论文阅读:MGMAE : Motion Guided Masking for Video Masked Autoencoding
MGMAE:Motion Guided Masking for Video Masked Autoencoding
Abstract
掩蔽自编码(Masked Autoencoding)在自监督视频表示学习中展现了出色的表现。时间冗余导致了VideoMAE中高掩蔽比率和定制的掩蔽策略。本文旨在通过引入运动引导掩蔽策略,进一步提升视频掩蔽自编码的性能。我们的关键见解是,运动是视频中的一种普遍且独特的先验信息,应在掩蔽预训练过程中加以考虑。我们提出的运动引导掩蔽明确地结合了运动信息,构建了时间一致的掩蔽体积。基于这个掩蔽体积,我们能够追踪时间上的未掩蔽标记,并从视频中采样一组时间一致的立方体。这些时间对齐的未掩蔽标记将进一步缓解信息泄漏问题,并鼓励MGMAE学习更多有用的结构信息。我们使用在线高效光流估计器和反向掩蔽图扭曲策略实现了MGMAE,并在Something-Something V2和Kinetics-400数据集上进行了实验,展示了MGMAE相较于原始VideoMAE的优越性能。此外,我们还提供了可视化分析,说明MGMAE能够以运动自适应的方式采样时间一致的立方体,从而更有效地进行视频预训练。
1. Introduction
基于注意力机制的Transformer(如Vision Transformer,ViT)自从引入以来,在计算机视觉领域取得了巨大成功。ViT被广泛应用于各种视觉任务,并取得了最先进的性能,如图像分类[36, 59, 52]、目标检测[23, 46]、语义分割[49]和目标跟踪[8]。得益于其优异的性能,ViT模型也已被应用于视频领域,如动作识别[5, 1]和检测[33, 54]。然而,Transformer通常具有较高的模型容量,这常常需要在大规模数据集上进行预训练,以降低后续微调时过拟合的风险。因此,ViT的有效预训练策略对于在视频领域获得优异的性能尤为重要,因为视频数据集相对较小。
早期的video Transformer[1, 5]通常依赖于基于图像的大规模数据集进行预训练,这些vision Transformer衍生于大规模的图像数据集[10]。这种预训练方案使得学习到的视频模型往往受到基于图像的ViT的影响。近年来,掩蔽自编码(MAE)[35, 14, 41]由于其简洁性以及在图像领域的良好表现[17],已被探索用于video Transformer的预训练。然而,与图像不同,视频数据具有额外的时间维度,并展现出时间冗余性和相关性的独特特性。这一特性要求视频掩蔽自编码器相比图像MAE需要一些定制化的设计。例如,VideoMAE和MAE-ST都提出在视频掩蔽自编码器的预训练中使用极高的掩蔽比率以提高其性能。此外,VideoMAE设计了一种管道掩蔽策略,在所有帧中相同位置丢弃标记,以进一步减少时间上的信息泄漏。尽管这种管道掩蔽方法较为简单,但其假设相邻帧之间几乎没有或只有微小的运动,这种假设对于某些高速运动场景可能并不成立。
基于上述分析,本文提出了一种新的掩蔽策略,旨在通过显式利用运动信息来减少时间上的信息泄漏,从而改善视频掩蔽自编码器的预训练。具体而言,我们在视频掩蔽编码器处理中设计了运动引导掩蔽(Motion Guided Masking),并将所得到的掩蔽自编码器命名为MGMAE。运动是视频中普遍存在的先验信息。光流表示法明确地编码了每个像素从当前帧到下一帧的运动信息。我们提出利用这种光流信息来对相邻帧之间的掩蔽图进行对齐,从而在时间上构建一致的掩蔽体积。通过构建一致的掩蔽体积,可以通过仅让编码器看到一个小的立方体轨迹集合,构建更具挑战性的重建任务。希望这种运动引导掩蔽能够进一步减轻时间上的信息泄漏风险,并促使学习到更有意义的视觉表示。
更具体地,我们使用了一种在线且轻量的光流估计器(RAFT [34])来捕捉运动信息,该估计器可以无缝集成到现有的VideoMAE框架中。为了构建时间一致的掩蔽体积,我们首先在基准帧上随机生成一个初始掩蔽图。然后,我们使用估算的光流将初始掩蔽图扭曲到相邻帧。通过多次扭曲操作,我们为视频中的所有帧构建了时间一致的掩蔽体积。最后,基于该掩蔽体积,我们使用基于帧的top-k选择方法从中采样一组可见标记供MAE编码器处理。对这些采样标记应用与原始VideoMAE相同的自编码过程进行视频预训练。通过这种简单的运动引导掩蔽,我们能够进一步增加视频预训练任务的难度,从而得到一个更好的预训练模型,供后续微调使用。
我们主要通过在Something-Something V2 [16]和Kinetics-400 [20]数据集上与原始VideoMAE中的管道掩蔽进行对比,验证了所提出的MGMAE的有效性。结果表明,MGMAE的预训练能够生成更强大的视频基础模型,并在下游任务中取得更高的微调准确率。特别是在以动作为中心的Something-Something基准上,MGMAE的改进更加明显,表明我们的运动引导掩蔽能够适应运动变化,并能更好地捕捉时间结构信息,从而为预训练提供支持。我们希望我们的研究结果能够启发在视频掩蔽自编码领域进行一些特定且独特的设计,尤其是在与图像对比时。

