PyTorch快速入门
Anaconda
Anaconda 是一款面向科学计算的开源 Python 发行版本,它集成了众多科学计算所需的库、工具和环境管理系统,旨在简化包管理和部署,提升开发与研究效率。
核心组件:
- Conda:这是 Anaconda 自带的包和环境管理系统,可在不同环境中轻松安装、更新和卸载软件包,同时支持在 Windows、macOS 和 Linux 系统上创建独立的 Python 环境,避免不同项目间的依赖冲突。
- Python:Anaconda 自带 Python 解释器,且会跟随版本更新,确保使用的是稳定且功能丰富的 Python 版本。
- 科学计算库:包含了 NumPy、Pandas、SciPy、Matplotlib 等常用科学计算和数据分析库,为数据处理、数值计算和可视化提供了强大支持。
主要功能:
- 环境管理:能创建多个相互独立的 Python 环境,每个环境可拥有不同的 Python 版本和软件包。例如,你可创建一个用于深度学习的环境,安装 TensorFlow、PyTorch 等库;再创建一个用于数据分析的环境,安装 Pandas、Matplotlib 等库,避免不同项目间的依赖冲突。
- 包管理:借助 Conda 命令,可方便地安装、更新和卸载软件包。Conda 会自动解决包之间的依赖关系,避免手动安装时的复杂配置和冲突问题。
- 跨平台支持:支持 Windows、macOS 和 Linux 等多种操作系统,方便不同平台的用户使用相同的工具和环境进行开发和研究。
应用场景:
- 数据科学与机器学习:提供了丰富的数据处理、分析和可视化工具,以及常用的机器学习库,如 Scikit-learn、TensorFlow、PyTorch 等,是数据科学家和机器学习工程师的首选工具之一。
- 科学研究:在物理学、生物学、化学等科学领域,Anaconda 提供了高效的数值计算和模拟工具,帮助科研人员快速实现算法和模型。
- 软件开发:可用于开发 Python 应用程序,通过环境管理功能,确保项目在不同开发阶段和部署环境中的一致性。
安装与使用
- 安装:可从 Anaconda 官方网站(Download Anaconda Distribution | Anaconda)下载适合自己操作系统的安装包,然后按照安装向导进行安装。
- 使用:安装完成后,可通过命令行工具(如 Windows 的 Anaconda Prompt、macOS 和 Linux 的终端)使用 Conda 命令进行环境管理和包管理。例如,创建一个新的 Python 环境(在Anaconda Prompt中输入以下指令):
conda create -n myenv python=3.8 #-n是name的意思,后面跟着环境的名字激活环境:
conda activate myenv在环境中安装包:
conda install numpy查看环境中有哪些工具包:
pip listCUDA
深度学习离不开显卡,有没有显卡其实并不影响PyTorch,显卡主要起到训练加速的作用。像TensorFlow,PyTorch这种常用的深度学习框架在NVDIA显卡上部署相对较容易,除此之外也可以在AMD显卡上部署
以PyTorch在CUDA上部署为例
环境准备:
- 安装 CUDA:CUDA 是 NVIDIA 推出的并行计算平台和编程模型,PyTorch 借助 CUDA 在 NVIDIA GPU 上运行。你要依据自己的 GPU 型号和系统环境,从 NVIDIA 官方网站下载并安装合适版本的 CUDA。
- 安装 cuDNN:cuDNN 是 NVIDIA 专门为深度神经网络开发的 GPU 加速库,能进一步提升 PyTorch 在 GPU 上的运行效率。安装时需从 NVIDIA 官方网站下载对应的 cuDNN 库,并将其配置到 CUDA 环境中。
- 安装支持 CUDA 的 PyTorch:通过 pip 或者 conda 安装支持 CUDA 的 PyTorch 版本。例如,使用 conda 安装支持 CUDA 11.8 的 PyTorch:
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia对于Intel核显,PyTorch的部署相对较麻烦。借助英特尔的 OpenVINO 工具包以及相关驱动,能够让 PyTorch 模型在 Intel 核显上进行推理,步骤如下:
1. 安装必要的库
要保证已安装 PyTorch 和 OpenVINO 工具包。可以通过以下命令安装 OpenVINO:
pip install openvino-dev[torch]2. 导出 PyTorch 模型为 ONNX 格式
ONNX(Open Neural Network Exchange)是一种开放的模型格式,可实现不同深度学习框架间的模型转换。示例代码如下:
import torch
import torchvision.models as models# 加载预训练的ResNet18模型
model = models.resnet18(pretrained=True)
model.eval()# 创建一个示例输入
dummy_input = torch.randn(1, 3, 224, 224)# 导出模型为ONNX格式
torch.onnx.export(model, dummy_input, "resnet18.onnx", export_params=True, opset_version=11)3. 将 ONNX 模型转换为 OpenVINO 中间表示(IR)
使用 OpenVINO 的模型优化器将 ONNX 模型转换为 IR 格式:
mo --input_model resnet18.onnx4. 在 Intel 核显上运行推理
利用 OpenVINO 的 Python API 加载 IR 模型并在 Intel 核显上执行推理:
from openvino.runtime import Core# 初始化OpenVINO核心对象
ie = Core()# 加载IR模型
model_xml = "resnet18.xml"
model_bin = "resnet18.bin"
net = ie.read_model(model=model_xml, weights=model_bin)
exec_net = ie.compile_model(model=net, device_name="GPU")# 准备输入数据
import cv2
import numpy as npimage = cv2.imread("test_image.jpg")
image = cv2.resize(image, (224, 224))
image = np.transpose(image, (2, 0, 1))
image = np.expand_dims(image, axis=0)# 执行推理
output = exec_net([image])注意事项:
- 硬件和驱动要求:要保证你的 Intel 核显支持 OpenCL,并且安装了最新的显卡驱动。
- 模型兼容性:并非所有的 PyTorch 模型都能完美转换为 ONNX 格式,部分复杂的自定义层或操作可能需要额外处理。
- 性能表现:虽然 Intel 核显可用于推理,但在性能上可能不如独立显卡,特别是对于大规模的深度学习模型。
安装PyTorch
在官网https://pytorch.org/中下载
下拉可以看到下图所示。根据下载方式选择相应的版本即可。下面是选择PyTorch稳定版Stable,在Windows系统下用conda方式安装,选择完成后,复制下载指令,在新建的myenv(conda create -n myenv python=3.8)环境中输入命令下载即可。

下载完成后,在 myenv环境下输入python3进入python3解释器,输入import torch回车后不报错说明Pytorch下载成功,再输入torch.cuda.is_available(),返回true说明gpu是可以被pytorch使用的

PyCharm
PyCharm 是由 JetBrains 公司开发的一款专门针对 Python 的集成开发环境(IDE)。它为 Python 开发者提供了丰富的功能和工具,能有效提升开发效率
主要功能:
- 代码编辑
- 智能代码补全:能根据上下文智能提示代码,包括变量名、函数名、类名等,还能补全方法的参数。
- 代码高亮:对不同的代码元素,如关键字、注释、字符串等采用不同颜色显示,方便阅读和编写代码。
- 代码格式化:可自动调整代码格式,使其符合 PEP 8 等编码规范,增强代码可读性。
- 代码调试
- 设置断点:能在代码中任意位置设置断点,方便逐行执行代码,观察变量的值和程序的执行流程。
- 变量监控:调试过程中可实时查看变量的值,帮助定位问题。
- 多线程调试:支持对多线程程序进行调试,便于处理复杂的并发问题。
- 项目管理
- 创建项目:可轻松创建不同类型的 Python 项目,如 Django、Flask 等 Web 项目,还能自动配置项目的运行环境。
- 文件导航:提供便捷的文件导航功能,能快速定位到项目中的文件和文件夹。
- 版本控制集成:集成了 Git 等版本控制系统,方便进行代码的版本管理和团队协作。
- 代码分析
- 语法检查:实时检查代码中的语法错误,并给出相应的提示和建议。
- 代码质量分析:能分析代码的复杂度、重复度等,帮助开发者优化代码结构。
- 代码重构:支持多种代码重构操作,如重命名变量、提取方法等,提高代码的可维护性。
使用步骤
- 安装:从 JetBrains 官方网站下载适合自己操作系统的 PyCharm 安装包,然后按照安装向导进行安装。下载社区版,社区版免费。
- 创建项目:打开 PyCharm,选择 “Create New Project”,设置项目的名称、存储位置和 Python 解释器等信息。
- 编写代码:在项目中创建 Python 文件,开始编写代码。
- 运行和调试:点击工具栏上的运行或调试按钮,执行代码并进行调试
下载后在Pycharm里选择刚才创建的myenv环境
Jupyter
Jupyter 是一个开源的 Web 应用程序,允许你创建和共享包含实时代码、方程、可视化和叙述性文本的文档,其名称源于对三种编程语言(Julia、Python、R)的致敬。
主要特点:
- 交互性强:Jupyter Notebook 以单元格为单位组织代码,你能逐个单元格运行代码,并立即查看输出结果。这种交互方式让你可以快速测试代码片段、调整参数,实时看到代码执行效果,极大地提高了开发和调试效率。
- 支持多种编程语言:尽管名字源于 Julia、Python 和 R,但 Jupyter 通过内核机制支持超过 40 种编程语言,如 Java、Scala、Ruby 等。这意味着你可以在同一个环境中使用不同语言进行编程,满足多样化的需求。
- 可视化功能强大:能够直接在 Notebook 中显示各种可视化图表,如 Matplotlib、Seaborn 绘制的统计图表,Plotly 绘制的交互式图表等。这使得数据探索、分析和结果展示变得更加直观和便捷。
- 文档一体化:除了代码和输出,Jupyter Notebook 还支持 Markdown 文本、LaTeX 公式等,你可以在文档中添加解释说明、注释、理论推导等内容,将代码、数据、分析过程和结果整合在一个文档中,形成完整的分析报告或研究记录。
- 易于分享和协作:Jupyter Notebook 文件以
.ipynb格式保存,这种文件可以轻松地在不同平台和环境中共享。你可以将 Notebook 上传到 GitHub、Jupyter Notebook Viewer 等平台,供他人查看和交互;也可以通过 JupyterHub 实现多用户协作,多个用户可以同时在一个 Notebook 上进行编辑和讨论。
核心组件:
- Jupyter Notebook:这是 Jupyter 最常用的组件,是一个基于 Web 的交互式开发环境,用户可以通过浏览器访问和操作。在 Notebook 中,用户可以创建、编辑和运行代码单元格,同时添加文本说明和可视化结果。
- JupyterLab:是 Jupyter Notebook 的下一代用户界面,提供了更强大的功能和更灵活的界面布局。它支持多文档视图、文件浏览器、终端等,类似于传统的集成开发环境(IDE),为用户提供了更丰富的开发体验。
- Jupyter Kernel:内核是 Jupyter 实现多语言支持的关键。每个内核对应一种编程语言,负责执行用户输入的代码,并将执行结果返回给前端界面。例如,Python 内核可以执行 Python 代码,R 内核可以执行 R 代码。
应用场景:
- 数据科学与数据分析:Jupyter 是数据科学家和分析师的首选工具之一。在数据探索阶段,可以使用 Python 或 R 等语言对数据进行清洗、预处理和可视化;在建模阶段,可以使用机器学习库(如 Scikit-learn、TensorFlow)进行模型训练和评估;最后,将整个分析过程和结果整理成一个 Notebook 文档,方便分享和交流。
- 学术研究:研究人员可以使用 Jupyter Notebook 记录实验过程、展示研究成果。通过在文档中插入代码、数据和可视化图表,结合 LaTeX 公式进行理论推导,使研究报告更加清晰和直观。
- 教学:Jupyter 在教育领域也有广泛的应用。教师可以使用 Notebook 编写教学材料,将理论知识与实践代码相结合,让学生在交互式环境中学习编程和数据分析。学生可以通过运行和修改代码,加深对知识的理解和掌握。
使用步骤
安装:可以使用 pip 或 conda 进行安装。一般安装Anaconda时会自动安装Jupyter,可以在Anaconda文件下找到Jupyter Notebook。但是Jupyter默认只安装在base环境中,可以在新建的myenv环境当中再安装Jupyter。在Anaconda Prompt中进入myenv环境,输入以下指令安装
conda install nb_conda
启动:在终端中输入以下命令启动 JupyterNotebook:
jupyter notebook创建和编辑 Notebook:启动 JupyterLab 后,在浏览器中打开相应的界面,点击 “New” 按钮选择新环境创建一个新的 Notebook,然后就可以开始编写代码和文本了。


运行代码:在代码单元格中输入代码后,按下Shift + Enter组合键即可运行代码,并查看输出结果。
Python包的概念(package)
在 Python 中,package(包)是一种组织和管理模块的方式,它允许将相关的模块组合在一起,形成一个层次化的目录结构,以便更好地进行代码的组织、维护和重用。
一个 Python 包本质上是一个包含__init__.py文件的目录。这个目录下可以包含多个模块文件(.py文件)以及其他子包。例如,要创建一个名为mypackage的包,需要创建一个名为mypackage的目录,在该目录下创建__init__.py文件,还可以根据需要创建其他模块文件,如module1.py、module2.py等。(在包的目录中,__init__.py文件是必不可少的,它用于标识该目录是一个 Python 包。在__init__.py文件中,可以进行一些包的初始化操作,比如导入包中的其他模块、定义包的全局变量、执行一些初始化代码等。在 Python 3.3 及以上版本中,__init__.py文件不是必需的,但它仍然是一种很好的实践,有助于更好地组织和管理包的内容。)
可以使用import语句来导入包中的模块。例如,如果有一个包mypackage,其中包含module1.py模块,可以使用以下方式导入:
import mypackage.module1
# 或者
from mypackage import module1导入模块后,就可以使用模块中定义的函数、类、变量等。例如,如果module1.py中定义了一个函数func1,可以通过以下方式调用:
import mypackage.module1mypackage.module1.func1()
# 或者
from mypackage import module1module1.func1()常用的标准库包和第三方包:
- 标准库包:Python 标准库提供了许多有用的包,如
os包用于操作系统相关的操作,sys包用于访问 Python 解释器的相关信息和功能,math包用于数学计算等。 - 第三方包:在 Python 社区中,有大量的第三方包可供使用。例如,
numpy包用于数值计算,pandas包用于数据处理和分析,matplotlib包用于数据可视化,django和flask是用于 Web 开发的包等。
dir()与help()
在 Python 中,dir() 和 help() 是两个非常实用的内置函数,它们在探索和理解 Python 对象以及模块方面起着重要作用
dir()函数主要用于快速查看对象的属性和方法名称,它返回的是一个名称列表,不提供具体的使用说明。help()函数则专注于提供对象的详细帮助信息,对于理解对象的功能和使用方法非常有帮助。两者结合使用,可以更深入地探索和学习 Python 中的各种对象和模块。
1,dir()
dir() 函数用于返回指定对象的所有属性和方法的名称列表。如果不提供参数,它将返回当前作用域内的所有名称列表,包括变量名、函数名、类名等。
dir([object])其中,object 是可选参数,可以是任何 Python 对象,如模块、类、实例等。
使用示例:
# 不传入参数,返回当前作用域内的所有名称
result = dir()
print(result)# 传入math模块对象,返回math模块的所有属性和方法
import math
math_attributes = dir(math)
print(math_attributes)# 传入类或实例对象
class MyClass:def __init__(self):self.my_variable = 10def my_method(self):pass# 创建MyClass的实例
obj = MyClass()# 获取实例的属性和方法
instance_attributes = dir(obj)
print(instance_attributes)2,help()
help() 函数用于查看对象的详细帮助信息,它可以提供对象的文档字符串、用法说明、参数信息等。如果不提供参数,它将进入交互式帮助模式,允许你输入对象名称来获取帮助信息。
help([object])其中,object 是可选参数,可以是任何 Python 对象。
使用示例:
# 进入交互式帮助模式
help() 运行上述代码后,会进入 Python 的交互式帮助模式,你可以在提示符下输入对象名称来获取相应的帮助信息,输入 q 可以退出帮助模式。
import math
# 获取math模块的帮助信息
help(math)运行这段代码,会输出 math 模块的详细帮助信息,包括模块的概述、包含的函数和常量的说明等。
import math
# 获取math.sqrt函数的帮助信息
help(math.sqrt)这里使用 help(math.sqrt) 获取 math 模块中 sqrt 函数的详细帮助信息,包括函数的作用、参数和返回值等。
过拟合
过拟合指的是模型在训练数据上表现非常好,但在未见过的新数据(测试数据)上表现不佳的现象。简单来说,模型过度学习了训练数据中的细节和噪声,把一些只存在于训练数据中的特征也当作普遍规律来学习,导致模型对训练数据的拟合过于紧密,失去了对新数据的泛化能力。
表现:
- 训练集和测试集性能差异大:在训练过程中,模型在训练集上的损失函数值不断降低,准确率等评估指标不断提高,但在测试集上,损失函数值可能先降低后升高,准确率等指标达到一定程度后不再提升甚至下降。
- 对数据噪声敏感:过拟合的模型会把训练数据中的噪声也学习进来,当遇到新的数据时,即使数据与训练数据只有微小的差异(比如存在一些噪声干扰),模型的预测结果也会出现较大偏差。
原因:
- 模型复杂度高:如果模型具有过多的参数和复杂的结构,它就有更大的能力去拟合训练数据中的所有细节,包括噪声和异常值。例如,在多项式回归中,使用过高阶的多项式会使模型曲线过于复杂,紧密贴合训练数据点。
- 训练数据量不足:当训练数据量有限时,模型容易记住训练数据中的每一个样本,而不是学习到数据的普遍规律。例如,在图像分类任务中,如果训练图像的数量太少,模型可能只是记住了这些图像的特征,而无法对新的图像进行准确分类。
- 数据特征过多:如果输入数据包含大量的特征,其中可能有很多是与目标变量无关或者相关性很弱的特征。模型在训练过程中可能会利用这些无关特征来拟合训练数据,从而导致过拟合。
解决方法
- 增加训练数据:收集更多的数据可以让模型学习到更广泛的特征和规律,减少对训练数据中噪声和异常值的依赖。例如,在图像识别任务中,可以通过数据增强(如旋转、翻转、缩放等)的方法来增加训练数据的多样性。
- 正则化:正则化是一种常用的防止过拟合的方法,它通过在损失函数中添加额外的惩罚项来限制模型的复杂度。常见的正则化方法包括 L1 正则化和 L2 正则化。
- 使用 Dropout 层:在神经网络中,Dropout 层可以随机丢弃一部分神经元,使得模型不能过度依赖某些特定的神经元,从而增强模型的泛化能力。
- 提前停止训练:在训练过程中,监控模型在验证集上的性能。当验证集上的性能不再提升时,停止训练,避免模型过度拟合训练数据。
- 简化模型结构:减少模型的参数数量和复杂度,例如减少神经网络的层数或神经元数量,选择更简单的模型架构。
欠拟合
欠拟合指的是模型在训练数据上都无法很好地学习数据的特征和规律,导致在训练集和测试集上的表现都不佳的现象。简单来讲,模型过于简单,不能捕捉到数据中的复杂模式,从而无法对数据进行有效的拟合。
表现:
- 训练集和测试集性能都差:在训练过程中,模型在训练集上的损失函数值较高,准确率等评估指标较低,并且在测试集上的表现同样不理想。例如,在一个线性回归任务中,若使用简单的线性模型去拟合一个非线性的数据集,模型将无法准确地拟合数据,训练集和测试集上的误差都会很大。
- 模型预测结果与真实值偏差大:由于模型没有学习到数据的内在规律,其对数据的预测结果与真实值之间存在较大的差距。比如在图像分类任务中,欠拟合的模型可能无法正确区分不同类别的图像,分类准确率很低。
原因:
- 模型复杂度不够:如果选择的模型过于简单,它可能无法表达数据中的复杂关系。例如,对于一个具有复杂非线性关系的数据集,使用简单的线性模型就会导致欠拟合。
- 特征提取不充分:输入数据的特征不能很好地反映数据的本质信息,模型缺乏足够的信息来学习数据的规律。比如在文本分类任务中,如果只提取了文本中的少量关键词作为特征,而忽略了更多的语义和上下文信息,就可能导致模型欠拟合。
- 训练时间不足:在训练过程中,如果模型没有经过足够的迭代次数进行训练,就可能无法充分学习到数据的特征和规律。例如,在神经网络训练中,过早停止训练可能会使模型还没有收敛到较好的状态。
解决方法:
- 增加模型复杂度:选择更复杂的模型结构来拟合数据。例如,在回归任务中,可以从简单的线性模型转换为多项式回归模型;在神经网络中,可以增加网络的层数或神经元数量。
- 提取更多有效特征:对原始数据进行更深入的特征工程,提取更多能够反映数据本质信息的特征。比如在图像识别中,可以使用更高级的特征提取方法,如卷积神经网络自动提取图像的特征。
- 延长训练时间:增加模型的训练迭代次数,让模型有足够的时间来学习数据的特征和规律。同时,可以调整学习率等超参数,使模型能够更有效地收敛。
- 使用更合适的模型算法:根据数据的特点和问题的性质,选择更适合的模型算法。例如,对于非线性数据,可以选择决策树、支持向量机等非线性模型。
正则化
正则化(Regularization)是机器学习和深度学习中用于防止模型过拟合、提高模型泛化能力的重要技术。正则化是指在模型训练过程中,通过在损失函数中添加额外的惩罚项,来约束模型的复杂度,使得模型在学习数据特征的同时,不会过度拟合训练数据中的噪声和异常值,从而提高模型在未知数据上的泛化能力。
原理:
在机器学习中,模型的目标是最小化损失函数,以使得模型的预测结果尽可能接近真实值。然而,过于复杂的模型可能会在训练数据上表现得非常好,但在新数据上表现不佳,即出现过拟合现象。正则化的基本思想是,在损失函数中加入一个与模型复杂度相关的惩罚项,当模型变得过于复杂时,惩罚项的值会增大,从而增加损失函数的值。这样,模型在训练过程中需要在拟合数据和控制复杂度之间进行权衡,避免过度拟合训练数据。
常见的正则化类型:
1. L1 正则化(Lasso 正则化)
- 定义:在损失函数中添加模型参数的绝对值之和作为惩罚项。对于线性回归模型,带有 L1 正则化的损失函数可以表示为:

