使用Pytorch训练一个图像分类器
一、准备数据集
一般来说,当你不得不与图像、文本或者视频资料打交道时,会选择使用python的标准库将原始数据加载转化成numpy数组,甚至可以继续转换成torch.*Tensor。
- 对图片而言,可以使用Pillow库和OpenCV库
- 对视频而言,可以使用scipy库和librosa库
- 对文本而言,可以使用基于原生Python或Cython加载,或NLTK和SpaCy等。
Pytorch特别针对视觉方面创建torchvision库,其中包含能够加载ImageNet、CIFAR10和MNIST等数据集的数据加载功能,对图像的数据增强功能,即torchvision.datasets和torch.utils.data.DataLoader。
这为大家搭建数据集提供了极大的便利,避免了需要自己写样板代码的情况。
本次我们使用CIFAR10数据集。这是一个含有“飞机”、“汽车”、“鸟”、“猫”、“鹿”、“狗”、“青蛙”、“马”、“轮船”和“卡车”等10个分类的数据集。数据集中每张图像均为[C×H×W]=[3×32×32]即3通道的高32像素宽32像素的彩色图像。

CIFAR-10数据集示例
二、训练图像分类器
下面的步骤大概可以分成5个有序部分:
- 用 torchvision 载入(loading)并归一化(normalize)CIFAR10训练数据集和测试数据集
- 定义卷积神经网络(CNN)
- 定义损失函数和优化器
- 训练网络
- 测试网络
P.S. 以下给出的代码均为在CPU上运行的代码。但本人在pycharm中运行的为自己修改过的在GPU上训练的代码,示例结果和截图也都是GPU运行的结果。
2.1 载入并归一化CIFAR10数据集
用torchvision载入CIFAR10
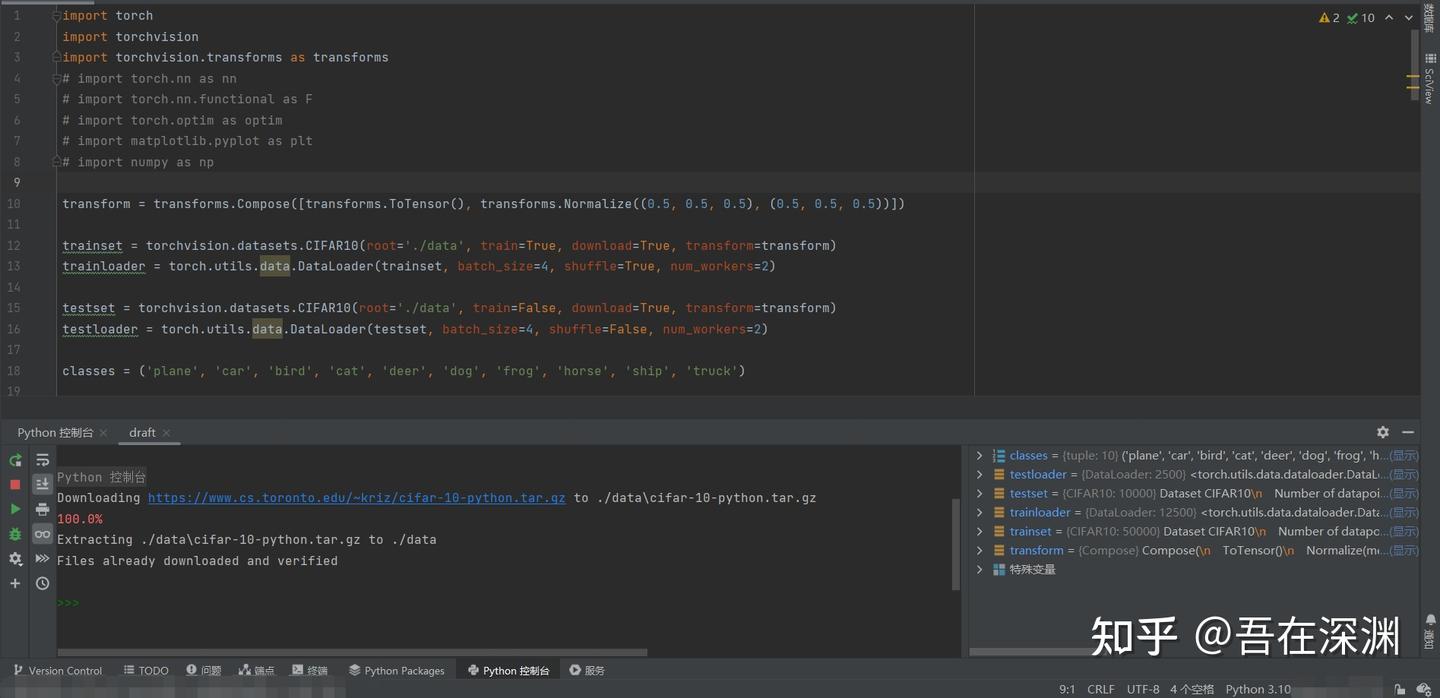
import torch
import torchvision
import torchvision.transforms as transformstorchvision加载的数据集是PILImage,数据范围[0,1]。我们需要使用transform函数将其归一化(normalize)为[-1,1]。
细心的伙伴发现了我将英文的normalize翻译成了“归一化”而不是标准化,这是因为接下来的代码你会看到预处理阶段transformer变量存储的处理操作仅仅是运用了normalize的计算规则将数据范围进行了缩放,并没有改变数据的分布,因此翻译成“归一化”更合理。
NOTE.(抄的原文,以防有小伙伴真的遇到这个意外问题)
If running on Windows and you get a BrokenPipeError,
try setting the num_worker of torch.utils.data.DataLoader() to 0。
--snip--transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])batch_size = 4trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2)testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2)classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')transform中的ToTensor和Normalize函数究竟在做什么,以及为什么要归一化等问题感兴趣的小伙伴可以阅读附录中的序号1~3文章,其中
- 博主“小研一枚”[1]通过源码为我们讲解函数的计算行为定义等知识点
- 答主"Transformer"[2]通过知乎专栏为我们做了几组代码实例。而我们则要看清文章、留言区争论的核心与我们真正求索的问题之间的区别和联系,避免被争论本身误导
- 答主“JMD”[3]则为我们科普归一化的相关知识
