【Elasticsearch】 Intervals Query
Elasticsearch Intervals Query
返回基于匹配术语的顺序和接近度的文档。
intervals 查询使用 匹配规则,这些规则由一小组定义构建而成。这些规则然后应用于指定 field 中的术语。
这些定义生成覆盖文本中术语的最小间隔序列。这些间隔可以进一步由父源组合和过滤。
以下 intervals 查询返回包含 my favorite food(没有任何间隔),后跟 hot water 或 cold porridge 的文档。查询应用于 my_text 字段。
这个查询将匹配 my_text 值为 my favorite food is cold porridge,但不匹配 when it's cold my favorite food is porridge。
JSON复制
POST _search
{"query": {"intervals" : {"my_text" : {"all_of" : {"ordered" : true,"intervals" : [{"match" : {"query" : "my favorite food","max_gaps" : 0,"ordered" : true}},{"any_of" : {"intervals" : [{ "match" : { "query" : "hot water" } },{ "match" : { "query" : "cold porridge" } }]}}]}}}}
}Intervals 查询的顶级参数
<field>
(必需,规则对象)您希望搜索的字段。
此参数的值是一个规则对象,用于基于匹配术语、顺序和接近度匹配文档。
有效的规则包括:
-
match -
prefix -
wildcard -
regexp -
fuzzy -
range -
all_of -
any_of
match 规则参数
match 规则匹配分析过的文本。
-
query:-
(必需,字符串)您希望在提供的
<field>中找到的文本。
-
-
max_gaps:-
(可选,整数)匹配术语之间的最大位置数。超过此距离的术语不被视为匹配。默认值为
-1。 -
如果未指定或设置为
-1,则匹配没有宽度限制。如果设置为0,术语必须相邻。
-
-
ordered:-
(可选,布尔值)如果为
true,匹配术语必须按指定顺序出现。默认值为false。
-
-
analyzer:-
(可选,字符串)用于分析
query中术语的分析器。默认值为顶级<field>的分析器。
-
-
filter:-
(可选,间隔过滤规则对象)可选的间隔过滤器。
-
-
use_field:-
(可选,字符串)如果指定,则从此字段匹配间隔,而不是顶级
<field>。术语使用此字段的搜索分析器进行分析。这允许您跨多个字段进行搜索,就像它们是同一个字段一样;例如,您可以将相同的文本索引到词干和非词干字段中,并搜索词干标记附近的非词干标记。
-
prefix 规则参数
prefix 规则匹配以指定字符集开头的术语。此前缀可以扩展以匹配最多 indices.query.bool.max_clause_count 搜索设置术语。如果前缀匹配更多术语,Elasticsearch 将返回错误。您可以在字段映射中使用 index-prefixes 选项来避免此限制。
-
prefix:-
(必需,字符串)您希望在顶级
<field>中找到的术语的起始字符。
-
-
analyzer:-
(可选,字符串)用于规范化
prefix的分析器。默认值为顶级<field>的分析器。
-
-
use_field:-
(可选,字符串)如果指定,则从此字段匹配间隔,而不是顶级
<field>。
-
wildcard 规则参数
wildcard 规则使用通配符模式匹配术语。此模式可以扩展以匹配最多 indices.query.bool.max_clause_count 搜索设置术语。如果模式匹配更多术语,Elasticsearch 将返回错误。
-
pattern:-
(必需,字符串)用于查找匹配术语的通配符模式。
-
此参数支持两个通配符操作符:
-
?,匹配任何单个字符 -
*,匹配零个或多个字符,包括空字符
-
-
-
analyzer:-
(可选,字符串)用于规范化
pattern的分析器。默认值为顶级<field>的分析器。
-
-
use_field:-
(可选,字符串)如果指定,则从此字段匹配间隔,而不是顶级
<field>。
-
regexp 规则参数
regexp 规则使用正则表达式模式匹配术语。此模式可以扩展以匹配最多 indices.query.bool.max_clause_count 搜索设置术语。如果模式匹配更多术语,Elasticsearch 将返回错误。
-
pattern:-
(必需,字符串)用于查找匹配术语的正则表达式模式。
-
避免使用通配符模式,如
.*或.*?+。这可能会增加找到匹配术语所需的迭代次数,并降低搜索性能。
-
-
analyzer:-
(可选,字符串)用于规范化
pattern的分析器。默认值为顶级<field>的分析器。
-
-
use_field:-
(可选,字符串)如果指定,则从此字段匹配间隔,而不是顶级
<field>。
-
fuzzy 规则参数
fuzzy 规则匹配与提供的术语相似的术语,编辑距离由 Fuzziness 定义。如果模糊扩展匹配的术语超过 indices.query.bool.max_clause_count 搜索设置术语,Elasticsearch 将返回错误。
-
