8.大规模推荐系统的实现
接下来我们将学习大规模推荐系统的实现。在实际应用中,推荐系统需要处理海量数据,并在短时间内生成推荐结果。这要求我们在设计和实现推荐系统时,考虑到数据的分布式存储与处理、计算的高效性和系统的可扩展性。在这一课中,我们将介绍以下内容:
- 大规模推荐系统的挑战
- 大规模推荐系统的架构设计
- 常用的大规模推荐系统技术
- 实践示例
1. 大规模推荐系统的挑战
在大规模推荐系统的实现中,面临以下几个主要挑战:
-
数据存储与管理:
- 推荐系统需要存储大量的用户行为数据和项目数据,如何高效地存储和管理这些数据是一个重要问题。
-
分布式计算:
- 推荐系统需要处理海量数据,单一服务器无法满足计算需求,需要使用分布式计算框架来进行大规模数据处理。
-
实时性要求:
- 推荐系统需要在用户交互时,实时生成推荐结果,这对系统的响应速度提出了很高的要求。
-
模型训练与更新:
- 推荐模型需要定期训练和更新,以适应用户兴趣的变化和新项目的加入。
2. 大规模推荐系统的架构设计
大规模推荐系统的架构通常包括以下几个关键组件:
-
数据收集与存储:
- 使用分布式存储系统(如HDFS、HBase、Cassandra等)来存储用户行为数据和项目数据。
- 使用流处理框架(如Apache Kafka)来收集和传输实时数据。
-
数据预处理:
- 使用分布式计算框架(如Apache Spark、Apache Flink)进行数据清洗、转换和特征提取。
-
推荐模型训练:
- 使用分布式机器学习框架(如TensorFlow on Spark、MLlib)进行推荐模型的训练和优化。
-
推荐结果生成与缓存:
- 使用高效的推荐算法生成推荐结果,并使用缓存系统(如Redis)来提高系统的响应速度。
-
推荐结果展示与反馈:
- 将推荐结果展示给用户,并收集用户的反馈数据,进一步优化推荐系统。
3. 常用的大规模推荐系统技术
实现大规模推荐系统需要使用多种技术,以下是一些常用的技术:
-
分布式存储系统:
- HDFS:Hadoop分布式文件系统,用于存储大规模数据。
- HBase:基于HDFS的分布式数据库,用于实时读写大规模数据。
- Cassandra:高可用的分布式数据库,用于存储和查询大规模数据。
-
流处理框架:
- Apache Kafka:分布式消息系统,用于收集和传输实时数据。
- Apache Flink:流处理框架,用于实时数据处理和分析。
- Apache Storm:实时计算框架,用于实时数据处理。
-
分布式计算框架:
- Apache Spark:分布式计算框架,用于大规模数据处理和分析。
- Apache Hadoop:分布式计算框架,用于大规模数据处理。
-
分布式机器学习框架:
- TensorFlow on Spark:结合TensorFlow和Spark,实现分布式机器学习。
- MLlib:Spark的机器学习库,用于大规模机器学习。
-
缓存系统:
- Redis:高效的缓存系统,用于缓存推荐结果,提高系统响应速度。
4. 实践示例
我们将通过一个简单的实例,展示如何设计和实现一个大规模推荐系统。假设我们有一个电商平台,需要根据用户的实时行为生成商品推荐。
数据收集与存储
我们将使用Apache Kafka来收集用户的实时行为数据,并使用HDFS来存储数据。
# 安装所需的库
# pip install kafka-python
# pip install hdfsfrom kafka import KafkaConsumer
from hdfs import InsecureClient
import json# 创建Kafka消费者,用于接收用户实时行为数据
consumer = KafkaConsumer('user_behavior',bootstrap_servers=['localhost:9092'],value_deserializer=lambda x: json.loads(x.decode('utf-8'))
)# 创建HDFS客户端
hdfs_client = InsecureClient('http://localhost:50070', user='hdfs')# 将用户行为数据写入HDFS
for message in consumer:user_behavior = message.valueuser_id = user_behavior['user_id']item_id = user_behavior['item_id']action = user_behavior['action']timestamp = user_behavior['timestamp']# 构建HDFS文件路径hdfs_path = f'/user_behavior/{user_id}_{item_id}_{timestamp}.json'# 将数据写入HDFSwith hdfs_client.write(hdfs_path, encoding='utf-8') as writer:writer.write(json.dumps(user_behavior))
数据预处理
我们将使用Apache Spark进行数据预处理,包括数据清洗、转换和特征提取。
# 安装所需的库
# pip install pysparkfrom pyspark.sql import SparkSession
from pyspark.sql.functions import col# 创建SparkSession
spark = SparkSession.builder \.appName('DataPreprocessing') \.getOrCreate()# 读取HDFS中的用户行为数据
user_behavior_df = spark.read.json('/user_behavior/*.json')# 数据清洗和转换
user_behavior_df = user_behavior_df.filter(col('action').isin('click', 'purchase'))# 特征提取
user_features_df = user_behavior_df.groupBy('user_id').agg(count('item_id').alias('item_count'),countDistinct('item_id').alias('distinct_item_count')
)# 将预处理后的数据存储到HDFS
user_features_df.write.parquet('/user_features')
推荐模型训练
我们将使用MLlib进行推荐模型的训练和优化。
from pyspark.ml.recommendation import ALS
from pyspark.ml.evaluation import RegressionEvaluator# 读取预处理后的数据
user_features_df = spark.read.parquet('/user_features')# 构建ALS模型
als = ALS(userCol='user_id', itemCol='item_id', ratingCol='rating', coldStartStrategy='drop')# 训练模型
als_model = als.fit(user_features_df)# 预测评分
predictions = als_model.transform(user_features_df)# 评价模型
evaluator = RegressionEvaluator(metricName='rmse', labelCol='rating', predictionCol='prediction')
rmse = evaluator.evaluate(predictions)
print(f'Root-mean-square error (RMSE): {rmse}')
推荐结果生成与缓存
我们将使用Redis缓存推荐结果,提高系统的响应速度。
# 安装所需的库
# pip install redisimport redis# 创建Redis连接
r = redis.Redis(host='localhost', port=6379, db=0)# 生成推荐结果并缓存
user_id = 1
recommendations = als_model.recommendForAllUsers(10).filter(col('user_id') == user_id).collect()# 缓存推荐结果
r.set(f'user:{user_id}:recommendations', json.dumps(recommendations))# 从缓存中获取推荐结果
cached_recommendations = r.get(f'user:{user_id}:recommendations')
if cached_recommendations:print(json.loads(cached_recommendations))
总结
在这一课中,我们介绍了大规模推荐系统的挑战、架构设计和常用技术,并通过一个实践示例展示了如何设计和实现一个大规模推荐系统。通过这些内容,你可以初步掌握大规模推荐系统的设计与实现方法。
下一步学习
在后续的课程中,你可以继续学习以下内容:
-
混合推荐系统的高级应用:
- 学习如何设计和实现更复杂的混合推荐系统,结合多种推荐算法提升推荐效果。
-
推荐系统的用户研究:
- 学习如何通过用户研究和实验设计,进一步提升推荐系统的用户体验和满意度。
-
推荐系统的安全与隐私:
- 学习如何在推荐系统中保护用户的隐私和数据安全。
希望这节课对你有所帮助,祝你在推荐算法的学习中取得成功!
相关文章:

8.大规模推荐系统的实现
接下来我们将学习大规模推荐系统的实现。在实际应用中,推荐系统需要处理海量数据,并在短时间内生成推荐结果。这要求我们在设计和实现推荐系统时,考虑到数据的分布式存储与处理、计算的高效性和系统的可扩展性。在这一课中,我们将…...
第三届通信网络与机器学习国际学术会议(CNML 2025)
在线投稿: 学术会议-学术交流征稿-学术会议在线-艾思科蓝 通信网络机器学习 通信理论 通信工程 计算机网络和数据通信 信息分析和基础设施 通信建模理论与实践 无线传感器和通信网络 云计算与物联网 网络和数据安全 光电子学和光通信 无线/移动通信和技术 智能通信…...

MySQL两阶段提交策略
书接上一篇文章,MySQL通过不同的策略来保证事务的ACID:原子性、一致性、隔离性、持久性,通过锁机制实现隔离性,通过redoundobinlog三种日志实现事务的原子性、一致性和持久性。 本文主要讲MySQL的持久性的一个实现机制-两阶段提交…...
uniapp商城之购物车模块
文章目录 一、列表渲染二、删除单品1.封装删除API2.按钮绑定事件三、修改单品数量1.复用步进器组件2.属性和事件的绑定3.接口封装4.调用接口四、修改商品选中/全选1.单品选中绑定事件调用修改API2.计算全选状态3.绑定事件调用全选API并渲染单品选中状态五、底部结算信息1.计算选…...

STM32_USART通用同步/异步收发器
目录 背景 程序 STM32浮空输入的概念 1.基本概念 2. STM32浮空输入的特点 3. STM32浮空输入的应用场景 STM32推挽输出详解 1. 基本概念 2. 工作原理 3. 应用场景 使能外设时钟 TXE 和 TC的区别 USART_IT_TXE USART_IT_TC 使能串口外设 中断处理函数 背景 单片…...
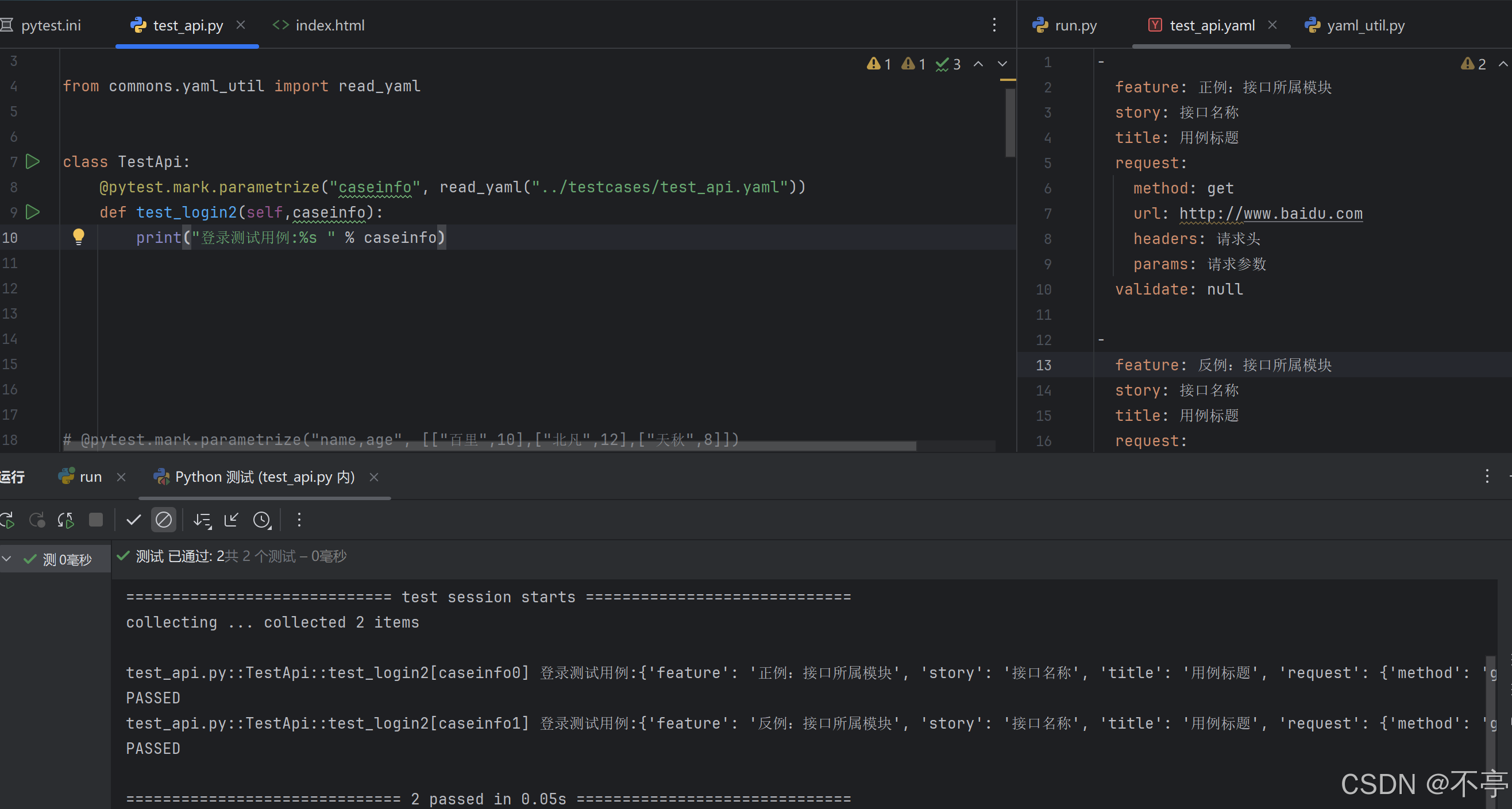
python自动化测试之Pytest框架之YAML详解以及Parametrize数据驱动!
一、YAML详解 YAML是一种数据类型,它能够和JSON数据相互转化,它本身也是有很多数据类型可以满足我们接口 的参数类型,扩展名可以是.yml或.yaml 作用: 1.全局配置文件 基础路径,数据库信息,账号信息&…...