- 特点:L1 正则化具有特征选择的作用,它可以使部分参数变为 0,从而将一些不重要的特征剔除,得到一个更简洁的模型。
2. L2 正则化(Ridge 正则化)
- 定义:在损失函数中添加模型参数的平方和作为惩罚项。对于线性回归模型,带有 L2 正则化的损失函数可以表示为:

- 特点:L2 正则化会使模型参数的值变小,但不会将其变为 0。它可以防止模型参数变得过大,从而减少模型的复杂度。
3. Dropout(适用于神经网络)
- 定义:在神经网络的训练过程中,Dropout 会以一定的概率随机 “丢弃”(将神经元的输出置为 0)一部分神经元。这样可以使得模型不能过度依赖某些特定的神经元,从而增强模型的泛化能力。在测试阶段,通常会将所有神经元的输出乘以一个缩放因子(, 是丢弃概率)来保证训练和测试阶段的输出期望一致。
- 特点:Dropout 可以看作是一种特殊的正则化方法,它相当于在训练过程中随机组合不同的子网络进行训练,最终的模型是这些子网络的组合,从而提高了模型的泛化能力。
反向传播
反向传播(Backpropagation)是深度学习中用于训练神经网络的一种核心算法,它基于链式法则计算损失函数关于模型参数的梯度,并根据这些梯度来更新模型的参数,从而使得模型的预测结果逐渐接近真实值。
反向传播的核心原理是链式法则(Chain Rule)。在神经网络中,损失函数是关于模型参数(如权重和偏置)的复合函数。通过链式法则,可以将损失函数对每个参数的梯度计算分解为一系列局部梯度的乘积。具体来说,神经网络从输入层到输出层的前向传播过程会计算出预测结果,然后根据预测结果和真实标签计算损失函数的值。反向传播则是从输出层开始,沿着与前向传播相反的方向,依次计算损失函数对每一层参数的梯度。
步骤:
- 前向传播(Forward Propagation):从输入层开始,将输入数据依次通过神经网络的每一层,经过线性变换(如矩阵乘法)和非线性激活函数处理,最终得到输出层的预测结果。例如,对于一个简单的两层神经网络,输入层到隐藏层的线性变换可以表示为z1=W1x+b1,其中W1是输入层到隐藏层的权重矩阵,x是输入数据,b1是偏置向量;然后经过激活函数处理得到隐藏层的输出a1=f(z1),其中f是激活函数。接着,隐藏层到输出层的线性变换为z2=W2a1+b2,输出层的预测结果为ypred=f(z2)
-
计算损失(Loss Calculation):根据预测结果ypred和真实标签ytrue计算损失函数L(ypred,ytrue)的值。常见的损失函数包括均方误差损失(MSE)、交叉熵损失等。
-
反向传播(Backward Propagation):从输出层开始,根据链式法则依次计算损失函数对每一层参数的梯度

-
参数更新(Parameter Update):根据计算得到的梯度,使用优化算法(如随机梯度下降、Adam 等)更新模型的参数。例如,对于随机梯度下降算法,参数更新公式为

一,PyTorch加载数据
1,功能介绍
再PyTorch当中如何读取数据主要涉及到两个类,Dataset和Dataloader。在 PyTorch 中,Dataset 和 DataLoader 是用于数据处理和加载的两个核心组件,它们在深度学习项目中起着至关重要的作用.
Dataset 是一个抽象类,它定义了访问和处理数据的接口。其主要作用是封装数据集,提供一种统一的方式来获取数据集中的样本及其label标签并且会对其进行标号,方便后续的数据处理和模型训练。主要实现获取每个数据及其label并且告诉我们共有多少个数据这样的功能。用户可以通过继承 torch.utils.data.Dataset 类来创建自定义的数据集。
DataLoader 是一个可迭代对象,它基于 Dataset 进行数据加载和处理。其主要功能包括批量处理数据、打乱数据顺序、并行加载数据等,能够提高数据加载的效率,方便模型进行批量训练。
2,功能演示
(1)数据集的组织形式
创建数据集:创建数据集文件夹,并在文件夹里创建train文件夹,里面存放用于训练的数据,再创建val文件夹,里面存放用于验证的数据。以下图为例

训练集里存放着要训练的蚂蚁和蜜蜂的图片数据。这是一个用于区分蚂蚁和蜜蜂对其进行二分类的数据集。


文件夹的名称就是它们所对应的label,这是其中一种组织形式,还有一种组织形式如下 ,train_images文件夹用于存放图片,里面都是图片;train_labels文件夹存放标签,里面都是txt文件,txt文件里写着图片的label(文字的坐标信息以及文字是什么);还有一种不常见的组织形式是将label直接作为图片的命名

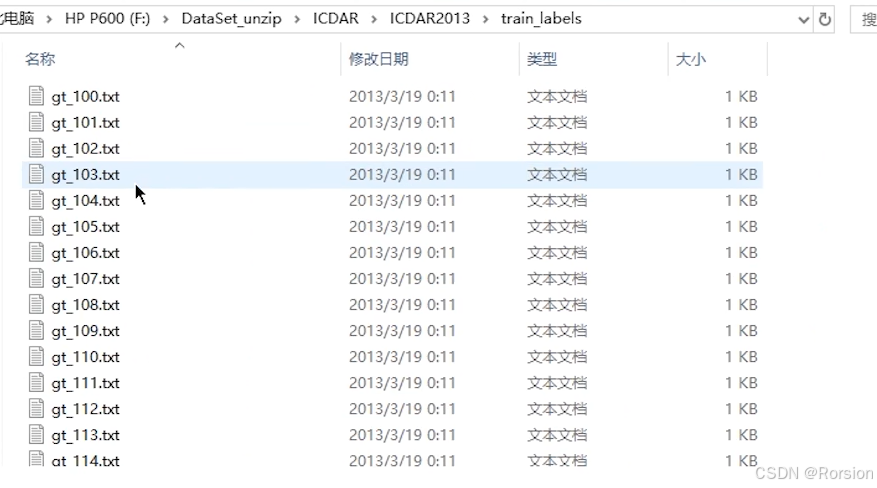

(2)Dataset功能演示
先使用help()指令或者Dataset??看如何使用Dataset

如下所示,介绍了Dataset是一个抽象类,所有的数据集都需要去集成这个类,所有的子类都应该重写__getitem__方法 (__getitem__ 方法是 Dataset 类的核心方法之一,它的主要功能是根据给定的索引,从数据集中获取对应的样本及其标签。该方法为数据的访问提供了一个统一的接口,使得后续的数据处理和模型训练可以方便地获取所需的数据。),同时我们也可以选择重写__len__方法(__len__ 方法的主要作用是返回数据集里样本的数量。它为后续的数据处理和模型训练提供了重要的信息,让程序知晓数据集的规模大小,进而合理地规划数据加载、迭代等操作。)

以下可以看到数据集存放在当前代码目录下

from torch.utils.data import Dataset# dataset数据集保存在当前代码路径下
class MyData(Dataset): # 继承Dataset类def __init__(self, root_dir, label_dir): # 初始化。实例化此类的时候会调用此函数self.root_dir = root_dirself.label_dir = label_dir # 实例化对象时创建root_dir,label_dir属性self.path = os.path.join(self.root_dir, self.label_dir) #拼接路径,获得数据集路径self.img_path = os.listdir(self.path) # 获得图片路径列表# idx作为图片编号输入图片。要读取某个图片时,需要获取图片的路径# 要遍历所有图片的路径需要将所有图片弄成一个列表,就要用到os.listdir()函数得到self.img_pathdef __getitem__(self, idx):# 获取其中的每一张图片img_name = self.img_path[idx]img_item_path = os.path.join(self.root_dir, self.label_dir) #获取每张图片的路径img = Image.open(img_item_path) label = self.label_dirreturn img, labeldef __len__(self):return len(self.img_path)root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)train_dataset = ants_dataset + bees_dataset
如下图所示,ants_dataset列表保存的就是各个img对象和label标签组成的元组

train_dataset = ants_dataset + bees_dataset 就相当于列表中元素拼接在一起,ants_dataset元素在前,bees_dataset元素在后。
二,TensorBoard的使用
1,介绍
在 PyTorch 中,TensorBoard 是一个强大的可视化工具,它最初由 TensorFlow 团队开发,PyTorch 通过torch.utils.tensorboard模块集成了 TensorBoard 的功能。TensorBoard 主要用于帮助用户在深度学习模型的训练和开发过程中进行可视化和监控。
- 标量可视化(Scalars):在训练过程中,我们通常会关注一些标量值,如损失值(Loss)、准确率(Accuracy)等。TensorBoard 可以将这些标量值随训练步数的变化绘制成折线图,帮助我们直观地观察模型的训练趋势,判断模型是否收敛、是否过拟合等。
- 图像可视化(Images)TensorBoard 可以展示训练数据、生成的图像、模型的中间特征图等。这对于计算机视觉任务尤为有用,例如在图像分类、目标检测、图像生成等任务中,我们可以通过可视化图像来检查数据的预处理是否正确,或者观察生成模型的输出效果
- 直方图可视化(Histograms):在深度学习中,我们经常需要观察模型参数(如权重、偏置)和梯度的分布情况。TensorBoard 的直方图功能可以展示这些张量的分布随训练步数的变化,帮助我们了解模型参数的更新情况,判断是否存在梯度消失或梯度爆炸等问题。
- 模型结构可视化(Graphs):TensorBoard 可以将 PyTorch 模型的计算图可视化,展示模型的结构和数据流。这有助于我们理解模型的架构,检查模型的输入输出是否正确。
- 嵌入可视化(Embeddings):在处理高维数据时,如文本、图像等,我们通常会使用嵌入(Embedding)技术将数据映射到低维空间。TensorBoard 的嵌入可视化功能可以将这些低维嵌入向量可视化,帮助我们观察数据的聚类情况和分布特征。
打开项目,并将其环境设置为要使用PyTorch的那个环境,这里我们命名为myTorch。
2,安装
在Anaconda Prompt中激活要安装到的对应环境或者在PyCharm终端输入pip install tensorboard
3,SummaryWriter类
它主要用于将各种类型的数据写入事件文件(log_dir文件夹),这些文件可以被 TensorBoard 读取并进行可视化展示。
SummaryWriter 类的主要功能是创建一个用于写入事件的对象,通过调用该对象的不同方法,可以将标量、图像、直方图、模型图等不同类型的数据写入指定的日志目录,方便后续使用 TensorBoard 进行可视化分析。

可以看到初始化函数需要我们输入文件夹保存的目录log_dir,如果不输入也是可以的。 后面的参数不常用。
重要的函数是add_image()和add_scalar()和close()函数,其余作为了解即可,也并没有很详细的介绍
(1)实例化类

from torch.utils.tensorboard import SummaryWriter# 创建一个 SummaryWriter 对象,指定日志保存的目录
# 如果不指定目录,默认会在 runs 目录下创建一个以当前时间戳命名的子目录
writer = SummaryWriter('runs/my_experiment')以下是官方给的示例

关闭 SummaryWriter.在完成数据写入后,建议关闭 SummaryWriter 对象,以确保所有数据都被正确写入磁盘。
# 关闭 SummaryWriter
writer.close()(2)add_scalar()函数
用于记录训练过程中的标量值,如损失值、准确率等,随着训练步骤的增加,可观察这些值的变化趋势。函数定义如下
add_scalar(tag, scalar_value, global_step=None, walltime=None)tag:- 类型:字符串(
str)。 - 作用:用于标识这个标量的名称,通常会以一种有层次的命名方式,比如
'Loss/train'表示训练过程中的损失值,'Accuracy/val'表示验证集上的准确率。在 TensorBoard 的可视化界面中,不同的tag会对应不同的折线图。
- 类型:字符串(
scalar_value:- 类型:浮点数(
float)或整数(int)。 - 作用:需要记录的标量值,例如训练过程中的损失值、准确率等。
- 类型:浮点数(
global_step:- 类型:整数(
int),可选参数,默认值为None。 - 作用:表示当前的训练步骤,通常是训练的轮数(epoch)或者迭代次数(iteration)。TensorBoard 会根据
global_step的值来确定在 x 轴上的位置,从而绘制出标量值随训练步骤的变化曲线。
- 类型:整数(
walltime:- 类型:浮点数(
float),可选参数,默认值为None。 - 作用:表示记录该标量值的实际时间(以秒为单位)。如果不指定,会使用当前系统时间。一般情况下,这个参数可以不设置。
- 类型:浮点数(
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter("logs")# 模拟训练过程
for epoch in range(100):# 模拟损失值loss = 1 / (epoch + 1)# 将损失值写入 TensorBoardwriter.add_scalar('y=x', loss, epoch)write.close()运行完成后就可以看到在当前目录中产生了logs文件夹,文件夹下就是产生的事件文件

同一个 tag名下的不同事件会集中在一个坐标轴下
先查看(4)打开事件一节!!!
补充:记录多个不同类型的标量值
from torch.utils.tensorboard import SummaryWriter
import torch# 创建一个 SummaryWriter 对象
writer = SummaryWriter('runs/multiple_scalars')# 模拟训练过程
num_epochs = 100
for epoch in range(num_epochs):# 模拟训练损失值train_loss = 1 / (epoch + 1)# 模拟验证集准确率val_accuracy = epoch / num_epochs# 记录训练损失值writer.add_scalar('Loss/train', train_loss, epoch)# 记录验证集准确率writer.add_scalar('Accuracy/val', val_accuracy, epoch)# 关闭 SummaryWriter
writer.close()(3)add_image()函数
可将图像数据(如训练样本、生成的图像等)写入日志,方便直观查看。
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')tag- 类型:字符串(
str)。 - 作用:图像的标识名称,用于在 TensorBoard 界面中区分不同的图像。例如,
'Training Images'、'Generated Images'等。
- 类型:字符串(
img_tensor- 类型:
torch.Tensor或numpy.ndarray。 - 作用:要记录的图像数据。该张量或数组需要遵循特定的数据格式,具体格式由
dataformats参数指定,一般采用HWC这种numpy型的格式。
- 类型:
global_step- 类型:整数(
int),可选参数,默认值为None。 - 作用:表示当前的训练步骤,通常是训练的轮数(epoch)或者迭代次数(iteration)。TensorBoard 会根据
global_step的值来确定图像的显示顺序,方便观察图像随训练过程的变化。
- 类型:整数(
walltime- 类型:浮点数(
float),可选参数,默认值为None。 - 作用:表示记录该图像的实际时间(以秒为单位)。如果不指定,会使用当前系统时间。一般情况下,这个参数可以不设置。
- 类型:浮点数(
dataformats- 类型:字符串(
str),可选参数,默认值为'CHW'。 - 作用:指定
img_tensor的数据格式。常见的格式有:'CHW':表示通道(Channel)、高度(Height)、宽度(Width)的顺序,这是 PyTorch 中图像数据的常见格式。'HWC':表示高度、宽度、通道的顺序,这是 OpenCV 等库中常用的格式,也是numpy型的数据。'HW':用于单通道图像,表示高度和宽度。
- 类型:字符串(
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image # 用于读取图像writer = SummaryWriter("logs")
image_path = "data/train/ants_image/0013035.jpg" # 图像相对路径
img_PIL = Image.open(image_path) # 读取图像为PIL格式
img_array = np.array(img_PIL) # 将图像转换为numpy的格式
print(imag_array.shape) # 打印查看是否为HWC三通道writer.add_image("test", img_array, 1, dataformats='HWC')write.close()点击进入到image界面,就可以看到图像了

补充:使用 torch.Tensor类型读取单张图像
import torch
from torch.utils.tensorboard import SummaryWriter# 创建一个 SummaryWriter 对象
writer = SummaryWriter('runs/image_example')# 模拟一张 3 通道的图像数据,形状为 (3, 224, 224)
'''torch.randn 是 PyTorch 库中一个常用的函数,用于生成服从标准正态分布(均值为 0,标准差为 1)的
随机数张量。torch.randn 函数在 torch 命名空间下,可直接通过 torch.randn() 调用,它主要用于创建随
机初始化的张量,在深度学习模型初始化权重、生成随机噪声等场景中非常有用。如下所示是创建三维张量,这里
只知道是创建一张图像即可'''
img_tensor = torch.randn(3, 224, 224)# 将图像写入 TensorBoard
writer.add_image('Single Image', img_tensor, global_step=0)# 关闭 SummaryWriter
writer.close()补充:写入写入多张图像组成的网格。仅作了解,函数看不懂没关系
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets, transforms# 创建一个 SummaryWriter 对象
writer = SummaryWriter('runs/image_grid_example')# 加载 MNIST 数据集
transform = transforms.Compose([transforms.ToTensor()])
trainset = datasets.MNIST('mnist_train', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)# 获取一批图像数据
images, labels = next(iter(trainloader))# 创建一个图像网格
img_grid = torchvision.utils.make_grid(images)# 将图像网格写入 TensorBoard
writer.add_image('MNIST Images Grid', img_grid, global_step=0)# 关闭 SummaryWriter
writer.close()(4)打开事件
在终端中输入tensorboard --logdir=logs(logdir=事件文件所在文件夹名),如下,点击http://localhost:6006即可打开

也可以指定端口号

之后每次修改完数据,只要端口号不变,代码运行后进入gttp://localhost:6007然后点击右上角更新即可 。

(5)add_histogram()函数
用于记录张量的直方图,可观察模型参数(如权重、偏置)或梯度的分布情况
import torch.nn as nn# 定义一个简单的神经网络
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet, self).__init__()self.fc = nn.Linear(10, 1)def forward(self, x):return self.fc(x)# 初始化模型
model = SimpleNet()# 模拟训练过程
for step in range(100):# 模拟输入数据inputs = torch.randn(32, 10)outputs = model(inputs)# 模拟损失计算loss = outputs.sum()loss.backward()# 将模型参数的直方图写入 TensorBoardfor name, param in model.named_parameters():writer.add_histogram(name, param, step)# 清空梯度model.zero_grad()(6)add_graph函数
将 PyTorch 模型的计算图写入日志,方便查看模型的结构和数据流。
# 模拟输入数据
inputs = torch.randn(32, 10)# 将模型的计算图写入 TensorBoard
writer.add_graph(model, inputs)三,torchvision中的transforms
在 PyTorch 的 torchvision 库中,transforms 模块提供了一系列用于图像预处理和数据增强的工具。这些工具可以帮助我们对图像数据进行各种转换操作,使得数据更适合模型的训练和评估。
常见功能:
- 数据预处理:对图像进行标准化、归一化、调整大小等操作,使输入数据具有一致的格式和范围,有助于模型的收敛和性能提升。
- 数据增强:通过随机裁剪、翻转、旋转等操作增加训练数据的多样性,提高模型的泛化能力,减少过拟合的风险。
以下是对transform类的简介。
1. 转换类
这类主要用于在不同数据类型之间进行转换,例如将 PIL 图像转换为 torch.Tensor,或者将 torch.Tensor 转换回 PIL 图像。
ToTensor:将PIL图像或NumPy数组转换为torch.Tensor,并将像素值从[0, 255]归一化到[0, 1]。ToPILImage:将torch.Tensor或NumPy数组转换为PIL图像。Lambda:应用一个用户自定义的 lambda 函数进行转换。
2. 裁剪类
用于对图像进行裁剪操作,可调整图像的尺寸和保留特定区域。
CenterCrop:从图像的中心位置裁剪出指定大小的图像区域。RandomCrop:随机裁剪图像到指定的大小。RandomResizedCrop:随机裁剪图像并调整大小,裁剪区域的大小和长宽比是随机的。FiveCrop:在图像的四个角和中心位置进行裁剪,返回包含五个裁剪图像的元组。TenCrop:在图像的四个角、中心位置进行裁剪,并对这些裁剪图像进行水平翻转,返回包含十个裁剪图像的元组。
3. 调整大小类
改变图像的尺寸,以满足模型输入的要求。
Resize:将图像的大小调整为指定的尺寸。可以传入一个整数或元组作为目标尺寸。Pad:在图像的边缘填充指定的像素值,可用于调整图像的大小或添加边框。
4. 翻转和旋转类
通过翻转和旋转操作增加数据的多样性,提高模型的泛化能力。
RandomHorizontalFlip:以指定的概率随机水平翻转图像。RandomVerticalFlip:以指定的概率随机垂直翻转图像。RandomRotation:随机旋转图像,旋转角度在指定范围内。RandomAffine:对图像进行随机仿射变换,包括旋转、平移、缩放和剪切等操作。
5. 颜色变换类
对图像的颜色属性进行调整,如亮度、对比度、饱和度和色调等。
ColorJitter:随机调整图像的亮度、对比度、饱和度和色调。Grayscale:将图像转换为灰度图像。RandomGrayscale:以指定的概率将图像转换为灰度图像。
6. 归一化类
对图像的像素值进行归一化处理,使数据具有统一的分布。
Normalize:对图像的每个通道减去指定的均值并除以指定的标准差。
7. 组合类
用于将多个转换操作组合成一个序列,方便一次性应用多个转换。
Compose:将多个转换操作按顺序组合在一起。
8. 其他类
RandomChoice:从给定的一组转换操作中随机选择一个进行应用。RandomApply:以指定的概率随机应用一组转换操作。
以下是对常用类的具体介绍。因为都是类,所以用的时候都是先创建对象再使用
1,常用转换类
(1)ToTensor()
它主要用于把 PIL 图像或者 NumPy 数组转换为 torch.Tensor 类型,并且会对像素值进行一定的处理。
在深度学习任务中,模型通常要求输入数据为 torch.Tensor 类型,而原始的图像数据一般以 PIL 图像或者 NumPy 数组的形式存在。ToTensor() 类就提供了一种方便的方式将这些数据转换为模型可处理的张量格式,同时还会将像素值的范围从 [0, 255] 归一化到 [0, 1]。
torchvision.transforms.ToTensor()ToTensor() 类没有可传入的参数,调用时直接实例化即可。
from PIL import Image
import torchvision.transforms as transforms
import torch# 打开一张图像
image = Image.open('example.jpg')# 定义 ToTensor 转换操作
to_tensor = transforms.ToTensor()# 将 PIL 图像转换为 torch.Tensor
tensor_image = to_tensor(image)print("转换后的张量形状:", tensor_image.shape)
print("张量的数据类型:", tensor_image.dtype)
print("张量的最小值:", tensor_image.min().item())
print("张量的最大值:", tensor_image.max().item())在上述代码中,首先使用 PIL 库打开一张图像,然后实例化 ToTensor() 类并将其应用到图像上,将图像转换为 torch.Tensor。最后打印出转换后张量的形状、数据类型以及最小值和最大值,可看到最大值不超过 1,最小值不小于 0。
注意事项:
- 输入数据格式:
ToTensor()接受的输入可以是PIL.Image.Image对象或者NumPy数组(形状为(H, W, C),其中H是高度,W是宽度,C是通道数)。 - 像素值归一化:转换后的
torch.Tensor像素值范围会被归一化到[0, 1],这是因为深度学习模型通常更喜欢处理这种范围的数据。 - 通道顺序:转换后的张量形状为
(C, H, W),即通道维度在前,与PIL图像和NumPy数组的(H, W, C)顺序不同。
为什么要使用tensor数据类型?
在深度学习中广泛使用 Tensor 数据类型(如 PyTorch 里的 torch.Tensor),主要是因为它具有多方面的优势,能很好地适配深度学习的各类任务和计算需求。而且它包装了神经网络所需要的参数

