【DeepSeek-R1 +1.5B】2060显卡ollama本地部署+open-webui界面使用
https://github.com/open-webui/open-webui
Deepseek开源R1系列模型,纯RL助力推理能力大跃升!
2060显卡下使用deepseek-r1-1.5B
deepseek开源小模型需要的显存(根据显存来选模型大小) ,图from: DeepSeek本地部署,保姆级教程,带你打造最强AI-CSDN博客

ollama官方下载 (可能卡住,往下看)
ollama pull deepseek-r1:1.5b
国内源下载
ollama serve
ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF下载成功

二、类似chatgpt界面使用 (需要先安装python管理软件anaconda)
open-webui
python相关环境安装
conda create -n open-webui python=3.11 -y
激活环境
conda activate open-webui安装open-webui的关键
pip install open-webui -i https://mirrors.aliyun.com/pypi/simple/启动open-webui
open-webui serve启动成功后获得浏览器的ip

类似chatgpt的界面
http://127.0.0.1:8080/

实际测试
扩散模型的原理


给出伪代码

给出的

思维过程可显示

我现在需要理解扩散模型(Diffusion Model)的原理。扩散模型听起来和图像生成有关,可能用于生成高分辨率的图像,比如电影或游戏角色。那它到底是怎么工作的呢?让我一步步来分析。
首先,我记得扩散模型是一种生成式模型,通过某种过程让数据逐渐扩散到中间层,最后在输出层形成最终的图像。这可能涉及到热扩散或者类似物理扩散的过程,但具体细节我不太清楚。
扩散模型通常包括几个步骤:训练和测试阶段。训练的时候,它随机初始化了一些变量,然后按照一定规则逐步“扩散”这些变量,直到它们达到某个平衡状态。这个过程可能类似于机器学习中的损失函数优化,通过调整每个变量的值来最小化某种损失。
让我看看具体是怎么操作的。训练模型时,数据可能会被“扩散”,比如先让低分辨率图像变得更像高分辨率图像。这可能涉及到在中间层进行一些变化或添加,使得最终的结果接近真实图像。这样做的目的是让生成的图像越来越接近真实数据分布。
然后,在测试阶段,模型生成一个新的数据点。这个过程应该和训练阶段类似,只是直接从数据开始扩散,生成新的样本。这样得到的样本可能比训练阶段的数据更接近真实数据,从而作为最终的输出。
我还记得,扩散模型可能使用了神经网络来处理这些变量。在每个步骤中,网络会处理当前的状态,并将其传递到下一个步骤。这可能涉及到一些数学变换或优化过程。
扩散模型的一个关键点是热扩散过程,或者说是基于随机游走的过程。这让我联想到物理中的热扩散,数据是如何逐步被“扩散”到中间层的。每个层次的数据是前面层次的某种函数,通过调整参数来生成最终的图像。
另外,扩散模型可能使用了不同的方法来优化训练过程。比如,他们可能会用概率分布来建模生成的过程,并尝试最小化一个损失函数,这涉及到KL散度等概念。这样可以让生成的结果更接近真实数据分布。
我还不太明白具体是如何进行热扩散的。可能在每个步骤中,数据会被随机扰动或调整,以逐渐趋近于高分辨率图像。这种随机性如何确保最终结果的有效性呢?是不是通过多次模拟来获得一个概率分布,然后取其平均值?
还有一个问题,扩散模型是否涉及到对偶训练方式。也就是说,在训练阶段生成模型的变量,而在测试阶段直接使用这些变量生成新的样本。这可能减少了一些中间步骤的计算负担,同时也能更好地利用数据间的相似性。
我还需要弄清楚扩散模型的具体方程是什么样的。比如,是否有参数θ,使得每个中间层的条件分布p(x_{t}|x_{t+1})或者类似的结构?这样模型就可以通过优化这些参数来调整生成过程,使其逼近真实数据分布。
最后,扩散模型的应用场景有哪些呢?除了生成图像外,可能还有其他如视频生成、音频合成或者其他高分辨率数据的生成。这些应用需要支持的计算资源和算法效率也很重要,所以扩散模型设计时应该考虑如何高效地进行训练和生成过程。
综上所述,扩散模型通过一个从低分辨率到高分辨率的数据扩散过程,使用神经网络来调整参数,并根据概率分布优化生成结果。这样就能在测试阶段生成高质量的高分辨率样本。
附录
下载gguf后导入为ollama格式 (用于无法直接拉,手动加载,有bug,会胡言乱语)
魔搭社区汇聚各领域最先进的机器学习模型,提供模型探索体验、推理、训练、部署和应用的一站式服务。https://modelscope.cn/models/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF![]() https://modelscope.cn/models/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF先安装modelscioe命令
https://modelscope.cn/models/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF先安装modelscioe命令
pip install modelscope
下载 DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf
modelscope download --model unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf --local_dir ./gguf转化为ollama读取形式
创建一个Modelfile文件(无后缀),写入以下内容
FROM ./DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf
转为为ollama模型
ollama create deepseek-r1-qwen-1.5b-Q4_K_M -f Modelfile导入结果

