export/software的文件名为hadoop-3.3.0.tar.gz的Hadoop安装包解压缩到/export/servers,命令为tar -zxvf /export/software/hadoop-3.3.0.tar.gz -C /export/servers(这里的目录约定在Hadoop•安装JDK有说明)
二、配置Hadoop系统环境变量🥮
编辑环境变量的配置文件,命令为vi /etc/profile,在文件底部添加这些你所安装的Hadoop(解压缩后)的路径以及它的bin目录(包含Hadoop可执行文件)和sbin目录(包含系统级别的Hadoop可执行文件,用于启动和停止Hadoop服务)的路径。编好后保存退出,用source /etc/profile使环境变量生效。
添加:
export HADOOP_HOME=/export/servers/hadoop-3.3.0export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
增加理解:

三、验证Hadoop系统环境变量是否配置成功🧁
执行hadoop version命令可以查看到Hadoop版本号就成功了(跟查看JDK版本号的命令不同,这个命令version前没有横杠-)

四、修改Hadoop配置文件🍭
修改的都是自己后来装的Hadoop3.3.0【/export/servers/hadoop-3.3.0/etc/hadoop】里的,一共要修改六个文件。
- hadoop-env.sh
在底部添加
export JAVA_HOME=/export/servers/jdk1.8.0_271
#文件最后添加
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
🧀🧀🧀我是分割线

- core-site.xml
在底部添加
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://test:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
🧀🧀🧀我是分割线

- hdfs-site.xml
在底部添加
<configuration>
<property>
name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>test1:9868</value>
</property>
</configuration>
🧀🧀🧀我是分割线

- mapred-site.xml
在底部添加
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>test:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>test:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
🧀🧀🧀我是分割线

- yarn-site.xml
在底部添加
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>test</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 保存的时间7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
🧀🧀🧀我是分割线

- workers
最终修改为(core-site.xml已经指定了主节点的地址,这里只要列出从节点地址就能让集群识别主从结点了)【下面是两个从节点的名字】:
test1
test2
五、分发Hadoop安装目录🧋
-
分发到test1
scp -r /export/servers/hadoop-3.3.0 root@test1:/export/servers -
分发到test2
scp -r /export/servers/hadoop-3.3.0 root@test2:/export/servers
六、分发系统环境变量文件🍨
-
分发到test1
scp /etc/profile root@test1:/etc -
分发到test2
scp /etc/profile root@test2:/etc
分发完后在test1和test2执行source /etc/profile
七、格式化HDFS文件系统🍰
在主结点test执行hdfs namenode -format,注意只有初次启动Hadoop集群前才需要格式化。

八、启动Hadoop🎂
在主结点test执行start-dfs.sh和start-yarn.sh实现在三台虚拟机上启动HDFS和YARN的相关服务。如果要关闭Hadoop,则在主结点test执行stop-dfs.sh和stop-yarn.sh的命令。(或者start-all.sh一键启动)
start-all.sh一键启动在Hadoop 2.x版本中已经被弃用,在Hadoop 3.x版本中,仍然可以使用,但建议分别使用start-dfs.sh和start-yarn.sh来启动HDFS和YARN服务,以避免潜在的问题。总的来说,就是最好分别启动。

🧀🧀🧀我是分割线

九、查看Hadoop运行状态🍬
分别在三台虚拟机执行jps命令查看Hadoop运行状态。



搭建时遇到的问题⚠️
logs does not exist. Creating
这里是以test为主结点、test1和test2为从结点。
问题:test1: WARNING: /export/servers/hadoop-3.3.0/logs does not exist. Creating.
解决办法:在三个节点上启动journalnode,命令是hdfs --daemon start journalnode,就是三台虚拟机都需要执行这个命令。




secondary namenode等丢失(jps时看不到)
问题:多次格式化导致secondary namenode等丢失(jps时看不到)
解决办法:
-
关闭集群
stop-all.sh或stop-dfs.sh和stop-yarn.sh -
删除集群产生的缓存文件(三台机子都要!!!)
(一)/export/data的hadoop文件夹(三台机子都要)

