Python分享20个Excel自动化脚本
在数据处理和分析的过程中,Excel文件是我们日常工作中常见的格式。通过Python,我们可以实现对Excel文件的各种自动化操作,提高工作效率。
本文将分享20个实用的Excel自动化脚本,以帮助新手小白更轻松地掌握这些技能。
1. Excel单元格批量填充
import pandas as pd # 批量填充指定列的单元格
def fill_column(file_path, column_name, value): df = pd.read_excel(file_path) df[column_name] = value # 将指定列的所有单元格填充为value df.to_excel(file_path, index=False) fill_column('example.xlsx', '备注', '已处理')
print("备注列已成功填充!")
解释
此脚本将example.xlsx中的“备注”列全部填充为“已处理”。对于普通用户来说,处理大量数据时常需要对某一列进行统一标记,这个功能就显得尤为重要。
2. 设置行高与列宽
from openpyxl import load_workbook # 设置Excel的行高与列宽
def set_row_column_size(file_path): wb = load_workbook(file_path) ws = wb.active # 设置第一行行高、第一列列宽 ws.row_dimensions[1].height = 30 # 设置行高 ws.column_dimensions['A'].width = 20 # 设置列宽 wb.save(file_path) set_row_column_size('example.xlsx')
print("行高和列宽设置成功!")
解释
这个脚本为Excel文件设置了第一行的行高和第一列的列宽。适当调整行高和列宽可以提高表格的可读性,尤其是在内容较多或较复杂时,使用此功能可以使报告更加美观易读。
3. 根据条件删除行
# 根据条件删除Excel中的行
def delete_rows_based_on_condition(file_path, column_name, condition): df = pd.read_excel(file_path) df = df[df[column_name] != condition] # 删除满足条件的行 df.to_excel(file_path, index=False) delete_rows_based_on_condition('example.xlsx', '状态', '无效')
print("符合条件的行已删除!")
解释
该脚本从Excel中删除“状态”列中值为“无效”的行。这种操作在数据清理过程中非常常见,有助于减少数据集中的噪声,提高数据分析的准确性。
4. 创建新的Excel工作表
# 在现有Excel文件中创建新的工作表
def create_new_sheet(file_path, sheet_name): wb = load_workbook(file_path) wb.create_sheet(title=sheet_name) # 创建新的工作表 wb.save(file_path) create_new_sheet('example.xlsx', '新工作表')
print("新工作表创建成功!")
解释
该脚本在已有的Excel文件中创建一个新的工作表。这对于组织数据,分开不同任务或项目的数据非常有用,保持文件结构的清晰。
5. 导入CSV文件到Excel
# 将CSV文件导入到Excel工作表
def import_csv_to_excel(csv_file, excel_file): df = pd.read_csv(csv_file) df.to_excel(excel_file, index=False) import_csv_to_excel('data.csv', 'imported_data.xlsx')
print("CSV文件成功导入到Excel!")
解释
这个脚本将CSV文件导入到Excel中。很多时候,数据是以CSV格式提供的,通过该脚本可以方便地将其转换为Excel格式,便于后续分析和处理。
6. 数据透视表生成
# 生成数据透视表并保存到新的Excel文件
def generate_pivot_table(file_path, index_column, values_column, output_file): df = pd.read_excel(file_path) pivot_table = df.pivot_table(index=index_column, values=values_column, aggfunc='sum') # 汇总 pivot_table.to_excel(output_file) generate_pivot_table('sales_data.xlsx', '地区', '销售额', 'pivot_output.xlsx')
print("透视表生成成功!")
解释
该脚本根据给定的“地区”和“销售额”列生成汇总透视表,并保存到新文件中。在进行业务分析时,透视表能快速展示不同维度下的数据总结。
7. 格式化Excel
from openpyxl.styles import Font, Color # 设置Excel单元格字体样式
def format_cells(file_path): wb = load_workbook(file_path) ws = wb.active for cell in ws['A']: # 遍历A列 cell.font = Font(bold=True, color="FF0000") # 设置字体加粗和红色 wb.save(file_path) format_cells('example.xlsx')
print("单元格格式化成功!")
解释
该脚本将example.xlsx中的A列字体设置为加粗和红色。这种格式化通常用于强调特定数据,使报告更具视觉吸引力。
8. 分析并输出描述性统计
# 输出描述性统计到Excel
def descriptive_statistics(file_path, output_file): df = pd.read_excel(file_path) stats = df.describe() # 计算描述性统计 stats.to_excel(output_file) descriptive_statistics('example.xlsx', 'statistics_output.xlsx')
print("描述性统计输出成功!")
解释