python基础入门:6.3异常处理机制
Python异常处理全面指南:构建健壮程序的关键技术 # 完整异常处理模板 def process_file(file_path):"""文件处理示例函数"""file Nonetry:file open(file_path, r, encodingutf-8)data json.load(file)if not data:raise EmptyDa…...
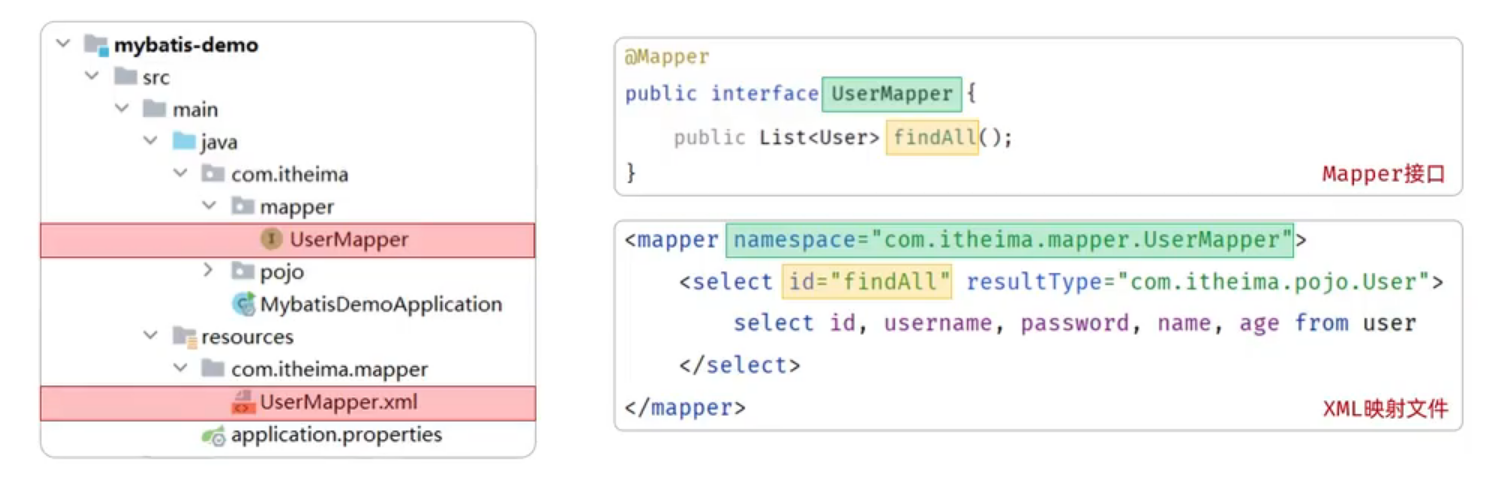
Mybatis快速入门与核心知识总结
Mybatis 1. 实体类(Entity Class)1.1 实体类的定义1.2 简化编写1.2.1 Data1.2.2 AllArgsConstructor1.2.3 NoArgsConstructor 2. 创建 Mapper 接口2.1 Param2.2 #{} 占位符2.3 SQL 预编译 3. 配置 MyBatis XML 映射文件(可选)3.1 …...
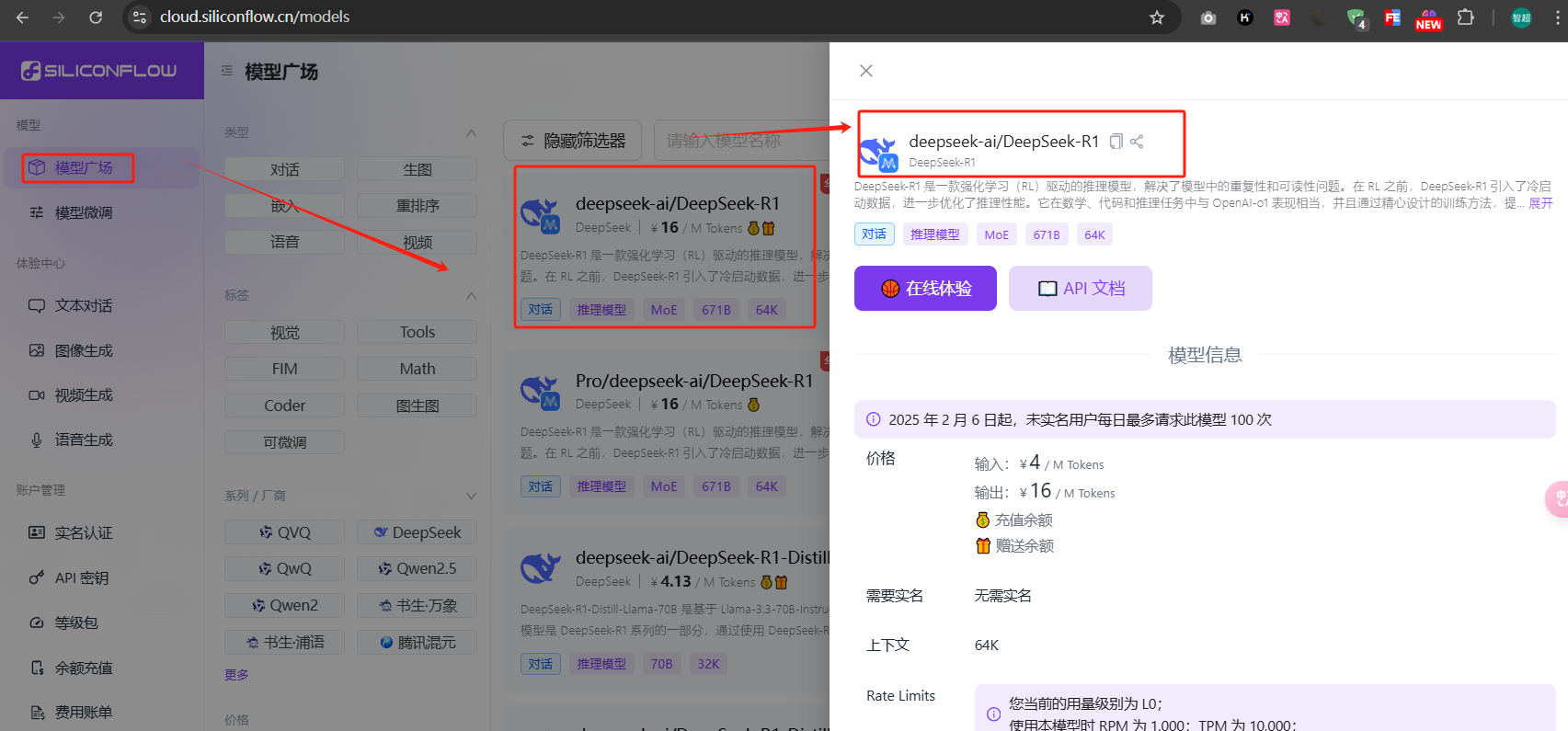