图 1:不同掩蔽策略的比较。掩蔽自动编码 [11, 17] 已在视频领域进行了探索,用于自我监督预训练,采用不同的掩蔽策略:随机掩蔽 [14] 和管掩蔽 [35]。我们建议在运动信息的指导下跟踪掩蔽图(称为运动引导掩蔽)。我们得到的 MGMAE 可以为视频预训练构建更具挑战性和意义的任务。
2. Related Work
掩蔽视觉建模。掩蔽自编码器是一种长期存在的无监督学习框架,广泛应用于计算机视觉领域。早期的研究提出了去噪自编码器的通用形式[40, 39],通过从噪声输入中重建干净信号来学习表示。另一项工作[27]也将掩蔽建模视为通过卷积从周围上下文中填充缺失区域的图像修复任务。受掩蔽语言建模(Masked Language Modeling, MLM)[11]成功的启发,一些研究尝试将这一预训练范式应用于视觉领域的自监督预训练。例如,iGPT[7]借鉴了自然语言处理(NLP)中的GPT工作[30],通过处理一系列像素进行下一像素的自回归预测。原始的ViT[12]使用掩蔽标记预测作为自监督训练步骤,在大规模图像数据集上进行预训练,但未能取得令人印象深刻的结果。近年来,一些有趣的工作通过使用掩蔽图像建模在自监督图像预训练中取得了突破性进展,如BEiT[3]、SimMIM[50]和MAE[17]。BEiT[3]直接借鉴了BERT框架,提出通过预测掩蔽块的离散标记来进行训练,要求使用显式的分词器来构建标记词典。SimMIM[50]和MAE[17]共享相同的设计,直接预测掩蔽块的像素,而不需要任何分词器设计。此外,MAE[17]设计了一个非对称的编码器-解码器架构,以加速掩蔽图像预训练。
自掩蔽图像建模取得巨大成功以来,一些研究尝试将这一新的预训练范式扩展到视频领域进行自监督视频预训练。BEVT[45]和VIMPAC[32]提出通过类似于BEiT的方法,预测离散视觉标记来学习视频表示。然而,它们在视频动作识别中的性能提升有限。MaskFeat[48]将HOG特征[9]作为掩蔽块的重建目标,并在视频识别中取得了优秀的性能,采用了多尺度视觉Transformer。VideoMAE[35]和MAE-ST[14]将图像MAE扩展到视频领域,使用普通的vision Transformer进行表示学习。它们都提出使用极高的掩蔽比率来处理视频数据冗余问题。同时,VideoMAE[35]使用管道掩蔽策略进一步增加了重建任务的难度。基于VideoMAE的多项工作应运而生。例如,MAR[29]通过引入运行单元掩蔽减少了训练和推理成本。与此同时,VideoMAE V2[41]提出了双重掩蔽策略,以降低预训练开销,并通过扩展模型规模和数据集进一步探索了VideoMAE的可扩展性。我们提出的运动引导掩蔽旨在通过构建更具挑战性的掩蔽和重建任务来提高VideoMAE的性能。与原始VideoMAE不同,我们的MGMAE显式地使用光流对跨帧的掩蔽图进行对齐,并生成时间一致的掩蔽体积来采样一组可见标记。
运动引导建模。运动信息,如光流,是视频中的一种通用先验信息,代表了与图像不同的独特特性。光流已广泛应用于为视频中的低层次和高层次视觉任务提供强大的先验信息。对于低层次的视频任务,运动通常用于对齐辅助帧的信息与目标帧的对应区域。例如,在视频超分辨率任务中,BasicVSR++[6]利用光流通过从邻近帧传递特征来增强低分辨率帧的外观。对于视频修复,Zhang等[56]利用光流提取的运动差异来指导Transformer中的注意力检索,以实现高保真度的视频修复。至于视频帧插值,主流方法直接利用光流在图像上合成中间帧,如DAIN[4]和RIFE[18],而Zhang等[55]则提出了一个统一的操作,利用帧间注意力同时提取运动和外观信息,并融合了混合CNN和Transformer设计,以提高效率和精细细节的保留。对于高层次视频任务,光流直接作为数据模态输入到网络中进行动作识别[44, 31]。TDD[42]利用运动轨迹池化深度卷积特征进行动作识别。Trajectory Convolution[57]将运动信息融入时间卷积核设计中。MSNet[21]提出了一个可插拔的MotionSqueeze模块,用于生成跨帧的运动信息。VideoMS[19]通过计算补丁嵌入后的特征差异来生成掩蔽图,并尝试动态调整掩蔽位置。AdaMAE[2]引入了一种端到端可训练的自适应掩蔽策略,利用辅助采样网络优先选择来自高时空信息区域的标记。Yang等[51]利用分层运动信息改进提取的视频特征。MotionFormer[28]在视频Transformer中采用轨迹进行注意力计算。TEA[22]和TDN[43]使用RGB差异近似运动信息,并将其融入视频CNN骨干网设计中。MGSampler[58]探索了运动信息,用于选择一组代表性帧以提高视频动作识别的效率。我们的MGMAE与这些运动引导建模的工作具有相同的精神。我们专注于利用运动信息作为提示,生成掩蔽图进行视频预训练。

