Web 代理、爬行器和爬虫
目录
- Web 在线网页代理服务器的使用方法
- Web 在线网页代理服务器
- 使用流程详解
- 注意事项
- Web 请求和响应中的代理方式
- Web 开发中的请求方法
- 借助代理进行文件下载的示例
- Web 服务器请求代理方式
- 代理、网关和隧道的概念
- 参考文献说明
- 爬虫的工作原理及案例
- 网络爬虫概述
- 爬虫工作原理
- Web 爬行器的作用及案例
- 使用 Python 的 Web 爬行器
- Web 爬行器在安全测试中的应用
Web 在线网页代理服务器的使用方法
Web 在线网页代理服务器
Web 在线网页代理服务器就像是网络穿越仪一般,它是一种具有转发功能的应用程序,能够帮助用户在特定网络环境下访问被封锁的网页。用户在某些网络环境中可能无法直接访问特定的网页资源,而通过 Web 在线网页代理服务器,用户的请求可以被转发到目标网站,然后将目标网站的响应返回给用户,从而实现对被封锁网页的访问。
使用流程详解
使用 Web 在线网页代理服务器的具体步骤如下:
首先,寻找可靠的代理服务器网站或服务提供商。用户可以通过网络搜索等方式找到一些信誉良好的代理服务器站点,比如一些知名的在线代理服务平台。
接着,打开代理网站,在网站的主页上通常会有一个输入框,提示用户输入要访问的网址。
然后,在输入框中输入要访问的被封锁的网址,并点击网站上的 “GO” 按钮或类似的开始按钮来提交请求。
此时,代理网站会接收到用户的请求,并将请求内容封装到 HTTP 包中。随后,代理网站会建立与目标网站的 TCP 连接,并发送封装好的 HTTP 包。
目标网站收到代理网站发送的请求后,解包并处理请求内容。处理完成后,目标网站将请求的资源封装到 HTTP 包中,然后发送回代理网站。
代理网站收到目标网站返回的 HTTP 包,解包并提取出资源。接着,代理网站将请求的资源封装到 HTTP 包中,并将该 HTTP 包发送回给用户的用户代理(如浏览器)。
最后,用户的用户代理收到代理网站返回的 HTTP 包后,解包并显示出请求的网页或资源
注意事项
使用 Web 在线网页代理服务器时,用户需要注意保护个人信息和隐私。虽然代理服务器可以帮助用户访问被封锁的网页,但它并不能保证网络安全。在使用代理服务器的过程中,用户的请求和响应都要经过代理服务器,这就增加了信息被泄露的风险。因此,用户在使用代理服务器时,应避免在通过代理访问的网页上输入敏感信息,如个人身份证号、银行卡密码等。
Web 请求和响应中的代理方式
Web 开发中的请求方法
在 Web 开发中,主要的请求方法有 GET 请求、POST 请求和 HEAD 请求。
GET 请求用于从服务器请求数据,不改变服务器的状态。通常用于获取静态资源、HTML 文件或读取数据,比如从 API 获取列表或单条数据。其特点是请求参数通过 URL 传递,对传递的数据有长度限制,并且是幂等的,无论请求多少次,服务器的状态不会发生变化。同时,GET 请求不应用于提交敏感信息,因为参数信息会显示在地址栏的 URL 中,不安全。
POST 请求用于向服务器发送数据,通常用于提交表单、上传文件、或创建新的资源。发送的数据通常会影响服务器的状态,比如在数据库中创建记录。POST 请求的特点是请求体中包含数据,传递的内容没有长度限制。它不是幂等的,每次请求都会对服务器的状态产生影响。通常用于提交敏感信息,因为数据不会暴露在 URL 中。
HEAD 请求与 GET 请求类似,但是它只返回 HTTP 头部信息,不返回实际的内容主体。HEAD 请求通常用于检查资源是否存在、获取资源的元数据等。
借助代理进行文件下载的示例
以文件下载为例,展示如何使用 NSURLRequest、NSURLConnection 等对象通过代理方式处理服务器响应。首先,需要设置代理服务器的地址和端口信息。然后,创建一个 NSURLRequest 对象,并将其配置为使用代理服务器。接着,使用 NSURLConnection 发送请求,并在连接的委托方法中处理服务器的响应。
