PostgreSQL模糊查询相关学习参考
PostgreSQL大数据量快速模糊检索实践_postgresql 模糊查询-CSDN博客文章浏览阅读1.5k次,点赞20次,收藏25次。注意: 本文内容于 2024-08-18 23:50:33 创建,可能不会在此平台上进行更新。。_postgresql 模糊查询https://blog.csdn.net/qq_30460361/article/details/141371128https://blog.csdn.net/qq_30460361/article/details/141371128https://blog.csdn.net/qq_30460361/article/details/141371128![]() https://blog.csdn.net/qq_30460361/article/details/141371128在 PostGIS 中进行千万级空间数据的空间查询和关键字查询_postgis空间查询-CSDN博客文章浏览阅读1k次,点赞12次,收藏21次。在给定的计算机配置下,通过合理的表结构设计、字符串处理、索引创建以及查询策略,可以较为高效地对千万级空间数据进行空间查询和关键字查询。创建表、更新字符串和创建索引的过程相对耗时较长,但一旦索引创建完成,实际查询操作非常迅速。同时,也验证了 PostGIS 在处理复杂空间查询和关键字查询方面的强大能力。本测试在探究在有限的计算机配置下,如何高效地对千万级的空间数据进行空间查询和关键字查询。通过实际操作和测试,评估不同查询策略的性能,为处理大规模空间数据提供可行的解决方案。_postgis空间查询https://blog.csdn.net/eqmaster/article/details/142382839https://blog.csdn.net/eqmaster/article/details/142382839https://blog.csdn.net/eqmaster/article/details/142382839
https://blog.csdn.net/qq_30460361/article/details/141371128在 PostGIS 中进行千万级空间数据的空间查询和关键字查询_postgis空间查询-CSDN博客文章浏览阅读1k次,点赞12次,收藏21次。在给定的计算机配置下,通过合理的表结构设计、字符串处理、索引创建以及查询策略,可以较为高效地对千万级空间数据进行空间查询和关键字查询。创建表、更新字符串和创建索引的过程相对耗时较长,但一旦索引创建完成,实际查询操作非常迅速。同时,也验证了 PostGIS 在处理复杂空间查询和关键字查询方面的强大能力。本测试在探究在有限的计算机配置下,如何高效地对千万级的空间数据进行空间查询和关键字查询。通过实际操作和测试,评估不同查询策略的性能,为处理大规模空间数据提供可行的解决方案。_postgis空间查询https://blog.csdn.net/eqmaster/article/details/142382839https://blog.csdn.net/eqmaster/article/details/142382839https://blog.csdn.net/eqmaster/article/details/142382839![]() https://blog.csdn.net/eqmaster/article/details/142382839利用pg_trgm的gist和gin索引加速字符匹配查询_gin索引 前缀匹配-CSDN博客文章浏览阅读5k次。pg_trgm是用来做相似度匹配的,在一些情况下也可以拿来代替全文检索做字符匹配。从大量数据中通过字符串的匹配查找数据的关键是索引,对字符串的精确相等匹配,前缀匹配(like 'x%')和后缀匹配(like '%x')可以使用btree索引,对中缀匹配(like '%x%')和正则表达式匹配就可以用pg_trgm的索引了。下面用一个例子说明一下。1.环境CentOS 6.5_gin索引 前缀匹配https://blog.csdn.net/rudygao/article/details/49247605https://blog.csdn.net/rudygao/article/details/49247605https://blog.csdn.net/rudygao/article/details/49247605
https://blog.csdn.net/eqmaster/article/details/142382839利用pg_trgm的gist和gin索引加速字符匹配查询_gin索引 前缀匹配-CSDN博客文章浏览阅读5k次。pg_trgm是用来做相似度匹配的,在一些情况下也可以拿来代替全文检索做字符匹配。从大量数据中通过字符串的匹配查找数据的关键是索引,对字符串的精确相等匹配,前缀匹配(like 'x%')和后缀匹配(like '%x')可以使用btree索引,对中缀匹配(like '%x%')和正则表达式匹配就可以用pg_trgm的索引了。下面用一个例子说明一下。1.环境CentOS 6.5_gin索引 前缀匹配https://blog.csdn.net/rudygao/article/details/49247605https://blog.csdn.net/rudygao/article/details/49247605https://blog.csdn.net/rudygao/article/details/49247605![]() https://blog.csdn.net/rudygao/article/details/49247605PostgreSQL(二) 索引介绍 索引扫描方式(gin索引 pg_trgm模糊查询索引原理)_gin索引扫描-CSDN博客文章浏览阅读3.3k次,点赞2次,收藏18次。1.索引的意义1.1索引的优点创建索引能够加快对表的查询,排序,以及唯一约束的作用。索引能够提供给优化器更好的值分布统计信息。1.2索引的缺点创建索引会增加数据库的存储空间,在计算数据库的容量大小时需要计算表和索引的总空间大小。在创建完索引之后的表,执行插入、更新和删除操作时,索引需要更新,故耗时会成倍增加。2.索引管理2.1创建索引创建索引时,不能包括schema模式名,因为索引默认被创建在其基表所在的模式中,创..._gin索引扫描https://blog.csdn.net/qq_35260875/article/details/106084392https://blog.csdn.net/qq_35260875/article/details/106084392https://blog.csdn.net/qq_35260875/article/details/106084392
https://blog.csdn.net/rudygao/article/details/49247605PostgreSQL(二) 索引介绍 索引扫描方式(gin索引 pg_trgm模糊查询索引原理)_gin索引扫描-CSDN博客文章浏览阅读3.3k次,点赞2次,收藏18次。1.索引的意义1.1索引的优点创建索引能够加快对表的查询,排序,以及唯一约束的作用。索引能够提供给优化器更好的值分布统计信息。1.2索引的缺点创建索引会增加数据库的存储空间,在计算数据库的容量大小时需要计算表和索引的总空间大小。在创建完索引之后的表,执行插入、更新和删除操作时,索引需要更新,故耗时会成倍增加。2.索引管理2.1创建索引创建索引时,不能包括schema模式名,因为索引默认被创建在其基表所在的模式中,创..._gin索引扫描https://blog.csdn.net/qq_35260875/article/details/106084392https://blog.csdn.net/qq_35260875/article/details/106084392https://blog.csdn.net/qq_35260875/article/details/106084392![]() https://blog.csdn.net/qq_35260875/article/details/106084392PostgreSQL pg_trgm扩展安装 模糊查询 使用原理_postgresql15模糊查询扩展包-CSDN博客文章浏览阅读7.2k次,点赞2次,收藏15次。1.pg_trgm安装(1)安装btree_gin和pg_trgm# 需要先进入pg源码包中su - postgrescd contrib/pg_trgm/make && make install安装pg_trgm扩展时需要安装btree_gin才可以使用cd contrib/btree_gin/make && make install(2)创建扩展 安装的扩展默认都是在pg_catalog这个schema下面。也..._postgresql15模糊查询扩展包https://blog.csdn.net/qq_35260875/article/details/106148664https://blog.csdn.net/qq_35260875/article/details/106148664https://blog.csdn.net/qq_35260875/article/details/106148664
https://blog.csdn.net/qq_35260875/article/details/106084392PostgreSQL pg_trgm扩展安装 模糊查询 使用原理_postgresql15模糊查询扩展包-CSDN博客文章浏览阅读7.2k次,点赞2次,收藏15次。1.pg_trgm安装(1)安装btree_gin和pg_trgm# 需要先进入pg源码包中su - postgrescd contrib/pg_trgm/make && make install安装pg_trgm扩展时需要安装btree_gin才可以使用cd contrib/btree_gin/make && make install(2)创建扩展 安装的扩展默认都是在pg_catalog这个schema下面。也..._postgresql15模糊查询扩展包https://blog.csdn.net/qq_35260875/article/details/106148664https://blog.csdn.net/qq_35260875/article/details/106148664https://blog.csdn.net/qq_35260875/article/details/106148664![]() https://blog.csdn.net/qq_35260875/article/details/106148664postgresql系列之并行查询_postgresql 关闭并行执行-CSDN博客文章浏览阅读6.5k次,点赞2次,收藏14次。本文是《postgresql实战》的读书笔记,感兴趣可以参考该书对应章节一、并行查询postgresql在9.6开始支持并行查询,但支持的范围非常有限,在postgresql10得到进一步了增强。1.1 并行查询相关参数参数描述max_work_processer(integer)设置系统支持的最大后台进程,默认值为8,此参数调整后需要重启数据库才生效max_p..._postgresql 关闭并行执行https://blog.csdn.net/qq_31156277/article/details/84261112https://blog.csdn.net/qq_31156277/article/details/84261112https://blog.csdn.net/qq_31156277/article/details/84261112
https://blog.csdn.net/qq_35260875/article/details/106148664postgresql系列之并行查询_postgresql 关闭并行执行-CSDN博客文章浏览阅读6.5k次,点赞2次,收藏14次。本文是《postgresql实战》的读书笔记,感兴趣可以参考该书对应章节一、并行查询postgresql在9.6开始支持并行查询,但支持的范围非常有限,在postgresql10得到进一步了增强。1.1 并行查询相关参数参数描述max_work_processer(integer)设置系统支持的最大后台进程,默认值为8,此参数调整后需要重启数据库才生效max_p..._postgresql 关闭并行执行https://blog.csdn.net/qq_31156277/article/details/84261112https://blog.csdn.net/qq_31156277/article/details/84261112https://blog.csdn.net/qq_31156277/article/details/84261112![]() https://blog.csdn.net/qq_31156277/article/details/84261112
https://blog.csdn.net/qq_31156277/article/details/84261112
