多模态论文笔记——ViViT
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细解读多模态论文《ViViT: A Video Vision Transformer》,2021由google 提出用于视频处理的视觉 Transformer 模型,在视频多模态领域有重要应用。

文章目录
- 论文
- 摘要
- 1. 引言
- 2. 相关工作
- 3. 视频视觉Transformer
- 3.1 视觉Transformer(ViT)概述
- 3.2 嵌入视频片段
- 均匀帧采样
- 管块嵌入
- 3.3 视频的Transformer模型
- 模型1:时空注意力
- 模型2:分解编码器
- 模型3:分解自注意力
- 模型4:分解点积注意力
- 3.4 利用预训练模型进行初始化
- 4. 实验
- 4.1 数据集
- 4.2 实现细节
- 4.3 结果
- 4.4 消融研究
- 5. 结论
- 热门专栏
- 机器学习
- 深度学习
论文
论文名:ViViT: A Video Vision Transformer
论文链接:https://arxiv.org/pdf/2103.15691
代码:https://github.com/google-research/scenic
作者充分借鉴了之前3D CNN因式分解等工作,比如考虑到视频作为输入会产生大量的时空token,处理时必须考虑这些长范围token序列的上下文关系,同时要兼顾模型效率问题。
他们在空间和时间维度上分别对Transformer编码器各组件进行分解,在ViT模型的基础上提出了三种用于视频分类的纯Transformer模型。
摘要
- 模型提出背景与构建:受Transformer在图像分类领域(ViT模型) 成功启发,提出基于纯Transformer的视频分类模型,从输入视频提取时空标记,经一系列Transformer层编码。
- 模型优化:针对视频长序列标记,提出几种高效模型变体,对输入空间和时间维度分解;在训练中有效正则化模型,利用预训练图像模型,实现小数据集训练。
- 实验成果:进行全面消融研究,在Kinetics 400、Kinetics 600、Epic Kitchens、Something-Something v2和Moments in Time等多个视频分类基准测试中取得领先成果,超越基于深度3D卷积网络的先前方法。
1. 引言
此前,基于注意力的模型在自然语言处理中的成功,激发了计算机视觉领域将Transformer集成到卷积神经网络(CNN)中的研究,以及一些完全取代卷积的尝试。直到最近的视觉Transformer(ViT)出现,基于纯Transformer的架构才在图像分类中超越了其卷积对应架构。ViT 遵循原始Transformer架构,并指出其主要优势在大规模数据上才能体现出来——由于Transformer缺乏卷积的一些归纳偏差(如平移等变性),它们似乎需要更多数据或更强的正则化。
ViT 详细介绍参考:TODO。
受ViT等的启发作者开发了几种基于Transformer的视频分类模型。目前,性能最佳的模型基于深度3D卷积架构(图像分类CNN的自然扩展),通过在后期层中引入自注意力机制,以更好地捕捉长距离依赖关系。