图 2: MGMAE 的流程
我们的 MGMAE 遵循简单的掩码和重建流程进行视频自监督预训练。我们的核心设计是提出一种运动引导的掩码策略,用于生成时间一致性的掩码体积。通过这个掩码体积,我们追踪可见的块并确保掩码图的时间一致性。最终,这使得我们能够构建一个更具挑战性的重建任务,并在掩码自监督预训练过程中鼓励提取更有效的表示。
3. Method
在本节中,我们首先回顾了 VideoMAE 的预训练范式,以在 3.1 节中清楚地介绍我们的 MGMAE。然后在 3.2 节中详细说明了运动引导的遮罩映射生成的细节。最后,在 3.3 节中描述了在时间一致的遮罩映射下的 MGMAE 预训练方法。
3.1. VideoMAE 回顾
VideoMAE 是一种简单的遮罩视频自动编码器,具有一个非对称的编码器-解码器架构,并通过立方体嵌入来处理输入的采样帧。接下来,我们简要回顾其实现细节。
立方体嵌入
VideoMAE 将输入视频片段 III(大小为 T×3×H×W)划分为不重叠的立方体 C={Ci∣Ci∈R2×16×16×3}i=1N,其中 N=2×H/16×W/16是立方体的数量。然后,对这些立方体进行嵌入生成视频标记 T={Ti∣Ti∈RD}i=1N,其中 Ti表示带有位置编码的立方体嵌入,D 是通道数。
遮罩策略
VideoMAE 使用管状遮罩策略,并设置极高的遮罩比率 ρ(即 90%),在输入视频片段的所有帧中采样相同的空间位置。具体而言,VideoMAE 首先生成一个二值遮罩映射 M′(大小为 H/16×W/16,0 表示未遮罩,1 表示遮罩),然后在时间维度上复制它,并展平成令输入视频片段的标记级遮罩映射 M 的大小为 N。
编码器
编码器是一个采用联合时空注意力机制的标准 ViT 模型。为了提高计算效率,仅将未遮罩的可见标记 Tv={Ti∣i∉M}(加上固定的位置编码)输入编码器,从而获得大小为 Nv×D的潜在特征Z,其中 Nv=⌊(1−ρ)N⌋ 是未遮罩的可见标记总数。
解码器
解码器比编码器更窄、更浅。它将由潜在特征 Z 与带有固定位置编码的可学习 [MASK] 标记连接形成的标记序列作为输入,以重建归一化的视频立方体 C^={C^i∣C^i∈R2×16×16×3}i=1N。
损失
预训练目标是在遮罩位置上最小化归一化 C 和 C^之间的均方误差损失:
 完成预训练后,编码器将作为主干网络用于下游任务的微调以获得专门模型。
完成预训练后,编码器将作为主干网络用于下游任务的微调以获得专门模型。
3.2. 运动引导遮罩图 (Motion Guided Masking Map)
时间是视频的一个独特特性,与空间维度有着不同的属性。在设计掩蔽视频自编码器时,我们需要仔细考虑这一额外的时间维度,并提出定制化的设计。时间信息泄漏是掩蔽视频预训练中的一个重要问题。当信息泄漏发生时,模型可以轻易地基于相邻帧的可见标记重建掩蔽的块,这将大大降低重建任务的难度,从而导致预训练模型在后续微调中的性能较差。一个简单的解决方案是增加掩蔽比率。VideoMAE[35]和MAE-ST[14]通过将掩蔽比率增加到90%,大大增加了重建任务的难度。此外,VideoMAE做出了小运动假设,并采用了管道掩蔽策略,该策略在所有帧中掩蔽相同的空间位置。然而,这种小运动先验并不总是适用于以运动为主的视频。一个更合理的方法是确保视频片段中的每个物体在所有帧中始终可见或不可见。为实现这一目标,我们提出了运动引导掩蔽策略,用以替代VideoMAE中的管道掩蔽策略。该策略包含两个过程:首先,我们使用光流作为指导,生成输入视频片段的时间一致的掩蔽体积;然后,基于时间一致的掩蔽体积采样未掩蔽的可见标记。我们将在第3.2节和第3.3节中详细介绍这两个过程。
一般而言,生成时间一致掩蔽体积的过程分为以下四个步骤:
- 步骤1:确定基准帧 Ib,其中 b 是基准帧的索引。
- 步骤2:随机生成一个像素级的初始掩蔽图 Mb ,大小为 H×W,作为基准帧 Ib的掩蔽图。
- 步骤3:从基准帧 Ib 中双向提取密集光流 F。
- 步骤4:在密集光流 F 的指导下,扭曲初始掩蔽图 Mb ,并逐步构建时间一致的掩蔽体积 M,大小为 T×H×W。
确定基准帧
默认情况下,我们选择中间帧作为基准帧。在运动引导掩蔽中,我们需要确保基准帧中的所有物体在输入片段的所有帧中始终保持一致的可见性或不可见性。需要注意的是,物体可能由于物体或相机的运动而在时间上(不)出现,通过光流来扭曲掩蔽图可能会导致一些“孔洞”,因为某些像素可能会被映射到边界外。因此,基准帧的选择可能会影响信息泄漏的抑制效果。我们将在第4.2节中探讨基准帧选择的影响,结果表明,中间帧是最优选择。
生成初始掩蔽图
我们为基准帧初始化一个像素级的掩蔽图,使用高斯混合模型(GMM)来分布这些掩蔽区域。掩蔽图用来指示基准帧中块的可见或不可见状态。以往的掩蔽策略通常使用基于标记级的二进制初始化,即每个大小为 2×16×16 的标记要么全为0,要么全为1,这种做法实际上打破了物体表面纹理的连续性。
具体而言,我们首先随机选择 N^v=⌊(1−ρ)×H/16×W/16⌋ 个标记,其中心坐标为 c={c⃗i:(ci1,ci2)}iN^v。然后,我们在每个标记的中点生成二维高斯分布 Ni(ci,σ2),其中 σ是标准差,取为块大小(16,16)。由此,我们会得到与基准帧对应的混合高斯分布  ,并使用混合高斯分布的概率密度函数来指示基准帧中块(标记)的可见性。
,并使用混合高斯分布的概率密度函数来指示基准帧中块(标记)的可见性。
提取光流
我们使用在线和离线两种方法提取光流。在线方法使用RAFT[34](小版本)来估计输入视频片段的光流;离线方法则应用传统的TVL1[53]算法提前提取所有相邻帧之间的密集光流。在读取光流时,我们执行一致的裁剪、缩放操作。在线和离线方法的结果相似,更多细节请参见第4.2节。
在实践中,我们仅从基准帧 Ib 提取前向和后向光流 F,即:
 其中,光流 νi→j表示从帧 Ii到帧 Ij的光流。
其中,光流 νi→j表示从帧 Ii到帧 Ij的光流。
使用光流扭曲掩蔽图
我们使用反向扭曲方法逐步生成视频片段的时间一致掩蔽图。前向扭曲 ϕF 和反向扭曲 ϕB 是两种相对的扭曲模式,都可以有效地用于从初始掩蔽图构建掩蔽体积。遗憾的是,前向扭曲会遇到“孔洞”或遮挡问题,即某些像素可能无法接收到光流,或者可能有多个光流指向同一像素。相比之下,反向扭曲将给定图像的像素逐一映射到各自的目标位置。值得注意的是,尽管反向扭曲并不能避免因光流映射超出边界而产生的孔洞,但这些孔洞通常比前向扭曲少,并且大多发生在图像的边界,因此对信息分布的影响较小。对于反向扭曲造成的孔洞,我们用基准帧中相应位置的值填充这些孔洞,从而模拟管道掩蔽策略。
形式化地,给定光流 F 和基准帧掩蔽体积 Mb ,可以通过反向扭曲构建视频帧 Ii的掩蔽图 Mi:
 随后,整个掩蔽体积 M={Mi}i=1T可以通过双向反向扭曲光流 FFF,从基准帧掩蔽图 Mb开始逐步构建。
随后,整个掩蔽体积 M={Mi}i=1T可以通过双向反向扭曲光流 FFF,从基准帧掩蔽图 Mb开始逐步构建。
3.3 运动引导的掩蔽自编码器 (MGMAE)
我们基于上述的运动引导掩蔽图构建了MGMAE。时间一致的掩蔽体积表示在光流追踪下,邻近帧中对应位置的可见性概率。为了尽可能抑制信息泄漏,我们沿时间维度采样具有最高可见概率的视频标记。具体来说,我们首先对掩蔽体积 M 执行大小为 2×16×16的平均池化操作,以获得大小为 T/2×H/16×W/16 的标记级掩蔽体积 M′。然后,我们在时间维度上选择前 N^v 个掩蔽图位置,并从中采样相应的视频标记作为未掩蔽的可见标记。
根据我们得到的时间一致掩蔽体积,这些采样的标记被输入到非对称的编码器-解码器中进行自编码器式的预训练。通过我们MGMAE预训练得到的模型与原始的VideoMAE模型在微调下游任务时采用相同的方法。
讨论
此前的研究 [35, 14] 将MAE扩展到了视频领域,它们分别采用了随机(无关)掩蔽和管道(仅空间)掩蔽策略。随机掩蔽不会对视频的空间和时间维度引入明确的归纳偏差,其目的是提供一个最小领域知识的统一特征表示学习框架。我们认为,尽管这个思想很简单,但时间本质上是与空间不同的维度。认识到这一点后,我们可以更好地利用这一先验信息来增强视频的掩蔽自编码。
管道掩蔽假设帧的大面积区域没有运动或只有很小的运动,因此跨帧掩蔽相同的位置可以大大减少信息泄漏的风险。然而,对于以运动为主的视频数据集,如Something-Something,这一假设将不再成立,正如表1b所示,反向扭曲的贡献证明了这一点。我们提出的运动引导掩蔽提供了一个更通用且概念上简单的解决方案,可以考虑时间关联性。它可以视为一种自适应的视频掩蔽策略,并在视频预训练中创造出更具挑战性但意义重大的任务。
4. Experiments
4. 实验
4.1 数据集
与原始的VideoMAE相同,我们在Kinetics-400 (K400) [20] 和 Something-Something V2 (SSV2) [16] 数据集上评估我们的MGMAE。K400包含约24万条训练视频和2万条验证视频,视频中的动作通常与特定的物体或场景相关,如刷牙和弹钢琴。而SSV2包含约16.9万条训练视频和2.5万条验证视频,SSV2中的类别主要关注特定的运动模式(例如推、拉)。我们首先在相应的数据集上使用MGMAE对视频Transformer进行自监督表示学习的预训练。然后,我们报告预训练模型在目标数据集上进行动作识别的微调表现。在我们的MGMAE预训练中,我们通常遵循原始VideoMAE的设置和实现。由于RAFT [34] 在MGMAE预训练中的效率和准确性,我们采用它来提取光流。有关MGMAE实现的详细信息,可以在附录中找到。
4.2 消融实验
在本小节中,我们对运动引导掩蔽策略中每个步骤的选择进行了深入的消融实验。我们使用16台80G-A100 GPU在SSV2数据集上训练ViT-base模型800个epoch,然后在SSV2数据集上微调编码器进行动作识别。所有模型共享相同的训练计划,并报告2个剪辑×3个裁剪的准确性。
基帧选择
在本研究中,我们探讨了基帧选择对初始掩蔽生成过程的影响。我们将中间帧作为基帧与第一帧或随机帧进行比较,结果如表1a所示。结果表明,中间帧是最佳选择。
使用光流的扭曲方法
我们比较了两种用于对齐帧间掩蔽图的扭曲方法,如第3.2节所述。正如之前提到的,前向扭曲往往会导致掩蔽扭曲过程中更严重的遮挡和孔洞问题。相反,反向扭曲可以有效缓解这一问题,并确保更加平滑的掩蔽扭曲。表1b的结果表明,反向扭曲有助于更好的性能。
顶部k个可见标记的采样策略
我们检查并比较了两种采样策略,基于我们的时间一致掩蔽体积选择可见标记。帧级策略为每帧独立采样前k个位置,而剪辑级策略为整个视频联合采样前k个位置。正如表1c所示,帧级前k采样策略的性能略优。
基帧的掩蔽初始化
我们消融了在基帧生成初始掩蔽图的选择,如表1d所示。标记级初始化方法将掩蔽图划分为大小为 H16×W16\frac{H}{16} \times \frac{W}{16}16H×16W 的16×16标记,并随机将90%的标记设置为0(表示被掩蔽)和10%的标记设置为1(表示未掩蔽)。像素级初始化方法随机将90%的像素设置为0,10%的像素设置为1。混合高斯方法的初始化过程在第3.2节中有详细描述。结果表明,混合高斯初始化方法效果最好。
孔洞填充方法
我们研究了在反向扭曲中通过映射出界产生的孔洞问题的不同处理方法,如表1e所示。为了确定反向扭曲所造成的真实孔洞,我们将初始掩蔽图中的0值设置为1e−8,然后将新掩蔽图中等于0的位置视为孔洞。我们试验了五种填充孔洞的方法:
- 不可见方法:将所有孔洞填充为0;
- 可见方法:将所有孔洞填充为1;
- 随机方法:根据掩蔽率ρ以随机概率将孔洞填充为0或1;
- 先前图方法:使用与上一个生成的掩蔽图相同位置的值填充孔洞;
- 管道方法:根据初始掩蔽图中对应位置的值填充孔洞,符合管道掩蔽的原则。
我们发现,管道方法在所有方法中表现最好。
光流估计方法
我们评估了不同光流估计方法的效果,如表1f所示。对于离线方法,我们使用TVL1算法提前提取光流,其准确性与在线的RAFT光流相当。尽管VideoMAE在使用RAFT-small(设为6次测试迭代)估计光流时训练速度比MGMAE快1.3倍,但MGMAE在性能和减少过拟合风险方面有明显优势。我们发现,离线方法的训练速度并不比在线方法快,因为读取光流(IO操作)会成为训练速度的瓶颈。值得注意的是,我们的默认设置并不是最优的,但其他消融实验中得出的结论应该不受影响。
掩蔽率
MGMAE的表现突出了即使在高掩蔽率下(例如90%),改进掩蔽策略的重要性。然而,在应用MGMAE之后,仍然有一个问题是是否仍然需要这么高的掩蔽率。正如[35, 14]所指出的,盲目提高掩蔽率可能会降低模型的性能。我们的消融实验如图3所示,表明即使在MGMAE的情况下,维持80%以上的高掩蔽率也是至关重要的。我们认为,视频背景和大物体主要驱动了高掩蔽率的需求。视频背景通常宽广且简单。如果掩蔽率不够高,模型仍然可以从其他背景部分重建像素,即使邻近帧掩蔽了相似的区域。对于大物体,较低的掩蔽率可能会让模型使用不同部分的纹理来重建被掩蔽的部分。从实验中也可以观察到,MGMAE在85%的掩蔽率下表现最佳,但90%仍然是一个不错的选择,考虑到训练效率和性能之间的折衷。
掩蔽对象的暴露
另一个值得考虑的建议是,偶尔暴露被掩蔽的对象是否有助于掩蔽视频建模的预训练。我们进行了一个补充实验。具体而言,在构建掩蔽体积之后,我们向一个随机选择的帧的掩蔽图上添加了高斯噪声。这种修改可能会提供一个机会,让被掩蔽的对象暴露出来。结果显示,准确率为71.2%,略高于默认设置的71.0%。