该脚本计算Excel文件的描述性统计信息(如均值、标准差等),并将结果保存到新的Excel文件中。这对于了解数据的基本特征非常重要,尤其在数据分析前期阶段。
9. 批量修改Excel文件名称
import os # 批量重命名指定目录下的Excel文件
def rename_excel_files(directory, prefix): for filename in os.listdir(directory): if filename.endswith('.xlsx'): new_name = f"{prefix}_{filename}" os.rename(os.path.join(directory, filename), os.path.join(directory, new_name)) print(f"已将 {filename} 重命名为 {new_name}") rename_excel_files('/path/to/excel/files', '2024')
解释
该脚本批量重命名指定目录中的所有Excel文件,在每个文件名前面添加一个前缀。对于需要处理大量Excel文件的用户来说,这种批量操作非常便利,比如根据年份或项目为文件命名,以便于管理和归档。
10. 自动发送包含Excel数据的电子邮件
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.application import MIMEApplication
from email.mime.text import MIMEText # 自动发送带有Excel附件的电子邮件
def send_email(to_address, subject, body, excel_file): from_address = "your_email@example.com" password = "your_password" msg = MIMEMultipart() msg['From'] = from_address msg['To'] = to_address msg['Subject'] = subject # 添加正文 msg.attach(MIMEText(body, 'plain')) # 添加Excel附件 with open(excel_file, "rb") as attachment: part = MIMEApplication(attachment.read(), Name=os.path.basename(excel_file)) part['Content-Disposition'] = f'attachment; filename="{os.path.basename(excel_file)}"' msg.attach(part) # 发送邮件 with smtplib.SMTP('smtp.example.com', 587) as server: server.starttls() server.login(from_address, password) server.send_message(msg) send_email('recipient@example.com', 'Monthly Report', 'Please find attached the monthly report.', 'report.xlsx')
print("邮件发送成功!")
解释
此脚本使用SMTP协议自动发送一封电子邮件,其中附带了一个Excel文件。这个功能在工作中尤其有用,比如每月定期发送财务报表或业绩报告给相关人员。通过自动化邮件发送,可以节省时间并减少人为错误。
11. 合并多个Excel文件
import pandas as pd
import osdef merge_excel_files(folder_path, output_file):all_data = pd.DataFrame()for filename in os.listdir(folder_path):if filename.endswith('.xlsx'):file_path = os.path.join(folder_path, filename)df = pd.read_excel(file_path)all_data = pd.concat([all_data, df], ignore_index=True)all_data.to_excel(output_file, index=False)merge_excel_files('your_folder_path', 'merged_file.xlsx')
print("多个Excel文件合并成功!")
解释
该脚本将指定文件夹下的所有Excel文件合并成一个文件。在处理分散在多个文件中的数据时,这个功能可以将数据整合在一起,方便后续的统一分析。
12. 拆分Excel文件
import pandas as pddef split_excel_file(file_path, column_name, output_folder):df = pd.read_excel(file_path)unique_values = df[column_name].unique()for value in unique_values:sub_df = df[df[column_name] == value]output_file = os.path.join(output_folder, f'{value}.xlsx')sub_df.to_excel(output_file, index=False)split_excel_file('example.xlsx', '部门', 'output_folder')
print("Excel文件拆分成功!")
解释
此脚本根据指定列的唯一值将Excel文件拆分成多个文件。例如,按照“部门”列将数据拆分成不同部门对应的文件,便于各部门独立查看和处理自己的数据。
13. 替换单元格内容
import pandas as pddef replace_cell_content(file_path, column_name, old_value, new_value):df = pd.read_excel(file_path)df[column_name] = df[column_name].replace(old_value, new_value)df.to_excel(file_path, index=False)replace_cell_content('example.xlsx', '产品名称', '旧产品', '新产品')
print("单元格内容替换成功!")
解释
该脚本将指定列中的特定内容替换为新的内容。在数据修正或更新时,这个功能可以快速修改数据中的错误或过时信息。
14. 对数据进行排序
