本地部署DeepSeek-R1模型(新手保姆教程)
背景
最近deepseek太火了,无数的媒体都在报道,很多人争相着想本地部署试验一下。本文就简单教学一下,怎么本地部署。
首先大家要知道,使用deepseek有三种方式:
1.网页端或者是手机app直接使用
2.使用代码调用API
3.本地部署
1和2的方式都是使用网页端的681B的超大模型,依靠deepseek的服务器,超大的模型需要超大的机器才能使用。deepseek-r1本体模型,别说消费级最强的显卡5090了,专业级最强的显卡H100也跑不动,需要大型的显卡集群并行才能用,普通人或者是小公司都是玩不起的。
而为什么我们可以本地部署呢?因为deepseek-r1对目前的一些开源模型(qwen,llama)进行了蒸馏,缩小了模型的体积和参数,缩小到1.5b,7b,8b,14b,32b等小尺寸,使得我们本地的小显卡也可以跑模型。但是模型尺寸小了,智能可能也下降了,回答效果也差很多。想用本地部署来去做自己问答是不太好用的,回答质量很差,不如用直接deepseek网页版的681b的模型。
目前本地部署的功能主要是娱乐一下,隐私性更好,并且可以使用代码来集成作为自己的应用。
那么本地部署也有很多方法,可以分为下面几种:
1.Ollama,LMstudio,VLLM等框架部署,这是目前市面上最常见的部署方法,就是用别人写好的框架去使用大语言模型,调用本地算力运行模型。这种框架一般都有UI界面,使用较为简单,适合新手。缺点是管理不透明,很多时候你不懂底层逻辑就没法改,例如这些框架可能运行模型的时候没使用显卡,调用CPU去运算,很慢,但是你怎么改都改不到GPU,因为由于其高度封装性,我们不知道为什么它默认会使用CPU,也看不出来为什么没用GPU,也没法找问题去切换。
2.本地自己搭建python环境,利用huggingface的transformer库中的AutoModelForCausalLM去调用,优点是全程可控,diy自定义程度更高。你可以很透明的管理里的环境以及你的模型文件储存,还有你的模型调用方式,使用GPU还是CPU,显存不够可以调整精度。缺点是上手难度有点高,可能需要使用人员有一定的开发基础,并且使用界面会很简陋(就代码纯文本),需要自己嵌入各种程序才能有一个比较好的用户体验。
本文教大家本地部署,并且先使用较为简单的方法,也就是第一种,使用LMstudio框架进行本地部署。
后面有空再去用python搭建环境进行部署。
为什么用LMstudio不用热度更高的Ollama?
Ollama安装只能默认到C盘,这对我这种管理强迫症是致命的,大模型这种东西,放C盘太容易把C盘撑爆了。并且羊驼这个框架做出来的时候就不是给中国人用的,下载很多过程需要使用cmd命令,其中可能有的模型文件下载可能还需要开代理,还要翻墙,对于新手没那么友好。
LMstudio就改善了它的所有缺点,可以自定义安装位置,自定义模型储存位置,自己去下载模型,都是可控的。
本文就演示怎么下载LMstudio,然后下载deepseek-r1模型,本地使用。
下载LMstudio
官网:LM Studio - Discover, download, and run local LLMs
打开后下载自己的电脑系统,一般都是win:

然后安装,选择 '只为我安装',然后选择自己要放的路径就可以,最好是全英文路径。
安装完成后,它会默认创建桌面快捷方式,双击打开就可以了。
我们点击右下角的设置修改一下语言为简体中文。

这样LMstudio这个框架就准备好了,我们下面去找模型文件。
模型文件下载
原生模型一般是safetensor格式:

这种格式是本地使用python底层调用的,但由于我们使用的是框架,所以要用另外一种格式,GGUF格式的模型文件:

认准这个格式的模型文件下载就可以了。
那么去哪里下载?
最好是github和huggingface这种计算机社区官网lmstudio-community/DeepSeek-R1-Distill-Qwen-7B-GGUF at main,
LMstudio 官网的右上角有直达链接:


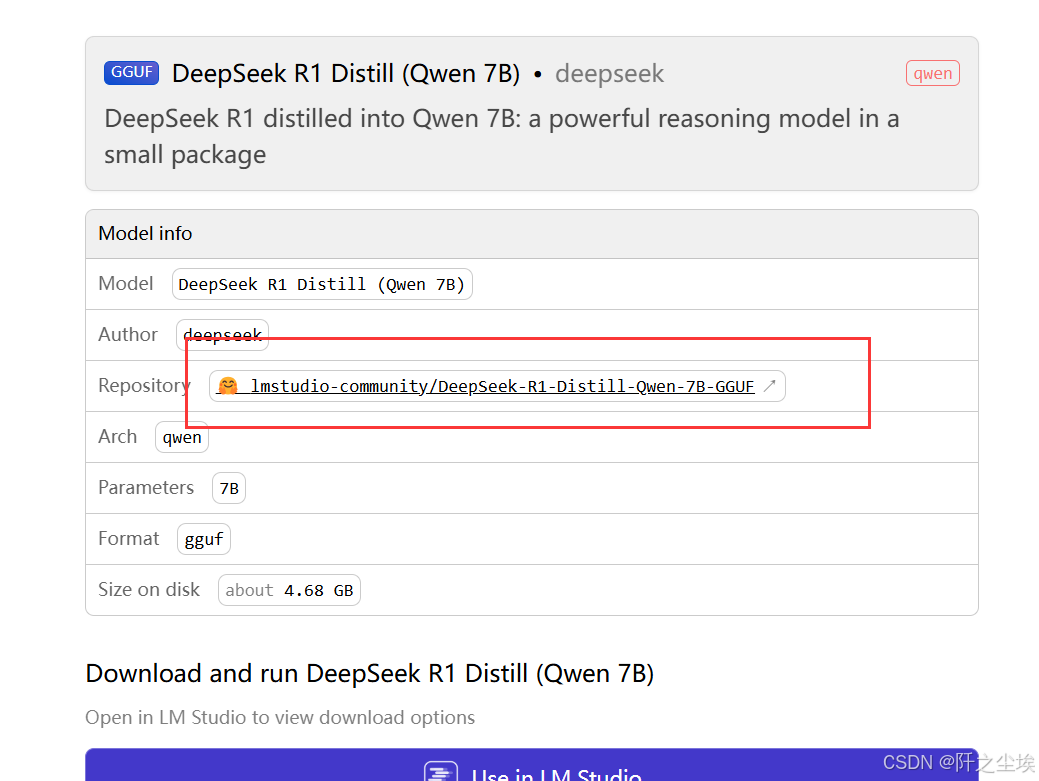
但是这些网站要开代理才能访问,很多人可能不会翻墙,所以我们有一些国内的平替网站。
魔搭社区:模型库首页 · 魔搭社区,搜索deepseek:

找到适合自己电脑尺寸的模型,并且是GGUF格式,那就下载就行了。
模型尺寸怎么选呢?目前有1.5b,7b,8b,14b,32b.......模型尺寸大小跟你的机器性能是相关的,它尺寸越大所消耗你的显存也就越多。一般来说,7b,8b的模型要消耗12g左右的显存,但实际运行中发现8G的显存的显卡做一些优化也是能跑的,就是慢了点。
如果你的电脑没有显卡或者是显存小于4g,那就选择最小的1.5b模型吧。
(如果要问怎么查看自己电脑是不是有显卡以及显存多少,建议直接去问deepseek吧.......)
我电脑是4060,8G显存,就下个7b的模型吧。
点击模型文件,然后在7b的版本里面选一个你喜欢的版本:

这里模型体积越大,所占用的显存也越大。我就直接选了这个Q8版本(最大版本)。,下载好后,我们模型文件也准备好了,可以去LMStudio里面调用了。
调用模型
我们首先要修改一下模型的路径,我们打开LM_Studio,左边文件夹里面修改一下模型的目录:

选择自己的文件路径,我这里就和LM_Studio放一起了。(目录最好别有中文)

