Vision Transformer:打破CNN垄断,全局注意力机制重塑计算机视觉范式

目录
引言
一、ViT模型的起源和历史
二、什么是ViT?
图像处理流程
图像切分
展平与线性映射
位置编码
Transformer编码器
分类头(Classification Head)
自注意力机制
注意力图
三、Coovally AI模型训练与应用平台
四、ViT与图像分类
五、CNN与ViT对比
效率
提取特征的方式
数据需求
六、ViT用例和应用
图像分类
目标检测与分割
图像生成
多模态任务
七、ViT的挑战
大规模数据集的依赖
计算复杂度和内存消耗
长距离依赖建模的困难
八、总结
引言
ViT(Vision Transformer)是一种用于图像处理的深度学习模型,基于Transformer架构,该架构最初是为自然语言处理(NLP)任务设计的。ViT的提出打破了传统视觉神经网络(CNN)在计算机视觉中的地位主导,采用了Transformer的自注意力机制来处理图像。

随着Transformer在自然语言处理(NLP)领域的成功应用。在计算机视觉研究中,人们对视觉转换器 (ViT) 和多层感知器 (MLP) 的兴趣日益浓厚。
ViT的出现标志着计算机视觉模型的一次范式转变,它不再依赖于传统的卷积操作,而是通过Transformer的自注意力机制来处理图像数据。这一创新模型在多个大型图像分类任务中,超越了CNN的表现,并为计算机视觉带来了新的思路。
-
参考论文:https://arxiv.org/pdf/2010.11929
一、ViT模型的起源和历史
以下是关于视觉转换器(Vision Transformer)和相关模型的表格,涵盖了从2017年Transformer的诞生到2021年ViT及其变种的重要发展:

这个表格展示了Transformer架构及其在视觉任务中的发展历程,从最初的NLP模型,到BERT、GPT-3等语言模型,再到DETR、ViT及其变种在计算机视觉领域的成功应用。
二、什么是ViT?

Vision Transformer (ViT) 模型架构是在ICLR 2021上作为会议论文发表的一篇研究论文中介绍的,该论文题为“An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale”。它由Neil Houlsby、Alexey Dosovitskiy和Google Research Brain Team的另外10位作者开发和发布。
ViT的设计灵感来源于Transformer架构,最初Transformer的提出是为了处理NLP任务的序列数据(如文本),它通过自注意力捕捉机制来捕捉图像中各部分之间的全局依赖。ViT的关键创新在于,将图像数据也视为一个“序列”,而通过Transformer的自注意力机制来捕捉图像中各部分之间的全局依赖。
-
图像处理流程
ViT将输入图像分解几个固定大小的块(patches),每个块可以扣一个“图像的令牌”,然后对每个块进行展平(flatten)操作,将每个块转化为一个保护。这些处理会被形成Transformer模型,通过自注意力机制进行处理,捕获图像各部分的全局关联。

具体流程如下:
图像切分
将输入图像(例如大小为𝐻×𝑊的RGB图像)划分为多个不重叠的小块(patches),小块的尺寸通常设置𝑃×𝑃。
展平与线性映射
每个𝑃×𝑃块的大小被展平为一个一维,大小为𝑃²×𝑃,其中C是每个图像块的通道数(例如RGB三通道)。接着,通过一个线性层(又称为投影层)进行放大器映射到模型所需的维度(通常是与Transformer模型中隐藏状态相同的维度)。
位置编码
由于Transformer本身不具备空间信息的处理能力,ViT在图像块的支持上加上位置编码(Positional Encoding),以保留图像的空间结构。
Transformer编码器
这些图像块的处理(包括位置编码)作为输入确定Transformer编码器。Transformer通过自注意力机制最终处理这些输入,生成的特征表示。
分类头(Classification Head)
通过一个全连接层(Fully Connected Layer)将Transformer输出的特征映射到目标类别空间,完成分类任务。
-
自注意力机制
在ViT中,最核心的部分是自注意力机制。它通过计算输入关注之间的相关性来决定每个输入关注对其他关注的程度。简单地说,自注意力机制使得每个图像块不仅可以考虑其自身的信息,还可以从图像中的其他区域获取信息。这种全局依赖的建模对于复杂的视觉任务关系至关重要。