1. 高效的数值计算
- 硬件加速:
Tensor可以充分利用 GPU(图形处理单元)进行高效的并行计算。现代的深度学习任务通常涉及大量的矩阵运算,如卷积、矩阵乘法等。GPU 拥有数千个小型处理核心,能够同时处理多个数据元素,使得这些矩阵运算的速度大幅提升。例如,在训练一个大型的卷积神经网络(CNN)时,使用 GPU 进行Tensor计算可以将训练时间从数天缩短至数小时甚至更短。 - 优化的底层库支持:许多深度学习框架(如 PyTorch、TensorFlow)都在底层集成了高度优化的数值计算库,如 CUDA(NVIDIA 提供的并行计算平台和编程模型)和 cuDNN(NVIDIA 提供的深度神经网络库)。这些库针对
Tensor运算进行了专门的优化,能够充分发挥硬件的性能。
2. 自动求导机制
- 简化模型训练:在深度学习中,训练模型的核心是通过反向传播算法计算梯度,并根据梯度更新模型的参数。
Tensor数据类型支持自动求导(如 PyTorch 中的autograd机制),这意味着当你定义好一个计算图(由Tensor之间的运算构成)后,框架可以自动计算出每个参数的梯度。例如,在训练一个简单的全连接神经网络时,你只需要定义好前向传播的过程,框架就能自动完成反向传播的计算,大大简化了模型训练的代码实现。 - 灵活性和可扩展性:自动求导机制使得你可以自由组合各种运算和模型结构,而无需手动推导和实现复杂的求导公式。这为研究人员和开发者提供了极大的灵活性,能够快速尝试不同的模型架构和算法。
3. 统一的数据表示
- 支持多维数据:深度学习任务中处理的数据类型多样,如图像、音频、文本等。
Tensor是一种多维数组,可以方便地表示这些不同类型的数据。例如,一张彩色图像可以表示为一个形状为(C, H, W)的三维Tensor,其中C是通道数(如 RGB 图像的通道数为 3),H是图像的高度,W是图像的宽度。这种统一的数据表示方式使得不同类型的数据可以使用相同的计算和处理方法。 - 易于集成和处理:在深度学习框架中,
Tensor是各个模块之间传递数据的标准格式。无论是数据加载、模型定义还是损失计算,都可以使用Tensor进行统一处理,避免了不同数据格式之间转换的复杂性。
4. 分布式训练支持
- 多设备并行:随着深度学习模型的规模不断增大,单台设备的计算资源可能无法满足训练需求。
Tensor支持分布式训练,可以将数据和计算任务分配到多个 GPU 或多台机器上并行进行。例如,在使用 PyTorch 的DistributedDataParallel模块时,可以将一个大型的神经网络模型分布到多个 GPU 上进行训练,每个 GPU 处理一部分数据,从而加速训练过程。 - 数据同步和通信:在分布式训练中,不同设备之间需要进行数据同步和通信,以保证模型参数的一致性。
Tensor数据类型提供了相应的机制来处理这些问题,使得分布式训练能够高效、稳定地进行。
5. 与深度学习框架的无缝集成
- 丰富的 API 支持:深度学习框架为
Tensor提供了丰富的 API,涵盖了各种数值运算、数学函数、数据处理等功能。例如,在 PyTorch 中,你可以使用Tensor的add、mul等方法进行基本的数学运算,也可以使用torch.nn模块中的各种层(如nn.Conv2d、nn.Linear)对Tensor进行处理。 - 模型构建和训练流程的整合:
Tensor是深度学习框架中模型构建和训练流程的核心数据结构。从数据加载、模型定义、前向传播、损失计算到反向传播和参数更新,整个过程都围绕着Tensor展开,使得开发者可以方便地构建和训练复杂的深度学习模型。
(2)ToPILImage()
它的主要作用是将 torch.Tensor 类型的张量或者 numpy.ndarray 类型的数组转换为 PIL.Image.Image 类型的图像对象。
在深度学习任务中,模型处理的数据通常是 torch.Tensor 类型,而在进行图像的可视化、保存或者使用一些基于 PIL(Python Imaging Library)库的图像处理操作时,我们需要将数据转换为 PIL 图像格式。ToPILImage() 就提供了这样一种便捷的转换方式。
torchvision.transforms.ToPILImage(mode=None)mode:可选参数,用于指定PIL图像的模式。常见的模式有'L'(灰度图)、'RGB'(真彩色图)等。如果不指定,ToPILImage会根据输入张量的通道数自动推断模式。
import torch
import torchvision.transforms as transforms
from PIL import Image
import matplotlib.pyplot as plt# 生成一个随机的 3 通道图像张量,形状为 (3, 224, 224)
image_tensor = torch.randn(3, 224, 224)# 将张量的值范围从 [-1, 1] 映射到 [0, 1]
image_tensor = (image_tensor + 1) / 2
image_tensor = image_tensor.clamp(0, 1)# 定义 ToPILImage 转换操作
to_pil = transforms.ToPILImage()# 将张量转换为 PIL 图像
pil_image = to_pil(image_tensor)# 显示 PIL 图像
plt.imshow(pil_image)
plt.axis('off')
plt.show() 在上述代码中,首先生成了一个随机的图像张量,然后对其进行了简单的归一化处理,确保像素值在 [0, 1] 范围内。接着使用 ToPILImage() 将张量转换为 PIL 图像,并使用 matplotlib 库将其显示出来。
注意事项:
- 输入的
torch.Tensor或numpy.ndarray数据需要满足一定的要求。对于torch.Tensor,其形状通常为(C, H, W),其中C是通道数,H是高度,W是宽度,且数据类型应为torch.float32或torch.uint8。 - 如果输入的张量像素值范围不在
[0, 255](对于torch.uint8类型)或[0, 1](对于torch.float32类型)内,可能会导致转换后的图像显示异常,因此在转换前需要进行适当的归一化或缩放处理。
(3)Normalize(mean, std)
Normalize(mean, std) 是一个用于对图像数据进行归一化处理的重要转换类。归一化是深度学习中常用的数据预处理步骤,它有助于提高模型的训练效率和稳定性。
Normalize(mean, std) 类的主要作用是对输入的图像张量进行标准化(归一化)操作。具体来说,它会对图像的每个通道分别减去指定的均值 mean,并除以指定的标准差 std。这样做可以将图像数据的分布调整到均值为 0、标准差为 1 的标准正态分布,使得不同样本之间的数据具有可比性,有助于模型更快地收敛,同时也能在一定程度上减少梯度消失或梯度爆炸的问题。
torchvision.transforms.Normalize(mean, std, inplace=False)参数说明:
mean:一个序列(如列表、元组),其长度等于图像的通道数。每个元素表示对应通道的均值。例如,对于 RGB 图像,mean可以是[0.485, 0.456, 0.406]。std:同样是一个序列,长度与mean相同,每个元素表示对应通道的标准差。例如,对于 RGB 图像,std可以是[0.229, 0.224, 0.225]。inplace:一个布尔值,默认为False。如果设置为True,则会直接在输入的张量上进行归一化操作,而不创建新的张量。
归一化后会改变像素值,图像颜色也会改变
import torch
import torchvision.transforms as transforms# 模拟一张 3 通道的图像张量,形状为 (3, 224, 224)
image_tensor = torch.randn(3, 224, 224)# 定义归一化操作,指定每个通道的均值和标准差
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])# 应用归一化操作。传入的必须是tensor数据类型
normalized_tensor = normalize(image_tensor)print("归一化前张量的均值和标准差:")
for i in range(3):print(f"通道 {i} 均值: {image_tensor[i].mean().item():.4f}, 标准差: {image_tensor[i].std().item():.4f}")print("\n归一化后张量的均值和标准差:")
for i in range(3):print(f"通道 {i} 均值: {normalized_tensor[i].mean().item():.4f}, 标准差: {normalized_tensor[i].std().item():.4f}")在上述代码中,首先创建了一个随机的图像张量,然后定义了 Normalize 转换操作,并将其应用到图像张量上。最后分别打印出归一化前后每个通道的均值和标准差,可以看到归一化后的数据更接近标准正态分布。
(4)Resize(size)
将图像的大小调整为指定的尺寸。size 可以是一个整数,表示将图像的短边调整为该值,长边按比例缩放;也可以是一个元组 (height, width),表示将图像调整为指定的高度和宽度。
# 定义调整大小操作,将图像短边调整为 256
resize = transforms.Resize(256)# 应用调整大小操作
resized_image = resize(image)(5)RandomCrop(size)
随机裁剪图像到指定的大小。size 可以是一个整数或元组,含义与 Resize 类似。
# 定义随机裁剪操作,裁剪出 224x224 的图像
random_crop = transforms.RandomCrop(224)# 应用随机裁剪操作
cropped_image = random_crop(image) (6)RandomHorizontalFlip(p=0.5)
以概率 p 随机水平翻转图像。默认概率为 0.5。
# 定义随机水平翻转操作
random_flip = transforms.RandomHorizontalFlip()# 应用随机水平翻转操作
flipped_image = random_flip(image) (7)RandomRotation(degrees)
随机旋转图像,degrees 可以是一个整数或元组。如果是整数,表示在 [-degrees, degrees] 范围内随机旋转;如果是元组 (min_degrees, max_degrees),表示在该范围内随机旋转。
# 定义随机旋转操作,在 [-10, 10] 度范围内随机旋转
random_rotation = transforms.RandomRotation(10)# 应用随机旋转操作
rotated_image = random_rotation(image)(8)CenterCrop(size)
CenterCrop 是一个用于图像裁剪的转换类。它的主要作用是从输入图像的中心位置裁剪出指定大小的图像区域,这在图像预处理和数据增强中是一个常见的操作。
参数size可以是一个整数,也可以是一个元组 (height, width)。
- 当
size为整数时,会将图像裁剪成一个正方形,边长为该整数。 - 当
size为元组时,会将图像裁剪成指定的高度和宽度。
# 定义 CenterCrop 转换操作,将图像裁剪成高度为 150,宽度为 200 的矩形
center_crop = transforms.CenterCrop((150, 200))# 应用裁剪操作
cropped_image = center_crop(image)# 显示裁剪后的图像
plt.imshow(cropped_image)
plt.axis('off')
plt.show()2,组合多个转换操作
(1)Compose
通常我们会将多个转换操作组合在一起使用,transforms.Compose 类可以帮助我们实现这一点。
# 定义一个组合转换操作
transform = transforms.Compose([transforms.Resize(256),transforms.RandomCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 应用组合转换操作
transformed_image = transform(image)也可以是下图用法,直接将实例化的对象放入compose中

四,transforms用在数据集中
1,torchvision.datasets
torchvision.datasets 是 PyTorch 中 torchvision 库提供的一个模块,它主要用于加载和处理计算机视觉领域中常用的公开数据集(是指那些被广泛公开共享、可供研究人员和开发者免费使用的图像或视频相关数据集)。这个模块为开发者提供了便捷的接口,使得在进行图像分类、目标检测、语义分割等任务时,可以轻松地获取和使用各种标准数据集,而无需手动编写复杂的数据加载和预处理代码。
主要功能:
- 数据加载:可以直接从网络下载数据集,并将其加载到内存中,方便后续的模型训练和评估。
- 数据预处理:支持对加载的数据进行各种预处理操作,如调整图像大小、归一化、裁剪等。
- 数据集划分:可以将数据集划分为训练集、验证集和测试集,以便进行模型的训练、调优和评估。
常见类型:
各个数据集要输入的参数都比较相近,在实例中会演示以CIFAR10为例的使用。
1,图像分类数据集
- MNIST:由手写数字的图像组成,包含 60,000 张训练图像和 10,000 张测试图像,图像大小为 28x28 像素,共 10 个类别(数字 0 - 9),是图像分类任务的入门级数据集。
- CIFAR - 10:包含 60,000 张 32x32 的彩色图像,分为 10 个不同的类别,如飞机、汽车、鸟类等,常用于评估图像分类算法的性能。
- ImageNet:大规模图像数据集,包含超过 1400 万张图像,分为 1000 个不同的类别,是目前计算机视觉领域最具影响力的数据集之一,广泛用于图像分类、目标检测等任务的研究。
2,目标检测数据集
- PASCAL VOC:包含了 20 个不同类别的目标,如人、汽车、狗等,提供了图像、目标的边界框标注以及分割标注,是目标检测和语义分割领域的经典数据集。
- COCO:一个大型的目标检测、实例分割和关键点检测数据集,包含了大量的图像和丰富的标注信息,涵盖了 80 个不同的目标类别,广泛应用于目标检测和相关领域的研究。
3,语义分割数据集
- Cityscapes:主要用于城市街道场景的语义分割任务,包含了来自 50 个不同城市的街道场景图像,提供了详细的像素级标注,涵盖了 30 个不同的类别,如道路、建筑物、行人等。
- CamVid:由驾驶场景的视频帧组成,用于语义分割任务,包含 32 个不同的类别,如天空、道路、汽车等,数据规模相对较小,但对于研究驾驶场景的语义分割具有重要价值。
4,视频相关数据集
- UCF101:包含 101 个不同类别的动作视频,如篮球、骑自行车、跳舞等,每个类别有多个视频样本,常用于视频动作识别任务的研究。
- Kinetics:大规模的视频动作识别数据集,包含了数百万个短视频,涵盖了 400 多个不同的人类动作类别,为视频动作识别模型的训练提供了丰富的数据资源。
2,torchvision. models
(1)介绍
torchvision.models 是 PyTorch 中 torchvision 库提供的一个重要模块,它包含了许多预训练好的计算机视觉模型,同时还提供了这些模型对应的预训练权重。
预训练模型是指在大规模数据集(如 ImageNet)上进行过训练的模型。这些模型已经学习到了大量图像的通用特征和模式,能够对图像进行有效的特征提取和分类等操作。使用预训练模型可以节省大量的训练时间和计算资源,并且在很多情况下能够提高模型在新任务上的性能。预训练模型有既定的、设计好的网络结构。研究人员和开发者经过大量实验和研究,设计出了一系列适用于不同计算机视觉任务的高效架构,这些架构是预训练模型的基础框架。以Resnet为例,ResNet 预训练模型最初是在 ImageNet 数据集上训练的,能够识别 1000 个类别的物体。然而,我们要训练自己的模型的时候可以使用Resnet作为特征提取器,从而迁移学习,适应新的分类任务。
预训练权重是指预训练模型在大规模数据集上训练后得到的模型参数。这些权重包含了模型学习到的图像特征和模式信息,在使用预训练模型时,可以直接加载这些权重,使得模型能够利用之前学习到的知识来处理新的数据。
(2)预训练权重
简单来说,预训练权重就是预训练模型在大规模数据集上经过训练后所学习到的模型参数的集合。
定义和存储形式:
- 定义:在神经网络中,权重是连接不同层神经元的参数,控制着信息在网络中的流动和转换。预训练权重就是模型在特定大规模数据集上进行训练后,这些权重所达到的一组特定取值。
- 存储形式:通常以文件的形式保存,不同的深度学习框架有不同的存储格式。例如,在 PyTorch 中,预训练权重一般保存为
.pth或.pt文件;在 TensorFlow 中,常见的保存格式是.ckpt或.h5文件。
学习过程:
预训练权重是通过在大规模数据集上进行迭代训练学习得到的。以图像分类任务为例,一般步骤如下:
- 数据输入:将大规模数据集中的图像样本输入到神经网络模型中。
- 前向传播:图像数据在网络中逐层传递,经过卷积、激活、池化等操作,最终得到模型的预测结果。
- 损失计算:将模型的预测结果与真实标签进行对比,使用损失函数(如交叉熵损失函数)计算两者之间的差异,得到损失值。
- 反向传播:根据损失值,使用优化算法(如随机梯度下降、Adam 等)计算每个权重参数的梯度,以确定如何调整权重能使损失值减小。
- 权重更新:根据计算得到的梯度,更新网络中的权重参数。
- 迭代训练:重复上述步骤,不断调整权重参数,直到模型在训练集上的性能达到满意的程度,此时得到的权重参数就是预训练权重
作用:
- 加速模型收敛:使用预训练权重初始化模型后,模型已经具备了一定的特征提取能力,在新的数据集上进行训练时,不需要从头开始学习所有的特征,从而可以大大减少训练时间,加快模型的收敛速度。
- 提高模型性能:尤其是在新数据集规模较小的情况下,预训练权重能够帮助模型学习到更通用、更有效的特征,避免模型因数据不足而出现过拟合现象,从而提高模型在新任务上的泛化能力和性能。
使用方式:
在不同的深度学习框架中,使用预训练权重的方式有所不同,但总体思路一致,即加载预训练权重文件并将其应用到模型中。
import torch
import torchvision.models as models# 加载预训练的 ResNet18 模型
model = models.resnet18(pretrained=True) # 设置 pretrained=True 会自动下载并加载预训练权重# 或者手动加载预训练权重文件
model = models.resnet18(pretrained=False)
pretrained_weights = torch.load('resnet18_pretrained.pth')
model.load_state_dict(pretrained_weights)(3)常见模型介绍
1,图像分类模型
- AlexNet:2012 年 ImageNet 图像分类竞赛冠军模型,开启了深度学习在计算机视觉领域的热潮,引入了 ReLU 激活函数、Dropout 等技术。
- VGG:具有非常深的网络结构,通过堆叠多个小卷积核(如 3x3)来增加网络的深度,提高特征提取能力,有 VGG11、VGG13、VGG16、VGG19 等不同版本。
- ResNet:引入了残差块(Residual Block)的概念,解决了深度神经网络训练过程中的梯度消失和梯度爆炸问题,能够训练更深的网络,有 ResNet18、ResNet34、ResNet50 等不同深度的版本。
import torchvision.models as models# 加载预训练的 AlexNet 模型
alexnet = models.alexnet(pretrained=True)# 加载预训练的 VGG16 模型
vgg16 = models.vgg16(pretrained=True)# 加载预训练的 ResNet50 模型
resnet50 = models.resnet50(pretrained=True)2,目标检测模型
- Faster R - CNN:一种两阶段的目标检测模型,通过区域建议网络(RPN)生成候选区域,然后对这些候选区域进行分类和边界框回归,实现目标的检测。
import torchvision.models as models# 加载预训练的 Faster R - CNN 模型
faster_rcnn = models.detection.fasterrcnn_resnet50_fpn(pretrained=True)3,语义分割模型
- DeepLabV3:用于语义分割任务,通过空洞卷积(Atrous Convolution)增大感受野,同时引入了多尺度特征融合的机制,提高分割的精度。
import torchvision.models as models# 加载预训练的 DeepLabV3 模型
deeplabv3 = models.segmentation.deeplabv3_resnet50(pretrained=True)3,实例
(1)CIFAR10数据集的使用
以下图片为PyTorch官网给的参数解释

root
- 类型:字符串
- 作用:指定数据集的存储路径。若该路径下不存在 CIFAR - 10 数据集,且
download参数设为True,则会自动将数据集下载到该路径。
from torchvision import datasets# 数据集将存储在当前目录下的 data 文件夹中
cifar10_trainset = datasets.CIFAR10(root='./data', train=True, download=True)train
- 类型:布尔值
- 作用:用于指定加载的是训练集还是测试集。设为
True时加载训练集(包含 50000 张图像);设为False时加载测试集(包含 10000 张图像)。
# 加载训练集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True)
# 加载测试集
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True)transform
- 类型:可调用对象(通常是
torchvision.transforms中的变换组合) - 作用:对加载的图像数据进行预处理操作,例如将图像转换为张量、归一化、裁剪、翻转等。可以使用
transforms.Compose来组合多个预处理操作。
import torchvision.transforms as transforms# 定义预处理操作
transform = transforms.Compose([transforms.ToTensor(), # 将图像转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 归一化处理
])# 加载数据集并应用预处理
cifar10_trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)target_transform
- 类型:可调用对象
- 作用:对图像对应的标签进行预处理操作。不过在 CIFAR - 10 数据集里,标签通常是简单的整数,一般较少用到此参数。
# 定义一个简单的标签转换函数
def target_transform(target):return target * 2cifar10_trainset = datasets.CIFAR10(root='./data', train=True, download=True, target_transform=target_transform)download
- 类型:布尔值
- 作用:决定是否从互联网下载 CIFAR - 10 数据集。设为
True且root指定的路径下没有数据集时,会自动下载;设为False则不会下载。
# 若 data 文件夹中没有数据集,会自动下载
cifar10_trainset = datasets.CIFAR10(root='./data', train=True, download=True)(2) 代码演示
import torchvisiontrain_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)运行后可以看到下方终端就开始下载了