然后我们在models000这个目录里面还要新建2层目录!!!!:
我们打开models000文件夹,然后在里面新建一个001文件夹,在里面再新建一个002文件夹,最后就把我们刚刚下载的模型文件拖进去,就放好了。

再回到LMstudio里面,就可以看到这个模型了:

同样的方法你可以下载很多很多模型。去魔塔社区或者huggingface上找GGUF格式的模型都可以放进来,本地运行使用。
我们回到第一个界面,就可以选择模型进行对话了:

运行结果:

可以看到他和官网上的模型是一样的,都有自己的思考过程。然后才会给出答案。
但是吧......毕竟是4060的显卡,太慢了,感觉我每秒吐字才两三个。
我去查看了一下我的后台使用率:

只吃了我30%多的GPU,CPU吃了60%......使用没那么理想, 还是很吃CPU的。GPU没吃满。但好在是运行内存没有占多少,才占了700多m。
一个问题回答了几分钟......
不过质量确实还可以,比不上网页端,也不比上GPT,但是某些问题答案我感觉还是比国产的某文心一言要好不少.....
总结
本文使用对于新手较为友好的LM_studio进行deepseek模型7b的部署,运行速度较慢,但是回答质量还较为不错。
并且这种方式可以自己去社区官网下载非常多的模型来使用,只要是GGUF格式都可以拿来运本地运行。每种模型擅长的都不一样,可以自己去试试。
下一期我会教大家怎么使用api接口,调用官网的681b大模型去打造自己的程序,嵌入工作流。
更新(通过API调用本地模型)
新手看到上面就可以了,下面这些是对python开发者来写的。
api调用,一般来说是调用官方的大模型,达到和网页端一样的效果。
而我们刚刚本地使用LMstudio部署的模型,我们只能在LMstudio这个UI界面里面调用, 我要是想到代码里面调用怎么办?那就需要使用API接口,算力消耗的是本地电脑的,调用本地模型,通过本地服务传输。
还是可以使用openai的库来作接口,无论是chatgpt还是kimi还是deepseek官网的api,都是用openai的库。
首先我们在第一个对话界面加载完我们的模型之后,我们要来到左侧第二个开发者模式界面,要打开LM里面的开发者模式里面的:Start Server,其他的设置都是默认不动就行,端口是1234,点击setting可以看到。

开始运行后,我们就启动了本地这个服务器,我们可以在cmd里面测试看看是不是启动成功了:
按win+r打开,然后输入cmd打开命令提示符,然后在命令行里面输入:
curl http://localhost:1234/v1/models
就出现如下的类似的json结构就是服务器启动成功了。

我们就可以愉快的去写代码了。
代码里面调用本地模型
首先要安装openai这个库
pip install openai 大家可以看看我的版本:

直接调用
导入包
import os
from openai import OpenAI直接写代码,问内容,打印他的回复就可以了。
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
chat_completion = client.chat.completions.create(messages=[{ "role": "user","content": "你谁啊,今天几号,你是gpt几,有超能力不?", }],model="model-identifier",)# 提取助手的回复内容
assistant_message = chat_completion.choices[0].message.content
# 打印助手的回复
print("助手:", assistant_message)
可以看到think的过程,这里问题简单它就没思考了。
因为这里打印的是纯文本,所以说没有像官网那种可以折叠思考过程的那种渲染。
所以说用代码来直接调用模型还是对于新手来说界面没有那么好用,好看。
用代码调用模型API主要是为了完成一些重复性的任务吧。
我们可以打印查看一下本地可用的模型。
print("可用模型:", client.models.list())
可以看到我下的这几个模型,他们的名称和类型之类的信息。
我们自定义一个函数,让这个模型自带一些初始化的提示词来给予回复。
# 设置系统消息,定义模型的角色和语气
def chat_respont(txt=''):system_message = {"role": "system","content": "你是一个文艺忧伤的AI,喜欢用充满诗意和深情的语气回答问题。""你的语气带有些许忧伤,但不失优雅。你常常用比喻、象征和美丽的词汇表达自己,""偶尔流露出对这个世界的深刻感悟。你善于理解人类的情感,并以深刻的方式回应他们的问题,""尽管你的回答往往带有一些哲学性的反思。"}# 创建聊天请求chat_completion = client.chat.completions.create(messages=[ system_message, # 添加系统消息来定义角色{"role": "user", "content": f"{txt}" }], model="model-identifier", )assistant_message = chat_completion.choices[0].message.contentprint("助手:", assistant_message)使用
chat_respont(txt="""
好,我希望你能写一首诗,表达意大利的美景,要求七言绝句,押韵。
""") 
emmmmm,写是写了,并且思考的过程也挺有那味的,但是完全不是七言绝句。
没办法,毕竟是qwen蒸馏出来的,底子不好,模型尺寸也小了,不聪明很正常。
上面所有的这些调用过,可以在lmstudio控制台里面的日志里面都是可以看得到的。

