(笔记+作业)书生大模型实战营春节卷王班---L0G2000 Python 基础知识
学员闯关手册:https://aicarrier.feishu.cn/wiki/QtJnweAW1iFl8LkoMKGcsUS9nld
课程视频:https://www.bilibili.com/video/BV13U1VYmEUr/
课程文档:https://github.com/InternLM/Tutorial/tree/camp4/docs/L0/Python
关卡作业:https://github.com/InternLM/Tutorial/blob/camp4/docs/L0/Python/task.md
开发机平台:https://studio.intern-ai.org.cn/
开发机平台介绍:https://aicarrier.feishu.cn/wiki/GQ1Qwxb3UiQuewk8BVLcuyiEnHe


Conda虚拟环境
#创建虚拟新环境,创建虚拟环境时我们主要需要设置两个参数,一是虚拟环境的名字,二是python的版本。
conda create --name myenv python=3.9
#激活环境和推出环境
conda activate myenv
conda deactivate
#查看当前设备上所有的虚拟环境
conda env list
#查看当前环境中安装了的所有包
conda list
#删除环境(比如要删除myenv)
conda env remove myenv
#创建新环境到指定目录下,和激活指定目录下的环境
conda create --prefix /root/envs/myenv python=3.9
conda activate /root/envs/myenv
使用pip安装Python三方依赖包
使用pip安装包
pip install <somepackage> # 安装单个包,<somepackage>替换成你要安装的包名
pip install pandas numpy # 安装多个包,如panda和numpy
pip install numpy==2.0 # 指定版本安装
pip install numpy>=1.19,<2.0 # 使用版本范围安装
安装requirement.txt
pip install -r requirements.txt
安装包到指定目录
# 首先激活环境
conda activate /root/share/pre_envs/pytorch2.1.2cu12.1# 创建一个目录/root/myenvs,并将包安装到这个目录下
mkdir -p /root/myenvs
pip install <somepackage> --target /root/myenvs# 注意这里也可以使用-r来安装requirements.txt
pip install -r requirements.txt --target /root/myenvs#使用安装在指定目录的python包
import sys # 你要添加的目录路径
your_directory = '/root/myenvs' # 检查该目录是否已经在 sys.path 中
if your_directory not in sys.path: # 将目录添加到 sys.path sys.path.append(your_directory) # 现在你可以直接导入该目录中的模块了
# 例如:import your_module
使用本地Vscode连接InternStudio开发机
VSCode安装Remote-SSH插件、python的插件、并进行SSH远程连接到开发机,
使用vscode连接开发机进行python debug
debug就是在程序中设置断点,一行一行运行代码,观测程序中变量的变化,然后找出并修正代码中的错误
调用书生LLM的api完成生成任务
获取api key
前往书生浦语的API文档,登陆后点击API tokens。初次使用可能会需要先填写邀请码。
https://internlm.intern-ai.org.cn/api/document
使用api
#./internlm_test.py
from openai import OpenAI
import osclient = OpenAI(api_key = os.getenv('api_key'), # 此处传token,不带Bearerbase_url="https://internlm-chat.intern-ai.org.cn/puyu/api/v1/",
)chat_rsp = client.chat.completions.create(model="internlm3-latest",messages=[{"role": "user", "content": "hello"}],
)for choice in chat_rsp.choices:print(choice.message.content)
export api_key=“填入你的api token”
python internlm_test.py


闯关任务 Leetcode 383
(笔记中提交代码与leetcode提交通过截图)
https://leetcode.cn/problems/ransom-note/description/