因此,自注意力机制会计算输入数据的加权和,其中权重是根据输入特征之间的相似性计算的。这使得模型能够更加重视相关的输入特征,从而帮助它捕获输入数据中更具信息性的表示。
所以,自注意力机制(Self-Attention)使得ViT能够在图像中建模各个区域之间的长距离依赖,而这正是ViT相对于传统卷积神经网络(CNN)的一个关键优势。
-
注意力图
在ViT的多头自注意力(Multi-Head Self-Attention,MHSA)机制中,每个输入的图像块(Patch)都会与其他图像块进行关联,并分配不同的注意力权重。

ViT的注意力图通常来自自注意力权重矩阵,该矩阵存储了所有图像块之间的注意力分布。
在ViT的每一层,注意力权重由Softmax(Q·Kᵀ/√d_k)计算得出:
![]()
计算出的Softmax(Q·Kᵀ/√d_k)形成一个𝑁×𝑁的矩阵,表示每个图像块(Patch)对其他块的注意力分布。

注意力图本质上就是这些权重的可视化,我们可以将注意力图可视化为热图网格,其中每个热图代表给定标记与所有其他标记之间的注意力权重。热图中像素的颜色越亮,相应标记之间的注意力权重就越高。通过分析注意力图,我们可以深入了解图像的哪些部分对于手头的分类任务最重要。
三、Coovally AI模型训练与应用平台
Coovally AI模型训练与应用平台,它整合了整合30+国内外开源社区1000+模型算法。

平台已部署ViT系列模型算法
在Coovally平台上,无需配置环境、修改配置文件等繁琐操作,可一键另存为我的模型,上传数据集,即可使用ViT等热门模型进行训练与结果预测,全程高速零代码!而且模型还可分享与下载,满足你的实验研究与产业应用。

四、ViT与图像分类
图像分类是计算机视觉领域的一项基本任务,涉及根据图像内容为图像分配标签。ViT是专门为了图像分类任务之一而设计的深度学习模型。多年来,像YOLOv7这样的深度CNN一直是用图像分类的SOTA方法。
然而,随着Transformer架构在自然语言处理(NLP)任务中的成功,研究人员将Transformer模型引入图像分类任务,ViT就是其中的重要成果。

计算机视觉研究表明,当使用足够量的数据进行预训练时,ViT模型至少与ResNet模型一样强大。
其他论文表明,Vision Transformer模型在隐私保护图像分类方面具有巨大潜力,并且在抗攻击性和分类准确性方面优于SOTA方法。
五、CNN与ViT对比
与CNN相比,Vision Transformer(ViT)取得了显著的成果,同时获得的预训练计算资源却少得多。与CNN相比,Vision Transformer(ViT)表现出的归纳偏差通常较弱,导致在较小的数据集上进行训练时更加依赖模型正则化或数据增强(AugReg)。

-
效率
CNN通过局部感受野进行特征提取,计算量随着网络层数量的增加而增加。而ViT由于使用自注意力机制,其计算复杂度通常为在2),其中N是输入序列的长度(即图像块的数量)。因此,ViT在处理大图像时,计算量可能会比CNN大,但随着硬件性能的提升,Transformer架构也逐渐能够在大型数据集上训练高效。
-
提取特征的方式
CNN通过拓扑操作进行特征提取,注重局部特征的学习,尤其擅长捕获空间的局部信息。而ViT则通过自注意力机制进行全局特征的学习,能够捕获图像中不同区域之间的长距离依赖。对于复杂的图像任务,ViT的全局建模能力通常能够超越CNN的局部建模。