书归正题,上述代码第一次运行的结果可能是这样子的:
数据集加载运行日志
此时,我们可以使用numpy库和matplotlib库查看数据集中的图片和标签。
import matplotlib.pyplot as plt
import numpy as np# functions to show an image
def imshow(img):img = img / 2 + 0.5 # unnormalizenpimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.show()# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join(f'{classes[labels[j]]:5s}' for j in range(batch_size)))但是如果你就这样将代码copy+paste在pycharm中直接接续在载入数据的代码下面点击“运行”,有可能得到的是一个RuntimeError,并建议你按照惯例设置if __name__ == '__main__':
所以,我建议将目前为止的代码优化成下面的样子:
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader # 如果torch.utils.data.DataLoader()有报错提示“在 '__init__.py' 中找不到引用 'data'则增加此语句或者其他语句 ”
import matplotlib.pyplot as plt
import numpy as np
# ①←后续如果继续导入packages,请直接在这里插入代码transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])batch_size = 4trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2)testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2)classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')def imshow(img):"""显示图像的函数"""img = img / 2 + 0.5 # 去归一化npimg = img.numpy()# 上面transform.ToTensor()操作后数据编程CHW[通道靠前模式],需要转换成HWC[通道靠后模式]才能plt.imshow()plt.imshow(np.transpose(npimg, (1, 2, 0))) # 转置前将排在第0位的Channel(C)放在最后,所以是(1,2,0)plt.show()# ②←后续再有定义class、function等在此插入代码编写if __name__ == '__main__':# 随机输出一个mini-batch的图像dataiter_tr = iter(trainloader) # 取一个batch的训练集数据# images_tr, labels_tr = dataiter_tr.next() 根据你的python选择迭代器调用语句images_tr, labels_tr = next(dataiter_tr) # 切分数据和标签imshow(torchvision.utils.make_grid(images_tr)) # 生成网格图print(' '.join(f'{classes[labels_tr[j]]:5s}' for j in range(batch_size))) # 打印标签值# print(' '.join('%5s' % classes[labels_tr[j]] for j in range(batch_size))) 如果你使用python3.6之前的版本,那么有可能无法使用f字符串语句,只能使用.format()方法# ③←后续的程序执行语句在此插入输出图像示例:

随机输出一个mini-batch的训练集图像
标签输出:bird cat deer ship
2.2 定义一个卷积神经网络
可以将之前写过的识别手写数字MNIST的神经网络迁移到这里来。
# 在①后插入import代码
import torch.nn as nn
import torch.nn.functional as F# 在②后插入神经网络定义代码
class Net(nn.Module):"""定义一个卷积神经网络及前馈函数"""def __init__(self):"""初始化网络:定义卷积层、池化层和全链接层"""super().__init__() # 继承父类属性。P.S. 如果看到super(Net, self).__init__()写法亦可self.conv1 = nn.Conv2d(3, 6, 5) # 使用2套卷积核。输入(B×3×32×32),输出(B×6×28×28)self.pool = nn.MaxPool2d(2, 2) # 最大池化操作,输出时高、宽减半,(B×6×14×14) (B×16×5×5)self.conv2 = nn.Conv2d(6, 16, 5) # 使用4套卷积核,卷积核大小为5×5。(B×16×10×10)self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全链接层。将数据扁平化成一维,共400个输入,120个输出self.fc2 = nn.Linear(120, 84) # 全链接层。120个输入,84个输出self.fc3 = nn.Linear(84, 10) # 全链接层。84个输入,10个输出用于分类def forward(self, x):"""前馈函数,规定数据正向传播的规则"""x = self.pool(F.relu(self.conv1(x))) # 输入 > conv1卷积 > ReLu激活 > maxpool最大池化x = self.pool(F.relu(self.conv2(x))) # > conv2卷积 > ReLu激活 > maxpool最大池化# x = torch.flatten(x, 1) # 如果你不喜欢下一种写法实现扁平化,可以使用这条语句代替x = x.view(-1, 16 * 5 * 5) # 相当于numpy的reshape。此处是将输入数据变换成不固定行数,因此第一个参数是-1,完成扁平化x = F.relu(self.fc1(x)) # 扁平化数据 > fc1全链接层 > ReLu激活x = F.relu(self.fc2(x)) # > fc2全链接层 > ReLu激活x = self.fc3(x) # > fc3全链接层 > 输出return x# 在③后插入神经网络实例化代码
net = Net() # 实例化神经网络2.3 定义损失函数和优化器
我们使用多分类交叉熵损失函数(Classification Cross-Entropy loss)[4]和随机梯度下降法(SGD)的动量改进版(momentum)[5][6]
# 在①后插入import代码
import torch.optim as optim# 在③后插入代码
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)这里必须做一个扩展。
在2.2中我们可以看到神经网络中,每个层的输出都经过了激活函数的激活作用。但是在输出层后却缺少了激活函数而貌似“直接作用了损失函数”。
简单地说,原因就在于torch.nn.CrossEntropyLoss()将nn.LogSoftmax()激活函数和nn.NLLLoss()负对数似然损失函数集成在一起。
logsoftmax是argmax => softargmax => softmax => logsoftmax逐步优化的求极大值的index的期望的方法。负对数似然损失函数(Negtive Log Likehood)就是计算最小化真实分布 P(y|x) 与模型输出分布 P(y^|x) 的距离,等价于最小化两者的交叉熵。实际使用函数时,是one-hot编码后的标签与logsoftmax结果相乘再求均值再取反,这个过程博主“不愿透漏姓名的王建森”在他的博客中做过实验[7]讲解。
上述结论的详尽说明请参考知乎上Cassie的创作《吃透torch.nn.CrossEntropyLoss()》[8]、知乎上Gordon Lee的创作《交叉熵和极大似然估计的再理解》[9]。
P.S. 对于torch.nn.CrossEntropyLoss()的官网Doc中提到的"This is particularly useful when you have an unbalanced training set."关于如何处理不均衡样品的几个解决办法,可以参考Quora上的问答《In classification, how do you handle an unbalanced training set?》[10]以及热心网友对此问答的翻译[11]。
2.4 训练神经网络
事情变得有趣起来了!我们只需要遍历我们的迭代器,将其输入进神经网络和优化器即可。
如果想在GPU上训练请参考文章开头给出的【学习源】链接中的末尾部分有教授如何修改代码的部分。
--snip--# 在③后插入代码for epoch in range(5): # 数据被遍历的次数running_loss = 0.0 # 每次遍历前重新初始化loss值for i, data in enumerate(trainloader, 0):inputs, labels = data # 切分数据集optimizer.zero_grad() # 梯度清零,避免上一个batch迭代的影响# 前向传递 + 反向传递 + 权重优化outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# 输出日志running_loss += loss.item() # Tensor.item()方法是将tensor的值转化成python numberif i % 2000 == 1999: # 每2000个mini batches输出一次# print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000)) 如果python3.6之前版本可以使用这个代码print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')running_loss = 0.0print('Finished Training')Out:
model will be trained on device: 'cuda:0'
某一次输出结果日志整理一下如下表:

Finished Training
将loss数据整理并画图(选做):
--snip--x = np.linspace(2000, 12000, 6, dtype=np.int32)
# 数据每次训练输出都不一样,给出画图代码,至于数据,大家寄几填吧~
epoch_01 = np.array([...])
epoch_02 = np.array([...])
epoch_03 = np.array([...])
epoch_04 = np.array([...])
epoch_05 = np.array([...])plt.plot(x, epoch_01, 'ro-.', x, epoch_02, 'bo-.', x, epoch_03, 'yo-.', x, epoch_04, 'ko-.', x, epoch_05, 'go-.')
plt.legend(['Epoch_1', 'Epoch_2', 'Epoch_3', 'Epoch_4', 'Epoch_5'])
plt.xlabel('number of mini-batches')
plt.ylabel('loss')
plt.title('Loss during CIFAR-10 training procedure in Convolution Neural Networks')
plt.show()
通过数据我们可以看出loss的下降趋势:
- 第一个epoch的最明显
- 第二个epoch继续降低,但趋势更平缓
- 后三个epoch在开始较前一个epoch有较明显下降,但下降幅度递减
- *后三个epoch在该epoch内下降趋势平缓,或出现小幅震荡并保持低于前一个epoch
现在我们可以快速保存训练完成的模型到指定的路径。
--snip--PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)保存的文件

2.5 测试神经网络
我们已经用训练集数据将神经网络训练了5次(epoches=5)。但我们还需要核实神经网络是否真的学到了什么。
我们将以神经网络预测的类别标签和真实标签进行对比核实。如果预测正确,则将样本添加到正确预测列表中。
首先我们像查看训练集的一个mini batch图像一样,看一下一部分测试集图像。
--snip--dataiter_te = iter(testloader)images_te, labels_te = next(dataiter_te) # 另一种备用写法参考训练集部分imshow(torchvision.utils.make_grid(images_te))print('GroundTruth: ', ' '.join('%5s' % classes[labels_te[j]] for j in range(batch_size))) # 另一种备用写法参考训练集部分
随机输出一个mini-batch的测试集图像
Out:
GroundTruth: cat ship ship plane
下面,我们载入之前保存的模型(注:保存和再载入模型不是必要步骤,这里这么做是为了演示这些操作):
--snip--net = Net()
net.load_state_dict(torch.load(PATH))OK,现在让我们看看神经网络如何看待这些图像的分类的:
--snip--outputs = net(images) # 看一下神经网络对上述展示图片的预测结果输出的是10个分类的“能量(energy)”。某个分类的能量越高,意味着神经网络认为该图像越符合该分类。因此我们可以获得那个能量的索引。
--snip--_, predicted = torch.max(outputs, 1) # torch.max(input, dim)返回按照dim方向的最大值和其索引print('Predicted: ', ' '.join(f'{classes[predicted[j]]:5s}' for j in range(batch_size)))Out:
Predicted: cat ship ship ship
看起来不错。下面就试一试在全部测试集上的表现:
correct = 0total = 0# 由于这不是在训练模型,因此对输出不需要计算梯度等反向传播过程with torch.no_grad():for data in testloader:images_pre, labels_pre = dataoutputs = net(images_pre) # 数据传入神经网络,计算输出_, predicted = torch.max(outputs.data, 1) # 获取最大能量的索引total += labels_pre.size(0) # 计算预测次数correct += (predicted == labels_pre).sum().item() # 计算正确预测次数print(f'Accuracy of the network on the 10000 test images: {100 * correct // total} %')Out:
Accuracy of the network on the 10000 test images: 61 %