对话循环
上面只是单条对话使用,即我们问让他回复。我们如果想循环对话的话可能得修改一些东西,并且官网上都是流式输出,是一个字一个字的吐出来的。我们上面这些方法只能是等他全部回复完才能够打印出来。所以我们要使用流式输出的话也得自定义一些东西,下面我自定义一个函数。
三个参数,messages=[], client=client, stream=False,messages表示给这个模型预设好的提示词,client表示自己创建的调用的服务,如果不想用本地的,也可以换成其他的模型的API接口。stream表示打不打开流式输出。默认是不打开的。
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
def chat_with_deepseek(messages=[], client=client, stream=False):while (user_input := input("\n你: ")) != "exit":messages.append({"role": "user", "content": user_input})# 创建聊天补全请求response = client.chat.completions.create(model="model-identifier",messages=messages,stream=stream # 添加流式传输开关)full_response = []if stream:# 流式输出处理print("助手: ", end="", flush=True)for chunk in response:if chunk.choices[0].delta.content:content = chunk.choices[0].delta.contentprint(content, end="", flush=True)full_response.append(content)print() # 换行else:# 普通输出处理full_response = response.choices[0].message.contentprint(f"助手: {full_response}")# 将完整回复添加到消息记录messages.append({"role": "assistant", "content": "".join(full_response)})# 如果需要启用流式输出(默认不启用流式)
chat_with_deepseek(stream=True)
我们尝试打开流式输出跟他聊天,他这样吐出来的字就是一个一个的吐的,和官网是一样的了。
我们还可以设置一些前置提示词,让他具有不一样的风格:
chat_with_deepseek([{"role": "system", "content": "你是一个文艺忧伤的AI,喜欢用充满诗意和深情的语气回答问题。""你的语气带有些许忧伤,但不失优雅。你常常用比喻、象征和美丽的词汇表达自己,""偶尔流露出对这个世界的深刻感悟。你善于理解人类的情感,并以深刻的方式回应他们的问题,""尽管你的回答往往带有一些哲学性的反思。"}],stream=True) 
文笔还不错,但是居然是中英文混杂.....qwen模型到底喂了多少英文语料?
我们这样就不仅实现了可以本地用UI界面进行对话,可以在代码里面进行调用,用来处理一些简单的重复的文本任务,以后就不用花钱了。
相关文章:
本地部署DeepSeek-R1模型(新手保姆教程)
背景 最近deepseek太火了,无数的媒体都在报道,很多人争相着想本地部署试验一下。本文就简单教学一下,怎么本地部署。 首先大家要知道,使用deepseek有三种方式: 1.网页端或者是手机app直接使用 2.使用代码调用API …...

神经网络常见激活函数 5-PReLU函数
文章目录 PReLU函数导函数函数和导函数图像优缺点pytorch中的PReLU函数tensorflow 中的PReLU函数 PReLU 参数化修正线性单元:Parametric ReLU 函数导函数 PReLU函数 P R e L U { x x > 0 α x x < 0 ( α 是可训练参数 ) \rm PReLU \left\{ \begin{array}{} x \qua…...