高级模糊查询的实现 | Pigsty如何在PostgreSQL中实现比较复杂的模糊查询逻辑?https://pigsty.cc/zh/blog/dev/fuzzymatch/#%E9%AB%98%E7%BA%A7%E6%A8%A1%E7%B3%8A%E6%9F%A5%E8%AF%A2https://pigsty.cc/zh/blog/dev/fuzzymatch/#%E9%AB%98%E7%BA%A7%E6%A8%A1%E7%B3%8A%E6%9F%A5%E8%AF%A2![]() https://pigsty.cc/zh/blog/dev/fuzzymatch/#%E9%AB%98%E7%BA%A7%E6%A8%A1%E7%B3%8A%E6%9F%A5%E8%AF%A2中文模糊查询性能优化 by PostgreSQL trgm - Digoal.Zhou’s Blog背景前模糊,后模糊,前后模糊,正则匹配都属于文本搜索领域常见的需求。PostgreSQL在文本搜索领域除了全文检索,还有trgm是一般数据库没有的,可能很多人没有听说过。对于前模糊和后模糊,PG则与其他数据库一样,可以使用btree来加速。后模糊可以使用反转函数的函数索引来加速。对于前后模糊和正则匹配,则可以使用trgm,TRGM是一个非常强的插件,对这类文本搜索场景性能提升非常有效,100万左右的数据量,性能提升有500倍以上。ascii字符模糊查询\正则匹配的例子生成100万数据,测试模糊查询的性能create extension pg_trgm; postgres=# create table tbl (id int, info text); CREATE TABLE postgres=# insert into tbl select generate_series(1,1000000), md5(random()::text); INSERT 0 1000000 postgres=# create index idx_tbl_1 on tbl using gin(info gin_trgm_ops); CREATE INDEX postgres=# select * from tbl limit 10; id | info ----+---------------------------------- 1 | dc369f84738f7fa4dc38c364cef817d0 2 | 4912b0b16670c4f2390d44ae790b9809 3 | eb442b00bf3b5bc6863d004a2c8fa3bb 4 | 0b4b8a8ad0cdf2e6870afbb94813eba4 5 | 661e895ee982ec4d9f944b10adffb897 6 | 09c4e7476d4bdfc1ccbdfe92ba0fdbdf 7 | 8b6e442faed938d066dda5e552100277 8 | e5cdeca599d5068a8d3bb6ce9f370827 9 | ddbbfbeaa9199219b7c909fb395d9a69 10 | 96f254f64df1ec43bb0cb4801222c919 (10 rows) postgres=# select * from tbl where info ~ '670c4f2'; id | info ----+---------------------------------- 2 | 4912b0b16670c4f2390d44ae790b9809 (1 row) Time: 2.668 ms postgres=# explain analyze select * from tbl where info ~ '670c4f2'; QUERY PLAN --------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on tbl (cost=28.27..138.43 rows=100 width=37) (actual time=1.957..1.958 rows=1 loops=1) Recheck Cond: (info ~ '670c4f2'::text) Heap Blocks: exact=1 -> Bitmap Index Scan on idx_tbl_1 (cost=0.00..28.25 rows=100 width=0) (actual time=1.939..1.939 rows=1 loops=1) Index Cond: (info ~ '670c4f2'::text) Planning time: 0.342 ms Execution time: 1.989 ms (7 rows) 不使用TRGM优化的情况下,需要1657毫秒.postgres=# set enable_bitmapscan=off; SET Time: 0.272 ms postgres=# select * from tbl where info ~ 'e770044a'; id | info ----+---------------------------------- 6 | 776c3cdf5fa818a324ef3e770044a488 (1 row) Time: 1657.231 ms 对于ascii字符,使用pg_trgm后性能提升非常明显。一、中文支持( 适用于小于9.3的版本 )PostgreSQL 9.3开始,pg_trgm支持wchar,如果你用的是9.3以前的版本,那么需要转换一下,把文本转换为bytea即可。转换为bytea前,效率是不高的,如下。postgres=# explain analyze select * from tbl where info ~ '中国'; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------ Bitmap Heap Scan on tbl (cost=149.62..151.82 rows=2 width=37) (actual time=8.624..8.624 rows=0 loops=1) Recheck Cond: (info ~ '中国'::text) Rows Removed by Index Recheck: 10103 Heap Blocks: exact=156 -> Bitmap Index Scan on idx_tbl_1 (cost=0.00..149.61 rows=2 width=0) (actual time=1.167..1.167 rows=10103 loops=1) Index Cond: (info ~ '中国'::text) Planning time: 0.244 ms Execution time: 8.657 ms (8 rows) Time: 9.388 ms 从执行计划来分析,中文虽然走索引,但是它是没有正确的使用token的,所以都放到recheck了。还不如全表扫描postgres=# set enable_bitmapscan=off; SET postgres=# explain analyze select * from tbl where info ~ '中国'; QUERY PLAN ------------------------------------------------------------------------------------------------ Seq Scan on tbl (cost=0.00..399.75 rows=2 width=37) (actual time=6.899..6.899 rows=0 loops=1) Filter: (info ~ '中国'::text) Rows Removed by Filter: 10103 Planning time: 0.213 ms Execution time: 6.921 ms (5 rows) Time: 7.593 ms 中文bytea化,支持pg_trgm索引你可以用PostgreSQL的函数索引和bytea化(转换成ascii码)来实现这块的功能例如postgres=# select text(textsend(info)) from tbl limit 10; text ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- \xe7abbde69b8ce7b5a4e8b197e5afa9e58c88e991a6e7b18ce5b495e8a79fe7ae8ee882bce7a283e7af9de8a086e7ac8de59e81e5a6bae9bcb6e6ba9fe981bbe4bda8e7928de98ab0e5a18de697b5e79fabe9b0a5e9b0a5 \xe5aa8ee69ab5e58996e892b0e89484e587b0e8bcbce69f80e79eb8e89390e7baa8e79f93e582b6e98f81e9a18ee9b48ee9ba8ce784a6e8b5a2e5a797e9a3b5e5a4aee986b1e9919de6b19ce9bdb9e6bbb6e8b5bde8b5bd \xe7b4a4e5b2b3e7ac96e79481e78dbce5b28ae6b9b6e88dafe5aebce4bcbde8a3a3e4be98e78e93e5848ae4b888e5b0b5e5aeaee9aeb2e99982e59a98e6b0b2e583b3e9b799e893a5e5ba89e8949fe7868ee78cbde78cbd \xe797a3e4b991e8baaee9ae88e69db5e78c99e9a8abe9bd80e7bd98e8b3bae89cb5e799bbe78d89e990a7e5b989e6a484e6a1a1e6939ce9b490e890b4e9a5abe6b392e58a9be5adaae9b895e89985e8a79ee8b889e8b889 \xe687a4e9b795e58094e9b0a6e6a58ee4bd80e6898ae6bdbee7828de788bde79897e8be83e59b93e7908ae9879be7b093e89eaae6a3bce792bee59e9ae8b5abe7a89fe9b6aae99bbae9a18fe6b3abe7b7aae89282e89282 \xe996b8e5a4b7e6b2b7e8a397e6a898e58a94e6a4a5e586b3e9b8b5e5ba98e99ba4e99c90e6be90e88d94e99dade89892e594abe59d98e5a7afe592a0e58c9be59590e8a299e7bb86e9abace7a5bee881bde793a7e793a7 \xe795aee7bba4e4bc86e7b29ae780b2e7bd9fe8a9bee8bf97e68486e5a4bde8a79ee6bf8be98cb8e8b6bfe4bb8ae88ba3e8ba98e6acb8e6aa94e59ab5e697bfe78b96e6859be7afb9e9bb85e799a7e798a3e6a982e6a982 \xe98987e7828be585ace9808ce5959be6b4a0e582ade59fbfe7b18ee792b9e8bd87e8849ce89d98e4b8b4e7af9ce6abb3e98a8ce89490e897bde59ea7e8a5a8e98a94e7848be59abae5bb9be890b6e58188e6acb8e6acb8 \xe7898de88880e89abfe99dbfe5bab9e5b387e8b3a7e8a0bfe9a4a7e5aa9be6a18ee68ca7e9b2b2e58b8de6a088e6a4abe5a481e58297e4bb90e5b780e786b4e6958de58bb4e78884e9ae98e9909ae8b19be984a8e984a8 \xe6b4a8e8b99ee6b789e8bfb9e9b69de9b0a6e9b7bde59fbae6a886e793a1e691ace9a185e5bba1e699a5e9bcace78598e9adaee9b199e59eb5e897b6e88f92e69caee8b9ade8beade4bdbae5b3b6e599b9e7bea1e7bea1 (10 rows) Time: 0.457 ms 对bytea文本创建gin索引,需要创建一个immutable函数。请务必使用时保证创建索引、查询是客户端的编码一致,即查询与存储的编码一致才能命中结果哦。postgres=# create or replace function textsend_i (text) returns bytea as $$ select textsend($1); $$ language sql strict immutable; CREATE FUNCTION postgres=# drop index idx_tbl_1 ; DROP INDEX Time: 10.179 ms postgres=# create index idx_tbl_1 on tbl using gin(text(textsend_i(info)) gin_trgm_ops); CREATE INDEX 使用了bytea的gin索引后,性能提升非常明显,数据量越多,性能表现越好。