【LLM】RedisSearch 向量相似性搜索在 SpringBoot 中的实现
整理不易,请不要吝啬你的赞和收藏。
1. 前言
2. 前提条件
- 已安装 Redis Stack ,如何安装请参考 docker compose 安装 Redis Stack 。
- 已对 Redis 作为向量库有了解,如不了解请参考 Redis 作为向量库入门指南。
- 项目中引入了 Spring AI Alibaba ,如何引入请参考 Spring AI Alibaba 的简单使用 。
-
项目中引入了 Redis ,如何引入请参考 SpringBoot 引入 redis 。
3. 使用 UnifiedJedis 实现
3.1 引入依赖
3.1.1 引入 Redis 客户端
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><exclusions><exclusion><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId></exclusion></exclusions>
</dependency><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId>
</dependency><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.2.4</version>
</parent>3.1.2 引入 Spring AI Alibaba
<dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter</artifactId>
</dependency>3.2 添加配置
3.2.1 添加 redis 配置
spring:data:redis:database: 0host: 127.0.0.1port: 6379password: gusy1234jedis:pool:# 连接池最大连接数max-active: 8# 连接池最大空闲连接数max-idle: 8# 连接池最大阻塞等待时间,负值表示没有限制max-wait: 0# 连接池最小空闲连接数min-idle: 2# 连接超时时间(毫秒)timeout: 10003.3 配置连接池
3.3.1 使用自定连接池
@Bean
public UnifiedJedis unifiedJedis() {HostAndPort hostAndPort = new HostAndPort(host, port);// 设置 Jedis 客户端配置DefaultJedisClientConfig jedisClientConfig = DefaultJedisClientConfig.builder().password(password).database(database).build();// 设置连接池参数ConnectionPoolConfig poolConfig = new ConnectionPoolConfig();poolConfig.setMaxTotal(maxActive);poolConfig.setMaxIdle(maxIdle);poolConfig.setMinIdle(minIdle);PooledConnectionProvider provider = new PooledConnectionProvider(hostAndPort, jedisClientConfig, poolConfig);return new UnifiedJedis(provider);
}3.3.2 (推荐)使用 JedisPooled
@Bean