import pandas as pddef sort_excel_data(file_path, column_name, ascending=True):df = pd.read_excel(file_path)df = df.sort_values(by=column_name, ascending=ascending)df.to_excel(file_path, index=False)sort_excel_data('example.xlsx', '销售额', ascending=False)
print("数据排序成功!")
解释
这个脚本的主要功能是对 Excel 文件中的数据根据指定列进行排序操作,并且可以选择升序或降序排列,最后将排序后的数据保存回原 Excel 文件。排序操作在数据处理和分析中非常常见,例如按照销售额对销售数据进行降序排序,能快速找出销售额高的记录。
15. 统计特定列的唯一值数量
import pandas as pddef count_unique_values(file_path, column_name):df = pd.read_excel(file_path)unique_count = df[column_name].nunique()print(f"{column_name}列的唯一值数量为: {unique_count}")count_unique_values('example.xlsx', '客户编号')
解释
该脚本用于统计Excel文件中指定列的唯一值数量。在数据分析中,了解某列有多少不同的值可以帮助我们快速掌握数据的分布情况,例如统计客户编号的唯一值数量可以知道有多少不同的客户。
16. 提取指定列到新的Excel文件
import pandas as pddef extract_columns(file_path, columns, output_file):df = pd.read_excel(file_path)new_df = df[columns]new_df.to_excel(output_file, index=False)extract_columns('example.xlsx', ['姓名', '年龄'], 'extracted_columns.xlsx')
print("指定列提取成功!")
解释
此脚本可以从一个Excel文件中提取指定的列,并保存到一个新的Excel文件中。当我们只需要数据中的部分信息时,使用这个脚本可以快速筛选出所需的数据,避免处理大量无关信息。
17. 为Excel表格添加边框
from openpyxl import load_workbook
from openpyxl.styles import Border, Sidedef add_border_to_excel(file_path):wb = load_workbook(file_path)ws = wb.activethin_border = Border(left=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'), bottom=Side(style='thin'))for row in ws.iter_rows():for cell in row:cell.border = thin_borderwb.save(file_path)add_border_to_excel('example.xlsx')
print("表格边框添加成功!")
解释
该脚本为Excel表格中的每个单元格添加了细边框。添加边框可以使表格更加清晰易读,特别是在打印或展示数据时,能够提升表格的美观度和专业性。
18. 检查Excel文件中是否存在空行并删除
import pandas as pddef remove_empty_rows(file_path):df = pd.read_excel(file_path)df = df.dropna(how='all')df.to_excel(file_path, index=False)remove_empty_rows('example.xlsx')
print("空行删除成功!")
解释
此脚本用于检查Excel文件中是否存在所有列都为空的行,并将这些空行删除。空行可能会影响数据处理和分析的结果,通过删除空行可以保证数据的完整性和准确性。
19. 根据多列条件筛选数据
import pandas as pddef filter_data_by_multiple_conditions(file_path, conditions, output_file):df = pd.read_excel(file_path)query_str = ' & '.join([f'{col} {op} {val}' for col, op, val in conditions])filtered_df = df.query(query_str)filtered_df.to_excel(output_file, index=False)# 示例条件:年龄大于25且性别为女
conditions = [('年龄', '>', 25), ('性别', '==', "'女'")]
filter_data_by_multiple_conditions('example.xlsx', conditions, 'filtered_data.xlsx')
print("多条件筛选数据成功!")
解释
该脚本可以根据多个列的条件对Excel数据进行筛选,并将筛选结果保存到新的文件中。在实际数据分析中,我们常常需要根据多个条件来筛选出符合要求的数据,使用这个脚本可以方便地实现多条件筛选。
20. 对Excel中的日期列进行格式化
import pandas as pddef format_date_column(file_path, column_name, date_format):df = pd.read_excel(file_path)df[column_name] = pd.to_datetime(df[column_name]).dt.strftime(date_format)df.to_excel(file_path, index=False)format_date_column('example.xlsx', '日期', '%Y-%m-%d')
print("日期列格式化成功!")
解释
此脚本用于对Excel文件中指定的日期列进行格式化。在处理日期数据时,不同的业务需求可能需要不同的日期格式,通过这个脚本可以将日期列转换为我们需要的格式,方便后续的数据分析和展示。
希望这些Excel自动化脚本能够进一步帮助你提高工作效率,更好地掌握Python在Excel数据处理方面的应用!如果你在实践过程中有任何疑问,欢迎随时交流。
相关文章:

Python分享20个Excel自动化脚本
在数据处理和分析的过程中,Excel文件是我们日常工作中常见的格式。通过Python,我们可以实现对Excel文件的各种自动化操作,提高工作效率。 本文将分享20个实用的Excel自动化脚本,以帮助新手小白更轻松地掌握这些技能。 1. Excel单…...

pytest+request+yaml+allure 接口自动化测试全解析[手动写的跟AI的对比]
我手动写的:Python3:pytest+request+yaml+allure接口自动化测试_request+pytest+yaml-CSDN博客 AI写的:pytest+request+yaml+allure 接口自动化测试全解析 在当今的软件开发流程中,接口自动化测试扮演着至关重要的角色。它不仅能够提高测试效率,确保接口的稳定性和正确性…...

深入解析 FFmpeg 的 AAC 编解码过程
深入解析 FFmpeg 的 AAC 编解码过程 —— 技术详解与代码实现 AAC(Advanced Audio Coding) 是一种高效的有损音频压缩格式,因其高压缩效率和良好的音质而被广泛应用于流媒体、广播和音频存储等领域。FFmpeg 是一个强大的多媒体处理工具,支持 AAC 的编码和解码。本文将详细…...

嵌入式硬件篇---OpenMV串口通信json字符串
文章目录 前言第一部分:Json字符串通信协议优点缺点 Json优点缺点编码与解码 第二部分:UART串口通信UART常用函数注意 总结 前言 以上就是今天要讲的内容,本文简单介绍了Json字符串、UART串口通信。 第一部分:Json字符串 通信协议 在传统的单片机应用中ÿ…...
Python基于Django的课堂投票系统的设计与实现【附源码】
博主介绍:✌Java老徐、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇&…...

蓝桥杯 Java 之输入输出
一、输入输出方式:Scanner vs BufferedReader Scanner类 简介:Scanner 是 Java 中一个非常方便的用于读取用户输入的类,它可以从多种输入源(如标准输入、文件等)读取基本数据类型和字符串。 1. Scanner的细节与使用…...
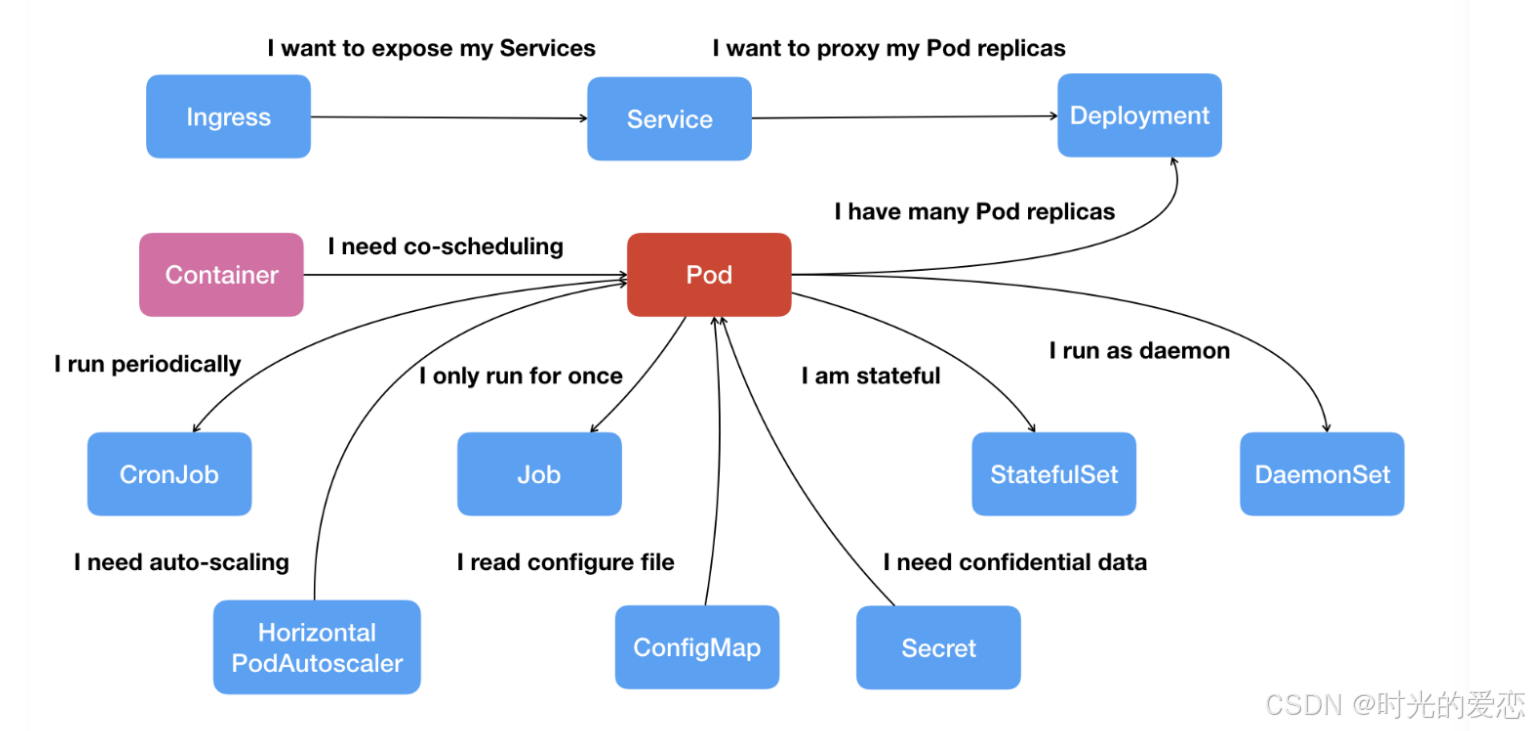
Kubernetes是什么?为什么它是云原生的基石
从“手工时代”到“自动化工厂” 想象一下,你正在经营一家工厂。在传统模式下,每个工人(服务器)需要手动组装产品(应用),效率低下且容易出错。而Kubernetes(k8s)就像一个…...