-
数据需求
CNN模型一般能够在较小的数据集上取得训练的表现,但ViT通常需要大量的数据才能进行有效的。在数据量较小的情况下,ViT的性能可能不如 CNN。因此,ViT在数据量的任务中表现更为重要。虽然Transformer架构已成为涉及自然语言处理(NLP)的任务的最高标准,但其与计算机视觉(CV)相关的用例仍然很少。在许多计算机视觉任务中,将注意力机制与卷积神经网络(CNN)结合使用,或者在保留CNN整体结构的同时替代CNN的某些方面。流行的图像识别模型包括ResNet、VGG、YOLOv3、YOLOv7或YOLOv8以及Segment Anything(SAM)。

然而,这种对CNN的依赖并不是强制性的,直接应用于图像块序列的纯变换器可以在图像分类任务中发挥出色的作用。
六、ViT用例和应用
ViT在流行的图像识别任务中有着广泛的应用,例如物体检测、分割、图像分类和动作识别。此外,ViT在生成建模和多模态任务中也有广泛应用,包括视觉基础任务、视觉问答和视觉推理等。
-
图像分类
大规模分类:Google的ViT模型在JFT-300M等超大数据集上训练后,分类精度超越ResNet。
细粒度分类:如鸟类或植物物种识别,ViT可区分细微纹理差异(如羽毛颜色、叶片形状)。
-
目标检测与分割
自动驾驶:ViT用于道路场景中车辆、行人检测,利用全局上下文减少遮挡误判。
医疗影像:分割肿瘤区域时,ViT的长程依赖建模能识别病灶边缘的扩散特征。
-
图像生成
艺术创作:生成风格化图像时,ViT的自注意力机制能协调全局色彩与局部笔触。
数据增强:为小样本任务生成逼真训练数据(如罕见病医学影像)。
-
多模态任务
CLIP模型:OpenAI的CLIP利用ViT提取图像特征,与文本编码对齐,支持零样本图像检索。
视频理解:将视频帧序列输入ViT,结合时间建模(如TimeSformer)分析动作时序。
ViT通过其全局建模能力,正在重塑计算机视觉领域,未来或与CNN形成互补,成为多模态智能系统的核心组件。
七、ViT的挑战
虽然ViT在多个任务中取得了优异的成绩,但它也面临一些挑战,包括与架构设计、泛化、鲁棒性、可解释性和效率相关的问题。
-
大规模数据集的依赖
ViT在训练时大量的数据才能发挥其优势。由于ViT基于Transformer架构,而Transformer模型在自然语言处理(NLP)中表现出色,主要是因为它能够从大量的文本数据中学习到丰富的上下文信息。在任务关系中,ViT也需要大量的图像数据来学习有效的特征,尤其是全局。
-
计算复杂度和内存消耗
ViT的计算复杂度较高,尤其是在处理大图像时。Transformer的自注意力机制需要计算所有图像块之间的相似程度,这会导致时间和内存的消耗呈平方级增长。特别是在图像分割成更多小块时,计算的成本将显著增加。
-
长距离依赖建模的困难
虽然ViT的自注意力机制能够建模全局的长距离依赖,但在某些复杂的视觉任务中,ViT可能仍然难以捕捉图像中的长距离空间信息,特别是在较浅的层次中。
总体而言,虽然ViT的Transformer架构是视觉处理任务的一个有前途的选择,但在ImageNet等中型数据集上从头开始训练时,ViT的性能仍然不如类似规模的CNN替代方案(例如ResNet)。
八、总结
ViT模型的提出标志着计算机视觉领域的一次重要突破,展现了Transformer架构在图像处理中的潜力。相比于传统的CNN,ViT通过自注意力机制实现了全局建模,能够捕捉更复杂的图像特征,尤其在大规模数据集上的表现非常优异。尽管ViT在计算复杂度和数据需求上存在一些挑战,但随着硬件的进步和优化算法的提出,ViT无疑会成为未来计算机视觉领域的一个重要方向。
随着研究的深入,我们有理由相信,ViT和Transformer的变种将在未来的视觉任务中发挥更大的作用。

相关文章:
Vision Transformer:打破CNN垄断,全局注意力机制重塑计算机视觉范式
目录 引言 一、ViT模型的起源和历史 二、什么是ViT? 图像处理流程 图像切分 展平与线性映射 位置编码 Transformer编码器 分类头(Classification Head) 自注意力机制 注意力图 三、Coovally AI模型训练与应用平台 四、ViT与图像…...