public JedisPooled jedisPooled() throws URISyntaxException {ConnectionPoolConfig poolConfig = new ConnectionPoolConfig();// 池中最大活跃连接数,默认 8poolConfig.setMaxTotal(maxActive);// 池中最大空闲连接数,默认 8poolConfig.setMaxIdle(maxIdle);// 池中的最小空闲连接数,默认 0poolConfig.setMinIdle(minIdle);// 启用等待连接变为可用poolConfig.setBlockWhenExhausted(true);// 等待连接变为可用的最大秒数,jdk17 以上支持,低版本可用 setMaxWaitMillispoolConfig.setMaxWait(Duration.ofSeconds(1));// 控制检查池中空闲连接的间隔时间,jdk17 以上支持,低版本可用 setTimeBetweenEvictionRunsMillispoolConfig.setTimeBetweenEvictionRuns(Duration.ofSeconds(1));return new JedisPooled(poolConfig, new URI(redisUri));
}3.4 Text Embedding
3.4.1 调用百炼 Embedding Model
public List<Embedding> textEmbedding(List<String> texts) {// 调用百炼 Embedding 模型EmbeddingResponse embeddingResponse = dashScopeEmbeddingModel.call(new EmbeddingRequest(texts,DashScopeEmbeddingOptions.builder().withModel(DashScopeApi.EmbeddingModel.EMBEDDING_V3.getValue()) // 设置使用的模型.withTextType(DashScopeApi.DEFAULT_EMBEDDING_TEXT_TYPE) // 设置文本类型.withDimensions(1024) // 设置向量维度,可选768、1024、1536.build()));List<Embedding> results = embeddingResponse.getResults();// 打印向量
// if (CollectionUtils.isEmpty(results)) {
// int tempSize = results.size();
// for (int i = 0; i < tempSize; i++) {
// float[] embeddingValue = results.get(i).getOutput();
// log.info("embeddingValue:{}", embeddingValue.toString());
// }
// }return results;}3.5 向量数据入库
3.5.1 主要代码
@Autowired
private RedisTemplate redisTemplate;/*** 存入向量信息** @param key redis KEY* @param vectorField 向量存储字段名* @param vectorValue 向量值* @param contentField 向量文本内容存储字段名* @param content 向量文本内容,增加存储文本内容,方便查看向量的内容*/