@emotion/styled / styled-components创建带有样式的 React 组件
一、安装依赖 npm install emotion/styled styled-components 二、使用 import styled from emotion/styled; import styled from styled-components;// 创建一个带样式的按钮 const StyledButton styled.buttonbackground-color: #4caf50;color: white;padding: 10px 20px…...
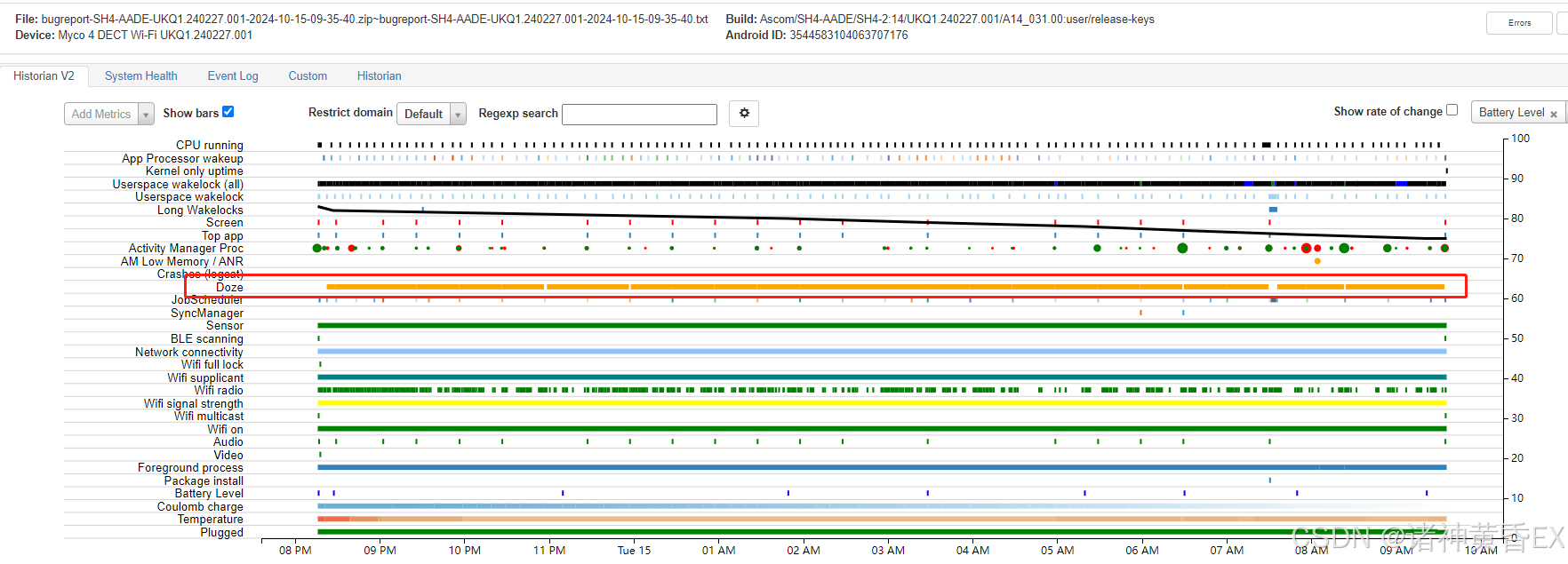
Android 常用命令和工具解析之Battery Historian
Batterystats是包含在 Android 框架中的一种工具,用于收集设备上的电池数据。您可以使用adb bugreport命令抓取日志,将收集的电池数据转储到开发机器,并生成可使用 Battery Historian 分析的报告。Battery Historian 会将报告从 Batterystats…...
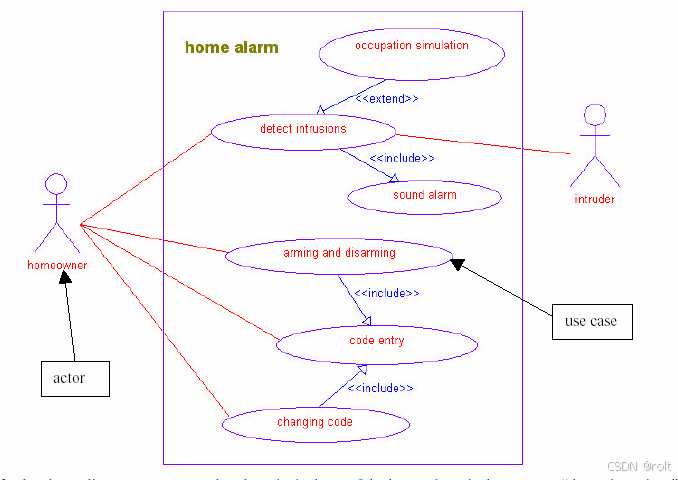
家用报警器的UML 设计及其在C++和VxWorks 上的实现01
M.W.Richardson 著,liuweiw 译 论文描述了如何运用 UML(统一建模语言)设计一个简单的家用报警器,并实现到 VxWorks 操作系统上。本文分两个部分,第一部分描述了如何用 UML 设计和验证家用报警器的模型,以使…...

