【RocketMQ】RocketMq之IndexFile深入研究
一:RocketMq 整体文件存储介绍
- CommitLog:存储消息的元数据。所有消息都会顺序存⼊到CommitLog⽂件当中。CommitLog由多个⽂件组成,每个⽂件固定⼤⼩1G。以第⼀条消 息的偏移量为⽂件名。
- ConsumerQueue:存储消息在CommitLog的索引。⼀个MessageQueue⼀个⽂件,记录当前MessageQueue被哪些消费者组消费到了哪⼀条CommitLog。
- IndexFile:为了消息查询提供了⼀种通过key或时间区间来查询消息的⽅法,这种通过IndexFile来查找消息的⽅法不影响发送与消费消息的主流程。
这篇文章主要介绍IndexFile的研究,以rocketmq5.3.0版本作为研究。
二:IndexFile的文件结构
文件整理格式,如下图2-1所示

图2-1 IndexFile 文件结构图
IndexFile 文件格式
-
文件名:以时间戳命名(例如
20240301120000000),表示该文件索引的消息的时间范围。 -
文件大小:默认为
400MB,可通过maxIndexSize配置调整。 -
存储路径:默认在
~/store/index目录下。
每个 IndexFile 文件由三部分组成:
1. 文件头部(Header)
2. 哈希槽(Hash Slot)区域
3. 索引条目(Index Entry)区域
1. 文件头部(Header)
| 字段名 | 长度(字节) | 说明 |
|---|---|---|
| beginTimestamp | 8 | 索引文件覆盖的最小时间戳(消息存储时间) |
| endTimestamp | 8 | 索引文件覆盖的最大时间戳(消息存储时间) |
| beginPhyOffset | 8 | 索引文件对应的最小物理偏移量(CommitLog 中的起始位置) |
| endPhyOffset | 8 | 索引文件对应的最大物理偏移量(CommitLog 中的结束位置) |
| hashSlotCount | 4 | 哈希槽数量(固定为 5,000,000) |
| indexCount | 4 | 当前已写入的索引条目数量 |
2. 哈希槽(Hash Slot)区域
-
哈希槽数量:固定为 500 万个(5,000,000),每个哈希槽占 4 字节。
-
哈希函数:对消息的 Key(如
UNIQ_KEY或KEYS)进行哈希计算,得到槽位索引:
slotPos = abs(hash(key)) % 5000000
每个哈希槽存储的是 索引条目区域 的起始位置(索引条目链表的头节点)。
3. 索引条目(Index Entry)区域
每个索引条目占 20 字节,包含以下字段:
| 字段名 | 长度(字节) | 说明 |
|---|---|---|
| keyHash | 4 | 消息 Key 的哈希值(用于快速比对) |
| phyOffset | 8 | 消息在 CommitLog 中的物理偏移量 |
| timeDiff | 4 | 消息存储时间与文件头部 |
| slotValue | 4 | 下一个索引条目的位置(用于解决哈希冲突的链表结构) |
三:IndexFile 写入和查询流程
IndexFile 写入流程:
+---------------------+
| Producer 发送消息 |
+---------------------+|v
+---------------------+
| 提取消息的 Key | --> 如 UNIQ_KEY 或 KEYS 属性
+---------------------+|v
+---------------------+
| 检查 IndexFile 容量 | --> 是否已满?(indexCount >= indexNum)
+---------------------+| 是v
+---------------------+
| 返回 false,写入失败 |
+---------------------+| 否v
+---------------------+
| 计算 Key 的哈希值 | --> `keyHash = indexKeyHashMethod(key)`
+---------------------+|v
+---------------------+
| 计算哈希槽位置 | --> `slotPos = keyHash % hashSlotNum`
+---------------------+|v
+---------------------+
| 计算哈希槽绝对位置 | --> `absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize`
+---------------------+|v
+---------------------+
| 读取哈希槽的当前值 | --> `slotValue = mappedByteBuffer.getInt(absSlotPos)`
+---------------------+|v
+---------------------+
| 校验 slotValue 有效性 | --> 是否无效?(slotValue <= invalidIndex || slotValue > indexCount)
+---------------------+| 是v
+---------------------+
| 将 slotValue 设为无效 | --> `slotValue = invalidIndex`
+---------------------+| 否v
+---------------------+
| 计算时间差 (timeDiff) | --> `timeDiff = (storeTimestamp - beginTimestamp) / 1000`
+---------------------+|v
+---------------------+
| 处理 timeDiff 边界值 | --> 确保 `0 <= timeDiff <= Integer.MAX_VALUE`
+---------------------+|v
+---------------------+
| 计算索引条目绝对位置 | --> `absIndexPos = IndexHeader.INDEX_HEADER_SIZE + hashSlotNum * hashSlotSize + indexCount * indexSize`
+---------------------+|v
+---------------------+
| 写入索引条目内容 |
| - keyHash |
| - phyOffset |
| - timeDiff |
| - slotValue (nextIndex)|
+---------------------+|v
+---------------------+
| 更新哈希槽指向新条目 | --> `mappedByteBuffer.putInt(absSlotPos, indexCount)`
+---------------------+|v
+---------------------+
| 更新 IndexFile 头部信息 |
| - 若 indexCount <= 1,更新 beginPhyOffset 和 beginTimestamp |
| - 若 slotValue 无效,增加 hashSlotCount |
| - 增加 indexCount |
| - 更新 endPhyOffset 和 endTimestamp |
+---------------------+|v
+---------------------+
| 返回 true,写入成功 |
+---------------------+|v
+---------------------+
| IndexFile 是否已满? | -- 是 --> 创建新 IndexFile
| (文件大小 ≥ 400MB) |
+---------------------+ 源码入口:org.apache.rocketmq.store.index.IndexFile#putKey
IndexFile 查询流程:
+---------------------+
| Consumer 根据 Key 查询 |
+---------------------+|v
+---------------------+
| 计算 Key 的哈希值 | --> `keyHash = Math.abs(key.hashCode())`
+---------------------+|v
+---------------------+
