[mmdetection]fast-rcnn模型训练自己的数据集的详细教程
本篇博客是由本人亲自调试成功后的学习笔记。使用了mmdetection项目包进行fast-rcnn模型的训练,数据集是自制图像数据。废话不多说,下面进入训练步骤教程。
注:本人使用linux服务器进行展示,Windows环境大差不差。另外,每个人的训练环境不同,目前我只展示自己所使用的环境和配置,条件允许的情况下,请尽可能地根据我的版本进行安装和训练,以防出错。
一、conda环境及torch、mmcv等包的安装
1.1 linux服务器上的conda环境及torch包
linux服务器上的conda环境及torch包等可以根据下面这位博主发的教程进行安装:
Linux服务器安装anaconda并安装pytorch_如何利用pycharm在linux服务器上安装anaconda-CSDN博客
1.2 mmdetection中的必须包安装
在安装mmdetection之前,先进行下面三个包的安装:
pip install -U openmim
mim install mmengine
mim install "mmcv>=2.0.0"
在安装完上面三个包后,到github官网上把mmdetection的项目包拉下来,下载网址如下:
GitHub - open-mmlab/mmdetection: OpenMMLab Detection Toolbox and Benchmark
dowm下来后,使用xshell等软件打开该项目包,确保路径在该项目的主文件上。然后使用以下命令安装必备的包:
pip install -v -e .经过上述步骤,mmdetection项目的运行环境就已经安装结束,下面进入mmdetection的配置和测试环节。
注意:请在该环节结束前检查自己安装torch版本是否是显卡(cuda)版本,不然无法使用显卡进行训练。可以在命令行中使用下面命令进行测试:
python # 进入python
import torch # 导入torch库
torch.cuda.is_available() # 返回True则是cuda版本;返回False则是cpu版本
exit() # 退出python
二、mmdetection配置及调试
2.1 mmdetection测试
根据官网给出的测试步骤进行测试,官网给出的是cpu的推理版本,这里给出的是cuda推理版本。调试命令如下:
mim download mmdet --config rtmdet_tiny_8xb32-300e_coco --dest .
进行以上步骤后,会在mmdetection主目录下下载一个权重文件(.pth)和模型配置文件(.py)。下载速度视自身网速而定,耐心等待~
在主目录中出现上述两个文件后,使用以下命令进行推理测试:
python demo/image_demo.py demo/demo.jpg rtmdet_tiny_8xb32-300e_coco.py --weights rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth --device cuda
运行结束后,mmdetection主目录中会自动生成一个新的文件夹output保存刚刚推理的结果。
注意:(1)推理的路径使用了相对路径,如果你在运行后提示文件路径的报错,可以使用绝对路径进行运行。如果还是报错的话请仔细检查是否是文件没有下载在正确的路径中。(2)运行后出现mmcv版本的报错,该报错的解决请看下面的步骤~
2.2 mmcv版本报错的解决方法
在运行推理测试后,弹出“AssertionError: MMCV==2.2.0 is used but incompatible. Please install mmcv>=2.0.0rc4, <2.2.0”的报错,可以找到并打开/mmdetection-main/mmdet文件夹下的init.py文件,然后注释掉下面的这四行代码:
# assert (mmcv_version >= digit_version(mmcv_minimum_version)
# and mmcv_version < digit_version(mmcv_maximum_version)), \
# f'MMCV=={mmcv.__version__} is used but incompatible. ' \
# f'Please install mmcv>={mmcv_minimum_version}, <{mmcv_maximum_version}.'
在执行完上述操作后,基本可以解决mmcv版本的问题。重新运行推理测试命令即可生成output结果文件夹。
至此,mmdetection项目的调试到此就结束了,可以进入正题开始fast-rcnn的训练准备工作!
三、自制数据集的准备
3.1 数据集的标注工作
这部分我就不详细展开标准的教程了,csdn中有很多这方面的教程,自己去找一下。
步骤:首先,使用labelme工具进行数据标注,我使用voc格式进行标注(.xml)。然后,在获得图片和标签文件后,将之分别存放在images和labels文件夹中。在这两个文件夹中请自行划分好train、val和test数据集。最终的数据集文件夹如下所示。
dataset
-images
--train
--val
--test
-labels
--train
--val
--test3.2 制作fast-rcnn能训练的标签格式
利用以下代码分别对train、val和test的标签进行xml到coco标签的转换:
(注意:为了后续训练的方便,输出的json文件命名方式请遵循:instances_train2017.json、instances_val2017.json、instances_test2017.json)
import xml.etree.ElementTree as ET
import json
import os# 预定义类别
PRE_DEFINE_CATEGORIES = {"A1": 1, "B1": 2, "B2": 3, "A2": 4}# 初始化 COCO 格式的字典
coco_dict = {"images": [],"annotations": [],"categories": []
}# 处理类别信息
for category_name, category_id in PRE_DEFINE_CATEGORIES.items():category_info = {"id": category_id,"name": category_name,"supercategory": "object"}coco_dict["categories"].append(category_info)# 指定 XML 文件所在的文件夹
xml_dir = r'E:\BaiduSyncdisk\WALNUT-DATESET\split_dataset\test\labels\voc_label' # 请替换为实际的 XML 文件所在文件夹路径annotation_id = 1
image_id = 1# 遍历文件夹下的所有 XML 文件
for filename in os.listdir(xml_dir):if filename.endswith('.xml'):xml_file_path = os.path.join(xml_dir, filename)try:# 解析 XML 文件tree = ET.parse(xml_file_path)root = tree.getroot()# 处理图像信息image_info = {"id": image_id,"file_name": root.find('filename').text,"width": int(root.find('size/width').text),"height": int(root.find('size/height').text)}coco_dict["images"].append(image_info)# 处理标注信息for obj in root.findall('object'):category_name = obj.find('name').textcategory_id = PRE_DEFINE_CATEGORIES[category_name]bbox = obj.find('bndbox')xmin = int(bbox.find('xmin').text)ymin = int(bbox.find('ymin').text)xmax = int(bbox.find('xmax').text)ymax = int(bbox.find('ymax').text)width = xmax - xminheight = ymax - yminannotation_info = {"id": annotation_id,"image_id": image_id,"category_id": category_id,"bbox": [xmin, ymin, width, height],"area": width * height,"iscrowd": 0}coco_dict["annotations"].append(annotation_info)annotation_id += 1image_id += 1except Exception as e:print(f"Error processing {xml_file_path}: {e}")# 保存为 JSON 文件
output_json_file = r'E:\BaiduSyncdisk\WALNUT-DATESET\tools\1.数据集制作\annotations\instances_test2017.json'
with open(output_json_file, 'w') as f:json.dump(coco_dict, f, indent=4)在对训练集、验证集和测试集都运行了以上代码后会生成三个josn文件,随后将这三个文件保存到一个annotation文件夹中。
3.3 fast-rcnn数据文件保存格式
在进行了上述操作后,现在可以在mmdetection主文件夹中按照以下格式新建文件夹:
mmdetection # 主目录
-... # 主目录的其他文件
-data
--coco
---annotations
---train2017
---val2017
---test2017
-... # 主目录的其他文件在新建完成后,将图片数据按照分类分别上传到train2017、val2017和test2017文件夹中,刚刚生成的json文件上传到annotations文件夹中。
3.4 数据集配置文件的准备
在执行完上述操作后,进入/mmdetection/mmdet/datasets文件夹中复制coco.py,粘贴新建一个自己数据集的配置文件,本教程用ABC.py做例子进行讲解。
(1)将复制的文件打开后,修改原来coco数据集的classes和palette信息,按照自己的来。
修改前:

修改后:(这是我的例子,请按照自己的情况设定)
class的名字也要改一下:ABCDataset

(2)然后打开/mmdet/datasets/init.py,导入自己的数据集
....from .walnut import ABCDataset....__all__ = ['XMLDataset', 'CocoDataset', 'ABCDataset', 'DeepFashionDataset', 'VOCDataset','CityscapesDataset', 'LVISDataset', 'LVISV05Dataset', 'LVISV1Dataset','WIDERFaceDataset', 'get_loading_pipeline', 'CocoPanopticDataset','MultiImageMixDataset', 'OpenImagesDataset', 'OpenImagesChallengeDataset','AspectRatioBatchSampler', 'ClassAwareSampler', 'MultiSourceSampler','GroupMultiSourceSampler', 'BaseDetDataset', 'CrowdHumanDataset','Objects365V1Dataset', 'Objects365V2Dataset', 'DSDLDetDataset','BaseVideoDataset', 'MOTChallengeDataset', 'TrackImgSampler','ReIDDataset', 'YouTubeVISDataset', 'TrackAspectRatioBatchSampler','ADE20KPanopticDataset', 'CocoCaptionDataset', 'RefCocoDataset','BaseSegDataset', 'ADE20KSegDataset', 'CocoSegDataset','ADE20KInstanceDataset', 'iSAIDDataset', 'V3DetDataset', 'ConcatDataset','ODVGDataset', 'MDETRStyleRefCocoDataset', 'DODDataset','CustomSampleSizeSampler', 'Flickr30kDataset'
]至此,fast-rcnn模型能接受的数据集格式已经已经布置完成。接下来进入fast-rcnn模型训练的配置环节。
四、模型配置文件的准备
在训练fast-rcnn模型前,需要先进行rpn的训练,因为rpn有fast-rcnn模型训练所需要的前置文件(.pkl)。
4.1 rpn模型的训练
(1)选择模型
进入到/mmdetection/configs文件夹中找到rpn文件夹,进入后找到rpn_r50_fpn_1x_coco.py,本博客将使用这个例子进行教学。

(2)rpn模型训练
在命令行中使用以下模型进行训练:
python tools/train.py /root/autodl-tmp/model/mmdetection-main/configs/rpn/rpn_r50_fpn_1x_coco.py修改rpn_r50_fpn_1x_coco.py文件中的相应代码获得train和val的.pkl文件,这两个文件会自动生成在数据集/mmdetection/data/coco/路径下的proposals文件夹中。
注:本例子只做训练集和验证集的pkl,没有test。各位根据自身的需要进行生成。

在获得这两个文件后,就可以进行fast-rcnn模型的训练啦~
4.2 fast-rcnn模型的训练
(1)类别设置
打开mmdetection-main/configs/_base_/models,找到并打开fast-rcnn_r50_fpn.py,搜索num_classes,把coco的80个类别修改成自己的类别,本博客例子有4个类别,所以我将num_classes设置成4。
(2)配置dataset、batch、workers
打开mmdetection-main/configs/_base_/datasets,找到并打开coco_detection.py。
修改一下部位,请Ctrl+F进行分别搜索关键字
dataset_type
train_dataloader
val_dataloader
test_dataloader
将dataset_type设置成ABCDataset;train_dataloader、val_dataloader、test_dataloader中的 batch_size=16,
num_workers=16,
根据自己的设备配置来设置,这里我将batch和worker都设置成了16。
以上就完成了fast-rcnn的环境、数据集和训练文件的全部配置。接下来开始进行fast-rcnn模型的训练步骤。
五、开始训练
在命令行中cd进到mmdetection的项目主目录中,使用以下命令进行fast-rcnn模型的训练:(文件路径请根据自己的来改)
python tools/train.py /root/autodl-tmp/model/mmdetection-main/configs/fast_rcnn/fast-rcnn_r50_fpn_2x_coco.py训练过程截图如下:
如果不报错并且出现和截图相似的界面就说明训练开始了!!

—————————— 今天不学习,明天变垃圾 ——————————
相关文章:
[mmdetection]fast-rcnn模型训练自己的数据集的详细教程
本篇博客是由本人亲自调试成功后的学习笔记。使用了mmdetection项目包进行fast-rcnn模型的训练,数据集是自制图像数据。废话不多说,下面进入训练步骤教程。 注:本人使用linux服务器进行展示,Windows环境大差不差。另外࿰…...

