机器学习 - 进一步理解最大似然估计和高斯分布的关系
一、高斯分布得到的是一个概率吗?
高斯分布(也称为正态分布)描述的是随机变量在某范围内取值的概率分布情况。其概率密度函数(PDF)为:

其中,μ 是均值,σ 是标准差。
需要注意的是,概率密度函数的值并不直接表示概率,而是表示概率密度。要计算随机变量在某个区间内取值的概率,需要对该区间上的概率密度函数进行积分。例如,计算随机变量 X 在区间 [a, b] 内取值的概率 P(a≤X≤b)时,需要计算:

因此,高斯分布本身并不是一个具体的概率值,而是描述随机变量取值的分布情况。通过对概率密度函数进行积分,可以得到特定区间内的概率。
二、高斯分布的积分怎么计算 ?
高斯分布的概率密度函数(PDF)为:

其中,μ 是均值,σ 是标准差。
要计算随机变量 X 在区间 [a, b] 内取值的概率,即 P(a≤X≤b),需要对概率密度函数在该区间上进行积分:

然而,直接对上述函数进行积分并不容易。因此,通常采用标准化的方法,将任意均值 μ 和标准差 σ 的正态分布转换为标准正态分布(均值为 0,标准差为 1),然后使用标准正态分布的累积分布函数(CDF)来计算概率。
标准化步骤:
-
标准化变量:将随机变量 X 转换为标准正态分布的随机变量 Z:

-
转换积分区间:

-
使用标准正态分布的累积分布函数:标准正态分布的累积分布函数 Φ(z)定义为:

由于标准正态分布的累积分布函数没有初等函数形式,通常通过数值方法或查表来获取其值。
需要注意的是,虽然高斯积分(即对 e^{-x^2} 在整个实数范围内的积分)有解析解,但对于一般形式的高斯分布的积分,通常需要借助数值方法或累积分布函数来计算。
三、对于离散的数据,高斯分布得到的是一个概率吗?
高斯分布(也称为正态分布)通常用于描述连续型数据的概率分布。然而,对于离散型数据,也可以定义相应的离散高斯分布。在离散高斯分布中,随机变量取离散值,每个值对应一个概率质量。因此,对于离散数据,离散高斯分布可以为每个可能的取值分配一个概率。
需要注意的是,离散高斯分布在某些领域(如格密码学)中有特定的应用。在这些应用中,离散高斯分布用于对格点进行采样,以满足特定的概率分布要求。
总之,对于离散数据,离散高斯分布可以为每个可能的取值分配一个概率,从而描述数据的分布特征。
四、离散高斯分布和高斯分布有什么区别?在数据表达式上有区别吗?
高斯分布(也称为正态分布)和离散高斯分布主要区别在于随机变量的取值范围和相应的概率表达方式。
高斯分布:
-
取值范围:连续型随机变量,取值为实数范围内的所有连续值。
-
概率表达:使用概率密度函数(PDF)来描述,其形式为:

离散高斯分布:
-
取值范围:离散型随机变量,取值为一组离散的数值,通常是整数或特定的离散集合。
-
概率表达:使用概率质量函数(PMF)来描述,即对每个离散取值 k,定义其概率为:

其中,S 是归一化常数,确保所有概率之和为 1。
数据表达式上的区别:
-
高斯分布:由于变量取值连续,概率密度函数用于描述在特定点附近的概率密度。
-
离散高斯分布:由于变量取值离散,概率质量函数用于描述每个具体取值的概率。
需要注意的是,离散高斯分布在某些领域(如格密码学)中有特定应用。在这些应用中,离散高斯分布用于对格点进行采样,以满足特定的概率分布要求。
总之,高斯分布和离散高斯分布的主要区别在于随机变量的取值范围(连续 vs. 离散)以及相应的概率表达方式(概率密度函数 vs. 概率质量函数)。
在概率质量函数(PMF)中,归一化常数 S 的作用是确保所有离散取值的概率之和等于 1。在概率密度函数(PDF)中,归一化常数的作用是确保整个连续范围内的概率密度函数的积分等于 1。因此,归一化常数 S 在 PMF 和 PDF 中的具体数值通常不同,但它们的作用是一致的,都是为了确保总概率为 1。
五、线性回归中,采用最大似然估计,为什么不采用离散高斯分布?而是采用高斯分布?
在线性回归中,采用最大似然估计时,通常假设误差项(即模型预测值与真实值之间的差异)服从连续的高斯分布(正态分布),而不是离散高斯分布。这是因为线性回归模型主要用于处理连续型数据,目标变量通常是连续的,因此误差项也被视为连续随机变量。
原因如下:

如果采用离散高斯分布,意味着假设误差项是离散的,这与连续型目标变量的性质不符。因此,在线性回归的最大似然估计中,采用连续的高斯分布来建模误差项是更合理的选择。
需要注意的是,最小二乘法可以视为在误差项服从正态分布假设下最大似然估计的特例。因此,采用高斯分布的假设与最小二乘法的应用是一致的。
六、但是所观察的数据集是离散的独立样本,不适用离散高斯分布,这怎么理解呢?
您提到的观察数据集是离散的独立样本,这在统计建模中是常见的。虽然数据点是离散的,但在线性回归中,我们关注的是这些数据点的分布趋势和误差项的性质。
理解要点:
-
数据点的离散性:在实际应用中,收集到的数据通常是离散的独立样本。这些样本代表了从总体中抽取的有限观测值。
-
误差项的连续性假设:在线性回归模型中,假设误差项(即模型预测值与真实值之间的差异)服从均值为零、方差为 σ2 的正态分布。这个假设并不要求数据点本身是连续的,而是认为误差项在总体上呈现连续的正态分布特征。
-
中心极限定理的应用:根据中心极限定理,当多个独立随机变量的影响叠加时,其总和趋向于服从正态分布。因此,即使单个观测值是离散的,多个独立误差项的组合也可以近似为正态分布。
-
模型的适用性:线性回归模型适用于连续型因变量的预测。即使观测数据是离散的独立样本,只要满足线性回归的基本假设(如线性关系、误差项独立同分布且服从正态分布等),模型仍然有效。
综上,虽然观测数据是离散的独立样本,但在线性回归中,我们对误差项的分布作出正态分布的假设,以便于模型的建立和推导。这种方法在统计学中被广泛接受,并在实践中证明是有效的。
七、线性回归中,采用最大似然估计,既然不是离散高斯分布,为什么观察数据集在对应高斯分布的乘积,就是对应的似然估计函数呢?
在线性回归中,采用最大似然估计时,虽然观测数据集由离散的独立样本组成,但我们假设这些样本的误差项服从连续的正态分布(高斯分布)。基于这一假设,构建的似然函数是各观测值在给定模型参数下出现的概率密度的乘积。
具体理解如下:

因此,尽管观测数据是离散的独立样本,但通过假设误差项服从连续的正态分布,我们能够构建似然函数,并通过最大化该函数来估计模型参数。这种方法在统计学和机器学习中被广泛应用。
那么不应该积分吗?为什么直接乘积就是似然函数呢?
在最大似然估计(MLE)中,似然函数是通过将所有观测数据点的概率密度函数(对于连续型数据)或概率质量函数(对于离散型数据)相乘得到的。这是因为我们假设每个观测数据点是独立同分布的,因此联合概率密度(或联合概率质量)是各自概率的乘积。
为什么不需要积分?
积分通常用于计算连续随机变量在某一区间内的概率。然而,在MLE中,我们关注的是给定参数下观测数据出现的联合概率,而不是某一区间内的概率质量。因此,对于独立同分布的观测数据,直接将每个数据点的概率相乘即可得到联合概率,这就是似然函数。
总结
在最大似然估计中,由于观测数据被假设为独立同分布,因此其联合概率是各自概率的乘积。这使得似然函数可以通过将所有观测数据点的概率相乘得到,而不涉及积分运算。
八、似然函数可以看成是联合概率密度函数吗?
似然函数可以看作是观测数据的联合概率密度函数(对于离散情况是概率质量函数),但是它是考虑参数的函数,而不是数据的函数。关键是,似然函数本身不是概率分布,因此它不一定被规范化为总和或积分为1。在最大似然估计的语境中,似然函数确实是给定参数的联合PDF。
似然函数确实是基于联合概率密度函数(或概率质量函数)的表达形式,但两者在使用时有不同的解释和作用。具体来说:
-
联合概率密度函数:
当我们讨论连续随机变量时,联合概率密度函数 p(x1,x2,…,xn∣θ)描述了在给定参数 θ 的条件下,随机变量 x1,x2,…,xn 同时取某些特定值的概率“密度”。这通常被看作一个关于数据 x 的函数,在参数 θ 固定时计算数据出现的可能性。 -
似然函数:
L(θ)=p(x1,x2,…,xn∣θ)
在最大似然估计中,我们将已观测到的数据视为已知(固定),而把参数 θ 看作未知的变量。此时,似然函数就是将联合概率密度函数看作关于参数的函数,记作尽管数学表达式相同,但在似然函数中,我们关注的是不同参数值下,观测数据出现的可能性大小。注意,似然函数通常不归一化,它仅用于比较不同参数值的相对“优劣”。
总结:
- 从形式上看,似然函数就是联合概率密度函数;
- 但从用途和解释上看,当我们固定数据、将参数视为变量时,这个函数被称为似然函数,并用于估计最优参数。
这种“角色转变”的思想是最大似然估计的核心:使用数据的联合概率密度(或质量)来反过来推断参数。
相关文章:
机器学习 - 进一步理解最大似然估计和高斯分布的关系
一、高斯分布得到的是一个概率吗? 高斯分布(也称为正态分布)描述的是随机变量在某范围内取值的概率分布情况。其概率密度函数(PDF)为: 其中,μ 是均值,σ 是标准差。 需要注意的是…...

Oracle常用导元数据方法
1 说明 前两天领导发邮件要求导出O库一批表和索引的ddl语句做国产化测试,涉及6个系统,6千多张表,还好涉及的用户并不多,要不然很麻烦。 如此大费周折原因,是某国产库无法做元数据迁移。。。额,只能我手动导…...

linux安装jdk 许可证确认 user did not accept the oracle-license-v1-1 license
一定要接受许可证,不然会出现 一、添加 ppa第三方软件源 sudo add-apt-repository ppa:ts.sch.gr/ppa二、更新系统软件包列表 sudo apt-get update三、接受许可证 echo debconf shared/accepted-oracle-license-v1-1 select true | sudo debconf-set-selection…...

Spring基于文心一言API使用的大模型
有时做项目我们可能会遇到要在项目中对接AI大模型 本篇文章是对使用文心一言大模型的使用总结 前置任务 在百度智能云开放平台中注册成为开发者 百度智能云开放平台 进入百度智能云官网进行登录,点击立即体验 点击千帆大模型平台 向下滑动,进入到模型…...

