蓝桥杯python基础算法(2-1)——排序
目录
一、排序
二、例题 P3225——宝藏排序Ⅰ
三、各种排序比较
四、例题 P3226——宝藏排序Ⅱ
一、排序
(一)冒泡排序
基本思想:比较相邻的元素,如果顺序错误就把它们交换过来。
(二)选择排序
基本思想:在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾
(三)插入排序
基本思想:将未排序数据插入到已排序序列的合适位置。
(四)快速排序
基本思想:选择一个基准值,将数组分为两部分,小于基准值的放在左边,大于基准值的放在右边,然后对左右两部分分别进行排序。
(五)归并排序
基本思想:将数组分成两个子数组,对两个子数组分别进行排序,然后将排序好的子数组合并成一个有序的数组。
(七)桶排序
基本思想:将待排序的数据元素,按照一定的规则划分到不同的“桶”中。每个桶内的数据元素再根据具体情况进行单独排序(通常可以使用其他简单排序算法,如插入排序),最后将各个桶中排好序的数据元素依次取出,就得到了一个有序的序列。
应用要点
时间复杂度:不同排序算法时间复杂度不同,如冒泡排序、选择排序、插入排序平均时间复杂度为 O(n^2),快速排序平均时间复杂度为 O(nlogn),归并排序时间复杂度稳定在 O(nlogn)。蓝桥杯题目对时间限制严格,大数据量下应优先选择 O(nlogn) 级别的排序算法。
空间复杂度:有些题目对空间也有限制。例如归并排序空间复杂度为 O(n),而快速排序如果实现合理(如原地分区)空间复杂度可以为 O(logn)。
稳定性:排序稳定性指相等元素在排序前后相对位置是否改变。例如插入排序、冒泡排序是稳定的,选择排序、快速排序是不稳定的。如果题目要求保持相等元素相对顺序,要选择稳定排序算法。
二、例题 P3225——宝藏排序Ⅰ
在一个神秘的岛屿上,有一支探险队发现了一批宝藏,这批宝藏是以整数数组的形式存在的。每个宝藏上都标有一个数字,代表了其珍贵程度。然而,由于某种神奇的力量,这批宝藏的顺序被打乱了,探险队需要将宝藏按照珍贵程度进行排序,以便更好地研究和保护它们。作为探险队的一员,肖恩需要设计合适的排序算法来将宝藏按照珍贵程度进行从小到大排序。请你帮帮肖恩。
输入描述
输入第一行包括一个数字 n ,表示宝藏总共有 n 个。
输入的第二行包括 n 个数字,第 ii 个数字 a[i] 表示第 i 个宝藏的珍贵程度。
数据保证 1≤n≤1000,1≤a[i]≤10^6 。
输出描述
输出 n 个数字,为对宝藏按照珍贵程度从小到大排序后的数组。
# 冒泡排序 def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n - i - 1):if arr[j] > arr[j + 1]:arr[j], arr[j + 1] = arr[j + 1], arr[j]return arr# 选择排序 def selection_sort(arr):n = len(arr)for i in range(n):min_index = ifor j in range(i + 1, n):if arr[j] < arr[min_index]:min_index = jarr[i], arr[min_index] = arr[min_index], arr[i]return arr# 插入排序 def insertion_sort(arr):n = len(arr)for i in range(1, n):key = arr[i]j = i - 1while j >= 0 and key < arr[j]:arr[j + 1] = arr[j]j = j - 1arr[j + 1] = keyreturn arr# 快速排序 def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)# 归并排序 def merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left_half = arr[:mid]right_half = arr[mid:]left_half = merge_sort(left_half)right_half = merge_sort(right_half)return merge(left_half, right_half)def merge(left, right):result = []left_index = 0right_index = 0while left_index < len(left) and right_index < len(right):if left[left_index] < right[right_index]:result.append(left[left_index])left_index += 1else:result.append(right[right_index])right_index += 1result.extend(left[left_index:])result.extend(right[right_index:])return result# 桶排序 def bucket_sort(arr):max_val = max(arr)min_val = min(arr)bucket_size = 1000bucket_count = (max_val - min_val) // bucket_size + 1buckets = [[] for _ in range(bucket_count)]for num in arr:index = (num - min_val) // bucket_sizebuckets[index].append(num)for i in range(bucket_count):buckets[i].sort()sorted_arr = []for bucket in buckets:sorted_arr.extend(bucket)return sorted_arrn = int(input()) treasures = list(map(int, input().split()))print("冒泡排序结果:") print(bubble_sort(treasures[:]))print("选择排序结果:") print(selection_sort(treasures[:]))print("插入排序结果:") print(insertion_sort(treasures[:]))print("快速排序结果:") print(quick_sort(treasures[:]))print("归并排序结果:") print(merge_sort(treasures[:]))print("桶排序结果:") print(bucket_sort(treasures[:]))