给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。
如果可以,返回 true ;否则返回 false 。
magazine 中的每个字符只能在 ransomNote 中使用一次。
class Solution:def canConstruct(self, ransomNote: str, magazine: str) -> bool:from collections import Counter# 统计 ransomNote 和 magazine 中每个字符的频率ransom_counter = Counter(ransomNote)magazine_counter = Counter(magazine)# 检查 ransomNote 中的字符是否可以由 magazine 提供for char, count in ransom_counter.items():if magazine_counter[char] < count:return Falsereturn True
代码解释:
Counter: 使用 collections.Counter 来统计 ransomNote 和 magazine 中每个字符的出现次数。
遍历 ransomNote: 遍历 ransomNote 中的字符及其数量,检查 magazine 是否有足够的字符数量。如果某个字符在 magazine 中的数量少于在 ransomNote 中的数量,则返回 False。
for char, count in ransom_counter.items():
这行代码开始一个循环,遍历ransom_counter字典中的所有键值对。
char是字典中的键,代表一个字符。
count是字典中的值,代表该字符在赎金信中出现的次数。
.items()方法返回一个包含字典所有键值对的视图对象,可以在for循环中使用。
if magazine_counter[char] < count:
这行代码检查杂志文章中该字符的出现次数是否小于赎金信中该字符的出现次数。
magazine_counter[char]获取杂志文章中该字符的出现次数。
如果杂志中的次数小于赎金信中的次数,意味着无法用杂志中的字符拼写出赎金信。
返回结果: 如果 magazine 中的所有字符都能满足 ransomNote 的需求,返回 True。
使用示例:
solution = Solution()
print(solution.canConstruct("a", "b")) # 输出: False
print(solution.canConstruct("aa", "ab")) # 输出: False
print(solution.canConstruct("aa", "aab")) # 输出: True
闯关任务 Vscode连接InternStudio debug笔记
下面是一段调用书生浦语API实现将非结构化文本转化成结构化json的例子,其中有一个小bug会导致报错。请大家自行通过debug功能定位到报错原因。
报错代码
#python_debug.py
from openai import OpenAI
import json
import os
def internlm_gen(prompt,client):'''LLM生成函数Param prompt: prompt stringParam client: OpenAI client '''response = client.chat.completions.create(model="internlm2.5-latest",messages=[{"role": "user", "content": prompt},],stream=False)return response.choices[0].message.contentapi_key = os.getenv('api_key')
client = OpenAI(base_url="https://internlm-chat.intern-ai.org.cn/puyu/api/v1/",api_key=api_key)content = """
书生浦语InternLM2.5是上海人工智能实验室于2024年7月推出的新一代大语言模型,提供1.8B、7B和20B三种参数版本,以适应不同需求。
该模型在复杂场景下的推理能力得到全面增强,支持1M超长上下文,能自主进行互联网搜索并整合信息。
"""
prompt = f"""
请帮我从以下``内的这段模型介绍文字中提取关于该模型的信息,要求包含模型名字、开发机构、提供参数版本、上下文长度四个内容,以json格式返回。
`{content}`
"""
res = internlm_gen(prompt,client)
res_json = json.loads(res)
print(res_json)

报错原因解析

设置断点,查看报错变量

‘根据提供的模型介绍文字,以下是提取的关于该模型的信息,以JSON格式返回:\n\njson\n{\n "model_name": "书生浦语InternLM2.5",\n "development_institution": "上海人工智能实验室",\n "parameter_versions": ["1.8B", "7B", "20B"],\n "context_length": "1M"\n}\n\n\n这个JSON对象包含了以下信息:\n- model_name:模型的名称,即“书生浦语InternLM2.5”。\n- development_institution:开发该模型的机构,为“上海人工智能实验室”。\n- parameter_versions:模型提供的参数版本,包括“1.8B”、“7B”和“20B”三个版本。\n- context_length:模型支持的上下文长度,为“1M”,表示模型能够处理的上下文信息长度达到1百万字符。\n\n这些信息概括了模型的基本属性和功能特点,便于快速了解该模型的关键信息。’

报错变量修正

通过提示词去除额为文本,通过 res.strip(‘json\n').strip('’)去除代码标记、换行符和缩进,
from openai import OpenAI
import json
import os
def internlm_gen(prompt,client):'''LLM生成函数Param prompt: prompt stringParam client: OpenAI client '''response = client.chat.completions.create(model="internlm2.5-latest",messages=[{"role": "user", "content": prompt},],stream=False)return response.choices[0].message.contentapi_key=""
client = OpenAI(base_url="https://internlm-chat.intern-ai.org.cn/puyu/api/v1/",api_key=api_key)content = """
书生浦语InternLM2.5是上海人工智能实验室于2024年7月推出的新一代大语言模型,提供1.8B、7B和20B三种参数版本,以适应不同需求。
该模型在复杂场景下的推理能力得到全面增强,支持1M超长上下文,能自主进行互联网搜索并整合信息。
"""
prompt = f"""
请参考json格式,请帮我从以下``内的这段模型介绍文字中提取关于该模型的信息,要求包含模型名字、开发机构、提供参数只版本、上下文长度四个内容,以json格式返回,请移除额外的 Markdown 代码块标记 ````json和 ```,以及换行符\n`,不要有其他文字。
`{content}`
"""
res = internlm_gen(prompt,client)
# 移除 Markdown 代码块标记和换行符
json_str = res.strip('```json\n').strip('```')
res_json = json.loads(json_str)
print(res_json)