k8s常见面试题2
k8s常见面试题2 安全与权限RBAC配置如何保护 Kubernetes 集群的 API Server?如何管理集群中的敏感信息(如密码、密钥)?如何限制容器的权限(如使用 SecurityContext)?如何防止容器逃逸࿰…...
CSS 伪类(Pseudo-classes)的详细介绍
CSS 伪类详解与示例 在日常的前端开发中,CSS 伪类可以帮助我们非常精准地选择元素或其特定状态,从而达到丰富页面表现的目的。本文将详细介绍以下伪类的使用: 表单相关伪类 :checked、:disabled、:enabled、:in-range、:invalid、:optional、…...
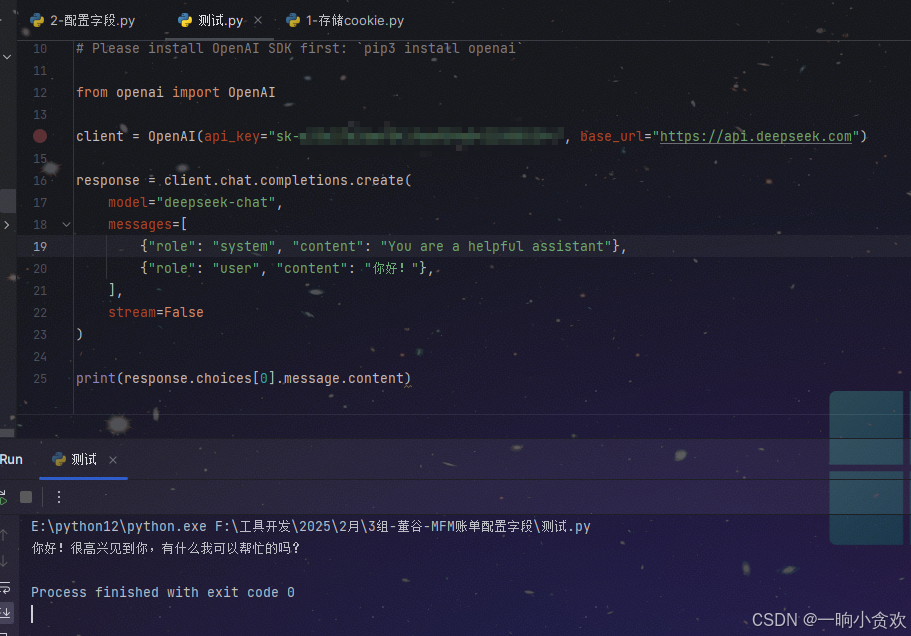
将Deepseek接入pycharm 进行AI编程
目录 专栏导读1、进入Deepseek开放平台创建 API key 2、调用 API代码 3、成功4、补充说明多轮对话 总结 专栏导读 🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手 🏳️🌈 博客主页:请点击——…...