表1:在Something-Something V2数据集上的部分消融实验结果。
我们的MGMAE预训练采用16帧的基础ViT-B骨干网络实现。所有模型均在掩码比例ρ=90%的条件下进行800个周期的预训练。推理协议采用2片段×3裁剪的方式报告微调动作识别的准确率。
默认设置在表中以灰色标出。尽管在光流估计方法上默认设置可能不是最优的,但我们认为这并不影响消融实验的结论。

图3:掩蔽比例对SSV2的影响。
4.3 主要结果与可视化分析
在对 MGMAE 设计进行详细的消融研究后,我们进一步通过与原始 VideoMAE 的比较进行更深入的分析,同时提供了一些中间可视化结果以说明运动引导采样过程。

表2:MGMAE和VideoMAE的预训练损失比较。
预训练损失表明任务更具挑战性
MGMAE 的核心设计是借助光流动态采样被遮掩 token 的位置,从而增加重建任务的难度。如表 2 所示,MGMAE 的预训练损失始终比 VideoMAE 高出 0.05 以上。此损失差距表明运动引导遮掩进一步抑制了信息泄露,并构建了更具挑战性的遮掩-重建预训练任务。这一更困难的任务有助于学习更有效的表示。

图 4:MGMAE 和 Video MAEbyClass 的准确率比较。
MGMAE 和 VideoMAE 的详细比较
为了理解 MGMAE 和 VideoMAE 遮掩策略对视频模型预训练的不同影响,我们深入分析了两者在每个类别上的准确率变化。图 4 展示了分类准确率差异最显著的 29 个类别,直观反映了两种方法的区别。

表3:MG MAE与VideoMAE的准确度比较。
MGMAE:更有效的视频表示学习器
MGMAE 因运动引导遮掩策略构建的更困难任务而受益匪浅。一方面,模型必须更加努力地编码可见 token 与不可见 token 之间的关系,从而更好地指导模型训练。另一方面,信息泄露的抑制可能有效降低预训练的过拟合风险,使得模型可以进行更长时间的预训练。如表 3 所示,在以动作为中心的 SSV2 数据集上,MGMAE 的微调性能相较 VideoMAE 一直保持明显优势(800 轮时提升 1.4%,2400 轮时提升 1.5%)。在以场景为中心的 Kinetics-400 数据集上也有一定提升(800 轮时提升 1.2%,1600 轮时提升 0.3%)。

图5:SSV2验证集视频的可视化。
我们展示了运动引导掩码图以及重建图像。从上到下依次为:原始图像、x方向的光流、y方向的光流、运动引导掩码图、掩码后的图像以及重建的图像。
可视化分析
我们随机选取了 SSV2 验证集中的一个视频片段,并在图 5 中展示了其重建示例。可以看到,遮掩图随着物体运动而变化,使得模型更难以重建原始视频。