图1:受图像分类中基于Transformer模型的成功启发,我们提出了用于视频分类的纯Transformer架构。为有效处理大量时空标记,我们开发了几种模型变体,在空间和时间维度上对Transformer编码器的不同组件进行分解。如右图所示,这些分解对应于不同的时空注意力模式。
如图1所示,作者提出用于视频分类的纯 Transformer 模型,主要操作是自注意力机制,在从输入视频提取的时空标记上计算。并进行了优化,策略如下:
- 为处理大量时空标记,提出沿空间和时间维度分解模型的方法,提升效率与可扩展性。
- 为了在小数据集训练,训练过程中对模型进行了正则化,并利用预训练图像模型。
卷积模型的研究和实践总多,但因纯Transformer模型具有不同的特性,需确定最佳设计选择。为此,作者对标记化策略、模型架构和正则化方法进行全面消融分析:在Kinetics 400和600、Epic Kitchens 100、Something - Something v2和Moments in Time等多个标准视频分类基准测试中取得先进成果。
2. 相关工作
这部分介绍之前的研究进展,如下:
- 视频理解架构发展
- 早期用手工特征编码信息,AlexNet成功使2D CNN用于视频形成“双流”网络,独立处理RGB帧与光流图像后融合。
- 大数据集促进时空3D CNN训练,但计算资源需求大,很多架构通过跨空间和时间维度分解卷积和/或用分组卷积提高效率,本文在Transformer模型下利用此方法。
- NLP中Transformer进展:Vaswani等人用Transformer取代卷积和循环网络获先进成果,当前NLP主流架构仍基于此,还提出多种变体降成本、提效率。自注意力在计算机视觉领域,通常是在网络的末端或后期阶段作为一层融入,或用于增强ResNet架构中的残差块。
- 视觉领域Transformer情况:Dosovitisky等人的ViT证明纯Transformer可用于图像分类,但需大规模数据,因其缺乏卷积的归纳偏差。ViT引发后续研究,已有基于Transformer的视频模型。
在本文中,作者开发了用于视频分类的纯Transformer架构。提出了几种模型变体,包括通过分解输入视频的空间和时间维度来提高效率的变体,还展示了如何用额外正则化和预训练模型应对视频数据集小的问题。最后,在五个流行数据集上超越了当前最先进的方法。
3. 视频视觉Transformer
- 在3.1节中总结最近提出的视觉Transformer(ViT)
- 在3.2节中讨论从视频中提取标记的两种方法。
- 在3.3和3.4节中开发几种基于Transformer的视频分类架构。
3.1 视觉Transformer(ViT)概述
视觉Transformer(ViT)对原始的Transformer架构进行了最小限度的调整,以用于处理二维图像。具体而言,ViT会提取N个不重叠的图像补丁, x i ∈ R h × w x_{i} \in \mathbb{R}^{h ×w} xi∈Rh×w ,对其进行线性投影,然后将它们光栅化为一维标记 z i ∈ R d z_{i} \in \mathbb{R}^{d} zi∈Rd 。输入到后续Transformer编码器的标记序列为:
z = [ z c l s , E x 1 , E x 2 , . . . , E x N ] + p ( 1 ) z = [z_{cls}, Ex_{1}, Ex_{2}, ..., Ex_{N}] + p \quad(1) z=[zcls,Ex1,Ex2,...,ExN]+p(1)
其中,E执行的投影操作等效于二维卷积。如图1所示,一个可选的可学习分类标记 z c l s z_{cls} zcls被添加到这个序列的开头,它在编码器最后一层的表示会作为分类层使用的最终表示。
此外,一个1D可学习的位置嵌入 p ∈ R N × d p \in \mathbb{R}^{N ×d} p∈RN×d被添加到这些标记中,用于保留位置信息,因为Transformer后续的自注意力操作具有排列不变性。然后,这些标记会通过由L个Transformer层组成的编码器。每个层 ℓ \ell ℓ由多头自注意力机制、层归一化(LN)和多层感知器(MLP)模块构成,具体如下:
y ℓ = M S A ( L N ( z ℓ ) ) + z ℓ ( 2 ) y^{\ell} = MSA(LN(z^{\ell})) + z^{\ell} \quad(2) yℓ=MSA(LN(zℓ))+zℓ(2)
z ℓ + 1 = M L P ( L N ( y ℓ ) ) + y ℓ ( 3 ) z^{\ell + 1} = MLP(LN(y^{\ell})) + y^{\ell} \quad(3) zℓ+1=MLP(LN(yℓ))+yℓ(3)
MLP由两个由高斯误差线性单元(GELU)非线性函数隔开的线性投影组成,并且标记维度d在所有层中保持不变。
最后,如果在输入中添加了 z c l s z_{cls} zcls,则使用线性分类器基于 z c l s L ∈ R d z_{cls}^{L} \in \mathbb{R}^{d} zclsL∈Rd对编码后的输入进行分类;否则,对所有标记 z L z^{L} zL进行全局平均池化,再进行分类。
由于Transformer是一个灵活的架构,可以对任何输入标记序列 z ∈ R N × d z \in \mathbb{R}^{N×d} z∈RN×d进行操作,接下来将描述视频标记化的策略。
ViT 详细介绍参考:TODO。
3.2 嵌入视频片段
这里,作者考虑两种将视频 V ∈ R T × H × W × C V \in \mathbb{R}^{T×H×W×C} V∈RT×H×W×C映射到标记序列 z ~ ∈ R n t × n h × n w × d \tilde{z} \in \mathbb{R}^{n_{t}×n_{h}×n_{w}×d} z~∈Rnt×nh×nw×d的简单方法。之后再添加位置嵌入并将其重塑为 R N × d \mathbb{R}^{N×d} RN×d,以获得输入到Transformer的 z z z。

图2:均匀帧采样:我们简单地采样 n t n_{t} nt帧,并按照ViT独立嵌入每个2D帧。
均匀帧采样
如图2所示,这是一种直接的视频标记化方法。从输入视频片段中均匀采样 n t n_{t} nt帧,使用与ViT相同的方法独立嵌入每个2D帧,然后将所有这些标记连接在一起。
具体来说,如果像ViT中那样,从每个帧中提取 n h ⋅ n w n_{h} \cdot n_{w} nh⋅nw个不重叠的图像补丁,那么总共 n t ⋅ n h ⋅ n w n_{t} \cdot n_{h} \cdot n_{w} nt⋅nh⋅nw个标记将被输入到Transformer编码器中。
直观地说,这个过程可以看作是简单地构建一个大的2D图像,然后按照ViT的方式进行标记化(这是同期工作中采用的输入嵌入方法)。