成功!!!
可选任务 pip安装到指定目录
使用VScode连接开发机后使用pip install -t命令安装一个numpy到看开发机/root/myenvs目录下,并成功在一个新建的python文件中引用。
# 首先激活环境
conda activate /root/share/pre_envs/pytorch2.1.2cu12.1# 创建一个目录/root/myenvs,并将包安装到这个目录下
mkdir -p /root/myenvs
pip install numpy --t /root/myenvs

import sys # 你要添加的目录路径
your_directory = '/root/myenvs' # 检查该目录是否已经在 sys.path 中
if your_directory not in sys.path: # 将目录添加到 sys.path sys.path.append(your_directory) # 现在你可以直接导入该目录中的模块了
# 例如:import your_module


相关文章:
(笔记+作业)书生大模型实战营春节卷王班---L0G2000 Python 基础知识
学员闯关手册:https://aicarrier.feishu.cn/wiki/QtJnweAW1iFl8LkoMKGcsUS9nld 课程视频:https://www.bilibili.com/video/BV13U1VYmEUr/ 课程文档:https://github.com/InternLM/Tutorial/tree/camp4/docs/L0/Python 关卡作业:htt…...

9、Docker环境安装Nginx
一、拉取镜像 docker pull nginx:1.24.0二、创建映射目录 作用:是将docker中nginx的相关配置信息映射到外面,方便修改配置文件 1、创建目录 # cd home/ # mkdir nginx/ # cd nginx/ # mkdir conf html log2、生成容器 docker run -p 80:80 -d --name…...

受击反馈HitReact、死亡效果Death Dissolve、Floating伤害值Text(末尾附 客户端RPC )
受击反馈HitReact 设置角色受击标签 (GameplayTag基本了解待补充) 角色监听标签并设置移动速度 创建一个受击技能,并应用GE 实现设置角色的受击蒙太奇动画 实现角色受击时播放蒙太奇动画,为了保证通用性,将其设置为一个函数,并…...

572. 另一棵树的子树
前导题:100. 相同的树 回顾一下 判断两棵二叉树相同,根结点相同 且 左子树相同 且 右子树相同。 于是判断如下: 根结点都为null,返回true根结点不都为null,返回false根结点都不为null,但是值不相同&#…...

MATLAB中textBoundary函数用法
目录 语法 说明 示例 匹配文本的边界 匹配文本的结尾边界 对文本的边界求反 textBoundary函数的功能是匹配文本的开头或结尾。 语法 pat textBoundary pat textBoundary(type) 说明 pat textBoundary 创建与文本开头或结尾匹配的模式。textBoundary 可以使用 ~ 运算…...

vue3的路由配置
先找到Layout布局文件,从中找到左侧边栏,找到下述代码 <SidebarItem v-for"route in noHiddenRoutes" :key"route.path" :item"route" :base-path"route.path" />/** *菜单项 <SidebarItem>: *使用…...

在彼此的根系里呼吸
爱如草木,需以晨露滋养,而非绳索捆缚。一段健康的亲密关系,恰似两株根系相连却各自向阳的树——风起时枝叶相触,晴空下共享光影,却始终保有向地心深处生长的自由。那些纠缠的根须是信任编织的网,容得下沉默…...

深入理解若依RuoYi-Vue数据字典设计与实现
深入理解若依数据字典设计与实现 一、Vue2版本主要文件目录 组件目录src/components:数据字典组件、字典标签组件 工具目录src/utils:字典工具类 store目录src/store:字典数据 main.js:字典数据初始化 页面使用字典例子…...

