当卷积神经网络遇上AI编译器:TVM自动调优深度解析
从铜线到指令:硬件如何"消化"卷积
在深度学习的世界里,卷积层就像人体中的毛细血管——数量庞大且至关重要。但鲜有人知,一个简单的3x3卷积在CPU上的执行路径,堪比北京地铁线路图般复杂。
卷积的数学本质
对于输入张量 X ∈ R N × C i n × H × W X \in \mathbb{R}^{N\times C_{in}\times H\times W} X∈RN×Cin×H×W和卷积核 W ∈ R C o u t × C i n × K h × K w W \in \mathbb{R}^{C_{out}\times C_{in}\times K_h\times K_w} W∈RCout×Cin×Kh×Kw,标准卷积运算可表示为:
Y n , c o u t , h , w = ∑ c i n = 0 C i n − 1 ∑ i = 0 K h − 1 ∑ j = 0 K w − 1 X n , c i n , h ⋅ s h + i − p h , w ⋅ s w + j − p w ⋅ W c o u t , c i n , i , j Y_{n,c_{out},h,w} = \sum_{c_{in}=0}^{C_{in}-1} \sum_{i=0}^{K_h-1} \sum_{j=0}^{K_w-1} X_{n,c_{in},h \cdot s_h + i - p_h, w \cdot s_w + j - p_w} \cdot W_{c_{out},c_{in},i,j} Yn,cout,h,w=cin=0∑Cin−1i=0∑Kh−1j=0∑Kw−1Xn,cin,h⋅sh+i−ph,w⋅sw+j−pw⋅Wcout,cin,i,j
这串看似简单的公式,在实际硬件执行时却要经历缓存争夺战、指令流水线阻塞、SIMD通道利用率不足等九重考验。
CPU的隐秘角落
现代x86 CPU的L1缓存通常只有32KB。当处理224x224的大尺寸特征图时,就像试图用汤匙舀干泳池的水。此时分块策略(tiling) 的重要性便凸显出来——它决定了数据如何在缓存间"轮转"。