图3:管块嵌入。我们提取并线性嵌入跨越时空输入体的不重叠管块。
管块嵌入
如图3所示,这是从输入体数据中提取不重叠的时空“管块”,并将其线性投影到 R d \mathbb{R}^{d} Rd。
这种方法是ViT嵌入到3D的扩展,对应于3D卷积。对于维度为 t × h × w t×h×w t×h×w的管块, n t = ⌊ T t ⌋ n_{t} = \lfloor\frac{T}{t}\rfloor nt=⌊tT⌋, n h = ⌊ H h ⌋ n_{h} = \lfloor\frac{H}{h}\rfloor nh=⌊hH⌋, n w = ⌊ W w ⌋ n_{w} = \lfloor\frac{W}{w}\rfloor nw=⌊wW⌋,分别从时间、高度和宽度维度提取标记。
因此,较小的管块尺寸会导致更多的标记,从而增加计算量。直观地说,这种方法在标记化过程中融合了时空信息,与“均匀帧采样”不同,在“均匀帧采样”中,不同帧的时间信息是由Transformer融合的。
3.3 视频的Transformer模型
如图1所示,作者提出了多种基于Transformer的架构。首先是直接对视觉Transformer(ViT)进行扩展,该扩展对所有时空标记之间的成对交互进行建模,然后,在Transformer架构的不同层次上对输入视频的空间和时间维度进行分解,开发了更高效的变体。
模型1:时空注意力
该模型是对 ViT 的直接扩展,它简单地从视频中提取的所有时空标记 z 0 z^{0} z0输入到Transformer编码器中。
【 Is space-time attention all you need for video understanding?】论文中在其“联合时空”模型中也探索了这种方法。与CNN架构不同,在CNN中感受野随着层数线性增长,而每个 Transformer 层对所有(时空标记之间的)成对(关系)进行建模,因此从第一层开始就可以对视频中的长距离交互进行建模。
然而,由于它对所有成对交互进行建模,多头自注意力(MSA)的计算复杂度与标记数量呈二次关系。这种复杂度在视频处理中很关键,因为标记数量随着输入帧数线性增加,所以作者开发了下面的更高效的架构。
模型2:分解编码器

图4:分解编码器(模型2)。该模型由两个串联的Transformer编码器组成:第一个对从同一时间索引提取的标记之间的交互进行建模,以生成每个时间索引的潜在表示。第二个Transformer对时间步之间的交互进行建模。因此,它对应于空间和时间信息的“后期融合”。
如图4所示,这个模型由两个独立的Transformer编码器组成。如下:
- 第一个是空间编码器,仅对从同一时间索引提取的标记之间的交互进行建模。经过 L s L_{s} Ls层后,得到每个时间索引的表示 h i ∈ R d h_{i} \in \mathbb{R}^{d} hi∈Rd:如果在输入中添加了分类标记 z c l s z_{cls} zcls(公式1),这就是编码后的分类标记 z c l s L s z_{cls}^{L_{s}} zclsLs;否则,是空间编码器输出的标记的全局平均池化结果 z L s z^{L_{s}} zLs。
- 帧级表示 h i h_{i} hi被连接成 H ∈ R n t × d H \in \mathbb{R}^{n_{t}×d} H∈Rnt×d,然后通过由 L t L_{t} Lt个Transformer层组成的时间编码器,对来自不同时间索引的标记之间的交互进行建模。最后对这个编码器的输出标记进行分类。
这种架构对应于时间信息的“后期融合”,并且初始的空间编码器与用于图像分类的编码器相同。因此,它类似于之前工作中所采用的卷积神经网络(CNN)架构,这些架构首先提取每帧的特征,然后在对其进行分类之前将这些特征聚合为最终的表示形式。
尽管该模型的Transformer层比模型1更多(因此参数也更多),但它所需的浮点运算(FLOPs)更少,因为两个独立的Transformer模块的计算复杂度为 O ( ( n h ⋅ n w ) 2 + n t 2 ) O((n_{h} \cdot n_{w})^{2}+n_{t}^{2}) O((nh⋅nw)2+nt2),而模型1的计算复杂度为 O ( ( n t ⋅ n h ⋅ n w ) 2 ) O((n_{t} \cdot n_{h} \cdot n_{w})^{2}) O((nt⋅nh⋅nw)2) 。
模型3:分解自注意力