三、各种排序比较
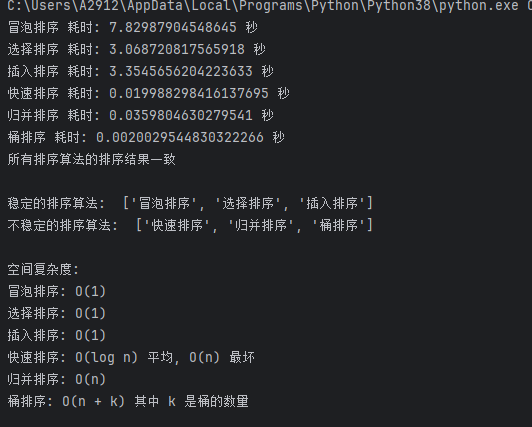
import time import random# 冒泡排序 def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n - i - 1):if arr[j] > arr[j + 1]:arr[j], arr[j + 1] = arr[j + 1], arr[j]return arr# 选择排序 def selection_sort(arr):n = len(arr)for i in range(n):min_index = ifor j in range(i + 1, n):if arr[j] < arr[min_index]:min_index = jarr[i], arr[min_index] = arr[min_index], arr[i]return arr# 插入排序 def insertion_sort(arr):n = len(arr)for i in range(1, n):key = arr[i]j = i - 1while j >= 0 and key < arr[j]:arr[j + 1] = arr[j]j = j - 1arr[j + 1] = keyreturn arr# 快速排序 def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)# 归并排序 def merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left_half = arr[:mid]right_half = arr[mid:]left_half = merge_sort(left_half)right_half = merge_sort(right_half)return merge(left_half, right_half)def merge(left, right):result = []left_index = 0right_index = 0while left_index < len(left) and right_index < len(right):if left[left_index] < right[right_index]:result.append(left[left_index])left_index += 1else:result.append(right[right_index])right_index += 1result.extend(left[left_index:])result.extend(right[right_index:])return result# 桶排序 def bucket_sort(arr):max_val = max(arr)min_val = min(arr)bucket_size = 1000bucket_count = (max_val - min_val) // bucket_size + 1buckets = [[] for _ in range(bucket_count)]for num in arr:index = (num - min_val) // bucket_sizebuckets[index].append(num)for i in range(bucket_count):buckets[i].sort()sorted_arr = []for bucket in buckets:sorted_arr.extend(bucket)return sorted_arr# —————————————————————————————————————————————— # 生成测试数据 test_array = [random.randint(1, 10000) for _ in range(10000)]# 记录每种排序的时间 sorting_methods = [("冒泡排序", bubble_sort),("选择排序", selection_sort),("插入排序", insertion_sort),("快速排序", quick_sort),("归并排序", merge_sort),("桶排序", bucket_sort) ]# 比较排序结果 sorted_results = {} for name, sort_func in sorting_methods:start_time = time.time()sorted_array = sort_func(test_array[:])end_time = time.time()sorted_results[name] = sorted_arrayprint(f"{name} 耗时: {end_time - start_time} 秒")# 比较排序结果是否一致 base_result = sorted_results[sorting_methods[0][0]] is_consistent = True for name, result in sorted_results.items():if result != base_result:is_consistent = Falseprint(f"{name} 的排序结果与基准排序结果不一致")if is_consistent:print("所有排序算法的排序结果一致")# 比较稳定性 # 稳定性定义: 排序后相同元素的相对顺序不变 # 生成包含重复元素的测试数据 test_stability_array = [5, 3, 8, 3, 6] stable_sorts = [] unstable_sorts = []for name, sort_func in sorting_methods:original_array = test_stability_array[:]sorted_array = sort_func(original_array)original_indices = [i for i, x in enumerate(original_array) if x == 3]sorted_indices = [i for i, x in enumerate(sorted_array) if x == 3]if original_indices == sorted_indices:stable_sorts.append(name)else:unstable_sorts.append(name)print("\n稳定的排序算法: ", stable_sorts) print("不稳定的排序算法: ", unstable_sorts)space_complexity = {"冒泡排序": "O(1)","选择排序": "O(1)","插入排序": "O(1)","快速排序": "O(log n) 平均, O(n) 最坏","归并排序": "O(n)","桶排序": "O(n + k) 其中 k 是桶的数量" }print("\n空间复杂度:") for name, complexity in space_complexity.items():print(f"{name}: {complexity}")
四、例题 P3226——宝藏排序Ⅱ
问题描述
注意:这道题于宝藏排序Ⅰ的区别仅是数据范围在一个神秘的岛屿上,有一支探险队发现了一批宝藏,这批宝藏是以整数数组的形式存在的。每个宝藏上都标有一个数字,代表了其珍贵程度。然而,由于某种神奇的力量,这批宝藏的顺序被打乱了,探险队需要将宝藏按照珍贵程度进行排序,以便更好地研究和保护它们。作为探险队的一员,肖恩需要设计合适的排序算法来将宝藏按照珍贵程度进行从小到大排序。请你帮帮肖恩。
输入描述
输入第一行包括一个数字 n ,表示宝藏总共有 n 个。
输入的第二行包括 n 个数字,第 i 个数字 a[i] 表示第 i 个宝藏的珍贵程度。
数据保证 1≤n≤10^5,1≤a[i]≤10^9。
输出描述
输出 n 个数字,为对宝藏按照珍贵程度从小到大排序后的数组。
list.sort():是Python标准库中已经实现好的方法,它是基于优化的C语言代码实现的,内部实现经过了高度优化,以确保在各种情况下都能高效运行。n = int(input()) treasures = list(map(int, input().split()))# 使用Python内置的排序函数进行排序 sorted_treasures = sorted(treasures)for treasure in sorted_treasures:print(treasure, end=" ")
相关文章:
蓝桥杯python基础算法(2-1)——排序
目录 一、排序 二、例题 P3225——宝藏排序Ⅰ 三、各种排序比较 四、例题 P3226——宝藏排序Ⅱ 一、排序 (一)冒泡排序 基本思想:比较相邻的元素,如果顺序错误就把它们交换过来。 (二)选择排序 基本思想…...