| 计算哈希槽位置 | --> `slotPos = keyHash % 5,000,000`
+---------------------+|v
+---------------------+
| 读取哈希槽的链表头位置 | --> `slotValue = mappedByteBuffer.getInt(slotPos * 4)`
+---------------------+|v
+---------------------+
| 遍历链表条目 |
| while (slotValue > 0)|
+---------------------+|v
+---------------------+
| 读取索引条目: |
| - keyHashRead |
| - phyOffset |
| - timeDiff |
| - nextIndex |
+---------------------+|v
+---------------------+
| 检查时间范围是否匹配? | --> `storeTime = beginTimestamp + timeDiff * 1000`
| (storeTime ∈ [begin, end]?)|
+---------------------+| 否|------------------> 跳过,继续下一个条目| 是v
+---------------------+
| 比对 keyHashRead 和 keyHash |
| (是否相等?) |
+---------------------+| 否|------------------> 跳过,继续下一个条目| 是v
+---------------------+
| 从 CommitLog 读取实际 Key |
| (检查 Key 是否一致?) |
+---------------------+| 否|------------------> 跳过,继续下一个条目| 是v
+---------------------+
| 返回 phyOffset | --> 添加到结果列表
+---------------------+|v
+---------------------+
| slotValue = nextIndex| --> 继续遍历下一个条目
+---------------------+|v
+---------------------+
| 遍历结束,返回结果列表 |
+---------------------+源码入口:org.apache.rocketmq.store.index.IndexService#queryOffset
四:IndexFile解决hash冲突问题思想
RocketMQ 的 IndexFile 通过 链地址法(Chaining) 解决哈希冲突问题,其核心思想是将哈希到同一槽位的多个索引条目组织成链表结构,并通过哈希槽(Hash Slot)与索引条目(Index Entry)的关联实现高效写入和查询。以下是具体实现思想及关键设计:
1. 哈希冲突的背景
-
哈希冲突:不同 Key 经过哈希函数计算后可能得到相同的哈希值,导致被分配到同一个哈希槽。
-
问题:若不处理冲突,后续 Key 的索引会覆盖已有数据,导致查询结果错误。
2. 解决冲突的核心思想:链地址法
RocketMQ 的 IndexFile 采用 单链表 结构管理同一哈希槽下的所有冲突条目,具体流程如下:
(1) 写入时的链表插入
-
新条目插入链表头部:
当新 Key 的哈希值与某槽位已有条目冲突时,新条目会被插入链表头部,并更新哈希槽指针指向新条目。// 新条目的 nextIndex 指向原头节点 this.mappedByteBuffer.putInt(absIndexPos + 16, slotValue); // 更新哈希槽指针为新条目位置 this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());-
优势:插入时间复杂度为 O(1),无需遍历链表。
-
(2) 查询时的链表遍历
-
遍历链表比对 Key:
查询时,从哈希槽指向的链表头节点开始,依次遍历所有条目,通过两次比对(哈希值 + 实际 Key)过滤冲突。while (nextIndexToRead > 0) {// 1. 读取条目内容int keyHashRead = this.mappedByteBuffer.getInt(absIndexPos);long phyOffsetRead = this.mappedByteBuffer.getLong(absIndexPos + 4);// 2. 比对哈希值if (keyHashRead == keyHash) {// 3. 从 CommitLog 读取实际 Key 比对String keyStored = readKeyFromCommitLog(phyOffsetRead);if (key.equals(keyStored)) {phyOffsets.add(phyOffsetRead);}}// 4. 移动到下一个节点nextIndexToRead = prevIndexRead; }
3. 关键设计优化
(1) 哈希槽数量固定
-
默认 500 万个哈希槽:
private static final int HASH_SLOT_NUM = 5000000; // 默认槽数-
目的:通过大量槽位减少哈希冲突的概率,使冲突链表尽可能短。
-
权衡:槽数过多会占用更多内存,但查询效率更高。
-
(2) 时间范围过滤
-
索引条目存储时间差(timeDiff):
每个索引条目记录消息存储时间与 IndexFile 起始时间的差值(秒级),查询时快速过滤掉不满足时间范围的条目。long timeRead = this.indexHeader.getBeginTimestamp() + timeDiff * 1000L; if (timeRead < begin || timeRead > end) {continue; // 跳过不符合时间条件的条目 }-
优势:减少无效条目的遍历,提升查询性能。
-
(3) 文件滚动(Rolling)
-
按时间或大小滚动:
IndexFile 文件默认大小上限为 400MB,或时间跨度超过阈值时,创建新文件。-
目的:避免单个文件过大导致链表过长,同时支持按时间范围快速定位文件。
-
4. 示例场景
写入冲突场景
-
Key1: Ea#20231001123456 → 哈希值 19583063 → 槽位 18332292
-
Key2: FB#20231001123456 → 哈希值 19583063 → 槽位 18332292(冲突)
-
处理流程:
-
Key1 写入槽位 18332292,链表头指向 Key1。
-
Key2 写入时,插入链表头部,槽位指针更新为 Key2,Key2 的
nextIndex指向 Key1。
-
查询冲突场景
-
查询 Key: Ea#20231001123456
-
哈希计算定位到槽位 18332292。
-
遍历链表:
-
先读取 Key2(哈希值匹配但 Key 不匹配,跳过)。
-
再读取 Key1(哈希值 + Key 均匹配,返回
phyOffset)。
-
-
hash冲突代码调试示例
public static void main(String[] args) throws Exception {DefaultMQProducer producer = new DefaultMQProducer("producerGroup");producer.setNamesrvAddr("127.0.0.1:9876");producer.start();Message msg = new Message("Ea", "TagA" , ("消息1").getBytes(RemotingHelper.DEFAULT_CHARSET));msg.setKeys("20231001123456");producer.sendOneway(msg);Message msg2 = new Message("FB", "TagA" , ("消息3").getBytes(RemotingHelper.DEFAULT_CHARSET));msg2.setKeys("20231001123456");producer.sendOneway(msg2);producer.shutdown();}相关文章:
【RocketMQ】RocketMq之IndexFile深入研究
一:RocketMq 整体文件存储介绍 存储⽂件主要分为三个部分: CommitLog:存储消息的元数据。所有消息都会顺序存⼊到CommitLog⽂件当中。CommitLog由多个⽂件组成,每个⽂件固定⼤⼩1G。以第⼀条消 息的偏移量为⽂件名。 ConsumerQue…...