深入MapReduce——从MRv1到Yarn
引入 我们前面篇章有提到,和MapReduce的论文不太一样。在Hadoop1.0实现里,每一个MapReduce的任务并没有一个独立的master进程,而是直接让调度系统承担了所有的worker 的master 的角色,这就是Hadoop1.0里的 JobTracker。在Hadoop1…...

Flutter_学习记录_Tab的简单Demo~真的很简单
1. Tab的简单使用了解 要实现tab(选项卡或者标签视图)需要用到三个组件: TabBarTabBarViewTabController 这一块,我也不知道怎么整理了,直接提供代码吧: import package:flutter/material.dart;void main() {runApp(MyApp());…...
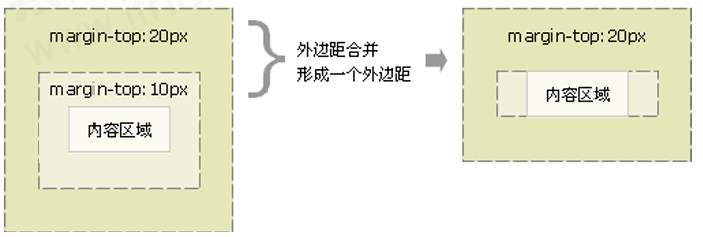
CSS核心
CSS的引入方式 内部样式表是在 html 页面内部写一个 style 标签,在标签内部编写 CSS 代码控制整个 HTML 页面的样式。<style> 标签理论上可以放在 HTML 文档的任何地方,但一般会放在文档的 <head> 标签中。 <style> div { color: r…...
)
Deepseek本地部署(ollama+open-webui)
ollama 首先是安装ollama,这个非常简单 https://ollama.com/ 下载安装即可 open-webui 这个是为了提供一个ui,毕竟我们也不想在cmd和模型交互,很不方便。 第一,需要安装python3.11,必须是3.11(其他版…...
PaddleSeg 从配置文件和模型 URL 自动化运行预测任务
git clone https://github.com/PaddlePaddle/PaddleSeg.git# 在ipynb里面运行 cd PaddleSegimport sys sys.path.append(/home/aistudio/work/PaddleSeg)import os# 配置文件夹路径 folder_path "/home/aistudio/work/PaddleSeg/configs"# 遍历文件夹,寻…...

数据结构 队列
目录 前言 一,队列的基本知识 二,用数组实现队列 三,用链表实现队列 总结 前言 接下来我们将学习队列的知识,这会让我们了解队列的基本概念和基本的功能 一,队列的基本知识 (Queue) 我们先来研究队列的ADT,…...

Cocoa和Cocoa Touch是什么语言写成的?什么是Cocoa?编程语言中什么是框架?为什么苹果公司Cocoa类库有不少NS前缀?Swift编程语言?
Cocoa和Cocoa Touch是什么语言写成的? 二者主要都是用Objective-C语言编写而成的。 什么是Cocoa? Cocoa是苹果操作系统macOS和iOS上的应用程序开发框架集合,核心语言是Objective-C编程语言,在移动平台被称为Cocoa Touch,Cocoa包含多个子框架…...

登录管理——认证方案(JWT、拦截器、ThreadLocal、短信验证)
两种常见的认证方案 基于Session认证 登录状态信息保存在服务器内存中,若访问量增加,单台节点压力会较大集群环境下需要解决集群中的各种服务器登录状态共享问题 解决方案:将登录状态保存的Redis中,从Redis中查找登录状态 基于…...

Java实现LFU缓存策略实战
LFU算法原理在Java中示例实现集成Caffeine的W-TinyLFU策略缓存实战总结LFU与LRU稍有不同,LFU是根据数据被访问的频率来决定去留。尽管它考虑了数据的近期使用,但它不会区分数据的首次访问和后续访问,淘汰那些访问次数最少的数据。 这种缓存策略主要用来处理以下场景: 数据…...

物业系统改革引领行业智能化管理与提升服务质量的新征程
内容概要 在当今迅速变化的社会中,物业系统改革正在悄然推动行业的智能化管理进程。物业管理作为一个古老而传统的领域,面临着诸多挑战,包括效率低下、业主需求难以满足等。数字化转型为这一现象注入了新活力,帮助物业公司通过先…...