【课程笔记】信息隐藏与数字水印
文章总览:YuanDaiMa2048博客文章总览 【课程笔记】信息隐藏与数字水印 信号处理基础知识隐写系统隐写算法性能指标音频信号处理基础数字音频概念人类听觉系统与语音质量评价信息隐藏的原理数字指纹与版权保护盲水印与非盲水印私钥水印与公钥水印信息隐藏的研究层次信息隐藏与数…...

Page Assist实现deepseek离线部署的在线搜索功能
前面文章Mac 基于Ollama 本地部署DeepSeek离线模型 实现了deepseek的离线部署,但是部署完成虽然可以进行问答和交互,也有thinking过程,但是没办法像官方一样进行联网搜索。今天我们介绍一款浏览器插件Page Assist来实现联网搜索,完…...

composeUI中Box 和 Surface的区别
在 Jetpack Compose 中,Box 和 Surface 都是常用的布局组件,但它们的用途和功能有所不同。 Box 组件: 功能:Box 是一个用于将子组件堆叠在一起的布局容器,类似于传统 Android 中的 FrameLayout。用途:适用…...

【LeetCode】5. 贪心算法:买卖股票时机
太久没更了,抽空学习下。 看一道简单题。 class Solution:def maxProfit(self, prices: List[int]) -> int:cost -1profit 0for i in prices:if cost -1:cost icontinueprofit_ i - costif profit_ > profit:profit profit_if cost > i:cost iret…...

MySQL表的CURD
目录 一、Create 1.1单行数据全列插入 1.2多行数据指定列插入 1.3插入否则更新 1.4替换 2.Retrieve 2.1 select列 2.1.1全列查询 2.1.2指定列查询 2.1.3查询字段为表达式 2.1.4为查询结果指定别名 2.1.5结果去重 2.2where条件 2.3结果排序 2.4筛选分页结果 三…...

