MyBatis-Plus笔记-快速入门
大家在日常开发中应该能发现,单表的CRUD功能代码重复度很高,也没有什么难度。而这部分代码量往往比较大,开发起来比较费时。
因此,目前企业中都会使用一些组件来简化或省略单表的CRUD开发工作。目前在国内使用较多的一个组件就是MybatisPlus.
当然,MybatisPlus不仅仅可以简化单表操作,而且还对Mybatis的功能有很多的增强。可以让我们的开发更加的简单,高效。
通过今天的学习,我们要达成下面的目标:
-
能利用MybatisPlus实现基本的CRUD
-
会使用条件构建造器构建查询和更新语句
-
会使用MybatisPlus中的常用注解
-
会使用MybatisPlus处理枚举、JSON类型字段
-
会使用MybatisPlus实现分页
1.快速入门
为了方便测试,我们先创建一个新的项目,并准备一些基础数据。
1.1.环境准备
复制课前资料提供好的一个项目到你的工作空间(不要包含空格和特殊字符):

然后用你的IDEA工具打开,项目结构如下:

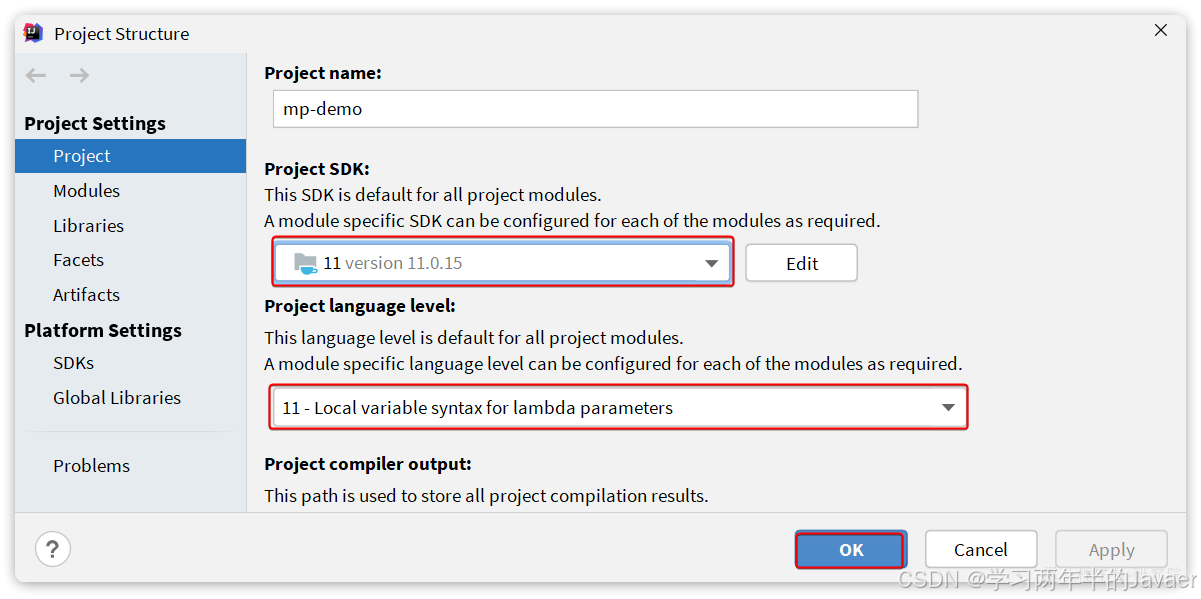
注意配置一下项目的JDK版本为JDK11。首先点击项目结构设置:

在弹窗中配置JDK:
接下来,要导入两张表,在课前资料中已经提供了SQL文件:

对应的数据库表结构如下:

最后,在application.yaml中修改jdbc参数为你自己的数据库参数:
spring:datasource:url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghaidriver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: MySQL123
logging:level:com.itheima: debugpattern:dateformat: HH:mm:ss1.2.快速开始
比如我们要实现User表的CRUD,只需要下面几步:
-
引入MybatisPlus依赖
-
定义Mapper
1.2.1引入依赖
MybatisPlus提供了starter,实现了自动Mybatis以及MybatisPlus的自动装配功能,坐标如下:
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.3.1</version>
</dependency>由于这个starter包含对mybatis的自动装配,因此完全可以替换掉Mybatis的starter。 最终,项目的依赖如下:
<dependencies><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.3.1</version></dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
</dependencies>1.2.2.定义Mapper
为了简化单表CRUD,MybatisPlus提供了一个基础的BaseMapper接口,其中已经实现了单表的CRUD:

因此我们自定义的Mapper只要实现了这个BaseMapper,就无需自己实现单表CRUD了。 修改mp-demo中的com.itheima.mp.mapper包下的UserMapper接口,让其继承BaseMapper:

代码如下:
package com.itheima.mp.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.itheima.mp.domain.po.User;
public interface UserMapper extends BaseMapper<User> {
}1.2.3.测试
新建一个测试类,编写几个单元测试,测试基本的CRUD功能:
package com.itheima.mp.mapper;
import com.itheima.mp.domain.po.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.time.LocalDateTime;
import java.util.List;
@SpringBootTest
class UserMapperTest {
@Autowiredprivate UserMapper userMapper;
@Testvoid testInsert() {User user = new User();user.setId(5L);user.setUsername("Lucy");user.setPassword("123");user.setPhone("18688990011");user.setBalance(200);user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");user.setCreateTime(LocalDateTime.now());user.setUpdateTime(LocalDateTime.now());userMapper.insert(user);}
@Testvoid testSelectById() {User user = userMapper.selectById(5L);System.out.println("user = " + user);}
@Testvoid testSelectByIds() {List<User> users = userMapper.selectBatchIds(List.of(1L, 2L, 3L, 4L, 5L));users.forEach(System.out::println);}
@Testvoid testUpdateById() {User user = new User();user.setId(5L);user.setBalance(20000);userMapper.updateById(user);}
@Testvoid testDelete() {userMapper.deleteById(5L);}
}可以看到,在运行过程中打印出的SQL日志,非常标准:
11:05:01 INFO 15524 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
11:05:02 INFO 15524 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
11:05:02 DEBUG 15524 --- [ main] c.i.mp.mapper.UserMapper.selectById : ==> Preparing: SELECT id,username,password,phone,info,status,balance,create_time,update_time FROM user WHERE id=?
11:05:02 DEBUG 15524 --- [ main] c.i.mp.mapper.UserMapper.selectById : ==> Parameters: 5(Long)
11:05:02 DEBUG 15524 --- [ main] c.i.mp.mapper.UserMapper.selectById : <== Total: 1
user = User(id=5, username=Lucy, password=123, phone=18688990011, info={"age": 21}, status=1, balance=20000, createTime=Fri Jun 30 11:02:30 CST 2023, updateTime=Fri Jun 30 11:02:30 CST 2023)只需要继承BaseMapper就能省去所有的单表CRUD,是不是非常简单!
1.3.常见注解
在刚刚的入门案例中,我们仅仅引入了依赖,继承了BaseMapper就能使用MybatisPlus,非常简单。但是问题来了: MybatisPlus如何知道我们要查询的是哪张表?表中有哪些字段呢?
大家回忆一下,UserMapper在继承BaseMapper的时候指定了一个泛型:

泛型中的User就是与数据库对应的PO.
MybatisPlus就是根据PO实体的信息来推断出表的信息,从而生成SQL的。默认情况下:
-
MybatisPlus会把PO实体的类名驼峰转下划线作为表名
-
MybatisPlus会把PO实体的所有变量名驼峰转下划线作为表的字段名,并根据变量类型推断字段类型
-
MybatisPlus会把名为id的字段作为主键
但很多情况下,默认的实现与实际场景不符,因此MybatisPlus提供了一些注解便于我们声明表信息。
1.3.1.@TableName
说明:
-
描述:表名注解,标识实体类对应的表
-
使用位置:实体类
示例:
@TableName("user")
public class User {private Long id;private String name;
}
TableName注解除了指定表名以外,还可以指定很多其它属性:
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 表名 |
| schema | String | 否 | "" | schema |
| keepGlobalPrefix | boolean | 否 | false | 是否保持使用全局的 tablePrefix 的值(当全局 tablePrefix 生效时) |
| resultMap | String | 否 | "" | xml 中 resultMap 的 id(用于满足特定类型的实体类对象绑定) |
| autoResultMap | boolean | 否 | false | 是否自动构建 resultMap 并使用(如果设置 resultMap 则不会进行 resultMap 的自动构建与注入) |
| excludeProperty | String[] | 否 | {} | 需要排除的属性名 @since 3.3.1 |
1.3.2.@TableId
说明:
-
描述:主键注解,标识实体类中的主键字段
-
使用位置:实体类的主键字段
示例:
@TableName("user")
public class User {@TableIdprivate Long id;private String name;
}TableId注解支持两个属性:
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 表名 |
| type | Enum | 否 | IdType.NONE | 指定主键类型 |
IdType支持的类型有:
| 值 | 描述 |
|---|---|
| AUTO | 数据库 ID 自增 |
| NONE | 无状态,该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) |
| INPUT | insert 前自行 set 主键值 |
| ASSIGN_ID | 分配 ID(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID(默认 default 方法) |
| ID_WORKER | 分布式全局唯一 ID 长整型类型(please use ASSIGN_ID) |
| UUID | 32 位 UUID 字符串(please use ASSIGN_UUID) |
| ID_WORKER_STR | 分布式全局唯一 ID 字符串类型(please use ASSIGN_ID) |
这里比较常见的有三种:
-
AUTO:利用数据库的id自增长 -
INPUT:手动生成id -
ASSIGN_ID:雪花算法生成Long类型的全局唯一id,这是默认的ID策略
1.3.3.@TableField
说明:
描述:普通字段注解
示例:
@TableName("user")
public class User {@TableIdprivate Long id;private String name;private Integer age;@TableField("isMarried")private Boolean isMarried;@TableField("'concat'")private String concat;@TableField(exist = false)private String address;
}一般情况下我们并不需要给字段添加@TableField注解,一些特殊情况除外:
-
成员变量名与数据库字段名不一致
-
成员变量是以
isXXX命名,按照JavaBean的规范,MybatisPlus识别字段时会把is去除,这就导致与数据库不符。 -
成员变量名与数据库一致,但是与数据库的关键字冲突。使用
@TableField注解给字段名添加转义字符:``。 -
成员变量不是数据库字段
支持的其它属性如下:
| 属性 | 类型 | 必填 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 数据库字段名 |
| exist | boolean | 否 | true | 是否为数据库表字段 |
| condition | String | 否 | "" | 字段 where 实体查询比较条件,有值设置则按设置的值为准,没有则为默认全局的 %s=#{%s},参考(opens new window) |
| update | String | 否 | "" | 字段 update set 部分注入,例如:当在version字段上注解update="%s+1" 表示更新时会 set version=version+1 (该属性优先级高于 el 属性) |
| insertStrategy | Enum | 否 | FieldStrategy.DEFAULT | 举例:NOT_NULL insert into table_a(<if test="columnProperty != null">column</if>) values (<if test="columnProperty != null">#{columnProperty}</if>) |
| updateStrategy | Enum | 否 | FieldStrategy.DEFAULT | 举例:IGNORED update table_a set column=#{columnProperty} |
| whereStrategy | Enum | 否 | FieldStrategy.DEFAULT | 举例:NOT_EMPTY where <if test="columnProperty != null and columnProperty!=''">column=#{columnProperty}</if> |
| fill | Enum | 否 | FieldFill.DEFAULT | 字段自动填充策略 |
| select | boolean | 否 | true | 是否进行 select 查询 |
| keepGlobalFormat | boolean | 否 | false | 是否保持使用全局的 format 进行处理 |
| jdbcType | JdbcType | 否 | JdbcType.UNDEFINED | JDBC 类型 (该默认值不代表会按照该值生效) |
| typeHandler | TypeHander | 否 | 类型处理器 (该默认值不代表会按照该值生效) | |
| numericScale | String | 否 | "" | 指定小数点后保留的位数 |
1.4.常见配置
MybatisPlus也支持基于yaml文件的自定义配置,详见官方文档:
https://www.baomidou.com/pages/56bac0/#%E5%9F%BA%E6%9C%AC%E9%85%8D%E7%BD%AE
大多数的配置都有默认值,因此我们都无需配置。但还有一些是没有默认值的,例如:
-
实体类的别名扫描包
-
全局id类型
mybatis-plus:type-aliases-package: com.itheima.mp.domain.poglobal-config:db-config:id-type: auto # 全局id类型为自增长需要注意的是,MyBatisPlus也支持手写SQL的,而mapper文件的读取地址可以自己配置:
mybatis-plus:mapper-locations: "classpath*:/mapper/**/*.xml" # Mapper.xml文件地址,当前这个是默认值。可以看到默认值是classpath*:/mapper/**/*.xml,也就是说我们只要把mapper.xml文件放置这个目录下就一定会被加载。
例如,我们新建一个UserMapper.xml文件:

然后在其中定义一个方法:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.mp.mapper.UserMapper">
<select id="queryById" resultType="User">SELECT * FROM user WHERE id = #{id}</select>
</mapper>然后在测试类UserMapperTest中测试该方法:
@Test
void testQuery() {User user = userMapper.queryById(1L);System.out.println("user = " + user);
}相关文章:
MyBatis-Plus笔记-快速入门
大家在日常开发中应该能发现,单表的CRUD功能代码重复度很高,也没有什么难度。而这部分代码量往往比较大,开发起来比较费时。 因此,目前企业中都会使用一些组件来简化或省略单表的CRUD开发工作。目前在国内使用较多的一个组件就是…...

爬取豆瓣书籍数据
# 1. 导入库包 import requests from lxml import etree from time import sleep import os import pandas as pd import reBOOKS [] IMGURLS []# 2. 获取网页源代码 def get_html(url):headers {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36…...

基于微信小程序的电子商城购物系统设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

6-图像金字塔与轮廓检测
文章目录 6.图像金字塔与轮廓检测(1)图像金字塔定义(2)金字塔制作方法(3)轮廓检测方法(4)轮廓特征与近似(5)模板匹配方法6.图像金字塔与轮廓检测 (1)图像金字塔定义 高斯金字塔拉普拉斯金字塔 高斯金字塔:向下采样方法(缩小) 高斯金字塔:向上采样方法(放大)…...

【Ai】DeepSeek本地部署+Page Assist图形界面
准备工作 1、ollama,用于部署各种开源模型,并开放接口的程序 https://ollama.com/download 2、deepseek-r1:32b 模型 https://ollama.com/library/deepseek-r1:32b 不同的模型版本对计算机性能的要求不一样,版本越高对显卡和内存的要求越高…...

【最长不下降子序列——树状数组、线段树、LIS】
题目 代码 #include <bits/stdc.h> using namespace std; const int N 1e510; int a[N], b[N], tr[N];//a保存权值,b保存索引,tr保存f,g前缀属性最大值 int f[N], g[N]; int n, m; bool cmp(int x, int y) {if(a[x] ! a[y]) return a[x] < a[…...

【实战篇章】深入探讨:服务器如何响应前端请求及后端如何查看前端提交的数据
文章目录 深入探讨:服务器如何响应前端请求及后端如何查看前端提交的数据一、服务器如何响应前端请求HTTP 请求生命周期全解析1.前端发起 HTTP 请求(关键细节强化版)2. 服务器接收请求(深度优化版) 二、后端如何查看前…...

Games104——引擎工具链基础
总览 工具链 用户到引擎架构图 工具链是衔接不同岗位、软件之间的桥梁,比如美术与技术,策划与美术,美术软件与引擎本身等,有Animation、UI、Mesh、Shader、Logical 、Level Editor等等。一般商业级引擎里的工具链代码量是超过…...