(二)删除/export/servers/hadoop-3.1.4/logs(三台机子都要)
也是先刷新哦,然后整个文件夹直接删掉,格式化后会自己创建的

-
重新格式化
hdfs namenode -format

能量站😚
我遇到的挑战可以帮助我成长。

❤️谢谢你为自己努力❤️
相关文章:
Hadoop•搭建完全分布式集群
听说这里是目录哦 一、安装Hadoop🥕二、配置Hadoop系统环境变量🥮三、验证Hadoop系统环境变量是否配置成功🧁四、修改Hadoop配置文件🍭五、分发Hadoop安装目录🧋六、分发系统环境变量文件🍨七、格式化HDFS文…...

SQL-leetcode—1141. 查询近30天活跃用户数
1141. 查询近30天活跃用户数 表:Activity ---------------------- | Column Name | Type | ---------------------- | user_id | int | | session_id | int | | activity_date | date | | activity_type | enum | ---------------------- 该表没有包含重复数据。 …...

总结与展望,龙蜥社区第 30 次运营委员会会议线上召开
2025 年 1 月 20 日,龙蜥社区召开了第 30 次运营委员会线上会议,来自 24 家理事单位的 22 位委员及委员代表出席,本次会议由运营委员凝思软件李晨斌主持。会上总结和回顾了龙蜥社区 1 月运营发展情况,同步了龙蜥社区 3 大运营目标…...

idea对jar包内容进行反编译
1.先安装一下这个插件java Bytecode Decompiler 2.找到这个插件的路径,在idea的plugins下面的lib文件夹内:java-decompiler.jar。下面是我自己本地的插件路径,以作参考: D:\dev\utils\idea\IntelliJ IDEA 2020.1.3\plugins\java-d…...

c++----------------------多态
1.多态 1.1多态的概念 多态(polymorphism)的概念:通俗来说,就是多种形态。多态分为编译时多态(静态多态)和运⾏时多 态(动态多态),这⾥我们重点讲运⾏时多态,编译时多态(静态多态)和运⾏时多态(动态多态)。编译时 多态(静态多态)…...

C语言 指针_野指针 指针运算
野指针: 概念:野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的) 指针非法访问: int main() {int* p;//p没有初始化,就意味着没有明确的指向//一个局部变量不初始化,放…...

【JavaEE进阶】Spring留言板实现
目录 🎍预期结果 🍀前端代码 🎄约定前后端交互接口 🚩需求分析 🚩接口定义 🌳实现服务器端代码 🚩lombok介绍 🚩代码实现 🌴运行测试 🎄前端代码实…...

第25篇 基于ARM A9处理器用C语言实现中断<一>
Q:怎样理解基于ARM A9处理器用C语言实现中断的过程呢? A:同样以一段使用C语言实现中断的主程序为例介绍,和汇编语言实现中断一样这段代码也使用了定时器中断和按键中断。执行该主程序会在DE1-SoC的红色LED上显示流水灯…...

面向通感一体化的非均匀感知信号设计
文章目录 1 非均匀信号设计的背景分析1.1 基于OFDM波形的感知信号1.2 非均匀信号设计的必要性和可行性1.2 非均匀信号设计的必要性和可行性 3 通感一体化系统中的非均匀信号设计方法3.1 非均匀信号的设计流程(1)均匀感知信号设计(2࿰…...

修改docker共享内存shm-size
法1:在创建容器时增加共享内存大小 nvidia-docker run -it -p 10000:22 --name"zm" -v /home/zm:/data ufoym/deepo:all-cu101 /bin/bash --shm-size20G法2:修改正在运行的容器的共享内存设置 查看容器、共享内存 docker ps -a df -lh | gr…...

WIN11 UEFI漏洞被发现, 可以绕过安全启动机制
近日,一个新的UEFI漏洞被发现,可通过多个系统恢复工具传播,微软已经正式将该漏洞标记为追踪编号“CVE-2024-7344”。根据报告的说明,该漏洞能让攻击者绕过安全启动机制,并部署对操作系统隐形的引导工具包。 据TomsH…...