运行
ollama run deepseek-r1-qwen-1.5b-Q4_K_M
相关文章:
【DeepSeek-R1 +1.5B】2060显卡ollama本地部署+open-webui界面使用
https://github.com/open-webui/open-webui Deepseek开源R1系列模型,纯RL助力推理能力大跃升! 2060显卡下使用deepseek-r1-1.5B deepseek开源小模型需要的显存(根据显存来选模型大小) ,图from: DeepSeek本地部署&…...

《翻转组件库之发布》
背景 继《翻转组件库之打包》_杨晓风-linda的博客-CSDN博客之后,组件库已经可以正常构建,那如何像elementUI等组件库那样,用npm安装,按照既定的用法使用即可呢?本篇便为你揭晓 资料相关 1、npm官方文档:…...

在深度学习中,样本不均衡问题是一个常见的挑战,尤其是在你的老虎机任务中,某些的中奖倍数较高
在深度学习中,样本不均衡问题是一个常见的挑战,尤其是在你的老虎机任务中,某些的中奖倍数较高 在深度学习中,样本不均衡问题是一个常见的挑战,尤其是在你的老虎机任务中,某些的中奖倍数较高而其他的中奖倍数较低。这种不均衡会导致模型偏向于高频样本(低中奖倍数的),…...

语言月赛 202311【基因】题解(AC)
》》》点我查看「视频」详解》》》 [语言月赛 202311] 基因 题目描述 有一个长度为 n n n 的字符串 S S S。其只包含有大写字母。 小 A 将 S S S 进行翻转后,得到另一个字符串 S ′ S S′。两个字符串 S S S 与 S ′ S S′ 对应配对。例如说,对…...

unity学习26:用Input接口去监测: 鼠标,键盘,虚拟轴,虚拟按键
目录 1 用Input接口去监测:鼠标,键盘,虚拟轴,虚拟按键 2 鼠标 MouseButton 事件 2.1 鼠标的基本操作 2.2 测试代码 2.3 测试情况 3 键盘Key事件 3.1 键盘的枚举方式 3.2 测试代码同上 3.3 测试代码同上 3.4 测试结果 4…...

GB/T 43698-2024 《网络安全技术 软件供应链安全要求》标准解读
一、43698-2024标准图解 https://mmbiz.qpic.cn/sz_mmbiz_png/rwcfRwCticvgeBPR8TWIPywUP8nGp4IMFwwrxAHMZ9Enfp3wibNxnfichT5zs7rh2FxTZWMxz0je9TZSqQ0lNZ7lQ/640?wx_fmtpng&fromappmsg 标准在线预览: 国家标准|GB/T 43698-2024 相关标准: &a…...

ASP.NET Core与EF Core的集成
目录 分层项目中EF Core的用法 数据库的配置 数据库迁移 步骤汇总 注意: 批量注册上下文 分层项目中EF Core的用法 创建一个.NET类库项目BooksEFCore,放实体等类。NuGet:Microsoft.EntityFrameworkCore.RelationalBooksEFCore中增加实…...