小白零基础--CPP多线程
进程 进程就是运行中的程序线程进程中的进程 1、C11 Thread线程库基础 #include <iostream> #include <thread> #include<string>void printthread(std::string msg){std::cout<<msg<<std::endl;for (int i 0; i < 1000; i){std::cout<…...

利用deepseek参与软件测试 基本架构如何 又该在什么环节接入deepseek
利用DeepSeek参与软件测试,可以考虑以下基本架构和接入环节: ### 基本架构 - **数据层** - **测试数据存储**:用于存放各种测试数据,包括正常输入数据、边界值数据、异常数据等,这些数据可以作为DeepSeek的输入&…...
大模型微调技术总结及使用GPU对VisualGLM-6B进行高效微调
1. 概述 在深度学习中,微调(Fine-tuning)是一种重要的技术,用于改进预训练模型的性能。在预训练模型的基础上,针对特定任务(如文本分类、机器翻译、情感分析等),使用相对较小的有监…...

WPF进阶 | WPF 样式与模板:打造个性化用户界面的利器
WPF进阶 | WPF 样式与模板:打造个性化用户界面的利器 一、前言二、WPF 样式基础2.1 什么是样式2.2 样式的定义2.3 样式的应用 三、WPF 模板基础3.1 什么是模板3.2 控件模板3.3 数据模板 四、样式与模板的高级应用4.1 样式继承4.2 模板绑定4.3 资源字典 五、实际应用…...

