Oracle常用导元数据方法
1 说明
前两天领导发邮件要求导出O库一批表和索引的ddl语句做国产化测试,涉及6个系统,6千多张表,还好涉及的用户并不多,要不然很麻烦。
如此大费周折原因,是某国产库无法做元数据迁移。。。额,只能我手动导出,拿去给他们同步。
考虑的方案有两个:
- 使用get_ddl查询出语句。
- 使用数据泵导元数据。
两种方式各有优点,分场景使用。
2 get_ddl查询
在需要查询的表不多,且不用导索引时,get_ddl方式比较省力。
缺点就是步骤比较多,表、索引、注释等都需要单独做查询;段属性之类的信息无法屏蔽。最大的问题是比较慢,我导出1000张表及其相关索引花了差不多4个小时,时间主要花在查询索引ddl上。
2.1 创建表清单表
将需要生成ddl的表粘到下面表中:
create table lu9up.cs_tab_250210
(owner varchar2(30) not null,table_name varchar2(30) not null
);select * from lu9up.cs_tab_250210 for update;
2.2 部署脚本
进入到某个目录下,创建script_cs_250210.sql脚本,用于跑get_ddl:
cat > script_cs_250210.sql << EOF
declarescripts varchar2(4000);cursor tab isselect owner,table_name,dbms_metadata.get_ddl('TABLE', table_name, owner) || ';' table_scriptsfrom lu9up.cs_tab_250210--where owner = '' and table_name = ''order by owner;
beginfor i in tab loopdbms_output.put_line(chr(10) || '----' || i.owner || '.' ||i.table_name);dbms_output.put_line(i.table_scripts);for j in (select to_char(dbms_metadata.get_ddl(t.index_type,t.index_name,t.owner)) || ';' scriptsfrom (select owner, index_name, 'INDEX' index_typefrom dba_indexes bwhere owner = i.ownerand not exists(select 1from dba_constraints cwhere b.owner = i.ownerand b.index_name = c.constraint_name)and table_name = i.table_nameorder by 3, 2) t) loopdbms_output.put_line(j.scripts);end loop;end loop;
end;
/
EOF
创建script_cs_250210.sh脚本,调用script_cs_250210.sql脚本:
#!/bin/bash
export ORACLE_SID=xxxdb
sqlplus -s / as sysdbba <<EOF
set lines 500
set serveroutput on
spool cs_tab_250210.sql
@script_cs_250210.sql
spool off
EOF
2.3 导出元数据到sql文件
执行script_cs_250210.sh脚本:
nohup sh script_cs_250210.sh &
结果在cs_tab_250210.sql文件。
3 数据泵导出
如果涉及到的表、索引很多的情况下,使用数据泵比较快,几千张表十来分钟就可以导出完毕了,且可读性比较高。
3.1 创建表清单表
将需要生成ddl的表粘到下面表中:
create table lu9up.cs_tab_250210
(owner varchar2(30) not null,table_name varchar2(30) not null
);select * from lu9up.cs_tab_250210 for update;
3.2 创建导出目录
创建一个具有oracle权限的导出目录:
create directory csdir as '/home/oracle/lu9up';
grant read,write on directory csdir to lu9up;
grant datapump_exp_full_database to lu9up;
grant datapump_imp_full_database to lu9up;select * from dba_directories;
3.3 生成执行语句
由于得按schema导出,执行以下sql可生成不同schema的数据泵执行语句:
select '--'||owner|| chr(10) ||'cat > cs_'||owner||'_exp_250210.par << EOF' || chr(10) ||'directory=CSDIR' || chr(10) || 'schemas='||owner||'' || chr(10) ||'include=table:"in (select table_name from lu9up.cs_tab_250210 where owner = '''||owner||''')"' ||chr(10) || 'parallel=8' || chr(10) || 'cluster=n' || chr(10) ||'content=metadata_only' || chr(10) ||'dumpfile=cs_'||owner||'_exp_250210.dmp' || chr(10) ||'logfile=cs_'||owner||'_exp_250210.log' || chr(10) || 'EOF' || chr(10) ||chr(10) ||'expdp lu9up/oracle parfile=cs_'||owner||'_exp_250210.par' ||chr(10) ||chr(10)||chr(10)|| 'cat > cs_'||owner||'_imp_250210.par << EOF' || chr(10) ||'directory=CSDIR' || chr(10)|| 'dumpfile=cs_'||owner||'_exp_250210.dmp' ||chr(10) || 'parallel=8' || chr(10) ||'exclude=grant,statistics' || chr(10) ||'transform=segment_attributes:n'|| chr(10) ||'sqlfile='||owner||'.sql' || chr(10) ||'logfile=cs_'||owner||'_imp_250210.log' || chr(10) ||'EOF' || chr(10) ||chr(10) ||'impdp lu9up/oracle parfile=cs_'||owner||'_imp_250210.par'from (select owner, count(*) ctfrom lu9up.cs_tab_250210group by ownerorder by ct desc);