(图:CPU三级缓存结构)
TVM:深度学习的"编译器革命"
传统深度学习框架如TensorFlow/PyTorch,就像只会做固定菜式的自动炒菜机。而TVM(Tensor Virtual Machine)则是配备了米其林主厨思维的智能厨房,能将计算图转化为针对特定硬件优化的机器代码。
AutoTVM的工作机制
TVM的自动调优系统包含一个精妙的探索-利用平衡:
- Schedule模板:定义可能的分块、展开、向量化等操作
- 成本模型:预测某配置的性能表现
- 搜索算法:采用模拟退火/遗传算法探索参数空间
# TVM自动调优示例代码(附中文注释)
import tvm
from tvm import autotvm# 定义卷积计算模板
@autotvm.template("conv2d_nchwc")
def conv2d_nchwc():# 输入张量定义N, C, H, W = 1, 3, 224, 224K, _, R, S = 64, 3, 7, 7data = tvm.placeholder((N, C, H, W), name="data")kernel = tvm.placeholder((K, C, R, S), name="kernel")# 创建默认调度conv = topi.nn.conv2d_nchw(data, kernel, stride=2, padding=3)s = tvm.create_schedule(conv.op)# 配置搜索空间cfg = autotvm.get_config()cfg.define_split("tile_ic", C, num_outputs=2) # 输入通道分块cfg.define_split("tile_oc", K, num_outputs=2) # 输出通道分块cfg.define_split("tile_ow", W // 2, num_outputs=2) # 输出宽度分块cfg.define_knob("unroll_kw", [True, False]) # 是否展开核宽循环return s, [data, kernel, conv]
Schedule原语详解
TVM提供了一组类汇编指令的优化原语,这些原语的组合决定了计算的"舞蹈步伐":
| 原语 | 作用 | 硬件影响 |
|---|---|---|
| split | 将维度拆分为子维度 | 提高缓存局部性 |
| tile | 多维分块 | 适配多级缓存结构 |
| unroll | 循环展开 | 减少分支预测开销 |
| vectorize | 向量化 | 激活SIMD指令集 |
| parallel | 多线程并行 | 利用多核架构 |
解剖一份调优报告
让我们回到用户提供的调优数据,解密其中隐藏的优化密码。
典型配置对比
选取两条具有代表性的记录:
// 记录81:优秀配置
{"config": {"entity": [["tile_ic", "sp", [-1, 3]],["tile_oc", "sp", [-1, 32]],["tile_ow", "sp", [-1, 7]], ["unroll_kw", "ot", true]]},"result": [[0.0032527687], ...]
}// 记录251:次优配置
{"config": {"entity": [["tile_ic", "sp", [-1, 3]],["tile_oc", "sp", [-1, 64]],["tile_ow", "sp", [-1, 8]],["unroll_kw", "ot", false]]},"result": [[0.004561739899999999], ...]
}
分块策略的蝴蝶效应
- tile_oc=32 vs 64:较小的输出通道分块(32)使得每个计算块正好占满L1缓存线(32KB),而64会导致缓存颠簸
- tile_ow=7的玄机:224的宽度被划分为32个7x7块,完美对齐SIMD的256-bit寄存器(每个寄存器可存8个float32)
循环展开的隐藏代价
unroll_kw=true时,编译器会展开卷积核宽度循环:
// 未展开的循环
for (int kw = 0; kw < 7; ++kw) {// 计算逻辑
}// 展开后的循环
compute_kw0();
compute_kw1();
...
compute_kw6();
这消除了循环控制开销,但增加了指令缓存压力。当分块过大时,展开反而会导致性能下降。
优化艺术:在约束中寻找最优解
通过分析数百条调优记录,笔者总结出卷积优化的"黄金法则":
三维平衡法则
性能 = min t i l e ( 计算强度 缓存缺失率 × 指令开销 ) \text{性能} = \min_{tile} \left( \frac{\text{计算强度}}{ \text{缓存缺失率} \times \text{指令开销} } \right) 性能=tilemin(缓存缺失率×指令开销计算强度)
其中计算强度指每字节内存访问进行的计算量,可通过TVM的Ansor自动调度器量化。
分块尺寸的量子化
理想分块尺寸应满足:
( t i l e i c × t i l e o h × t i l e o w × d t y p e _ s i z e ) ≤ L 1 _ c a c h e _ s i z e (tile_{ic} \times tile_{oh} \times tile_{ow} \times dtype\_size) \leq L1\_cache\_size (tileic×tileoh×tileow×dtype_size)≤L1_cache_size
对于float32和32KB L1缓存:
t i l e i c × t i l e o h × t i l e o w ≤ 8192 tile_{ic} \times tile_{oh} \times tile_{ow} \leq 8192 tileic×tileoh×tileow≤8192
这解释了为何记录81选择tile_ic=3, tile_ow=7:3x7x32=672 << 8192。
从理论到实践:手把手优化指南
让我们用TVM Python API实现一个自动优化的工作流:
def optimize_conv():# 步骤1:定义计算N, C, H, W = 1, 3, 224, 224K, _, R, S = 64, 3, 7, 7data = tvm.placeholder((N, C, H, W), name="data")kernel = tvm.placeholder((K, C, R, S), name="kernel")conv = topi.nn.conv2d_nchw(data, kernel, stride=2, padding=3)# 步骤2:创建调优任务task = autotvm.task.create("conv2d_nchwc", args=(data, kernel), target="llvm")print(task.config_space) # 打印可调参数# 步骤3:配置调优器measure_option = autotvm.measure_option(builder=autotvm.LocalBuilder(),runner=autotvm.LocalRunner(repeat=3, number=10))# 步骤4:启动自动搜索tuner = autotvm.tuner.XGBTuner(task)tuner.tune(n_trial=50, measure_option=measure_option,callbacks=[autotvm.callback.log_to_file("conv.log")])# 应用最佳配置with autotvm.apply_history_best("conv.log"):with tvm.target.build_config():s, args = conv2d_nchwc()func = tvm.build(s, args, target="llvm")# 验证结果dev = tvm.cpu()data_np = np.random.uniform(size=(N, C, H, W)).astype("float32")kernel_np = np.random.uniform(size=(K, C, R, S)).astype("float32")conv_np = topi.testing.conv2d_nchw_python(data_np, kernel_np, 2, 3)data_tvm = tvm.nd.array(data_np, dev)kernel_tvm = tvm.nd.array(kernel_np, dev)conv_tvm = tvm.nd.empty(conv_np.shape, device=dev)func(data_tvm, kernel_tvm, conv_tvm)tvm.testing.assert_allclose(conv_np, conv_tvm.asnumpy(), rtol=1e-3)
关键参数解析:
n_trial=50:通常需要500+次试验才能收敛,此处为演示减少次数XGBTuner:基于XGBoost的智能调优器,比随机搜索快3-5倍log_to_file:保存调优记录供后续分析
未来展望:当编译器学会思考
在测试ResNet-50的卷积层时,笔者发现一个有趣现象:同一优化配置在不同批大小下的性能差异可达10倍。这引出了动态shape优化等前沿课题。
最新研究显示,将强化学习与编译优化结合(如Chameleon),可使搜索效率提升40%。或许不久的将来,我们能看到具备"元学习"能力的编译器,能根据硬件特性自动推导最优调度策略。
结语:优化卷积层的历程,就像在迷宫中寻找隐藏的通道。每次性能的提升,都是对计算机体系结构本质的更深理解。当看到自己的配置使推理速度提升10倍时,那种喜悦,大概就是工程师的"多巴胺时刻"吧。
相关文章:
当卷积神经网络遇上AI编译器:TVM自动调优深度解析
从铜线到指令:硬件如何"消化"卷积 在深度学习的世界里,卷积层就像人体中的毛细血管——数量庞大且至关重要。但鲜有人知,一个简单的3x3卷积在CPU上的执行路径,堪比北京地铁线路图般复杂。 卷积的数学本质 对于输入张…...