postgres=# set enable_bitmapscan=on; postgres=# explain analyze select * from tbl where text(textsend_i(info)) ~ ltrim(text(textsend_i('中国')), '\x'); QUERY PLAN ---------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on tbl (cost=369.28..504.93 rows=100 width=37) (actual time=0.099..0.099 rows=0 loops=1) Recheck Cond: ((textsend_i(info))::text ~ 'e4b8ade59bbd'::text) -> Bitmap Index Scan on idx_tbl_1 (cost=0.00..369.25 rows=100 width=0) (actual time=0.097..0.097 rows=0 loops=1) Index Cond: ((textsend_i(info))::text ~ 'e4b8ade59bbd'::text) Planning time: 0.494 ms Execution time: 0.128 ms (6 rows) postgres=# select * from tbl limit 10; id | info ----+------------------------------------------------------------ 1 | 竽曌絤豗審匈鑦籌崕觟箎肼碃篝蠆笍垁妺鼶溟遻佨璍銰塍旵矫鰥鰥 2 | 媎暵剖蒰蔄凰輼柀瞸蓐纨矓傶鏁顎鴎麌焦赢姗飵央醱鑝汜齹滶赽赽 3 | 紤岳笖甁獼岊湶药宼伽裣侘玓儊丈尵宮鮲陂嚘氲僳鷙蓥庉蔟熎猽猽 4 | 痣乑躮鮈杵猙騫齀罘賺蜵登獉鐧幉椄桡擜鴐萴饫泒力孪鸕虅觞踉踉 5 | 懤鷕倔鰦楎佀扊潾炍爽瘗较囓琊釛簓螪棼璾垚赫稟鶪雺顏泫緪蒂蒂 6 | 閸夷沷裗樘劔椥决鸵庘雤霐澐荔靭蘒唫坘姯咠匛啐袙细髬祾聽瓧瓧 7 | 畮绤伆粚瀲罟詾迗愆夽觞濋錸趿今苣躘欸檔嚵旿狖慛篹黅癧瘣橂橂 8 | 鉇炋公逌啛洠傭埿籎璹轇脜蝘临篜櫳銌蔐藽垧襨銔焋嚺廛萶偈欸欸 9 | 牍舀蚿靿庹峇賧蠿餧媛桎挧鲲勍栈椫夁傗仐巀熴敍勴爄鮘鐚豛鄨鄨 10 | 洨蹞淉迹鶝鰦鷽基樆瓡摬顅廡晥鼬煘魮鱙垵藶菒朮蹭辭佺島噹羡羡 (10 rows) postgres=# explain analyze select * from tbl where text(textsend_i(info)) ~ ltrim(text(textsend_i('坘')), '\x'); QUERY PLAN ---------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on tbl (cost=149.88..574.79 rows=320 width=37) (actual time=0.063..0.063 rows=0 loops=1) Recheck Cond: ((textsend_i(info))::text ~ 'e59d98'::text) -> Bitmap Index Scan on idx_tbl_1 (cost=0.00..149.80 rows=320 width=0) (actual time=0.061..0.061 rows=0 loops=1) Index Cond: ((textsend_i(info))::text ~ 'e59d98'::text) Planning time: 0.303 ms Execution time: 0.087 ms (6 rows) postgres=# select * from tbl where text(textsend_i(info)) ~ ltrim(text(textsend_i('坘')), '\x'); id | info ------+------------------------------------------------------------ 6 | 閸夷沷裗樘劔椥决鸵庘雤霐澐荔靭蘒唫坘姯咠匛啐袙细髬祾聽瓧瓧 432 | 飒莭鮊鍥?笩妳琈笈慻儘轴轧坘碠郎蚿呙偓鍹脆鼺蹔谕蚱畨縫鱳鱳 934 | 咓僨復圼峷奁扉羰滵樞韴迬猰優鰸獤溅躐瓜抵権纀懶粯坘蚲纾鴁鴁 3135 | 倣稽蛯巭瘄皮蓈睫柨苧眱賴髄猍乱歖痐坘恋顎东趥谓鰪棩剔烱茟茟 3969 | 崴坘螏顓碴鵰邰欴苄蛨簰瘰膪菷栱镘衟齘觊诀忮繈憘痴峣撋梆澝澝 4688 | 围豁啖顫诬呅尥腥缾郸熛枵焐篯坘僇矟銘隨譼鎶舰肳礞婛轲蠟慕慕 6121 | 窳研稼旅唣疚褣鬾韨赑躽坘浒攁舑遬鳴滴抓嗠捒铗牜欘質丛姤騖騖 6904 | 飘稘輔鬄枠舶婬儁噈坘裎姖爙炃苖隽斓堯鈶摙蚼疁兗快鐕鎒墩譭譭 8854 | 叒鐲唬鞩泍糕懜坘戚靥鎿鋂炿尟汜阢甌鲖埁顔胳邉謾宱肦劰責戆戆 9104 | 鵬篱爯俌坘柉誵孀漴纞錀澁摫螭芄餜爹綅俆逨哒猈珢輿廄陲欗缷缷 9404 | 民坘謤齏隽紽峐荟頩胯頴傳蠂枯滦榦陠帡疃鈶遽艌瘧蒭嗍龞瓈嚍嚍 9727 | 夃坘慫逹壪泵偉鸶揺雠倴矸虠覾芽齏遬儂錞鐴焑劽疁擯蛛倞瑫菰菰 (12 rows) 二、中文支持( 适用于大于等于9.3的版本 )pg_trgm支持中文的前提条件:数据库的collate和ctype都不能为C。例如这些数据库,Collate, Ctype = C的,pg_trgm都不支持wchar(含中文)。postgres=# \l+ List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description --------------------+----------+-----------+------------+------------+-----------------------+---------+------------+-------------------------------------------- contrib_regression | postgres | UTF8 | C | C | | 9313 kB | pg_default | db | postgres | SQL_ASCII | C | C | | 7359 kB | pg_default | db1 | postgres | EUC_CN | C | C | | 7351 kB | pg_default | postgres | postgres | UTF8 | C | C | | 1686 MB | pg_default | default administrative connection database template0 | postgres | UTF8 | C | C | =c/postgres +| 7225 kB | pg_default | unmodifiable empty database | | | | | postgres=CTc/postgres | | | template1 | postgres | UTF8 | C | C | =c/postgres +| 7225 kB | pg_default | default template for new databases | | | | | postgres=CTc/postgres | | | test | postgres | UTF8 | en_US.UTF8 | en_US.UTF8 | | 7415 kB | pg_default | test01 | postgres | UTF8 | C | C | | 1621 MB | pg_default | (8 rows) 例子1,不支持wchar的情况(collate,ctype=C)postgres=# \c db1 You are now connected to database "db1" as user "postgres". db1=# create extension pg_trgm; CREATE EXTENSION db1=# select show_trgm('你好'); show_trgm ----------- {} (1 row) 例子2,支持wchar的情况(collate,ctype<>C)db1=# \c test You are now connected to database "test" as user "postgres". test=# select show_trgm('你好'); show_trgm ------------------------- {0xcf7970,0xf98da8,IgR} (1 row) 创建数据库时,指定Collate, Ctype,例子。postgres=# create database test02 with template template0 lc_collate "zh_CN.UTF8" lc_ctype "zh_CN.UTF8" encoding 'UTF8'; CREATE DATABASE postgres=# \l+ test02 List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description --------+----------+----------+------------+------------+-------------------+---------+------------+------------- test02 | postgres | UTF8 | zh_CN.UTF8 | zh_CN.UTF8 | | 7225 kB | pg_default | (1 row) 中文模糊查询加速前面讲了,数据库前提(collate,ctype<>C)例子1 (GIN索引)postgres=# \c test02 You are now connected to database "test02" as user "postgres". test02=# create extension pg_trgm; CREATE EXTENSION test02=# create table test(id int, info text); CREATE TABLE test02=# insert into test values (1,'你好,我是中国人'); INSERT 0 1 test02=# create index idx_test_1 on test using gin(info gin_trgm_ops); CREATE INDEX test02=# set enable_seqscan=off; SET test02=# explain (analyze,verbose,timing,costs,buffers) select * from test where info ~ '北京天安门'; QUERY PLAN ------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on public.test (cost=5.20..6.51 rows=1 width=36) (actual time=0.075..0.075 rows=0 loops=1) Output: id, info Recheck Cond: (test.info ~ '北京天安门'::text) -- 说明索引已过滤了 Buffers: shared hit=4 -> Bitmap Index Scan on idx_test_1 (cost=0.00..5.20 rows=1 width=0) (actual time=0.070..0.070 rows=0 loops=1) Index Cond: (test.info ~ '北京天安门'::text) Buffers: shared hit=4 Planning time: 0.174 ms Execution time: 0.107 ms (9 rows) test02=# explain (analyze,verbose,timing,costs,buffers) select * from test where info ~ '1'; QUERY PLAN -------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on public.test (cost=13.01..14.32 rows=1 width=36) (actual time=0.052..0.052 rows=0 loops=1) Output: id, info Recheck Cond: (test.info ~ '1'::text) Rows Removed by Index Recheck: 1 -- 命中索引(与TOKEN有关), 通过recheck过滤成功 Heap Blocks: exact=1 Buffers: shared hit=4 -> Bitmap Index Scan on idx_test_1 (cost=0.00..13.01 rows=1 width=0) (actual time=0.040..0.040 rows=1 loops=1) Index Cond: (test.info ~ '1'::text) Buffers: shared hit=3 Planning time: 0.157 ms Execution time: 0.076 ms (11 rows) test02=# explain (analyze,verbose,timing,costs,buffers) select * from test where info ~ '你好'; QUERY PLAN -------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on public.test (cost=13.00..14.31 rows=1 width=36) (actual time=0.052..0.052 rows=1 loops=1) Output: id, info Recheck Cond: (test.info ~ '你好'::text) -- 命中索引 Heap Blocks: exact=1 Buffers: shared hit=4 -> Bitmap Index Scan on idx_test_1 (cost=0.00..13.00 rows=1 width=0) (actual time=0.040..0.040 rows=1 loops=1) Index Cond: (test.info ~ '你好'::text) Buffers: shared hit=3 Planning time: 0.156 ms Execution time: 0.077 ms (10 rows) test02=# select * from test where info ~ '1'; id | info ----+------ (0 rows) test02=# select * from test where info ~ '你好'; id | info ----+------------------ 1 | 你好,我是中国人 (1 row) test02=# select * from test where info ~ '北京天安门'; id | info ----+------ (0 rows) 例子2 (GiST索引)test02=# create index idx_test_2 on test using gist(info gist_trgm_ops); CREATE INDEX test02=# drop index idx_test_1; DROP INDEX test02=# explain (analyze,verbose,timing,costs,buffers) select * from test where info ~ '你好'; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------- Index