【Elasticsearch】derivative聚合
1.定义与用途 derivative聚合是一种管道聚合(pipeline aggregation),用于计算指定度量(metric)的变化率。它通过计算当前值与前一个值之间的差异来实现这一点。这种聚合特别适用于分析时间序列数据,例如监…...
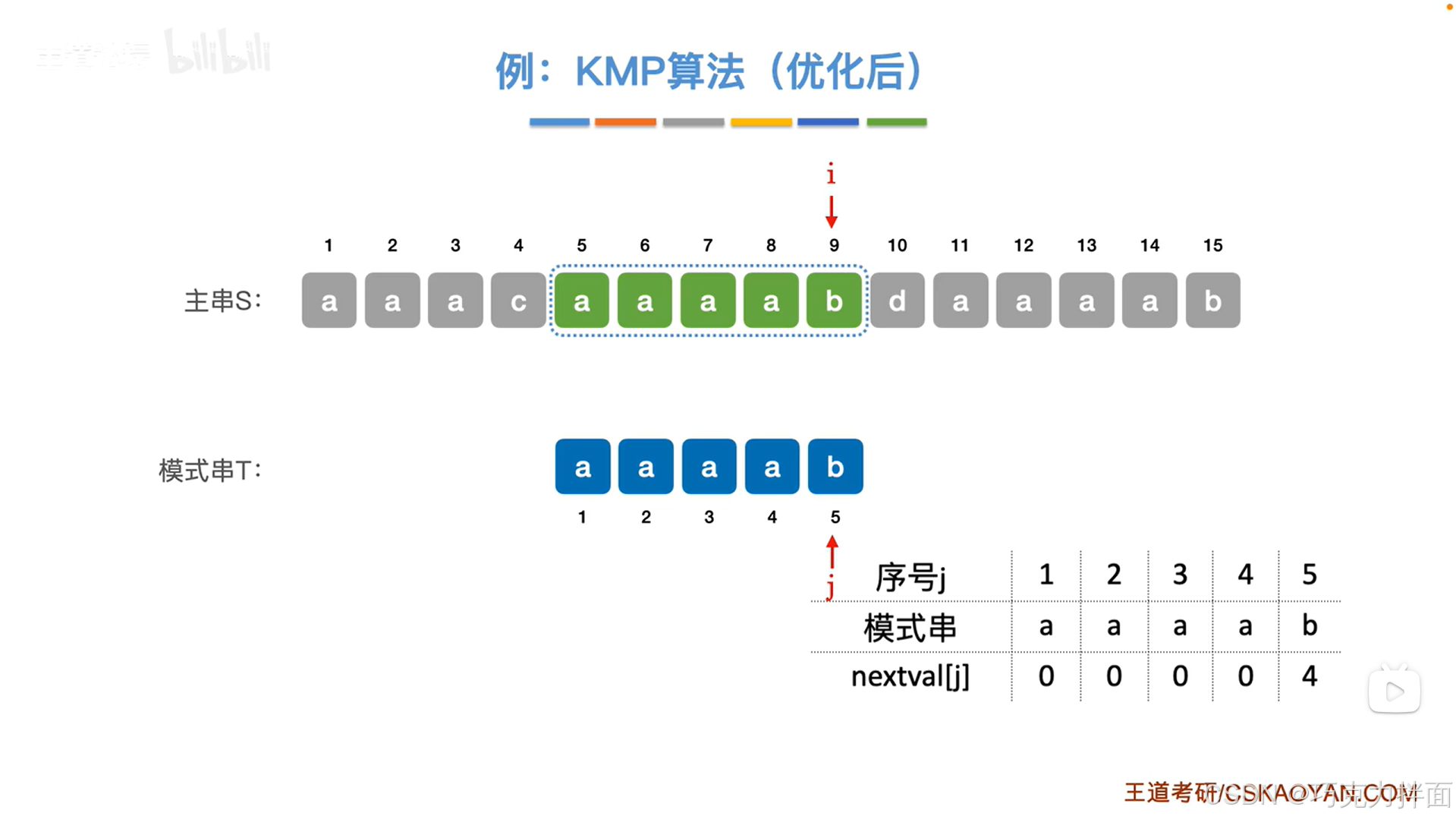
4.7.KMP算法(新版)
一.回顾:KMP算法基于朴素模式匹配算法优化而得来的 朴素模式匹配算法核心思想:把主串中所有长度与模式串长度相等的子串与模式串进行对比,直到找到第一个完全匹配的子串为止,如果当前尝试匹配的子串在某一个位置匹配失败…...

iOS AES/CBC/CTR加解密以及AES-CMAC
感觉iOS自带的CryptoKit不好用,有个第三方库CryptoSwift还不错,好巧不巧,清理过Xcode缓存后死活下载不下来,当然也可以自己编译个Framework,但是偏偏不想用第三方库了,于是研究了一下,自带的Com…...

错误报告:WebSocket 设备连接断开处理问题
错误报告:WebSocket 设备连接断开处理问题 项目背景 设备通过自启动的客户端连接到服务器,服务器将设备的 mac_address 和设备信息存入 Redis。前端通过 Redis 接口查看设备信息并展示。 问题描述 设备连接到服务器后,前端无法立即看到设…...