【AI大模型】Ubuntu18.04安装deepseek-r1模型+服务器部署+内网访问
以下内容主要参考博文:DeepSeek火爆全网,官网宕机?本地部署一个随便玩「LLM探索」 - 程序设计实验室 - 博客园 安装 ollama Download Ollama on Linux curl -fsSL https://ollama.com/install.sh | sh 配置 ollama 监听地址 ollama 安装后…...

SpringAI系列 - 使用LangGPT编写高质量的Prompt
目录 一、LangGPT —— 人人都可编写高质量 Prompt二、快速上手2.1 诗人 三、Role 模板3.1 Role 模板3.2 Role 模板使用步骤3.3 更多例子 四、高级用法4.1 变量4.2 命令4.3 Reminder4.4 条件语句4.5 Json or Yaml 方便程序开发 一、LangGPT —— 人人都可编写高质量 Prompt La…...

Github - 记录一次对“不小心包含了密码的PR”的修复
Github - 记录一次对“不小心包含了密码的PR”的修复 前言 和好朋友一起开发一个字节跳动青训营抖音电商后端(now private)的项目,某大佬不小心把本地一密码commit上去并提了PR。 PR一旦发出则无法被删除,且其包含的commit也能被所有能看到这个仓库的…...

【玩转 Postman 接口测试与开发2_014】第11章:测试现成的 API 接口(下)——自动化接口测试脚本实战演练 + 测试集合共享
《API Testing and Development with Postman》最新第二版封面 文章目录 3 接口自动化测试实战3.1 测试环境的改造3.2 对列表查询接口的测试3.3 对查询单个实例的测试3.4 对新增接口的测试3.5 对修改接口的测试3.6 对删除接口的测试 4 测试集合的共享操作4.1 分享 Postman 集合…...
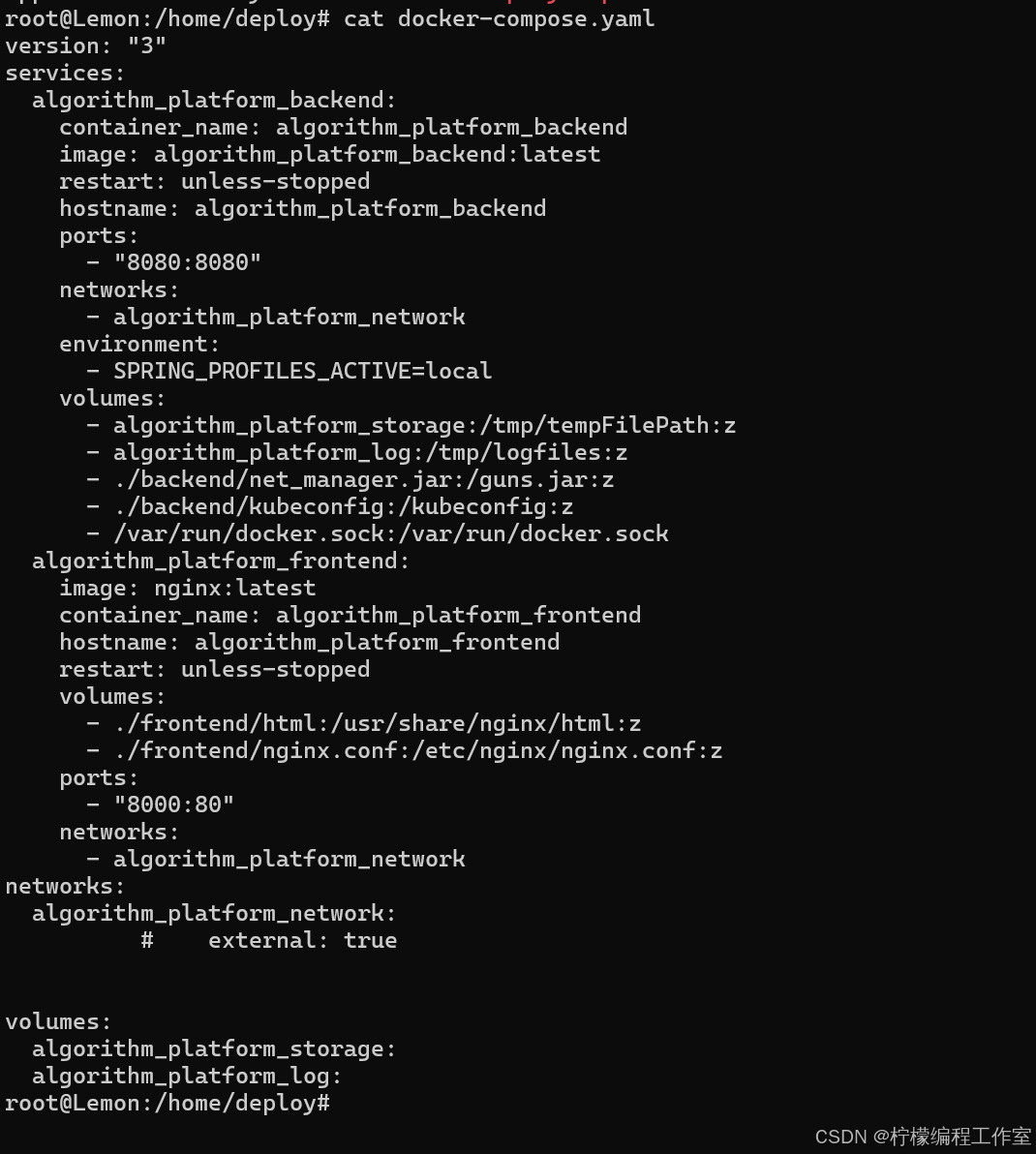
前后端通过docker部署笔记
项目背景:这是一个SpringBootvue3的项目,通过maven打包后,需要在Linux服务器上部署,本篇博客主要记录docker-compose.yaml文件的含义: docker-compose.yml 文件中定义了一个 algorithm_platform_frontend 容器&#…...