term:-
(必需,字符串)要匹配的术语。
-
-
prefix_length:-
(可选,整数)创建扩展时保持不变的起始字符数。默认值为
0。
-
-
transpositions:-
(可选,布尔值)指示编辑是否包括两个相邻字符的换位(ab → ba)。默认值为
true。
-
-
fuzziness:-
(可选,字符串)允许匹配的最大编辑距离。参见 Fuzziness 以获取有效值和更多信息。默认值为
auto。
-
-
analyzer:-
(可选,字符串)用于规范化
term的分析器。默认值为顶级<field>的分析器。
-
-
use_field:-
(可选,字符串)如果指定,则从此字段匹配间隔,而不是顶级
<field>。
-
range 规则参数
range 规则匹配包含在提供范围内的术语。此范围可以扩展以匹配最多 indices.query.bool.max_clause_count 搜索设置术语。如果范围匹配更多术语,Elasticsearch 将返回错误。
-
gt:-
(可选,字符串)大于:匹配大于提供术语的术语。
-
-
gte:-
(可选,字符串)大于或等于:匹配大于或等于提供术语的术语。
-
-
lt:-
(可选,字符串)小于:匹配小于提供术语的术语。
-
-
lte:-
(可选,字符串)小于或等于:匹配小于或等于提供术语的术语。
-
all_of 规则参数
all_of 规则返回跨多个其他规则组合的匹配项。
-
intervals:-
(必需,规则对象数组)要组合的规则数组。所有规则必须在文档中生成匹配项,整体源才能匹配。
-
-
max_gaps:-
(可选,整数)匹配术语之间的最大位置数。规则生成的间隔超过此距离的不被视为匹配。默认值为
-1。
-
-
ordered:-
(可选,布尔值)如果为
true,规则生成的间隔应按指定顺序出现。默认值为false。
-
-
filter:-
(可选,间隔过滤规则对象)用于过滤返回间隔的规则。
-
any_of 规则参数
any_of 规则返回其子规则生成的任何间隔。
-
intervals:-
(必需,规则对象数组)要匹配的规则数组。
-
-
filter:-
(可选,间隔过滤规则对象)用于过滤返回间隔的规则。
-
filter 规则参数
filter 规则基于查询返回间隔。有关示例,请参见过滤器示例。
-
after:-
(可选,查询对象)返回跟随
filter规则间隔的间隔的查询。
-
-
before:-
(可选,查询对象)返回在
filter规则间隔之前发生的间隔的查询。
-
-
contained_by:-
(可选,查询对象)返回被
filter规则间隔包含的间隔的查询。
-
-
containing:-
(可选,查询对象)返回包含
filter规则间隔的间隔的查询。
-
-
not_contained_by:-
(可选,查询对象)返回不被
filter规则间隔包含的间隔的查询。
-
-
not_containing:-
(可选,查询对象)返回不包含
filter规则间隔的间隔的查询。
-
-
not_overlapping:-
(可选,查询对象)返回不与
filter规则间隔重叠的间隔的查询。
-
-
overlapping:-
(可选,查询对象)返回与
filter规则间隔重叠的间隔的查询。
-
-
script:-
(可选,脚本对象)返回匹配文档的脚本。此脚本必须返回布尔值
true或false。
-
示例
以下查询包含一个 filter 规则。它返回包含 hot 和 porridge 且两者之间不超过 10 个位置的文档,且两者之间没有 salty。
JSON复制
POST _search
{"query": {"intervals" : {"my_text" : {"match" : {"query" : "hot porridge","max_gaps" : 10,"filter" : {"not_containing" : {"match" : {"query" : "salty"}}}}}}}
}脚本过滤器
您可以使用脚本根据间隔的起始位置、结束位置和内部间隔数过滤间隔。以下 filter 脚本使用 interval 变量及其 start、end 和 gaps 方法:
JSON复制
POST _search
{"query": {"intervals" : {"my_text" : {"match" : {"query" : "hot porridge","filter" : {"script" : {"source" : "interval.start > 10 && interval.end < 20 && interval.gaps == 0"}}}}}}
}注意事项
-
最小化间隔:
-
intervals查询始终最小化间隔,以确保查询可以在线性时间内运行。这有时会导致意外结果,特别是在使用max_gaps限制或过滤器时。例如,考虑以下查询,搜索hot porridge中包含的salty:
JSON复制
POST _search {"query": {"intervals" : {"my_text" : {"match" : {"query" : "salty","filter" : {"contained_by" : {"match" : {"query" : "hot porridge"}}}}}}} }-
此查询不会匹配包含
hot porridge is salty porridge的文档,因为hot porridge的匹配查询返回的间隔仅覆盖此文档中的前两个术语,这些术语不与覆盖salty的间隔重叠。
-
相关文章:

【Elasticsearch】 Intervals Query
Elasticsearch Intervals Query 返回基于匹配术语的顺序和接近度的文档。 intervals 查询使用 匹配规则,这些规则由一小组定义构建而成。这些规则然后应用于指定 field 中的术语。 这些定义生成覆盖文本中术语的最小间隔序列。这些间隔可以进一步由父源组合和过滤…...

DeepSeek技术深度解析:从不同技术角度的全面探讨
DeepSeek技术深度解析:从不同技术角度的全面探讨 引言 DeepSeek是一个集成了多种先进技术的平台,旨在通过深度学习和其他前沿技术来解决复杂的问题。本文将从算法、架构、数据处理以及应用等不同技术角度对DeepSeek进行详细分析。 一、算法层面 深度学…...

Docker 部署 Starrocks 教程
Docker 部署 Starrocks 教程 StarRocks 是一款高性能的分布式分析型数据库,主要用于 OLAP(在线分析处理)场景。它最初是由百度的开源团队开发的,旨在为大数据分析提供一个高效、低延迟的解决方案。StarRocks 支持实时数据分析&am…...

【LLM-agent】(task6)构建教程编写智能体
note 构建教程编写智能体 文章目录 note一、功能需求二、相关代码(1)定义生成教程的目录 Action 类(2)定义生成教程内容的 Action 类(3)定义教程编写智能体(4)交互式操作调用教程编…...

29.Word:公司本财年的年度报告【13】
目录 NO1.2.3.4 NO5.6.7 NO8.9.10 NO1.2.3.4 另存为F12:考生文件夹:Word.docx选中绿色标记的标题文本→样式对话框→单击右键→点击样式对话框→单击右键→修改→所有脚本→颜色/字体/名称→边框:0.5磅、黑色、单线条:点…...
)
14 2D矩形模块( rect.rs)
一、 rect.rs源码 // Copyright 2013 The Servo Project Developers. See the COPYRIGHT // file at the top-level directory of this distribution. // // Licensed under the Apache License, Version 2.0 <LICENSE-APACHE or // http://www.apache.org/licenses/LICENS…...
【Unity3D】实现2D角色/怪物死亡消散粒子效果
核心:这是一个Unity粒子系统自带的一种功能,可将粒子生成控制在一个Texture图片网格范围内,并且粒子颜色会自动采样图片的像素点颜色,之后则是粒子编辑出消散效果。 Particle System1物体(爆发式随机速度扩散10000个粒…...
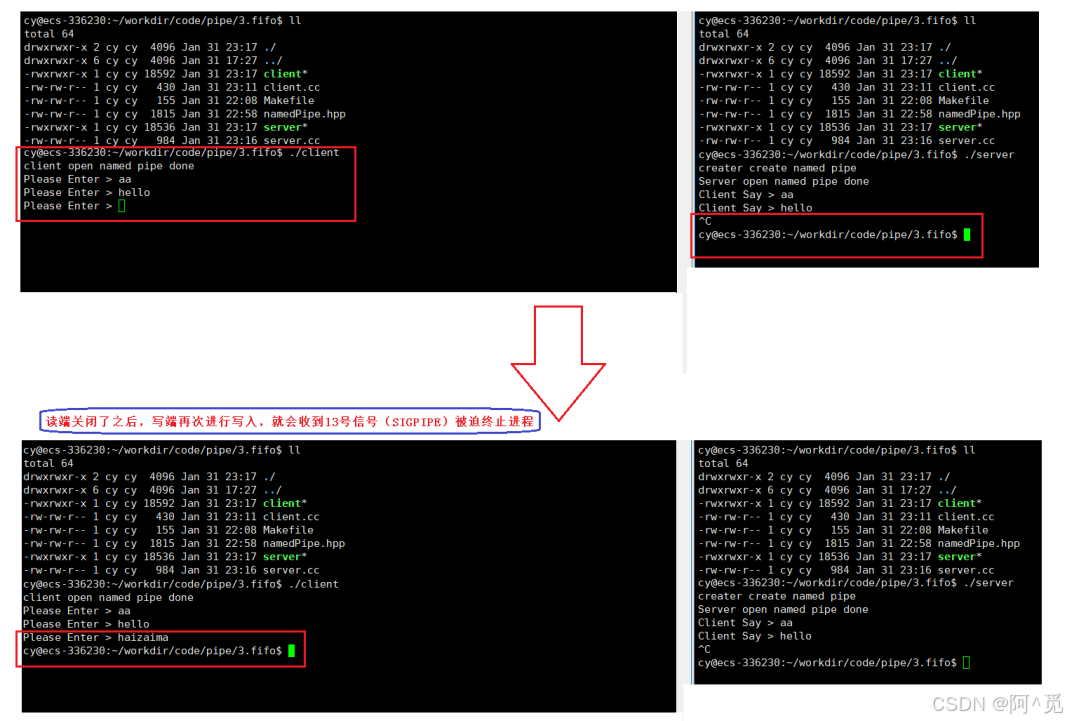
Linux - 进程间通信(3)
目录 3、解决遗留BUG -- 边关闭信道边回收进程 1)解决方案 2)两种方法相比较 4、命名管道 1)理解命名管道 2)创建命名管道 a. 命令行指令 b. 系统调用方法 3)代码实现命名管道 构建类进行封装命名管道&#…...
3、C#基于.net framework的应用开发实战编程 - 实现(三、三) - 编程手把手系列文章...
三、 实现; 三.三、编写应用程序; 此文主要是实现应用的主要编码工作。 1、 分层; 此例子主要分为UI、Helper、DAL等层。UI负责便签的界面显示;Helper主要是链接UI和数据库操作的中间层;DAL为对数据库的操…...
)
C++编程语言:抽象机制:泛型编程(Bjarne Stroustrup)
泛型编程(Generic Programming) 目录 24.1 引言(Introduction) 24.2 算法和(通用性的)提升(Algorithms and Lifting) 24.3 概念(此指模板参数的插件)(Concepts) 24.3.1 发现插件集(Discovering a Concept) 24.3.2 概念与约束(Concepts and Constraints) 24.4 具体化…...