下载完成后目录就出现了这个压缩文件,对压缩文件进行解压

使用索引[i]即可查看数据集中的图片信息等

可以在调试中查看数据集都有那些信息。如下所示,classes,data,meta等就是数据集信息,用.的方式(如test_set.classes的方式就可以访问)
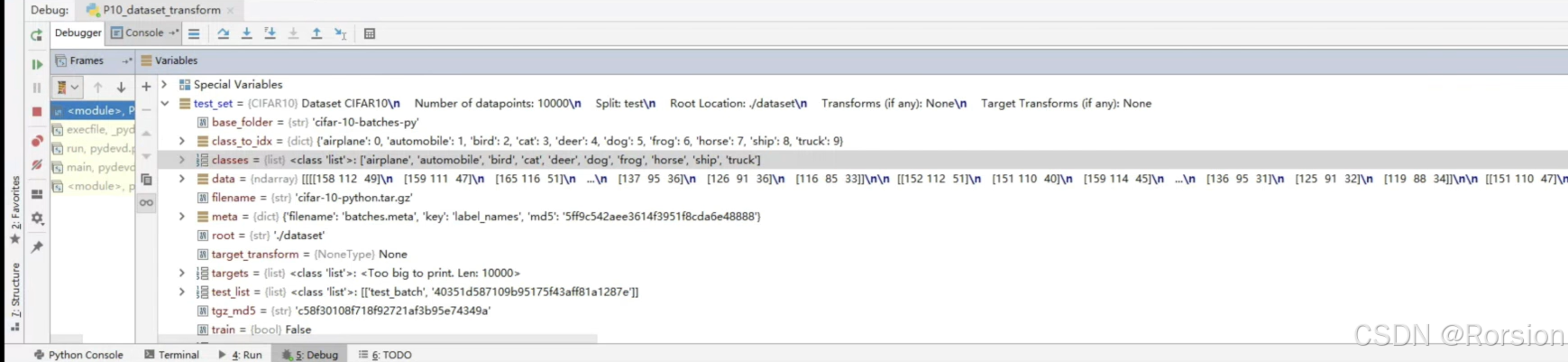
在使用 torchvision.datasets.CIFAR10 加载测试集后,test_set 是一个 torch.utils.data.Dataset 类型的对象,它主要由图像数据和对应的标签组成。所以可以用两个变量来接收test_set中的一张图片,如下所示
import torchvisiontrain_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)img, target = test_set[0]
print(img)
print(target)输出结果如下。这里的3是指第1张图片的标签是CIFAR10标签列表的第4个, 即cat

结合transforms:
import torchvision
from torch.utils.tensorboard import SummaryWriterdataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",transform=dataset_transform,train=False,download=True)writer = SummaryWriter("p10")
for i in range(10): # 连续显示10张图片img, target = test_set[i]writer.add_image("test_set", img, i)writer.close()五,DataLoader
1,介绍
DataLoader 本质上是一个可迭代对象,它封装了数据集(Dataset 对象),能够按照指定的规则从数据集中批量地加载数据,并可以对数据进行打乱顺序、并行加载等操作。
作用:
- 批量加载数据:在深度学习训练过程中,通常无法一次性将所有数据加载到内存中进行处理。
DataLoader可以将数据集分割成多个小批次(batch),每次只加载一个批次的数据到内存中进行计算,这样可以有效减少内存的使用,同时提高训练效率。 - 数据打乱:在每个训练周期(epoch)开始时,可以对数据进行打乱操作,这样可以增加数据的随机性,避免模型学习到数据的特定顺序,有助于提高模型的泛化能力。
- 并行加载:
DataLoader支持使用多线程或多进程并行加载数据,利用多核 CPU 的计算能力,进一步加快数据加载的速度,减少模型训练过程中的数据等待时间。
2,参数介绍
必选参数:
dataset- 类型:
torch.utils.data.Dataset对象 - 作用:指定要加载的数据集。这个数据集可以是 PyTorch 内置的数据集(如
torchvision.datasets.CIFAR10),也可以是用户自定义的数据集,只要该数据集类继承自torch.utils.data.Dataset并实现了__len__和__getitem__方法即可
- 类型:
import torchvision
from torch.utils.data import DataLoader# 加载 CIFAR - 10 训练集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True)
# 创建 DataLoader 并指定数据集
trainloader = DataLoader(dataset=trainset)可选参数:
批次相关参数
batch_size
- 类型:整数
- 作用:指定每个批次中包含的样本数量。在深度学习训练中,由于内存限制,通常不会一次性将整个数据集加载到内存中,而是将数据集分成多个批次进行处理。较大的
batch_size可以提高训练的效率,但可能会增加内存的使用;较小的batch_size可以使模型的更新更加频繁,但训练速度可能会变慢。 - 默认值:1
trainloader = DataLoader(trainset, batch_size=32)drop_last
- 类型:布尔值
- 作用:当数据集的样本数量不能被
batch_size整除时,如果drop_last设为True,则会丢弃最后一个不完整的批次;如果设为False,则会保留最后一个不完整的批次。 - 默认值:
False
# 丢弃最后一个不完整的批次
trainloader = DataLoader(trainset, batch_size=32, drop_last=True)数据顺序相关参数
shuffle
- 类型:布尔值
- 作用:控制是否在每个训练周期(epoch)开始时打乱数据的顺序。打乱数据顺序可以增加数据的随机性,避免模型学习到数据的特定顺序,有助于提高模型的泛化能力。在训练阶段,通常将
shuffle设为True;在测试阶段,一般将其设为False。 - 默认值:
False
# 在每个 epoch 开始时打乱数据顺序
trainloader = DataLoader(trainset, batch_size=32, shuffle=True)并行加载相关参数
num_workers
- 类型:整数
- 作用:指定用于数据加载的子进程数量。设置为 0 表示在主进程中加载数据;设置为大于 0 的值则会使用相应数量的子进程并行加载数据,这样可以利用多核 CPU 的计算能力,加快数据加载的速度。但过多的子进程可能会导致内存占用过高,需要根据实际情况进行调整。
- 默认值:0
# 使用 4 个工作进程并行加载数据
trainloader = DataLoader(trainset, batch_size=32, num_workers=4)pin_memory
- 类型:布尔值
- 作用:如果设为
True,则会将数据加载到固定内存(页锁定内存)中,这样在将数据从 CPU 传输到 GPU 时可以加快传输速度,尤其在使用 GPU 进行训练时比较有用。 - 默认值:
False
trainloader = DataLoader(trainset, batch_size=32, pin_memory=True)其他参数 (了解)
sampler
- 类型:
torch.utils.data.Sampler对象 - 作用:自定义采样策略,用于决定如何从数据集中选取样本组成批次。当使用
sampler时,shuffle参数将被忽略。 - 默认值:
None
from torch.utils.data import SubsetRandomSampler# 定义采样器
indices = list(range(len(trainset)))
sampler = SubsetRandomSampler(indices[:1000])
trainloader = DataLoader(trainset, batch_size=32, sampler=sampler)batch_sampler
- 类型:
torch.utils.data.Sampler对象 - 作用:与
sampler类似,但它返回的是一个批次的样本索引,而不是单个样本的索引。当使用batch_sampler时,batch_size、shuffle、sampler和drop_last参数将被忽略。 - 默认值:
None
3,代码演示
需要注意的是,DataLoader的返回值是数据和标签的元组,例如batch_size=4,那么DataLoader就会对4张图片的图像数据打包成一个元组,然后对其标签也打包成一个元组
import torchvisiontest_data = torchvison.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)for data in test_loader:imags, targets = dataprint(imgs.shape)print(targets)运行后就会生成一系列DataLoader打包的数据。

六,神经网络
此章目的是为了学会如何自己搭建一个神经网络结构模型,自己规定神经层数,卷积方法,自己添加线性层,非线性层等等。实际上为了快速训练一个模型,可以直接用上几节说到的torchvison.models torchaudios等PyTorch官网为我们提供的预训练模型直接进行训练。
1,torch.nn介绍
torch.nn是 PyTorch 中用于构建神经网络的核心模块,它提供了丰富的工具和类,方便用户定义、训练和评估各种类型的神经网络模型。
主要组件
1,层(Layers)
torch.nn 包含了各种常用的神经网络层,这些层是构建神经网络的基本单元。 以下是一些常用的层
nn.Linear:全连接层,也称为线性层,用于实现输入和输出之间的线性变换,公式为 ,其中 是输入, 是权重矩阵, 是偏置向量。常用于神经网络的最后几层进行分类或回归任务。nn.Conv2d:二维卷积层,主要用于处理图像数据。通过卷积操作提取图像的特征,能够自动学习图像中的局部模式,如边缘、纹理等。在计算机视觉任务中广泛应用,如目标检测、图像分类等。nn.MaxPool2d:二维最大池化层,用于对输入的特征图进行下采样,减少数据的维度,同时保留重要的特征信息。可以提高模型的计算效率,增强模型的鲁棒性。nn.ReLU:修正线性单元(Rectified Linear Unit)激活函数层,它将所有小于 0 的输入值置为 0,大于 0 的输入值保持不变。ReLU 函数具有计算简单、收敛速度快等优点,能够有效缓解梯度消失问题,是深度学习中最常用的激活函数之一。
2,损失函数(Loss Functions)
损失函数用于衡量模型预测结果与真实标签之间的差异,是模型训练过程中的重要指标。
nn.CrossEntropyLoss:交叉熵损失函数,常用于多分类问题。它结合了 Softmax 激活函数和负对数似然损失,能够有效地衡量模型输出的概率分布与真实标签之间的差异。nn.MSELoss:均方误差损失函数,用于回归问题。计算模型预测值与真实值之间的平方误差的平均值,衡量预测值与真实值之间的距离。
3,优化器 (Optimizers)
优化器用于更新模型的参数,以最小化损失函数。虽然优化器在 torch.optim 模块中,但与 torch.nn 紧密相关。常见的优化器有:
torch.optim.SGD:随机梯度下降优化器,是最基本的优化算法。通过计算损失函数关于模型参数的梯度,沿着梯度的反方向更新参数,学习率控制参数更新的步长。torch.optim.Adam:自适应矩估计优化器,结合了 AdaGrad 和 RMSProp 的优点,能够自适应地调整每个参数的学习率,在许多任务中表现良好。
4,容器(Containers)
容器用于组织和管理神经网络的层,方便构建复杂的模型结构。常见的容器有:
nn.Sequential:顺序容器,按照传入层的顺序依次执行前向传播。可以将多个层组合成一个序列,简化模型的定义过程。nn.ModuleList:模块列表容器,用于存储多个子模块,可以像列表一样进行索引和操作。适合需要动态添加或管理子模块的场景。
使用流程
一般来说,使用 torch.nn 构建和训练神经网络的基本流程如下:
- 定义模型:继承
nn.Module类,在__init__方法中定义网络的层,在forward方法中定义前向传播的逻辑。 - 定义损失函数和优化器:选择合适的损失函数和优化器,并传入模型的参数。
- 训练模型:在训练循环中,进行前向传播计算损失,然后进行反向传播计算梯度,最后使用优化器更新模型的参数。
- 评估模型:在测试集上评估模型的性能。
2,Containers(容器)
(1)nn.Module
在 torch.nn 里,Module 是所有神经网络模块的基类,像 nn.Sequential、nn.ModuleList、nn.ModuleDict 这些容器,以及各类具体的层(如 nn.Linear、nn.Conv2d 等)都继承自 nn.Module。 继承后对其中的不满意部分进行修改。
如下所示即为一个简单的Module使用案例
import torch
from torch import nnclass MyModel(nn.Module):def __init__(self):
'''
在 Python 中,super() 是一个非常有用的内置函数,主要用于在类的继承体系中调用父类(超类)的方法。
super() 函数返回一个代理对象,这个代理对象可以调用父类或兄弟类的方法。它的常见使用形式是
super().method(),用于调用父类的 method 方法。通过 super(),可以避免直接使用父类的名称来调用方
法,从而使代码更加灵活和易于维护,特别是在多重继承和复杂的继承结构中优势明显。super().__init()则是调用父类的 __init__ 方法,也就是父类的构造函数。在类继承时,子类可以通过这种方式继承父类的初
始化逻辑。在使用 torch.nn.Module 构建神经网络模型时,nn.Module 类的 __init__ 方法包含了许多重要
的初始化操作,例如注册子模块、管理参数等。通过调用 super().__init(),子类可以继承这些初始化操
作,确保模型能够正常工作。
'''super().__init()def forward(self, input):output = input + 1return outputmymodel = MyModel()
input = torch.tensor(1.0)
# 给mymodel input参数实际上是调用nn.Module的__call__方法
# nn.Module 类的 __call__ 方法会执行一系列操作,其中就包括调用子类中定义的 forward 方法
output = mymodel(input)
print(output)以下是简化的 nn.Module 类 __call__ 方法:
class Module:def __call__(self, *input, **kwargs):# 执行一些前置操作,如记录钩子等result = self.forward(*input, **kwargs)# 执行一些后置操作return result最终输出结果为2.0
(2)nn.Sequential
nn.Sequential 是一个顺序容器,它可以按照顺序依次包装多个神经网络层,形成一个连续的神经网络模块。。当我们构建一个简单的、按顺序执行的神经网络时,使用 nn.Sequential 可以大大简化代码。
在构建神经网络时,我们通常需要按照一定的顺序堆叠多个层,如卷积层、激活函数层、池化层等。使用 nn.Sequential 可以将这些层按顺序组合在一起,避免编写大量重复的前向传播代码,使模型的定义更加简洁和直观。nn.Sequential 会自动按照层的顺序进行前向传播,当输入数据传入 nn.Sequential 封装的模块时,数据会依次通过每一层进行处理,最终输出结果,无需手动编写复杂的前向传播逻辑
import torch
import torch.nn as nn# 使用 nn.Sequential 构建一个简单的全连接神经网络
model = nn.Sequential(nn.Linear(10, 20), # 输入维度为 10,输出维度为 20 的全连接层nn.ReLU(), # ReLU 激活函数层nn.Linear(20, 1) # 输入维度为 20,输出维度为 1 的全连接层
)# 生成随机输入数据
input_data = torch.randn(5, 10) # 输入数据的形状为 (5, 10)# 进行前向传播
output = model(input_data)print("输入数据形状:", input_data.shape)
print("输出数据形状:", output.shape)在上述示例中,我们使用 nn.Sequential 依次堆叠了两个全连接层和一个 ReLU 激活函数层。输入数据 input_data 首先通过第一个全连接层 nn.Linear(10, 20),然后经过 ReLU 激活函数处理,最后通过第二个全连接层 nn.Linear(20, 1) 得到输出结果。
在 nn.Sequential 中,我们还可以为每一层指定名称,这样可以更方便地访问和操作特定的层
import torch
import torch.nn as nn
from collections import OrderedDict# 使用 OrderedDict 构建带名称的 nn.Sequential
model = nn.Sequential(OrderedDict([('fc1', nn.Linear(10, 20)),('relu', nn.ReLU()),('fc2', nn.Linear(20, 1))
]))# 访问指定名称的层
fc1_layer = model.fc1
print(fc1_layer)或者通过以下方式为每一层指定名称
import torch
import torch.nn as nnmodel = nn.Sequential()
model.add_module('fc1', nn.Linear(10, 20))
model.add_module('relu', nn.ReLU())
model.add_module('fc2', nn.Linear(20, 1))# 访问指定名称的层
relu_layer = model.relu
print(relu_layer)nn.Sequential 还可以嵌套使用,即一个 nn.Sequential 模块可以作为另一个 nn.Sequential 模块的一部分。
import torch
import torch.nn as nn# 定义一个子模块
sub_module = nn.Sequential(nn.Linear(10, 15),nn.ReLU()
)# 定义主模块,嵌套使用子模块
model = nn.Sequential(sub_module,nn.Linear(15, 1)
)# 生成随机输入数据
input_data = torch.randn(5, 10)# 进行前向传播
output = model(input_data)print("输出数据形状:", output.shape)(3)nn.ModuleList(了解)
nn.ModuleList 是一个模块列表容器,它可以像 Python 列表一样存储多个子模块,并且会自动注册这些子模块,使其成为父模块的一部分。与 nn.Sequential 不同的是,nn.ModuleList 不会自动按顺序执行子模块,需要我们在 forward 方法中手动指定执行顺序,适合需要动态添加或管理子模块的场景。
import torch
import torch.nn as nnclass MyModel(nn.Module):def __init__(self):super().__init__()# 创建一个 nn.ModuleList 并添加两个线性层self.module_list = nn.ModuleList([nn.Linear(784, 128),nn.Linear(128, 10)])def forward(self, x):x = x.view(-1, 784)for module in self.module_list:x = module(x)return xmodel = MyModel()
input_tensor = torch.randn(64, 784)
output = model(input_tensor)
print(output.shape) # 输出: torch.Size([64, 10])(4)nn.ModuleDict(了解)
nn.ModuleDict 是一个模块字典容器,它允许我们使用字符串作为键来存储和访问子模块。与 nn.ModuleList 类似,nn.ModuleDict 也需要我们在 forward 方法中手动指定子模块的执行顺序,适合需要根据不同条件选择不同子模块的场景。
import torch
import torch.nn as nnclass MyModelWithDict(nn.Module):def __init__(self):super().__init__()# 创建一个 nn.ModuleDict 并添加两个线性层self.module_dict = nn.ModuleDict({'fc1': nn.Linear(784, 128),'fc2': nn.Linear(128, 10)})def forward(self, x):x = x.view(-1, 784)x = self.module_dict['fc1'](x)x = torch.relu(x)x = self.module_dict['fc2'](x)return xmodel = MyModelWithDict()
input_tensor = torch.randn(64, 784)
output = model(input_tensor)
print(output.shape) # 输出: torch.Size([64, 10])3,Convolution Layers(卷积层)
卷积层(Convolution Layers)是构建卷积神经网络(Convolutional Neural Networks, CNN)的核心组件,在图像、语音等数据处理任务中有着广泛应用。
卷积层参数基本都是一样的。
除了以下的常规卷积层,还有转量卷积层(反卷积层)nn.ConvTranspose1d,nn.ConvTranspose2d,nn.ConvTranspose3d等。具体可参考官网对于torch.nn的各类解析,这里不做过多介绍
(1)nn.Conv1d(了解)
一维卷积层,常用于处理一维序列数据,像音频信号、时间序列数据等。
在一维输入数据上滑动一个一维卷积核,对每个位置进行卷积操作,将卷积核与输入数据对应位置的元素相乘并求和,得到输出特征图的一个元素。
一维卷积层不是我学习的重点,如果需要用到,可以搜索相关参数进行具体学习。以下为一个代码示例
import torch
import torch.nn as nn# 定义一维卷积层
conv1d = nn.Conv1d(in_channels=3, out_channels=6, kernel_size=3)
# 生成随机输入数据,形状为 (batch_size, in_channels, sequence_length)
input_data = torch.randn(1, 3, 10)
# 进行卷积操作
output = conv1d(input_data)
print(output.shape)(2)nn.Conv2d
二维卷积层,是最常用的卷积层类型,主要用于处理二维图像数据。
在二维输入图像上滑动一个二维卷积核,对每个位置进行卷积操作,将卷积核与输入图像对应位置的元素相乘并求和,得到输出特征图的一个元素。