点云配准网络
【论文笔记】点云配准网络 PCRNet: Point Cloud Registration Network using PointNet Encoding 2019_pcr-net-CSDN博客 【点云配准】【深度学习】Windows11下PCRNet代码Pytorch实现与源码讲解-CSDN博客 【点云配准】【深度学习】Windows11下GCNet代码Pytorch实现与源码讲解_…...

黑马Redis详细笔记(实战篇---短信登录)
目录 一.短信登录 1.1 导入项目 1.2 Session 实现短信登录 1.3 集群的 Session 共享问题 1.4 基于 Redis 实现共享 Session 登录 一.短信登录 1.1 导入项目 数据库准备 -- 创建用户表 CREATE TABLE user (id BIGINT AUTO_INCREMENT PRIMARY KEY COMMENT 用户ID,phone …...

51单片机俄罗斯方块整行消除函数
/************************************************************************************************************** * 名称:flash * 功能:行清除动画 * 参数:NULL * 返回:NULL * 备注: * 采用非阻塞延时࿰…...

Vue 3 30天精进之旅:Day 21 - 项目实践:打造功能完备的Todo应用
前言 经过前20天的学习,我们已经掌握了Vue 3的核心概念、组合式API、路由、状态管理等关键技术。今天将通过一个完整的项目实践——Todo应用,将所学知识融会贯通。我们将为Todo应用添加编辑、删除、过滤等进阶功能,并优化代码结构。 一、项目…...

32单片机学习记录1之GPIO
32单片机学习记录1之GPIO 前置 GPIO口在单片机中扮演着什么角色? 在单片机中,GPIO口(General Purpose Input/Output) 是一种通用输入/输出接口,扮演着连接单片机与外部设备的桥梁角色。具体来说,它在单片…...

AI 编程助手 Cline
Cline 是一款集成于 Visual Studio Code(VS Code)的 AI 编程助手,旨在提升开发者的编程效率和代码质量。 主要功能: 代码生成与补全:Cline 能根据开发者的输入,自动生成代码片段或完整的函数,减…...

YOLOv11-ultralytics-8.3.67部分代码阅读笔记-patches.py
patches.py ultralytics\utils\patches.py 目录 patches.py 1.所需的库和模块 2.def imread(filename: str, flags: int cv2.IMREAD_COLOR): 3.def imwrite(filename: str, img: np.ndarray, paramsNone): 4.def imshow(winname: str, mat: np.ndarray): 5.PyTorch…...

R语言LCMM多维度潜在类别模型流行病学研究:LCA、MM方法分析纵向数据
全文代码数据:https://tecdat.cn/?p39710 在数据分析领域,当我们面对一组数据时,通常会有已知的分组情况,比如不同的治疗组、性别组或种族组等(点击文末“阅读原文”获取完整代码数据)。 然而,…...

2025 年前端开发现状分析:卷疯了还是卷麻了?
一、前端现状:框架狂飙,开发者崩溃 如果你是个前端开发者,那么你大概率经历过这些场景: 早上打开 CSDN(或者掘金,随便),发现又有新框架发布了,名字可能是 VueXNext.js 之…...

RDK新一代模型转换可视化工具!!!
作者:SkyXZ CSDN:SkyXZ~-CSDN博客 博客园:SkyXZ - 博客园 之前在使用的RDK X3的时候,吴诺老师wunuo发布了新一代量化转换工具链使用教程,这个工具真的非常的方便,能非常快速的完成X3上模型的量化…...

JVM春招快速学习指南
1.说在前面 在Java相关岗位的春/秋招面试过程中,JVM的学习是必不可少的。本文主要是通过《深入理解Java虚拟机》第三版来介绍JVM的学习路线和方法,并对没有过JVM基础的给出阅读和学习建议,尽可能更加快速高效的进行JVM的学习与秋招面试的备战…...