Java 大视界 -- Java 大数据在自动驾驶中的数据处理与决策支持(68)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...
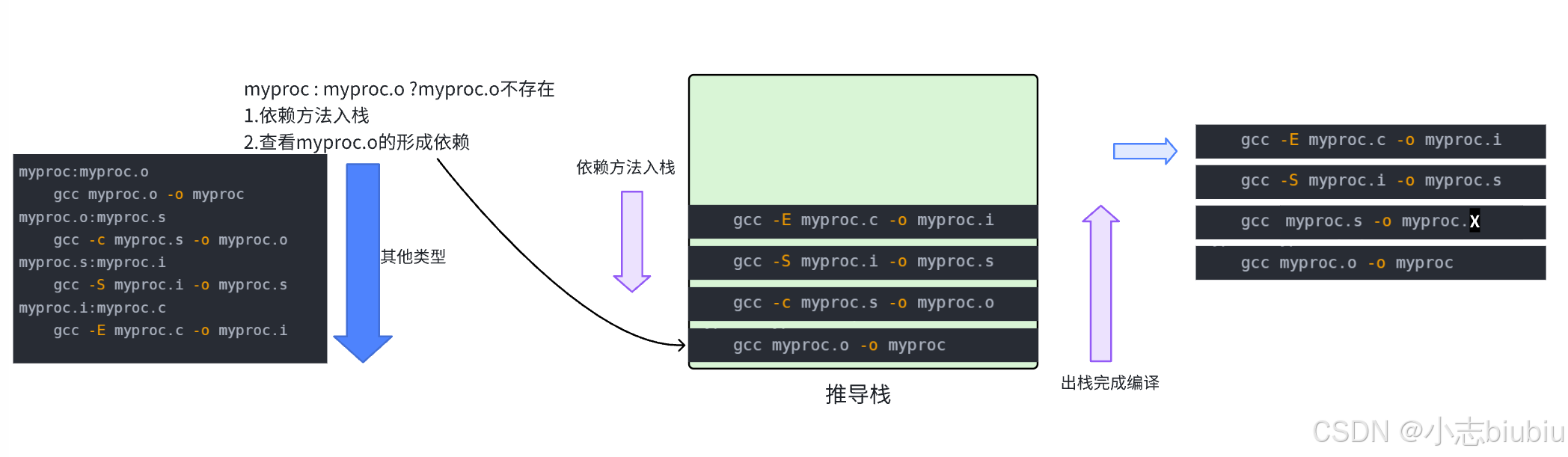
自动化构建-make/Makefile 【Linux基础开发工具】
文章目录 一、背景二、Makefile编译过程三、变量四、变量赋值1、""是最普通的等号2、“:” 表示直接赋值3、“?” 表示如果该变量没有被赋值,4、""和写代码是一样的, 五、预定义变量六、函数**通配符** 七、伪目标 .PHONY八、其他常…...

python学opencv|读取图像(五十二)使用cv.matchTemplate()函数实现最佳图像匹配
【1】引言 前序学习了图像的常规读取和基本按位操作技巧,相关文章包括且不限于: python学opencv|读取图像-CSDN博客 python学opencv|读取图像(四十九)原理探究:使用cv2.bitwise()系列函数实现图像按位运算-CSDN博客…...
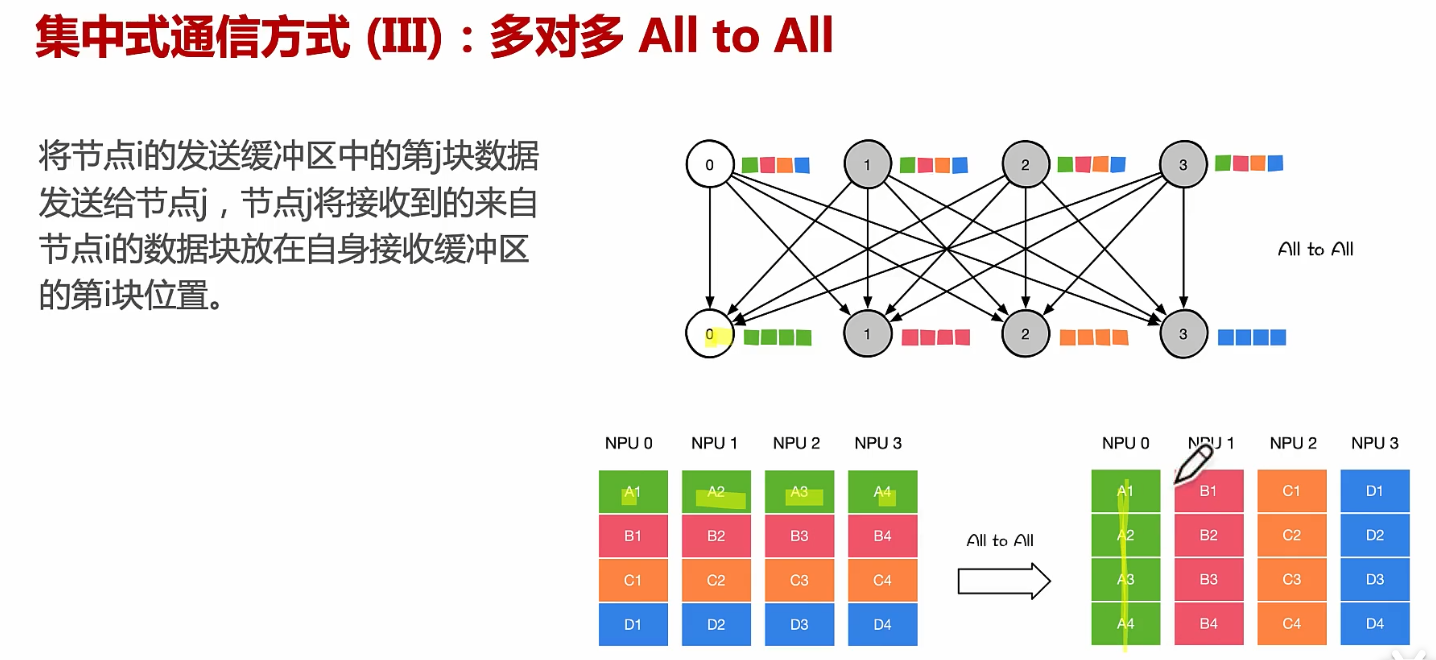
通信方式、点对点通信、集合通信
文章目录 从硬件PCIE、NVLINK、RDMA原理到通信NCCL、MPI原理!通信实现方式:机器内通信、机器间通信通信实现方式:通讯协调通信实现方式:机器内通信:PCIe通信实现方式:机器内通信:NVLink通信实现…...