public void addDocument(String key, String vectorField, float[] vectorValue, String contentField, String content) {// 将向量值转为二进制byte[] vectorByte = CommonUtil.floatArrayToByteArray(vectorValue);// 组装字段mapMap<String, Object> fieldMap = new LinkedMap<>();fieldMap.put(contentField, content.getBytes(StandardCharsets.UTF_8));fieldMap.put(vectorField, vectorByte);// 入库redisTemplate.opsForHash().putAll(key, fieldMap);
}3.5.2 存储数据展示
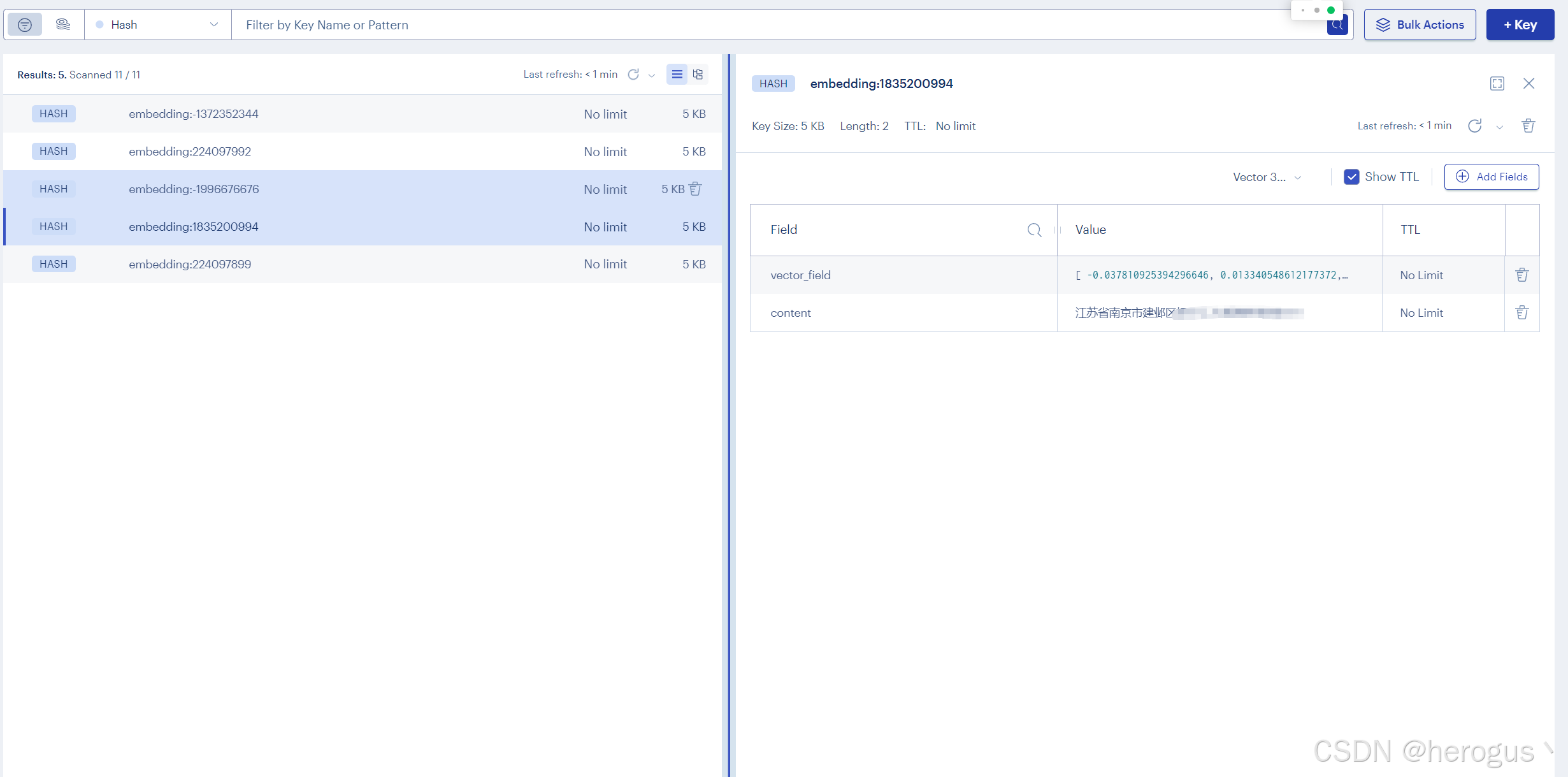
3.6 查询相似度
3.6.1 主要代码
@Autowired
private JedisPooled jedisPooled;/*** 相似度搜索** @param queryVector 查询的向量内容* @param k 返回 k 个最相似内容* @param indexName 索引名称* @param vectorField 向量存储字段名* @return*/
public SearchResult similaritySearch(float[] queryVector, int k, String indexName, String vectorField) {// 组装查询// 同:FT.SEARCH embedding_index "* => [KNN 3 @vector_field $query_vector AS distance]"// PARAMS 2 query_vector "\x12\xa9\xf5\x6c"// SORTBY distance// DIALECT 4Query q = new Query("*=>[KNN $K @" + vectorField + " $query_vector AS distance]").returnFields("content", "distance").addParam("K", k).addParam("query_vector", CommonUtil.floatArrayToByteArray(queryVector)).setSortBy("distance", true).dialect(4);// 使用 UnifiedJedis 执行 FT.SEARCH 语句try {SearchResult result = jedisPooled.ftSearch(indexName, q);log.info("redis相似度搜索,result:{}", JSONObject.toJSONString(result));return result;}catch (Exception e) {log.warn("redis相似度搜索,异常:", e);throw new ErrorCodeException(e.getMessage());}
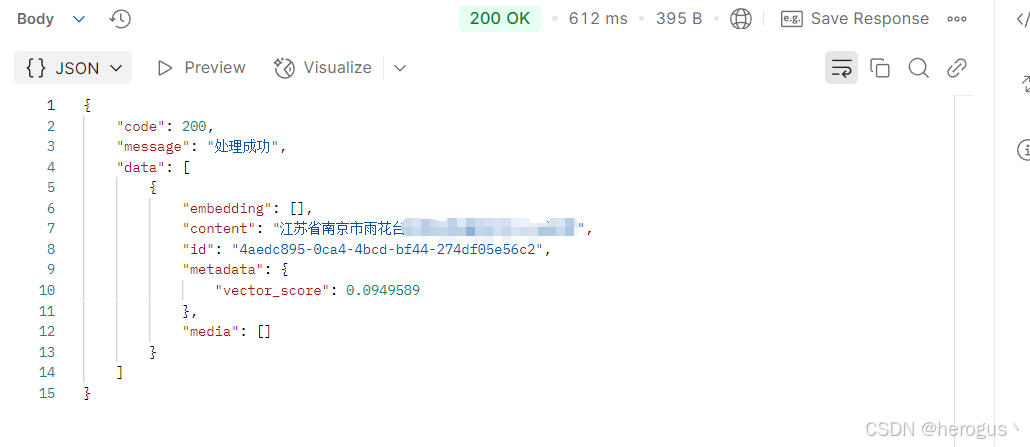
}3.6.2 查询结果展示
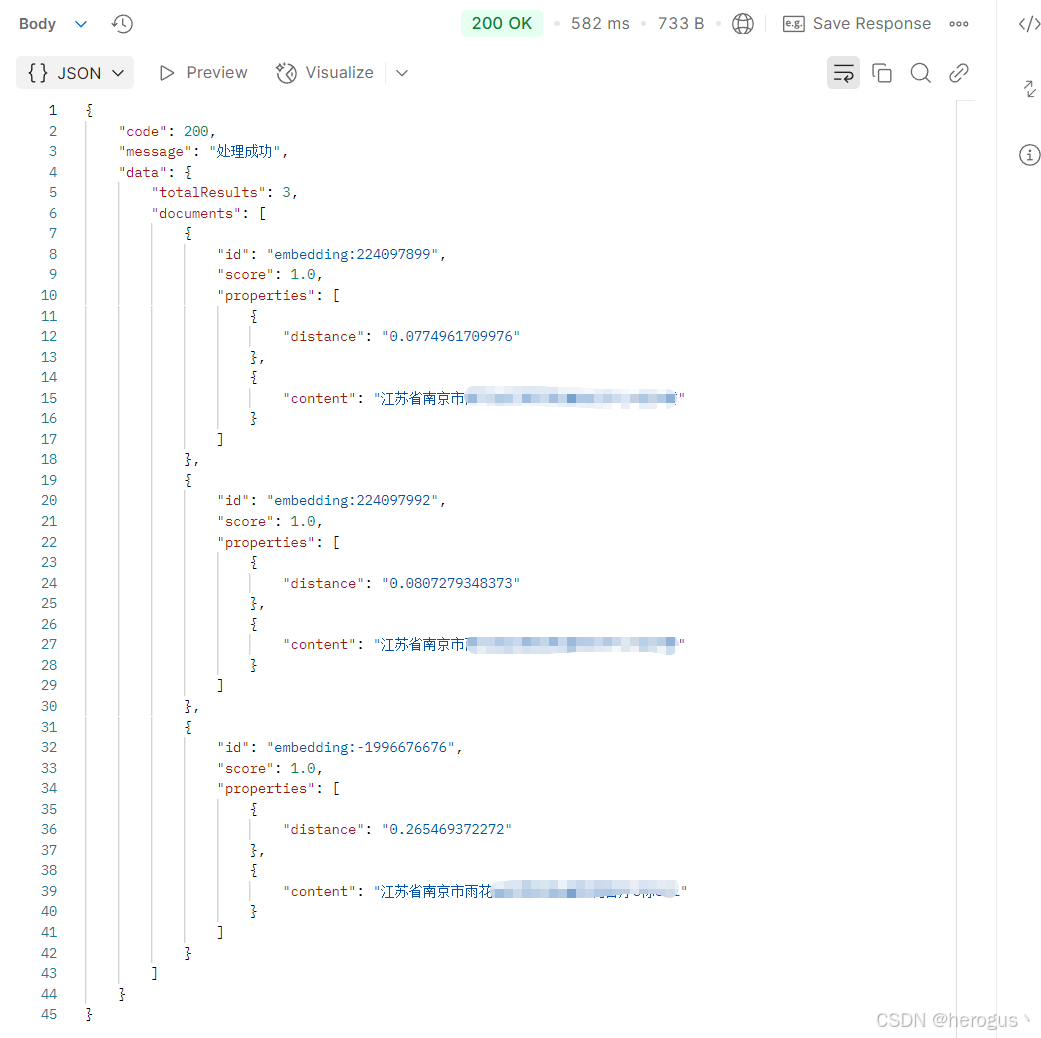
3.7 工具方法
3.7.1 float[] 转二进制
/*** float[] 转二进制** @param floats* @return*/