表 4:Something-Something V2 数据集上的比较。我们仅列出使用类似主干获得的结果。
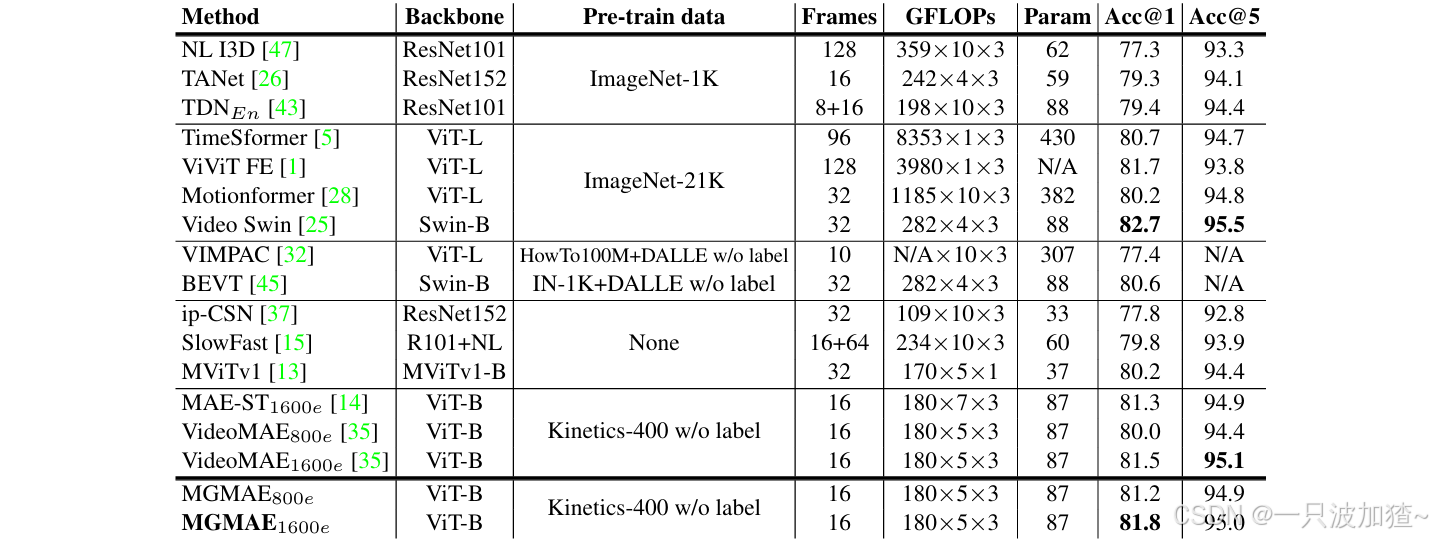
表 5:Kinetics-400 数据集上的比较。我们仅列出使用相似主链获得的结果。
4.4 与最新方法的比较
我们将 MGMAE 与之前的最新方法在 Kinetics-400 和 Something-Something V2 数据集上进行了比较,结果分别展示在表 5 和表 4 中。为保证公平比较,我们主要列出计算成本相近的结果。在 Something-Something V2 数据集上,MGMAE 使用 ViT-B 骨干网络在 2400 轮训练中取得了 72.3% 的性能,相较原始 VideoMAE 提升了 1.5%。在 Kinetics-400 数据集上,MGMAE 的性能略优于原始 VideoMAE。这种较小的性能提升可能归因于 Kinetics-400 是一个以场景为中心的动作识别基准,相较于 Something-Something 数据集,运动信息的重要性较低。
5. Conclusion
总结
本文提出了运动引导的掩码自动编码器 (MGMAE),它通过运动引导的掩码策略,在光流的指导下动态采样未掩码的可见 Token,从而抑制信息泄露,为掩码视频预训练构建了一个更具挑战性的任务。实验结果表明,MGMAE 性能良好,并在公平比较的条件下始终保持对现有方法的显著性能优势。此外,该策略还降低了预训练过程中过拟合的风险,使得模型能够从更长时间的预训练中受益。
相关文章:
论文阅读:MGMAE : Motion Guided Masking for Video Masked Autoencoding
MGMAE:Motion Guided Masking for Video Masked Autoencoding Abstract 掩蔽自编码(Masked Autoencoding)在自监督视频表示学习中展现了出色的表现。时间冗余导致了VideoMAE中高掩蔽比率和定制的掩蔽策略。本文旨在通过引入运动引导掩蔽策略࿰…...
记录一下 在Mac下用pyinstallter 打包 Django项目
安装: pip install pyinstaller 在urls.py from SheepMasterOneToOne import settings from django.conf.urls.static import staticurlpatterns [path("admin/", admin.site.urls),path(generate_report/export/, ReportAdmin(models.Report, admin.site).generat…...
【漫话机器学习系列】084.偏差和方差的权衡(Bias-Variance Tradeoff)
偏差和方差的权衡(Bias-Variance Tradeoff) 1. 引言 在机器学习模型的训练过程中,我们常常面临一个重要的挑战:如何平衡 偏差(Bias) 和 方差(Variance),以提升模型的泛…...
deepseek本地部署-linux
1、官网推荐安装方法(使用脚本,我绕不过github,未采用) 登录ollama下载网站https://ollama.com/download/linux,linux下有下载脚本。 正常来说,在OS系统下直接执行脚本即可。 2、手动安装方法 2.1获取ol…...

解决使用python提取word文档中所有的图片时图片丢失的问题
python解析word文档,提取文档中所有的图片并保存,并将原图位置用占位符替换。 问题描述 利用python-dox库解析word文档,并提取里面的所有图片时发现会出现一摸一样的图片只解析一次,导致图片丢失,数量不对的情况。 …...

【Spring相关知识】Spring应用如何优雅使用消息队列
文章目录 概述**核心概念****使用场景****快速入门**1. 添加依赖2. 配置 Binder3. 定义消息通道4. 发送和接收消息5. 运行应用 **高级特性****优点****适用场景** 概述 Spring Cloud Stream 是一个用于构建消息驱动微服务的框架,它基于 Spring Boot 和 Spring Inte…...

人工智能:从概念到未来
人工智能:从概念到未来 一、引言 在当今数字化时代,人工智能(Artificial Intelligence,AI)已从科幻小说和电影中的幻想逐渐走进现实,成为推动社会进步和经济发展的关键力量。它正在深刻地改变着我们的生活…...