Python面试宝典13 | Python 变量作用域,从入门到精通
今天,我们来深入探讨一下 Python 中一个非常重要的概念——变量作用域。理解变量作用域对于编写清晰、可维护、无 bug 的代码至关重要。 什么是变量作用域? 简单来说,变量作用域就是指一个变量在程序中可以被访问的范围。Python 中有四种作…...

基于最近邻数据进行分类
人工智能例子汇总:AI常见的算法和例子-CSDN博客 完整代码: import torch import numpy as np from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt# 生成一个简单的数据…...

DeepSeek V3 vs R1:大模型技术路径的“瑞士军刀“与“手术刀“进化
DeepSeek V3 vs R1:——大模型技术路径的"瑞士军刀"与"手术刀"进化 大模型分水岭:从通用智能到垂直突破 2023年,GPT-4 Turbo的发布标志着通用大模型进入性能瓶颈期。当模型参数量突破万亿级门槛后,研究者们开…...
一、TensorFlow的建模流程
1. 数据准备与预处理: 加载数据:使用内置数据集或自定义数据。 预处理:归一化、调整维度、数据增强。 划分数据集:训练集、验证集、测试集。 转换为Dataset对象:利用tf.data优化数据流水线。 import tensorflow a…...

指导初学者使用Anaconda运行GitHub上One - DM项目的步骤
以下是指导初学者使用Anaconda运行GitHub上One - DM项目的步骤: 1. 安装Anaconda 下载Anaconda: 让初学者访问Anaconda官网(https://www.anaconda.com/products/distribution),根据其操作系统(Windows、M…...

7层还是4层?网络模型又为什么要分层?
~犬📰余~ “我欲贱而贵,愚而智,贫而富,可乎? 曰:其唯学乎” 一、为什么要分层 \quad 网络通信的复杂性促使我们需要一种分层的方法来理解和管理网络。就像建筑一样,我们不会把所有功能都混在一起…...

C++:抽象类习题
题目内容: 求正方体、球、圆柱的表面积,抽象出一个公共的基类Container为抽象类,在其中定义一个公共的数据成员radius(此数据可以作为正方形的边长、球的半径、圆柱体底面圆半径),以及求表面积的纯虚函数area()。由此抽象类派生出…...
)
C++ 泛型编程指南02 (模板参数的类型推导)
文章目录 一 深入了解C中的函数模板类型推断什么是类型推断?使用Boost TypeIndex库进行类型推断分析示例代码关键点解析 2. 理解函数模板类型推断2.1 指针或引用类型2.1.1 忽略引用2.1.2 保持const属性2.1.3 处理指针类型 2.2 万能引用类型2.3 传值方式2.4 传值方式…...
——FFmpeg源码中,解析SDP的实现)
音视频入门基础:RTP专题(5)——FFmpeg源码中,解析SDP的实现
一、引言 FFmpeg源码中通过ff_sdp_parse函数解析SDP。该函数定义在libavformat/rtsp.c中: int ff_sdp_parse(AVFormatContext *s, const char *content) {const char *p;int letter, i;char buf[SDP_MAX_SIZE], *q;SDPParseState sdp_parse_state { { 0 } }, *s1…...