网安加·百家讲坛 | 樊山:数据安全之威胁建模
作者简介:樊山,锦联世纪教育能源工业互联网数字安全CSM(新能源运维师)课程特聘培训讲师,哈尔滨工业大学(深圳)信飞合创数据合规联合实验室特聘专家,武汉赛博网络安全人才研究中心资深专家;近24年…...

jQuery阶段总结(二维表+思维导图)
引言 经过23天的学习,期间有期末考试,有放假等插曲。本来应该在学校里学习,但是特殊原因,让回家了。但是在家学习的过程,虽然在学,很让我感觉到不一样。但是效果始终还是差点的,本来17、18号左右…...
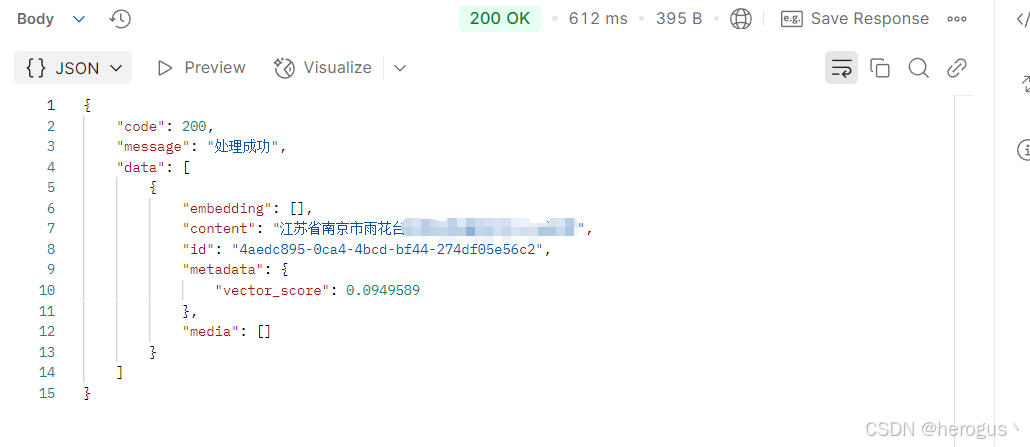
【LLM】RedisSearch 向量相似性搜索在 SpringBoot 中的实现
整理不易,请不要吝啬你的赞和收藏。 1. 前言 写这篇文章挺不容易的,网络上对于 SpringBoot 实现 Redis 向量相似性搜索的文章总体来说篇幅较少,并且这些文章很多都写得很粗糙,或者不是我想要的实现方式,所以我不得不阅…...
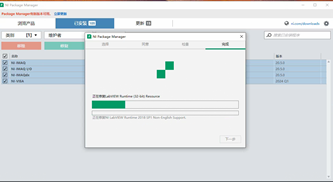
如何为64位LabVIEW配置正确的驱动程序
在安装 64位 LabVIEW 后,确保驱动程序正确配置是关键。如果您首先安装了 32位 LabVIEW 和相关驱动,然后安装了 64位 LabVIEW,需要确保为 64位 LabVIEW 安装和配置适当的驱动程序,才能正常访问硬件设备。以下是详细步骤:…...

Redis(5,jedis和spring)
在前面的学习中,只是学习了各种redis的操作,都是在redis命令行客户端操作的,手动执行的,更多的时候就是使用redis的api(),进一步操作redis程序。 在java中实现的redis客户端有很多,…...