有多个用户的时候就非常方便,可以直接拿去执行,不用再修改脚本。
其实也可以直接用dblink+impdp不落地导sqlfile,省去了expdp的步骤。
3.4 脚本部署
把cs_xxx_exp_250210.par和cs_xxx_imp_250210.par两个文件部署到数据库服务器,确认有oracle用户权限。

3.5 执行导出
脚本分两个,一个是使用expdp导出元数据到dmp文件,然后再用impdp将dmp文件转化为sqlfile。
expdp:
expdp lu9up/oracle parfile=cs_xxx_exp_250210.par
impdp:
impdp lu9up/oracle parfile=cs_xxx_imp_250210.par
结果生成到导出目录csdir中xxx.sql文件。
4 总结
总的来说,使用数据泵导出元数据比较符合规范,内容比较完整,阅读性高,且可以使用参数控制输出的内容。
get_ddl在少量表和索引的情况下,相对比较方便快捷。
相关文章:
Oracle常用导元数据方法
1 说明 前两天领导发邮件要求导出O库一批表和索引的ddl语句做国产化测试,涉及6个系统,6千多张表,还好涉及的用户并不多,要不然很麻烦。 如此大费周折原因,是某国产库无法做元数据迁移。。。额,只能我手动导…...

linux安装jdk 许可证确认 user did not accept the oracle-license-v1-1 license
一定要接受许可证,不然会出现 一、添加 ppa第三方软件源 sudo add-apt-repository ppa:ts.sch.gr/ppa二、更新系统软件包列表 sudo apt-get update三、接受许可证 echo debconf shared/accepted-oracle-license-v1-1 select true | sudo debconf-set-selection…...

Spring基于文心一言API使用的大模型
有时做项目我们可能会遇到要在项目中对接AI大模型 本篇文章是对使用文心一言大模型的使用总结 前置任务 在百度智能云开放平台中注册成为开发者 百度智能云开放平台 进入百度智能云官网进行登录,点击立即体验 点击千帆大模型平台 向下滑动,进入到模型…...