分层多维度应急管理系统的设计
一、系统总体架构设计 1. 六层体系架构 #mermaid-svg-QOXtM1MnbrwUopPb {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-QOXtM1MnbrwUopPb .error-icon{fill:#552222;}#mermaid-svg-QOXtM1MnbrwUopPb .error-text{f…...

【漏斗图】——1
🌟 解锁数据可视化的魔法钥匙 —— pyecharts实战指南 🌟 在这个数据为王的时代,每一次点击、每一次交易、每一份报告背后都隐藏着无尽的故事与洞察。但你是否曾苦恼于如何将这些冰冷的数据转化为直观、吸引人的视觉盛宴? 🔥 欢迎来到《pyecharts图形绘制大师班》 �…...

(二)QT——按钮小程序
目录 前言 按钮小程序 1、步骤 2、代码示例 3、多个按钮 ①信号与槽的一对一 ②多对一(多个信号连接到同一个槽) ③一对多(一个信号连接到多个槽) 结论 前言 按钮小程序 Qt 按钮程序通常包含 三个核心文件: m…...

【Linux】从硬件到软件了解进程
个人主页~ 从硬件到软件了解进程 一、冯诺依曼体系结构二、操作系统三、操作系统进程管理1、概念2、PCB和task_struct3、查看进程4、通过系统调用fork创建进程(1)简述(2)系统调用生成子进程的过程〇提出问题①fork函数②父子进程关…...

HTB:Alert[WriteUP]
目录 连接至HTB服务器并启动靶机 信息收集 使用rustscan对靶机TCP端口进行开放扫描 使用nmap对靶机TCP开放端口进行脚本、服务扫描 使用nmap对靶机TCP开放端口进行漏洞、系统扫描 使用nmap对靶机常用UDP端口进行开放扫描 使用ffuf对alert.htb域名进行子域名FUZZ 使用go…...

ARM嵌入式学习--第十天(UART)
--UART介绍 UART(Universal Asynchonous Receiver and Transmitter)通用异步接收器,是一种通用串行数据总线,用于异步通信。该总线双向通信,可以实现全双工传输和接收。在嵌入式设计中,UART用来与PC进行通信,包括与监控…...

玉米苗和杂草识别分割数据集labelme格式1997张3类别
数据集格式:labelme格式(不包含mask文件,仅仅包含jpg图片和对应的json文件) 图片数量(jpg文件个数):1997 标注数量(json文件个数):1997 标注类别数:3 标注类别名称:["corn","weed","Bean…...

哈夫曼树
哈夫曼树(Huffman Tree)是一种最优的二叉树,常用于数据压缩,如在 Huffman 编码中使用。它是根据字符出现的频率来构造的,频率越高的字符越靠近树的根,频率低的字符则在较深的节点上。其核心思想是通过构建一…...

wax到底是什么意思
在很久很久以前,人类还没有诞生文字之前,人类就产生了语言;在诞生文字之前,人类就已经使用了语言很久很久。 没有文字之前,人们的语言其实是相对比较简单的,因为人类的生产和生活水平非常低下,…...

笔记:使用ST-LINK烧录STM32程序怎么样最方便?
一般板子在插件上, 8脚 3.3V;9脚 CLK;10脚 DIO;4脚GND ST_Link 19脚 3.3V;9脚 CLK;7脚 DIO;20脚 GND 烧录软件:ST-LINK Utility,Keil_5; ST_Link 接口针脚定义: 按定义连接ST_Link与电路板; 打开STM32 ST-LINK Uti…...

数据分析系列--[11] RapidMiner,K-Means聚类分析(含数据集)
一、数据集 二、导入数据 三、K-Means聚类 数据说明:提供一组数据,含体重、胆固醇、性别。 分析目标:找到这组数据中需要治疗的群体供后续使用。 一、数据集 点击下载数据集 二、导入数据 三、K-Means聚类 Ending, congratulations, youre done....

