DeepSeek图解10页PDF
以前一直在关注国内外的一些AI工具,包括文本型、图像类的一些AI实践,最近DeepSeek突然爆火,从互联网收集一些资料与大家一起分享学习。
本章节分享的文件为网上流传的DeepSeek图解10页PDF,免费附件链接给出。
 1 本地
1 本地
1 本地部署并运行DeepSeek
1.1 为什么要在本地部署DeepSeek
在本地搭建大模型(如DeepSeek)具有多个重要的优势,比如:
1. 保护隐私与数据安全。数据不外传:本地运行模型可以完全避免数据上传至云端,确保敏感信息不被第三方访问。
2. 可定制化与优化。支持微调(Fine-tuning):可以根据特定业务需求对模型进行微调,以适应特定任务,如行业术语、企业内部知识库等。
3. 离线运行,适用于无网络环境。可在离线环境下运行:适用于无互联网连接或网络受限的场景。提高系统稳定性:即使云服务宕机,本地大模型依然可以正常工作,不受外部因素影响。

1.2 DeepSeek 本地部署三个步骤
一共只需要三步,就能做到DeepSeek 在本地运行并与它对话。
第一步,使用的是ollama 管理各种不同大模型,ollama 比较直接、干净,一键下载后安装就行,安装过程基本都是下一步。
Ollama的官网下载地址:Ollama
支持macos、windows、linux多端的安装包管理
Ollama windows安装_ollama 下载-CSDN博客安装windows下的ollama可以参考以上链接写的较为详细:Ollama windows安装_ollama 下载-CSDN博客
安装后,打开命令窗口,输入ollama,然后就能看到它的相关指令,一共10 个左右的命令,如下图2所示,就能帮我们管理好不同大模型:

第二步,命令窗口输入:ollama pull deepseek-r1:1.5b,下载大模型deepseekr1到我们自己的电脑,如下图3所示:

至此在我们本地电脑,DeepSeek 大模型就下载到我们本地电脑,接下来第三步就可以直接使用和它对话了。在cmd(Windows 电脑) 或terminal(苹果电脑) 执行命令:ollama run deepseek-r1:1.5b,很快就能进入对话界面,如下图4所示:

1.3 DeepSeek 本地运行使用演示
基于上面步骤搭建完成后,接下来提问DeepSeek 一个问题:请帮我分析Python 编程如何从零开始学习?,下面是它的回答,首先会有一个think标签,这里面嵌入的是它的思考过程,不是正式的回复:

等我们看到另一个结束标签think 后,表明它的思考已经结束,下面一行就是正式回答,如下图6所示:
 2 DeepSeek 零基础必知
2 DeepSeek 零基础必知
为了更深入理解DeepSeek-R1,首先需要掌握LLM 的基础知识,包括其工作原理、架构、训练方法。
近年来,人工智能(AI)技术的快速发展催生了大型语言模型((LargeLanguage Model, LLM))的兴起。LLM 在自然语言处理(NLP)领域发挥着越来越重要的作用,广泛应用于智能问答、文本生成、代码编写、机器翻译等任务。LLM 是一种基于深度学习的人工智能模型,其核心目标是通过预测下一个单词来理解和生成自然语言。训练LLM 需要大量的文本数据,使其能够掌握复杂的语言模式并应用于不同任务。接下来,咱们先从较为基础的概念开始。
2.1 LLM 基础概念
模型参数。其中比较重要的比如deepseek-r1:1.5b, qwen:7b, llama:8b,这里的1.5b, 7b、8b 代表什么?b 是英文的billion,意思是十亿,7b 就是70 亿,8b 就是80 亿,70 亿、80 亿是指大模型的神经元参数(权重参数weight+bias)的总量。目前大模型都是基于Transformer 架构,并且是很多层的Transformer结构,最后还有全连接层等,所有参数加起来70 亿,80 亿,还有的上千亿。
通用性更强。大模型和我们自己基于某个特定数据集(如ImageNet、20News-Group)训练的模型在本质上存在一些重要区别。主要区别之一,大模型更加通用,这是因为它们基于大量多样化的数据集进行训练,涵盖了不同领域和任务的数据。这种广泛的学习使得大模型具备了较强的知识迁移能力和多任务处理能力,从而展现出“无所不知、无所不晓”的特性。相比之下,我们基于单一数据集训练的模型通常具有较强的针对性,但其知识范围仅限于该数据集的领域或问题。因此,这类模型的应用范围较为局限,通常只能解决特定领域或单一任务的问题。Scaling Laws 大家可能在很多场合都见到过。它是一个什么法则呢?大模型之所以能基于大量多样化的数据集进行训练,并最终“学得好”,核心原因之一是Scaling Laws(扩展规律)的指导和模型自身架构的优势。Scaling Laws 指出参数越多,模型学习能力越强;训练数据规模越大、越多元化,模型最后就会越通用;即使包括噪声数据,模型仍能通过扩展规律提取出通用的知识。而Transformer 这种架构正好完美做到了Scaling Laws,Transformer 就是自然语言处理领域实现扩展规律的最好的网络结构。亿。
Scaling Laws 大家可能在很多场合都见到过。它是一个什么法则呢?大模型之所以能基于大量多样化的数据集进行训练,并最终“学得好”,核心原因之一是Scaling Laws(扩展规律)的指导和模型自身架构的优势。Scaling Laws 指出参数越多,模型学习能力越强;训练数据规模越大、越多元化,模型最后就会越通用;即使包括噪声数据,模型仍能通过扩展规律提取出通用的知识。而Transformer 这种架构正好完美做到了Scaling Laws,Transformer 就是自然语言处理领域实现扩展规律的最好的网络结构。
2.2 Transformer 基础架构
LLM 依赖于2017 年Google 提出的Transformer 模型,该架构相比传统的RNN(递归神经网络)和LSTM(长短时记忆网络)具有更高的训练效率和更强的长距离依赖建模能力。Transformer 由多个关键组件组成:1. 自注意力机制(Self-Attention):模型在处理文本时,会自动关注句子中的重要单词,理解不同词语间的联系。2. 多头注意力(Multi-Head Attention):使用多个注意力头同时分析不同的语义信息,使得模型的理解能力更强。3. 前馈神经网络(FFN):非线性变换模块,提升模型的表达能力。4. 位置编码(Positional Encoding):在没有循环结构的情况下,帮助模型理解单词的顺序信息。

2.3 LLM 基本训练方法
2.3.1 预训练(Pretraining)
LLM 训练通常采用大规模无监督学习,即:1. 从互联网上收集大量文本数据,如书籍、新闻、社交媒体等。2. 让模型学习词语之间的概率分布,理解句子结构。3. 训练目标是最小化预测误差,使其能更好地完成语言任务。
2.3.2 监督微调(Supervised Fine-Tuning, SFT)
在预训练之后,通常需要对模型进行监督微调(SFT):使用人工标注的数
据集,让模型在特定任务上优化表现。调整参数,使其更符合人类需求,如
问答、对话生成等任务。
2.3.3 强化学习(Reinforcement Learning, RL)
采用强化学习(RL)方法进行优化,主要通过人类反馈强化学习(RLHF,
Reinforcement Learning from Human Feedback):

3 DeepSeek-R1 精华图解
3.1 DeepSeek-R1 完整训练过程
DeepSeek-R1 主要亮点在于出色的数学和逻辑推理能力,区别于一般的通用AI 模型。其训练方式结合了强化学习(RL)与监督微调(SFT),创造了一种高效训练,高推理能力AI 模型的方法。
整个训练过程分为核心两阶段,第一步训练基于DeepSeek-V3 论文中的基础模型(而非最终版本),并经历了SFT 和基于纯强化学习调优+ 通用性偏好调整,如下图7所示:

训练起点。DeepSeek-R1 的训练起点是DeepSeek-v3-Base,作为基础模型进行训练,为后续的推理优化奠定基础。
3.1.1 核心创新1:含R1-Zero 的中间推理模型
如图7所示,推理导向的强化学习(Reasoning-Oriented Reinforcement Learning) 得到中间推理模型(Iterim reasoning model), 图8会详细解释中间模 型的训练过程
DeepSeek-R1 核心贡献:首次验证了通过纯强化学习也能大幅提升大模
型推理能力,开源纯强化学习推理模型DeepSeek-R1-Zero
R1-Zero 能生成高质量的推理数据,包括大量长链式思维(Chain-of-Thought,CoT)示例,用于支持后续的SFT 阶段,如图7所示。更加详细介绍参考3.2节。
3.1.2 核心创新2:通用强化学习
第一阶段R1-Zero 虽然展现出惊人的推理能力提升,但是也出现了回复时语言混合,非推理任务回复效果差的问题,为了解决这些问题,DeepSeek提出通用强化学习训练框架。如图7所示,通用强化学习(General Reinforcement Learning)基于SFTcheckpoint,模型进行通用强化学习(RL)训练,优化其在推理任务和其他通用任务上的表现。更加详细介绍参考3.3节。
3.2 含R1-Zero 的中间推理模型训练过程
中间模型占据主要训练精力的阶段,实际上完全通过推理导向的强化学习直接训练而成,完全跳过了监督微调(SFT),如下图8所示,只在强化学习的冷启动阶段使用了SFT