【Elasticsearch】derivative聚合
1.定义与用途 derivative聚合是一种管道聚合(pipeline aggregation),用于计算指定度量(metric)的变化率。它通过计算当前值与前一个值之间的差异来实现这一点。这种聚合特别适用于分析时间序列数据,例如监…...
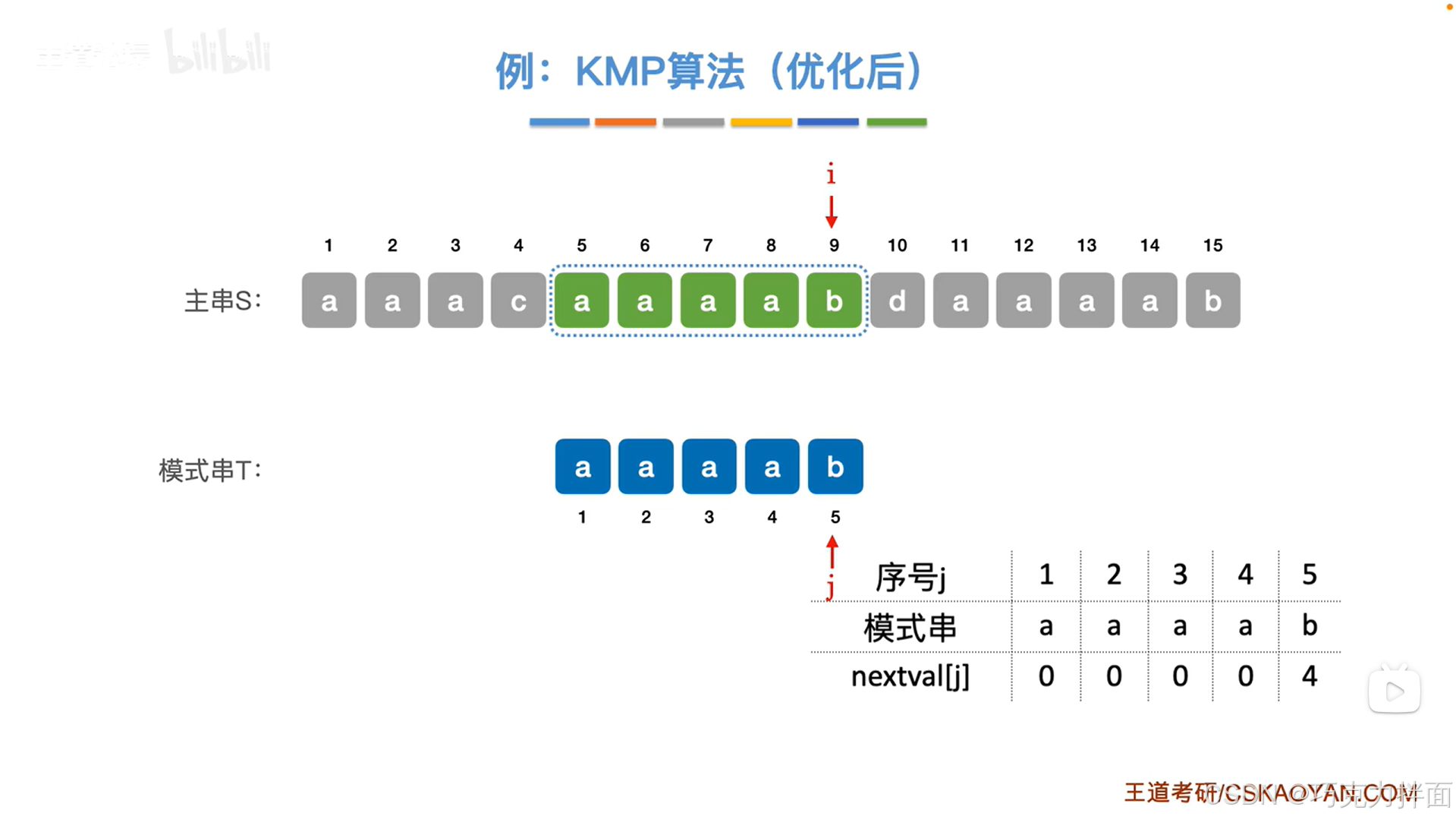
4.7.KMP算法(新版)
一.回顾:KMP算法基于朴素模式匹配算法优化而得来的 朴素模式匹配算法核心思想:把主串中所有长度与模式串长度相等的子串与模式串进行对比,直到找到第一个完全匹配的子串为止,如果当前尝试匹配的子串在某一个位置匹配失败…...

iOS AES/CBC/CTR加解密以及AES-CMAC
感觉iOS自带的CryptoKit不好用,有个第三方库CryptoSwift还不错,好巧不巧,清理过Xcode缓存后死活下载不下来,当然也可以自己编译个Framework,但是偏偏不想用第三方库了,于是研究了一下,自带的Com…...

错误报告:WebSocket 设备连接断开处理问题
错误报告:WebSocket 设备连接断开处理问题 项目背景 设备通过自启动的客户端连接到服务器,服务器将设备的 mac_address 和设备信息存入 Redis。前端通过 Redis 接口查看设备信息并展示。 问题描述 设备连接到服务器后,前端无法立即看到设…...