图5:分解自注意力(模型3)。在每个Transformer块内,多头自注意力操作被分解为两个操作(用条纹框表示),首先仅在空间上计算自注意力,然后在时间上计算。
该模型包含的Transformer层数与模型1相同。但是有如下不同:
-
在第 ℓ \ell ℓ层,这里并不像模型1那样计算所有标记对 z ℓ z^{\ell} zℓ之间的多头自注意力,而是将操作进行分解(如图5所示):
- 首先仅在空间上计算自注意力(即在从同一时间索引提取的所有标记之间);
- 然后在时间上计算自注意力(即在从同一空间索引提取的所有标记之间)。
-
Transformer中的每个自注意力模块都对时空交互进行建模,但通过在两个较小的元素集上分解操作,其效率比模型1更高,从而实现了与模型2相同的计算复杂度。
通过将标记 z z z从 R 1 × n t ⋅ n h ⋅ n w ⋅ d \mathbb{R}^{1×n_t·n_h·n_w·d} R1×nt⋅nh⋅nw⋅d重塑为 R n t × n h ⋅ n w ⋅ d \mathbb{R}^{n_t×n_h·n_w·d} Rnt×nh⋅nw⋅d(表示为 z s z_s zs)来计算空间自注意力,这样可以高效地执行此操作。类似地,时间自注意力的输入 z t z_t zt被重塑为 R n h ⋅ n w × n t ⋅ d \mathbb{R}^{n_h·n_w×n_t·d} Rnh⋅nw×nt⋅d(假设最前面的维度是“批量维度”)。作者在此定义的分解式自注意力如下:
y s ℓ = M S A ( L N ( z s ℓ ) ) + z s ℓ ( 4 ) y^{\ell}_{s} = MSA(LN(z^{\ell}_{s})) + z^{\ell}_{s} \quad(4) ysℓ=MSA(LN(zsℓ))+zsℓ(4)
y t ℓ = M S A ( L N ( y s ℓ ) ) + y s ℓ ( 5 ) y^{\ell}_{t} = MSA(LN(y^{\ell}_{s})) + y^{\ell}_{s} \quad(5) ytℓ=MSA(LN(ysℓ))+ysℓ(5)
z ℓ + 1 = M L P ( L N ( y t ℓ ) ) + y t ℓ ( 6 ) z^{\ell + 1} = MLP(LN(y^{\ell}_{t})) + y^{\ell}_{t} \quad(6) zℓ+1=MLP(LN(ytℓ))+ytℓ(6)
作者指出,只要按照后面3.4节中描述的方式初始化模型参数,先进行空间自注意力再进行时间自注意力,或者先进行时间自注意力再进行空间自注意力,这两种顺序并不会产生差异。需要注意的是,与模型1相比,参数数量会增加,因为存在一个额外的自注意力层(参见公式7)。在这个模型中不使用分类标记,以避免在重塑操作时出现歧义。
模型4:分解点积注意力