1. Kubernetes组成及常用命令
Pods(k8s最小操作单元)ReplicaSet & Label(k8s副本集和标签)Deployments(声明式配置)Services(服务)k8s常用命令Kubernetes(简称K8s)是一个开源的容器编排系统,用于自动化应用程序的部署、扩展和管理。自2014年发布以来,K8s迅速成为容器编排领域的行业标准,被…...

linux下ollama更换模型路径
Linux下更换Ollama模型下载路径指南 在使用Ollama进行AI模型管理时,有时需要根据实际需求更改模型文件的存储路径。本文将详细介绍如何在Linux系统中更改Ollama模型的下载路径。 一、关闭Ollama服务 在更改模型路径之前,需要先停止Ollama服务。…...

本地Ollama部署DeepSeek R1模型接入Word
目录 1.本地部署DeepSeek-R1模型 2.接入Word 3.效果演示 4.问题反馈 上一篇文章办公新利器:DeepSeekWord,让你的工作更高效-CSDN博客https://blog.csdn.net/qq_63708623/article/details/145418457?spm1001.2014.3001.5501https://blog.csdn.net/qq…...

【自学笔记】Git的重点知识点-持续更新
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 Git基础知识Git高级操作与概念Git常用命令 总结 Git基础知识 Git简介 Git是一种分布式版本控制系统,用于记录文件内容的改动,便于开发者追踪…...

[EAI-028] Diffusion-VLA,能够进行多模态推理和机器人动作预测的VLA模型
Paper Card 论文标题:Diffusion-VLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression 论文作者:Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, Yaxin Peng, Chao…...

实现数组的扁平化
文章目录 1 实现数组的扁平化1.1 递归1.2 reduce1.3 扩展运算符1.4 split和toString1.5 flat1.6 正则表达式和JSON 1 实现数组的扁平化 1.1 递归 通过循环递归的方式,遍历数组的每一项,如果该项还是一个数组,那么就继续递归遍历,…...
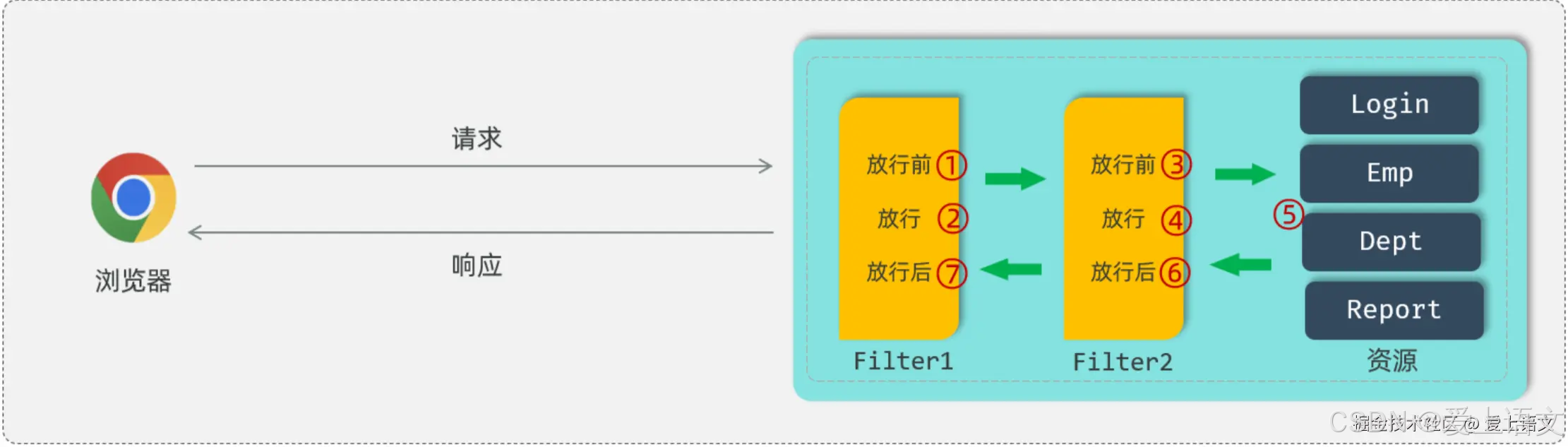
登录认证(5):过滤器:Filter
统一拦截 上文我们提到(登录认证(4):令牌技术),现在大部分项目都使用JWT令牌来进行会话跟踪,来完成登录功能。有了JWT令牌可以标识用户的登录状态,但是完整的登录逻辑如图所示&…...

pytorch实现门控循环单元 (GRU)
人工智能例子汇总:AI常见的算法和例子-CSDN博客 特性GRULSTM计算效率更快,参数更少相对较慢,参数更多结构复杂度只有两个门(更新门和重置门)三个门(输入门、遗忘门、输出门)处理长时依赖一般适…...