计算机网络 应用层 笔记 (电子邮件系统,SMTP,POP3,MIME,IMAP,万维网,HTTP,html)
电子邮件系统: SMTP协议 基本概念 工作原理 连接建立: 命令交互 客户端发送命令: 服务器响应: 邮件传输: 连接关闭: 主要命令 邮件发送流程 SMTP的缺点: MIME: POP3协议 基本概念…...

坐到马斯克和库克中间的湖南女人
梦瑶 发自 凹非寺量子位 | 公众号 QbitAI谁能在国宴现场坐在马斯克和库克中间?她——你可能不认识她的脸。△图源:《新闻联播》但你手上这块iPhone的玻璃屏,是她家公司做的。你开的特斯拉的车体配件,大概率也是。三星、Meta、摩托…...

iOS 27 开放 AI 生态@ACP#小型化扩展黄金风口,IX8008全面超越 ASM2806,铸就嵌入式 AI 扩展核心
苹果 iOS 27 系统全面开放第三方 AI 模型自由切换,支持 Claude、Gemini、DeepSeek 等主流大模型深度接入,iPhone/iPad 成为全球最大 AI 流量入口。这一变革引爆小型 AI 扩展坞、嵌入式 AI 终端、便携存储扩展、迷你主机、车载 AI五大硬件新机遇。作为连接…...

源代码论文分享|图书管理系统!
这份「图书管理系统」源码和论文,适合你在最需要“有个靠谱参考”的时候打开。 不是那种只放一堆代码、让人自己猜怎么跑的资料,也不是标题写得很大、内容却很空的论文模板。它更像一份已经整理好的项目包:有源码、有论文,可以直…...

AI赋能Anki:基于LLM与Prompt工程的智能制卡技能全解析
1. 项目概述:当Anki遇上AI,一个卡片技能的革命如果你和我一样,是个重度Anki用户,那你一定经历过这样的时刻:面对一本厚厚的教科书,或者一篇几十页的论文,想要把里面的核心知识点做成记忆卡片&am…...

Steam库存管理革命:5分钟掌握批量操作终极指南
Steam库存管理革命:5分钟掌握批量操作终极指南 【免费下载链接】Steam-Economy-Enhancer 中文版:Enhances the Steam Inventory and Steam Market. 项目地址: https://gitcode.com/gh_mirrors/ste/Steam-Economy-Enhancer Steam Economy Enhancer…...

基于发布订阅模式的Web实时通信框架hermes-for-web实践指南
1. 项目概述:一个为Web应用注入灵魂的“信使”最近在折腾一个前后端分离的Web项目,遇到了一个老生常谈但又极其磨人的问题:前端页面状态和后端数据更新之间的“延迟”与“不一致”。比如,用户A在后台管理界面删除了一个订单&#…...

VTube Studio API架构解析:构建下一代虚拟主播交互生态的核心技术
VTube Studio API架构解析:构建下一代虚拟主播交互生态的核心技术 【免费下载链接】VTubeStudio VTube Studio API Development Page 项目地址: https://gitcode.com/gh_mirrors/vt/VTubeStudio 探索虚拟主播技术生态的核心构建模块,VTube Studio…...

29 - Go time 时间模块详解:时间处理、定时控制与底层设计
文章目录29 - Go time 时间模块详解:时间处理、定时控制与底层设计核心概念time 模块解决什么问题?Go 为什么不用字符串表示时间?time.Duration 是什么?小结基础使用示例获取当前时间时间格式化为什么是 2006-01-02?小…...

5大隐藏功能揭秘:Markor如何重塑Android移动文本创作生态
5大隐藏功能揭秘:Markor如何重塑Android移动文本创作生态 【免费下载链接】markor Text editor - Notes & ToDo (for Android) - Markdown, todo.txt, plaintext, math, .. 项目地址: https://gitcode.com/gh_mirrors/ma/markor 在移动设备成为主要生产力…...

硅与锗PN结实战对比:手把手测量导通电压VF与温度系数
硅与锗PN结实战对比:手把手测量导通电压VF与温度系数 在电子工程实践中,PN结的特性测量是理解半导体器件行为的基础。硅(Si)和锗(Ge)作为两种经典半导体材料,其PN结在导通电压(VF)和温度特性上表现出显著差异。本文将带领读者通过实际测量&a…...