// 设置代理服务器地址和端口let proxyHost = "proxy.example.com"let proxyPort = 8080// 创建 URLlet url = URL(string: "http://download.example.com/file.zip")!// 创建请求对象var request = URLRequest(url: url)// 设置代理let proxyURL = URL(string: "http://(proxyHost):(proxyPort)")let configuration = URLSessionConfiguration.defaultconfiguration.connectionProxyDictionary = [kCFProxyHostNameKey as String: proxyHost, kCFProxyPortNumberKey as String: proxyPort]let session = URLSession(configuration: configuration)// 发送请求并处理响应let task = session.dataTask(with: request) { (data, response, error) inif let error = error {print("Error: (error.localizedDescription)")} else if let data = data {// 处理下载的文件数据// 将数据保存到本地文件等操作}}task.resume()在使用代理进行文件下载时,需要注意以下几点:
首先,确保代理服务器的稳定性和可靠性。如果代理服务器不稳定,可能会导致下载中断或速度缓慢。
其次,注意代理服务器的安全性。一些不可信的代理服务器可能会窃取用户的下载内容或个人信息。
最后,根据实际情况选择合适的代理方式。不同的代理服务器可能支持不同的协议和功能,需要根据具体的需求进行选择。
Web 服务器请求代理方式
代理、网关和隧道的概念
代理、网关和隧道在通信中都起着重要的作用,但它们的功能和作用有所不同。
代理作为中间人转发请求和响应。代理服务器位于客户端和服务器之间,接收客户端的请求并转发给服务器,同时接收服务器的响应并返回给客户端。代理服务器可以用于缓存资源、过滤请求、隐藏客户端的真实 IP 地址等。
网关将 HTTP 请求转化为其他协议通信并提高安全性。网关可以将 HTTP 请求转换为其他协议,如 FTP、SMTP 等,以便与不同类型的服务器进行通信。网关还可以提供安全功能,如身份验证、加密等。
隧道用于中转客户端和服务器的通信并确保安全。隧道建立起一条与服务器的通信线路,使用 SSL 加密技术进行通信,确保客户端和服务器端安全通信。隧道通常用于在不安全的网络环境中建立安全的通信通道。
参考文献说明
参考书籍《图解 HTTP》对理解相关内容有很大的帮助。这本书对互联网基盘 ——HTTP 协议进行了全面系统的介绍,包括代理、网关和隧道的概念和作用。通过阅读这本书,读者可以更深入地了解 Web 通信中的各种技术和概念,提高对 Web 开发和网络通信的理解。
爬虫的工作原理及案例
网络爬虫概述
-
定义和作用
网络爬虫是自动抓取互联网信息的程序或脚本。它们被广泛用于搜索引擎、数据挖掘等领域,能够从公开网页抓取数据,为不同领域如金融分析、市场趋势预测等提供数据支持。在一定程度上代替了手工访问网页,实现自动化采集互联网的数据,从而更高效地利用互联网中的有效信息。 -
历史沿革
网络爬虫技术起源于 1990 年代初的搜索引擎。1990 年,Archie 搜索引擎的出现标志着网络爬虫研究的开始。1993 年麻省理工学院的马修格雷开发了名为 World wide Web Wanderer 的爬虫系统,该系统能够统计互联网中服务器的数量,为后续爬虫系统的开发提供了重要设计思想。