大规模推理导向的强化学习训练,必不可少的就是推理数据,手动标注就太繁琐了,成本昂贵,所以DeepSeek 团队为了解决这个问题,训了一个R1-Zero 模型,这是核心创新。R1-Zero 完全跳过SFT(监督微调)阶段,直接使用强化学习训练,如下图9所示,基于V3,直接使用强化学习开训:

这样做竟然达到了惊人的、意想不到的效果,推理超越OpenAI O1,如下图10所示,蓝线表示单次推理(pass@1)的准确率,红线表示16 次推理取一致性结果(cons@16)的准确率,可以看出一致性推理提高了最终性能。虚线代表OpenAI O1 的基准表现,图中可以看到DeepSeek-R1-Zero 的性能逐步接近甚至超越了OpenAI O1.

中间模型虽然推理能力很强,但存在可读性和多任务能力不足的问题,所以
才有了第二个创新。
3.3 通用强化学习训练过程
最终偏好调整(Preference Tuning),如下图11所示。通用强化学习训练过程后,使得R1 不仅在推理任务中表现卓越,同时在非推理任务中也表现出色。但由于其能力拓展至非推理类应用,因此在这些应用中引入了帮助性(helpfulness)和安全性(safety)奖励模型(类似于Llama 模型),以优化与这些应用相关的提示处理能力。
DeepSeek-R1 是训练流程的终点,结合了R1-Zero 的推理能力和通用强化学习的任务适应能力,成为一个兼具强推理和通用能力的高效AI 模型。

3.4 总结DeepSeek-R1
中间推理模型生成:通过推理导向的强化学习(Reasoning-Oriented RL),直接生成高质量的推理数据(CoT 示例),减少人工标注依赖。通用强化学习优化:基于帮助性和安全性奖励模型,优化推理与非推理任务表现,构建通用性强的模型。最终,DeepSeek-R1 将R1-Zero 的推理能力与通用强化学习的适应能力相结合,成为一个兼具强推理能力和任务广泛适应性的高效AI 模型。

相关文章:
DeepSeek图解10页PDF
以前一直在关注国内外的一些AI工具,包括文本型、图像类的一些AI实践,最近DeepSeek突然爆火,从互联网收集一些资料与大家一起分享学习。 本章节分享的文件为网上流传的DeepSeek图解10页PDF,免费附件链接给出。 1 本地 1 本地部…...

Centos7 停止维护,docker 安装
安装docker报错 执行docker安装命令:sudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin,出现如下错误 更换yum源 [rootlocalhost yum.repos.d]# sudo mv /etc/yum.repos.d/CentOS-Base.repo /et…...

日志级别修改不慎引发的一场CPU灾难
背景 今天下午16.28有同事通过日志配置平台将某线上应用部分包的日志等级由error调为info,进而导致部分机器CPU升高,甚至有机器CPU达到100%,且ygc次数增加,耗时增加到80~100ms。 故障发现与排查 16.28陆续出现线上C…...

FPGA实现SDI视频缩放转UltraScale GTH光口传输,基于GS2971+Aurora 8b/10b编解码架构,提供2套工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目我这里已有的 GT 高速接口解决方案本博已有的 SDI 编解码方案我这里已有的FPGA图像缩放方案 3、工程详细设计方案工程设计原理框图SDI 输入设备GS2971芯片BT1120转RGB…...

二级C语言题解:矩阵主、反对角线元素之和,二分法求方程根,处理字符串中 * 号
目录 一、程序填空📝 --- 矩阵主、反对角线元素之和 题目📃 分析🧐 二、程序修改🛠️ --- 二分法求方程根 题目📃 分析🧐 三、程序设计💻 --- 处理字符串中 * 号 题目…...