QT+mysql+python 效果:
# This Python file uses the following encoding: utf-8 import sysfrom PySide6.QtWidgets import QApplication, QWidget,QMessageBox from PySide6.QtGui import QStandardItemModel, QStandardItem # 导入需要的类# Important: # 你需要通过以下指令把 form.ui转为ui…...
:利用图神经网络进行图分类)
动手学图神经网络(4):利用图神经网络进行图分类
利用图神经网络进行图分类:从理论到实践 引言 在之前的学习中,大家了解了如何使用图神经网络(GNNs)进行节点分类。本次教程将深入探讨如何运用 GNNs 解决图分类问题。图分类是指在给定一个图数据集的情况下,根据图的一些结构属性对整个图进行分类,而不是对图中的节点进…...

考公学习追踪器:用数据驱动备考,打造个人学习仪表盘
1. 项目概述:一个为“考公”学子量身定制的学习追踪器如果你正在准备公务员考试,或者身边有朋友在“考公”,那你一定对那种“学了忘,忘了学”的循环深有体会。行测的题海、申论的素材、时政的热点,每天的学习任务像一座…...

3分钟掌握B站视频下载神器BilibiliDown:跨平台免费开源下载工具
3分钟掌握B站视频下载神器BilibiliDown:跨平台免费开源下载工具 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_…...

3分钟搞定!FigmaCN终极中文插件:让英文界面秒变中文的免费神器
3分钟搞定!FigmaCN终极中文插件:让英文界面秒变中文的免费神器 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?专业术…...

三步快速解锁网盘高速下载:LinkSwift直链解析终极指南
三步快速解锁网盘高速下载:LinkSwift直链解析终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...
 (光通信必学必会))
【信息科学与工程学】信息科学领域工程——第二篇 材料工程10 光学材料 (1) (光通信必学必会)
表1:光学材料知识库 第一部分:光学基础理论与数学模型 编号 算法/策略名称和伪代码/数学方程式 核心数学描述/规律 关键参数/变量 物理/化学/工程意义/控制目标 典型应用场景 优点与局限 关联知识连接点 1.1.1 麦克斯韦方程组 ∇D = ρ_f ∇B = 0 ∇E = -∂B/∂t ∇…...

网络通信调试难题的Qt解决方案:mNetAssist深度解析
网络通信调试难题的Qt解决方案:mNetAssist深度解析 【免费下载链接】mNetAssist mNetAssist - A UDP/TCP Assistant 项目地址: https://gitcode.com/gh_mirrors/mn/mNetAssist 网络协议调试过程中,开发者常面临协议兼容性、数据传输验证和连接状态…...

智能助手会话上下文管理:基于向量检索的长期记忆与多技能协作实践
1. 项目概述与核心价值最近在折腾一个基于大语言模型的智能助手项目,发现一个挺有意思的痛点:如何让AI在持续的对话中,不仅能记住当前聊了什么,还能“聪明地”回忆起我们之前讨论过的所有相关背景?比如,你昨…...

透视 Mission Control 源码:如何构建高性能的 Agent 实时监控架构?
在 AI Agent 爆火的当下,我们正从“对话式 AI”迈向“行为式 AI”。然而,当数十个 Agent 同时运行,处理复杂的链上交易或长程任务时,开发者面临的最大挑战往往是:观测性(Observability)。你无法…...

从Excel到Python:用Pandas的fillna优雅处理缺失值,数据分析效率翻倍
从Excel到Python:用Pandas的fillna优雅处理缺失值,数据分析效率翻倍 当你在Excel中处理上千行数据时,是否曾被那些零散的#N/A或空白单元格折磨得焦头烂额?CtrlF查找替换、IFERROR函数嵌套、手动拖拽填充柄...这些操作在小型数据集…...

你的显卡真的在干活吗?Pycharm里用这行代码快速验证PyTorch GPU加速是否生效
你的显卡真的在干活吗?Pycharm里用这行代码快速验证PyTorch GPU加速是否生效 当你在Pycharm中完成了PyTorch GPU版的安装,torch.cuda.is_available()也返回了True,是否就意味着GPU加速已经完美运行?现实情况往往比这复杂得多。很多…...