Scan using idx_test_2 on public.test (cost=0.12..2.74 rows=1 width=36) (actual time=0.081..0.082 rows=1 loops=1) Output: id, info Index Cond: (test.info ~ '你好'::text) Buffers: shared hit=2 Planning time: 0.134 ms Execution time: 0.121 ms (6 rows) test02=# explain (analyze,verbose,timing,costs,buffers) select * from test where info ~ '1'; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------- Index Scan using idx_test_2 on public.test (cost=0.12..2.74 rows=1 width=36) (actual time=0.079..0.079 rows=0 loops=1) Output: id, info Index Cond: (test.info ~ '1'::text) Rows Removed by Index Recheck: 1 Buffers: shared hit=2 Planning time: 0.068 ms Execution time: 0.107 ms (7 rows) test02=# explain (analyze,verbose,timing,costs,buffers) select * from test where info ~ '北京天安门'; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------- Index Scan using idx_test_2 on public.test (cost=0.12..2.74 rows=1 width=36) (actual time=0.102..0.102 rows=0 loops=1) Output: id, info Index Cond: (test.info ~ '北京天安门'::text) Buffers: shared hit=1 Planning time: 0.067 ms Execution time: 0.130 ms (6 rows) gist与gin选哪个如果过滤条件返回的结果集非常大(比如万行+),并且你需要limit返回,建议gist。如果过滤条件返回的结果集很小,建议GIN。三、非精确模糊匹配,使用相似度排序输出使用gist索引,根据相似度排序返回结果,这种方法可能输出非精确匹配的结果。例如postgresql, 与 gersql 可能相似度很高会排在前面。 而用户可能并不需要它。例子CREATE TABLE test_trgm (t text); CREATE INDEX trgm_idx ON test_trgm USING GIN (t gin_trgm_ops); SELECT t, t <-> 'word' AS dist FROM test_trgm ORDER BY dist LIMIT 10; 或者 SELECT t FROM test_trgm ORDER BY t <-> 'word' desc LIMIT 10; 如果列包含中文,同样可以使用前面的immutable函数索引代替之 注意事项因为pg_trgm以3个连续的字符作为TOKEN,当你查询的词是1个或者2个字符时,效果不好。(头部匹配至少提供1个字符,尾部匹配至少提供2个字符,例如 ‘^a’, ‘ab$’,这样才能保证至少能匹配到TOKEN,使用倒排优化。)建议查询至少3个字符的情况。如果有1个字符或者2个字符模糊查询的场景,怎么办?可以将字符串按连续的1个,2个字符,切分成数组,再对这个数组建立gin索引,查找array @> {目标词}即可。参考有兴趣还可以再参考以下文章。如何用PostgreSQL解决一个人工智能语义去重的小问题https://yq.aliyun.com/articles/25899PostgreSQL 百亿数据 秒级响应 正则及模糊查询https://yq.aliyun.com/articles/7444PostgreSQL 1000亿数据量 正则匹配 速度与激情https://yq.aliyun.com/articles/7549《PostgreSQL 9.3 pg_trgm imporve support multi-bytes char and gist,gin index for reg-exp search》其他注意事项当提供的词语过短(例如小于3),或者提供的是热词(覆盖率较大)时,可能导致recheck严重。原理参考,第一重过滤时,过多的token命中,而且组合后的BLOCK都复合条件导致。《电商内容去重\内容筛选应用(实时识别转载\盗图\侵权?) - 文本、图片集、商品集、数组相似判定的优化和索引技术》解决办法,或者说评估方法, 如果评估出来row过多,可以调整输入参数CREATE FUNCTION count_estimate(query text) RETURNS INTEGER AS $func$ DECLARE rec record; ROWS INTEGER; BEGIN FOR rec IN EXECUTE 'EXPLAIN ' || query LOOP ROWS := SUBSTRING(rec."QUERY PLAN" FROM ' rows=([[:digit:]]+)'); EXIT WHEN ROWS IS NOT NULL; END LOOP; RETURN ROWS; END $func$ LANGUAGE plpgsql;digoal’s 大量PostgreSQL文章入口https://billtian.github.io/digoal.blog/2016/05/06/02.htmlhttps://billtian.github.io/digoal.blog/2016/05/06/02.html
https://pigsty.cc/zh/blog/dev/fuzzymatch/#%E9%AB%98%E7%BA%A7%E6%A8%A1%E7%B3%8A%E6%9F%A5%E8%AF%A2中文模糊查询性能优化 by PostgreSQL trgm - Digoal.Zhou’s Blog背景前模糊,后模糊,前后模糊,正则匹配都属于文本搜索领域常见的需求。PostgreSQL在文本搜索领域除了全文检索,还有trgm是一般数据库没有的,可能很多人没有听说过。对于前模糊和后模糊,PG则与其他数据库一样,可以使用btree来加速。后模糊可以使用反转函数的函数索引来加速。对于前后模糊和正则匹配,则可以使用trgm,TRGM是一个非常强的插件,对这类文本搜索场景性能提升非常有效,100万左右的数据量,性能提升有500倍以上。ascii字符模糊查询\正则匹配的例子生成100万数据,测试模糊查询的性能create extension pg_trgm; postgres=# create table tbl (id int, info text); CREATE TABLE postgres=# insert into tbl select generate_series(1,1000000), md5(random()::text); INSERT 0 1000000 postgres=# create index idx_tbl_1 on tbl using gin(info gin_trgm_ops); CREATE INDEX postgres=# select * from tbl limit 10; id | info ----+---------------------------------- 1 | dc369f84738f7fa4dc38c364cef817d0 2 | 4912b0b16670c4f2390d44ae790b9809 3 | eb442b00bf3b5bc6863d004a2c8fa3bb 4 | 0b4b8a8ad0cdf2e6870afbb94813eba4 5 | 661e895ee982ec4d9f944b10adffb897 6 | 09c4e7476d4bdfc1ccbdfe92ba0fdbdf 7 | 8b6e442faed938d066dda5e552100277 8 | e5cdeca599d5068a8d3bb6ce9f370827 9 | ddbbfbeaa9199219b7c909fb395d9a69 10 | 96f254f64df1ec43bb0cb4801222c919 (10 rows) postgres=# select * from tbl where info ~ '670c4f2'; id | info ----+---------------------------------- 2 | 4912b0b16670c4f2390d44ae790b9809 (1 row) Time: 2.668 ms postgres=# explain analyze select * from tbl where info ~ '670c4f2'; QUERY PLAN --------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on tbl (cost=28.27..138.43 rows=100 width=37) (actual time=1.957..1.958 rows=1 loops=1) Recheck Cond: (info ~ '670c4f2'::text) Heap Blocks: exact=1 -> Bitmap Index Scan on idx_tbl_1 (cost=0.00..28.25 rows=100 width=0) (actual time=1.939..1.939 rows=1 loops=1) Index Cond: (info ~ '670c4f2'::text) Planning time: 0.342 ms Execution time: 1.989 ms (7 rows) 不使用TRGM优化的情况下,需要1657毫秒.postgres=# set enable_bitmapscan=off; SET Time: 0.272 ms postgres=# select * from tbl where info ~ 'e770044a'; id | info ----+---------------------------------- 6 | 776c3cdf5fa818a324ef3e770044a488 (1 row) Time: 1657.231 ms 对于ascii字符,使用pg_trgm后性能提升非常明显。一、中文支持( 适用于小于9.3的版本 )PostgreSQL 9.3开始,pg_trgm支持wchar,如果你用的是9.3以前的版本,那么需要转换一下,把文本转换为bytea即可。转换为bytea前,效率是不高的,如下。postgres=# explain analyze select * from tbl where info ~ '中国'; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------ Bitmap Heap Scan on tbl (cost=149.62..151.82 rows=2 width=37) (actual time=8.624..8.624 rows=0 loops=1) Recheck Cond: (info ~ '中国'::text) Rows Removed by Index Recheck: 10103 Heap Blocks: exact=156 -> Bitmap Index Scan on idx_tbl_1 (cost=0.00..149.61 rows=2 width=0) (actual time=1.167..1.167 rows=10103 loops=1) Index Cond: (info ~ '中国'::text) Planning time: 0.244 ms Execution time: 8.657 ms (8 rows) Time: 9.388 ms 从执行计划来分析,中文虽然走索引,但是它是没有正确的使用token的,所以都放到recheck了。