利用 Python 爬虫获取按关键字搜索淘宝商品的完整指南
在电商数据分析和市场研究中,获取商品的详细信息是至关重要的一步。淘宝作为中国最大的电商平台之一,提供了丰富的商品数据。通过 Python 爬虫技术,我们可以高效地获取按关键字搜索的淘宝商品信息。本文将详细介绍如何利用 Python 爬虫技术获…...

什么是幂等性
幂等性(Idempotence)是一个在数学、计算机科学等多个领域都有重要应用的概念,下面从不同领域为你详细介绍其含义。 数学领域 在数学中,幂等性是指一个操作或函数进行多次相同的运算,其结果始终与进行一次运算的结果相…...
群晖NAS如何通过WebDAV和内网穿透实现Joplin笔记远程同步
文章目录 前言1. 检查群晖Webdav 服务2. 本地局域网IP同步测试3. 群晖安装Cpolar工具4. 创建Webdav公网地址5. Joplin连接WebDav6. 固定Webdav公网地址7. 公网环境连接测试 前言 在数字化浪潮的推动下,笔记应用已成为我们记录生活、整理思绪的重要工具。Joplin&…...

示例:JAVA调用deepseek
近日,国产AI DeepSeek在中国、美国的科技圈受到广泛关注,甚至被认为是大模型行业的最大“黑马”。在外网,DeepSeek被不少人称为“神秘的东方力量”。1月27日,DeepSeek应用登顶苹果美国地区应用商店免费APP下载排行榜,在…...

【提示工程】:如何有效与大语言模型互动
随着人工智能技术的快速发展,大语言模型(LLM)如 GPT 系列在各类任务中的应用越来越广泛。从文本生成到代码编写,从数据分析到内容创作,这些模型展现出了强大的能力。然而,要充分发挥大语言模型的潜力,关键在于如何设计高质量的提示词(Prompts)。这门技术被称为提示工程…...

操作系统—经典同步问题
补充 互斥信号量mutex初值均为1 同步信号量根据问题实际描述自己设计 生产者-消费者问题 问题描述:一组生产者进程和一组消费者进程 共享一个初始为空、大小为n的缓冲区。(缓冲区:临界资源) 只有缓冲区没满时,生产者…...