点云配准网络
【论文笔记】点云配准网络 PCRNet: Point Cloud Registration Network using PointNet Encoding 2019_pcr-net-CSDN博客 【点云配准】【深度学习】Windows11下PCRNet代码Pytorch实现与源码讲解-CSDN博客 【点云配准】【深度学习】Windows11下GCNet代码Pytorch实现与源码讲解_…...

黑马Redis详细笔记(实战篇---短信登录)
目录 一.短信登录 1.1 导入项目 1.2 Session 实现短信登录 1.3 集群的 Session 共享问题 1.4 基于 Redis 实现共享 Session 登录 一.短信登录 1.1 导入项目 数据库准备 -- 创建用户表 CREATE TABLE user (id BIGINT AUTO_INCREMENT PRIMARY KEY COMMENT 用户ID,phone …...

51单片机俄罗斯方块整行消除函数
/************************************************************************************************************** * 名称:flash * 功能:行清除动画 * 参数:NULL * 返回:NULL * 备注: * 采用非阻塞延时࿰…...

Vue 3 30天精进之旅:Day 21 - 项目实践:打造功能完备的Todo应用
前言 经过前20天的学习,我们已经掌握了Vue 3的核心概念、组合式API、路由、状态管理等关键技术。今天将通过一个完整的项目实践——Todo应用,将所学知识融会贯通。我们将为Todo应用添加编辑、删除、过滤等进阶功能,并优化代码结构。 一、项目…...

32单片机学习记录1之GPIO
32单片机学习记录1之GPIO 前置 GPIO口在单片机中扮演着什么角色? 在单片机中,GPIO口(General Purpose Input/Output) 是一种通用输入/输出接口,扮演着连接单片机与外部设备的桥梁角色。具体来说,它在单片…...

AI 编程助手 Cline
Cline 是一款集成于 Visual Studio Code(VS Code)的 AI 编程助手,旨在提升开发者的编程效率和代码质量。 主要功能: 代码生成与补全:Cline 能根据开发者的输入,自动生成代码片段或完整的函数,减…...

YOLOv11-ultralytics-8.3.67部分代码阅读笔记-patches.py
patches.py ultralytics\utils\patches.py 目录 patches.py 1.所需的库和模块 2.def imread(filename: str, flags: int cv2.IMREAD_COLOR): 3.def imwrite(filename: str, img: np.ndarray, paramsNone): 4.def imshow(winname: str, mat: np.ndarray): 5.PyTorch…...

R语言LCMM多维度潜在类别模型流行病学研究:LCA、MM方法分析纵向数据
全文代码数据:https://tecdat.cn/?p39710 在数据分析领域,当我们面对一组数据时,通常会有已知的分组情况,比如不同的治疗组、性别组或种族组等(点击文末“阅读原文”获取完整代码数据)。 然而,…...

2025 年前端开发现状分析:卷疯了还是卷麻了?
一、前端现状:框架狂飙,开发者崩溃 如果你是个前端开发者,那么你大概率经历过这些场景: 早上打开 CSDN(或者掘金,随便),发现又有新框架发布了,名字可能是 VueXNext.js 之…...

RDK新一代模型转换可视化工具!!!
作者:SkyXZ CSDN:SkyXZ~-CSDN博客 博客园:SkyXZ - 博客园 之前在使用的RDK X3的时候,吴诺老师wunuo发布了新一代量化转换工具链使用教程,这个工具真的非常的方便,能非常快速的完成X3上模型的量化…...

JVM春招快速学习指南
1.说在前面 在Java相关岗位的春/秋招面试过程中,JVM的学习是必不可少的。本文主要是通过《深入理解Java虚拟机》第三版来介绍JVM的学习路线和方法,并对没有过JVM基础的给出阅读和学习建议,尽可能更加快速高效的进行JVM的学习与秋招面试的备战…...