《网络编程基础之完成端口模型》
【完成端口模型导读】完成端口模型,算得上是真正的异步网络IO模型吧,相对于其它网络IO模型,操作系统通知我们的时候,要么就是连接已经帮我建立好,客户端套接字帮我们准备好;要么就是数据已经接收完成&#…...

Axure PR 9 旋转效果 设计交互
大家好,我是大明同学。 这期内容,我们将学习Axure中的旋转效果设计与交互技巧。 旋转 创建旋转效果所需的元件 1.打开一个新的 RP 文件并在画布上打开 Page 1。 2.在元件库中拖出一个按钮元件。 创建交互 创建按钮交互状态 1.选中按钮元件…...

完美还是完成?把握好度,辨证看待
完美还是完成? 如果说之前这个答案有争议,那么现在,答案毋庸置疑 ■为什么完美大于完成 ●时间成本: 做事不仅要考虑结果,还要考虑时间和精力,要说十年磨一剑的确质量更好,但是现实没有那么多…...

C++的类Class
文章目录 一、C的struct和C的类的区别二、关于OOP三、举例:一个商品类CGoods四、构造函数和析构函数1、定义一个顺序栈2、用构造和析构代替s.init(5);和s.release();3、在不同内存区域构造对象4、深拷贝和浅拷贝5、构造函数和深拷贝的简单应用6、构造函数的初始化列…...
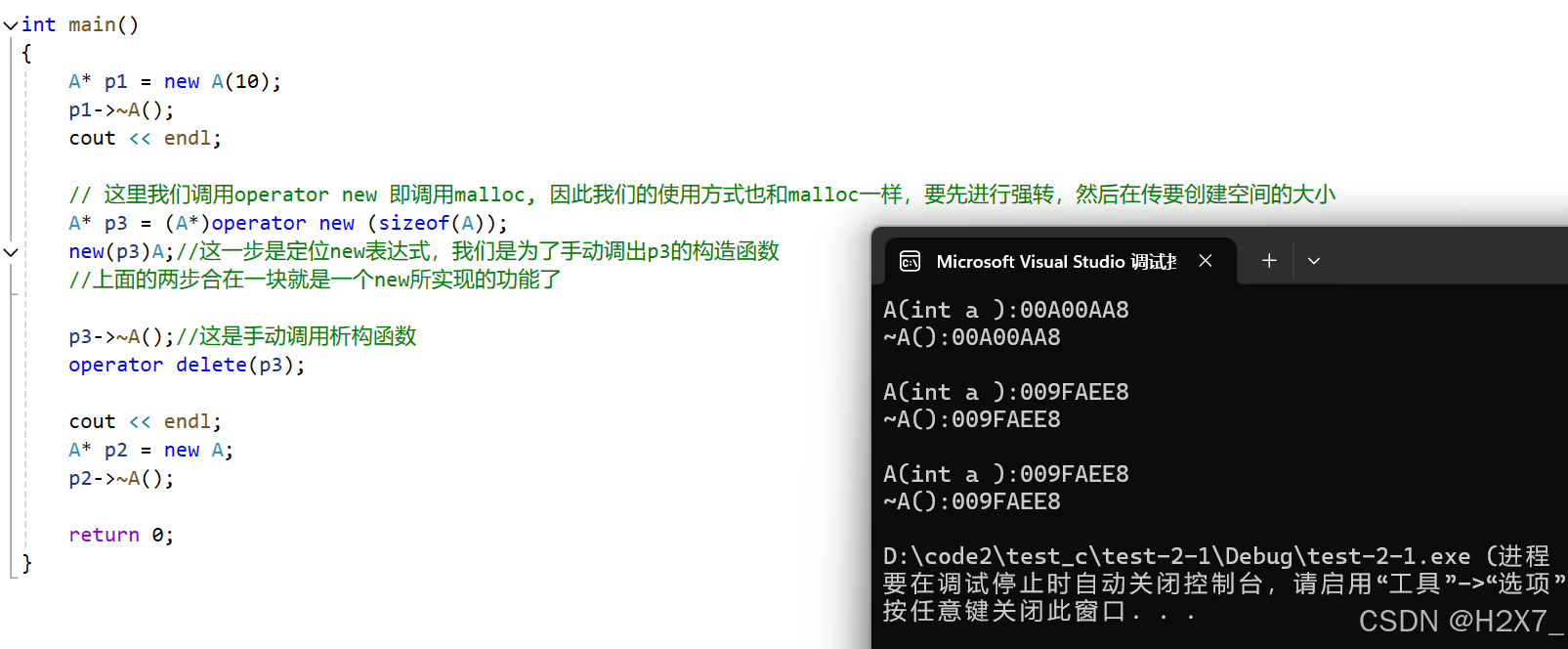
C++中的内存管理
学完了类与对象,这节我们来了解一下内存里的那些事 文章目录 一、C/C中的内存分布 1. 常量区(代码段) (Text Segment) 2. 静态区(数据段) (Data Segment) 3. 堆区 (Heap) 4. 栈区 (Stack) 5. 内存映射区域 (Memory-map…...

MySQL为什么默认引擎是InnoDB ?
大家好,我是锋哥。今天分享关于【MySQL为什么默认引擎是InnoDB ?】面试题。希望对大家有帮助; MySQL为什么默认引擎是InnoDB ? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 MySQL 默认引擎是 InnoDB,主要…...