public static byte[] floatArrayToByteArray(float[] floats) {byte[] bytes = new byte[Float.BYTES * floats.length];ByteBuffer.wrap(bytes).order(ByteOrder.LITTLE_ENDIAN).asFloatBuffer().put(floats);return bytes;
}4 SpringAI VectorStore 实现
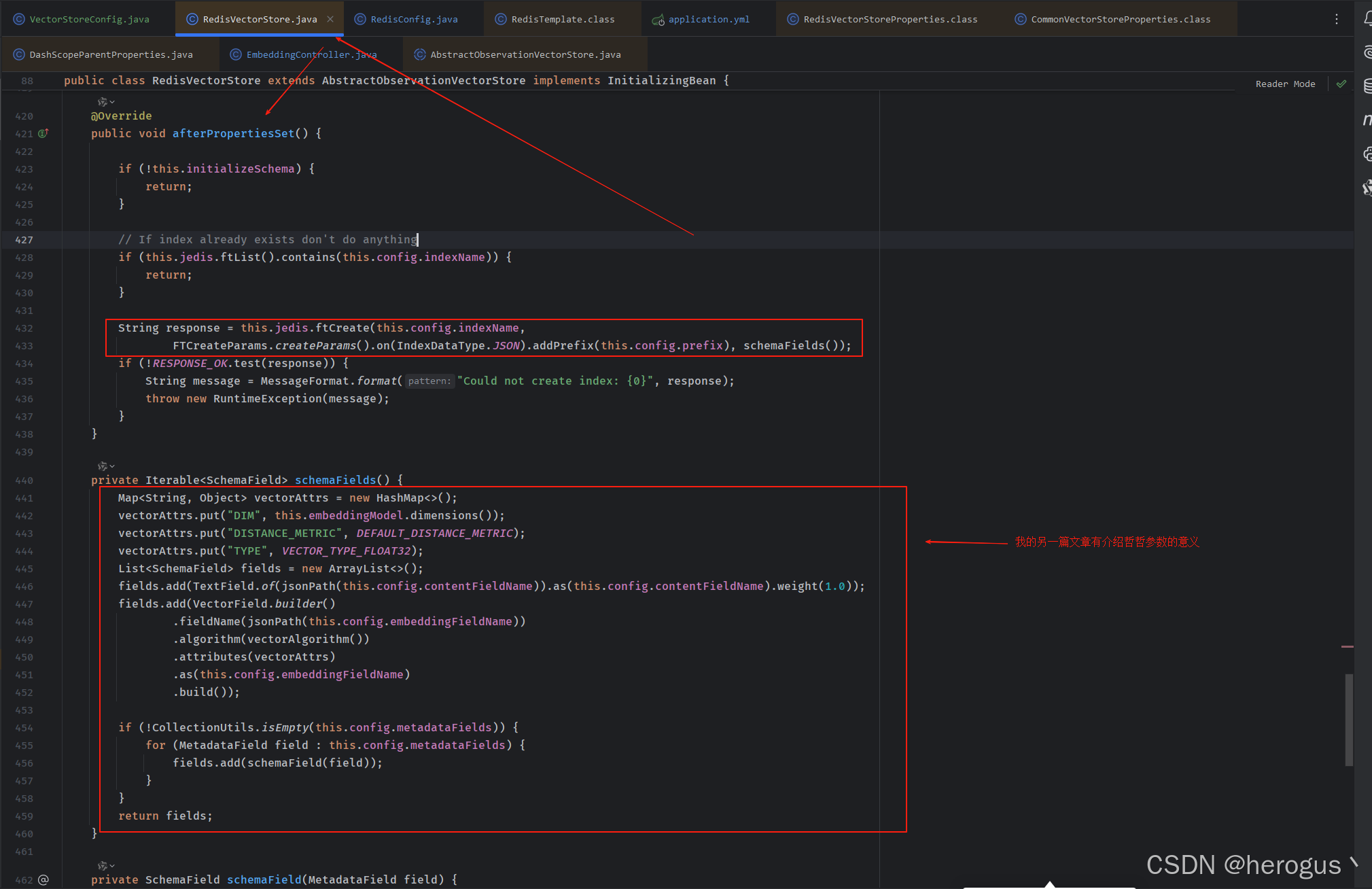
4.1 引入依赖
4.1.1 引入 Spring AI Alibaba
<dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter</artifactId>
</dependency>4.1.2 引入 Spring Ai Redis Store
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-redis-store-spring-boot-starter</artifactId>
</dependency>4.2 添加配置
4.2.1 添加 Spring Ai Alibaba 配置
spring:ai:dashscope:# 阿里百炼平台申请的 api_key -->api-key: your api_keychat:client:enabled: true4.2.2 添加 Spring AI Redis Store 配置
spring:data:redis:# uri 为 spring ai 中使用 redis 作为 Vector Store 的配置uri: redis://:gusy1234@127.0.0.1:6379/0ai:# 这里我多包了一层 mine ,因为如果多加一层,spring 会自动装配mine:# redis 作为向量库的配置 vectorstore:redis:# 是否初始化索引信息initialize-schema: true# 索引名称,默认 spring-ai-indexindex-name: spring-ai-index# 向量字段 key 的前缀,默认 embedding:prefix: 'embedding-ai:'# 文档批处理计算嵌入的策略。选项为 TOKEN_COUNT 或 FIXED_SIZEbatching-strategy: TOKEN_COUNT4.3 配置 JedisPooled 连接池
4.4 配置 VectorSotre
@Resourceprivate DashScopeEmbeddingModel dashScopeEmbeddingModel;@Resourceprivate JedisPooled jedisPooled;@Bean("vectorStoreWithDashScope")public VectorStore vectorStore() {return new RedisVectorStore(RedisVectorStore.RedisVectorStoreConfig.builder().withIndexName(indexName).withPrefix(prefix)
// .withEmbeddingFieldName("embedding") // 向量字段名,默认 embedding
// .withContentFieldName("content") // 文本字段名,默认 content.build(), embeddingModel, jedisPooled, initializeSchema); // initializeSchema 为是否初始化索引配置信息}4.5 向量数据入库
4.5.1 主要代码
@Autowired
@Qualifier("vectorStoreWithDashScope")