profinet工业通信协议网关:提升钢铁冶炼智能制造效率的利器
工业通信协议网关profinet转ethercat(稳联技术WL-PN-ECATM)在钢铁冶炼生产线中的智能应用实践 在现代钢铁冶炼生产中,复杂的设备互联和数据传输对生产效率和质量控制至关重要。本案例详细阐述了某大型钢铁集团通过工业通信协议网关实现生产线…...
)
Vue基础:计算属性(描述依赖响应式状态的复杂逻辑)
文章目录 引言computed() 方法期望接收一个 getter 函数可写计算属性:计算属性的 Setter计算属性的缓存机制调试 Computed引言 推荐使用计算属性来描述依赖响应式状态的复杂逻辑 computed 函数:它接受 getter 函数并为 getter 返回的值返回一个不可变的响应式 ref 对象。 c…...
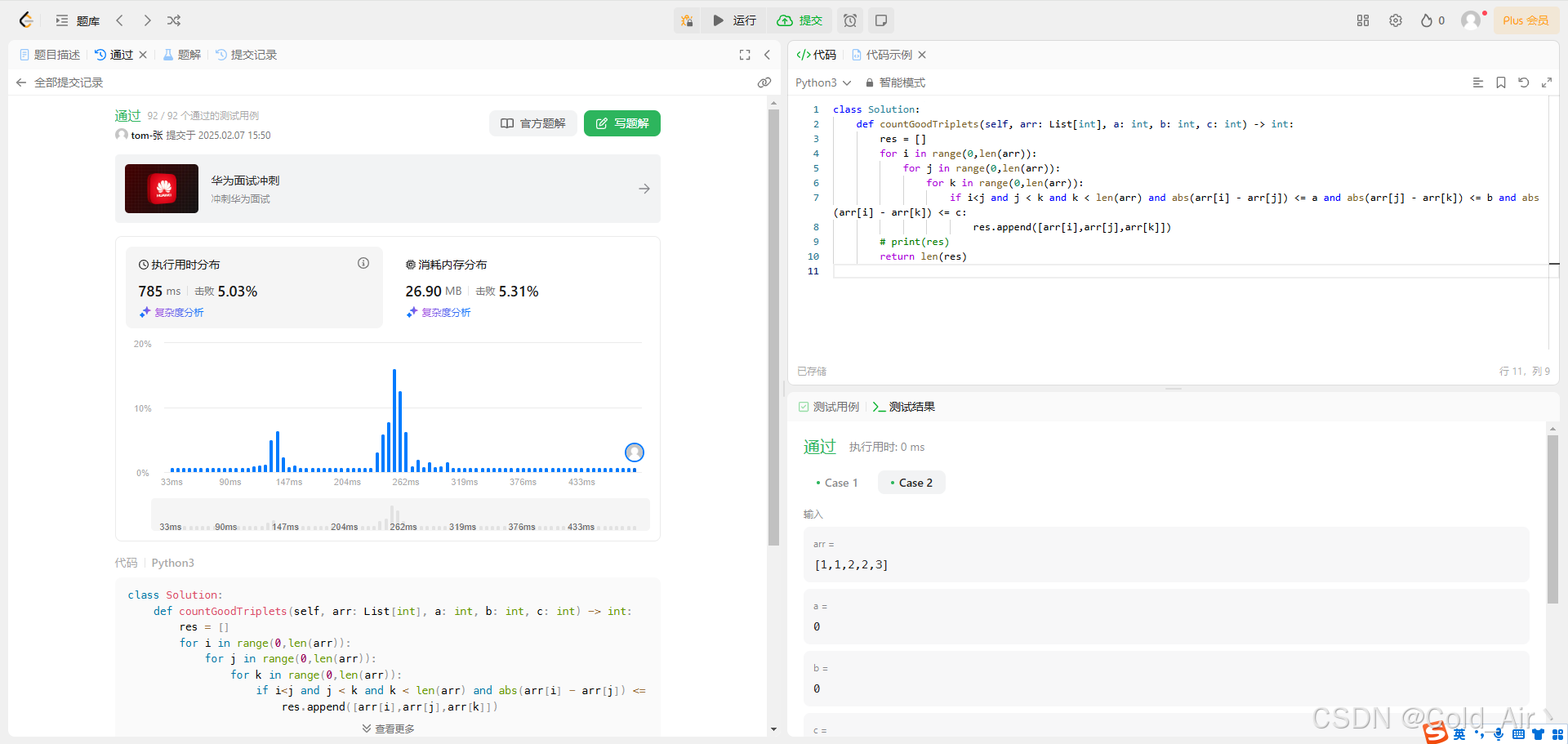
leetcode:1534. 统计好三元组(python3解法)
难度:简单 给你一个整数数组 arr ,以及 a、b 、c 三个整数。请你统计其中好三元组的数量。 如果三元组 (arr[i], arr[j], arr[k]) 满足下列全部条件,则认为它是一个 好三元组 。 0 < i < j < k < arr.length|arr[i] - arr[j]| &l…...

BUU27 [SUCTF 2019]CheckIn1
题目是上传文件 直接上传muma.jpg还不成功: 好吧,那做一个图片马上去,换马以后发现还是不行,呃啊啊啊啊 干啥啥不行,搜wp第一名,哎 新面孔:exif_imagetype 函数在 PHP 中用于检测一个文件是否为…...

unity学习30:Audio Source, Audio clip 音效和音乐
目录 1 音乐相关必须要有 Audio listener 和Source 2 Scene里必须要有 Audio listener 3 Audio Source 3.1 Audio Source 就是音源,可播放的音乐clip 分类 3.2 创建Audio Source 3.3 各种属性 3.4 3D sound Settings 4 使用脚本来播放声音 4.1 声明AudioC…...

【Qt 常用控件】输入类控件1(QLineEdit和QTextEdit 输入框)
目录 1.QLineEdit 单行输入框 例:输入个人信息,通过按钮提交 例:为输入框设置验证器,检查输入的电话 例:验证两次输入的密码是否一致 例:是否显示密码按钮,toggled信号。 2.QTextEdit多行输入框 、QPl…...

openEuler22.03LTS系统升级docker至26.1.4以支持启用ip6tables功能
本文记录了openEuler22.03LTS将docker升级由18.09.0升级至26.1.4的过程(当前docker最新版本为27.5.1,生产环境为保障稳定性,选择升级到上一个大版本26的最新小版本)。 一、现有环境 1、系统版本 [rootlocalhost opt]# cat /etc…...