畅聊deepseek-r1,SiliconFlow 硅基流动注册+使用
文章目录 SiliconFlow 硅基流动注册使用注册创建API密钥使用网页端使用代码调用api调用支持的模型 SiliconFlow 硅基流动注册使用 注册 硅基流动官网 https://cloud.siliconflow.cn/i/XcgtUixn 注册流程 切换中文 邀请码: XcgtUixn 创建API密钥 账户管理 --&g…...
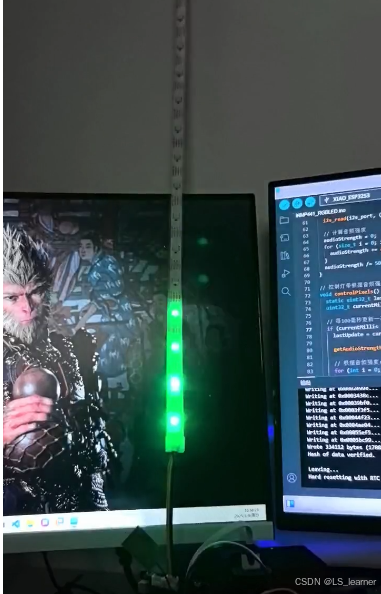
一个基于ESP32S3和INMP441麦克风实现音频强度控制RGB灯带律动的代码及效果展示
一个基于ESP32S3和INMP441麦克风实现音频强度控制RGB灯带律动的代码示例,使用Arduino语言: 硬件连接 INMP441 VCC → ESP32的3.3VINMP441 GND → ESP32的GNDINMP441 SCK → ESP32的GPIO 17INMP441 WS → ESP32的GPIO 18INMP441 SD → ESP32的GPIO 16RG…...
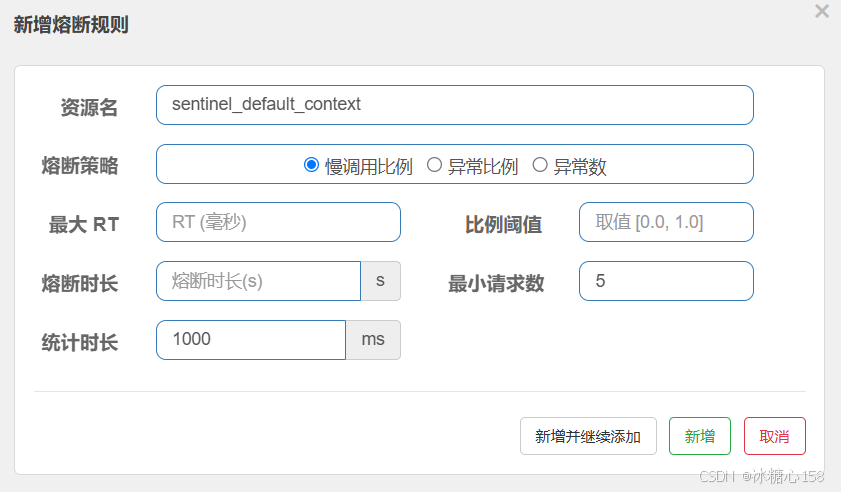