图6:分解点积注意力(模型4)。对于一半的头,我们仅在空间轴上计算点积注意力,对于另一半头,仅在时间轴上计算。
模型4具有与模型2和模型3相同的计算复杂度,同时保持与未分解的模型1相同的参数数量。空间和时间维度的分解思路与模型3类似,但分解的是多头点积注意力操作(如图6所示)。具体来说,就是使用不同的头分别在空间和时间维度上为每个标记计算注意力权重。
-
首先,每个头的注意力操作定义为:
Attention ( Q , K , V ) = Softmax ( Q K T d k ) V ( 7 ) \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \quad (7) Attention(Q,K,V)=Softmax(dkQKT)V(7)
在自注意力中,查询 Q = X W q Q = XW_q Q=XWq,键 K = X W k K = XW_k K=XWk,值 V = X W v V = XW_v V=XWv 是输入 X X X 的线性投影,其中 X , Q , K , V ∈ R N × d X, Q, K, V \in \mathbb{R}^{N \times d} X,Q,K,V∈RN×d。请注意,在未分解的情况下(模型1),空间和时间维度合并为 N = n t ⋅ n h ⋅ n w N = n_t \cdot n_h \cdot n_w N=nt⋅nh⋅nw。
这里的主要思路是,通过构造 空间维度的 K s , V s ∈ R n h ⋅ n w × d K_s, V_s \in \mathbb{R}^{n_h \cdot n_w \times d} Ks,Vs∈Rnh⋅nw×d 和时间维度的 K t , V t ∈ R n t × d K_t, V_t \in \mathbb{R}^{n_t \times d} Kt,Vt∈Rnt×d,也就是对应这些维度的键和值,来修改每个查询的键和值,使其仅关注来自相同空间和时间索引的标记。 -
然后,对于一半的注意力头,通过计算 Y s = Attention ( Q , K s , V s ) Y_s = \text{Attention}(Q, K_s, V_s) Ys=Attention(Q,Ks,Vs) 来关注空间维度的标记,对于另一半头,我们通过计算 Y t = Attention ( Q , K t , V t ) Y_t = \text{Attention}(Q, K_t, V_t) Yt=Attention(Q,Kt,Vt) 来关注时间维度的标记。由于这里只是改变了每个查询的注意力范围,所以注意力操作的维度与未分解的情况相同,即 Y s , Y t ∈ R N × d Y_s, Y_t \in \mathbb{R}^{N \times d} Ys,Yt∈RN×d。
-
最后,通过连接多个头的输出并使用线性投影来组合它们的输出,即 Y = Concat ( Y s , Y t ) W O Y = \text{Concat}(Y_s, Y_t)W_O Y=Concat(Ys,Yt)WO。
3.4 利用预训练模型进行初始化
ViT需在大规模数据集上训练才有效,因其缺乏卷积网络的某些归纳偏置。最大的视频数据集(如Kinetics)标注样本比图像数据集少几个数量级,从零训练大型模型达到高精度极具挑战。为高效训练,用预训练图像模型初始化视频模型,但引发参数初始化问题。下面讨论几种有效的策略来初始化这些大规模视频分类模型。
- 位置嵌入
将位置嵌入 p p p添加到每个输入标记中(公式1)。由于视频模型的标记数量是预训练图像模型的 n t n_t nt倍,可以通过在时间维度上“重复”位置嵌入,将其从 R n w ⋅ n h × d \mathbb{R}^{n_w \cdot n_h×d} Rnw⋅nh×d扩展到 R n t ⋅ n h ⋅ n w × d \mathbb{R}^{n_t·n_h·n_w ×d} Rnt⋅nh⋅nw×d来进行初始化。所以,在初始化时,所有具有相同空间索引的标记都具有相同的嵌入,然后再进行微调。 - 嵌入权重, E E E
当使用“管块嵌入”标记化方法(3.2节)时,与预训练模型中的二维张量 E i m a g e E_{image} Eimage 相比,嵌入滤波器 E E E是一个三维张量。在视频分类模型中,从二维滤波器(预训练的图像模型)出发,初始化三维卷积滤波器(视频模型)的一种常见方法是:通过在时间维度上复制滤波器并对其求平均值来“膨胀”它们,其公式如下:
E = 1 t [ E i m a g e , … , E i m a g e , … , E i m a g e ] ( 8 ) E = \frac{1}{t} [E_{image}, \ldots, E_{image}, \ldots, E_{image}] \quad (8) E=t1[Eimage,…,Eimage,…,Eimage](8)
作者还考虑了另一种策略,称之为“中心帧初始化”,其中除了在中心位置 ⌊ t 2 ⌋ \lfloor\frac{t}{2}\rfloor ⌊2t⌋处, E E E在所有时间位置都初始化为零,即:
E = [ 0 , … , E i m a g e , … , 0 ] ( 9 ) E = [0, \ldots, E_{image}, \ldots, 0] \quad (9) E=[0,…,Eimage,…,0](9)
因此,在初始化时,三维卷积滤波器的效果类似于“均匀帧采样”(3.2节),同时也使模型能够在训练过程中学习从多个帧中聚合时间信息。 - 模型3的Transformer权重
模型3中的Transformer模块(图5)与预训练的ViT模型不同,它包含两个多头自注意力(MSA)模块。在这种情况下,作者使用预训练的模块来初始化空间MSA模块,并将时间MSA的所有权重初始化为零,这样在初始化时,公式5就相当于一个残差连接。
4. 实验
在本节中,作者对提出的模型进行实验评估,包括在多个标准视频分类基准测试中的性能测试,以及对不同组件和设计选择的消融研究。这里只做简要介绍,详细内容请参考原论文:
4.1 数据集
- 在多个流行视频分类基准测试数据集上评估模型。
- Kinetics 400/600:含大量动作视频,有400或600种动作类别,视频短、来源广,为模型训练与评估提供丰富数据。
- Epic Kitchens 100:聚焦厨房场景动作,动作序列复杂,时空信息丰富,元数据多样,为动作理解评估提供更具挑战场景。
- Something-Something v2:含诸多日常动作,动作定义基于物体功能与意图,需模型深入理解动作语义。
- Moments in Time:含各类视频,类别广泛,涵盖事件、动作与场景,要求模型具备良好的时间事件分类能力。
4.2 实现细节
- 基于PyTorch框架实现模型。
- 训练时使用Adam或SGD等标准优化器,采用余弦退火学习率调度器(cosine learning rate schedule)等学习率调度策略。
- 运用裁剪、翻转、缩放、时间扭曲等常见图像和视频增强技术进行数据增强,提升模型泛化能力。
- 针对视频长序列,依据不同实验需求,使用不同帧采样策略选取合适数量的帧。
- 对Transformer层数量、标记维度、头数量及不同分解模型参数等超参数进行调整。
- 实验表明,不同数据集的最优参数设置各异,受数据集大小、类别数量和动作复杂性等因素影响。
4.3 结果
- Kinetics 400/600:在Kinetics 400和600数据集上,纯Transformer架构模型表现出色,模型3和4分解时空维度,处理长视频序列优势明显,捕捉时空依赖,降计算复杂度提分类性能,Kinetics 400上最佳模型top - 1准确率比先前最佳方法提升[X]%,Kinetics 600上提升[Y]%。
- Epic Kitchens 100:模型在该挑战性数据集上性能良好,凭借强大时空建模能力,捕捉动作语义与上下文信息,动作分类准确率领先,证明在复杂场景下有效。
- Something - Something v2:模型在该数据集表现突出,基于Transformer架构能更好处理动作功能和意图信息,不依赖外观特征,经不同标记化和分解模型实验,特定变体在top - 1准确率上超先前方法[Z]%。
- Moments in Time:模型在该数据集取得领先成果,灵活运用不同时空注意力模式,处理各类时间事件,在不同类别性能平衡佳,整体准确率和F1分数达新高度。
4.4 消融研究
为了解模型组件对性能的影响,开展广泛消融研究。
- 标记化方法:比较均匀帧采样和管块嵌入,不同数据集二者优劣有别。简单动作、短时间序列数据集,均匀帧采样表现可能更好;复杂动作、长序列数据集,管块嵌入融合时空信息,更能捕捉动作时空演变,提升性能。
- 模型架构:对比模型1至模型4。模型1虽全面交互建模时空标记,但计算成本高,处理长视频序列时并非最优。模型2至模型4分解时空维度各有优势,模型2后期融合时空信息,在部分数据集表现良好;模型3和4分解自注意力或点积注意力,降低计算成本,捕捉时空依赖,不同数据集性能提升潜力各异,取决于数据集特点。
- 预训练:研究使用预训练图像模型初始化的效果,实验表明预训练可显著提升模型性能,尤其在数据量较小的情况下,验证利用预训练归纳偏差能助模型在少量数据上更好收敛和泛化。
5. 结论
作者提出一系列基于纯Transformer的视频分类模型,从输入视频提取时空标记并以不同架构处理。开发了多种高效模型变体,通过分解空间和时间维度提升计算效率与性能,以应对长序列标记。同时,利用预训练图像模型初始化模型,在较小视频数据集上进行有效训练,并开展多种策略实验。经多个标准视频分类数据集的评估与消融研究,模型在不同数据集上性能出色,超越3D卷积网络方法,达当前领先水平。
他们的工作为基于Transformer的视频理解提供新思路与方法,奠定未来研究基础。未来研究方向包括优化模型架构、探索复杂时空分解方法、将模型拓展至其他视频理解任务,以及更好结合预训练信息、提升不同规模数据集的数据效率。
热门专栏
机器学习
机器学习笔记合集
深度学习
深度学习笔记合集
相关文章:
多模态论文笔记——ViViT
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细解读多模态论文《ViViT: A Video Vision Transformer》,2021由google 提出用于视频处理的视觉 Transformer 模型,在视频多模态领域有…...