深入解析:如何利用 Java 爬虫按关键字搜索淘宝商品
在电商领域,通过关键字搜索商品是常见的需求。无论是商家分析竞争对手,还是消费者寻找心仪的商品,获取搜索结果中的商品信息都至关重要。本文将详细介绍如何利用 Java 爬虫按关键字搜索淘宝商品,并提供完整的代码示例。 一、Java…...

STM32上部署AI的两个实用软件——Nanoedge AI Studio和STM32Cube AI
1 引言 STM32 微控制器在嵌入式领域应用广泛,因为它性能不错、功耗低,还有丰富的外设,像工业控制、智能家居、物联网这些场景都能看到它的身影。与此同时,人工智能技术发展迅速,也逐渐融入各个行业。 把 AI 部署到 STM…...

8255 Boot流程深度解析与Bring Up实战避坑指南
1. 8255芯片启动流程全景解析 第一次拿到8255芯片开发板时,最让我困惑的就是这个"安全岛"架构的启动流程。和传统芯片不同,8255的启动更像是一场精心编排的交响乐,SAIL(安全岛)、APPS(应用处理器…...

把旧路由器变成全能开发板:OpenWrt安装ADB、Python3和FFmpeg,远程调试手机还能玩推流
旧路由器改造指南:打造OpenWrt全能开发平台 在科技快速迭代的今天,路由器更新换代的速度远超实际需求。许多家庭和企业都堆积着性能过剩的旧路由器,它们往往被束之高阁或直接丢弃。然而,这些被淘汰的设备实际上隐藏着巨大的潜力—…...

SysML v2系统建模语言:2025年模型驱动系统工程实战指南
SysML v2系统建模语言:2025年模型驱动系统工程实战指南 【免费下载链接】SysML-v2-Release The latest incremental release of SysML v2. Start here. 项目地址: https://gitcode.com/gh_mirrors/sy/SysML-v2-Release SysML v2系统建模语言作为新一代系统工…...

别再死记硬背了!用‘配对’思想图解二次剩余,5分钟理解勒让德符号
用配对游戏破解二次剩余:勒让德符号的视觉化理解指南 数论中那些看似晦涩的概念,往往只需要换个角度就能豁然开朗。想象你手里有一副特殊的扑克牌,每张牌代表一个数字,而你要玩的游戏是找到那些能完美配对的数字——这就是理解二次…...

SystemVerilog中logic数据类型:统一reg与wire的设计实践
1. 项目概述:从“reg”到“logic”的思维跃迁如果你写过Verilog,那么对reg和wire这两个数据类型一定再熟悉不过了。在RTL设计的世界里,我们习惯了用reg来描述寄存器,用wire来描述连线,这几乎成了一种肌肉记忆。但当你开…...

Android Studio中文界面解决方案:从语言障碍到开发效率提升
Android Studio中文界面解决方案:从语言障碍到开发效率提升 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 当你在And…...

设计程序统计共享单车使用分布数据,优化投放点位,解决市民短途出行找不到车辆出行难题。
构建一个共享单车使用分布统计与投放点位优化的商务智能示例项目,去营销化、中立化,仅用于学习与工程实践参考。一、实际应用场景描述在城市短途出行场景中,共享单车已成为重要补充:- 覆盖公交、地铁“最后一公里”- 解决 1–3 公…...

基于LoRA与SFT技术构建中文大语言模型:从词表扩展到指令微调实战
1. 项目概述:为什么我们需要中文专属的大语言模型底座? 如果你在过去一年里尝试过用开源的大语言模型(LLM)来处理中文任务,大概率会遇到过这样的尴尬:模型对英文指令理解得很好,但一换成中文&am…...
)
从聊天到拿Shell:一个Netcat命令的‘黑白’两面实战指南(含正向/反向Shell演示)
从聊天到拿Shell:Netcat命令的双面实战手册 在网络安全领域,很少有工具能像Netcat这样同时扮演"天使"与"恶魔"的双重角色。这个被称为"网络瑞士军刀"的轻量级工具,既能帮助管理员快速排查网络问题,…...

SkillZero:零样本AI智能体的分层规划与工具调用实战解析
1. 项目概述:从“零技能”到“零样本”的智能体进化最近在开源社区里,一个名为“SkillZero”的项目引起了我的注意。它来自浙江大学REAL实验室,名字本身就很有意思——“技能为零”。乍一听,这似乎是个悖论,一个智能体…...