感觉预测的准确率比随机从10个类中蒙一个类(概率10%)要高,看来神经网络确实学到了一些东西。
当然,我们还可以看一下对于不同的类的学习效果:
--snip--# 生成两个dict,分别用来存放预测正确数量和总数量的个数
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}# 启动预测过程,无需计算梯度等
with torch.no_grad():for data in testloader:images_cl, labels_cl = dataoutputs = net(images_cl)_, predictions = torch.max(outputs, 1)# 开始计数for label, prediction in zip(labels_cl, predictions):if label == prediction:correct_pred[classes[label]] += 1total_pred[classes[label]] += 1# 分类别打印预测准确率
for classname, correct_count in correct_pred.items():accuracy = 100 * float(correct_count) / total_pred[classname]print(f'Accuracy for class: {classname:5s} is {accuracy:.1f} %')Out:
Accuracy for class: plane is 66.2 %
Accuracy for class: car is 80.7 %
Accuracy for class: bird is 39.1 %
Accuracy for class: cat is 53.4 %
Accuracy for class: deer is 64.6 %
Accuracy for class: dog is 35.8 %
Accuracy for class: frog is 67.9 %
Accuracy for class: horse is 69.5 %
Accuracy for class: ship is 75.0 %
Accuracy for class: truck is 65.5 %

至此,我们完成了练习!
在结束前,让我们反思一下准确率为何会呈现上述样子,我推测:
- 数据集本身缺陷,如图片太小(32×32)不足以让卷积神经网络提取到足够特征,类别划分不合理(汽车&卡车,以及飞机&鸟等较其他类别而言是否太过相似),各类别图像数量和图像本身质量等
- 数据的预处理不足,预处理阶段对数据的增强不够,是否可以加入旋转/镜像/透视、裁剪、亮度调节、噪声/平滑等处理
- 神经网络本身的结构、参数设置等是否合理,如卷积/全链接层数的规定、卷积核相关的定义、损失函数的选择、batch size/epoch的平衡等(希望可以通过学习后续的Alexnet、VGG、Resnet、FastRCNN、YOLO等受到启发)
- 避免偶然。不能以单次的结果去评价,评价应当建立在若干次重复试验的基础上
本文翻译至:Training a Classifier — PyTorch Tutorials 2.6.0+cu124 documentation
参考
- pytorch的transform中ToTensor接着Normalize http://t.csdn.cn/bCDSU
- pytorch中归一化transforms.Normalize的真正计算过程 - Transformer的文章 - 知乎 https://zhuanlan.zhihu.com/p/414242338
- 标准化/归一化的目的和作用 - JMD的文章 - 知乎 https://zhuanlan.zhihu.com/p/465264729
- Doc--torch.nn.CrossEntropyLoss CrossEntropyLoss — PyTorch 2.6 documentation
- Doc-torch.optim.SGD SGD — PyTorch 2.6 documentation
- 深度学习中常用优化器的总结 - Alex Chung的文章 - 知乎 https://zhuanlan.zhihu.com/p/166362509
- ^交叉熵的数学原理及应用——pytorch中的CrossEntropyLoss()函数 交叉熵的数学原理及应用——pytorch中的CrossEntropyLoss()函数 - 不愿透漏姓名的王建森 - 博客园
- ^吃透torch.nn.CrossEntropyLoss() - Cassie的文章 - 知乎 https://zhuanlan.zhihu.com/p/159477597
- 交叉熵和极大似然估计的再理解 - Gordon Lee的文章 - 知乎 https://zhuanlan.zhihu.com/p/165139520
- In classification, how do you handle an unbalanced training set? https://www.quora.com/In-classification-how-do-you-handle-an-unbalanced-training-set
- 如何处理训练样本不均衡的问题 http://t.csdn.cn/FDVYJ
相关文章:
使用Pytorch训练一个图像分类器
一、准备数据集 一般来说,当你不得不与图像、文本或者视频资料打交道时,会选择使用python的标准库将原始数据加载转化成numpy数组,甚至可以继续转换成torch.*Tensor。 对图片而言,可以使用Pillow库和OpenCV库对视频而言…...