LabVIEW国内外开发的区别
LabVIEW作为全球领先的图形化编程平台,在国内外工业测控领域均占据重要地位。本文从开发理念、技术生态、应用深度及自主可控性四个维度,对比分析国内外LabVIEW开发的差异,并结合国内实际应用场景,探讨其未来发展趋势。 一、开…...

【并发控制、更新、版本控制】.NET开源ORM框架 SqlSugar 系列
系列文章目录 🎀🎀🎀 .NET开源 ORM 框架 SqlSugar 系列 🎀🎀🎀 文章目录 系列文章目录一、并发累计(累加)1.1 单条批量累计1.2 批量更新并且字段11.3 批量更新并且字段list中对应的…...

淘宝App交易链路终端混合场景体验探索
如何应对产品形态与产品节奏相对确定情况下转变为『在业务需求与产品形态高度不确定性的情况下,如何实现业务交付时间与交付质量的确定性』。我们希望通过混合架构(Native 业务容器 Weex 2.0)作为未来交易终端架构的重要演进方向,…...

数据中心网络监控
数据中心是全球协作的特定设备网络,用来在internet网络基础设施上传递、加速、展示、计算、存储数据信息。 对于任何利用IT基础设施的企业来说,数据中心都是运营的核心,它本质上为整个业务网络托管业务应用程序和存储空间。数据中心可以是任…...

【含开题报告+文档+PPT+源码】基于springboot的汽车销售管理系统的设计与实现
开题报告 本论文聚焦于基于SpringBoot框架构建的汽车销售管理系统,该系统旨在赋能汽车销售企业实现一体化、智能化的业务运营与管理。管理员作为系统的核心员工群体,其功能权限深度集成并涵盖了登录认证、公告发布、人力资源调配、商品品牌管控、车辆信…...

flink cdc2.2.1同步postgresql表
目录 简要说明前置条件maven依赖样例代码 简要说明 在flink1.14.4 和 flink cdc2.2.1下,采用flink sql方式,postgresql同步表数据,本文采用的是上传jar包,利用flink REST api的方式进行sql执行。 前置条件 1.开启logical 确保你…...

rebase和merge
rebase 和merge区别: rebase变基,改变基底:rebase会抹去提交记录。 git pull 默认merge,git pull --rebase 变基 rebase C、D提交属于feature分支,是基于master分支,在B提交额外拉出来的,当…...

Spring boot中实现字典管理
数据库脚本 CREATE TABLE data_dict (id bigint NOT NULL COMMENT 主键,dict_code varchar(32) DEFAULT NULL COMMENT 字典编码,dict_name varchar(64) DEFAULT NULL COMMENT 字典名称,dict_description varchar(255) DEFAULT NULL COMMENT 字典描述,dict_status tinyint DEFA…...

调用DeepSeek官方的API接口
效果 前端样式体验链接:https://livequeen.top/deepseekshow 准备工作 1、注册deepseek官网账号 地址:DeepSeek 点击进入右上角【API开放平台】,并进行账号注册。 2、注册完成后,依次点击【API keys】-【生成API key】&#x…...

3.3 学习UVM中的uvm_driver 类分为几步?
文章目录 前言1. 定义2. 核心功能3. 适用场景4. 使用方法5. 完整代码示例5.1 事务类定义5.2 Driver 类定义5.3 Sequencer 类定义5.4 测试平台 6. 代码说明7. 总结 前言 以下是关于 UVM 中 uvm_driver 的详细解释、核心功能、适用场景、使用方法以及一个完整的代码示例ÿ…...