到了 1994 年,出现了机器人、蜘蛛、爬虫等网络自动跟踪索引程序。同年,美国华盛顿大学的师生开发了一种在网络上查询信息的工具,被认为是现代网络爬虫的雏形。它是首个能对 Web 页面进行全文搜索的搜索引擎,使用了广度优先的策略来遍历网页。同年,斯坦福大学的杨致远和大卫费罗共同创办了 Yahoo 公司,其搜索引擎后来成为极具影响力的分类目录式搜索引擎。随后,Lycos、Infoseek、Metacrawler 和 HotBot 等搜索引擎相继推出。
1995 年春,美国数字设备公司的三位科学家开发了 Altavista 搜索引擎,于同年 12 月开始提供信息检索服务,这是首次采用爬虫技术进行网页索引的实例之一。
1997 年,分布式网络爬虫技术的出现进一步推动了搜索引擎技术的发展。同年年底,斯坦福大学的拉里佩奇、谢尔盖布林、斯科特哈桑和阿伦斯特博格共同开发了 Google 搜索引擎,开启了以搜索引擎为主导的互联网新时代。1998 年由谢尔盖布林和拉里佩奇共同开发的 PageRank 算法大大改进了搜索引擎的效果,后来成为了谷歌爬虫的著名算法。
2002 年,开源的网络搜索引擎 Apache Nutch 发布,通过开放源代码的方式推动了网络爬虫技术的发展,促进了学术界和工业界对网络爬虫的研究和应用。
随着技术的发展,网络爬虫经历了从单一处理方式到分布式并行处理的显著演变。起初,爬虫技术仅限于捕获静态网页信息,但后来发展到能够处理动态和实时加载的页面内容。数据爬取的范围和精确性也得到了提升,从一般性的爬取转向更加专注和精准的目标数据爬取。
爬虫工作原理
- 基本步骤
(1)确定爬取目标:明确需要抓取的网页或数据范围。
(2)发送请求:向目标网页发送 HTTP 请求,获取网页内容。
(3)获取响应:接收服务器返回的响应,包括网页的 HTML 代码等。
(4)解析数据:使用特定的解析工具或库,从网页源代码中提取所需的数据。
(5)存储数据:将提取到的数据保存到本地文件或数据库中,以便后续分析和使用。 - 实现方式
爬虫可以用多种编程语言实现,其中 Python 是常用的编程语言之一。Python 爬虫常用的库有 requests、BeautifulSoup、Scrapy、Selenium 和 PyQuery 等。
requests 是基于 urllib 编写的阻塞式 HTTP 请求库,发出一个请求,一直等待服务器响应后,程序才能进行下一步处理。
BeautifulSoup 是 HTML 和 XML 的解析库,从网页中提取信息,同时拥有强大的 API 和多样解析方式。
Scrapy 是一个强大的爬虫框架,可以满足简单的页面爬取,也可以用于复杂的爬虫项目。
Selenium 是自动化测试工具,可以模拟用户操作浏览器,适用于处理 JavaScript 渲染的页面。
PyQuery 是 jQuery 的 Python 实现,能够以 jQuery 的语法来操作解析 HTML 文档,易用性和解析速度都很好。 - 注意事项
(1)合法合规爬取:在爬取数据时,要遵守法律法规和网站的使用条款。不得爬取受版权保护的内容或未经授权的数据。
(2)应对反爬机制:许多网站会采取反爬措施,如验证码、IP 封锁等。爬虫开发者需要不断更新技术,以绕过这些障碍。
(3)注意数据抓取方式:避免对目标网站造成过大的负担,不要在短时间内发送大量请求,以免影响网站的正常运行。
Web 爬行器的作用及案例
使用 Python 的 Web 爬行器
-
功能介绍
Python 开发 Web 爬行器具有诸多优势。首先,Python 语言简洁易读,使得代码易于理解和维护。其次,它拥有强大的库和框架,如 BeautifulSoup、Scrapy 等,为开发人员提供了丰富的工具和功能。Web 爬行器能够自动抓取和提取信息,实现自动化数据采集和处理,大大提高了工作效率。 -
分类和优势
Web 爬行器主要分为通用爬行器、垂直爬行器和增量爬行器。通用爬行器可以爬取任意网站的数据,具有广泛的适用性。垂直爬行器专注于特定领域或特定类型的网站,如新闻网站、电商网站等,能够更深入地挖掘特定领域的信息。增量爬行器只爬取更新的数据,避免重复爬取已有的数据,节省时间和资源。