private VectorStore vectorStore;// 向量入库主要代码
List<String> inputInfos = List.of("文本1","文本2");
List<Document> documentList = new ArrayList<>();
inputInfos.forEach(text -> {documentList.add(new Document(text));
});
vectorStore.add(documentList);4.5.2 存储数据展示
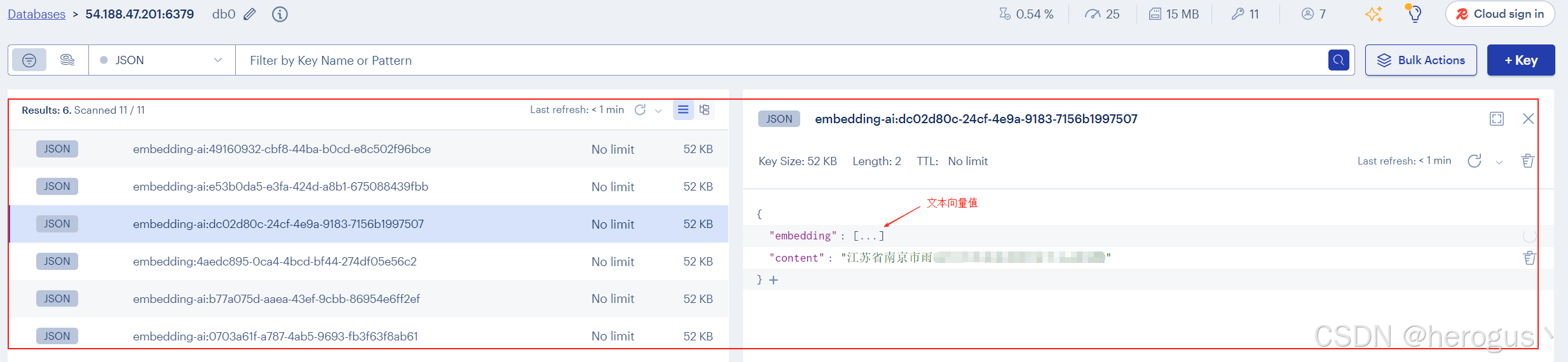
4.6 查询相似度
4.6.1 主要代码
// 相似度查询主要代码
List<Document> result = vectorStore.similaritySearch(org.springframework.ai.vectorstore.SearchRequest.defaults().withQuery(inputInfos.get(0)) // 查询的内容.withTopK(3)// 一个值从 0 到 1 的双精度数,接近1的值表示更高的相似性。默认为为0.75。.withSimilarityThreshold(0.6)
);4.6.2 查询结果展示
5. 参考文档
- Java 中使用 Jedis 客户端库执行向量搜索
- Spring AI Redis Vector Database 文档
- Spring AI Alibaba 向量存储文档
-
Jedis 官方教程
相关文章:
【LLM】RedisSearch 向量相似性搜索在 SpringBoot 中的实现
整理不易,请不要吝啬你的赞和收藏。 1. 前言 写这篇文章挺不容易的,网络上对于 SpringBoot 实现 Redis 向量相似性搜索的文章总体来说篇幅较少,并且这些文章很多都写得很粗糙,或者不是我想要的实现方式,所以我不得不阅…...
如何为64位LabVIEW配置正确的驱动程序
在安装 64位 LabVIEW 后,确保驱动程序正确配置是关键。如果您首先安装了 32位 LabVIEW 和相关驱动,然后安装了 64位 LabVIEW,需要确保为 64位 LabVIEW 安装和配置适当的驱动程序,才能正常访问硬件设备。以下是详细步骤:…...

Redis(5,jedis和spring)
在前面的学习中,只是学习了各种redis的操作,都是在redis命令行客户端操作的,手动执行的,更多的时候就是使用redis的api(),进一步操作redis程序。 在java中实现的redis客户端有很多,…...

Git 小白入门教程
🎯 这篇文章详细介绍了版本控制的重要性,特别是通过Git实现的分布式版本控制相对于SVN集中式控制的优势。文章首先解释了版本控制的基本概念,强调了在文档或项目多版本迭代中备份与恢复任意版本的能力。接着,重点阐述了Git的历史背…...
:神经网络与迁移学习在猫狗分类中的应用)
Python从0到100(八十五):神经网络与迁移学习在猫狗分类中的应用
在人工智能的浩瀚宇宙中,深度学习犹如一颗璀璨的星辰,引领着机器学习和计算机视觉领域的前沿探索。而神经网络,作为深度学习的核心架构,更是以其强大的数据建模能力,成为解决复杂问题的重要工具。今天,我们…...
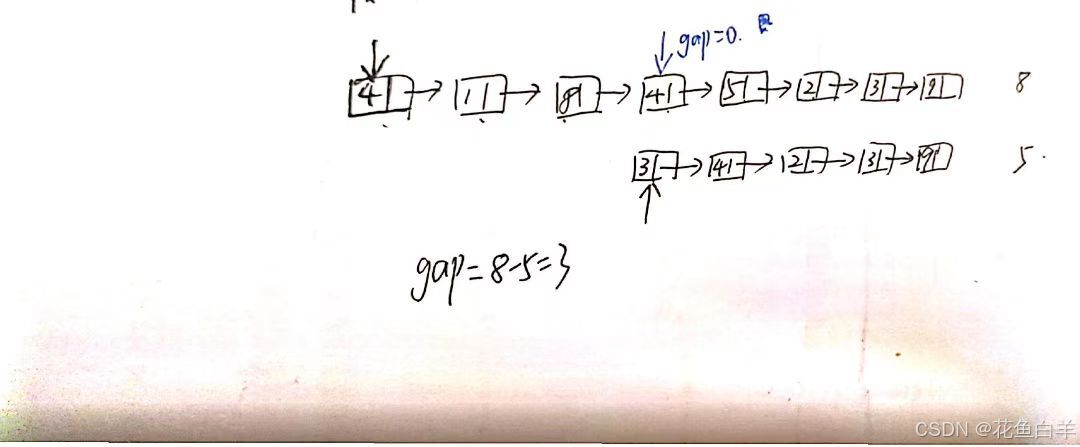
代码随想录刷题day14(2)|(链表篇)02.07. 链表相交(疑点)
目录 一、链表理论基础 二、链表相交求解思路 三、相关算法题目 四、疑点 一、链表理论基础 代码随想录 二、链表相交求解思路 链表相交时,是结点的位置,也就是指针相同,不是结点的数值相同; 思路:定义两个指针…...