C#中的序列化和反序列化
序列化是指将对象转换为可存储或传输的格式,例如将对象转换为JSON字符串或字节流。反序列化则是将存储或传输的数据转换回对象的过程。这两个过程在数据持久化、数据交换以及与外部系统的通信中非常常见 把对象转换成josn字符串格式 这个过程就是序列化 josn字符…...

StructBERT文本相似度模型在互联网内容治理中的应用:重复与低质内容识别
StructBERT文本相似度模型在互联网内容治理中的应用:重复与低质内容识别 你有没有遇到过这样的情况?打开一个内容平台,满屏都是大同小异的文章,或者点开几篇帖子,发现内容似曾相识,只是换了几个词。对于平…...

GTE中文嵌入模型部署案例:中文新闻聚合平台热点事件发现系统
GTE中文嵌入模型部署案例:中文新闻聚合平台热点事件发现系统 1. 项目背景与需求 在信息爆炸的时代,每天都有海量的新闻内容产生。对于新闻聚合平台来说,如何从成千上万的新闻文章中快速识别出热点事件,成为了一个关键的技术挑战…...

从ReVeal到实战:基于图神经网络的智能漏洞检测技术演进与落地思考
1. 图神经网络在漏洞检测中的崛起 第一次接触代码漏洞检测领域时,我被传统方法的繁琐流程震惊了。记得当时需要手动定义数百条规则来检测缓冲区溢出漏洞,每次遇到新漏洞类型就得加班加点补充规则。直到2018年遇到ReVeal论文,才发现图神经网络…...

PT 助手 Plus:全方位提升 PT 站点种子下载体验
PT 助手 Plus:全方位提升 PT 站点种子下载体验 【免费下载链接】PT-Plugin-Plus PT 助手 Plus,为 Microsoft Edge、Google Chrome、Firefox 浏览器插件(Web Extensions),主要用于辅助下载 PT 站的种子。 项目地址: h…...

Phaser游戏中的布料模拟:高级物理效果终极指南
Phaser游戏中的布料模拟:高级物理效果终极指南 【免费下载链接】phaser Phaser is a fun, free and fast 2D game framework for making HTML5 games for desktop and mobile web browsers, supporting Canvas and WebGL rendering. 项目地址: https://gitcode.co…...

Release It! 终极自动化发布工具:5分钟配置完整版本管理流程
Release It! 终极自动化发布工具:5分钟配置完整版本管理流程 【免费下载链接】release-it 🚀 Automate versioning and package publishing 项目地址: https://gitcode.com/gh_mirrors/re/release-it Release It! 是一款强大的自动化发布工具&…...

突破限制,让老旧Mac焕发新体验:OpenCore Legacy Patcher全解析
突破限制,让老旧Mac焕发新体验:OpenCore Legacy Patcher全解析 【免费下载链接】OpenCore-Legacy-Patcher 体验与之前一样的macOS 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一款强大…...

Redis非主键索引查询实践,网友推荐:高效数据检索新方案
最近,关于使用Redis进行非主键查询的话题在开发者社区中引起了新的讨论。2024年7月,有技术博主分享了一套基于Redis Sorted Set和Hash的组合索引方案,声称在处理千万级用户数据的场景下,查询延迟降低了近70%。同年早些时候&#x…...

Empire渗透测试框架深度解析:如何构建无文件攻击链的实战指南
Empire渗透测试框架深度解析:如何构建无文件攻击链的实战指南 【免费下载链接】Empire EmpireProject/Empire: Empire 是一个开源的Post-Exploitation框架,主要用于渗透测试后的操作阶段,通过模块化的设计实现远程命令执行、持久化连接、凭证…...

OpenClaw安全防护指南:GLM-4.7-Flash执行权限管控实践
OpenClaw安全防护指南:GLM-4.7-Flash执行权限管控实践 1. 为什么需要安全防护? 上周我在调试OpenClaw自动化脚本时,差点酿成大祸。当时想让GLM-4.7-Flash模型帮我整理下载目录里的PDF文件,结果模型误解了指令,竟然试…...