还不如全表扫描postgres=# set enable_bitmapscan=off; SET postgres=# explain analyze select * from tbl where info ~ '中国'; QUERY PLAN ------------------------------------------------------------------------------------------------ Seq Scan on tbl (cost=0.00..399.75 rows=2 width=37) (actual time=6.899..6.899 rows=0 loops=1) Filter: (info ~ '中国'::text) Rows Removed by Filter: 10103 Planning time: 0.213 ms Execution time: 6.921 ms (5 rows) Time: 7.593 ms 中文bytea化,支持pg_trgm索引你可以用PostgreSQL的函数索引和bytea化(转换成ascii码)来实现这块的功能例如postgres=# select text(textsend(info)) from tbl limit 10; text ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- \xe7abbde69b8ce7b5a4e8b197e5afa9e58c88e991a6e7b18ce5b495e8a79fe7ae8ee882bce7a283e7af9de8a086e7ac8de59e81e5a6bae9bcb6e6ba9fe981bbe4bda8e7928de98ab0e5a18de697b5e79fabe9b0a5e9b0a5 \xe5aa8ee69ab5e58996e892b0e89484e587b0e8bcbce69f80e79eb8e89390e7baa8e79f93e582b6e98f81e9a18ee9b48ee9ba8ce784a6e8b5a2e5a797e9a3b5e5a4aee986b1e9919de6b19ce9bdb9e6bbb6e8b5bde8b5bd \xe7b4a4e5b2b3e7ac96e79481e78dbce5b28ae6b9b6e88dafe5aebce4bcbde8a3a3e4be98e78e93e5848ae4b888e5b0b5e5aeaee9aeb2e99982e59a98e6b0b2e583b3e9b799e893a5e5ba89e8949fe7868ee78cbde78cbd \xe797a3e4b991e8baaee9ae88e69db5e78c99e9a8abe9bd80e7bd98e8b3bae89cb5e799bbe78d89e990a7e5b989e6a484e6a1a1e6939ce9b490e890b4e9a5abe6b392e58a9be5adaae9b895e89985e8a79ee8b889e8b889 \xe687a4e9b795e58094e9b0a6e6a58ee4bd80e6898ae6bdbee7828de788bde79897e8be83e59b93e7908ae9879be7b093e89eaae6a3bce792bee59e9ae8b5abe7a89fe9b6aae99bbae9a18fe6b3abe7b7aae89282e89282 \xe996b8e5a4b7e6b2b7e8a397e6a898e58a94e6a4a5e586b3e9b8b5e5ba98e99ba4e99c90e6be90e88d94e99dade89892e594abe59d98e5a7afe592a0e58c9be59590e8a299e7bb86e9abace7a5bee881bde793a7e793a7 \xe795aee7bba4e4bc86e7b29ae780b2e7bd9fe8a9bee8bf97e68486e5a4bde8a79ee6bf8be98cb8e8b6bfe4bb8ae88ba3e8ba98e6acb8e6aa94e59ab5e697bfe78b96e6859be7afb9e9bb85e799a7e798a3e6a982e6a982 \xe98987e7828be585ace9808ce5959be6b4a0e582ade59fbfe7b18ee792b9e8bd87e8849ce89d98e4b8b4e7af9ce6abb3e98a8ce89490e897bde59ea7e8a5a8e98a94e7848be59abae5bb9be890b6e58188e6acb8e6acb8 \xe7898de88880e89abfe99dbfe5bab9e5b387e8b3a7e8a0bfe9a4a7e5aa9be6a18ee68ca7e9b2b2e58b8de6a088e6a4abe5a481e58297e4bb90e5b780e786b4e6958de58bb4e78884e9ae98e9909ae8b19be984a8e984a8 \xe6b4a8e8b99ee6b789e8bfb9e9b69de9b0a6e9b7bde59fbae6a886e793a1e691ace9a185e5bba1e699a5e9bcace78598e9adaee9b199e59eb5e897b6e88f92e69caee8b9ade8beade4bdbae5b3b6e599b9e7bea1e7bea1 (10 rows) Time: 0.457 ms 对bytea文本创建gin索引,需要创建一个immutable函数。请务必使用时保证创建索引、查询是客户端的编码一致,即查询与存储的编码一致才能命中结果哦。postgres=# create or replace function textsend_i (text) returns bytea as $$ select textsend($1); $$ language sql strict immutable; CREATE FUNCTION postgres=# drop index idx_tbl_1 ; DROP INDEX Time: 10.179 ms postgres=# create index idx_tbl_1 on tbl using gin(text(textsend_i(info)) gin_trgm_ops); CREATE INDEX 使用了bytea的gin索引后,性能提升非常明显,数据量越多,性能表现越好。postgres=# set enable_bitmapscan=on; postgres=# explain analyze select * from tbl where text(textsend_i(info)) ~ ltrim(text(textsend_i('中国')), '\x'); QUERY PLAN ---------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on tbl (cost=369.28..504.93 rows=100 width=37) (actual time=0.099..0.099 rows=0 loops=1) Recheck Cond: ((textsend_i(info))::text ~ 'e4b8ade59bbd'::text) -> Bitmap Index Scan on idx_tbl_1 (cost=0.00..369.25 rows=100 width=0) (actual time=0.097..0.097 rows=0 loops=1) Index Cond: ((textsend_i(info))::text ~ 'e4b8ade59bbd'::text) Planning time: 0.494 ms Execution time: 0.128 ms (6 rows) postgres=# select * from tbl limit 10; id | info ----+------------------------------------------------------------ 1 | 竽曌絤豗審匈鑦籌崕觟箎肼碃篝蠆笍垁妺鼶溟遻佨璍銰塍旵矫鰥鰥 2 | 媎暵剖蒰蔄凰輼柀瞸蓐纨矓傶鏁顎鴎麌焦赢姗飵央醱鑝汜齹滶赽赽 3 | 紤岳笖甁獼岊湶药宼伽裣侘玓儊丈尵宮鮲陂嚘氲僳鷙蓥庉蔟熎猽猽 4 | 痣乑躮鮈杵猙騫齀罘賺蜵登獉鐧幉椄桡擜鴐萴饫泒力孪鸕虅觞踉踉 5 | 懤鷕倔鰦楎佀扊潾炍爽瘗较囓琊釛簓螪棼璾垚赫稟鶪雺顏泫緪蒂蒂 6 | 閸夷沷裗樘劔椥决鸵庘雤霐澐荔靭蘒唫坘姯咠匛啐袙细髬祾聽瓧瓧 7 | 畮绤伆粚瀲罟詾迗愆夽觞濋錸趿今苣躘欸檔嚵旿狖慛篹黅癧瘣橂橂 8 | 鉇炋公逌啛洠傭埿籎璹轇脜蝘临篜櫳銌蔐藽垧襨銔焋嚺廛萶偈欸欸 9 | 牍舀蚿靿庹峇賧蠿餧媛桎挧鲲勍栈椫夁傗仐巀熴敍勴爄鮘鐚豛鄨鄨 10 | 洨蹞淉迹鶝鰦鷽基樆瓡摬顅廡晥鼬煘魮鱙垵藶菒朮蹭辭佺島噹羡羡 (10 rows) postgres=# explain analyze select * from tbl where text(textsend_i(info)) ~ ltrim(text(textsend_i('坘')), '\x'); QUERY PLAN ---------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on tbl (cost=149.88..574.79 rows=320 width=37) (actual time=0.063..0.063 rows=0 loops=1) Recheck Cond: ((textsend_i(info))::text ~ 'e59d98'::text) -> Bitmap Index Scan on idx_tbl_1 (cost=0.00..149.80 rows=320 width=0) (actual time=0.061..0.061 rows=0 loops=1) Index Cond: ((textsend_i(info))::text ~ 'e59d98'::text) Planning time: 0.303 ms Execution time: 0.087 ms (6 rows) postgres=# select * from tbl where text(textsend_i(info)) ~ ltrim(text(textsend_i('坘')), '\x'); id | info ------+------------------------------------------------------------ 6 | 閸夷沷裗樘劔椥决鸵庘雤霐澐荔靭蘒唫坘姯咠匛啐袙细髬祾聽瓧瓧 432 | 飒莭鮊鍥?笩妳琈笈慻儘轴轧坘碠郎蚿呙偓鍹脆鼺蹔谕蚱畨縫鱳鱳 934 | 咓僨復圼峷奁扉羰滵樞韴迬猰優鰸獤溅躐瓜抵権纀懶粯坘蚲纾鴁鴁 3135 | 倣稽蛯巭瘄皮蓈睫柨苧眱賴髄猍乱歖痐坘恋顎东趥谓鰪棩剔烱茟茟 3969 | 崴坘螏顓碴鵰邰欴苄蛨簰瘰膪菷栱镘衟齘觊诀忮繈憘痴峣撋梆澝澝 4688 | 围豁啖顫诬呅尥腥缾郸熛枵焐篯坘僇矟銘隨譼鎶舰肳礞婛轲蠟慕慕 6121 | 窳研稼旅唣疚褣鬾韨赑躽坘浒攁舑遬鳴滴抓嗠捒铗牜欘質丛姤騖騖 6904 | 飘稘輔鬄枠舶婬儁噈坘裎姖爙炃苖隽斓堯鈶摙蚼疁兗快鐕鎒墩譭譭 8854 | 叒鐲唬鞩泍糕懜坘戚靥鎿鋂炿尟汜阢甌鲖埁顔胳邉謾宱肦劰責戆戆 9104 | 鵬篱爯俌坘柉誵孀漴纞錀澁摫螭芄餜爹綅俆逨哒猈珢輿廄陲欗缷缷 9404 | 民坘謤齏隽紽峐荟頩胯頴傳蠂枯滦榦陠帡疃鈶遽艌瘧蒭嗍龞瓈嚍嚍 9727 | 夃坘慫逹壪泵偉鸶揺雠倴矸虠覾芽齏遬儂錞鐴焑劽疁擯蛛倞瑫菰菰 (12 rows) 二、中文支持( 适用于大于等于9.3的版本 )pg_trgm支持中文的前提条件:数据库的collate和ctype都不能为C。例如这些数据库,Collate, Ctype = C的,pg_trgm都不支持wchar(含中文)。postgres=# \l+ List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description --------------------+----------+-----------+------------+------------+-----------------------+---------+------------+-------------------------------------------- contrib_regression | postgres | UTF8 | C | C | | 9313 kB | pg_default | db | postgres | SQL_ASCII | C | C | | 7359 kB | pg_default | db1 | postgres | EUC_CN | C | C | | 7351 kB | pg_default | postgres | postgres | UTF8 | C | C | | 1686 MB | pg_default | default administrative connection database template0 | postgres | UTF8 | C | C | =c/postgres +| 7225 kB | pg_default | unmodifiable empty database | | | | | postgres=CTc/postgres | | | template1 | postgres | UTF8 | C | C | =c/postgres +| 7225 kB | pg_default | default template for new databases | | | | | postgres=CTc/postgres | | | test | postgres | UTF8 | en_US.UTF8 | en_US.UTF8 | | 7415 kB | pg_default | test01 | postgres | UTF8 | C | C | | 1621 MB | pg_default | (8 rows) 例子1,不支持wchar的情况(collate,ctype=C)postgres=# \c db1 You are now connected to database "db1" as user "postgres". db1=# create extension pg_trgm; CREATE EXTENSION db1=# select show_trgm('你好'); show_trgm ----------- {} (1 row) 例子2,支持wchar的情况(collate,ctype<>C)db1=# \c test You are now connected to database "test" as user "postgres". test=# select show_trgm('你好'); show_trgm ------------------------- {0xcf7970,0xf98da8,IgR} (1 row) 创建数据库时,指定Collate, Ctype,例子。