TCP编程
1.socket函数 int socket(int domain, int type, int protocol); 头文件:include<sys/types.h>,include<sys/socket.h> 参数 int domain AF_INET: IPv4 Internet protocols AF_INET6: IPv6 Internet protocols AF_UNIX, AF_LOCAL : Local…...

OpenAI 实战进阶教程 - 第七节: 与数据库集成 - 生成 SQL 查询与优化
内容目标 学习如何使用 OpenAI 辅助生成和优化多表 SQL 查询了解如何获取数据库结构信息并与 OpenAI 结合使用 实操步骤 1. 创建 SQLite 数据库示例 创建数据库及表结构: import sqlite3# 连接 SQLite 数据库(如果不存在则创建) conn sq…...

Apache Iceberg数据湖技术在海量实时数据处理、实时特征工程和模型训练的应用技术方案和具体实施步骤及代码
Apache Iceberg在处理海量实时数据、支持实时特征工程和模型训练方面的强大能力。Iceberg支持实时特征工程和模型训练,特别适用于需要处理海量实时数据的机器学习工作流。 Iceberg作为数据湖,以支持其机器学习平台中的特征存储。Iceberg的分层结构、快照…...
QT交叉编译环境搭建(Cmake和qmake)
介绍一共有两种方法(基于qmake和cmake): 1.直接调用虚拟机中的交叉编译工具编译 2.在QT中新建编译套件kits camke和qmake的区别:CMake 和 qmake 都是自动化构建工具,用于简化构建过程,管理编译设置&…...
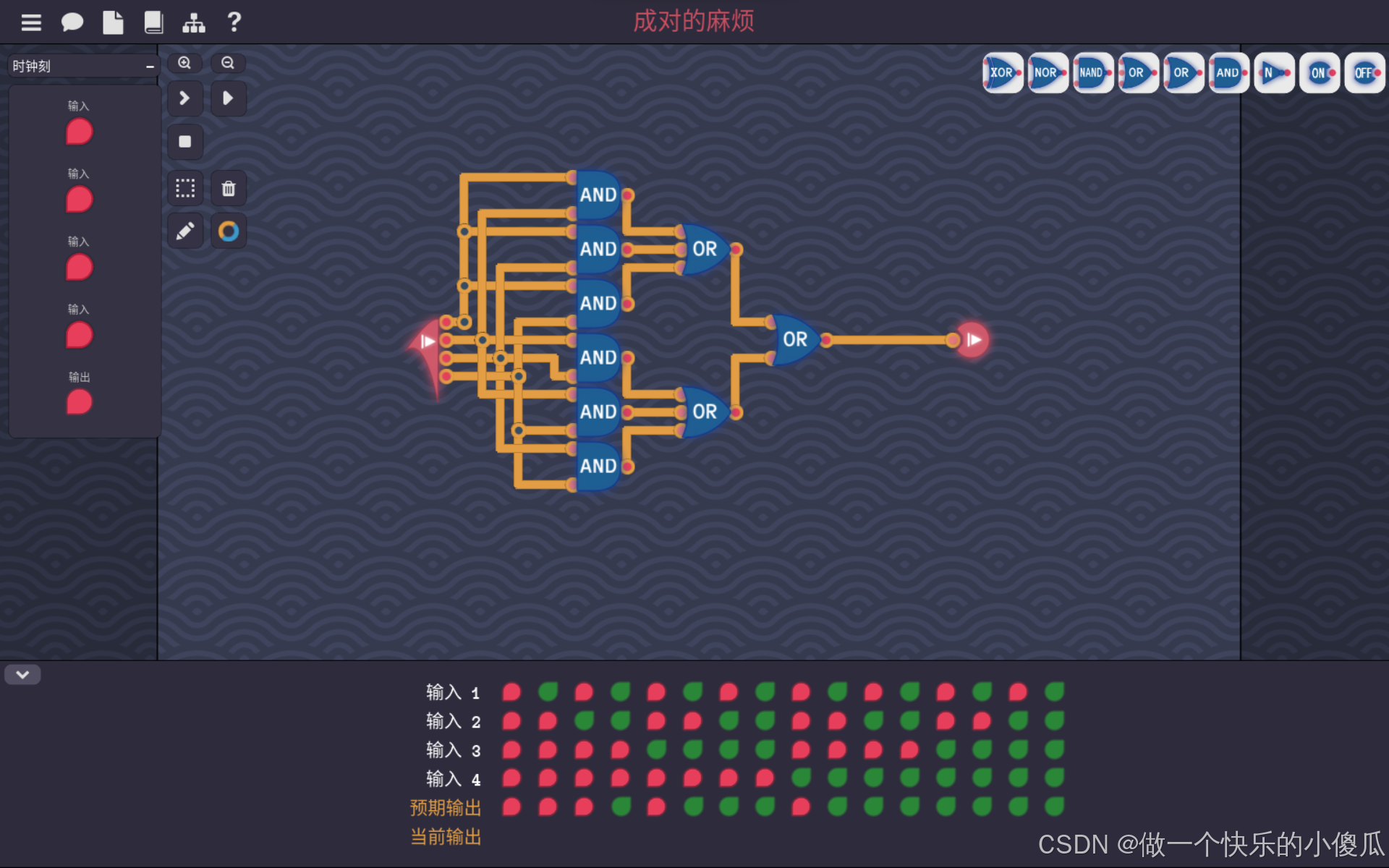
Turing Complete-成对的麻烦
这一关是4个输入,当输入中1的个数大于等于2时,输出1。 那么首先用个与门来检测4个输入中,1的个数是否大于等于2,当大于等于2时,至少会有一个与门输出1,所以再用两级或门讲6个与门的输出取或,得…...