C#中的序列化和反序列化
序列化是指将对象转换为可存储或传输的格式,例如将对象转换为JSON字符串或字节流。反序列化则是将存储或传输的数据转换回对象的过程。这两个过程在数据持久化、数据交换以及与外部系统的通信中非常常见 把对象转换成josn字符串格式 这个过程就是序列化 josn字符…...

xcode常见设置
1、如何使用cmake构建archs为$(ARCHS_STANDARD)的xcode项目 在cmake中使用如下指令 set(CMAKE_OSX_ARCHITECTURES "$(ARCHS_STANDARD)") cmake - nomadli的博客 | nomadli Blog...

视频内容自动打标:基于Emotion2Vec+ Large的语音情绪分析方案
视频内容自动打标:基于Emotion2Vec Large的语音情绪分析方案 1. 引言:语音情绪分析在视频内容管理中的价值 在视频内容爆炸式增长的今天,如何高效管理和检索海量视频素材成为内容平台面临的重大挑战。传统的人工打标方式不仅效率低下&#…...

百川2-13B-Chat惊艳效果展示:同一提示词下Temperature=0.3与0.9输出对比
百川2-13B-Chat惊艳效果展示:同一提示词下Temperature0.3与0.9输出对比 你有没有想过,同一个问题问给同一个AI,为什么每次的回答都不太一样?有时候它像个严谨的学者,回答得一丝不苟;有时候又像个天马行空的…...

SpaceClaim流体域实战:从零到一构建仿真计算空间
1. 流体域基础概念与工程价值 第一次接触流体域这个概念时,我正对着电脑屏幕发愁——明明在物理世界里空气无处不在,为什么在仿真软件里非得画个"框"才能计算?这个看似简单的方盒子,后来成了我CFD生涯中最重要的"…...

3分钟,零代码!让Arduino看懂你的手势——Teachable Machine硬件魔法揭秘
3分钟,零代码!让Arduino看懂你的手势——Teachable Machine硬件魔法揭秘 【免费下载链接】teachablemachine-community Example code snippets and machine learning code for Teachable Machine 项目地址: https://gitcode.com/gh_mirrors/te/teachab…...
)
告别串口调试助手:用Chrome浏览器直接调试Arduino/ESP32(Web Serial API实战)
浏览器直连硬件:Web Serial API在物联网开发中的高阶应用 每次调试Arduino或ESP32设备时,那些繁琐的串口助手切换、驱动安装和兼容性问题是否让您感到疲惫?现在,只需一个Chrome浏览器窗口,就能完成从设备连接到数据可…...

知识图谱入门第一步:用SpringBoot+HanLP快速构建你的中文实体识别与关系抽取Demo
知识图谱实战:基于SpringBoot与HanLP的中文实体关系抽取系统构建指南 在人工智能与大数据技术蓬勃发展的今天,知识图谱作为结构化知识的重要载体,正在智能搜索、推荐系统、金融风控等领域展现出巨大价值。但对于许多刚接触这一领域的开发者而…...

QMCDecode:解放加密音乐的格式转换专家指南
QMCDecode:解放加密音乐的格式转换专家指南 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结果存储…...

AIVideo效果震撼:输入‘量子计算科普’生成带3D动画与专家语音的12分钟视频
AIVideo效果震撼:输入‘量子计算科普’生成带3D动画与专家语音的12分钟视频 只需输入一个主题词,就能自动生成包含专业分镜、精美画面、专家级配音的完整长视频——AIVideo让视频创作变得如此简单。 1. AIVideo:一站式AI视频创作革命 当我第…...
)
告别手写C库!用Buddy-MLIR一键编译PyTorch模型到Gemmini加速器(实战避坑)
告别手写C库!用Buddy-MLIR一键编译PyTorch模型到Gemmini加速器(实战避坑) 当算法工程师面对定制硬件加速器时,最头疼的莫过于如何将训练好的模型高效部署到专用计算架构上。传统手工编写C库的方法不仅耗时费力,更成为阻…...

Go HTTP Server 性能分析与优化
Go HTTP Server 性能分析与优化 在当今高并发的互联网应用中,HTTP Server的性能直接决定了用户体验和系统稳定性。Go语言凭借其轻量级协程和高效的网络库,成为构建高性能HTTP服务的首选之一。即使使用Go,开发者仍需深入分析性能瓶颈并进行针…...