Web 爬行器的优势主要体现在以下几个方面:一是自动化数据采集,能够自动访问网页、提取数据,大大提高了数据采集的效率;二是数据多样性,可以采集各种类型的数据,如文本、图片、视频等;三是数据实时性,可以定期或实时地爬取数据,保持数据的最新性;四是可用于数据分析和挖掘,通过爬取大量数据,可以发现隐藏的规律和趋势。
- 腾讯云相关产品
腾讯云提供了一系列与 Web 爬行器相关的产品。云服务器(CVM)提供弹性计算能力,支持多种操作系统和应用场景,为 Web 爬行器的运行提供稳定的计算资源。云数据库 MySQL 版(CDB)提供高可用、可扩展的 MySQL 数据库服务,可用于存储爬取的数据。云存储(COS)提供安全、稳定、低成本的对象存储服务,适用于图片、视频、文档等数据的存储和管理。人工智能平台(AI Lab)提供丰富的人工智能算法和模型,可对爬取的数据进行分析和处理。物联网(IoT Hub)提供稳定、安全的物联网连接和管理服务,可与 Web 爬行器结合,实现物联网数据的采集和处理。区块链服务(BCS)提供高性能、安全可信的区块链服务,可用于保障爬取数据的真实性和安全性。视频直播(Live)提供高清、低延迟的视频直播服务,与 Web 爬行器结合可实现直播数据的采集和分析。产品介绍链接可参考:云服务器产品介绍链接、云数据库 MySQL 版产品介绍链接、云存储产品介绍链接、人工智能平台产品介绍链接、物联网产品介绍链接、区块链服务产品介绍链接、视频直播产品介绍链接。
Web 爬行器在安全测试中的应用
-
使用 DirBuster 寻找敏感文件和目录
DirBuster 是一款安全工具,可通过暴力或者表单进行来发现 Web 应用服务器上的目录名和文件名。具体实验步骤如下:首先,创建一个包含要查找的文件列表的文本文件,如 dir_dictionary.txt。然后,在 DirBuster 窗口中,将目标 URL 设置为靶机地址,如 http://192.168.123.12/。接着,设置线程数为 20 以获得不错的测试速度。选择基于列表的暴力破解,点击 “浏览”,选择创建的文件。取消选中 “Be Recursive” 选项,其余选项保留默认值。最后,点击 “Start” 开始扫描。如果转到结果选项卡,我们将看到 DirBuster 在字典中找到的文件夹,响应码 200 表示文件或目录存在并且可以被读取。 -
使用 ZAP 寻找敏感文件和目录
OWASP Zed Attack Proxy(ZAP)是一种非常通用的 web 安全测试工具,具有代理、被动和主动漏洞扫描器、爬行器等特性。配置 ZAP 作为浏览器代理的步骤如下:从 Kali Linux 菜单启动 OWASP ZAP,选择 Applications |03 - Web Application Analysis owasp-zap 或者打开终端并输入 owasp-zap 命令。更改 ZAP 的代理设置,默认端口为 8080,为避免与其他代理冲突,可将端口更改为 8088。在 Firefox 中,转到主菜单并导航到 Preferences | Advanced / Network;在 Connection 中,单击 Settings,选择手动代理配置,并将 HTTP 代理设置为 127.0.0.1,将端口设置为 8088,选中该选项以对所有协议使用相同的代理,然后单击 OK。
使用 ZAP 扫描服务器存在的文件夹的方法:正确配置代理后,浏览到目标网站,如 http://192.168.123.130/WackoPicko/。我们将看到 ZAP 通过显示我们刚访问过的主机的树结构来对此操作做出反应。现在在 ZAP 的左上角面板(“站点” 选项卡)中在目标网站内右键单击,然后在上下文菜单中,导航到 Attack(攻击)强制浏览目录(和子目录),WackoPicko 文件夹
相关文章:

Web 代理、爬行器和爬虫
目录 Web 在线网页代理服务器的使用方法Web 在线网页代理服务器使用流程详解注意事项 Web 请求和响应中的代理方式Web 开发中的请求方法借助代理进行文件下载的示例 Web 服务器请求代理方式代理、网关和隧道的概念参考文献说明 爬虫的工作原理及案例网络爬虫概述爬虫工作原理 W…...

MySQL 事件调度器
MySQL 事件调度器确实是一个更方便且内置的解决方案,可以在 MySQL 服务器端自动定期执行表优化操作,无需依赖外部工具或应用程序代码。这种方式也能减少数据库维护的复杂性,尤其适用于在数据库频繁更新或删除时进行自动化优化。 使用 MySQL …...

直线拟合例子 ,岭回归拟合直线
目录 直线拟合,算出离群点 岭回归拟合直线: 直线拟合,算出离群点 import cv2 import numpy as np# 输入的点 points np.array([[51, 149],[122, 374],[225, 376],[340, 382],[463, 391],[535, 298],[596, 400],[689, 406],[821, 407] ], dtypenp.float32)# 使用…...

Flutter android debug 编译报错问题。插件编译报错
下面相关内容 都以 Mac 电脑为例子。 一、问题 起因:(更新 Android studio 2024.2.2.13、 Flutter SDK 3.27.2) 最近 2025年 1 月 左右,我更新了 Android studio 和 Flutter SDK 再运行就会出现下面的问题。当然 下面的提示只是其…...

关于IPD流程的学习理解和使用
IPD(Integrated Product Development,集成产品开发)是一种系统化的产品开发流程和方法论,旨在通过跨职能团队的协作和并行工程,缩短产品开发周期,提高产品质量,降低开发成本。IPD 最初由美国 PR…...
)
C# 类(Class)
C# 类(Class) 概述 在C#编程语言中,类(Class)是面向对象编程(OOP)的核心概念之一。类是一种用户定义的数据类型,它包含了一组属性(数据)和方法(…...

Jenkins pipline怎么设置定时跑脚本
目录 示例:在Jenkins Pipeline中设置定时触发 使用pipeline指令设置定时触发 使用Declarative Pipeline设置定时触发 使用Scripted Pipeline设置定时触发 解释Cron表达式 保存和应用配置 小结 在Jenkins中,定时跑脚本(例如定时执行Pip…...
PostgreSQL模糊查询相关学习参考
PostgreSQL大数据量快速模糊检索实践_postgresql 模糊查询-CSDN博客文章浏览阅读1.5k次,点赞20次,收藏25次。注意: 本文内容于 2024-08-18 23:50:33 创建,可能不会在此平台上进行更新。。_postgresql 模糊查询https://blog.csdn.n…...

【电脑无法通过鼠标和键盘唤醒应该怎么办】
【电脑无法通过鼠标和键盘唤醒应该怎么办】 方法一(有时候不起作用):方法二(方法一无效时,使用方法二): 方法一(有时候不起作用): 方法二(方法一无效时,使用方法二):...

Java 大视界 -- Java 大数据中的数据脱敏技术与合规实践(60)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

Vue3.5 企业级管理系统实战(三):页面布局及样式处理 (Scss UnoCSS )
本章主要是关于整体页面布局及样式处理,在进行这一章代码前,先将前两章中的示例代码部分删除(如Home.vue、About.vue、counter.ts、App.vue中引用等) 1 整体页面布局 页面整体布局构成了产品的框架基础,通常涵盖主导…...