ComfyUI安装调用DeepSeek——DeepSeek多模态之图形模型安装问题解决(ComfyUI-Janus-Pro)
ComfyUI 的 Janus-Pro 节点,一个统一的多模态理解和生成框架。 试用: https://huggingface.co/spaces/deepseek-ai/Janus-1.3B https://huggingface.co/spaces/deepseek-ai/Janus-Pro-7B https://huggingface.co/spaces/deepseek-ai/JanusFlow-1.3B 安装…...

电脑要使用cuda需要进行什么配置
在电脑上使用CUDA(NVIDIA的并行计算平台和API),需要进行以下配置和准备: 1. 检查NVIDIA显卡支持 确保你的电脑拥有支持CUDA的NVIDIA显卡。 可以在NVIDIA官方CUDA支持显卡列表中查看显卡型号是否支持CUDA。 2. 安装NVIDIA显卡驱动…...

利用Muduo库实现简单且健壮的Echo服务器
一、muduo网络库主要提供了两个类: TcpServer:用于编写服务器程序 TcpClient:用于编写客户端程序 二、三个重要的链接库: libmuduo_net、libmuduo_base、libpthread 三、muduo库底层就是epoll线程池,其好处是…...

Scratch 《像素战场》系列综合游戏:像素战场游戏Ⅰ~Ⅲ 介绍
资源下载 Scratch《像素战场》系列综合游戏合集:像素战场游戏Ⅰ~Ⅲ压缩包 https://download.csdn.net/download/leyang0910/90332765 游戏操作介绍 Scratch 《像素战场Ⅰ》操作规则: 这是一款与朋友一起玩的 1v1 游戏。先赢得6轮胜利! WA…...

Android学习制作app(ESP8266-01S连接-简单制作)
一、理论 部分理论见arduino学习-CSDN博客和Android Studio安装配置_android studio gradle 配置-CSDN博客 以下直接上代码和效果视频,esp01S的收发硬件代码目前没有分享,但是可以通过另一个手机网络调试助手进行模拟。也可以直接根据我的代码进行改动…...

三甲医院大型生信服务器多配置方案剖析与应用(2024版)
一、引言 1.1 研究背景与意义 在当今数智化时代,生物信息学作为一门融合生物学、计算机科学和信息技术的交叉学科,在三甲医院的科研和临床应用中占据着举足轻重的地位。随着高通量测序技术、医学影像技术等的飞速发展,生物医学数据呈爆发式…...

【Unity3D】实现横版2D游戏——单向平台(简易版)
目录 问题 项目Demo直接使用免费资源:Hero Knight - Pixel Art (Asset Store搜索) 打开Demo场景,进行如下修改,注意Tag是自定义标签SingleDirCollider using System.Collections; using System.Collections.Generic;…...

大白话讲清楚embedding原理
Embedding(嵌入)是一种将高维数据(如单词、句子、图像等)映射到低维连续向量的技术,其核心目的是通过向量表示捕捉数据之间的语义或特征关系。以下从原理、方法和应用三个方面详细解释Embedding的工作原理。 一、Embe…...

电脑优化大师-解决电脑卡顿问题
我们常常会遇到电脑运行缓慢、网速卡顿的情况,但又不知道是哪个程序在占用过多资源。这时候,一款能够实时监控网络和系统状态的工具就显得尤为重要了。今天,就来给大家介绍一款小巧实用的监控工具「TrafficMonitor」。 「TrafficMonitor 」是…...

el-table组件样式如何二次修改?
文章目录 前言一、去除全选框按钮样式二、表头颜色的修改 前言 ElementUI中的组件el-table表格组件提供了丰富的样式,有一个全选框的el-table组件,提供了全选框和多选。 一、去除全选框按钮样式 原本默认是有全选框的。假如有一些开发者,因…...

java练习(1)
两数之和(题目来自力扣) 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相…...