Java 如何覆盖第三方 jar 包中的类
目录 一、需求描述二、示例描述三、操作步骤四、验证结果五、实现原理 背景: 在我们日常的开发中,经常需要使用第三方的 jar 包,有时候我们会发现第三方的 jar 包中的某一个类有问题,或者我们需要定制化修改其中的逻辑,…...

VSCode中使用EmmyLua插件对Unity的tolua断点调试
一.VSCode中搜索安装EmmyLua插件 二.创建和编辑launch.json文件 初始的launch.json是这样的 手动编辑加上一段内容如下图所示: 三.启动调试模式,并选择附加的进程...
【数据结构】_链表经典算法OJ(力扣/牛客第二弹)
目录 1. 题目1:返回倒数第k个节点 1.1 题目链接及描述 1.2 解题思路 1.3 程序 2. 题目2:链表的回文结构 2.1 题目链接及描述 2.2 解题思路 2.3 程序 1. 题目1:返回倒数第k个节点 1.1 题目链接及描述 题目链接: 面试题 …...

Spring Boot 2 快速教程:WebFlux优缺点及性能分析(四)
WebFlux优缺点 【来源DeepSeek】 Spring WebFlux 是 Spring 框架提供的响应式编程模型,旨在支持非阻塞、异步和高并发的应用场景。其优缺点如下: 优点 高并发与低资源消耗 非阻塞 I/O:基于事件循环模型(如 Netty)&am…...

自定义多功能输入对话框:基于 Qt 打造灵活交互界面
一、引言 在使用 Qt 进行应用程序开发时,我们经常需要与用户进行交互,获取他们输入的各种信息。QInputDialog 是 Qt 提供的一个便捷工具,可用于简单的输入场景,但当需求变得复杂,需要支持更多类型的输入控件࿰…...

基于springboot河南省旅游管理系统
基于Spring Boot的河南省旅游管理系统是一种专为河南省旅游行业设计的信息管理系统,旨在整合和管理河南省的旅游资源信息,为游客提供准确、全面的旅游攻略和服务。以下是对该系统的详细介绍: 一、系统背景与意义 河南省作为中国的中部省份&…...

LabVIEW图像采集与应变场测量系统
开发了一种基于LabVIEW的图像采集与应变场测量系统,提供一种高精度、非接触式的测量技术,用于监测物体的全场位移和应变。系统整合了实时监控、数据记录和自动对焦等功能,适用于工程应用和科学研究。 项目背景 传统的位移和应变测量技术往往…...

CommonAPI学习笔记-2
一. 概述 这篇文章主要是想整理并且分析CommonAPI代码生成工具根据fidl和fdepl配置文件生成出来的代码的结构和作用。 二. fidl 用户根据业务需求在fidl文件中定义业务服务接口的结构以及自定义数据类型,然后使用core生成工具传入fidl文件生成该fidl的核心…...

ISP代理与住宅代理的区别
代理充当用户和互联网之间的中介,在增强安全性、隐私和可访问性方面提供多种功能。在众多代理类型中,ISP和住宅代理脱颖而出,各自拥有不同的功能和应用程序。 一、ISP代理 ISP代理,俗称Internet服务提供商代理,通过其…...

[25] cuda 应用之 nppi 实现图像色彩调整
[25] cuda 应用之 nppi 实现图像色彩调整 在 NPPI(NVIDIA Performance Primitives)中,图像色彩调整通常包括以下几种操作: 亮度调整:增加或减少图像的亮度。对比度调整:增强或减弱图像的对比度。饱和度调整:增强或减弱图像的颜色饱和度。色调调整:改变图像的色调(通常…...

Java 大视界 -- Java 大数据在智慧文旅中的应用与体验优化(74)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

PyTorch快速入门
Anaconda Anaconda 是一款面向科学计算的开源 Python 发行版本,它集成了众多科学计算所需的库、工具和环境管理系统,旨在简化包管理和部署,提升开发与研究效率。 核心组件: Conda:这是 Anaconda 自带的包和环境管理…...

100.7 AI量化面试题:如何利用新闻文本数据构建交易信号?
目录 0. 承前1. 解题思路1.1 数据处理维度1.2 分析模型维度1.3 信号构建维度 2. 新闻数据获取与预处理2.1 数据获取接口2.2 文本预处理 3. 情感分析与事件抽取3.1 情感分析模型3.2 事件抽取 4. 信号生成与优化4.1 信号构建4.2 信号优化 5. 策略实现与回测5.1 策略实现 6. 回答话…...