寒假刷题Day20
一、80. 删除有序数组中的重复项 II class Solution { public:int removeDuplicates(vector<int>& nums) {int n nums.size();int stackSize 2;for(int i 2; i < n; i){if(nums[i] ! nums[stackSize - 2]){nums[stackSize] nums[i];}}return min(stackSize, …...
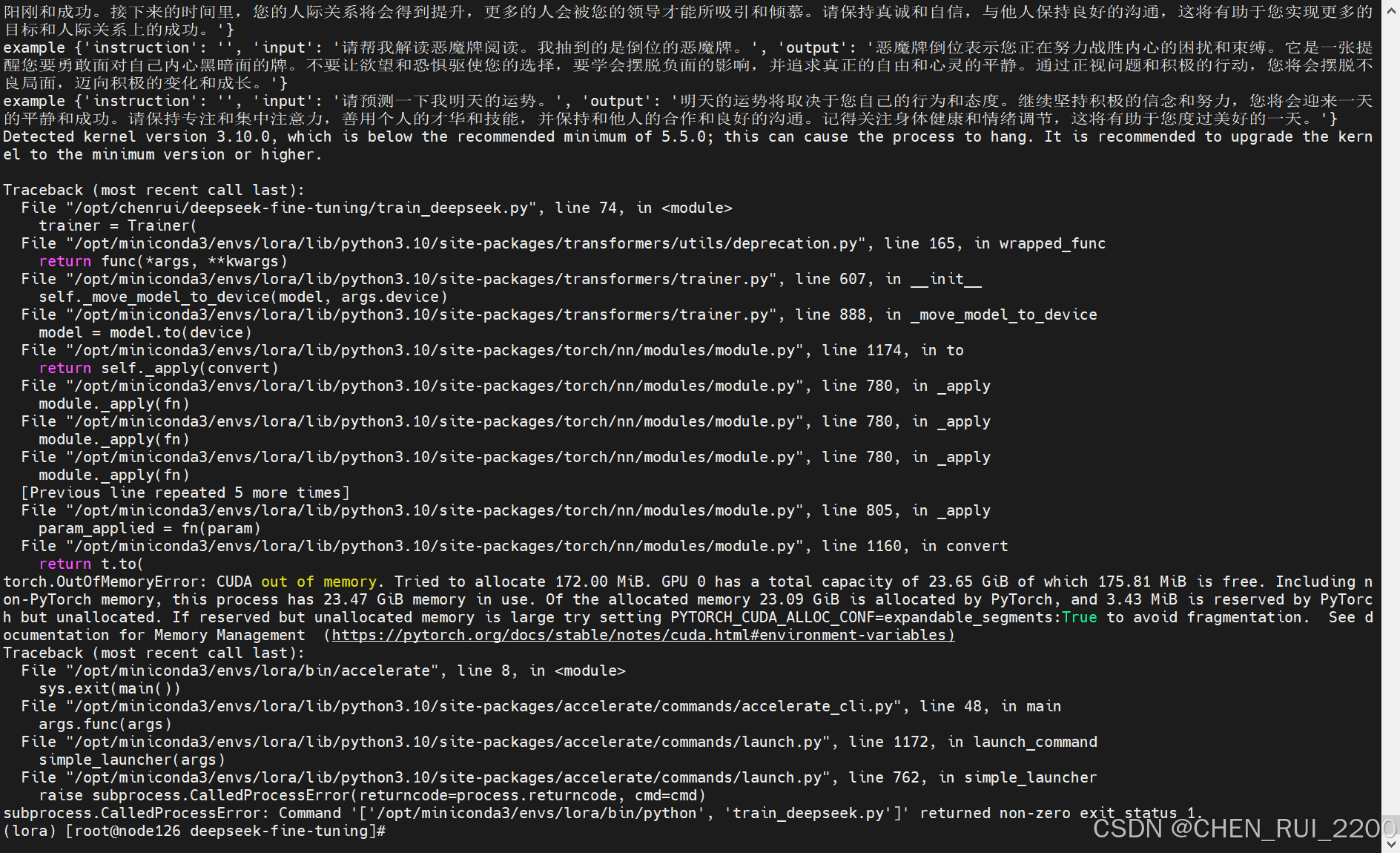
deepseek 本地化部署和小模型微调
安装ollama 因为本人gpu卡的机器系统是centos 7, 直接使用ollama会报 所以ollama使用镜像方式进行部署, 拉取镜像ollama/ollama 启动命令 docker run -d --privileged -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama 查看ollama 是否启动…...