UbuntuWindows双系统安装
做系统盘: Ubuntu20.04双系统安装详解(内容详细,一文通关!)_ubuntu 20.04-CSDN博客 ubuntu系统调整大小: 调整指南: 虚拟机中的Ubuntu扩容及重新分区方法_ubuntu重新分配磁盘空间-CSDN博客 …...
DeepSeek大模型技术深度解析:揭开Transformer架构的神秘面纱
摘要 DeepSeek大模型由北京深度求索人工智能基础技术研究有限公司开发,基于Transformer架构,具备卓越的自然语言理解和生成能力。该模型能够高效处理智能对话、文本生成和语义理解等复杂任务,标志着人工智能在自然语言处理领域的重大进展。 关…...

从零到一:基于HappyBase的HBase Python应用实战指南
1. 环境准备与基础配置 第一次接触HBase和HappyBase时,环境配置往往是最让人头疼的部分。记得我刚开始搭建环境时,花了整整两天时间才把所有服务调通。为了让各位少走弯路,我把这些年积累的经验都整理在这里。 首先需要明确的是,…...

Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏
Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏 【免费下载链接】godot-card-game-framework A framework which comes with prepared scenes and classes to kickstart your card game, as well as a powerful scripting engine to use to provide full r…...

基于Sovereign-MCP-Servers构建私有AI工具链:从协议原理到Docker化部署
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给Claude、Cursor这类工具加上“联网”和“执行”能力时,绕不开一个概念:MCP(Model Context Protocol)。简单说,MCP就是一套标准协议,它能让…...

构建通用Docker工具镜像:从设计到实践的全流程指南
1. 项目概述:一个“反重力”的Docker镜像?看到这个镜像名runzhliu/docker-antigravity,很多人的第一反应可能是好奇和疑惑。在Docker Hub上,以“antigravity”(反重力)命名的镜像并不常见,它不像…...

轻量级配置中心zcf:中小团队微服务配置管理实战指南
1. 项目概述:一个轻量级、高可用的配置中心最近在梳理团队内部的技术栈,发现一个挺有意思的现象:很多中小型项目,甚至是一些快速迭代的业务线,在配置管理上依然处于一种“原始”状态。要么是各种application.yml、appl…...

Claude API钩子框架设计:非侵入式中间件与生命周期管理实践
1. 项目概述与核心价值最近在折腾一些AI应用开发,发现一个挺有意思的现象:很多开发者想给Claude API的调用过程加点“料”,比如在请求发出前或收到响应后,自动执行一些自定义逻辑。可能是为了日志记录、数据清洗、请求重试&#x…...

All in Token, 移动,电信,联通,阿里,百度,华为,字节,Token石油战争,Token经济,百度要“重写”AI价值度量
AI Agent的价值,应该怎么被衡量? 2026年,AI行业的标志性拐点是Agent(智能体)快速普及。Agent作为核心生产力载体,将AI从Chatbot聊天模式带进主动执行的办事时代。 这个时候,如果我们还用旧尺子…...

基于声明式Web自动化框架Hydra的电商数据监控实战
1. 项目概述:一个被低估的自动化利器 如果你经常需要处理一些重复性的、基于Web界面的操作,比如批量下载某个网站的资源、定时填写表单、或者监控网页内容的变化,那么你很可能已经厌倦了手动点击和等待。传统的脚本编写,尤其是涉及…...

小红书自动化工具xhs-skill:接口逆向与数据采集实战指南
1. 项目概述:一个面向小红书内容创作的效率工具箱最近在逛GitHub的时候,发现了一个挺有意思的项目,叫PengJiyuan/xhs-skill。光看名字,你大概能猜到它和小红书有关,但具体是做什么的,可能有点模糊。作为一个…...
基于Particle Photon与NeoPixel的物联网徽章:实时追踪ISS空间站
1. 项目概述:一个会“感知”太空的智能徽章 如果你和我一样,对头顶那片星空充满好奇,特别是当得知国际空间站(ISS)这个重达数百吨的大家伙,其实每天都会数次悄无声息地掠过我们的城市上空时,总…...