Springboot 中如何使用Sentinel
在 Spring Boot 中使用 Sentinel 非常方便,Spring Cloud Alibaba 提供了 spring-cloud-starter-alibaba-sentinel 组件,可以快速将 Sentinel 集成到你的 Spring Boot 应用中,并利用其强大的流量控制和容错能力。 下面是一个详细的步骤指南 …...
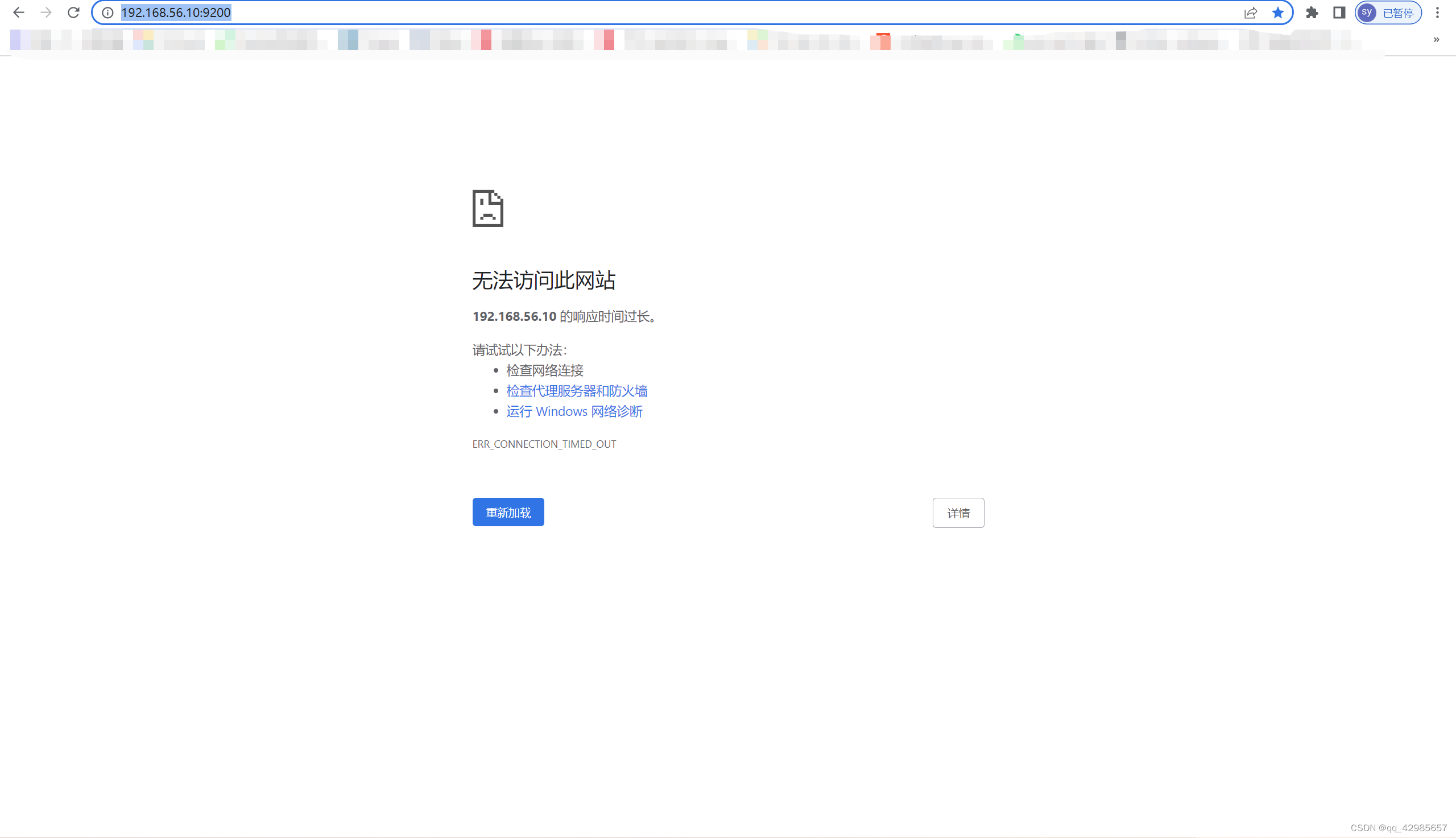
访问Elasticsearch服务 curl ip 端口可以 浏览器不可以
LINUX学习 在虚拟机上面的linux上面用docker 部署Elasticsearch项目后,在linux系统内部用curl ip 端口地址的形式可以访问到Elasticsearch。可以返回数据。 但是在本机的浏览器中输入ip 端口,会报错,找不到服务。 ping 和 trelnet均不通。 …...
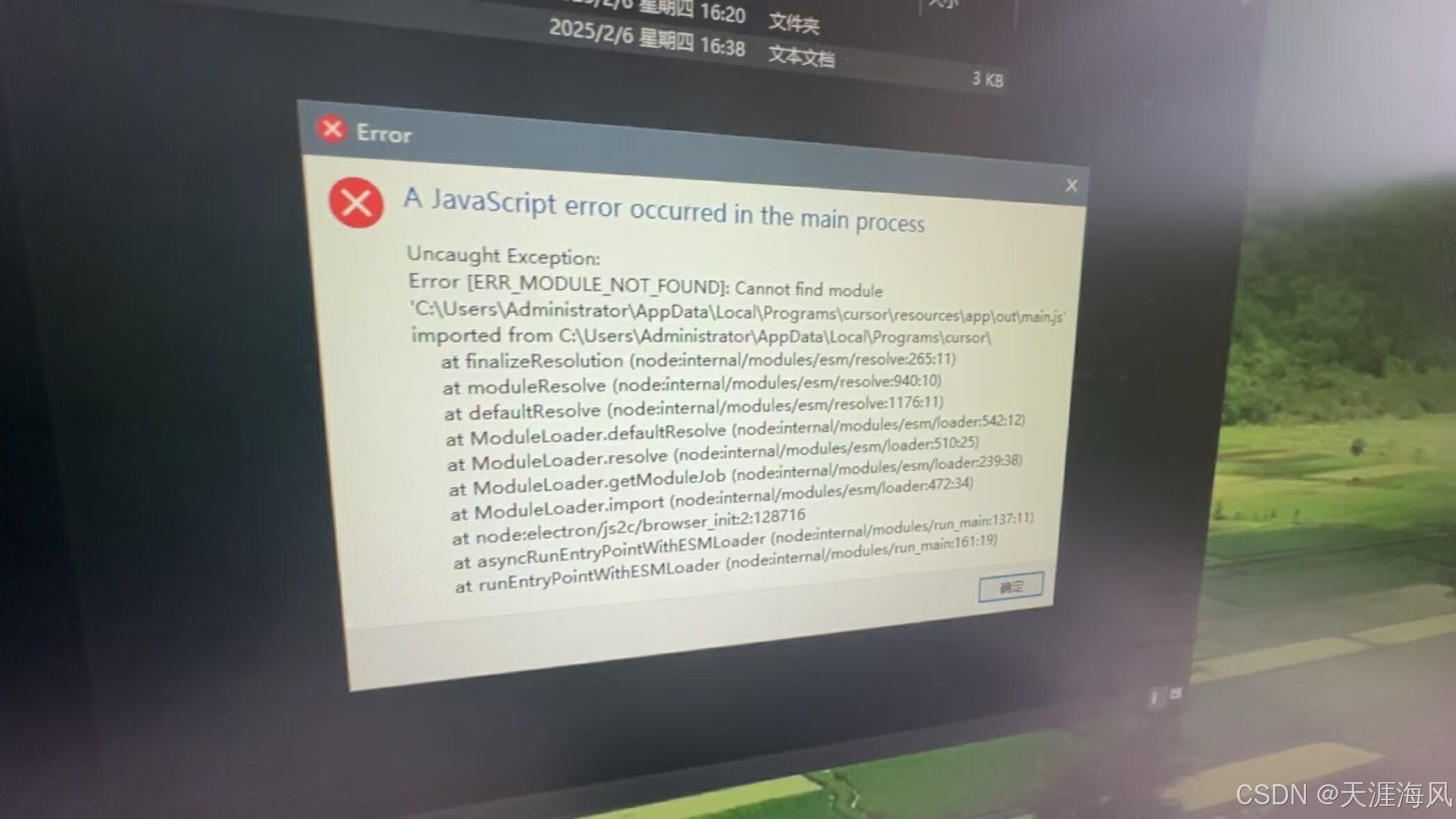
Curser2_解除机器码限制