参数
必选参数:
in_channels- 类型:整数
- 作用:表示输入特征图的通道数。对于图像数据,彩色图像通常有 3 个通道(RGB),灰度图像则只有 1 个通道。在神经网络中,前一层输出的特征图通道数会作为当前卷积层的输入通道数。
- 示例:若输入的是彩色图像,
in_channels就设置为 3。
import torch
import torch.nn as nn# 创建一个输入通道数为 3 的二维卷积层
conv2d = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3)out_channels- 类型:整数
- 作用:表示输出特征图的通道数,也等同于卷积核的数量。每个卷积核会对输入特征图进行卷积操作,生成一个对应的输出通道,不同的卷积核可以提取不同类型的特征。
- 示例:若希望卷积层输出 6 个不同的特征通道,
out_channels就设为 6。
在卷积操作中,每个卷积核会对输入特征图进行卷积运算,从而生成一个对应的输出通道。不同的卷积核可以提取输入特征图中不同类型的特征,因此 out_channels 的值越大,卷积层能够提取的特征种类就越多,模型的特征表达能力也就越强。但同时,较大的 out_channels 会增加模型的参数数量和计算量,可能导致过拟合等问题。
import torch
import torch.nn as nn# 创建一个二维卷积层,设置输入通道数为 3,输出通道数为 6,卷积核大小为 3x3
conv2d = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3)# 生成一个随机输入特征图,形状为 (batch_size, in_channels, height, width)
input_tensor = torch.randn(1, 3, 10, 10)# 进行卷积操作
output = conv2d(input_tensor)# 输出特征图的形状,第二个维度即为输出通道数
print(output.shape) 在上述代码中创建了一个 nn.Conv2d 卷积层,将 out_channels 设置为 6,这意味着卷积层会使用 6 个不同的卷积核对输入特征图进行卷积,最终输出的特征图会有 6 个通道。
kernel_size- 类型:整数或元组
- 作用:指定卷积核的大小。如果是整数,意味着卷积核是正方形,边长为该整数;如果是元组,元组的两个元素分别表示卷积核的高度和宽度。
- 示例:
kernel_size = 3表示使用 3x3 的正方形卷积核;kernel_size = (3, 5)表示使用高度为 3、宽度为 5 的矩形卷积核。
kernel_size只设置卷积核大小。在构建卷积层时,如果不进行额外的初始化设置,卷积核的参数会按照默认的随机初始化方法进行赋值。不同的深度学习框架和层类型可能采用不同的默认随机初始化策略。 卷积核的权重初始化方法有很多,在nn.Conv2d中默认使用Kaiming初始化。除了随机初始化,还可以根据具体需求自定义卷积核的权重
可选参数:
stride- 类型:整数或元组,默认值为 1
- 作用:表示卷积核在输入特征图上滑动的步长。可以是一个整数,表示在高度和宽度方向上的步长相同;也可以是一个元组,元组的两个元素分别表示在高度和宽度方向上的步长。较大的步长会使输出特征图的尺寸变小。
- 示例:
stride = 2表示卷积核在高度和宽度方向上每次滑动 2 个像素;stride = (1, 2)表示在高度方向上步长为 1,在宽度方向上步长为 2。
# 创建一个步长为 2 的二维卷积层
conv2d = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=2)padding- 类型:整数、元组或字符串,默认值为 0
- 作用:用于在输入特征图的边界添加填充。若为整数,会在高度和宽度方向上都添加相同数量的填充;若为元组,两个元素分别表示在高度和宽度方向上的填充数量;若为字符串,如
'same',会自动计算填充量,使输出特征图的尺寸与输入特征图相同(在stride = 1时)。填充可以防止在卷积过程中特征图尺寸过度减小,保留更多边界信息。 - 在选择padding!=0时,还可以设置参数padding_mode来确定填充的默认数据是多少,一般为0,写作padding_mode='zeros'
- 示例:
padding = 1表示在输入特征图的四周各添加 1 个像素的填充;padding = (1, 2)表示在高度方向上添加 1 个像素的填充,在宽度方向上添加 2 个像素的填充。
# 创建一个填充为 1 的二维卷积层
conv2d = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, padding=1)如下所示为padding=1时,在图像数据左右上下分别填充一行后的图像数据,一般填充的地方数值为0

dilation- 类型:整数或元组,默认值为 1
- 作用:控制卷积核元素之间的间距,即膨胀率。可以是一个整数,表示在高度和宽度方向上的膨胀率相同;也可以是一个元组,两个元素分别表示在高度和宽度方向上的膨胀率。较大的膨胀率能增大卷积核的感受野,让卷积核可以关注到更广泛的输入区域。
- 在普通卷积中,卷积核的元素是紧密相连的,
dilation = 1就是这种情况。当dilation值大于 1 时,卷积核元素之间会插入指定数量的空洞,从而改变卷积核在输入特征图上的作用方式。 - 示例:
dilation = 2表示卷积核元素之间的间距为 2;dilation = (1, 2)表示在高度方向上膨胀率为 1,在宽度方向上膨胀率为 2。
为了更好地理解 dilation 的作用,先看一个简单的一维示例。假设输入序列为 [1, 2, 3, 4, 5],卷积核为 [1, 2, 3]。
dilation = 1(普通卷积):卷积核元素紧密相连,在输入序列上依次滑动计算卷积结果。dilation = 2:卷积核元素之间插入一个空洞,实际作用的卷积核可以看作[1, 0, 2, 0, 3](这里的 0 表示空洞),这样卷积核每次计算时会跳过一个输入元素,从而扩大了感受野。
二维数据同理,每次计算时会跳过一个输入元素
# 创建一个膨胀率为 2 的二维卷积层
conv2d = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, dilation=2)groups- 类型:整数,默认值为 1
- 作用:用于指定输入通道和输出通道之间的分组连接方式。
in_channels和out_channels必须都能被groups整除。当groups = 1时,所有输入通道都与所有输出通道进行卷积;当groups > 1时,输入通道和输出通道会被分成groups个组,每个组内独立进行卷积操作。它可以减少模型的参数量和计算量,同时也能对模型的特征提取能力产生影响 - 示例:
groups = 3表示将输入通道和输出通道都分成 3 组,每组分别进行卷积。
# 创建一个分组数为 3 的二维卷积层
conv2d = nn.Conv2d(in_channels=6, out_channels=6, kernel_size=3, groups=3)以下对groups使用具体分析,groups用到的很少,以下部分可以不看
groups = 1(普通卷积):所有输入通道与所有输出通道进行卷积。
import torch
import torch.nn as nn# 创建一个普通的二维卷积层,groups 默认为 1
conv2d = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3)# 生成随机输入特征图
input_tensor = torch.randn(1, 3, 10, 10)# 进行卷积操作
output = conv2d(input_tensor)
print(output.shape)在这个例子中,输入的 3 个通道会与 6 个输出通道的卷积核进行全连接的卷积操作,即每个输出通道的卷积核会对所有 3 个输入通道进行卷积。
groups = in_channels = out_channels(深度可分离卷积):
当 groups 的值等于输入通道数和输出通道数时,就实现了深度可分离卷积。在深度可分离卷积中,每个输入通道对应一个输出通道,每个卷积核只对一个输入通道进行卷积。
# 创建一个深度可分离卷积层
conv2d = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, groups=3)# 生成随机输入特征图
input_tensor = torch.randn(1, 3, 10, 10)# 进行卷积操作
output = conv2d(input_tensor)
print(output.shape)在深度可分离卷积中,由于每个卷积核只处理一个输入通道,所以参数量和计算量都大幅减少。但这种方式可能会限制模型的特征融合能力,因为不同输入通道之间没有直接的信息交流。
1 < groups < in_channels 且 1 < groups < out_channels :
当 groups 取一个介于 1 和输入 / 输出通道数之间的值时,输入通道和输出通道会被分成多个组,组内进行独立的卷积操作。
# 创建一个分组卷积层,groups 为 3
conv2d = nn.Conv2d(in_channels=6, out_channels=6, kernel_size=3, groups=3)# 生成随机输入特征图
input_tensor = torch.randn(1, 6, 10, 10)# 进行卷积操作
output = conv2d(input_tensor)
print(output.shape)在这个例子中,输入的 6 个通道和输出的 6 个通道都会被分成 3 组,每组包含 2 个输入通道和 2 个输出通道。每个组内的 2 个输入通道会与对应的 2 个输出通道的卷积核进行卷积操作,不同组之间相互独立。
bias
- 类型:布尔值,默认值为
True - 作用:决定是否在卷积操作的输出上添加可学习的偏置项(一个常数)。若为
True,会在每个输出通道上添加一个偏置值;若为False,则不添加偏置项。
# 创建一个不添加偏置项的二维卷积层
conv2d = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, bias=False)下图是通过设置参数来调整输出图像的高和宽的公式

(3)nn.Conv3d(了解)
三维卷积层,用于处理三维数据,如视频数据(包含时间维度)、医学影像数据(如 CT 扫描数据)等。
在三维输入数据上滑动一个三维卷积核,对每个位置进行卷积操作,将卷积核与输入数据对应位置的元素相乘并求和,得到输出特征图的一个元素。
import torch
import torch.nn as nn# 定义三维卷积层
conv3d = nn.Conv3d(in_channels=3, out_channels=6, kernel_size=3)
# 生成随机输入数据,形状为 (batch_size, in_channels, depth, height, width)
input_data = torch.randn(1, 3, 10, 32, 32)
# 进行卷积操作
output = conv3d(input_data)
print(output.shape)(4)代码案例
使用nnc.Conv2d时,输入数据必须是torch.Tensor类型:(batch_size, in_channels, height, width)
batch_size:表示一次输入的样本数量。在训练或推理过程中,通常会将多个样本组成一个批次进行处理,以提高计算效率。in_channels:表示输入特征图的通道数。对于彩色图像,通常有 3 个通道(RGB);对于灰度图像,只有 1 个通道。在神经网络中,前一层输出的特征图通道数会作为当前卷积层的输入通道数。height和width:分别表示输入特征图的高度和宽度,单位为像素。
输出数据也是 torch.Tensor类型:(batch_size, out_channels, output_height, output_width)
import torch
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)class MyModel(nn.Module):def __init__(self):super().__init__()# 创建卷积层self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)def forward(self, x):# 卷积x = self.conv1(x)return xmymodel = MyModel()for data in dataloader:imgs, targets = dataoutput = mymodel(imgs)4,Pooling Layers(池化层)
在 PyTorch 中,池化层(Pooling Layers)是卷积神经网络(CNN)中的重要组件,主要用于对输入的特征图进行下采样,以减少数据的维度,降低计算量,同时增强模型的鲁棒性和特征的平移不变性。
以下为常见池化层类型
(1)最大池化层(Max Pooling)
最大池化层在输入特征图的每个局部区域(池化窗口)内选取最大值作为该区域的输出值。通过这种方式,它能够保留局部区域内最显著的特征,减少数据量,同时对特征的位置变化具有一定的鲁棒性。
最大池化层包含的类有nn.MaxPool1d,nn.MaxPool2d,nn.MaxPool3d分别适用于一维、二维和三维数据。还有与之对应的nn.MaxUnpool1d,nn.MaxUnpool2d,nn.MaxUnpool3d。以下是对他们的区别介绍:
nn.MaxPoolxd是最大池化层,用于对输入的特征图进行下采样。其工作原理是在输入特征图上滑动一个固定大小的池化窗口,在每个窗口内选取最大值作为该窗口的输出值,然后将这些最大值组合成新的特征图。这样做可以减少特征图的尺寸,降低计算量,同时保留输入特征图中的重要信息。nn.MaxUnpoolxd是最大反池化层,它是nn.MaxPoolxd的逆操作,但并不是完全的逆运算。最大反池化的主要作用是将经过最大池化后的特征图恢复到原来的尺寸。在反池化过程中,它会利用最大池化时记录的最大值的位置信息,将最大值放回原来的位置,而其他位置填充为 0。
nn.MaxPool2d
这里仅对nn.MaxPool2d这个函数做详细解释

其参数和卷积层类似 ,具体如下
必选参数:
kernel_size- 类型:整数或元组
- 作用:定义池化窗口的大小。若为整数,代表正方形池化窗口的边长;若为元组,元组的两个元素分别表示池化窗口的高度和宽度。
- 示例:
kernel_size = 2表示使用 2x2 的正方形池化窗口;kernel_size = (2, 3)表示使用高度为 2、宽度为 3 的矩形池化窗口。
可选参数:
stride- 类型:整数或元组,默认值为
kernel_size - 作用:指定池化窗口在输入特征图上滑动的步长。若为整数,代表在高度和宽度方向上的步长相同;若为元组,两个元素分别表示在高度和宽度方向上的步长。
- 示例:
stride = 2表示池化窗口在高度和宽度方向上每次滑动 2 个像素;stride = (1, 2)表示在高度方向上步长为 1,在宽度方向上步长为 2。
- 类型:整数或元组,默认值为
padding- 类型:整数或元组,默认值为 0
- 作用:用于在输入特征图的边界添加填充。若为整数,会在高度和宽度方向上都添加相同数量的填充;若为元组,两个元素分别表示在高度和宽度方向上的填充数量。填充可以防止在池化过程中特征图尺寸过度减小,保留更多边界信息。
- 示例:
padding = 1表示在输入特征图的四周各添加 1 个像素的填充;padding = (1, 2)表示在高度方向上添加 1 个像素的填充,在宽度方向上添加 2 个像素的填充。
dilation- 类型:整数或元组,默认值为 1
- 作用:控制池化窗口内元素之间的间距。若为整数,代表在高度和宽度方向上的间距相同;若为元组,两个元素分别表示在高度和宽度方向上的间距。较大的
dilation值可以扩大池化窗口的感受野。 - 示例:
dilation = 2表示池化窗口内元素之间的间距为 2。
return_indices- 类型:布尔值,默认值为
False - 作用:若设置为
True,在进行最大池化操作时会返回最大值所在的索引,这些索引可用于后续的最大反池化操作(如nn.MaxUnpool2d)。 - 示例:当需要对特征图进行反池化恢复尺寸时,可将该参数设为
True。
- 类型:布尔值,默认值为
ceil_mode- 类型:布尔值,默认值为
False - 作用:控制输出特征图尺寸的计算方式。若为
True,使用向上取整的方式计算输出尺寸;若为False,使用向下取整的方式计算。分别对应Ceiling和Floor模式 - 示例:当输入特征图尺寸不能被池化窗口和步长整除时,不同的
ceil_mode设置会得到不同的输出尺寸。例如对于5*5的输入图像,池化核是3*3的,5不能被3整除,当横向第二次池化时池化核的第三列数据就会缺失(参照下图),如果是Ceiling模式,则会保留此处池数据,如果为Floor模式就不会保留。如果是Floor模式,下图所示的5*5的数据最终只会有2一个数据保留下来
- 类型:布尔值,默认值为


代码案例
使用时nn.MaxPool2d时的输入数据必须是torch.Tensor类型:(batch_size, channels, height, width)
输出数据也是torch.Tensor类型:(batch_size, channels, output_height, output_width)
输入输出数据类型上和卷积一样
import torch
from torch import nn
from torch.nn import MaxPool2d#在 PyTorch 里,神经网络的计算大多基于浮点数进行,特别是 32 位浮点数(torch.float32)像卷积层、
#池化层等操作,在进行计算时需要对输入数据进行乘法、加法等运算,而整数类型无法很好地处理这些连续的
#数值计算。所以,将输入数据转换为浮点数类型是神经网络计算的基本要求。
input = torch.tensor([[1,2,4,0,5],[0,1,2,3,4],[3,3,2,1,3],[5,2,3,1,3],[0,0,2,0,1]], dtype=torch.float32)input = torch.reshape(input, (-1, 1, 5,5)) # -1表示自动推断该维度的大小class MyModel(nn.Module):def __init__(self):super().__init__()self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)def forward(self, input):output = self.maxpool1(input)return outputmymodel = MyModel()
output = mymodel(input)(2)平均池化层(Average Pooling)
平均池化层在输入特征图的每个局部区域(池化窗口)内计算所有元素的平均值作为该区域的输出值。它可以平滑特征图,减少噪声的影响。
平均池化层类有nn.AvgPool1d,nn.AvgPool2d,nn.AvgPool3d。这里不做详细介绍
(3)自适应池化层(Adaptive Pooling)
自适应池化层允许用户指定输出特征图的大小,而不需要手动指定池化窗口的大小和步长。它会根据输入特征图的大小自动调整池化操作,以得到指定大小的输出 。
自适应池化层类有nn.AdaptiveMaxPool1d(用于一维序列数据的自适应最大池化,它会在每个通道上对输入序列进行最大池化操作,以得到指定长度的输出序列。),nn.AdaptiveAvgPool1d(用于一维序列数据的自适应平均池化,通过计算每个通道上输入序列的局部平均值,得到指定长度的输出序列),nn.AdaptiveMaxPool2d,nn.AdaptiveAvgPool2d,nn.AdaptiveMaxPool3d,nn.AdaptiveAvgPool3d.这里不做详细介绍
5,Padding Layers(填充层)
Padding 层(填充层)的主要作用是在输入数据的边界添加额外的元素,以此来改变输入数据的尺寸。在卷积神经网络(CNN)中,卷积和池化操作通常会使特征图的尺寸减小。通过在输入数据周围添加填充,可以控制输出特征图的尺寸,使其与输入尺寸相同或达到期望的大小。例如,在一些需要保持特征图尺寸不变的网络结构中,使用填充可以确保每一层的输出尺寸稳定。 适当的填充可以增加数据的多样性,使得模型在处理不同位置的特征时更加鲁棒,从而提高模型的泛化能力。
填充层不常用,这里仅做简要介绍,了解即可
以下为常用的二维数据类,除此之外还有1d 3d三维类,不做介绍
(1)nn.ZeroPad2d
这是一个二维零填充层,用于在二维输入数据的边界添加零元素。
(2)nn.ReflectionPad2d
二维反射填充层,它会在输入数据的边界反射其相邻的元素来进行填充,这种填充方式可以更好地保留数据的局部特征
(3)nn.ReplicationPad2d
二维复制填充层,它会复制输入数据边界的元素来进行填充。
6,Non-linear Activations(非线性激活)
(1)介绍
非线性激活在官网上有Non-linear Activations(weighted sum, nonlinearity)和Non-linear Activations(Other)两种
非线性激活函数是神经网络的重要组成部分,它们为网络引入了非线性特性,使得神经网络能够学习和表示复杂的函数关系。
如果神经网络仅由线性层(如全连接层、卷积层)构成,那么无论网络有多少层,其整体仍然是一个线性模型。线性模型只能学习到输入和输出之间的线性关系,对于现实世界中大量存在的复杂非线性关系(如语音、图像、自然语言等数据中的模式),线性模型的表达能力远远不够 。通过在神经网络中引入非线性激活函数,能够打破线性约束,使网络可以学习和表示任意复杂的函数。这样,神经网络就能对各种复杂的模式和关系进行建模,从而大大增强了模型的表达能力。例如,在图像识别任务中,非线性激活函数可以帮助网络学习到图像中物体的边缘、纹理、形状等复杂特征。
非线性激活函数可以对输入的特征进行筛选和提取。不同的激活函数具有不同的特性,能够突出输入特征中的某些部分,抑制其他部分。以 ReLU 激活函数为例,它会将输入中的负值置为 0,只保留正值部分,这可以看作是一种特征筛选的过程,能够提取出对模型有用的特征信息。激活函数将输入特征映射到一个新的空间,在这个新空间中,数据的分布和特征可能更有利于后续的处理和分类。例如,Sigmoid 函数将输入映射到 (0,1)区间,Tanh 函数将输入映射到 (-1,1)区间,这种映射可以使数据的范围更加合适,便于模型进行学习和优化。
以下介绍几个常用的非线性函数,非线性激活函数有很多,其他非线性激活函数可以参考PyTorch官网
(2)Sigmoid
- 数学公式:

- 特性:将输入值映射到 (0,1)区间,常用于二分类问题的输出层,可表示概率。但它存在梯度消失问题,当输入值很大或很小时,导数趋近于 0。
import torch
import torch.nn as nn# 创建 Sigmoid 激活函数实例
sigmoid = nn.Sigmoid()# 生成随机输入张量
input_tensor = torch.randn(10)# 应用 Sigmoid 激活函数,输入参数为 input_tensor
output = sigmoid(input_tensor)
print(output)(3)ReLU
- 数学公式:ReLU(x) = max(0, x)
- 特性:计算简单,在正区间导数恒为 1,有效缓解了梯度消失问题,被广泛应用于隐藏层。但它存在神经元 “死亡” 问题,当输入为负时,导数为 0,神经元可能不再更新。
import torch
import torch.nn as nn# 创建 ReLU 激活函数实例
relu = nn.ReLU()# 生成随机输入张量
input_tensor = torch.randn(10)# 应用 ReLU 激活函数,输入参数为 input_tensor
output = relu(input_tensor)
print(output)在创建实例的时候也可以指定ReLU的inplace参数:假设输入input为-1,指定inplace=True,则input=0;如果指定inplace=False,则input仍等于-1,而input_tensor用于接收的变量为0。inplace默认为False,这样可以保留原始数据。
(4)Leaky ReLU
- 数学公式:

- 特性:在负区间引入一个小的斜率 ,避免了神经元 “死亡” 问题。
使用 nn.LeakyReLU 类,创建实例时需要传入 negative_slope 参数(表示负斜率 ),调用实例时输入参数为待激活的张量。
import torch
import torch.nn as nn# 创建 LeakyReLU 激活函数实例,指定 negative_slope 参数
leaky_relu = nn.LeakyReLU(negative_slope=0.01)# 生成随机输入张量
input_tensor = torch.randn(10)# 应用 LeakyReLU 激活函数,输入参数为 input_tensor
output = leaky_relu(input_tensor)
print(output)(5)Tanh
- 数学公式:

- 特性:将输入值映射到 (-1,1)区间,相较于 Sigmoid 函数,它的输出以 0 为中心,在一定程度上缓解了梯度消失问题,但仍然存在该问题。
import torch
import torch.nn as nn# 创建 Tanh 激活函数实例
tanh = nn.Tanh()# 生成随机输入张量
input_tensor = torch.randn(10)# 应用 Tanh 激活函数,输入参数为 input_tensor
output = tanh(input_tensor)
print(output)(6)代码案例
import torch
from torch import nn
from torch.nn import ReLUinput = torch.tensor([[1,-0.5],[-1, 3]])input = torch.reshape(input, (-1, 1, 2, 2))class MyModel(nn.Module):def __init__(self):super().__init__()self.relu1 = ReLU()def forward(self, input):output = self.relu1(input)return outputmymodel = MyModel()
output = mymodel(input)7,Normalization Layers(归一化层)
归一化层(Normalization Layers)是深度学习模型中非常重要的组件,它们有助于加速模型的训练过程、提高模型的稳定性和泛化能力。
用的不多,仅作了解
在神经网络训练过程中,随着网络层数的增加,各层输入的分布会不断发生变化,这种现象被称为内部协变量偏移(Internal Covariate Shift)。归一化层可以使每层输入数据的分布保持相对稳定,使得梯度在反向传播过程中能够更加稳定地流动,避免梯度消失或梯度爆炸问题。这样一来,模型可以使用更大的学习率进行训练,从而加快收敛速度。在训练深度卷积神经网络(CNN)时,如果不使用归一化层,网络可能需要经过大量的迭代才能收敛;而添加了批量归一化层(Batch Normalization)后,模型可以更快地达到较好的性能。归一化层具有一定的正则化效果。它通过对输入数据进行归一化处理,减少了模型对特定输入值的依赖,使得模型更加鲁棒,能够更好地适应不同的输入数据。例如,在图像分类任务中,即使图像的亮度、对比度等发生一定变化,经过归一化处理后,模型依然能够保持较好的分类性能。神经网络的训练对参数的初始化非常敏感。合适的初始化方法可以帮助模型更快地收敛,但不同的初始化可能会导致模型性能的巨大差异。归一化层可以缓解这种敏感性,因为它会对输入数据进行标准化,使得输入数据的分布更加一致,从而减少了初始化对模型训练的影响。
8,Recurrent Layers(循环层)
PyTorch 的循环层(Recurrent Layers)主要用于处理具有序列结构的数据
传统的前馈神经网络(如多层感知机)在处理输入时,每个输入样本都是独立的,不考虑样本之间的顺序和上下文信息。然而,像文本、语音、时间序列等数据都具有明显的序列特征,元素之间的顺序和依赖关系对于理解数据至关重要。循环层通过引入循环结构,能够保存和利用之前的信息。在每个时间步,循环层接收当前的输入和上一个时间步的隐藏状态,经过计算得到当前时间步的隐藏状态,并将其作为下一个时间步的输入。这种机制使得循环层可以对序列中的每个元素进行处理时考虑到其上下文信息,从而更好地捕捉序列数据中的模式和规律。
以下是几个应用场景:
- 文本分类:例如垃圾邮件分类、新闻分类等。可以将文本看作一个单词或字符的序列,使用循环层对文本进行编码,提取文本的语义信息,然后将编码后的结果输入到分类器中进行分类。
- 机器翻译:将源语言的句子翻译成目标语言的句子。循环层可以用于对源语言句子进行编码,然后解码生成目标语言句子。常见的模型如基于 LSTM 或 GRU 的编码器 - 解码器架构。
- 情感分析:判断文本所表达的情感倾向(如积极、消极、中性)。通过循环层对文本进行处理,提取情感相关的特征,从而实现情感分类。
- 股票价格预测:股票价格随时间变化形成一个时间序列,循环层可以学习到价格的历史走势和变化规律,从而对未来的股票价格进行预测。
- 天气预测:气象数据(如温度、湿度、气压等)是按时间顺序记录的时间序列数据。使用循环层可以分析气象数据的变化趋势,预测未来的天气情况。
- 语音识别:语音信号是一种典型的序列数据,循环层可以对语音信号进行特征提取和建模,将语音转换为文本。例如,使用 LSTM 或 GRU 处理语音特征序列,结合声学模型和解码算法实现语音识别任务。
- 视频分析:在视频中,每一帧图像可以看作序列中的一个元素。循环层可以用于分析视频帧之间的动态变化,例如视频分类(判断视频的类别,如动作、喜剧等)、行为识别(识别视频中人物的行为,如跑步、跳舞等)。
具体要用的话可以参考官网定义的各种类
9,Transformer Layers(Transformer 层)
PyTorch 的 Transformer Layers 提供了构建 Transformer 架构所需的核心组件
Transformer 架构专门用于处理序列数据,广泛应用于自然语言处理(NLP)、时间序列分析等领域
- 自然语言处理:语言本质上是序列结构,单词按顺序组成句子和段落。Transformer Layers 能够捕捉文本中单词之间复杂的依赖关系,无论是短距离还是长距离的依赖。例如在翻译任务里,能精准理解源语言句子中各单词的语义和语法关系,进而生成高质量的目标语言翻译。在文本生成任务(如自动写作、对话系统)中,它可以根据前文生成符合逻辑和语境的后续文本。
- 时间序列分析:时间序列数据(如股票价格、气象数据)随时间变化呈现一定规律。Transformer Layers 可学习时间步之间的长期依赖,对未来数据进行准确预测。比如预测股票价格走势、气象变化等
Transformer Layers 的核心是自注意力机制(Self - Attention)
- 捕捉长距离依赖:传统的循环神经网络(RNN)在处理长序列时,难以捕捉远距离元素之间的关系,存在梯度消失或爆炸问题。而自注意力机制允许模型在处理序列中任意位置的元素时,直接关注序列中其他位置的元素,从而有效捕捉长距离依赖。例如在分析一篇长文章时,能关联到前文很远位置的相关信息。
- 并行计算:RNN 是按顺序逐个处理序列元素,难以并行化,计算效率较低。Transformer Layers 中的自注意力机制可以并行计算序列中所有元素的表示,大大提高了训练和推理的速度。这使得模型能够在大规模数据集上更高效地训练
Transformer Layers和Recurrent Layers的区别:
- 在结构设计上,循环层具有循环结构,在处理序列数据时,会按顺序逐个处理序列中的元素。在每个时间步,循环层接收当前输入和上一个时间步的隐藏状态,通过特定的计算更新当前隐藏状态;而Transformer 层完全基于注意力机制,摒弃了循环结构。它采用多头自注意力(Multi - Head Self - Attention)机制并行处理序列中的所有元素,同时结合前馈神经网络(Feed - Forward Network)进行特征变换。这种结构使得模型能够同时考虑序列中的所有位置,而不需要按顺序逐个处理。
- 在计算效率上,循环层在处理长序列时计算效率较低,尤其是在训练大规模模型时,训练时间会显著增加;Transformer 层的多头自注意力机制可以并行计算序列中所有元素的表示,大大提高了计算效率。在现代 GPU 等硬件设备上,并行计算能够充分发挥硬件的性能优势,减少训练时间,使得模型可以在更短的时间内处理大规模的序列数据。
- 在长序列处理能力上,循环层存在梯度消失或梯度爆炸的问题。随着序列长度的增加,早期时间步的信息在传递过程中会逐渐丢失或变得不稳定,导致模型难以捕捉长距离的依赖关系。虽然 LSTM 和 GRU 等改进的循环结构在一定程度上缓解了这个问题,但仍然存在局限性。Transformer 层通过自注意力机制可以直接关注序列中任意位置的元素,有效地捕捉长距离依赖关系。无论序列长度如何,模型都能在处理每个元素时考虑到序列中的所有其他元素,从而更好地处理长序列数据。
- 在应用场景上,由于其具有一定的时序建模能力,循环层在一些对序列顺序敏感的任务中仍然有应用,例如语音识别中的语音信号处理,它可以较好地处理语音信号的时序特征;在一些小规模的序列数据处理任务中,循环层也能取得不错的效果,并且其结构相对简单,易于理解和实现。Transformer 层在自然语言处理领域取得了巨大的成功,广泛应用于机器翻译、文本生成、问答系统等任务。在计算机视觉领域,Transformer 也逐渐成为主流架构,用于图像分类、目标检测、图像生成等任务。此外,在时间序列分析、音频处理等领域,Transformer 层也展现出了强大的性能优势,尤其适用于处理大规模、长序列的数据。
具体要用的话可以参考官网定义的各种类
10,Linear Layers
(1)介绍
线性层(Linear Layers)是最基础且常用的神经网络层之一,也被称为全连接层(Fully Connected Layers)
作用:线性层的核心作用是对输入数据进行线性变换,将输入特征映射到一个新的特征空间。在这个过程中,通过学习权重矩阵W和偏置向量b,线性层可以提取输入数据中的重要信息,并将其转换为更适合后续处理的形式。例如,在图像识别任务中,输入的原始像素值可能包含大量冗余信息,线性层可以将这些像素特征转换为更具代表性的特征,有助于提高模型的性能。在神经网络中,每个神经元可以接收多个输入信号,并通过线性组合的方式将这些信号整合为一个输出。线性层通过对输入特征进行加权求和,实现了信息的整合。这种信息整合机制使得神经网络能够学习到输入特征之间的复杂关系,从而对数据进行更准确的建模。线性层是构建更复杂神经网络的基础组件之一。在深度神经网络中,通常会将多个线性层与激活函数(如 ReLU、Sigmoid 等)交替堆叠,以增加模型的非线性表达能力。
(2)定义和原理
线性层执行一个线性变换,对于输入的张量x ,线性层将其与一个权重矩阵W相乘,然后加上一个偏置向量b,可以用以下公式表示:
![]()
其中, x是输入张量, W是可学习的权重矩阵, b是可学习的偏置向量, y是输出张量。
(3)nn.Linear
torch.nn.Linear 是最基础、最常用的线性层类,也被称为全连接层。它对输入进行线性变换,将输入特征映射到输出特征。
torch.nn.Linear(in_features, out_features, bias=True)参数说明:
in_features:输入特征的数量,也就是输入张量最后一个维度的大小。例如,若输入是一个形状为(batch_size, 10)的张量,那么in_features就应设为 10。out_features:输出特征的数量,即输出张量最后一个维度的大小。例如,若希望输出是一个形状为(batch_size, 5)的张量,那么out_features就设为 5。bias:一个布尔值,指示是否使用偏置向量。默认为True,即使用偏置;若设为False,则不使用偏置。
in_features就是下图所示的x1~xd的数量,out_features就是每一层神经网络的输出值个数,比如x1~xd的下一层输出的g1~gL的个数

关于线性层的权重weight和偏置项bias如何取可以参照下图

import torchvision
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor, download=True)
dataloader = DataLoader(dataset, batch_size=64)class MyModel(nn.Moudle):def __init__(self):super().__init__()# imgs数据类型为Tensor([64, 3, 32, 32]),64*3*32*32=196608也就是共196608个数据self.linear1 = Linear(196608, 10) # 将196608个数据输出为10个数据def forward(self, input):output = self.linear1(input)return outputmymodel = MyModel()for data in dataloader:imgs, targets = datainput = torch.reshape(imgs, (1,1,1,-1))# 也可以用函数torch.flatten(imgs),这个函数可以将任意维数的数据变为一维,展成一行一维数据output = mymodel(output)
# 最终将[1,1,1,196608]转换成了[1,1,1,10](4)nn.Bilinear(了解)
torch.nn.Bilinear 是一个双线性层,它对两个输入进行双线性变换。双线性变换在一些需要同时处理两个输入并考虑它们之间交互作用的场景中很有用,比如在图神经网络、推荐系统等领域。
torch.nn.Bilinear(in1_features, in2_features, out_features, bias=True)参数说明
in1_features:第一个输入的特征数量,即第一个输入张量最后一个维度的大小。in2_features:第二个输入的特征数量,即第二个输入张量最后一个维度的大小。out_features:输出特征的数量,即输出张量最后一个维度的大小。bias:一个布尔值,指示是否使用偏置向量。默认为True。
(5)nn.Identity(了解)
torch.nn.Identity 是一个特殊的线性层,它不进行任何变换,直接将输入输出,通常用于占位或者在需要简单跳过某些操作时使用。
torch.nn.Identity(*args, **kwargs) 该类不接受特定的参数,*args 和 **kwargs 是为了与其他层的接口保持一致而保留的,但实际上不会被使用。
(6)nn.LazyLinear(了解)
nn.LazyLinear 是 PyTorch 中一个比较实用的线性层类,它属于 “惰性模块”(Lazy Modules)的一种。与传统的 nn.Linear 不同,nn.LazyLinear 不需要在创建时显式指定输入特征的数量,而是在第一次前向传播时根据输入自动推断输入特征的数量。在构建神经网络时,有时候我们可能不清楚输入数据的具体特征维度,或者在设计网络结构时希望更加灵活。nn.LazyLinear 就解决了这个问题,它会在第一次前向传播时根据输入张量的最后一个维度自动确定 in_features 的值,然后按照线性层的规则进行后续的计算。
torch.nn.LazyLinear(out_features, bias=True, device=None, dtype=None)out_features:输出特征的数量,即输出张量最后一个维度的大小,这是必须指定的参数。bias:一个布尔值,指示是否使用偏置向量,默认为True。device:指定该层的参数存储的设备,例如'cpu'或'cuda',默认为None,即使用默认设备。dtype:指定该层参数的数据类型,默认为None,即使用默认数据类型。
11,Dropout Layers(丢弃层)
在 PyTorch 中,Dropout Layers(丢弃层)是一种常用的正则化技术,用于防止神经网络过拟合。
Dropout 是由 Hinton 等人在 2012 年提出的一种正则化方法。在训练过程中,Dropout 层会以一定的概率随机 “丢弃”(将神经元的输出置为 0)一部分神经元,这样可以使得模型在训练时不会过度依赖某些特定的神经元,从而增强模型的泛化能力。
具体来说,假设一个 Dropout 层的丢弃概率为p ,那么在每次前向传播时,每个神经元都有p的概率被丢弃,即其输出被置为 0,而有1-p的概率保持不变。在测试阶段,Dropout 层通常不进行丢弃操作,而是会将所有神经元的输出乘以1-p进行缩放,以保证训练和测试阶段的输出期望一致。
通过随机丢弃神经元,使得模型不能依赖于某些特定的特征组合,迫使模型学习更鲁棒的特征表示,从而减少过拟合的风险。让模型在不同的神经元子集上进行学习,相当于训练了多个不同的子模型,最终的模型是这些子模型的组合,从而提高了模型在未知数据上的泛化能力。
具体要用的话可以参考官网定义的各种类
12,Sparse Layers(稀疏层)
在 PyTorch 中,Sparse Layers(稀疏层)用于处理稀疏数据,稀疏数据是指大部分元素为零的数据。
稀疏数据在很多实际场景中广泛存在。例如,在自然语言处理里的词袋模型,一个文档的词向量表示中大部分维度对应词汇在该文档中未出现,值为 0;在推荐系统中,用户 - 物品交互矩阵里大部分用户和物品之间没有交互,矩阵元素为 0;在生物信息学中,基因表达数据也常常是稀疏的。
作用:
- 节省内存:稀疏数据中大量的零元素占用了不必要的内存空间。PyTorch 的稀疏层采用特殊的数据结构(如 COO、CSR 等)来存储稀疏矩阵,只存储非零元素及其对应的索引,从而显著减少内存使用。
- 提高计算效率:在进行矩阵运算时,稀疏层可以避免对大量零元素进行无意义的计算。例如,在矩阵乘法中,当一个矩阵是稀疏的,只需要计算非零元素的乘积和累加,从而减少计算量,提高计算速度。
- 处理大规模数据:由于稀疏层节省了内存和提高了计算效率,使得模型能够处理更大规模的稀疏数据。在实际应用中,很多数据集规模非常大,如果使用普通的稠密表示和计算方式,可能会导致内存溢出或计算时间过长。
具体要用的话可以参考官网定义的各种类
13,Vision Layers(视觉层)
PyTorch 的 Vision Layers(视觉层)主要用于构建和训练计算机视觉相关的神经网络模型。计算机视觉涉及到对图像和视频数据的理解、分析和处理,而 PyTorch 的视觉层提供了丰富的工具和组件,帮助开发者高效地实现各种视觉任务。
用途概述:
1. 特征提取
视觉层可以从图像或视频中提取有意义的特征。在卷积神经网络(CNN)中,卷积层是核心的视觉层之一,它通过卷积核在图像上滑动进行卷积操作,提取图像的局部特征,如边缘、纹理等。不同层次的卷积层可以提取不同抽象程度的特征,从底层的简单特征逐渐过渡到高层的复杂语义特征。这些特征是后续进行图像分类、目标检测等任务的基础。
2. 数据变换
Vision Layers 提供了各种数据变换的功能,用于对输入的图像数据进行预处理和增强。例如,通过调整图像的大小、裁剪、旋转、翻转等操作,可以增加数据的多样性,提高模型的泛化能力。同时,对图像进行归一化处理可以使数据具有相似的分布,有助于模型的训练和收敛。
3. 模型构建
视觉层包含了构建复杂视觉模型所需的各种组件,如卷积层、池化层、全连接层等。开发者可以根据具体的任务需求,将这些组件组合成不同的网络架构,如 LeNet、AlexNet、VGG、ResNet 等。此外,还可以使用预训练的模型进行迁移学习,在已有模型的基础上进行微调,以快速适应新的任务。
4. 空间信息处理
视觉层能够有效地处理图像中的空间信息。例如,池化层可以对特征图进行下采样,减少特征图的尺寸,同时保留重要的特征信息,降低模型的计算量和参数数量。而反卷积层(转置卷积层)则可以对特征图进行上采样,恢复图像的空间尺寸,常用于图像生成、语义分割等任务。
常见应用场景:
1. 图像分类
图像分类是计算机视觉中最基础的任务之一,其目标是将输入的图像分类到不同的类别中。PyTorch 的视觉层可以用于构建分类模型,通过卷积层提取图像特征,然后使用全连接层将特征映射到不同的类别上。例如,在花卉分类任务中,可以使用预训练的 ResNet 模型,经过微调后对不同种类的花卉图像进行分类。
2. 目标检测
目标检测是指在图像中定位和识别多个目标的任务。Vision Layers 可以用于构建目标检测模型,如 Faster R - CNN、YOLO 等。这些模型通常包含卷积层用于特征提取,以及特定的检测头用于预测目标的位置和类别。例如,在智能安防系统中,可以使用目标检测模型实时检测监控画面中的人物、车辆等目标。
3. 语义分割
语义分割是将图像中的每个像素分配到不同的类别中,实现对图像的像素级分类。PyTorch 的视觉层可以用于构建语义分割模型,如 U - Net、DeepLab 等。这些模型通常采用编码器 - 解码器结构,通过卷积层提取特征,然后使用反卷积层进行上采样,恢复图像的空间尺寸并输出像素级的分类结果。例如,在医学图像分析中,可以使用语义分割模型对肿瘤等病变区域进行分割。
4. 图像生成
图像生成任务包括生成逼真的图像、图像风格迁移等。Vision Layers 可以用于构建生成对抗网络(GAN)或变分自编码器(VAE)等生成模型。例如,在图像风格迁移任务中,可以使用卷积层提取图像的内容和风格特征,然后通过生成网络将一种风格的图像转换为另一种风格的图像。
5. 姿态估计
姿态估计是指估计图像或视频中人体或物体的姿态信息。PyTorch 的视觉层可以用于构建姿态估计模型,通过卷积层提取图像特征,然后预测人体关节点的位置。例如,在运动分析、人机交互等领域,姿态估计模型可以用于分析运动员的动作姿态或实现手势控制等功能。
具体要用的话可以参考官网定义的各种类
14,Shuffle Layers(混洗层)
在 PyTorch 里,Shuffle Layers(混洗层)通常指的是通道混洗层(Channel Shuffle Layer),它主要用于提升卷积神经网络(CNN)的效率和性能,尤其在轻量级网络架构中应用广泛。
通道混洗层的核心思想是打乱特征图中通道的顺序。在很多 CNN 架构中,为了提高计算效率,会采用分组卷积(Grouped Convolution)的方式。分组卷积将输入通道分成多个组,每个组独立进行卷积操作,这样可以减少参数数量和计算量。然而,分组卷积也带来了一个问题:不同组之间的通道缺乏信息交流,这可能会限制模型的表达能力。通道混洗层就是为了解决这个问题而设计的,它通过打乱通道顺序,使得不同组的通道能够进行信息交互,从而在不显著增加计算量的情况下提升模型性能。
具体作用:
1. 促进通道间信息交流
- 原理:分组卷积中,每个卷积组只处理自己组内的通道信息,导致不同组的通道之间缺乏信息共享。通道混洗层会重新排列通道,让原本属于不同组的通道在后续的卷积操作中有机会相互作用,增强了特征图的信息融合。
- 示例:假设在一个分组卷积中,将输入的 64 个通道分成 4 组,每组 16 个通道。经过通道混洗层后,原本属于不同组的通道会被重新组合,在后续卷积时就能实现跨组的信息交流。
2. 提高模型效率
- 原理:通道混洗层的操作非常简单,计算成本很低。它可以在不增加太多计算量和参数的情况下,提升分组卷积网络的性能。通过促进通道间的信息交流,使得模型能够更有效地学习特征,减少了因为分组卷积带来的信息隔离问题,从而提高了整体的计算效率。
- 示例:在轻量级的 CNN 架构中,如 ShuffleNet 系列,通道混洗层是核心组件之一。这些网络需要在有限的计算资源下实现较好的性能,通道混洗层通过高效的通道信息融合,帮助模型在减少计算量的同时保持较高的准确率。
3. 增强模型表达能力
- 原理:信息在通道间的充分交流使得模型能够学习到更丰富、更复杂的特征表示。不同组的通道可能捕捉到不同类型的特征,通道混洗层将这些特征进行整合,让模型能够更好地理解输入数据的特征分布,从而增强了模型的表达能力。
- 示例:在图像分类任务中,模型需要学习到图像的各种特征,如颜色、纹理、形状等。通道混洗层促进了不同特征信息的融合,使得模型能够更准确地对图像进行分类。
应用场景
1. 移动设备和嵌入式系统
在移动设备(如手机、平板电脑)和嵌入式系统(如智能摄像头、无人机)中,计算资源和功耗是重要的考虑因素。轻量级的 CNN 架构结合通道混洗层可以在有限的资源下实现高效的图像识别、目标检测等任务,例如在手机端的图像分类 APP 中,使用包含通道混洗层的模型可以快速准确地对图像进行分类,同时减少电池消耗。
2. 实时计算机视觉任务
对于需要实时处理的计算机视觉任务,如实时视频监控、自动驾驶中的环境感知等,模型的计算速度至关重要。通道混洗层能够提高模型的计算效率,使得模型可以在更短的时间内完成图像或视频的处理,满足实时性的要求。例如,在自动驾驶系统中,车辆需要实时识别道路上的各种目标,包含通道混洗层的模型可以快速准确地完成目标检测任务,保障行车安全。
具体要用的话可以参考官网定义的各种类
15,Loss Functions(损失函数)
(1)介绍
在 PyTorch 中,损失函数(Loss Functions)是深度学习模型训练过程中的关键组件,它用于衡量模型预测结果与真实标签之间的差异。
损失函数能够量化模型预测结果与真实值之间的差距。通过计算损失值,我们可以直观地了解模型在当前训练阶段的表现。损失值越小,说明模型的预测结果越接近真实值,模型性能越好。在训练过程中,优化器的目标是最小化损失函数。损失函数为优化器提供了优化的方向,通过反向传播算法计算损失函数关于模型参数的梯度,然后根据梯度更新模型参数,使得损失函数的值不断减小,从而逐步提高模型的性能。
除了以下介绍的损失函数,PyTorch还提供了很多其他的损失函数,按照自己项目的具体要求在官网选择一个合适的损失函数即可。
(2)nn.L1Loss(平均绝对误差)
nn.L1Loss 是 PyTorch 中用于计算损失的一个类,它实现了 L1 损失函数,也被称为平均绝对误差(Mean Absolute Error,MAE)损失函数。