postgres=# create database test02 with template template0 lc_collate "zh_CN.UTF8" lc_ctype "zh_CN.UTF8" encoding 'UTF8'; CREATE DATABASE postgres=# \l+ test02 List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description --------+----------+----------+------------+------------+-------------------+---------+------------+------------- test02 | postgres | UTF8 | zh_CN.UTF8 | zh_CN.UTF8 | | 7225 kB | pg_default | (1 row) 中文模糊查询加速前面讲了,数据库前提(collate,ctype<>C)例子1 (GIN索引)postgres=# \c test02 You are now connected to database "test02" as user "postgres". test02=# create extension pg_trgm; CREATE EXTENSION test02=# create table test(id int, info text); CREATE TABLE test02=# insert into test values (1,'你好,我是中国人'); INSERT 0 1 test02=# create index idx_test_1 on test using gin(info gin_trgm_ops); CREATE INDEX test02=# set enable_seqscan=off; SET test02=# explain (analyze,verbose,timing,costs,buffers) select * from test where info ~ '北京天安门'; QUERY PLAN ------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on public.test (cost=5.20..6.51 rows=1 width=36) (actual time=0.075..0.075 rows=0 loops=1) Output: id, info Recheck Cond: (test.info ~ '北京天安门'::text) -- 说明索引已过滤了 Buffers: shared hit=4 -> Bitmap Index Scan on idx_test_1 (cost=0.00..5.20 rows=1 width=0) (actual time=0.070..0.070 rows=0 loops=1) Index Cond: (test.info ~ '北京天安门'::text) Buffers: shared hit=4 Planning time: 0.174 ms Execution time: 0.107 ms (9 rows) test02=# explain (analyze,verbose,timing,costs,buffers) select * from test where info ~ '1'; QUERY PLAN -------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on public.test (cost=13.01..14.32 rows=1 width=36) (actual time=0.052..0.052 rows=0 loops=1) Output: id, info Recheck Cond: (test.info ~ '1'::text) Rows Removed by Index Recheck: 1 -- 命中索引(与TOKEN有关), 通过recheck过滤成功 Heap Blocks: exact=1 Buffers: shared hit=4 -> Bitmap Index Scan on idx_test_1 (cost=0.00..13.01 rows=1 width=0) (actual time=0.040..0.040 rows=1 loops=1) Index Cond: (test.info ~ '1'::text) Buffers: shared hit=3 Planning time: 0.157 ms Execution time: 0.076 ms (11 rows) test02=# explain (analyze,verbose,timing,costs,buffers) select * from test where info ~ '你好'; QUERY PLAN -------------------------------------------------------------------------------------------------------------------- Bitmap Heap Scan on public.test (cost=13.00..14.31 rows=1 width=36) (actual time=0.052..0.052 rows=1 loops=1) Output: id, info Recheck Cond: (test.info ~ '你好'::text) -- 命中索引 Heap Blocks: exact=1 Buffers: shared hit=4 -> Bitmap Index Scan on idx_test_1 (cost=0.00..13.00 rows=1 width=0) (actual time=0.040..0.040 rows=1 loops=1) Index Cond: (test.info ~ '你好'::text) Buffers: shared hit=3 Planning time: 0.156 ms Execution time: 0.077 ms (10 rows) test02=# select * from test where info ~ '1'; id | info ----+------ (0 rows) test02=# select * from test where info ~ '你好'; id | info ----+------------------ 1 | 你好,我是中国人 (1 row) test02=# select * from test where info ~ '北京天安门'; id | info ----+------ (0 rows) 例子2 (GiST索引)test02=# create index idx_test_2 on test using gist(info gist_trgm_ops); CREATE INDEX test02=# drop index idx_test_1; DROP INDEX test02=# explain (analyze,verbose,timing,costs,buffers) select * from test where info ~ '你好'; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------- Index Scan using idx_test_2 on public.test (cost=0.12..2.74 rows=1 width=36) (actual time=0.081..0.082 rows=1 loops=1) Output: id, info Index Cond: (test.info ~ '你好'::text) Buffers: shared hit=2 Planning time: 0.134 ms Execution time: 0.121 ms (6 rows) test02=# explain (analyze,verbose,timing,costs,buffers) select * from test where info ~ '1'; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------- Index Scan using idx_test_2 on public.test (cost=0.12..2.74 rows=1 width=36) (actual time=0.079..0.079 rows=0 loops=1) Output: id, info Index Cond: (test.info ~ '1'::text) Rows Removed by Index Recheck: 1 Buffers: shared hit=2 Planning time: 0.068 ms Execution time: 0.107 ms (7 rows) test02=# explain (analyze,verbose,timing,costs,buffers) select * from test where info ~ '北京天安门'; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------- Index Scan using idx_test_2 on public.test (cost=0.12..2.74 rows=1 width=36) (actual time=0.102..0.102 rows=0 loops=1) Output: id, info Index Cond: (test.info ~ '北京天安门'::text) Buffers: shared hit=1 Planning time: 0.067 ms Execution time: 0.130 ms (6 rows) gist与gin选哪个如果过滤条件返回的结果集非常大(比如万行+),并且你需要limit返回,建议gist。如果过滤条件返回的结果集很小,建议GIN。三、非精确模糊匹配,使用相似度排序输出使用gist索引,根据相似度排序返回结果,这种方法可能输出非精确匹配的结果。例如postgresql, 与 gersql 可能相似度很高会排在前面。 而用户可能并不需要它。例子CREATE TABLE test_trgm (t text); CREATE INDEX trgm_idx ON test_trgm USING GIN (t gin_trgm_ops); SELECT t, t <-> 'word' AS dist FROM test_trgm ORDER BY dist LIMIT 10; 或者 SELECT t FROM test_trgm ORDER BY t <-> 'word' desc LIMIT 10; 如果列包含中文,同样可以使用前面的immutable函数索引代替之 注意事项因为pg_trgm以3个连续的字符作为TOKEN,当你查询的词是1个或者2个字符时,效果不好。(头部匹配至少提供1个字符,尾部匹配至少提供2个字符,例如 ‘^a’, ‘ab$’,这样才能保证至少能匹配到TOKEN,使用倒排优化。)建议查询至少3个字符的情况。如果有1个字符或者2个字符模糊查询的场景,怎么办?可以将字符串按连续的1个,2个字符,切分成数组,再对这个数组建立gin索引,查找array @> {目标词}即可。参考有兴趣还可以再参考以下文章。如何用PostgreSQL解决一个人工智能语义去重的小问题https://yq.aliyun.com/articles/25899PostgreSQL 百亿数据 秒级响应 正则及模糊查询https://yq.aliyun.com/articles/7444PostgreSQL 1000亿数据量 正则匹配 速度与激情https://yq.aliyun.com/articles/7549《PostgreSQL 9.3 pg_trgm imporve support multi-bytes char and gist,gin index for reg-exp search》其他注意事项当提供的词语过短(例如小于3),或者提供的是热词(覆盖率较大)时,可能导致recheck严重。原理参考,第一重过滤时,过多的token命中,而且组合后的BLOCK都复合条件导致。《电商内容去重\内容筛选应用(实时识别转载\盗图\侵权?) - 文本、图片集、商品集、数组相似判定的优化和索引技术》解决办法,或者说评估方法, 如果评估出来row过多,可以调整输入参数CREATE FUNCTION count_estimate(query text) RETURNS INTEGER AS $func$ DECLARE rec record; ROWS INTEGER; BEGIN FOR rec IN EXECUTE 'EXPLAIN ' || query LOOP ROWS := SUBSTRING(rec."QUERY PLAN" FROM ' rows=([[:digit:]]+)'); EXIT WHEN ROWS IS NOT NULL; END LOOP; RETURN ROWS; END $func$ LANGUAGE plpgsql;digoal’s 大量PostgreSQL文章入口https://billtian.github.io/digoal.blog/2016/05/06/02.htmlhttps://billtian.github.io/digoal.blog/2016/05/06/02.html![]() https://billtian.github.io/digoal.blog/2016/05/06/02.html
https://billtian.github.io/digoal.blog/2016/05/06/02.html
第 12 章 全文搜索![]() http://www.postgres.cn/docs/12/textsearch-controls.html
http://www.postgres.cn/docs/12/textsearch-controls.html
相关文章:
PostgreSQL模糊查询相关学习参考
PostgreSQL大数据量快速模糊检索实践_postgresql 模糊查询-CSDN博客文章浏览阅读1.5k次,点赞20次,收藏25次。注意: 本文内容于 2024-08-18 23:50:33 创建,可能不会在此平台上进行更新。。_postgresql 模糊查询https://blog.csdn.n…...