《ARM64体系结构编程与实践》学习笔记(四)
MMU内存管理 1.MMU内存管理(armv8.6手册的D5章节),MMU包含快表TLB,TLB是对页表的部分缓存,页表是存放在内存里面的。 AArch64仅仅支持Long Descriptor的页表格式,AArch32支持两种页表格式Armv7-A Short De…...

01-SDRAM控制器的设计——案例总概述
本教程重点▷▷▷ 存储器简介。 介绍 SDRAM 的工作原理。 详细讲解SDRAM 控制的Verilog 实现方法。 PLL IP和FIFO IP 的调用,计数器设计,按键边沿捕获,数码管控制。 完成SDRAM控制器应用的完整案例。 Signal Tap 调试方法。 准备工作▷…...

京准:NTP卫星时钟服务器对于DeepSeek安全的重要性
京准:NTP卫星时钟服务器对于DeepSeek安全的重要性 京准:NTP卫星时钟服务器对于DeepSeek安全的重要性 在网络安全领域,分布式拒绝服务(DDoS)攻击一直是企业和网络服务商面临的重大威胁之一。随着攻击技术的不断演化…...

uniapp访问django目录中的图片和视频,2025[最新]中间件访问方式
新建中间件, middleware.py 匹配,以/cover_image/ 开头的图片 匹配以/episode_video/ 开头的视频 imageSrc: http://192.168.110.148:8000/cover_image/12345/1738760890657_mmexport1738154397386.jpg, videoSrc: http://192.168.110.148:8000/episode_video/12345/compres…...

RuoYi-Vue-Oracle的oracle driver驱动配置问题ojdbc8-12.2.0.1.jar的解决
RuoYi-Vue-Oracle的oracle driver驱动配置问题ojdbc8-12.2.0.1.jar的解决 1、报错情况 下载:https://gitcode.com/yangzongzhuan/RuoYi-Vue-Oracle 用idea打开,启动: 日志有报错: 点右侧m图标,maven有以下报误 &…...

python脚本实现windows电脑内存监控内存清理(类似rammap清空工作集功能)
import ctypes import psutil import time import sys import os from datetime import datetime import pyautogui# 检查管理员权限 def is_admin():try:return ctypes.windll.shell32.IsUserAnAdmin()except:return False# 内存清理核心功能 def cleanup_memory(aggressivene…...

【狂热算法篇】并查集:探秘图论中的 “连通神器”,解锁动态连通性的神秘力量
嘿,朋友们!喜欢这个并查集的讲解吗 记得点个关注哦,让我们一起探索算法的奥秘,别忘了一键三连,你的支持是我最大的动力! 欢迎拜访:羑悻的小杀马特.-CSDN博客 本篇主题:深度剖析并查…...

SpringBoot中实现动态数据源切换
SpringBoot中实现动态数据源切换 文章目录 SpringBoot中实现动态数据源切换SpringBoot中实现动态数据源切换基础知识1. 什么是数据源?2. 动态数据源切换的概念3. Spring Boot 中的默认数据源配置4. 动态数据源的挑战5. Spring 中的数据源切换方式 设计思路1. 明确应…...

数据结构及排序算法
数据结构 线性结构 ◆线性结构:每个元素最多只有一个出度和一个入度,表现为一条线状。线性表按存储方式分为顺序表和链表。 存储结构: ◆顺序存储:用一组地址连续的存储单元依次存储线性表中的数据元素,使得逻辑上相邻的元素物理上也相邻。 ◆链式存储:存储各数据元素的结点…...

Python基础-元组tuple的学习
在 Python 中,元组(tuple)是一种不可变的序列类型,允许存储不同类型的元素。元组非常类似于列表(list),但与列表不同的是,元组一旦创建,就不能修改其内容。 1 元组的创建…...