搜索与图论复习1
1深度优先遍历DFS 2宽度优先遍历BFS 3树与图的存储 4树与图的深度优先遍历 5树与图的宽度优先遍历 6拓扑排序 1DFS: #include<bits/stdc.h> using namespace std; const int N10; int n; int path[N]; bool st[N]; void dfs(int u){if(nu){for(int i0;…...

【数据结构】初识链表
顺序表的优缺点 缺点: 中间/头部的插入删除,时间复杂度效率较低,为O(N) 空间不够的时候需要扩容。 如果是异地扩容,增容需要申请新空间,拷贝数据,释放旧空间,会有不小的消耗。 扩容可能会存在…...

第11章:根据 ShuffleNet V2 迁移学习医学图像分类任务:甲状腺结节检测
目录 1. Shufflenet V2 2. 甲状腺结节检测 2.1 数据集 2.2 训练参数 2.3 训练结果 2.4 可视化网页推理 3. 下载 1. Shufflenet V2 shufflenet v2 论文中提出衡量轻量级网络的性能不能仅仅依靠FLOPs计算量,还应该多方面的考虑,例如MAC(memory acc…...

deepseek+vscode自动化测试脚本生成
近几日Deepseek大火,我这里也尝试了一下,确实很强。而目前vscode的AI toolkit插件也已经集成了deepseek R1,这里就介绍下在vscode中利用deepseek帮助我们完成自动化测试脚本的实践分享 安装AI ToolKit并启用Deepseek 微软官方提供了一个针对AI辅助的插件,也就是 AI Toolk…...