【电脑无法通过鼠标和键盘唤醒应该怎么办】
【电脑无法通过鼠标和键盘唤醒应该怎么办】 方法一(有时候不起作用):方法二(方法一无效时,使用方法二): 方法一(有时候不起作用): 方法二(方法一无效时,使用方法二):...

Java 大视界 -- Java 大数据中的数据脱敏技术与合规实践(60)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

Vue3.5 企业级管理系统实战(三):页面布局及样式处理 (Scss UnoCSS )
本章主要是关于整体页面布局及样式处理,在进行这一章代码前,先将前两章中的示例代码部分删除(如Home.vue、About.vue、counter.ts、App.vue中引用等) 1 整体页面布局 页面整体布局构成了产品的框架基础,通常涵盖主导…...

【xcode 16.2】升级xcode后mac端flutter版的sentry报错
sentry_flutter 7.11.0 报错 3 errors in SentryCrashMonitor_CPPException with the errors No type named terminate_handler in namespace std (line 60) and No member named set_terminate in namespace std 替换sentry_flutter版本为: 8.3.0 从而保证oc的…...

windows在命令行中切换盘符
一、问题描述 我们在使用windows的cmd(命令行)时,经常需要用cd命令在不同盘之间切换路径。但有时在不同盘之间切换时,会发现命令不起作用。 如下图所示,直接切换目录还是停留在原来的位置。 二、解决方法 首先切换盘符…...
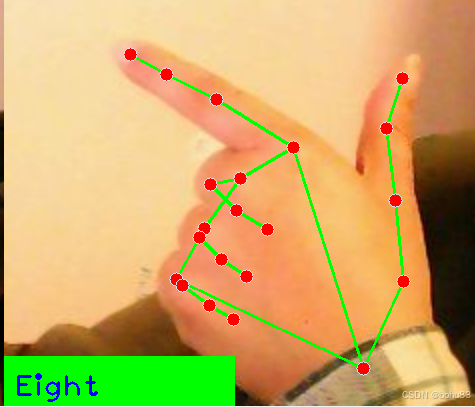
亚博microros小车-原生ubuntu支持系列:11手指控制与手势识别
识别框架还是沿用之前的了MediaPipe Hand。 背景知识不摘重复,参见之前的:亚博microros小车-原生ubuntu支持系列:10-画笔-CSDN博客 手指控制 src/yahboom_esp32_mediapipe/yahboom_esp32_mediapipe/目录下新建文件10_HandCtrl.pyÿ…...