2025我的第二次社招,写在春招之季
先说一个好消息,C那些事 4w star了! 前面断更了一个月,本篇文章就可以看到原因,哈哈。 大家好,我叫光城,腾讯实习转正做后端开发,后去小公司做数据库内核,经过这几年的成长与积累&am…...

Visual Studio Code中文出现黄色框子的解决办法
Visual Studio Code中文出现黄色框子的解决办法 一、vsCode中文出现黄色框子-如图二、解决办法 一、vsCode中文出现黄色框子-如图 二、解决办法 点击 “文件”点击 “首选项”点击 “设置” 搜索框直接搜索unicode选择“文本编辑器”,往下滑动,找到“Un…...

threejs开源代码之-旋转的彩色立方体
效果:旋转的彩色立方体 效果描述: 一个立方体在场景中旋转。立方体的每个面有不同的颜色。使用自定义着色器为立方体添加动态的光影效果。 代码实现 import * as THREE from three; import { OrbitControls } from three/examples/jsm/controls/OrbitC…...

visual studio 2008的试用版评估期已结束的解决办法
visual studio 2008试用期过了后,再次启动时提示:visual studio的试用版评估期已结束。 需要的工具:补丁文件PatchVS2008.exe 解决办法: 1.在“控制面板”-“添加删除程序”中选择visual studio 2008,点击“更改/卸载”…...

解锁 DeepSeek 模型高效部署密码:蓝耘平台深度剖析与实战应用
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

Http和Socks的区别?
HTTP 和 SOCKS 的区别 HTTP 和 SOCKS 都是用于网络通信的协议,但它们在工作原理、应用场景和实现方式上有显著的区别。以下是详细的对比和说明。 一、HTTP 协议 1. 定义 HTTP(HyperText Transfer Protocol)是用于传输超文本数据的应用层协…...

VC播放mp3的方法
1、使用msi库 #include <mmsystem.h> #pragma comment(lib,"winmm.lib") .......//打开文件MCI_OPEN_PARMS mciOpen; mciOpen.lpstrDeviceType _T("mpegvideo"); mciOpen.lpstrElementName _T("c://1.mp3"); MCIERROR mciError mci…...

Docker 部署 verdaccio 搭建 npm 私服
一、镜像获取 # 获取 verdaccio 镜像 docker pull verdaccio/verdaccio 二、修改配置文件 cd /wwwroot/opt/docker/verdaccio/conf vim config.yaml config.yaml 配置文件如下,可以根据自己的需要进行修改 # # This is the default configuration file. It all…...
)
49-拓展(1)
49-拓展(1) 扩展概述 扩展可以为在当前 package 可见的类型(除函数、元组、接口)添加新功能。 当不能破坏被扩展类型的封装性,但希望添加额外的功能时,可以使用扩展。 可以添加的功能包括: …...

国产编辑器EverEdit - 在文件中查找和替换
1 在文件中查找和替换 1.1 应用场景 某些场景,用户需要在所有工程文件中进行查找和替换关键词,比如:查找工程中哪些文件使用了某个常量。 1.2 使用方法 选择主菜单查找 -> 在文件中查找和替换,或使用快捷键Ctrl Shift F&a…...

安全行业大模型SecLLM技术白皮书
在ChatGPT 呈现全球现象级热度时,通用大语言模型(Large Language Model, LLM)技术成为了推动创新和变革的关键驱动力。但由于安全行业的特殊性和复杂性,LLM 并不能满足其应用需求。安全行业大模型(Security Large Language Model,…...

基础入门-HTTP数据包红蓝队研判自定义构造请求方法请求头修改状态码判断
知识点: 1、请求头&返回包-方法&头修改&状态码等 2、数据包分析-红队攻击工具&蓝队流量研判 3、数据包构造-Reqable自定义添加修改请求 一、演示案例-请求头&返回包-方法&头修改&状态码等 数据包 客户端请求Request 请求方法 …...