Python在数据科学领域的深度应用:从数据处理到机器学习模型构建
Python在数据科学领域的深度应用:从数据处理到机器学习模型构建 在当今大数据与人工智能蓬勃发展的时代,Python凭借其简洁的语法、强大的库支持和活跃的社区,已成为数据科学家和工程师的首选编程语言。本文将深入探讨Python在数据科学领域的应用,从数据预处理、探索性分析…...

EVA-01效果展示:多场景图文问答案例,看AI如何精准识别与深度分析
EVA-01效果展示:多场景图文问答案例,看AI如何精准识别与深度分析 1. 视觉神经同步系统初体验 当你第一次打开EVA-01视觉神经同步系统,最直观的感受就是它独特的"暴走白昼"界面设计。与传统AI工具常见的深色背景不同,这…...

告别“炼丹”:用ReVeal的GGNN+Triplet Loss实战代码漏洞检测,我踩过的坑你别踩
从理论到实践:ReVeal漏洞检测模型落地中的关键挑战与解决方案 在代码安全领域,深度学习技术的应用正经历着从实验室研究到工业落地的关键转折期。ReVeal作为近年来备受关注的漏洞检测框架,其结合GGNN图神经网络与Triplet Loss的创新设计&…...

Companion Object - 伴生对象 类比java中的什么?
这是一个非常经典且准确的对比问题。简单来说,Kotlin 中的 companion object(伴生对象)核心类比的是 Java 中的 static(静态)成员。在 Java 中,如果你想让一个成员(方法或变量)属于类…...

3分钟搞定Windows软件安装难题:winget-install终极解决方案
3分钟搞定Windows软件安装难题:winget-install终极解决方案 【免费下载链接】winget-install Install WinGet using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2019/2022. 项目地址: https://gitcode.com/gh_mirror…...
)
SEO_本地中小企业快速见效的SEO操作指南(345 )
SEO:本地中小企业快速见效的SEO操作指南 在当今数字化时代,本地中小企业如何在竞争激烈的市场中脱颖而出,是每一个企业主都需要面对的问题。本文将从多个角度为你详细解析如何通过SEO(搜索引擎优化)让本地中小企业迅速见效。 问…...
)
30个核心概念一次讲明白,小白也能轻松入门大模型(收藏版)
这几年,AI 几乎成了人人都在谈的话题。 有人在聊大模型,有人在说智能体,有人担心算力不够,也有人被“参数”、“微调”、“多模态”、“RAG”这些词绕得头晕。 结果就是:听了很多,越听越乱。 这篇文章是用尽…...

效率提升秘籍:利用快马AI生成自动化脚本高效管理50台云桌面
效率提升秘籍:利用快马AI生成自动化脚本高效管理50台云桌面 手动配置和管理大量云桌面效率低下,尤其是当需要同时管理50台甚至更多云桌面时,重复性的操作不仅耗时耗力,还容易出错。最近我在InsCode(快马)平台上尝试了一个自动化运…...

教师评估软件市场迎增长机遇:未来六年CAGR锁定6.7%,教育数字化转型添动能
据恒州诚思调研统计,2025年全球教师评估软件市场规模约30.58亿元,预计未来将持续平稳增长,到2032年市场规模将接近47.92亿元,未来六年复合年增长率(CAGR)为6.7%。在教育行业数字化转型加速的背景下…...

坚定信心,顺势而为 ——中国企业出海与人工智能时代语言服务行业的新机遇
坚定信心,顺势而为——中国企业出海与人工智能时代语言服务行业的新机遇前言人工智能技术的逐步成熟以及智能体的普遍应用是最近两三年的热点和趋势,很多人说,2026年是智能体爆发的元年。春节期间,豆包、千问、元宝等50亿元的红包…...

3个高效功能让视频创作者轻松生成专业字幕
3个高效功能让视频创作者轻松生成专业字幕 【免费下载链接】video-srt-windows 这是一个可以识别视频语音自动生成字幕SRT文件的开源 Windows-GUI 软件工具。 项目地址: https://gitcode.com/gh_mirrors/vi/video-srt-windows 工具概述 VideoSrt是一款基于Golang开发的…...