Git 小白入门教程
🎯 这篇文章详细介绍了版本控制的重要性,特别是通过Git实现的分布式版本控制相对于SVN集中式控制的优势。文章首先解释了版本控制的基本概念,强调了在文档或项目多版本迭代中备份与恢复任意版本的能力。接着,重点阐述了Git的历史背…...
:神经网络与迁移学习在猫狗分类中的应用)
Python从0到100(八十五):神经网络与迁移学习在猫狗分类中的应用
在人工智能的浩瀚宇宙中,深度学习犹如一颗璀璨的星辰,引领着机器学习和计算机视觉领域的前沿探索。而神经网络,作为深度学习的核心架构,更是以其强大的数据建模能力,成为解决复杂问题的重要工具。今天,我们…...
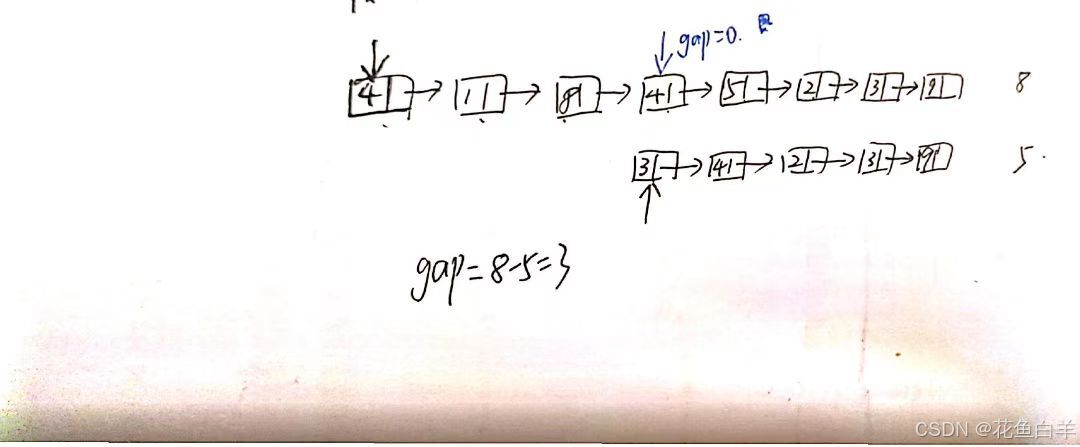
代码随想录刷题day14(2)|(链表篇)02.07. 链表相交(疑点)
目录 一、链表理论基础 二、链表相交求解思路 三、相关算法题目 四、疑点 一、链表理论基础 代码随想录 二、链表相交求解思路 链表相交时,是结点的位置,也就是指针相同,不是结点的数值相同; 思路:定义两个指针…...
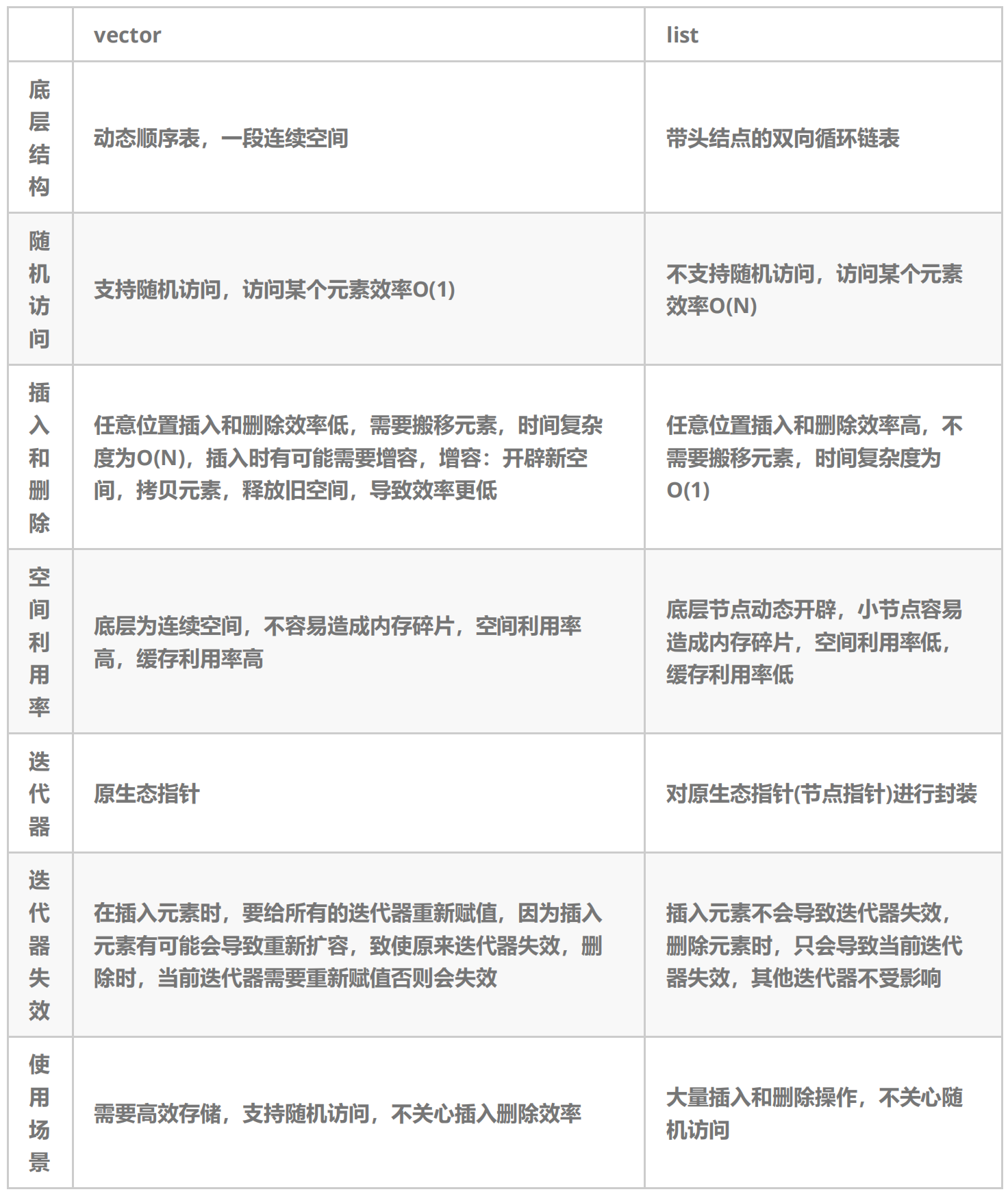
C++ 复习总结记录九
C 复习总结记录九 主要内容 1、list 介绍及使用 2、list 剖析及模拟实现 3、list 与 vector 对比 一 list 介绍及使用 List 相关文档 1、List 在任意位置进行插入和删除的序列式容器 O(1) ,且该容器可前后双向迭代 2、List 底层是带头双向循环链表ÿ…...