CF 465B.Inbox (100500)(Java实现)
题目分析 计算读取所有未读邮件所需的步数,其中1代表未读,0代表已读 思路分析 遍历邮件,如果当前是未读,那么所需步数1,如果下一封也是未读,不用管(遍历后会直接1),如果下一封是已读࿰…...

LearningX:构建结构化开发者知识体系,从基础到架构的实践指南
1. 项目概述:一个面向开发者的系统性学习仓库最近在GitHub上看到一个挺有意思的项目,叫“LearningX”。光看名字,你可能会觉得这又是一个普通的“Awesome-XXX”列表,或者是一堆学习资料的简单堆砌。但当我点进去,花了一…...
)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战(含ifconfig与DHCP详解)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战 当你第一次看到QNX Neutrino RTOS的Photon桌面时,那种兴奋感可能很快会被一个现实问题冲淡——这个看起来酷炫的系统怎么连上网?作为实时操作系统领域的标杆,QNX在车载系…...

告别答辩PPT焦虑:百考通AI智能生成,高效搞定毕业答辩全流程
毕业季悄然来临,随着毕业论文定稿,答辩PPT成了不少同学面临的下一个挑战。不懂设计、不会梳理逻辑、找不到合适的学术模板……许多同学花费大量时间在排版调整、修改打磨上,不仅效率低下,还常常做出结构混乱、风格不统一的PPT&…...

桌面CNC木质游戏手柄外壳制作:从Fusion 360设计到实战加工全流程
1. 项目概述:从数字模型到木质手柄的旅程如果你和我一样,既痴迷于复古游戏的怀旧情怀,又享受亲手将数字设计变为实体物件的成就感,那么这个项目绝对能点燃你的热情。我们这次要做的,不是一个简单的3D打印外壳ÿ…...

2026产品经理学数据分析对升职的价值
一、数据分析能力对产品经理升职的重要性数据分析能力已成为产品经理的核心竞争力之一。掌握数据分析技能可以帮助产品经理更精准地决策,提升产品成功率,从而在职业发展中占据优势。二、数据分析在产品经理工作中的具体应用通过数据分析优化产品功能迭代…...

HTTP客户端设计哲学:从axios到hoomanity的易用性演进
1. 项目概述:一个为人类设计的HTTP客户端在构建现代应用程序时,与外部API或服务进行HTTP通信几乎是每个开发者都会遇到的日常任务。无论是调用一个天气接口、上传文件到云存储,还是与自家的微服务进行数据交换,我们都需要一个可靠…...

基于Trinket M0与伺服电机的宠物激光护目镜DIY全攻略
1. 项目概述与核心思路给自家毛孩子做个赛博朋克风的万圣节装备,这个想法在我脑子里盘桓很久了。市面上那些宠物装饰要么千篇一律,要么就是简单的布料缝制,总感觉少了点“硬核”的趣味。直到我看到伺服电机和激光二极管这两个小玩意儿&#x…...

dotAI:将AI能力环境化,打造可配置的智能开发工作流
1. 项目概述:当AI成为你的“数字管家”最近在GitHub上看到一个挺有意思的项目,叫udecode/dotai。乍一看这个标题,你可能和我最初的反应一样,有点摸不着头脑。dotai?是“点AI”的意思吗?它和.env文件那种“点…...

Node.js后端框架Hereetria:平衡灵活性与约定,构建现代化Web应用
1. 项目概述与核心价值 最近在折腾一个挺有意思的开源项目,叫“Hereetria”。这个名字听起来有点陌生,但如果你对构建现代化的、可扩展的Web应用后端架构感兴趣,那它绝对值得你花时间研究一下。简单来说,Hereetria是一个基于Node.…...

基于CircuitPython与ItsyBitsy M4打造可编程宏键盘:从硬件到代码全解析
1. 项目概述:打造你的专属输入利器 在键盘这个看似成熟的领域里,我们真的满足于厂商提供的“标准答案”吗?对于视频剪辑师、程序员、设计师或者硬核游戏玩家来说,一套固定的键位布局和功能,往往意味着效率的妥协。真正…...