Word List 2
词汇颜色标识解释 词汇表中的生词 词汇表中的词组成的搭配、派生词 例句中的生词 我自己写的生词(用于区分易混淆的词,无颜色标识) 不认识的单词或句式 单词的主要汉语意思 不太理解的句子语法和结构 Word List 2 英文音标中文regi…...

机器学习常用包numpy篇(四)函数运算
目录 前言 一、三角函数 二、双曲函数 三、数值修约 四、 求和、求积与差分 五、 指数与对数 六、算术运算 七、 矩阵与向量运算 八、代数运算 九、 其他数学工具 总结 前言 Python 的原生运算符可实现基础数学运算(加减乘除、取余、取整、幂运算&#…...

CSS in JS
css in js css in js 的核心思想是:用一个 JS 对象来描述样式,而不是 css 样式表。 例如下面的对象就是一个用于描述样式的对象: const styles {backgroundColor: "#f40",color: "#fff",width: "400px",he…...

TCP 丢包恢复策略:代价权衡与优化迷局
网络物理层丢包是一种需要偿还的债务,可以容忍低劣的传输质量,这为 UDP 类服务提供了空间,而对于 TCP 类服务,可以用另外两类代价来支付: 主机端采用轻率的 GBN 策略恢复丢包,节省 CPU 资源,但…...

面经--C语言——内存泄漏、malloc和new的区别 .c文件怎么转换为可执行程序 uart和usart的区别 继承的访问权限总结
文章目录 内存泄漏预防内存泄漏的方法: malloc和new的区别.c文件怎么转换为可执行程序uart和usart的区别继承的访问权限总结访问控制符总结1. **public**:2. **protected**:3. **private**:继承类型: 内存泄漏 内存泄漏是指程序在运行时动态分配内存后&…...

Denavit-Hartenberg DH MDH坐标系
Denavit-Hartenberg坐标系及其规则详解 6轴协作机器人的MDH模型详细图_6轴mdh-CSDN博客 N轴机械臂的MDH正向建模,及python算法_mdh建模-CSDN博客 运动学3-----正向运动学 | 鱼香ROS 机器人学:MDH建模 - 哆啦美 - 博客园 机械臂学习——标准DH法和改进MDH…...

力扣动态规划-20【算法学习day.114】
前言 ###我做这类文章一个重要的目的还是记录自己的学习过程,我的解析也不会做的非常详细,只会提供思路和一些关键点,力扣上的大佬们的题解质量是非常非常高滴!!! 习题 1.网格中的最小路径代价 题目链接…...

计算机视觉-边缘检测
一、边缘 1.1 边缘的类型 ①实体上的边缘 ②深度上的边缘 ③符号的边缘 ④阴影产生的边缘 不同任务关注的边缘不一样 1.2 提取边缘 突变-求导(求导也是一种卷积) 近似,1(右边的一个值-自己可以用卷积做) 该点f(x,y)…...

文字加持:让 OpenCV 轻松在图像中插上文字
前言 在很多图像处理任务中,我们不仅需要提取图像信息,还希望在图像上加上一些文字,或是标注,或是动态展示。正如在一幅画上添加一个标语,或者在一个视频上加上动态字幕,cv2.putText 就是这个“文字魔术师”,它能让我们的图像从“沉默寡言”变得生动有趣。 今天,我们…...

掌握 HTML5 多媒体标签:如何在所有浏览器中顺利嵌入视频与音频
系列文章目录 01-从零开始学 HTML:构建网页的基本框架与技巧 02-HTML常见文本标签解析:从基础到进阶的全面指南 03-HTML从入门到精通:链接与图像标签全解析 04-HTML 列表标签全解析:无序与有序列表的深度应用 05-HTML表格标签全面…...