使用场景:
- 回归任务:在回归问题中,目标是预测一个连续的数值,如房价预测、股票价格预测等。L1 损失对异常值的敏感性相对较低,因为它只考虑误差的绝对值,而不是误差的平方。这使得模型在存在异常值的数据集上训练时,不会过度受到异常值的影响,从而得到更稳健的预测结果。
- 模型鲁棒性要求较高的场景:当数据中可能存在噪声或异常值,并且希望模型对这些异常情况具有一定的鲁棒性时,L1 损失是一个不错的选择。与均方误差损失(MSE)相比,L1 损失在处理异常值时更加温和,不会因为个别异常样本的误差过大而使整个损失值大幅增加。
torch.nn.L1Loss(reduction='mean')reduction:指定损失的计算方式,有三种可选值:'mean':默认值,对所有样本的损失求平均值,得到一个标量值。'sum':将所有样本的损失相加,得到一个标量值。'none':不进行任何缩减操作,返回每个样本的损失值,输出的形状与输入的预测值和真实值相同。
import torch
import torch.nn as nn# 创建 L1Loss 实例
l1_loss = nn.L1Loss()# 生成随机的预测值和真实值
y_pred = torch.randn(10, 1) # 预测值,形状为 (10, 1)
y_true = torch.randn(10, 1) # 真实值,形状为 (10, 1)# 计算 L1 损失
loss = l1_loss(y_pred, y_true)print("L1 损失值:", loss.item())# 使用 'sum' 缩减方式
l1_loss_sum = nn.L1Loss(reduction='sum')
loss_sum = l1_loss_sum(y_pred, y_true)
print("使用 'sum' 缩减方式的 L1 损失值:", loss_sum.item())# 使用 'none' 缩减方式
l1_loss_none = nn.L1Loss(reduction='none')
loss_none = l1_loss_none(y_pred, y_true)
print("使用 'none' 缩减方式的 L1 损失形状:", loss_none.shape)(3)nn.MSELoss(均方误差损失)
- 适用场景:常用于回归任务,如房价预测、股票价格预测等,目标是预测一个连续的数值。
- 公式:

import torch
import torch.nn as nn# 定义 MSE 损失函数
mse_loss = nn.MSELoss()# 生成随机的真实标签和预测值
y_true = torch.randn(10, 1)
y_pred = torch.randn(10, 1)# 计算损失
loss = mse_loss(y_pred, y_true)
print("MSE 损失值:", loss.item())(4)nn.CrossEntropyLoss(交叉熵损失)
- 适用场景:常用于分类任务,如图像分类、文本分类等。

import torch
import torch.nn as nn# 定义交叉熵损失函数
ce_loss = nn.CrossEntropyLoss()# 生成随机的真实标签和预测的 logits
y_true = torch.randint(0, 5, (10,)) # 10 个样本,5 个类别
# 其形状为 (10,),这意味着它包含 10 个元素。 y_true 中的每个元素都是从 0 到 4 之间的整数。
#在多分类问题中,y_true 代表每个样本的真实类别标签。这里假设有 10 个样本,并且有 5 个不同的类
#别,类别索引从 0 到 4。例如,y_true 可能是 tensor([2, 4, 0, 3, 1, 2, 4, 0, 3, 1]),这表示第一
#个样本的真实类别是索引为 2 的类别,第二个样本的真实类别是索引为 4 的类别,依此类推。y_pred = torch.randn(10, 5) # 预测的 logits
#y_pred 是一个二维的 PyTorch 张量,其形状为 (10, 5),即有 10 行 5 列。
#使用 torch.randn(10, 5) 生成,这意味着张量中的每个元素都是从标准正态分布(均值为 0,标准差为
#1)中随机采样得到的。
#y_pred 代表模型对每个样本在各个类别上的预测得分,也称为 logits。对于每个样本,模型会输出一个长
#度为 5 的向量,向量中的每个元素对应一个类别的得分。例如,对于第一个样本,y_pred[0] 是一个长度为
#5 的向量,表示该样本属于 5 个不同类别的得分。在计算交叉熵损失时,nn.CrossEntropyLoss 会自动对这
#些 logits 应用 Softmax 函数,将其转换为概率分布,然后与真实标签进行比较。# 计算损失
#具体来说,nn.CrossEntropyLoss 会根据 y_pred 计算每个样本属于各个类别的概率,然后根据 y_true
#中的真实标签,计算预测概率与真实标签之间的交叉熵损失。最终返回的 loss 是所有样本损失的平均值
#(因为 reduction 参数默认是 'mean')。loss = ce_loss(y_pred, y_true)
print("交叉熵损失值:", loss.item())以下是交叉熵函数对输入输出数据的要求

输入数据要求
1. 预测值(input)
- 形状:通常是一个二维张量,形状为
(N, C),其中N表示批量大小(即样本数量),C表示类别数量。在一些情况下,对于图像等数据,预测值可能是三维或四维张量,但最后一个维度必须是类别数C。 - 数据类型:预测值的数据类型应为
torch.float32或torch.float64。 - 含义:预测值是模型最后一层(通常是全连接层)的输出,也称为 logits,即未经过 Softmax 函数处理的原始分数。
nn.CrossEntropyLoss内部会自动对 logits 应用 Softmax 函数,将其转换为概率分布。
2. 真实标签(target)
- 形状:通常是一个一维张量,形状为
(N),其中N是批量大小,与预测值的批量大小一致。 - 数据类型:真实标签的数据类型应为
torch.long。 - 含义:真实标签中的每个元素是一个整数,表示对应样本的真实类别索引,索引范围是
[0, C - 1],其中C是类别数量。
(5)nn.BCELoss(二元交叉熵损失)(了解)
- 适用场景:专门用于二分类任务,即类别只有两种的情况
- 公式:

import torch
import torch.nn as nn# 定义二元交叉熵损失函数
bce_loss = nn.BCELoss()# 生成随机的真实标签和预测的概率值
y_true = torch.randint(0, 2, (10, 1)).float() # 10 个样本的二分类标签
y_pred = torch.sigmoid(torch.randn(10, 1)) # 预测的概率值# 计算损失
loss = bce_loss(y_pred, y_true)
print("二元交叉熵损失值:", loss.item())(6)nn.NLLLoss(负对数似然损失)(了解)
- 适用场景:常用于多分类任务,通常与
nn.LogSoftmax层一起使用。 - 公式:

import torch
import torch.nn as nn# 定义负对数似然损失函数
nll_loss = nn.NLLLoss()# 生成随机的真实标签和经过 LogSoftmax 处理后的预测值
y_true = torch.randint(0, 5, (10,)) # 10 个样本,5 个类别
log_softmax = nn.LogSoftmax(dim=1)
y_pred = log_softmax(torch.randn(10, 5)) # 经过 LogSoftmax 处理后的预测值# 计算损失
loss = nll_loss(y_pred, y_true)
print("负对数似然损失值:", loss.item())(7)使用示例
一般使用步骤。在反向传播的介绍中说过
- 选择合适的损失函数:根据具体的任务类型(回归或分类)和问题特点,选择合适的损失函数。
- 定义损失函数对象:使用 PyTorch 提供的损失函数类创建损失函数对象。
- 计算损失:在模型的前向传播过程中,得到预测结果后,将预测结果和真实标签传入损失函数对象中,计算损失值。
- 反向传播和参数更新:调用损失值的
backward()方法进行反向传播计算梯度,然后使用优化器更新模型参数。
import torch
import torch.nn as nn
import torch.optim as optim# 定义一个简单的线性模型
model = nn.Linear(10, 1)# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 生成随机的真实标签和输入数据
y_true = torch.randn(5, 1)
x = torch.randn(5, 10)# 前向传播
y_pred = model(x)# 计算损失
loss = criterion(y_pred, y_true)# 反向传播
loss.backward()# 更新参数
optimizer.step()# 清空梯度
optimizer.zero_grad()print("更新后的损失值:", loss.item())在这个示例中,我们定义了一个简单的线性模型,使用 MSE 损失函数和随机梯度下降(SGD)优化器。在训练过程中,先进行前向传播得到预测结果,然后计算损失,接着进行反向传播和参数更新,最后清空梯度为下一次迭代做准备。
16,Optimizer(优化器)
(1)介绍
在 PyTorch 中,优化器(Optimizer)是用于更新模型参数以最小化损失函数的工具。优化器根据计算得到的梯度信息,按照特定的优化算法来更新模型的参数。
在深度学习中,训练模型的目标是找到一组最优的模型参数,使得模型在给定的数据集上的损失函数值最小。损失函数用于衡量模型预测结果与真实标签之间的差异,而优化器的作用就是根据损失函数的梯度信息,不断调整模型的参数,逐步降低损失函数的值,从而让模型的预测能力不断提升。
- 参数更新:在每次迭代中,优化器根据计算得到的梯度,按照特定的算法对模型的参数进行更新,使得模型朝着损失函数减小的方向前进。
- 自适应调整:一些优化器(如 Adam、RMSprop)能够自适应地调整每个参数的学习率,从而在不同参数的更新过程中更加灵活和高效。
- 加速收敛:不同的优化器采用了不同的优化策略,能够在一定程度上加速模型的收敛速度,减少训练所需的时间和迭代次数。
优化器的类有很多种,以下仅以SGD类做举例,讲解如何在模型中使用优化器。如果需要使用优化器,建议在PyTorch官网找到torch.optim中的各种优化器,根据需求选择。
(2)torch.optim.SGD(随机梯度下降)
选择优化器需要根据原理选择适合自己需求的优化器,并参考官方文档查找各参数含义。
随机梯度下降(Stochastic Gradient Descent,SGD)是最基础的优化算法,其核心思想是在每次迭代中,随机选择一个或一小批样本计算损失函数的梯度,然后根据梯度的反方向更新模型的参数。

torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False)这里仅介绍常用的两个参数 ,因为不同优化器基本只有前两项参数相同,其他参数根据不同优化器的算法各有不同
params:
- 类型:可迭代对象,通常为
model.parameters() - 说明:需要优化的模型参数。在 PyTorch 中,当你定义一个继承自
nn.Module的模型后,可以通过调用model.parameters()方法获取模型中所有需要训练的参数,将其作为params传入优化器。
import torch
import torch.nn as nn# 定义一个简单的线性模型
model = nn.Linear(10, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)lr:
- 类型:浮点数
- 说明:学习率(Learning Rate),它控制了每次参数更新的步长。学习率过大可能导致模型无法收敛,在最优解附近震荡;学习率过小则会使模型收敛速度过慢。这是一个必需的参数。
(3)使用实例
导入必要的库
import torch
import torch.nn as nn
import torch.optim as optim定义模型
class LinearRegression(nn.Module):def __init__(self):super(LinearRegression, self).__init__()# 定义一个线性层,输入维度为 1,输出维度为 1self.linear = nn.Linear(1, 1) def forward(self, x):# 前向传播,将输入 x 通过线性层得到输出out = self.linear(x)return out# 实例化模型
model = LinearRegression()定义损失函数
选择合适的损失函数来衡量模型预测结果与真实标签之间的差异。对于线性回归问题,常用的损失函数是均方误差损失(Mean Squared Error, MSE)。
# 定义均方误差损失函数
criterion = nn.MSELoss()定义优化器
选择合适的优化器,并传入模型的参数和学习率等超参数。这里我们使用随机梯度下降(SGD)优化器。
# 定义 SGD 优化器,传入模型参数和学习率
optimizer = optim.SGD(model.parameters(), lr=0.01)准备数据
准备训练数据,包括输入特征和对应的真实标签。在这个示例中,我们使用随机生成的数据。
# 生成一些随机训练数据
x_train = torch.randn(100, 1)
y_train = 2 * x_train + 1 + 0.1 * torch.randn(100, 1)训练模型
通过多次迭代训练模型,在每次迭代中执行以下操作:
- 前向传播:将输入数据传入模型,得到预测结果,并计算损失。
- 反向传播:调用
loss.backward()计算损失函数关于模型参数的梯度。 - 更新参数:调用
optimizer.step()根据梯度更新模型的参数。 - 清空梯度:调用
optimizer.zero_grad()清空上一次迭代的梯度信息,避免梯度累积。
# 设置训练的轮数
num_epochs = 100for epoch in range(num_epochs):# 前向传播outputs = model(x_train)loss = criterion(outputs, y_train)# 反向传播和参数更新optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 打印训练信息if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')保存模型
在训练完成后,你可以选择将训练好的模型保存下来,以便后续使用。
# 保存模型
torch.save(model.state_dict(), 'linear_regression_model.pth')七,使用PyTorch提供的网络模型
我们主要研究的是图像方面的网络模型,如果你要使用语音网络模型的话就可以在torchaudio里找,如果你要是用文字网络模型的话就可以在torchtext里面找。如下图所示官网,都可以找到对应的模型

本节只讲与图像有关的torchvision.models
1,介绍
torchvision.models 是 PyTorch 中 torchvision 库的一个子模块,它提供了许多预训练好的深度学习模型,涵盖了图像分类、目标检测、语义分割等多个计算机视觉任务。这些预训练模型在大规模图像数据集(如 ImageNet)上进行了训练,能够为用户提供强大的特征提取和预测能力,极大地简化了模型开发的过程。
以下仅对图像分类模型展开讲解,目标检测模型和语义分割模型大同小异
2,图像分类模型
除了AlexNet,ResNet模型外,还有VGG,SqueezeNet,DenseNet,ResNext等等模型,不同模型在不同场景和任务下各有优势,可以参考官网找到适合自己的模型再具体学习。以下仅以AlexNet和ResNet模型做介绍学习
(1)AlexNet
1,背景及原理
AlexNet 是由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 在 2012 年提出的深度卷积神经网络模型,它在当年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)中取得了巨大的成功,Top - 5 错误率相比之前的方法大幅降低。AlexNet 的出现标志着深度学习在计算机视觉领域的崛起,开启了深度卷积神经网络在图像识别等任务上的广泛应用。
AlexNet 网络结构相对较深,共有 8 层,其中包含 5 个卷积层和 3 个全连接层。以下是其详细结构:
- 输入层:输入图像的大小为 224×224×3(高度 × 宽度 × 通道数)。
- 卷积层 1:使用 96 个大小为 11×11 的卷积核,步长为 4,填充为 0。经过卷积操作后,输出特征图的大小为 55×55×96。接着使用 ReLU 激活函数引入非线性。之后使用最大池化层,池化窗口大小为 3×3,步长为 2,输出特征图大小变为 27×27×96。
- 卷积层 2:使用 256 个大小为 5×5 的卷积核,步长为 1,填充为 2。经过卷积和 ReLU 激活后,使用最大池化层(3×3 窗口,步长 2),输出特征图大小为 13×13×256。
- 卷积层 3:使用 384 个大小为 3×3 的卷积核,步长为 1,填充为 1,经过 ReLU 激活。
- 卷积层 4:使用 384 个大小为 3×3 的卷积核,步长为 1,填充为 1,经过 ReLU 激活。
- 卷积层 5:使用 256 个大小为 3×3 的卷积核,步长为 1,填充为 1。之后使用最大池化层(3×3 窗口,步长 2),输出特征图大小为 6×6×256。
- 全连接层 1:将卷积层 5 的输出展平为一维向量,输入到包含 4096 个神经元的全连接层,经过 ReLU 激活和 Dropout(丢弃率为 0.5)。
- 全连接层 2:同样有 4096 个神经元,经过 ReLU 激活和 Dropout(丢弃率为 0.5)。
- 输出层:包含 1000 个神经元,对应 ImageNet 数据集的 1000 个类别,使用 Softmax 函数输出每个类别的概率。
创新点:
- ReLU 激活函数:传统的神经网络使用 Sigmoid 或 Tanh 作为激活函数,这些函数在输入值较大或较小时容易出现梯度消失的问题。ReLU(Rectified Linear Unit)激活函数的公式为f(x)=max(0,x) ,它在正区间内梯度恒为 1,有效缓解了梯度消失问题,加快了网络的训练速度。
- 数据增强:通过随机裁剪、水平翻转等方式对训练数据进行扩充,增加了数据的多样性,减少了过拟合的风险。
- Dropout:在全连接层中使用 Dropout 技术,以一定的概率随机丢弃部分神经元,使得网络在训练过程中不会过度依赖某些特定的神经元,增强了模型的泛化能力。
- GPU 加速:AlexNet 是第一个充分利用 GPU 并行计算能力进行训练的深度神经网络,大大缩短了训练时间。
2,使用方法
参数说明
pretrained:
- 类型:布尔值(
bool) - 默认值:
False - 说明:用于指定是否加载在 ImageNet 数据集上预训练好的模型权重。
- 当
pretrained = True时,会自动从 PyTorch 的官方模型库中下载预训练的权重并加载到模型中。这样做的好处是可以利用在大规模数据集上学习到的特征表示,在自己的任务上进行微调,通常能加快收敛速度并提升模型性能。 - 当
pretrained = False时,会创建一个随机初始化权重的 AlexNet 模型,适合从头开始训练模型的场景。
- 当
import torchvision.models as models# 加载预训练模型
pretrained_alexnet = models.alexnet(pretrained=True)# 加载随机初始化模型
random_alexnet = models.alexnet(pretrained=False)progress:
- 类型:布尔值(
bool) - 默认值:
True - 说明:仅在
pretrained = True时有效。用于控制在下载预训练权重时是否显示下载进度条。- 当
progress = True时,下载过程中会在控制台显示下载进度信息。 - 当
progress = False时,下载过程将静默进行,不会显示进度条。# 加载预训练模型,不显示下载进度条 alexnet = models.alexnet(pretrained=True, progress=False)
- 当
num_classes:
- 类型:整数(
int) - 默认值:1000
- 说明:指定模型输出层的类别数量,即模型可以进行分类的类别总数。在 ImageNet 数据集上,有 1000 个不同的类别,所以默认值为 1000。如果你的任务涉及的类别数量不同,需要修改这个参数。通常在使用预训练模型进行迁移学习时,会根据具体任务调整输出层的类别数。
import torch
import torchvision.models as models# 假设我们的任务是进行 10 分类
num_classes = 10
alexnet = models.alexnet(pretrained=True)# 修改输出层#在 AlexNet 模型中,classifier 是一个包含多个全连接层的序列模块(nn.Sequential)。
#alexnet.classifier[6] 指的是 classifier 序列中的第 7 个模块(索引从 0 开始),也就是原始的输出
#层。in_features 是 nn.Linear 层的一个属性,它表示该层的输入特征数量,即前一层输出的神经元数量。
#通过这行代码,我们获取了原始输出层的输入特征数量,并将其存储在变量 num_ftrs 中。
num_ftrs = alexnet.classifier[6].in_features
#这行代码将原始的输出层替换为一个新的全连接层。torch.nn.Linear 是 PyTorch 中用于定义全连接层的
#类,它接受两个参数:in_features 和 out_features。这里我们将 in_features 设置为 num_ftrs,确保
#新的输出层接收的输入特征数量与原始输出层相同;将 out_features 设置为 num_classes,也就是我们前
#定义的 10,表示新的输出层将输出 10 个神经元,对应 10 个分类类别。
alexnet.classifier[6] = torch.nn.Linear(num_ftrs, num_classes)(2)ResNet
1,背景及原理
在深度神经网络的发展过程中,人们发现随着网络深度的增加,模型的训练误差和测试误差反而会增大,这种现象被称为 “退化问题”,它并非由过拟合导致。传统的神经网络在层数加深时,梯度在反向传播过程中容易出现消失或爆炸的情况,使得模型难以收敛到较好的结果。