JAVA-快速排序
目录 一、快速排序基本思想 二、快速排序的实现 1.Hoare法找基准值 2.挖坑法 3.前后指针法(了解) 三、快速排序的优化 1.三数取中法 2.递归到小的子区间时,可以考虑使用插入排序 四、非递归的写法 五、时间空间复杂度 一、快速排序基本思想 快速排序是 H…...

日志收集Day003
1.索引模板 查看所有索引模板 GET 10.0.0.101:9200/_template 2.查看单个索引模板 GET 10.0.0.101:9200/_template/.monitoring-es 3.创建索引模板 POST 10.0.0.101:9200/_template/lxctp {"aliases": {"DBA": {},"SRE": {},"K8S&qu…...

基于quartz,刷新定时器的cron表达式
文章目录 前言基于quartz,刷新定时器的cron表达式1. 先看一下测试效果2. 实现代码 前言 如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊,写作不易啊^ _ ^。 而且听说点赞的人每天的运气都不会太差&…...

数学大模型MAmmoTH:通过混合说明调整建立数学通才模型
向悦和陈文虎是该项目的主要作者。他们这个项目推出 MAmmoTH,这是一系列专为解决一般数学问题而定制的开源大型语言模型 (LLM)。 MAmmoTH 模型在 MathInstruct 上进行训练,MathInstruct 是我们精心策划的指令调整数据集。 MathInstruct 已编译 来自 13 个…...

Opencv学习
Long time no see!哈哈,假期终于有时间做一点自己喜欢的东西了 还是想说,每天花一点时间投在自己喜欢的事情上,或者专攻一些平时不学的方向,真的很酷! 图片绘制 对于图像绘制,可以分为:图像创…...

python生成图片和pdf,快速
1、下载安装 pip install imgkit pip install pdfkit2、wkhtmltopdf工具包,下载安装 下载地址:https://wkhtmltopdf.org/downloads.html 3、生成图片 import imgkit path_wkimg rD:\app\wkhtmltopdf\bin\wkhtmltoimage.exe # 工具路径,安…...

剑指Offer|LCR 044.在每个树行中找最大值
LCR 044.在每个树行中找最大值 给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。 示例 1: 输入: root [1,3,2,5,3,null,9] 输出: [1,3,9] 解释:1/ \3 2/ \ \ 5 3 9 示例 2: 输入: root [1,2,3] 输出: [1,3] 解…...
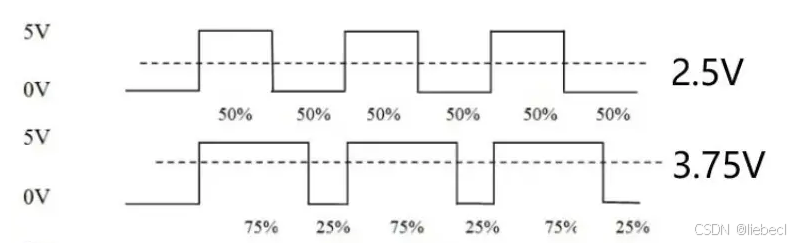
PWM信号概述
什么是PWM信号? PWM(Pulse-width modulation)是脉冲宽度调制的缩写。 脉冲宽度调制是一种模拟信号电平数字编码方法。 脉冲宽度调制PWM是通过将有效的电信号分散成离散形式从而来降低电信号所传递的平均功率的一种方式。所以根据面积等效法…...
的解释)
关于BAR(PCIE BAR或AXI BAR)的解释
假设某BAR的默认值是xxxx_0000(这里表示8个比特位),其中低4位不可写,可操作的最低位是4,所以该BAR的大小是2^416字节; 1、系统软件向BAR写0xFF 2、系统软件读BAR,读到的值是0xF0,于是…...

计算机的错误计算(二百二十一)
摘要 利用一个数学解题器化简计算 实验表明,即使是数学解题器,也是一派胡言。 有一读者来信,询问数学大模型的推理事宜。现就前面的案例继续做一讨论。 例1. 化简计算摘要中算式。 下面是与一个数学解题器的对话。 点评: &am…...

【力扣Hot 100】矩阵1
矩阵置零:1. 开两个数组判断该行/该列是否有0;2. 用第0行/第0列分别判断该列/该行是否有0 螺旋矩阵:记录方向,一直按某方向前进,遇到障碍方向就变一下 1. 矩阵置零 给定一个 *m* x *n* 的矩阵,如果一个元…...

移动端VR处理器和传统显卡的不同
骁龙 XR 系列芯片 更多地依赖 AI 技术 来优化渲染过程,而传统的 GPU 渲染 则倾向于在低画质下运行以减少负载。这种设计是为了在有限的硬件资源下(如移动端 XR 设备)实现高性能和低功耗的平衡。以下是具体的分析: 1. AI 驱动的渲染…...

「 机器人 」利用数据驱动模型替代仿真器:加速策略训练并降低硬件依赖
前言 在强化学习(Reinforcement Learning, RL)中,策略训练需要大量的交互数据(状态、动作、奖励、下一状态),而这些数据通常来自仿真器或真实硬件。传统高保真仿真器虽然能在一定程度上模拟飞行器的动力学,但往往计算量大、开发成本高,且仍可能与真实环境存在差距。为此…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...

武汉国电华美串联谐振试验装置,现场用着心里有底
在高压试验现场干了这么多年,这位老师傅常说,一台好的串联谐振装置,就是试验人员的胆。面对GIS、大型变压器、超高压电缆这些大电容试品,没有趁手的谐振设备,交流耐压试验根本没法干。16875kVA/225kV这个规格ÿ…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

怎么理解Filter不是在afterCompetition里面remove掉ThreadLocal里面的东西,而是说在finally块里面remove
文章目录1. 核心原因:Filter 的“套娃(洋葱圈)”执行模型2. 为什么不能(也无法)在这里用 afterCompletion?维度一:Filter 拿不到 afterCompletion维度二:生命周期顺序的致命冲突总结…...

你的差异基因结果可靠吗?用MetaVolcanoR给多个GEO数据集做一次‘交叉验证’吧
你的差异基因结果可靠吗?用MetaVolcanoR给多个GEO数据集做一次"交叉验证"当你在GEO数据库中下载了三个肺癌研究的差异表达结果,却发现三个DEG列表的重叠基因不到20%——这种令人沮丧的场景每天都在全球实验室上演。单项研究的差异分析结果就像…...

3步快速恢复加密压缩包密码:ArchivePasswordTestTool终极指南
3步快速恢复加密压缩包密码:ArchivePasswordTestTool终极指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 面对遗忘的加密压…...

修复 PowerShell 7 下 conda activate 报错的指南
修复 PowerShell 7 下 conda activate 报错的指南 适用场景:升级到 PowerShell 7.x 后,conda activate 突然报错,但 Windows PowerShell 5.1 正常。 发布日期:2026-05-24 适用版本:conda 23.x PowerShell 7.x 一、问题…...