在Mac mini M4上部署DeepSeek R1本地大模型
在Mac mini M4上部署DeepSeek R1本地大模型 安装ollama 本地部署,我们可以通过Ollama来进行安装 Ollama 官方版:【点击前往】 Web UI 控制端【点击安装】 如何在MacOS上更换Ollama的模型位置 默认安装时,OLLAMA_MODELS 位置在"~/.o…...

告别串口线!手把手教你用WCH-LinkE的SDI功能实现CH32V303RCT6的无线调试打印
无线调试革命:基于WCH-LinkE的SDI功能实现CH32V303RCT6高效打印 调试嵌入式系统时,串口打印是最常用的调试手段之一。然而传统串口调试需要占用宝贵的硬件UART资源,在IO口紧张或串口已被占用的场景下尤为不便。沁恒微电子推出的SDI(Serial Da…...

软件检测领域CNAS能力验证信息怎么查?今年有哪些软件检测领域可以参加的能力验证?
实验室在初次申请CNAS资质或者扩项时,必须要参加一次能力验证活动,并获得满意结果。对于初次申请CNAS资质的软件检测实验室,能力验证应该在质量管理体系试运行期间完成。如果时间不合适,也可以选择参加测量审核活动。测量审核活动…...
)
基于深度学习YOLOv12的管道泄漏检测系统(YOLOv12+YOLO数据集+UI界面+登录注册界面+Python项目源码+模型)
一、项目介绍 管道泄漏检测是工业安全生产中的重要环节,传统的人工巡检方式存在效率低、实时性差、易漏检等问题。本项目基于最新的YOLOv12目标检测算法,开发了一套智能管道泄漏检测系统,实现对管道泄漏的实时、精准识别。 系统采用先进的深…...
)
Python+Mediamtx实战:5分钟搞定WebRTC视频流帧捕获(附完整代码)
PythonMediamtx实战:5分钟搞定WebRTC视频流帧捕获(附完整代码) 在实时视频处理领域,WebRTC技术因其低延迟和点对点传输特性而备受青睐。本文将带你快速搭建一个基于Mediamtx流媒体服务器和Python的WebRTC视频帧捕获系统࿰…...

XGBoost+SHAP实战:如何让机器学习模型‘看懂’地图?
XGBoostSHAP实战:如何让机器学习模型‘看懂’地图? 当机器学习遇上地理空间数据,我们常常面临一个核心矛盾:模型预测精度与人类可解释性之间的博弈。传统GIS分析方法如空间滞后模型(SLM)或地理加权回归&…...

公开信息整理|2026年3月26日:科学进展、词元活动、食品安全、护理保险与部分国际动态速览
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

Stable Diffusion炼丹指南:从Classifier Guidance到Classifier-Free Guidance,一文搞懂两种主流引导方式的区别与实战选择
Stable Diffusion条件生成实战:Classifier Guidance与Classifier-Free Guidance深度解析 在AIGC技术爆发的今天,Stable Diffusion等开源模型已成为内容创作的重要工具。但当你需要精确控制生成结果时——比如指定生成"穿红色连衣裙的亚洲女性"…...
开源AI工具降本增效:Pixel Fashion Atelier助力小型工作室节省70%概念图外包成本
开源AI工具降本增效:Pixel Fashion Atelier助力小型工作室节省70%概念图外包成本 1. 项目概述 Pixel Fashion Atelier是一款基于Stable Diffusion与Anything-v5的开源图像生成工具,专为时尚设计领域打造。它通过创新的像素风格界面和优化的模型组合&am…...

毕业设计题目100个:面向工程实践的技术选型与实现指南
最近在帮学弟学妹们看毕业设计,发现一个挺普遍的现象:很多同学想法天马行空,但一到动手实现就卡壳,要么技术栈选得五花八门拼不起来,要么代码写得像一锅粥,后期根本没法维护。选题“假大空”、实现“散乱差…...

RTX4090D优化版Qwen3-32B+OpenClaw:3小时搞定AI办公自动化
RTX4090D优化版Qwen3-32BOpenClaw:3小时搞定AI办公自动化 1. 为什么选择本地部署方案 去年冬天,当我第17次被飞书机器人返回的"API配额不足"提示打断工作流时,终于下定决心寻找替代方案。作为一个小型技术团队的负责人࿰…...