CUDA Graph
cudaGraphLaunch 是 NVIDIA CUDA API 中的一个函数,用于在 CUDA Graphs 中启动一个已实例化的图。 CUDA Graphs 简介 CUDA Graphs 是 NVIDIA CUDA 编程模型中的一种技术,旨在优化 GPU 程序的性能。它允许将一系列连续的 GPU 操作(如计算和数…...
1343. 大小为 K 且平均值大于等于阈值的子数组数目
目录 一、题目二、思路2.1 解题思路2.2 代码尝试2.3 疑难问题 三、解法四、收获4.1 心得4.2 举一反三 一、题目 二、思路 2.1 解题思路 在遍历时维护一个统计的变量,用来统计满足条件的子数组个数 2.2 代码尝试 class Solution { public:int numOfSubarrays(vec…...
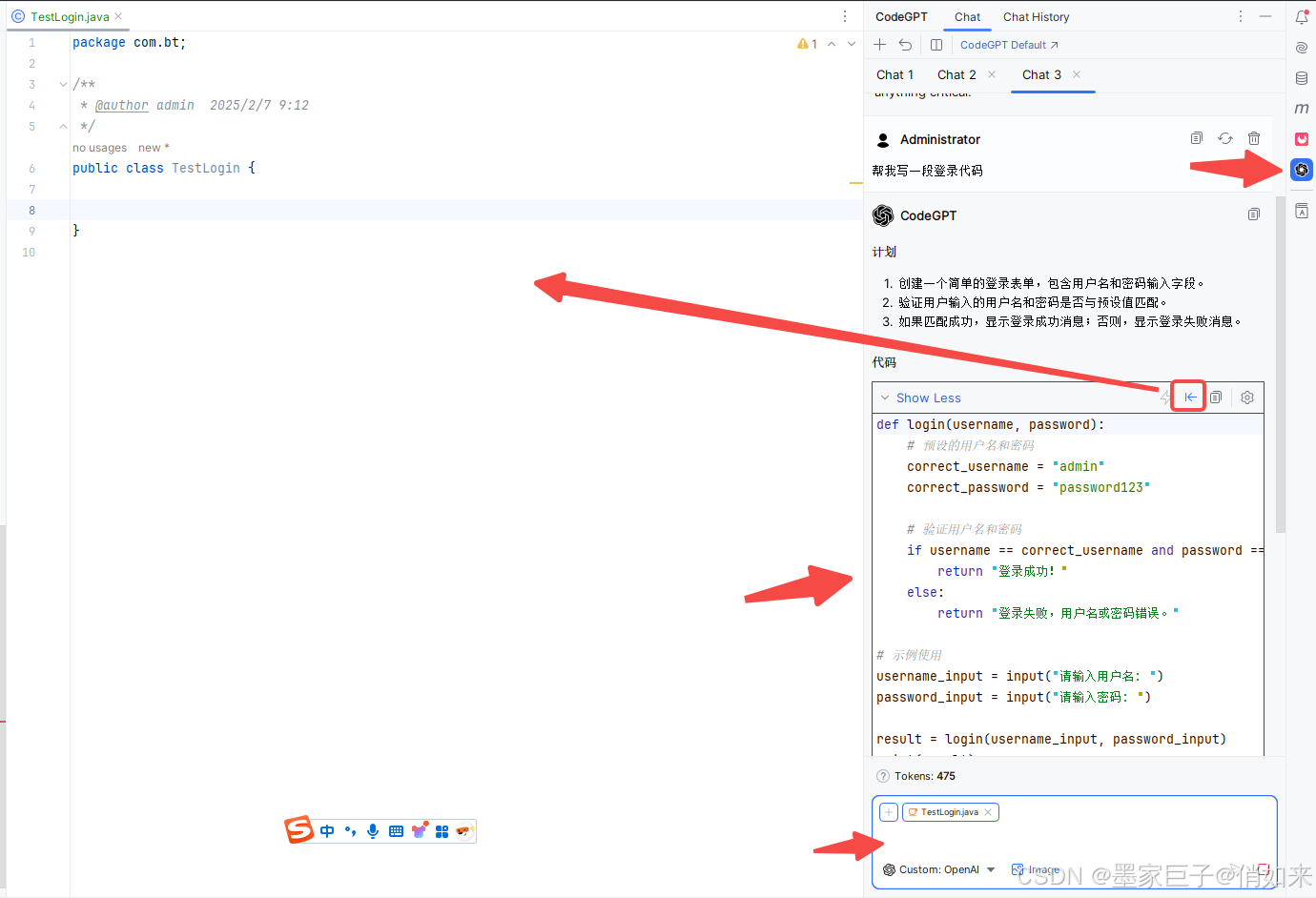
IDEA+DeepSeek让Java开发起飞
1.获取DeepSeek秘钥 登录DeepSeek官网 : https://www.deepseek.com/ 进入API开放平台,第一次需要注册一个账号 进去之后需要创建一个API KEY,然后把APIkey记录保存下来 接着我们获取DeepSeek的API对话接口地址,点击左边的:接口…...

C# winforms 使用菜单和右键菜单
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 源码指引:github源…...
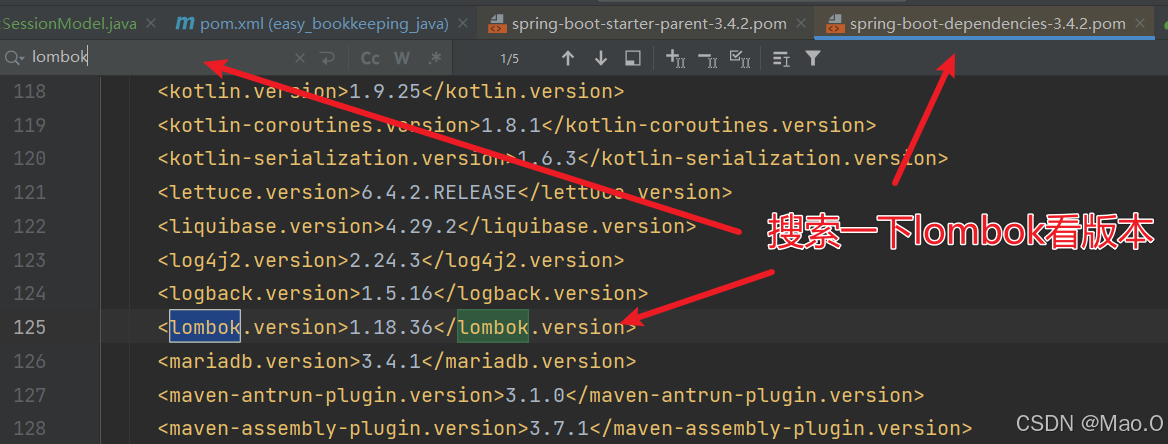
IDEA编写SpringBoot项目时使用Lombok报错“找不到符号”的原因和解决
目录 概述|背景 报错解析 解决方法 IDEA配置解决 Pom配置插件解决 概述|背景 报错发生背景:在SpringBoot项目中引入Lombok依赖并使用后出现"找不到符号"的问题。 本文讨论在上述背景下发生的报错原因和解决办法,如果仅为了解决BUG不论原…...
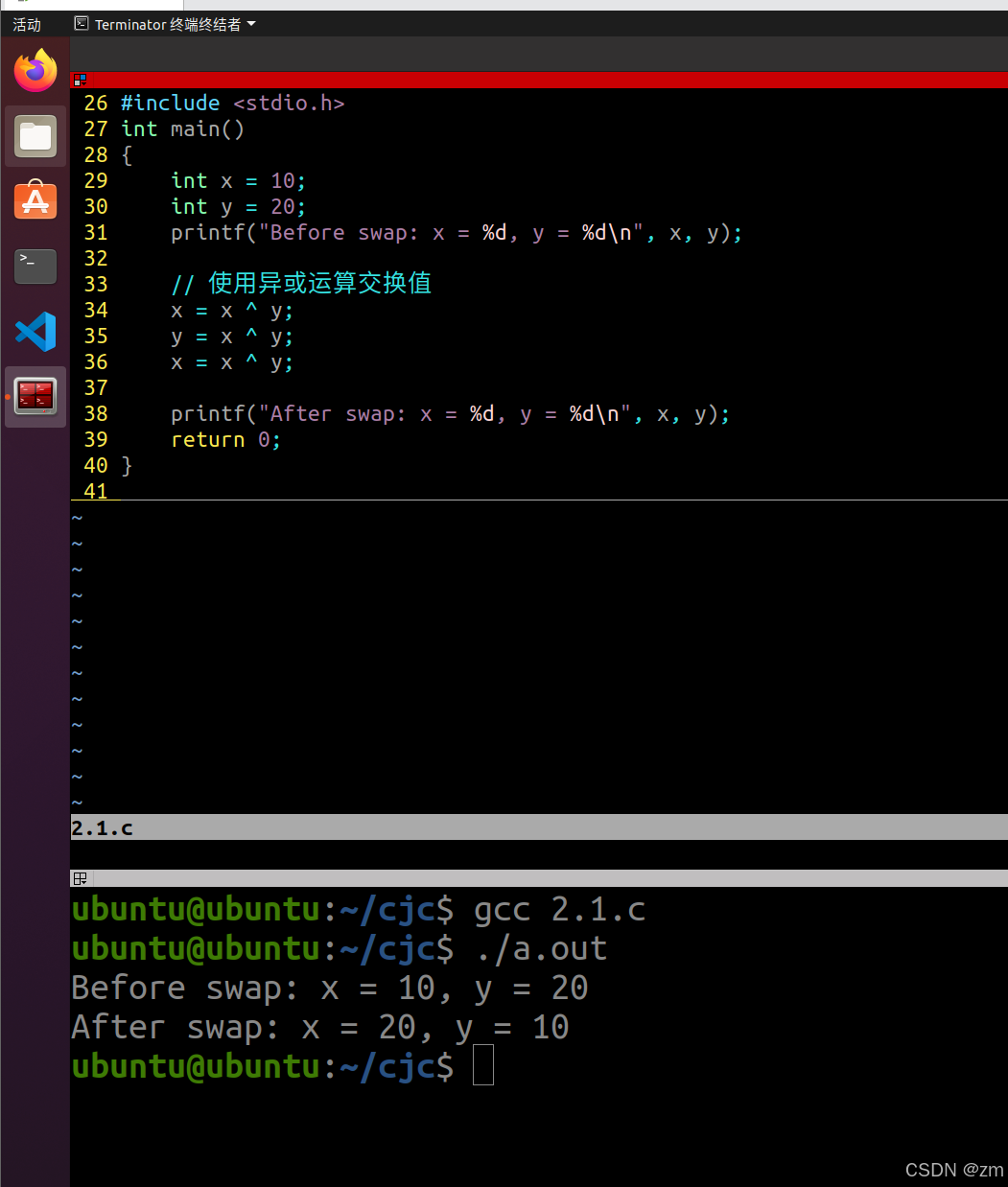
C基础寒假练习(6)
一、终端输入行数,打印倒金字塔 #include <stdio.h> int main() {int rows;printf("请输入倒金字塔的行数: ");scanf("%d", &rows);for (int i rows; i > 0; i--) {// 打印空格for (int j 0; j < rows - i; j) {printf(&qu…...
【论文翻译】DeepSeek-V3论文翻译——DeepSeek-V3 Technical Report——第一部分:引言与模型架构
论文原文链接:DeepSeek-V3/DeepSeek_V3.pdf at main deepseek-ai/DeepSeek-V3 GitHub 特别声明,本文不做任何商业用途,仅作为个人学习相关论文的翻译记录。本文对原文内容直译,一切以论文原文内容为准,对原文作者表示…...