五十天精通硬件设计第四天-场效应管知识及选型
场效应管(FET,Field-Effect Transistor)是一种利用电场效应控制电流的半导体器件,广泛应用于放大、开关等电路中。以下是场效应管的基本知识及选型要点: 一、场效应管的基本知识 1. 类型: - **结型场效应管(JFET)**: - N沟道和P沟道两种类型。 - 栅极与…...
)
了解 ALV 中的 field catalog (ABAP List Viewer)
在 ABAP 中,字段目录是使用 ALV (ABAP List Viewer) 定义内部表中的数据显示方式的关键元素。它提供对 ALV 中显示的字段的各种属性的控制,例如列标题、对齐方式、可见性、可编辑性等。关键概念: Field Catelog 字段目…...

【基于SprintBoot+Mybatis+Mysql】电脑商城项目之修改密码和个人资料
🧸安清h:个人主页 🎥个人专栏:【Spring篇】【计算机网络】【Mybatis篇】 🚦作者简介:一个有趣爱睡觉的intp,期待和更多人分享自己所学知识的真诚大学生。 目录 🎃1.修改密码 -持久…...

十一、CentOS Stream 9 安装 Docker
一、Docker 环境安装 1、软件源(仓库)信息 使用如下命令可列出当前系统配置的所有软件源(仓库)信息 # 列出所有软件源 dnf repolist 这表明系统有三个仓库 AppStream 、 BaseOS、Extras-Common 被启用 2、配置软件源镜像 使用如下命令可配置 Docker 软件包下载的镜像地址 …...

FreeRTOS学习 --- 中断管理
什么是中断? 让CPU打断正常运行的程序,转而去处理紧急的事件(程序),就叫中断 中断执行机制,可简单概括为三步: 1,中断请求 外设产生中断请求(GPIO外部中断、定时器中断…...

如何在Intellij IDEA中识别一个文件夹下的多个Maven module?
目录 问题描述 理想情况 手动添加Module,配置Intellij IDEA的Project Structure 问题描述 一个文件夹下有多个Maven项目,一个一个开窗口打开可行但是太麻烦。直接open整个文件夹会发现Intellij IDEA默认可能就识别一个或者几个Maven项目,如…...