【xcode 16.2】升级xcode后mac端flutter版的sentry报错
sentry_flutter 7.11.0 报错 3 errors in SentryCrashMonitor_CPPException with the errors No type named terminate_handler in namespace std (line 60) and No member named set_terminate in namespace std 替换sentry_flutter版本为: 8.3.0 从而保证oc的…...

windows在命令行中切换盘符
一、问题描述 我们在使用windows的cmd(命令行)时,经常需要用cd命令在不同盘之间切换路径。但有时在不同盘之间切换时,会发现命令不起作用。 如下图所示,直接切换目录还是停留在原来的位置。 二、解决方法 首先切换盘符…...
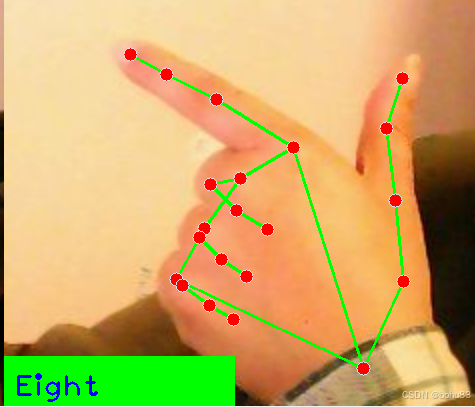
亚博microros小车-原生ubuntu支持系列:11手指控制与手势识别
识别框架还是沿用之前的了MediaPipe Hand。 背景知识不摘重复,参见之前的:亚博microros小车-原生ubuntu支持系列:10-画笔-CSDN博客 手指控制 src/yahboom_esp32_mediapipe/yahboom_esp32_mediapipe/目录下新建文件10_HandCtrl.pyÿ…...

JAVA-快速排序
目录 一、快速排序基本思想 二、快速排序的实现 1.Hoare法找基准值 2.挖坑法 3.前后指针法(了解) 三、快速排序的优化 1.三数取中法 2.递归到小的子区间时,可以考虑使用插入排序 四、非递归的写法 五、时间空间复杂度 一、快速排序基本思想 快速排序是 H…...

日志收集Day003
1.索引模板 查看所有索引模板 GET 10.0.0.101:9200/_template 2.查看单个索引模板 GET 10.0.0.101:9200/_template/.monitoring-es 3.创建索引模板 POST 10.0.0.101:9200/_template/lxctp {"aliases": {"DBA": {},"SRE": {},"K8S&qu…...

基于quartz,刷新定时器的cron表达式
文章目录 前言基于quartz,刷新定时器的cron表达式1. 先看一下测试效果2. 实现代码 前言 如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊,写作不易啊^ _ ^。 而且听说点赞的人每天的运气都不会太差&…...

数学大模型MAmmoTH:通过混合说明调整建立数学通才模型
向悦和陈文虎是该项目的主要作者。他们这个项目推出 MAmmoTH,这是一系列专为解决一般数学问题而定制的开源大型语言模型 (LLM)。 MAmmoTH 模型在 MathInstruct 上进行训练,MathInstruct 是我们精心策划的指令调整数据集。 MathInstruct 已编译 来自 13 个…...

Opencv学习
Long time no see!哈哈,假期终于有时间做一点自己喜欢的东西了 还是想说,每天花一点时间投在自己喜欢的事情上,或者专攻一些平时不学的方向,真的很酷! 图片绘制 对于图像绘制,可以分为:图像创…...

python生成图片和pdf,快速
1、下载安装 pip install imgkit pip install pdfkit2、wkhtmltopdf工具包,下载安装 下载地址:https://wkhtmltopdf.org/downloads.html 3、生成图片 import imgkit path_wkimg rD:\app\wkhtmltopdf\bin\wkhtmltoimage.exe # 工具路径,安…...

AI Agent在智能风控中的实战:多智能体欺诈检测与预警
AI Agent在智能风控中的实战:多智能体欺诈检测与预警 你有没有过明明是正常交易却被银行冻结账户的糟糕体验?或是听说过某电商平台上线新活动首日就被黑产团伙薅走数千万补贴的新闻?随着黑产欺诈向团伙化、专业化、动态化演进,传统依赖规则引擎、单模型机器学习的风控体系已…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF
告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/…...

阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月
阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月 Jianbing Zhu 1^{1}1 1^{1}1 ECT-OS-JiuHuaShan 文明实验室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20373157 Email: ect-os-jiuhuashanzoho…...