# Curser1_无限白嫖试用次数 文末有所需工具下载地址 Cursor Device ID Changer 一个用于修改 Cursor 编辑器设备 ID 的跨平台工具集。当遇到设备 ID 锁定问题时,可用于重置设备标识。 功能特性 ✨ 支持 Windows 和 macOS 系统🔄 自动生成符合格式的…...
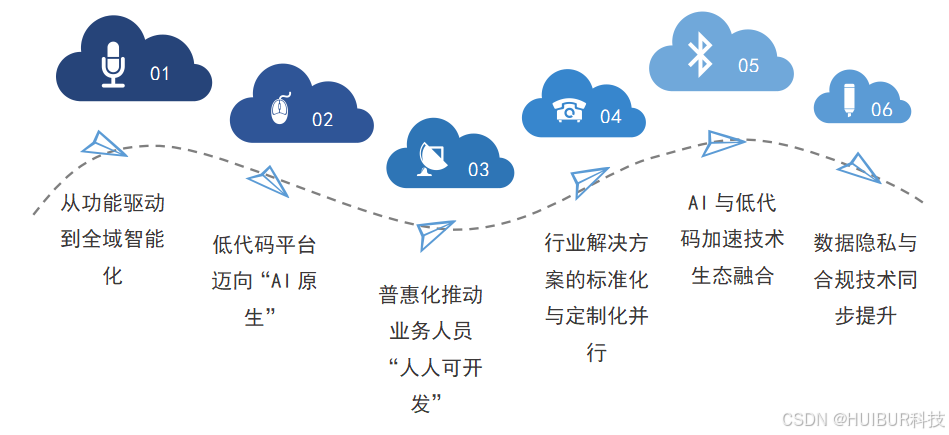
人工智能与低代码如何重新定义企业数字化转型?
引言:数字化转型的挑战与机遇 在全球化和信息化的浪潮中,数字化转型已经成为企业保持竞争力和创新能力的必经之路。然而,尽管“数字化”听上去是一个充满未来感的词汇,落地的过程却往往充满困难。 首先,传统开发方式…...
arkTS基础
arkTS基础 // 变量声明 let hi: string hello; hi hello,world; // 常量声明 const hi: string hello;// ArkTS是一种静态类型语言,所有数据的类型都必须在编译时确定 // 如果一个变量或常量的声明包含了初始值,那么开发者就不需要显式指定其类型。…...