【Java异步编程】基于任务类型创建不同的线程池
文章目录 一. 按照任务类型对线程池进行分类1. IO密集型任务的线程数2. CPU密集型任务的线程数3. 混合型任务的线程数 二. 线程数越多越好吗三. Redis 单线程的高效性 使用线程池的好处主要有以下三点: 降低资源消耗:线程是稀缺资源,如果无限…...

makailio-alias_db模块详解
ALIAS_DB 模块 作者 Daniel-Constantin Mierla micondagmail.com Elena-Ramona Modroiu ramonaasipto.com 编辑 Daniel-Constantin Mierla micondagmail.com 版权 © 2005 Voice Sistem SRL © 2008 asipto.com 目录 管理员指南 概述依赖 2.1 Kamailio 模块 2.2 外…...
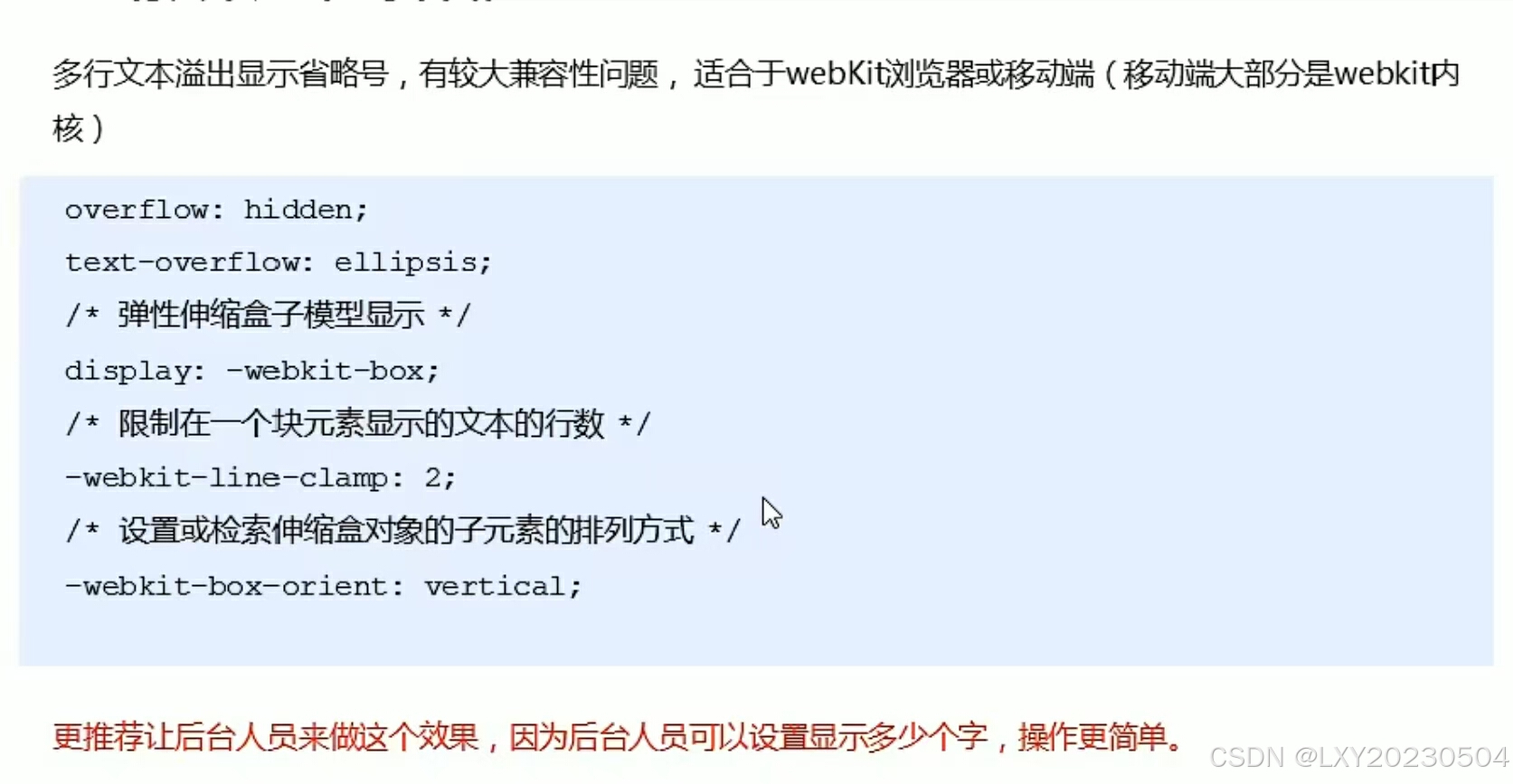
文字显示省略号
多行文本溢出显示省略号...