机器学习模型--线性回归、逻辑回归、分类
一、线性回归 级别1:简单一元线性回归(手工实现) import numpy as np import matplotlib.pyplot as plt# 生成数据 X np.array([1, 2, 3, 4, 5]) y np.array([2, 4, 5, 4, 5])# 手动实现梯度下降 def gradient_descent(X, y, lr0.01, epo…...

gitlab个别服务无法启动可能原因
目录 一、gitlab的puma服务一直重启 1. 查看日志 2. 检查配置文件 3. 重新配置和重启 GitLab 4. 检查系统资源 5. 检查依赖和服务状态 6. 清理和优化 7. 升级 GitLab 8. 查看社区和文档 二、 gitlab个别服务无法启动可能原因 1.服务器内存或磁盘已满 2.puma端口冲突…...

国内热门的广州租车工厂哪个好
在广州,租车需求日益增长,如何选择一家靠谱的租车工厂成为众多消费者关心的问题。今天,就为大家介绍一家热门的租车企业——广州市白驹旅游汽车有限公司(简称白驹旅汽),并与其他大厂进行对比分析。车辆保障…...

专业解析开源AI浏览器助手:Page Assist的深度技术架构与实战应用
专业解析开源AI浏览器助手:Page Assist的深度技术架构与实战应用 【免费下载链接】page-assist Use your locally running AI models to assist you in your web browsing 项目地址: https://gitcode.com/GitHub_Trending/pa/page-assist Page Assist是一款革…...

TSL2561高精度光照传感器在可穿戴设备中的集成与应用指南
1. 项目概述:为可穿戴设备注入“视觉”在智能硬件和物联网项目里,让设备“看见”环境光,是实现人机环境智能交互的第一步。无论是根据环境亮度自动调节屏幕的智能手表,还是能感知昼夜变化自动调整工作模式的园艺监测设备ÿ…...
)
LabelImg标注的YOLO格式txt坐标转换保姆级教程(附Python代码)
LabelImg标注的YOLO格式坐标转换实战指南:从原理到Python实现 在计算机视觉项目中,数据标注是模型训练前的关键步骤。LabelImg作为一款开源的图像标注工具,支持生成YOLO格式的标注文件。然而,许多开发者在实际应用中发现ÿ…...
的模板化部署)
统信UOS系统管理员必看:一招搞定用户配置文件(.config/autostart)的模板化部署
统信UOS系统配置模板化实战:从屏保设置到全局用户环境部署 在大型企业或教育机构的桌面环境管理中,统信UOS作为国产操作系统的代表,其标准化部署能力直接影响运维效率。当我们在模板用户中精心配置了各项参数——从屏幕保护时间到电源管理策略…...
怎么选,告别‘卖家秀’惨案)
从LED灯珠到手机屏幕:一文搞懂色温、显色指数(CRI)怎么选,告别‘卖家秀’惨案
从LED灯珠到手机屏幕:色温与显色指数的科学选购指南 深夜伏案工作时,你是否总觉得眼睛干涩疲劳?网购衣物到手后颜色总与屏幕显示相差甚远?餐厅美食拍出来总是暗淡无光?这些困扰的根源往往在于——光源质量。当我们面对…...

LeaderKey.app开发者指南:深入源码解析架构设计
LeaderKey.app开发者指南:深入源码解析架构设计 【免费下载链接】LeaderKey The *faster than your launcher* launcher 项目地址: https://gitcode.com/gh_mirrors/le/LeaderKey LeaderKey.app是一款轻量级启动器应用,以"比你的启动器更快&…...

在多模型AI应用开发中利用Taotoken实现成本与性能的平衡
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型AI应用开发中利用Taotoken实现成本与性能的平衡 开发一个复杂的AI应用,往往意味着需要调用多个模型来完成不同…...
 终极指南:显卡驱动彻底清理解决方案)
Display Driver Uninstaller (DDU) 终极指南:显卡驱动彻底清理解决方案
Display Driver Uninstaller (DDU) 终极指南:显卡驱动彻底清理解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-driv…...

C++二叉树控制台可视化:从递归布局到层序遍历的图形化实现
1. 项目概述:为什么我们需要“看见”二叉树?在C的学习和数据结构实践中,二叉树是一个绕不开的核心概念。我们经常需要实现它的插入、删除、遍历等操作。然而,无论是调试一个复杂的平衡算法,还是向他人展示你的数据结构…...