【docker】Failed to allocate manager object, freezing:兼容兼容 cgroup v1 和 v2
参考大神让系统同时兼容 cgroup v1 和 v2 要解决你系统中只挂载了 cgroup v2 但需要兼容 cgroup v1 的问题,可以通过以下几步来使系统同时兼容 cgroup v1 和 cgroup v2。这样 Docker 和其他服务就可以正常工作了。步骤 1:更新 Grub 配置,启用兼容模式 编辑 GRUB 配置来启用同…...

我使用deepseek高效学习-分析外文网站Cron定时执行任务
最近在spring框架中 设置定时任务,有的末尾是星号有的是问号,有的是6位,有的是7位。就这个机会总结下cron表达式的使用,综合源代码中的crontab地址翻译分析,结合最近超爆的deepseek 提高学习效率,归纳总结出…...
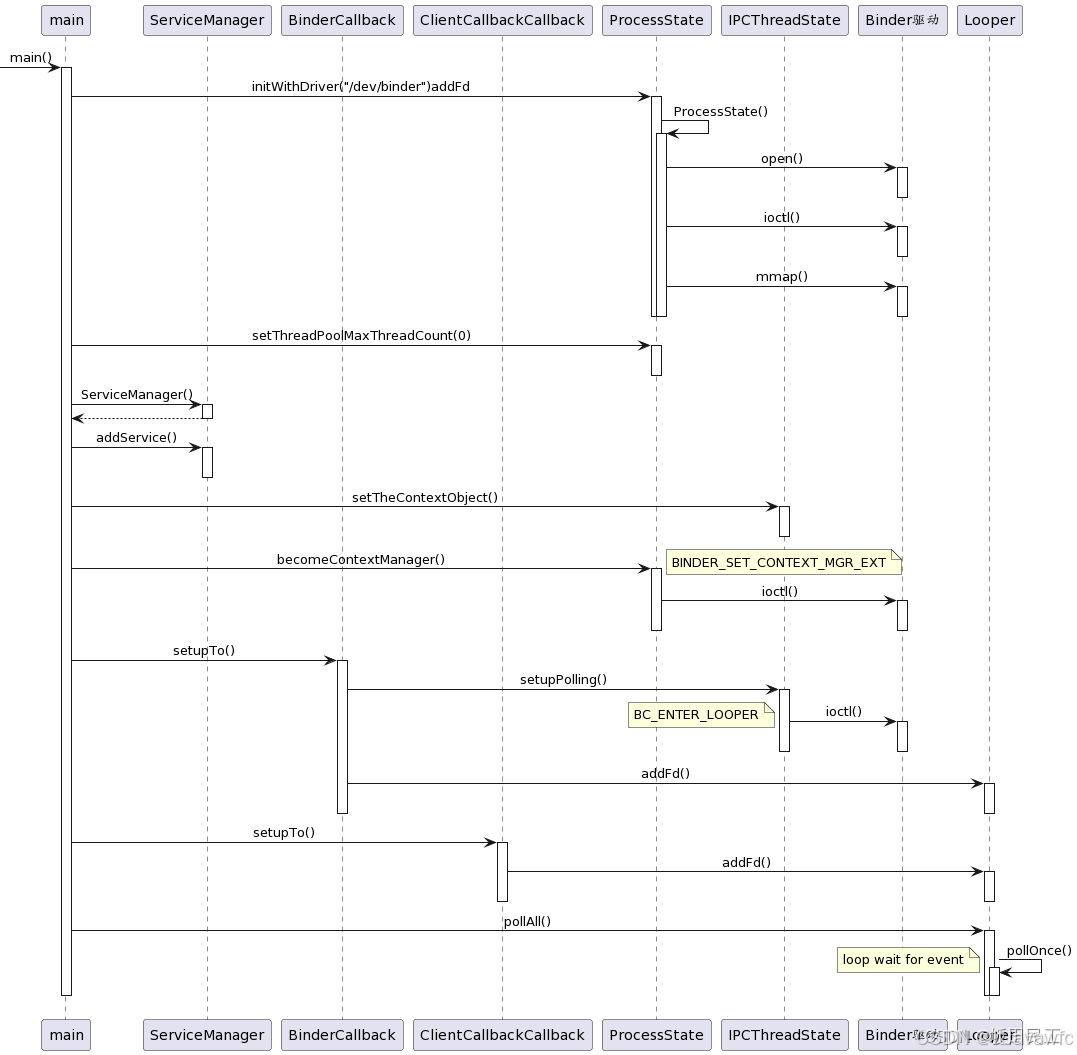
Android13-系统服务大管家-ServiceManager进程-启动篇
文章目录 关注 ServiceMager 原因ServerManager需要掌握的知识资料参考ServiceManager 进程启动启动脚本涉及到的相关源码文件源码跟踪ServiceManager脚本启动位置ServiceManager关联脚本 Native层源码分析main.cpp流程打开驱动 initWithDriverinitmakeProcessState 构造方法op…...
论文笔记:Rethinking Graph Neural Networks for Anomaly Detection
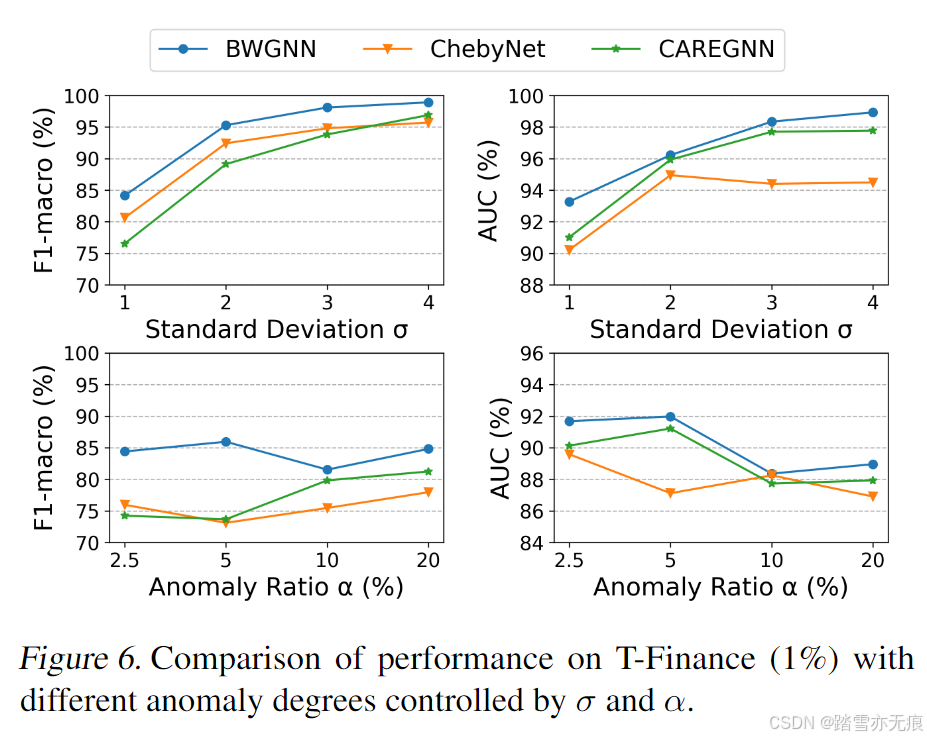
目录 摘要 “右移”现象 beta分布及其小波 实验 《Rethinking Graph Neural Networks for Anomaly Detection》,这是一篇关于图(graph)上异常节点诊断的论文。 论文出处:ICML 2022 论文地址:Rethinking Graph Ne…...

vue知识补充
1.列的样式 第一种:一列一列的写 <div class"house-detail"><div class"static-container"><form-item-static label"业主姓名">{{ baseData.mainOwnerName }}</form-item-static><form-item-static la…...

pushgateway指标聚合问题
一 问题现象 一个job有多个实例推送指标,但是从pushgateway上看这个job的instance字段,只显示一个实例的ip,而不是多个实例。导致在grafana上无法正常根据ip查看监控。 应用的prometheus的配置 management:metrics:tags:application: ${spr…...

终极UE4SS游戏Mod开发指南:从零开始掌握虚幻引擎脚本系统
终极UE4SS游戏Mod开发指南:从零开始掌握虚幻引擎脚本系统 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4S…...

模块二-数据选择与索引——06. 列选择与操作
06. 列选择与操作 1. 概述 数据选择是 Pandas 最常用的操作之一。掌握列选择与操作,可以高效地提取、添加、修改和删除数据列。 import pandas as pd import numpy as np# 创建示例数据 df pd.DataFrame({姓名: [张三, 李四, 王五, 赵六, 钱七],年龄: [25, 30, 28,…...

3PEAK思瑞浦 TPA3532-SO1R SOP8 运算放大器
特性 超低输入偏置电流:-在TA25C时最大土1pA(实验室测试限值)-在-40C至125C(实验室测试限值)下,最大土30皮安 低输入失调电压:250V(最大值)集成保护缓冲器,最大偏移电压200V低电压噪声密度:18nV/Hz(在1kHz时). 宽带宽:2.1MHz 供电电压:4.5V至16V(2.25V至…...

对比使用Taotoken前后,个人开发者的月度AI调用成本变化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比使用Taotoken前后,个人开发者的月度AI调用成本变化 在原型开发与日常编码辅助中,频繁调用大模型API已成…...

对比直接使用官方 API,Taotoken 在批量处理任务中的用量可视化优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API,Taotoken 在批量处理任务中的用量可视化优势 当开发团队或个人开发者需要处理大量文本生成任务时…...

电子仪器CE标志合规:从技术文件到尽职调查的完整指南
1. CE标志合规:从品牌声誉到技术文件的完整闭环在电子设计与制造领域,无论你开发的是精密的数据采集卡、复杂的信号发生器,还是看似简单的万用表,只要你的产品最终要进入欧洲经济区(EEA)市场,CE…...

网站国产化改造怎么做?深度解读国产化替代路径与CMS推荐
在近年来科技领域的舆论场中,“国产化”无疑是出现频率最高的关键词之一。从芯片到操作系统,从数据库到办公软件,再到企业对外展示的门户——网站,国产化替代已从“可选项”变成了很多行业的“必答题”。但国产化仅仅是“换个牌子…...

Apollo Save Tool:3步解决PlayStation存档管理难题的终极方案
Apollo Save Tool:3步解决PlayStation存档管理难题的终极方案 【免费下载链接】apollo-ps4 Apollo Save Tool (PS4) 项目地址: https://gitcode.com/gh_mirrors/ap/apollo-ps4 你是否曾为丢失珍贵的游戏进度而懊恼?是否在主机升级时面临数百个存档…...

ComfyUI-Impact-Pack终极指南:快速掌握AI图像增强的完整教程
ComfyUI-Impact-Pack终极指南:快速掌握AI图像增强的完整教程 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: ht…...

微信自动化终极指南:5个强大功能助你高效管理微信数据
微信自动化终极指南:5个强大功能助你高效管理微信数据 【免费下载链接】wechat-toolbox WeChat toolbox(微信工具箱) 项目地址: https://gitcode.com/gh_mirrors/we/wechat-toolbox 还在为繁琐的微信数据管理而烦恼吗?微信…...