LLM API安全攻防实战:从提示词注入到自动化测试方案
1. 项目概述:被忽视的LLM API安全前线最近在帮几个团队做上线前的安全审计,发现一个挺有意思的现象:大家对于传统API的鉴权、限流、SQL注入这些常规检查已经形成了肌肉记忆,但一旦涉及到LLM(大语言模型)的A…...

AMLP:基于大语言模型的自动化机器学习势函数构建平台
1. 项目概述:当AI遇见原子模拟,AMLP如何重塑机器学习势函数构建在计算材料科学和化学物理领域,分子动力学模拟是我们窥探微观世界动态行为的“显微镜”。无论是研究新材料的相变过程,还是探索生物大分子的折叠机制,其核…...

物联网与云技术赋能咖啡后处理:CeriTech 的实时监控系统实践
1. 项目概述:用物联网与云技术重塑咖啡后处理在印尼的咖啡农场里,传统的发酵与干燥过程很大程度上依赖“感觉”和“经验”。一位有经验的农人可能会用手触摸、用鼻子闻,或者根据天气和日照时间来估算发酵是否完成、干燥是否均匀。这种方法固然…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

光轮智能 谢晨 访谈总结机器人仿真数据产业
光轮智能 谢晨 访谈总结机器人仿真关于创始人关于数据数据金字塔数据痛点仿真数据的重要性仿真数据的质量b站链接地址公司官网关于创始人 清华物理;哥伦比亚金融;英伟达智驾仿真;小鹏智驾仿真;现为光轮智能CEO 关于数据 数据的…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

Java项目中如何提升整体系统性能?
性能优化可以说是我们程序员的必修课,如果你想要跳出CRUD的苦海,成为一个更“高级”的程序员的话,性能优化这一关你是无论无何都要去面对的。为了提升系统性能,开发人员可以从系统的各个角度和层次对系统进行优化。除了最常见的代…...

UE4SS终极指南:从零开始掌握虚幻引擎脚本系统
UE4SS终极指南:从零开始掌握虚幻引擎脚本系统 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE4S…...