Python——批量图片转PDF(GUI版本)
目录 专栏导读1、背景介绍2、库的安装3、核心代码4、完整代码总结专栏导读 🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手 🏳️🌈 博客主页:请点击——> 一晌小贪欢的博客主页求关注 👍 该系列文章专栏:请点击——>Python办公自动化专…...

科技查新过不了怎么办
“科技查新过不了怎么办?” “科技查新不通过的原因是什么?” 想必这些问题一直困扰着各位科研和学术的朋友们,尤其是对于查新经验不够多的小伙伴,在历经千难万险,从选择查新机构、填写线上委托单到付费,…...
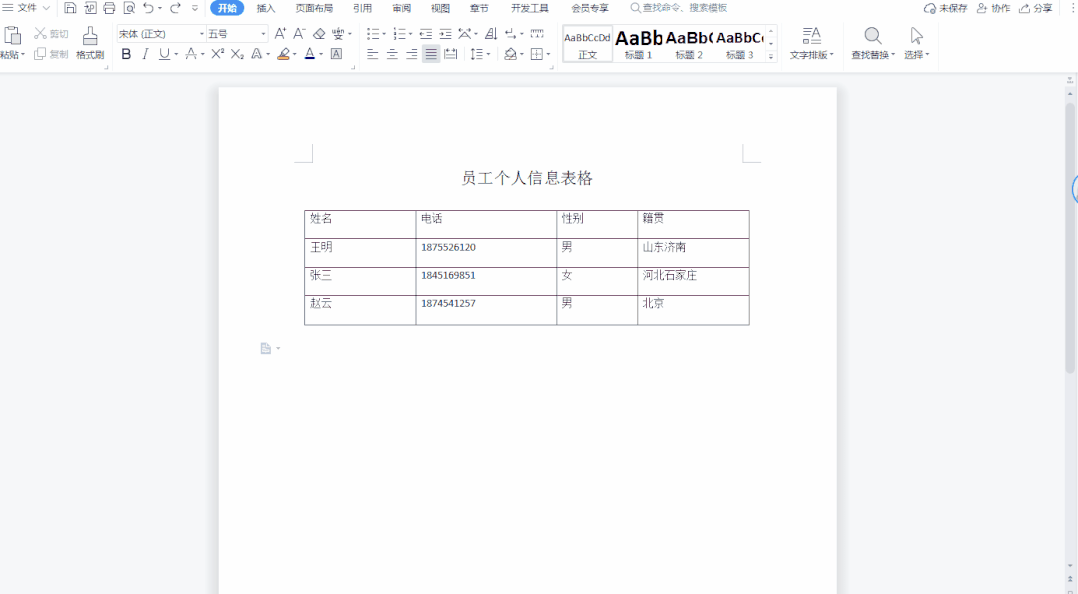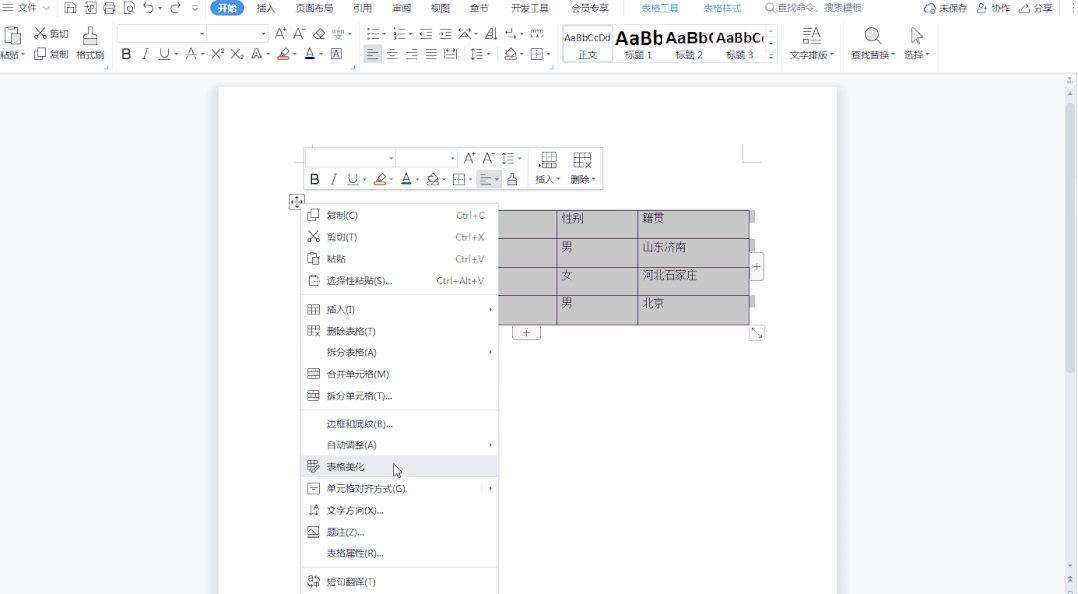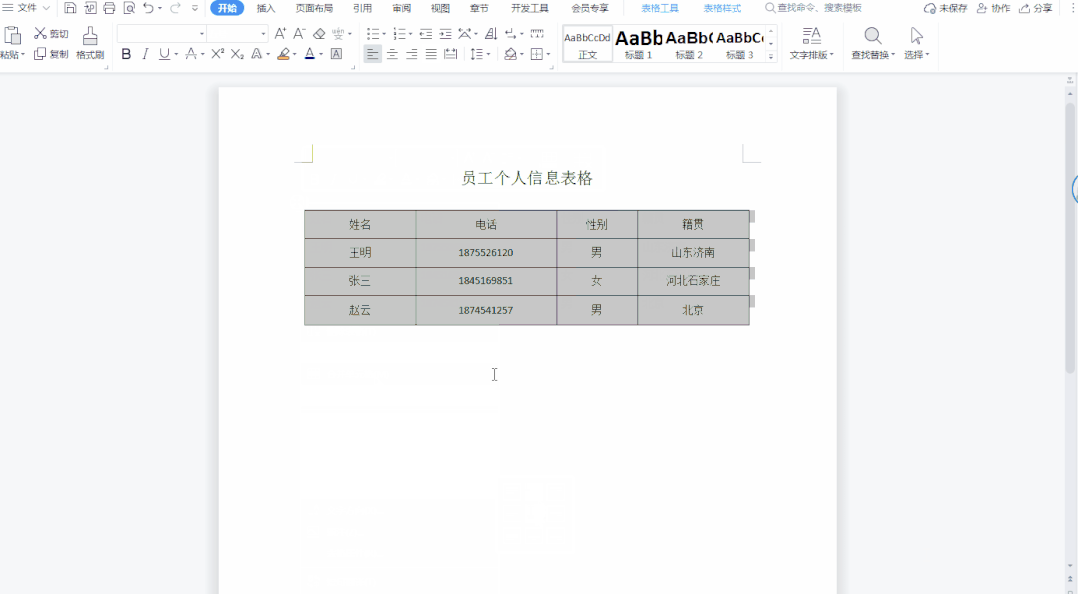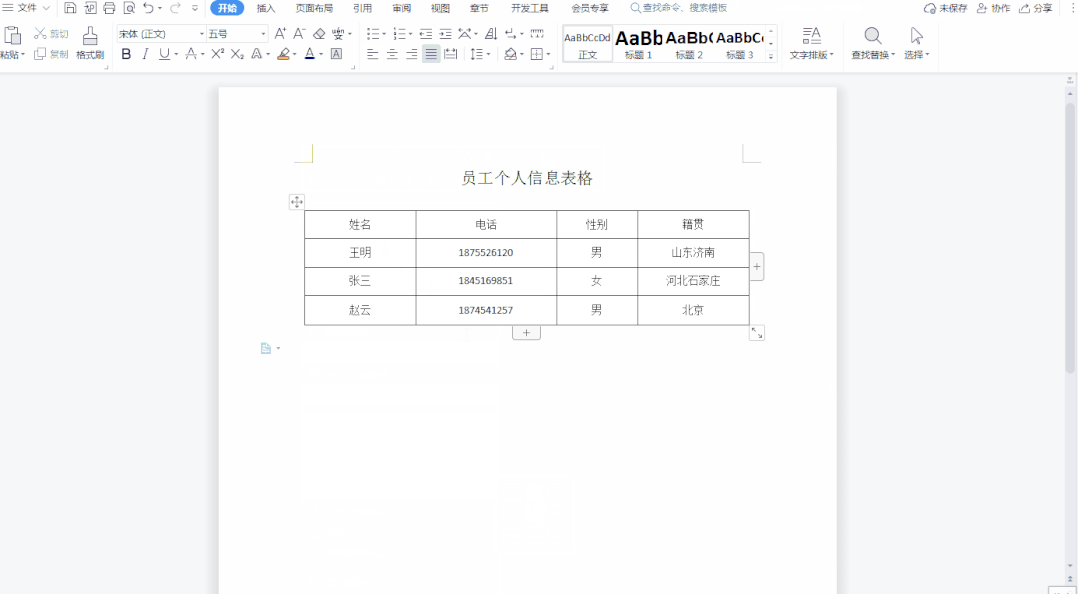
WPS中如何批量上下居中对齐word表格中的所有文字
大家好,我是小鱼。 在日常制作Word表格时,经常需要对表格中的内容进行排版。经常会把文字设置成左对齐、居中对齐或者是右对齐,这些对齐方式都比较好设置,有时制作的表格需要把文字批量上下居中对齐,轻松几步就可以搞…...