ResNet 有多种不同的架构,如 ResNet18、ResNet34、ResNet50、ResNet101 和 ResNet152 等,数字代表网络的层数。以 ResNet18 和 ResNet50 为例:
- ResNet18 和 ResNet34:使用基本的残差块(Basic Block),每个基本残差块包含两个 3x3 的卷积层。
- ResNet50、ResNet101 和 ResNet152:使用瓶颈残差块(Bottleneck Block),瓶颈残差块由一个 1x1 卷积层进行降维、一个 3x3 卷积层进行特征提取和一个 1x1 卷积层进行升维组成,这样可以减少参数量。
ResNet 的整体结构通常包括:
- 输入层:接收输入图像,一般会进行一些预处理操作,如归一化等。
- 初始卷积层:通常使用一个较大的卷积核(如 7x7)进行初步的特征提取,并使用最大池化层进行下采样。
- 多个残差块组:由多个残差块堆叠而成,每个组内的残差块结构相同,不同组之间的通道数会逐渐增加,同时可能会进行下采样操作。
- 全局平均池化层:将特征图在空间维度上进行平均池化,将每个通道的特征图变为一个标量,减少参数量。
- 全连接层:将全局平均池化层的输出连接到一个全连接层,输出最终的分类结果。
2,使用方法
参数说明
pretrained:
- 类型:布尔值(
bool) - 默认值:
False - 说明:指定是否加载在 ImageNet 数据集上预训练好的模型权重。当
pretrained = True时,会自动下载并加载预训练权重;当pretrained = False时,模型权重将随机初始化。
import torchvision.models as models# 加载预训练的 ResNet50 模型
resnet50_pretrained = models.resnet50(pretrained=True)# 加载随机初始化的 ResNet50 模型
resnet50_random = models.resnet50(pretrained=False)progress
- 类型:布尔值(
bool) - 默认值:
True - 说明:仅在
pretrained = True时有效。用于控制在下载预训练权重时是否显示下载进度条。当progress = True时,会显示进度条;当progress = False时,下载过程将静默进行。
num_classes
- 类型:整数(
int) - 默认值:1000
- 说明:指定模型输出层的类别数量。由于预训练的 ResNet 模型是在 ImageNet 数据集上训练的,该数据集有 1000 个类别,所以默认值为 1000。如果你的任务类别数不同,需要修改这个参数。
import torch
import torchvision.models as models# 假设我们的任务是进行 10 分类
num_classes = 10
resnet50 = models.resnet50(pretrained=True)
num_ftrs = resnet50.fc.in_features
resnet50.fc = torch.nn.Linear(num_ftrs, num_classes)3,目标检测模型
- Faster R-CNN:一种两阶段的目标检测模型,由区域生成网络(Region Proposal Network, RPN)和 Fast R-CNN 组成,能够同时完成目标的定位和分类。
- Mask R-CNN:在 Faster R-CNN 的基础上增加了一个用于实例分割的分支,能够同时完成目标的检测、分类和分割任务。
4,语义分割模型
- FCN:全卷积网络(Fully Convolutional Networks),是最早提出的用于语义分割的深度学习模型,将传统的卷积神经网络中的全连接层替换为卷积层,能够输出与输入图像大小相同的分割结果。
- DeepLabV3:采用了空洞卷积(Dilated Convolution)和空间金字塔池化(Atrous Spatial Pyramid Pooling, ASPP)等技术,在语义分割任务上取得了很好的效果。
5,模型的保存
import torchvisionvgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1(既保存模型结构,也保存参数)
torch.save(vgg16, "vgg16_method1.pth") # ""里指定路径。运行后即可在当前目录下看到保存的模型# 保存方式2(只将模型的参数保存为字典)
torch.save(vgg16.state_dict(), "vgg16_method2.pth")对于自己定义的模型保存也是一样的,如下
import torch
from torch import nnclass MyModel(nn.Module):def __init__(self):super().__init()def forward(self, input):output = input + 1return outputmymodel = MyModel()
torch.save("mymodel1.pth")6,模型的加载
import torch# 保存方式1加载模型
model = torch.load("vgg16_method1.pth") # 输入模型路径即可加载模型# 保存方式2加载模型
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))对于自己的模型保存后再加载需要注意一个点:加载此模型时必须将class定义的模型粘贴复制到要加载模型的文件中。可以不用再实例 当然也可以通过from ... import *将定义了模型的文件内容都引用过去
import torch
from torch import nnclass MyModel(nn.Module):def __init__(self):super().__init()def forward(self, input):output = input + 1return outputmodel = torch.load("mymodel1.pth")八,完整模型训练过程
以CIFAR10数据集为例进行训练
import torchvision
from torch import nn
import torch
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader# 准备训练集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(), download=True)# 准备测试集
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)# DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 搭建神经网络
class MyModel(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return x# 创建网络模型
mymodel = MyModel()# 损失函数
loss_fn = nn.CrossEntropyLoss()# 优化器
optimizer = torch.optim.SGD(mymodel.parameters(), lr=0.01)# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数变量
total_test_step = 0 # 记录测试的次数
epoch = 100 # 训练的轮数# 添加tensorboard
writer = SummaryWriter("../logs_train")for i in range(epoch):print("第{}轮训练开始".format(i+1))for data in train_dataloader:imgs, targets = dataoutputs = mymodel(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0: # 100轮打印一次训练误差print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 每次训练完后在测试数据集上跑一遍,以测试数据集的正确率来评估模型是否训练好total_test_loss = 0with torch.no_grad():for data in test_dataloader:imgs, targets = dataoutputs = mymodel(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()print("整体测试集上的Loss:{}".format(total_test_loss))total_test_step = total_test_step + 1writer.add_scaler("test_loss", total_test_loss, total_test_step)# 保存每一轮的模型torch.save(mymodel, "mymodel_{}.pth".format(i))writer.close()以下为优化代码,对于分类问题一般采用测试集正确率来衡量模型训练的效果
import torchvision
from torch import nn
import torch
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader# 准备训练集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(), download=True)# 准备测试集
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)# DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 搭建神经网络
class MyModel(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return x# 创建网络模型
mymodel = MyModel()# 损失函数
loss_fn = nn.CrossEntropyLoss()# 优化器
optimizer = torch.optim.SGD(mymodel.parameters(), lr=0.01)# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数变量
total_test_step = 0 # 记录测试的次数
epoch = 100 # 训练的轮数# 添加tensorboard
writer = SummaryWriter("../logs_train")for i in range(epoch):print("第{}轮训练开始".format(i+1))for data in train_dataloader:imgs, targets = dataoutputs = mymodel(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0: # 100轮打印一次训练误差print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 每次训练完后在测试数据集上跑一遍,以测试数据集的正确率来评估模型是否训练好total_test_loss = 0total_accuracy = 0 with torch.no_grad():for data in test_dataloader:imgs, targets = dataoutputs = mymodel(imgs)accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的正确率:{}%".format((total_accuracy / len(test_data)))*100)total_test_step = total_test_step + 1writer.add_scaler("test_accuracy", total_accuracy / len(test_data), total_test_step)# 保存每一轮的模型torch.save(mymodel, "mymodel_{}.pth".format(i))writer.close()有些人会在训练开始时加入mymodel.train()函数,在测试开始时加入mymodel.eval()函数。这两个函数是让模型进入训练模式或者测试模式,只有在模型用到了某些层(Dropout,BatchNorm等)时才有作用,保险起见一般我们写代码的时候都加上。


九,使用GPU进行训练
在上一章的代码基础上修改几处即可
GPU的训练方式有两种
下面介绍第一种,第一种GPU的训练方式只要找到网络模型,数据(imgs,targets),损失函数,然调用他们的.cuda()进行返回即可
import torchvision
from torch import nn
import torch
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader# 准备训练集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(), download=True)# 准备测试集
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)# DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 搭建神经网络
class MyModel(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return x# 创建网络模型
mymodel = MyModel()
if torch.cuda.is_available():mymodel.cuda()# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():loss_fn.cuda()# 优化器
optimizer = torch.optim.SGD(mymodel.parameters(), lr=0.01)# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数变量
total_test_step = 0 # 记录测试的次数
epoch = 100 # 训练的轮数# 添加tensorboard
writer = SummaryWriter("../logs_train")for i in range(epoch):print("第{}轮训练开始".format(i+1))for data in train_dataloader:imgs, targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = mymodel(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0: # 100轮打印一次训练误差print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 每次训练完后在测试数据集上跑一遍,以测试数据集的正确率来评估模型是否训练好total_test_loss = 0total_accuracy = 0 with torch.no_grad():for data in test_dataloader:imgs, targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = mymodel(imgs)accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的正确率:{}%".format((total_accuracy / len(test_data)))*100)total_test_step = total_test_step + 1writer.add_scaler("test_accuracy", total_accuracy / len(test_data), total_test_step)# 保存每一轮的模型torch.save(mymodel, "mymodel_{}.pth".format(i))writer.close()下面介绍第二种也是更常用的GPU使用方式 。使用.to(device)方法
import torchvision
from torch import nn
import torch
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader# 定义训练设备
device = torch.device("cuda") # 在GPU上运行,也可以填cpu。可以填cuda:0选择第一张显卡# 也可以填cuda:1选择第二张显卡(对于多显卡设备)
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 准备训练集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(), download=True)# 准备测试集
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)# DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 搭建神经网络
class MyModel(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return x# 创建网络模型
mymodel = MyModel()
mymodel.to(device)# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)# 优化器
optimizer = torch.optim.SGD(mymodel.parameters(), lr=0.01)# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数变量
total_test_step = 0 # 记录测试的次数
epoch = 100 # 训练的轮数# 添加tensorboard
writer = SummaryWriter("../logs_train")for i in range(epoch):print("第{}轮训练开始".format(i+1))for data in train_dataloader:imgs, targets = dataimgs = imgs.to(device)targets = targets.to(device)outputs = mymodel(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0: # 100轮打印一次训练误差print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 每次训练完后在测试数据集上跑一遍,以测试数据集的正确率来评估模型是否训练好total_test_loss = 0total_accuracy = 0 with torch.no_grad():for data in test_dataloader:imgs, targets = dataimgs = imgs.to(device)targets = targets.to(device)outputs = mymodel(imgs)accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的正确率:{}%".format((total_accuracy / len(test_data)))*100)total_test_step = total_test_step + 1writer.add_scaler("test_accuracy", total_accuracy / len(test_data), total_test_step)# 保存每一轮的模型torch.save(mymodel, "mymodel_{}.pth".format(i))writer.close()十,模型验证(利用已经训练好的模型测试)
from PIL import Image
import torchvisionimage_path = "../imgs.png" # 要测试的图片所在路径
Image.open(image_path) # 读取图片
image = image.convert('RGB') # 确保图片为三颜色通道,可以适应各种格式的图片transform = tochvision.transforms.Compose([torchvision.transforms.Resize(32,32),torchvision.transforms.ToTensor()])image = transform(image)# 加载模型
model = torch.load("mymodel_0.pth")image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():output = model(image)
outputs = model(image)print(output.argmax(1))
注意使用GPU训练的模型,在CPU中加载时要用map_location=torch.device('cpu')对应到cpu上
from PIL import Image
import torchvisionimage_path = "../imgs.png" # 要测试的图片所在路径
Image.open(image_path) # 读取图片
image = image.convert('RGB') # 确保图片为三颜色通道,可以适应各种格式的图片transform = tochvision.transforms.Compose([torchvision.transforms.Resize(32,32),torchvision.transforms.ToTensor()])image = transform(image)# 加载模型
model = torch.load("mymodel_0_gpu.pth", map_location=torch.device('cpu'))image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():output = model(image)
outputs = model(image)print(output.argmax(1))
相关文章:
PyTorch快速入门
Anaconda Anaconda 是一款面向科学计算的开源 Python 发行版本,它集成了众多科学计算所需的库、工具和环境管理系统,旨在简化包管理和部署,提升开发与研究效率。 核心组件: Conda:这是 Anaconda 自带的包和环境管理…...

100.7 AI量化面试题:如何利用新闻文本数据构建交易信号?
目录 0. 承前1. 解题思路1.1 数据处理维度1.2 分析模型维度1.3 信号构建维度 2. 新闻数据获取与预处理2.1 数据获取接口2.2 文本预处理 3. 情感分析与事件抽取3.1 情感分析模型3.2 事件抽取 4. 信号生成与优化4.1 信号构建4.2 信号优化 5. 策略实现与回测5.1 策略实现 6. 回答话…...

CF 465B.Inbox (100500)(Java实现)
题目分析 计算读取所有未读邮件所需的步数,其中1代表未读,0代表已读 思路分析 遍历邮件,如果当前是未读,那么所需步数1,如果下一封也是未读,不用管(遍历后会直接1),如果下一封是已读࿰…...

微信小程序获取openid和其他接口同时并发请求如何保证先获取到openid
在微信小程序中,如果你需要并发请求获取 openid 和其他接口的数据,并且希望确保先获取到 openid 之后再进行后续操作,可以考虑以下几种方法: 方法一:使用 Promise 链 1, 先请求 openid:使用 Promise 来请求 openid。 2, 在获取到 openid 后再请求其他接口。 function g…...

实现动态卡通笑脸的着色器实现
大家好!我是 [数擎 AI],一位热爱探索新技术的前端开发者,在这里分享前端和 Web3D、AI 技术的干货与实战经验。如果你对技术有热情,欢迎关注我的文章,我们一起成长、进步! 开发领域:前端开发 | A…...

DeepSeek R1 模型解读与微调
DeepSeek R1 模型是 DeepSeek 团队推出的一款重要的大语言模型,旨在通过强化学习提升大型语言模型的推理能力。 模型架构 DeepSeek-R1-Zero DeepSeek-R1-Zero 是 DeepSeek 团队推出的第一代推理模型,完全依靠强化学习(RL)训练&…...

YOLOv11实时目标检测 | 摄像头视频图片文件检测
在上篇文章中YOLO11环境部署 || 从检测到训练https://blog.csdn.net/2301_79442295/article/details/145414103#comments_36164492,我们详细探讨了YOLO11的部署以及推理训练,但是评论区的观众老爷就说了:“博主博主,你这个只能推理…...

Node.js学习指南
一、模块化规范 nodejs使用的模块化规范 叫做 common.js 规范: 每一个模块都有独立的作用域 代码在各自模块中执行 不会造成全局污染 每一个模块都是一个独立的文件(module对象) 模块可以被多次加载(module.exports 属性) 但是仅…...

2.5学习总结
今天看了二叉树,看的一脸懵,写了两道题 P4913:二叉树深度 #include <stdio.h> #include <stdlib.h> struct hly {int left;int right; }tree[1000005]; int hulingyun(int x) {if(x0)return 0;return 1max(hulingyun(tree[x].le…...

java进阶文章链接
java 泛型:java 泛型详解-绝对是对泛型方法讲解最详细的,没有之一 Java 泛型,你了解类型擦除吗? java 注解:深入理解Java注解类型 秒懂,Java 注解 (Annotation)你可以这样学 jav…...

vue2+vue3 HMCXY基础入门
vue2vue3 HMCXY基础入门 一、Vue2.x技术精讲1.Vue快速上手(1)Vue概念(2)创建实例(3)插值表达式(4)响应式特性(5)开发者工具 2.Vue指令二、Vue3.x技术精讲 一、…...

一次线程数超限导致的hive写入hbase作业失败分析
1.集群配置 操作系统:SuSe操作系统 集群节点:100台相同配置的服务器 单台:核心112Core,内存396G 2.问题现象 现象1:跑单个入库任务报错,批量提交任务后出现OOM异常 执行12个hivesql,将数据写入hbase.hbase入库有近一半的任务报错。 每次报错的任务不是同一个,hivesql…...

ip属地是手机号还是手机位置?一文理清
在数字化和网络化的今天,IP属地这一概念逐渐成为了人们关注的焦点。特别是在社交媒体和在线平台上,IP属地的显示往往让人联想到用户的地理位置。然而,关于IP属地到底与手机号还是手机位置有关,却存在着不少误解和混淆。本文将深入…...

查看设备uuid
在大多数操作系统中,可以通过不同的方式来查看设备的 UUID(Universally Unique Identifier)。以下是一些常见的方法: 在Linux系统中,可以使用命令行工具blkid或lsblk来查看设备的 UUID。例如,执行以下命令…...
)
C_C++输入输出(下)
C_C输入输出(下) 用两次循环的问题: 1.一次循环决定打印几行,一次循环决定打印几项 cin是>> cout是<< 字典序是根据字符在字母表中的顺序来比较和排列字符串的(字典序的大小就是字符串的大小)…...

All in one 的 AI tool Chain “Halomate”
这不算广告啊,就是真好用,虽然是我哥们儿的产品 比如你定了个gpt的plus 订阅,你发现好像有挺多功能 1- chat,这个自不必说,必须的功能 2- 高级语音 现在变成学英语的了,实时视频也就是我过年给姑婶介绍是…...

crewai框架第三方API使用官方RAG工具(pdf,csv,json)
最近在研究调用官方的工具,但官方文档的说明是在是太少了,后来在一个视频里看到了如何配置,记录一下 以PDF RAG Search工具举例,官方文档对于自定义模型的说明如下: 默认情况下,该工具使用 OpenAI 进行嵌…...

脉冲信号傅里叶变换与频域分析:从计算到理解
摘要 本文聚焦于脉冲信号的傅里叶变换,详细推导了矩形脉冲信号和单边指数信号的傅里叶变换过程,深入解释了傅里叶变换结果 F ( ω ) F(\omega) F(ω) 的内涵,包括其定义、物理意义、包含的信息以及在实际应用中的重要性。旨在帮助读者全面掌…...

6.【BUUCTF】[SUCTF 2019]CheckIn
打开题目页面如下 看样子是一道有关文件上传的题 上传一句话木马 显示:非法后缀! 看来.php后缀被过滤了 上传一张带有木马的照片 在文件地址处输入cmd 输入以下代码执行 copy 1.jpg/b4.php/a 5.jpg 最后一行有一句话木马 上传带有木马的图片 但其实…...

基于springboot的体质测试数据分析及可视化设计
作者:学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等 文末获取“源码数据库万字文档PPT”,支持远程部署调试、运行安装。 项目包含: 完整源码数据库功能演示视频万字文档PPT 项目编码࿱…...

3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南
3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否在使用Windows 11 24H2 LT…...

如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南
如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management…...

JetBrains IDE 30天试用重置:一键解决方案的完整实践指南
JetBrains IDE 30天试用重置:一键解决方案的完整实践指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 当您正专注于代码调试时,IDE突然弹出"评估期已结束"的红色警告…...

移动端AI助手开发实战:混合架构、模型部署与性能优化
1. 项目概述:一个移动端AI助手的诞生 最近在移动端AI应用开发圈子里,一个名为 copaw-mobile 的项目开始引起不少同行的注意。这个由 xmingai 团队开源的项目,定位非常清晰——它要做的,就是将一个功能强大的AI助手,…...

详解C++作用域与生命周期
Pascal之父Nicklaus Wirth曾经提出一个公式,展示出了程序的本质:程序算法数据结构。后人又给出一个公式与之遥相呼应:软件程序文档。这两个公式可以简洁明了的为我们展示程序和软件的组成。程序的运行过程可以理解为算法对数据的加工过程&…...

数据分析师GitHub作品集构建指南:从项目架构到技术实现
1. 项目概述:一个数据分析师的作品集仓库意味着什么? 在数据驱动的时代,简历上的“精通Python/SQL”已经不够看了。面试官,尤其是那些懂行的技术面试官,更想看到的是你如何用这些工具解决真实世界的问题。这就是为什么…...
嵌入式LED色彩校正:Gamma原理与Arduino NeoPixel实战
1. 项目概述:为什么你的NeoPixel灯带颜色总是不对劲?如果你玩过像NeoPixel、WS2812B这类可编程LED灯带,并且尝试过自己调色,大概率遇到过这样的困惑:你在代码里设定了一个“橙色”——比如红色满值255,绿色…...

基于电子纸与ESP32的物联网桌面日历制作指南
1. 项目概述:打造一个永不掉电的桌面物联网日历如果你和我一样,喜欢在桌面上放点既实用又有科技感的小玩意儿,那么这个基于电子纸的物联网日历绝对能让你眼前一亮。它不像普通屏幕那样需要一直插着电,显示完日历后,你甚…...

Harness 中的请求标识染色:端到端追踪
1. 标题选项(核心关键词:Harness、请求标识染色、端到端追踪、可观测性、CI/CD) 「Harness 可观测性实战:请求标识染色实现全链路端到端追踪」 「从0到1搞定Harness请求染色:让微服务调用链路+变更链路无所遁形」 「告别排查黑洞:Harness请求标识染色的端到端追踪落地指南…...

CircuitPython嵌入式开发实战:从GPIO到音频输出的完整指南
1. CircuitPython嵌入式开发入门:从GPIO到音频的实战指南如果你刚拿到一块Adafruit的开发板,刷好了CircuitPython,看着板子上那些密密麻麻的引脚,是不是既兴奋又有点无从下手?别担心,几乎所有嵌入式开发者都…...