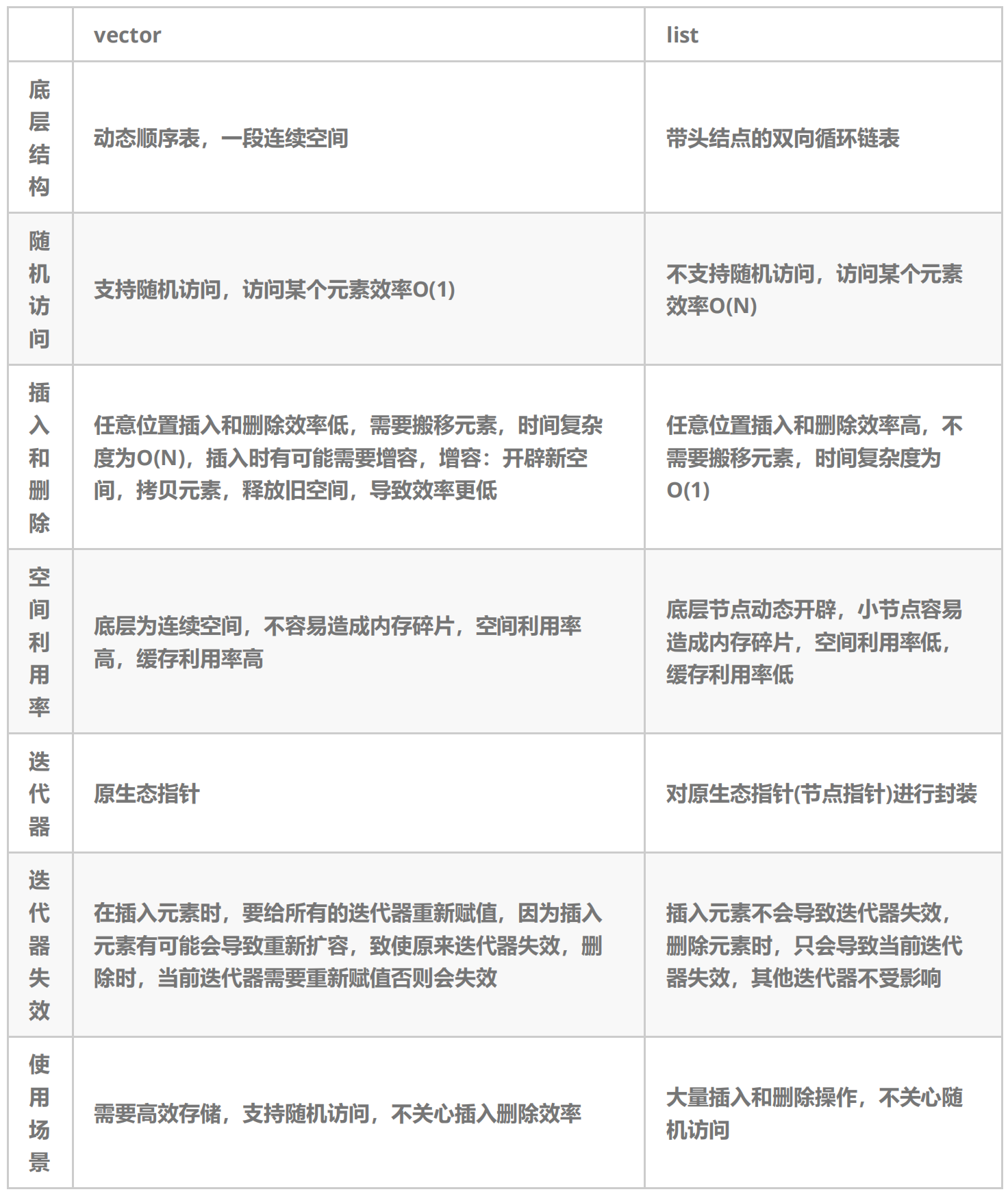
C++ 复习总结记录九
C 复习总结记录九 主要内容 1、list 介绍及使用 2、list 剖析及模拟实现 3、list 与 vector 对比 一 list 介绍及使用 List 相关文档 1、List 在任意位置进行插入和删除的序列式容器 O(1) ,且该容器可前后双向迭代 2、List 底层是带头双向循环链表ÿ…...
_SQL执行计划02_yxy)
数据库性能优化(sql优化)_SQL执行计划02_yxy
数据库性能优化_SQL执行计划详解02 常用操作符解读1.1 表扫描类型操作符1.1.1 CSCN 聚集索引扫描1.1.2 CSEK 聚集索引数据定位1.1.3 SSEK 二级索引数据定位1.1.4 SSCN 直接使用二级索引进行扫描1.2 其他常见操作符1.2.1 BLKUP 二次扫描1.2.2 SLCT 选择1.2.3 PRJT 投影1.2.4 NSE…...
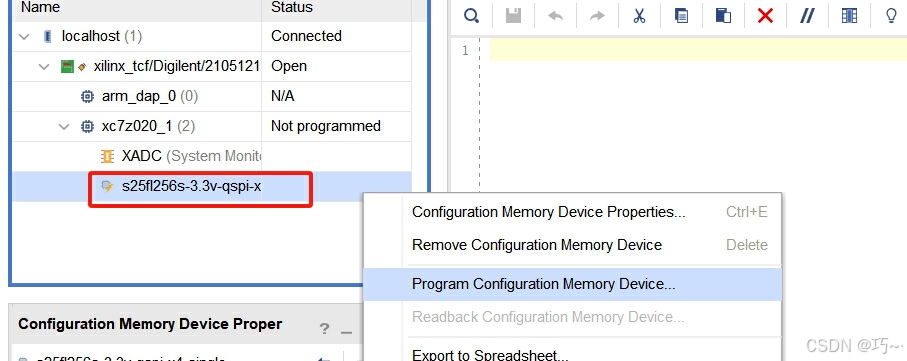
Vivado生成X1或X4位宽mcs文件并固化到flash
1.生成mcs文件 01.在vivado里的菜单栏选择"tools"工具栏 02.在"tools"里选择"生成内存配置文件" 03.配置参数 按照FPGA板上的flash型号进行选型,相关配置步骤可参考下图。 注意:Flash数据传输位宽如果需要选择X4位宽&am…...