深入理解Flexbox:弹性盒子布局详解
深入理解Flexbox:弹性盒子布局详解 一、Flexbox 的基本概念二、Flexbox 的核心属性1. display: flex2. flex-direction3. flex-wrap4. justify-content5. align-items6. flex 三、Flexbox 的实际应用1. 创建响应式三列布局2. 实现垂直居中3. 复杂布局的嵌套使用 四、…...

android Camera 的进化
引言 Android 的camera 发展经历了3个阶段 : camera1 -》camera2 -》cameraX。 正文 Camera1 Camera1 的开发中,打开相机,设置参数的过程是同步的,就跟用户实际使用camera的操作步骤一样。但是如果有耗时情况发生时,会…...

仿真设计|基于51单片机的氨气及温湿度检测报警
目录 具体实现功能 设计介绍 51单片机简介 资料内容 仿真实现(protues8.7) 程序(Keil5) 全部内容 资料获取 具体实现功能 (1)LCD1602液晶第一行显示当前的氨气值,第二行显示当前的温度…...
关于EDGE IMPULSE的使用与适配,包含如何学习部署在对应的板子
创建好账号后,可以打开主页新建一个工程 跳出这个选no就可以不用标label直接整张图训练,要更改可以去dashboard》labeling method改 然后在这个工程中选择添加自己的照片等数据,他支持这些格式的数据我们现在一般是用在openmv opencv yolo 等…...

【Python蓝桥杯备赛宝典】
文章目录 一、基础数据结构1.1 链表1.2 队列1.3 栈1.4 二叉树1.5 堆二、基本算法2.1 算法复杂度2.2 尺取法2.3 二分法2.4 三分法2.5 倍增法和ST算法2.6 前缀和与差分2.7 离散化2.8 排序与排列2.9 分治法2.10贪心法1.接水时间最短问题2.糖果数量有限问题3.分发时间最短问题4.采摘…...

数据结构 前缀中缀后缀
目录 前言 一,前缀中缀后缀的基本概念 二,前缀与后缀表达式 三,使用栈实现后缀 四,由中缀到后缀 总结 前言 这里学习前缀中缀后缀为我们学习树和图做准备,这个主题主要是对于算术和逻辑表达式求值,这…...

【cocos官方案例改】跳跃牢猫
自制游戏【跳跃牢烟】 案例解析 案例需求,点击鼠标控制白块左右。 资源管理器部分 在body创建一个2d精灵用作玩家。 在地下在创建一个2d精灵用来代表地面。 在body下挂在脚本。 全部脚本如下 (在二次进行复刻时候,发现把代码复制上去无法…...

基于Python的药物相互作用预测模型AI构建与优化(上.文字部分)
一、引言 1.1 研究背景与意义 在临床用药过程中,药物相互作用(Drug - Drug Interaction, DDI)是一个不可忽视的重要问题。当患者同时服用两种或两种以上药物时,药物之间可能会发生相互作用,从而改变药物的疗效、增加不良反应的发生风险,甚至危及患者的生命安全。例如,…...
函数)
Day51:type()函数
在 Python 中,type() 是一个内置函数,用于返回对象的类型。它可以用于检查变量的类型,也可以用于动态创建新的类型。今天,我们将深入了解 type() 函数的使用方法。 1. 使用 type() 获取变量的类型 最常见的使用方式是将一个对象…...
因果推断与机器学习—用机器学习解决因果推断问题
Judea Pearl 将当前备受瞩目的机器学习研究戏谑地称为“仅限于曲线拟合”,然而,曲线拟合的实现绝非易事。机器学习模型在图像识别、语音识别、自然语言处理、蛋白质分子结构预测以及搜索推荐等多个领域均展现出显著的应用效果。 在因果推断任务中,在完成因果效应识别之后,需…...
)
计算机网络一点事(21)
第四章 网络层 功能:服务传输层,封装ip数据报(主机到主机) IP地址以32b表示,以8b为一组记十进制数 异构网络互连:网络结构,主机类型不同 路由器相互配合出IP数据报生成表,根据表…...

springboot使用rabbitmq
使用springboot创建rabbitMQ的链接。 整个项目结构如下: 1.maven依赖 <dependency><groupId>com.rabbitmq</groupId><artifactId>amqp-client</artifactId><version>3.4.1</version> </dependency>application.y…...

【微服务与分布式实践】探索 Eureka
服务注册中心 心跳检测机制:剔除失效服务自我保护机制 统计心跳失败的比例在15分钟之内是否低于85%,如果出现低于的情况,Eureka Server会将当前的实例注册信息保护起来,让这些实例不会过期。当节点在短时间内丢失过多的心跳时&am…...