【手写公式识别】MEMix: Improving HMER with Diverse Formula Structure Augmentation 论文阅读
发表于:ICME 2024 原文链接:https://ieeexplore.ieee.org/document/10687521 源码:无 Abstract 手写数学表达式识别(HMER)旨在将数学表达式(MEs)的图像转换为相应的LaTeX序列。然而࿰…...

使用deepseek写一个飞机大战游戏
说明: 安装pygame:在运行代码之前,需要先安装 pygame 库。可以通过以下命令安装: pip install pygame图像文件:需要将玩家、敌人和子弹的图像文件(player.png, enemy.png, bullet.png)放在与脚本…...

用Kibana实现Elasticsearch索引的增删改查:实战指南
在大数据时代,Elasticsearch(简称 ES)和 Kibana 作为强大的数据搜索与可视化工具,受到了众多开发者的青睐。Kibana 提供了一个直观的界面,可以方便地对 Elasticsearch 中的数据进行操作。本文将详细介绍如何使用 Kiban…...

C# 封送和远程编程介绍
.NET学习资料 .NET学习资料 .NET学习资料 在 C# 编程领域中,封送(Marshaling)和远程编程(Remote Programming)是两个极为重要的概念,它们为开发者提供了与不同环境、不同进程或不同机器上的代码进行交互的…...
)
MybatisPlus较全常用复杂查询引例(limit、orderby、groupby、having、like...)
MyBatis-Plus 是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。以下是 MyBatis-Plus 中常用复杂查询(如 LIMIT、ORDER BY、GROUP BY、HAVING、LIKE 等)的引例: 1. 环境准备…...

02.07 TCP服务器与客户端的搭建
一.思维导图 二.使用动态协议包实现服务器与客户端 1. 协议包的结构定义 首先,是协议包的结构定义。在两段代码中,pack_t结构体都被用来表示协议包: typedef struct Pack {int size; // 记录整个协议包的实际大小enum Type type; …...

Jenkins数据备份到windows FTP服务器
文章目录 背景1. 安装配置 FileZilla Server(Windows)1.1 下载并安装 FileZilla Server1.2 配置 FTP 用户和共享目录 2. 安装并配置 FTP 客户端(CentOS)2.1 在 CentOS 安装 lftp 3. 编写 Jenkins 备份脚本3.1 赋予执行权限3.2 测试…...

【R语言】卡方检验
一、定义 卡方检验是用来检验样本观测次数与理论或总体次数之间差异性的推断性统计方法,其原理是比较观测值与理论值之间的差异。两者之间的差异越小,检验的结果越不容易达到显著水平;反之,检验结果越可能达到显著水平。 二、用…...

ASP.NET Core托管服务
目录 托管服务的异常问题 托管服务中使用DI 托管服务案例:数据的定时导出 场景,代码运行在后台。比如服务器启动的时候在后台预先加载数据到缓存,每天凌晨3点把数据导出到备份数据库,每隔5秒钟在两张表之间同步一次数据。托管服…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...

户外实用|艾迪欧 R6000 测评 —— 户外 / 自驾 / 露营的通讯好搭档
户外出行,通讯工具的核心是稳定、清晰、耐用、续航久、功能全。艾迪欧 R6000 作为一款兼顾专业与户外的 DMR 对讲机,全频段覆盖、双模通讯、自定义功能、长续航,完美适配自驾、露营、登山、越野等户外场景,是户外爱好者的靠谱通讯…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

FeHelper前端助手:30+开发工具集,让你的浏览器变身效率神器
FeHelper前端助手:30开发工具集,让你的浏览器变身效率神器 【免费下载链接】FeHelper 😍FeHelper--Web前端助手(Awesome!Chrome & Firefox & MS-Edge Extension, All in one Toolbox!) 项目地址:…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...
【php语法学习,iscc校赛wp】)
学习日志(三)【php语法学习,iscc校赛wp】
1. 任务 1.1.1.1.1.1. 知识部分 rce看【之前的笔记?】php的知识点学习继续jwt token好像是比赛的题目考察内容,我看看php伪协议 1.1.1.1.1.2. 题目 参加iscc比赛【五一】rce题目 1.1.1.1.1.3. 环境配置 把vscode搞好,上学期没有把Php配…...