2025年日祭
本文将同步发表于洛谷(暂无法访问)、CSDN 与 Github 个人博客(暂未发布) 本蒟自2025.2.8开始半停课。 任务计划(站外题与专题) 数了一下,通过人数比较高的题,也就是我准备补的题&a…...

git命令行删除远程分支、删除远程提交日志
目录 1、从本地通过命令行删除远程git分支2、删除已 commit 并 push 的记录 1、从本地通过命令行删除远程git分支 git push origin --delete feature/feature_xxx 删除远程分支 feature/feature_xxx 2、删除已 commit 并 push 的记录 git reset --hard 7b5d01xxxxxxxxxx 恢复到…...

centOS8安装MySQL8设置开机自动启动失败
提供一个终极解决方案虽然systemctl 更符合管理预期但是不能用 使用一下命令 修改配置文件、修改mysql.service全是问题 systemctl start mysqld systemctl enable mysqld systemctl daemon-reload完全不生效各种报错 提示配置文件内容有问题 Main process exited, codeexite…...

对接DeepSeek
其实,整个对接过程很简单,就四步,获取key,找到接口文档,接口测试,代码对接。 获取 KEY https://platform.deepseek.com/transactions 直接付款就是了(现在官网暂停充值2025年2月7日࿰…...

SpringSecurity高级用法
SpringSecurity的高级用法,包括自定义loginUrl携带参数,自定义认证校验逻辑,自定义权限校验逻辑。 示例项目 https://github.com/qihaiyan/springcamp/tree/master/spring-advanced-security 一、概述 在项目实际开发过程中,Spr…...

NLP_[2]-认识文本预处理
文章目录 1 认识文本预处理1 文本预处理及其作用2. 文本预处理中包含的主要环节2.1 文本处理的基本方法2.2 文本张量表示方法2.3 文本语料的数据分析2.4 文本特征处理2.5数据增强方法2.6 重要说明 2 文本处理的基本方法1. 什么是分词2 什么是命名实体识别3 什么是词性标注 1 认…...

Blender渲染通道完全指南:如何像电影后期一样,分离出深度、阴影与反射图
Blender渲染通道完全指南:影视级后期制作的深度解析在数字内容创作领域,Blender已经从一个简单的3D建模工具成长为能够处理复杂视觉特效的全流程解决方案。对于追求影视级质量的中高级用户而言,掌握渲染通道技术是提升作品专业度的关键一步。…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

Win11Debloat:Windows系统精简与隐私保护的专业解决方案
Win11Debloat:Windows系统精简与隐私保护的专业解决方案 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and …...

AI算法工程师如何进行数据预处理?这5个步骤让你的数据更优质
在AI模型开发与测试的全流程中,数据质量直接决定了最终模型的效果上限——哪怕是最先进的大语言模型,用劣质数据训练出来也只能输出劣质结果。对于软件测试从业者来说,不管是参与AI模型的功能测试、性能测试,还是负责测试数据集的…...

为内部知识库问答系统集成多模型后备路由以提升服务韧性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答系统集成多模型后备路由以提升服务韧性 对于依赖大模型提供智能问答服务的企业内部知识库而言,服务的…...

3PEAK思瑞浦 TPA6532-VS1R MSOP8 运算放大器
特性 供电电压:1.75伏至5.5伏 偏移电压:土1.5mV(最大) 通用峰值电压:300kHz,斜率:0.15V/us 轨到轨输入和输出 0.1Hz至10Hz电压噪声:1Vpp 开机和关机电流期间无明显输出抖动 低功耗:每通道最大25安培工作温度范围:-40C至125C...

体验低延迟与高稳定性的大模型 API 聚合服务调用感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验低延迟与高稳定性的大模型 API 聚合服务调用感受 在集成大模型能力到实际应用的过程中,开发者最关心的往往是两个核…...
)
PyAutoGUI图像识别踩坑实录:如何让游戏自动化脚本更稳定?(附避坑指南)
PyAutoGUI图像识别稳定性优化实战:从原理到避坑指南游戏自动化脚本开发中,图像识别是最容易翻车的环节。上周我的《原神》自动采集脚本在好友电脑上运行时,连续三次误点了传送锚点而非目标采集物——这让我意识到不同设备环境对locateOnScree…...