【Docker】从瀑布开发到敏捷开发
引言 软件开发方法论是指导团队如何规划、执行和管理软件项目的框架。随着软件行业的不断发展,开发方法论也在不断演进。从传统的瀑布开发到现代的敏捷开发,软件开发方法论经历了深刻的变革。本文将详细探讨瀑布开发和敏捷开发的定义、特点、优缺点以及…...

若依框架二次开发——若依介绍、环境部署及更换项目包路径
文章目录 一、若依介绍1、项目简介2、主要特性3、技术选型4、内置功能5、文件结构6、配置文件7、核心技术介绍二、环境部署1、准备工作2、运行系统3、必要配置4、部署系统三、更换项目包路径1、更换目录名称2、更换顶级目录中的pom.xml3、更换项目所有包名称4、修改application…...

【DeepSeek】在本地计算机上部署DeepSeek-R1大模型实战(完整版)
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈人工智能与大模型应用 ⌋ ⌋ ⌋ 人工智能(AI)通过算法模拟人类智能,利用机器学习、深度学习等技术驱动医疗、金融等领域的智能化。大模型是千亿参数的深度神经网络(如ChatGPT&…...

996引擎-问题处理:三职业改单职业
996引擎-问题处理:三职业改单职业 问题解决方案顺便补充点单性别设置补充:可视化配置表参考资料问题 目前的版本: 引擎版本号:2024.8.7.0 三端配套客户端:3.40.9 传统PC客户端:23.12.07 配套数据库:64_24.8.7.0此版本需要通过可视化配置表...

Redis 发生宕机时,数据怎样恢复?
当 Redis 发生宕机时,数据恢复的核心依赖于其持久化机制和备份策略。以下是结合不同场景的恢复方法及原理: 一、通过持久化机制恢复数据 1. RDB(Redis Database)快照恢复 原理:RDB 通过生成内存数据的全量快照&#…...
)
【02】RUST项目(Cargo)
文章目录 rust项目与编译创建项目检查编译运行各级目录文件作用TODO各文件作用Cargo.tomlCargo.lockRUST项目一些关键字`mod``pub``use` (`as`)`pub use`重导出(re-exporting)`crate``suer`模块系统包 Pcakagescrate模块 Modules 和 usemain.rs的例子`lib.rs`的例子拆分文件为…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...

Oracle11g安装包
Oracle 11g安装包 适用于windows系统,64位 下载路径 oracle 11g 安装包...