C++20中的std::atomic_ref
一、std::atomic_ref 我们在学习C11后的原子操作时,都需要提前定义好std::atomic变量,然后才可以在后续的应用程序中进行使用。原子操作的优势在很多场合下优势非常明显,所以这也使得很多开发者越来习惯使用原子变量。 但是,在实…...

四、自然语言处理_08Transformer翻译任务案例
0、前言 在Seq2Seq模型的学习过程中,做过一个文本翻译任务案例,多轮训练后,效果还算能看 Transformer作为NLP领域的扛把子,对于此类任务的处理会更为强大,下面将以基于Transformer模型来重新处理此任务,看…...
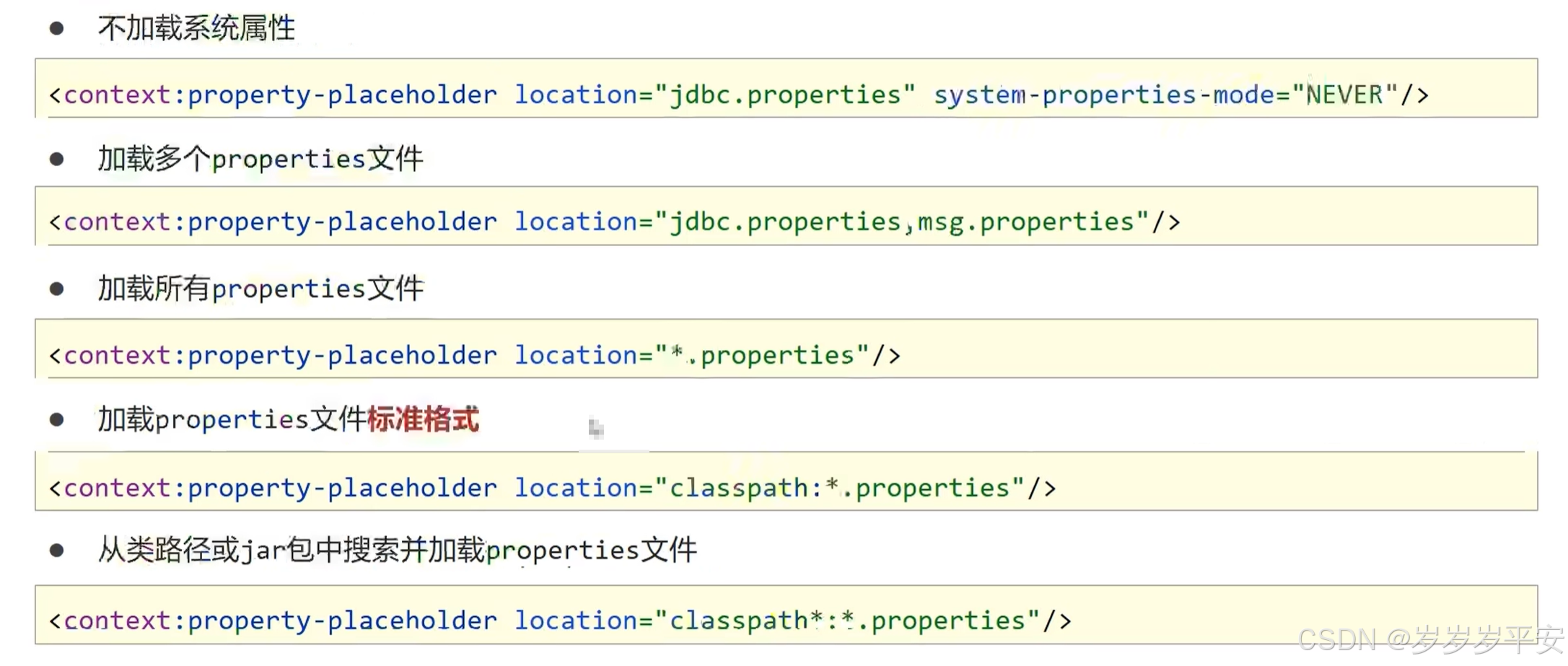
spring学习(使用spring加载properties文件信息)(spring自定义标签引入)
目录 一、博客引言。 二、基本配置准备。 (1)初步分析。 (2)初始spring配置文件。 三、spring自定义标签的引入。 (1)基本了解。 (2)引入新的命名空间:xmlns:context。 &…...
bigemap pro如何进行poi兴趣点搜索?
准备工具:BIGEMAP Pro是数据要素设计软件(DED),国产基础软件,大数据编辑、制图、多源数据要素类处理软件打开软件右上角选择分类搜索然后用矩形或者选择行政边界线选择需要查询的范围选中范围以后点击查询然后可以直接加载到地图然后图层右键数据导出矢量…...
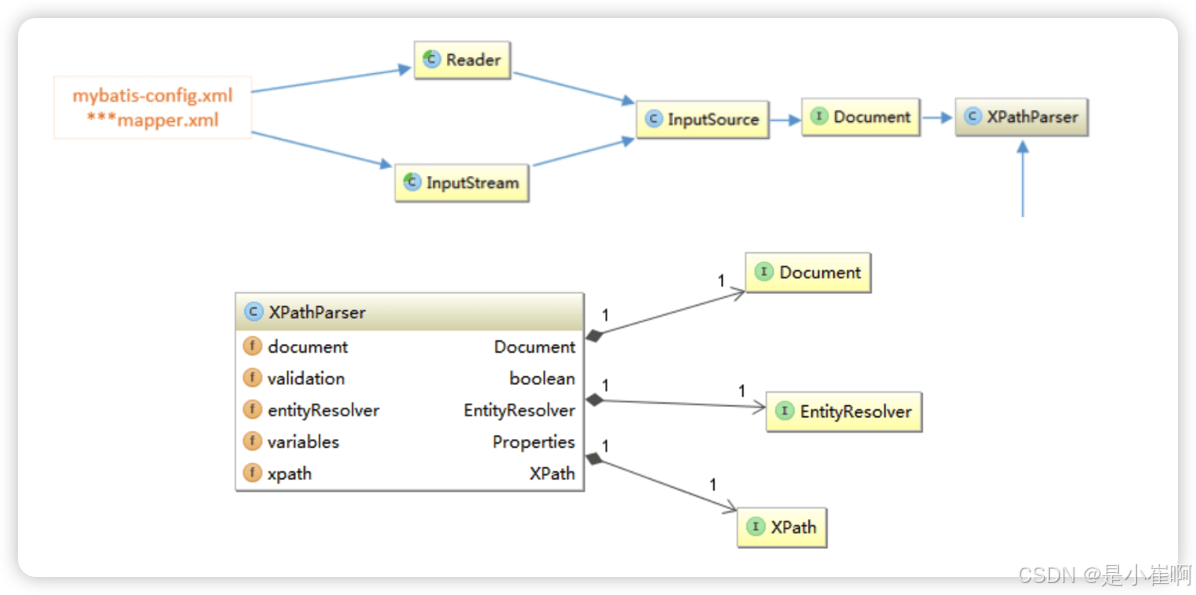
Mybatis源码02 - 初始化基本过程(引导层部分)
初始化基本过程(引导层部分) 文章目录 初始化基本过程(引导层部分)一:初始化的方式及引入二:初始化方式-XML配置文件1:MyBatis初始化基本过程2:创建Configuration对象的过程2.1&…...