【Ollama】一、介绍
介绍 Ollama 是一个开源项目,专注于提供本地化的大型语言模型(LLM)部署和运行解决方案。它允许用户在本地环境中轻松运行和微调各种开源语言模型(如 LLaMA、Falcon 等),而无需依赖云服务或高性能 GPU。Oll…...
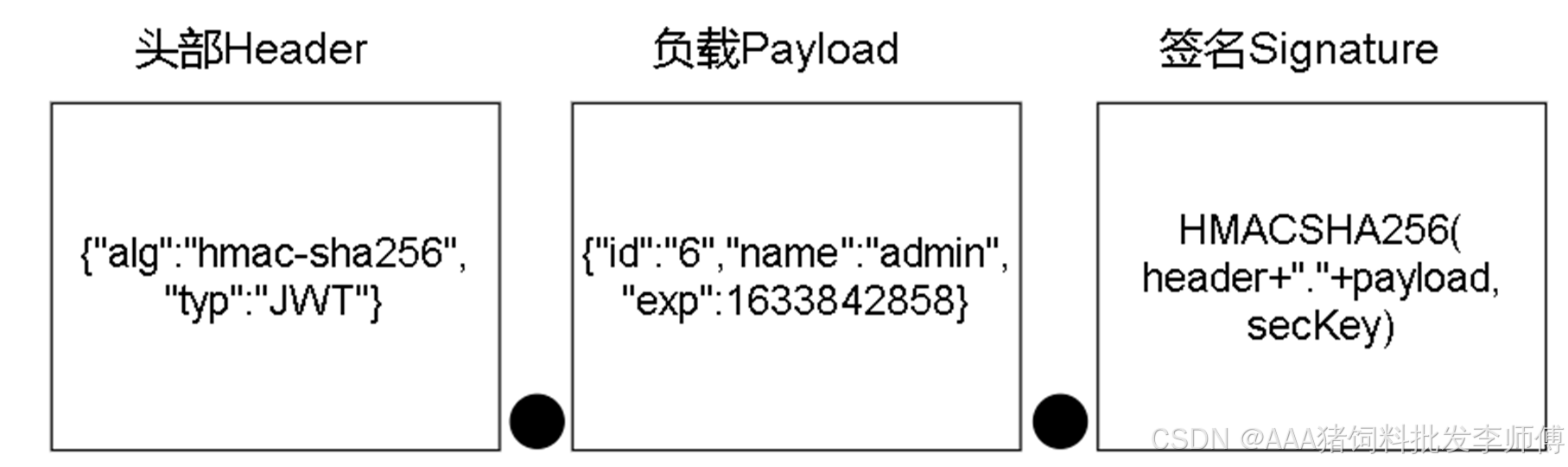
ASP.NET Core JWT
目录 Session的缺点 JWT(Json Web Token) 优点: 登录流程 JWT的基本使用 生成JWT 解码JWT 用JwtSecurityTokenHandler对JWT解码 注意 Session的缺点 对于分布式集群环境,Session数据保存在服务器内存中就不合适了&#…...

查询引擎:它们是什么以及为什么重要
了解查询引擎、它们的优势以及如何简化现代应用程序的数据管理。查询引擎是高效处理和检索数据的强大工具,但并非所有查询引擎都能满足现代应用程序对速度和实时性的需求。在本文中,我们将解析查询引擎的定义、主要优势以及它们如何用于实时数据和AI应用…...

03/29 使用 海康SDK 对接时使用的 MysqlUtils
前言 最近朋友的需求, 是需要使用 海康sdk 连接海康设备, 进行数据的获取, 比如 进出车辆, 进出人员 这一部分是 资源比较贫瘠时的一个 Mysql 工具类 测试用例 public class MysqlUtils {public static String MYSQL_HOST "192.168.31.9";public static int MY…...

2025.2.7 Python开发岗面试复盘
2025.2.7 Python开发岗面试复盘 问题: 是否了解过其他语言? 了解过Java、JavaScript、C等语言,但主要技术栈是Python。 Python跟Java的区别? Python是解释型语言,Java是编译型语言 Python动态类型,Java静态类型 Python简洁易读,Java相对严谨复杂 Python GIL限制并发,Java并…...
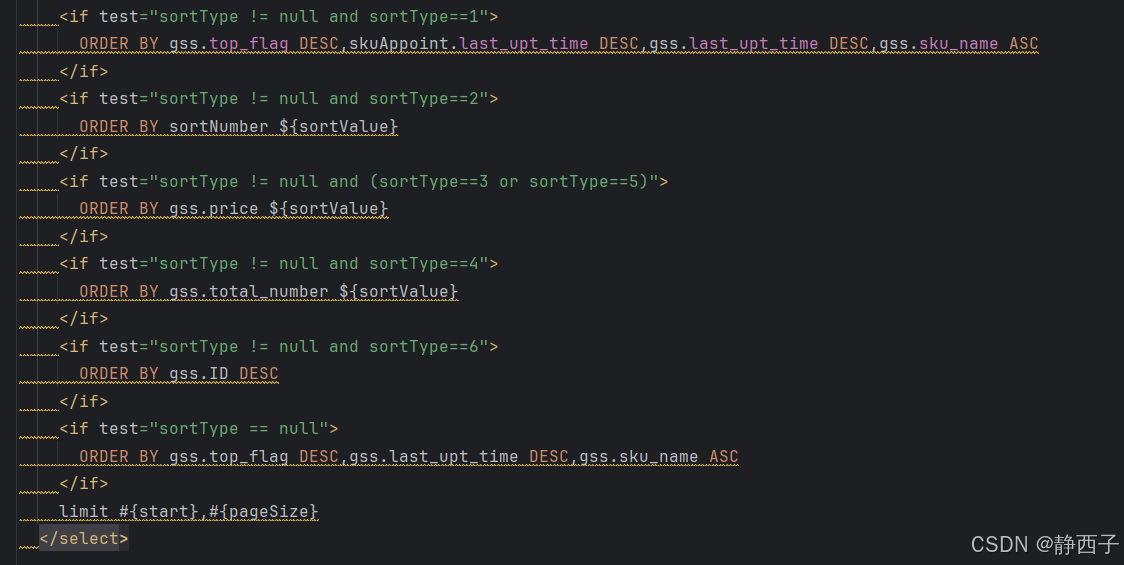
一个sql只能有一个order by
ORDER BY 子句在 SQL 中只能出现一次,静态部分和动态部分只能写一个 ORDER BY...