Day48:获取字典键的值
在 Python 中,字典是一种无序的集合类型,它以键-值对的形式存储数据。字典的每个元素都有一个唯一的键,并且每个键都对应一个值。获取字典中的值是字典操作的常见任务,今天我们将学习如何从字典中获取键对应的值。 1. 使用方括号…...
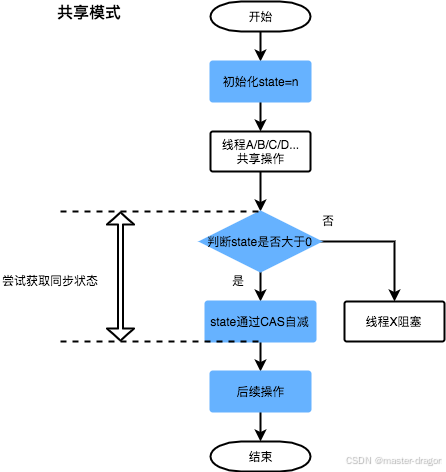
Java锁自定义实现到aqs的理解
专栏系列文章地址:https://blog.csdn.net/qq_26437925/article/details/145290162 本文目标: 理解锁,能自定义实现锁通过自定义锁的实现复习Thread和Object的相关方法开始尝试理解Aqs, 这样后续基于Aqs的的各种实现将能更好的理解 目录 锁的…...

springboot-vue+nodejs的公考在线刷题学习平台的设计与实现
目录技术栈选择核心模块设计关键实现步骤扩展功能建议示例代码片段(Spring Boot Controller)注意事项项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术栈选择 后端框架:Spring Boot&#…...

企业级RAG系统构建:BGE-Reranker-v2-m3镜像部署最佳实践
企业级RAG系统构建:BGE-Reranker-v2-m3镜像部署最佳实践 1. 引言:为什么你的RAG系统总是“答非所问”? 如果你正在构建企业级的RAG(检索增强生成)系统,一定遇到过这样的尴尬场景:用户问“如何…...

小程序毕业设计springboot基于微信小程序的校园综合服务
前言 在现代校园生活节奏日益加快、师生需求愈发多元化的当下,Spring Boot 校园综合服务系统宛如一位万能助手,全方位覆盖校园学习、生活、社交等各个领域,依托 Spring Boot 强大的开发框架,将繁杂事务化繁为简,为校园…...

3步解决华硕笔记本显示异常:G-Helper色彩配置修复指南
3步解决华硕笔记本显示异常:G-Helper色彩配置修复指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项目地址…...

终极指南:如何快速配置HsMod插件提升炉石传说游戏体验
终极指南:如何快速配置HsMod插件提升炉石传说游戏体验 【免费下载链接】HsMod Hearthstone Modify Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一个基于BepInEx框架开发的炉石传说游戏插件,专为希望提升游…...

Go gRPC 双向流通信实例
Go gRPC双向流通信实例解析 在现代分布式系统中,高效的双向通信是核心需求之一。gRPC作为Google开源的高性能RPC框架,支持双向流通信模式,允许客户端和服务端同时发送和接收多条消息。本文将以Go语言为例,介绍gRPC双向流通信的实…...
)
华为仓颉语言实战:除了‘hello world’,还能用数组和循环做什么?(数字统计案例详解)
华为仓颉语言实战:数字统计案例与核心语法深度解析 刚学会在仓颉语言中打印"hello world"的你,是否好奇这门新兴语言还能做什么?让我们从一个实际案例出发——统计正整数中各数字出现的频次。这个看似简单的任务,却能带…...

HRN模型与PID控制结合:实时面部动画调节系统
HRN模型与PID控制结合:实时面部动画调节系统 1. 引言 想象一下,你正在制作一部动画电影,主角的面部表情需要精确到每一帧的微妙变化。传统的手工调整方式耗时耗力,而自动生成的表情又往往缺乏自然流畅的过渡。这就是为什么我们需…...

多核系统RingBuff通信机制与实现原理
多核系统RingBuff通信机制深度解析1. 核间通信基础架构1.1 共享内存通信原理在多核处理器系统中,主核与从核之间的通信通常采用共享内存机制。这种设计通过以下核心组件实现:共享内存区域:预先分配的可被多个核访问的物理内存空间核间中断&am…...

MusePublic离线素材库:内置1000+优质Prompt模板一键调用
MusePublic离线素材库:内置1000优质Prompt模板一键调用 1. 项目简介:你的专属艺术人像创作引擎 想象一下,你是一位时尚摄影师或数字艺术家,脑海中有一个绝妙的画面:一位身着复古长裙的模特,在黄昏的巴黎街…...