现在的人为什么不焦虑了!
就拿我来说吧!现在你努力没有方向,焦虑只能让自己的什么出现问题,晚上睡不好的,伴随着偏头疼,是在是太难了。 !、而且回过头来看我们真的需要那么多消费吗?消费降一点,吃踏实点&…...
)
Linux驱动开发避坑指南:手把手教你实现三种mmap内存映射(附完整代码)
Linux驱动开发实战:三种mmap内存映射方案深度解析与性能对比 在嵌入式系统和图形处理领域,直接访问内核内存的需求日益增长。想象一下这样的场景:你正在开发一个视频处理驱动,需要将摄像头采集的高清帧数据传输到用户空间进行实时…...

开源技能管理工具rei-skills:从零构建个人技术能力图谱
1. 项目概述与核心价值 最近在折腾个人知识库和技能树管理,发现了一个挺有意思的开源项目 rootcastleco/rei-skills 。这项目名字乍一看有点神秘, rei 在日语里是“零”或“灵”的意思,结合 skills ,我理解它想表达的是一种…...

从ARM预警看半导体不确定性:硬件弹性设计与供应链应对策略
1. 从一则旧闻谈起:当不确定性成为半导体行业的主旋律十多年前,也就是2012年的秋天,一则来自EE Times的报道在业内引起了不小的讨论。报道的标题是《London Calling: ARM’s East copes with uncertainty》,核心内容是时任ARM公司…...

Poppins几何无衬线字体:9种字重与多语言支持的技术实现深度解析
Poppins几何无衬线字体:9种字重与多语言支持的技术实现深度解析 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins Poppins几何无衬线字体是一款由Indian Type Foundry…...

10个无状态服务构建技巧:解锁gh_mirrors/awe/awesome-sre中的水平扩展最佳实践
10个无状态服务构建技巧:解锁gh_mirrors/awe/awesome-sre中的水平扩展最佳实践 【免费下载链接】awesome-sre A curated list of Site Reliability and Production Engineering resources. 项目地址: https://gitcode.com/gh_mirrors/awe/awesome-sre 在现代…...

MediaCreationTool.bat:解决Windows安装媒体创建痛点的灵活工具
MediaCreationTool.bat:解决Windows安装媒体创建痛点的灵活工具 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...

网络虚拟化如何应对100G性能挑战:从SDN/NFV到DPDK与智能网卡的演进
1. 网络虚拟化与100G浪潮:一场正在发生的架构革命如果你在2015年前后从事网络或云计算相关的工作,大概会对一个词印象深刻:100G。当时,行业媒体和厂商都在热烈讨论一个预测——到2018年,100G将成为网络设备,…...

如何轻松解锁Cursor Pro完整功能:一键激活与无限使用的完整指南
如何轻松解锁Cursor Pro完整功能:一键激活与无限使用的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached…...

在ubuntu上为nodejs后端服务接入taotoken多模型api的步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Ubuntu 上为 Node.js 后端服务接入 Taotoken 多模型 API 的步骤 为后端服务集成大模型能力是现代应用开发的常见需求。如果你在…...