在K8S中使用Values文件定制不同环境下的应用配置详解
在Kubernetes(简称K8s)环境中,应用程序的配置管理是一项关键任务。为了确保应用程序在不同环境(如开发、测试、预发布和生产)中都能稳定运行,我们需要为每个环境定制相应的配置。Values文件是在使用Helm管理…...

边缘网关具备哪些功能?
边缘网关,又称边缘计算网关,部署在网络边缘,它位于物联网设备与云计算平台之间,充当着数据流动的“守门员”和“处理器”。通过其强大的数据处理能力和多样化的通信协议支持,边缘网关能够实时分析、过滤和存储来自终端…...

ThinkPHP 8 操作JSON数据
【图书介绍】《ThinkPHP 8高效构建Web应用》-CSDN博客 《2025新书 ThinkPHP 8高效构建Web应用 编程与应用开发丛书 夏磊 清华大学出版社教材书籍 9787302678236 ThinkPHP 8高效构建Web应用》【摘要 书评 试读】- 京东图书 使用VS Code开发ThinkPHP项目-CSDN博客 编程与应用开…...
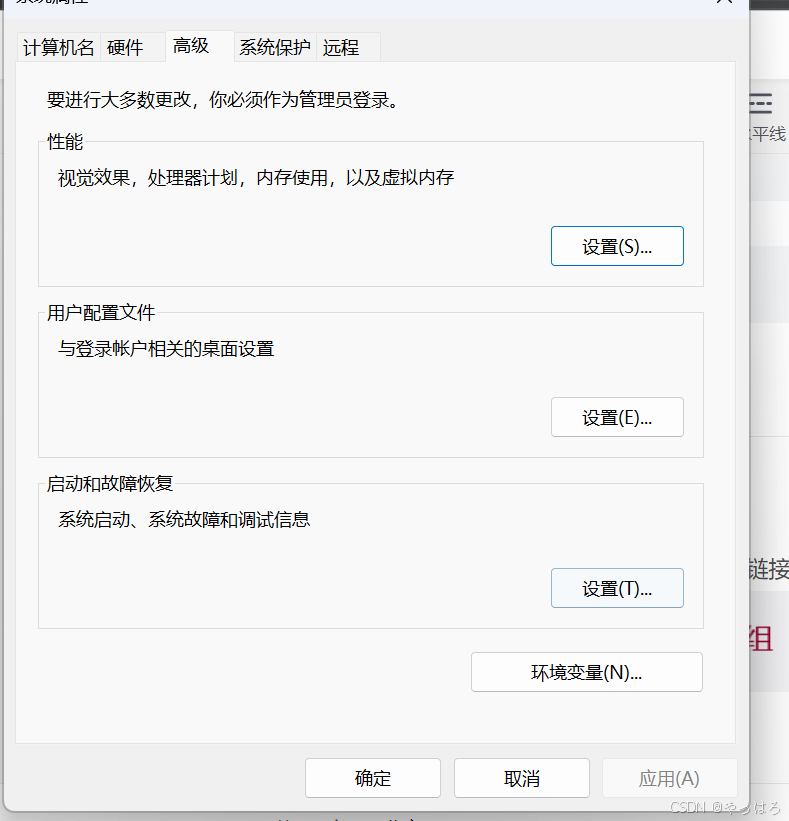
环境变量配置与问题解决
目录 方法 配置了还是运行不了想要的东西 解决方案 为什么 解决方案 方法 方法一:此电脑右击-属性-相关链接-高级系统设置-环境变量(N)-系统变量里面找到Path-三个确定】 方法二:winr cmd 黑框输入sysdm.cpl,后面…...

pytorch2.5实例教程
以下是再次为你提供的一个详细的PyTorch使用教程: 一、安装PyTorch 环境准备 确保系统已安装合适版本的Python(推荐3.10及以上)。 安装方式 CPU版本 对于Linux和macOS: 使用命令 pip install torch torchvision torchaudio。 对…...
【开源免费】基于SpringBoot+Vue.JS智慧图书管理系统(JAVA毕业设计)
本文项目编号 T 152 ,文末自助获取源码 \color{red}{T152,文末自助获取源码} T152,文末自助获取源码 目录 一、系统介绍二、数据库设计三、配套教程3.1 启动教程3.2 讲解视频3.3 二次开发教程 四、功能截图五、文案资料5.1 选题背景5.2 国内…...

基于自然语言处理的垃圾短信识别系统
基于自然语言处理的垃圾短信识别系统 🌟 嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 目录 设计题目设计目的设计任务描述设计要求输入和输出…...

Node.js HTTP模块详解:创建服务器、响应请求与客户端请求
Node.js HTTP模块详解:创建服务器、响应请求与客户端请求 Node.js 的 http 模块是 Node.js 核心模块之一,它允许你创建 HTTP 服务器和客户端。以下是一些关键知识点和代码示例: 1. 创建 HTTP 服务器 使用 http.createServer() 方法可以创建…...
Day 17 卡玛笔记
这是基于代码随想录的每日打卡 654. 最大二叉树 给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建: 创建一个根节点,其值为 nums 中的最大值。递归地在最大值 左边 的 子数组前缀上 构建左子树。递归地在最大值 右边 的 子数组…...