[LeetCode] 字符串完整版 — 双指针法 | KMP
字符串 基础知识双指针法344# 反转字符串541# 反转字符串II54K 替换数字151# 反转字符串中的单词55K 右旋字符串 KMP 字符串匹配算法28# 找出字符串中第一个匹配项的下标#459 重复的子字符串 基础知识 字符串的结尾:空终止字符00 char* name "hello"; …...
)
保姆级教程:在STM32MP157开发板上跑通LVGL 8.3.11(含FrameBuffer配置与触控校准)
嵌入式Linux GUI开发实战:STM32MP157移植LVGL 8.3.11全流程解析 当一块ARM开发板首次点亮LVGL的炫酷界面时,那种成就感堪比程序员世界的"Hello World"。本文将带你深入STM32MP157开发板的LVGL移植全过程,从FrameBuffer配置到触控校…...

创业团队如何用Taotoken低成本试验多个AI模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何用Taotoken低成本试验多个AI模型 对于资源有限的创业团队而言,在开发产品原型或验证AI功能时,…...

LZ4与ZSTD压缩算法在LLM内存优化中的硬件实现对比
1. 项目概述:压缩算法在LLM内存优化中的关键作用 在大型语言模型(LLM)推理过程中,内存带宽和容量一直是制约性能的关键瓶颈。特别是随着模型规模的不断扩大,KV缓存(Key-Value Cache)所占用的内存…...

基于数据科学的宠物性格分析:从行为量化到性格画像的工程实践
1. 项目概述与核心价值最近在逛GitHub的时候,发现了一个挺有意思的项目,叫petsonality。光看名字,你大概就能猜到它和“宠物”(Pets)以及“性格”(Personality)有关。没错,这是一个通…...

ComfyUI-Inpaint-CropAndStitch终极指南:30倍加速AI图像修复的完整教程
ComfyUI-Inpaint-CropAndStitch终极指南:30倍加速AI图像修复的完整教程 【免费下载链接】ComfyUI-Inpaint-CropAndStitch ComfyUI nodes to crop before sampling and stitch back after sampling that speed up inpainting 项目地址: https://gitcode.com/gh_mir…...

终极指南:PersistentWindows如何彻底解决Windows多显示器窗口管理难题
终极指南:PersistentWindows如何彻底解决Windows多显示器窗口管理难题 【免费下载链接】PersistentWindows fork of http://www.ninjacrab.com/persistent-windows/ with windows 10 update 项目地址: https://gitcode.com/gh_mirrors/pe/PersistentWindows …...

Godot游戏开发:模块化系统集成与事件驱动架构实战
1. 项目概述与核心价值如果你正在用Godot引擎做游戏,尤其是那种玩法稍微复杂一点的,比如RPG、策略游戏或者带点模拟经营元素的,那你肯定遇到过这样的问题:每次开新项目,都得从零开始搭一套基础系统。角色状态管理、物品…...

如何用ChatGPT进行金融数据分析:从入门到实战的完整指南
如何用ChatGPT进行金融数据分析:从入门到实战的完整指南 【免费下载链接】awesome-chatgpt-zh ChatGPT 中文指南🔥,ChatGPT 中文调教指南,指令指南,应用开发指南,精选资源清单,更好的使用 chatG…...

超漂亮的影视APP下载页官网html源码
超级好看的电影影视APP下载官网下载地址:https://pan.quark.cn/s/1d8f089b24c8...
:涵盖217家认证出版机构、11种非标准署名格式及4类灰色地带处理协议)
Perplexity出版社信息查询终极清单(2024Q3独家更新):涵盖217家认证出版机构、11种非标准署名格式及4类灰色地带处理协议
更多请点击: https://intelliparadigm.com 第一章:Perplexity出版社信息查询 Perplexity 是一家以 AI 增强研究为定位的技术出版与知识平台,其核心产品并非传统纸质出版物,而是基于实时网络检索、引用溯源与结构化摘要的交互式问…...