Windows Docker笔记-在容器中运行项目
在文章《Windows Docker笔记-Docker容器操作》中,已经成功创建了容器,也就是建好了工厂,接下来就应该要安装流水线设备,即运行项目达到生产的目的。 在Ubuntu容器中新建项目 这里要新建一个简单的C项目,步骤如下&…...

农业图像标注效率暴跌63%?这5个Auto-Labeling技巧已获农业农村部AI应用白皮书推荐
第一章:农业图像标注效率暴跌的根源与Auto-Labeling破局逻辑农业图像标注正面临严峻效率瓶颈:单张田间作物病害图平均需人工耗时4.7分钟完成细粒度标注(含病斑轮廓、类别、严重等级三重标签),而标注错误率高达18.3%——…...

PyTorch模型性能分析与瓶颈定位:使用PyTorch Profiler工具详解
PyTorch模型性能分析与瓶颈定位:使用PyTorch Profiler工具详解 1. 为什么需要性能分析工具 训练深度学习模型时,我们经常会遇到这样的困惑:为什么模型训练这么慢?是数据加载拖慢了速度,还是计算本身效率低下…...

告别零散烧录:一个脚本搞定Petalinux 2020.1 ZynqMP QSPI全镜像生成与烧写
告别零散烧录:Petalinux 2020.1 ZynqMP QSPI全镜像自动化生成实战 在嵌入式Linux开发中,QSPI Flash烧录往往是最后一道工序,也是最容易出错的环节之一。传统分步烧录方式不仅效率低下,还容易因地址偏移计算错误导致启动失败。本文…...

AI工具使用限制解决方案:突破设备识别与权限重置完全指南
AI工具使用限制解决方案:突破设备识别与权限重置完全指南 【免费下载链接】go-cursor-help 解决Cursor在免费订阅期间出现以下提示的问题: Youve reached your trial request limit. / Too many free trial accounts used on this machine. Please upgrade to pro. …...

博科光纤交换机命令行配置实战:从基础查询到高级Zone管理
1. 博科光纤交换机基础入门 第一次接触博科光纤交换机的命令行界面时,我完全被那一串串看似复杂的命令搞懵了。但经过几个项目的实战后,我发现只要掌握几个核心命令,就能轻松完成大部分日常管理工作。让我们从最基础的IP地址查询开始…...

8公里巷道,最小误差仅0.6%,天宝耐特携L2pro解锁矿山井下高效安全测量
随着数字矿山建设的加速推进,空间数据采集技术成为矿山数字化转型的重要支撑。在此背景下,天宝耐特在华南某大型金矿完成了灵光L2pro手持SLAM三维激光扫描技术的深度应用实践,以硬核技术破解矿山作业难题,实现井下数字孪生底座构建…...

从概念到生产:使用快马AI生成企业级开yun微服务实战代码
今天想和大家分享一个实战经验:如何用InsCode(快马)平台快速搭建一个生产级可用的微服务项目。这个项目是一个产品目录服务,但重点不在于业务逻辑,而是如何集成企业开发中那些真正实用的技术栈。 项目骨架搭建 首先用Spring Initializr创建…...

效率提升利器:用快马生成智能脚本,一键统一团队node.js开发环境
在团队协作开发中,最让人头疼的莫过于"在我电脑上能跑"的环境问题。最近我们团队尝试用InsCode(快马)平台生成智能脚本,彻底解决了Node.js环境配置这个老大难问题。分享下这个提升效率的实践过程: 环境检测自动化 传统方式需要每个…...

UniApp静态资源分包实战:除了图片500错误,你的分包策略真的优化到位了吗?
UniApp静态资源分包深度优化:从500报错到全平台兼容方案 在UniApp开发中,随着项目规模扩大,静态资源管理逐渐成为性能优化的关键瓶颈。许多开发者初次接触分包策略时,往往只关注基础配置而忽略资源加载的深层逻辑,直到…...

清华团队发布机器人版“GPT时刻”:UniDex让机械手看懂世界,零样本操控万物!
80%成功率,碾压式超越现有方案,灵巧手操控迎来“GPT”时刻这篇论文用一种极其优雅且强大的方式,解决了机器人领域一个长期存在的根本性难题:如何让形态各异、复杂无比的灵巧手,像人类一样,看一眼就能学会使…...