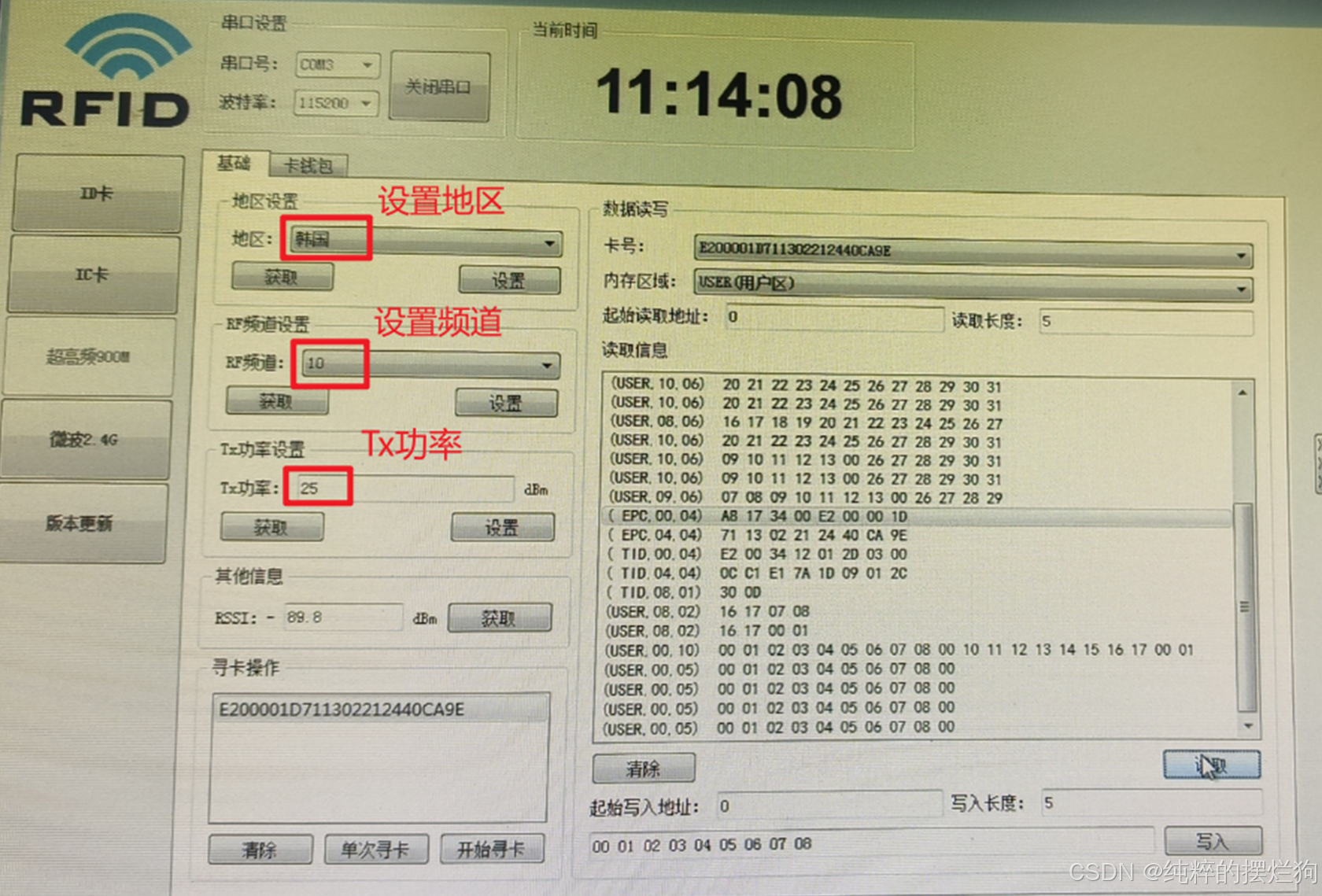
深圳大学-智能网络与计算-实验一:RFID原理与读写操作
实验目的与要求 掌握超高频RFID标签的寻卡操作。掌握超高频RFID标签的读写操作。掌握超高频RFID标签多张卡读取时的防冲突机制。 方法,步骤 软硬件的连接与设置超高频RFID寻卡操作超高频RFID防冲突机制超高频RFID读写卡操作 实验过程及内容 一.软硬…...
⚡C++ 中 std::transform 函数深度解析:解锁容器元素转换的奥秘⚡【AI 润色】
在 C 编程的世界里,我们常常需要对容器中的元素进行各种转换操作。无论是将数据进行格式调整,还是对元素进行数学运算,高效的转换方法都是提升代码质量和效率的关键。std::transform函数作为 C 标准库<algorithm &g…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...

sudo企业级应用【20260525】001篇
文章目录 一、总体设计思路 1️⃣ 设计原则 2️⃣ 日志策略(重点) 二、10 个真实生产场景(含 sudoers 配置) 🔹 Linux 系统管理(3 个) ✅ 场景 1:基础运维(用户 / 权限) ✅ 场景 2:磁盘与文件系统 ✅ 场景 3:网络与防火墙 🔹 云管理(2 个) ✅ 场景 4:云 CLI …...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

基于LSTM自编码器的家用电器功耗异常检测系统构建指南
1. 项目概述:从能耗洞察到智能干预我们每天都在和各种家用电器打交道,从清晨唤醒你的咖啡机,到深夜还在默默工作的路由器。你有没有想过,这些看似微不足道的设备,其背后隐藏的能耗模式,其实大有文章&#x…...
)
嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(3)
接前一篇文章:嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(2) 节点查找 API:如何在设备树中定位目标节点 有了数据结构基础,现在我们可以开始讲具体的API了。第一步是找到你要操作的节点。就像你想操…...

3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界
3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI SMAPI(Stardew Valley Modding API)是星露谷物语官…...
)
告别Appium!用Python+UIAutomator2搞定Android自动化测试(附完整环境搭建与实战代码)
PythonUIAutomator2:Android自动化测试的高效实践指南 在移动应用测试领域,效率与稳定性始终是工程师们追求的核心目标。传统方案如Appium虽然功能全面,但在执行速度和资源消耗方面往往难以满足高频测试需求。本文将带您探索基于Python和UIA…...