【IC】AI处理器核心--第二部分 用于处理 DNN 的硬件设计
第 II 部分 用于处理 DNN 的硬件设计
第 3 章 关键指标和设计目标
在过去的几年里,对 DNN 的高效处理进行了大量研究。因此,讨论在比较和评估不同设计和拟议技术的优缺点时应考虑的关键指标非常重要,这些指标应纳入设计考虑中。虽然效率通常仅与每瓦每秒的操作次数相关(例如,每秒每瓦特的浮点运算数为 FLOPS/W 或每秒每瓦万亿次操作数为 TOPS/W),但它实际上由更多指标组成,包括准确性、吞吐量、延迟、能耗、功耗、成本、灵活性和可扩展性。报告一组全面的这些指标非常重要,以便全面了解设计或技术所做的权衡。
在本章中,我们将
• 讨论这些指标中的每一个的重要性;
• 细分影响每个量度的因素。如果可行,提出描述因素和指标之间关系的方程;
• 描述如何将这些指标纳入DNN 硬件和DNN 模型(即工作负载)的设计考虑因素中
• 指定应为给定量度报告的内容,以便进行适当的评估。
最后,我们将提供一个案例研究,说明如何将所有这些指标整合在一起,以对给定的方法进行整体评估。但首先,我们将讨论每个指标。
3.1 准确性
准确性用于指示给定任务的结果质量。DNN 可以在各种任务上实现最先进的准确性,这是推动当今 DNN 普及和广泛使用的关键原因之一。用于测量准确性的单位取决于任务。例如,对于图像分类,准确率报告为正确分类图像的百分比,而对于对象检测,准确率报告为平均平均精度均值 (mAP),这与真阳性率和假阳性率之间的权衡有关。
影响准确性的因素包括任务和数据集的难度1。例如,ImageNet 上的分类比 MNIST 上的分类要困难得多,对象检测或语义分割比分类更难。因此,在 MNIST 上表现良好的 DNN 模型不一定在 ImageNet 上表现良好。
在困难的任务或数据集上实现高精度通常需要更复杂的 DNN 模型(例如,更多的 MAC操作和更不同的权重、层形状的多样性增加等),这可能会影响硬件处理 DNN 模型的效率。
因此,应根据任务和数据集的难度来解释准确性2。 使用经过充分研究、广泛使用的 DNN 模型、任务和数据集来评估硬件,可以更好地解释准确性指标的重要性。最近,在通用计算 [114] 的 SPEC 基准影响的推动下,一些行业和学术组织将一套广泛的 DNN 模型(称为 MLPerf)放在一起,作为一组经过充分研究的通用 DNN 模型,以评估性能并实现各种软件框架、硬件加速器和云平台的公平比较,以便对 DNN 进行训练和推理 [115]3。该套件包括各种类型的 DNN(例如 CNN、RNN 等)适用于各种任务,包括图像分类、对象识别、翻译、语音转文本、推荐、情感分析和强化学习。
1理想情况下,稳健性和公平性应与准确性一起考虑,因为这些因素之间也存在相互作用;然而,这些都是正在进行的研究领域,超出了本书的范围。
2打个比方,在高中考试中 10 个答案中答对 9 个与在大学考试中答对 10 个答案中的 9 个不同。人们必须超越分数,考虑考试的难度。
3早期的 DNN 基准测试工作,包括 DeepBench [116] 和 Fathom [117],现在已经被 MLPerf 归入其中。
3.2 吞吐量和延迟
吞吐量用于指示在给定时间段内可以处理的数据量或可以完成的任务执行次数。高吞吐量通常对应用程序至关重要。例如,以每秒 30 帧的速度处理视频对于提供实时性能是必要的。对于数据分析,高吞吐量意味着可以在给定的时间内分析更多的数据。随着视觉数据量呈指数级增长,高吞吐量大数据分析变得越来越重要,尤其是在需要根据分析采取行动时(例如,安全或恐怖主义预防;医疗诊断或药物发现)。吞吐量通常报告为每秒的操作数。在推理的情况下,吞吐量以每秒推理数报告,或以每次推理的秒数表示运行时间。
延迟(延时 Latency)是输入数据到达系统与生成结果之间的时间。低延迟对于实时交互式应用程序(如增强现实、自主导航和机器人技术)是必要的。延迟通常以秒为单位报告。
吞吐量和延迟通常被认为是可以直接相互派生的。然而,它们实际上是非常不同的。一个典型的例子是众所周知的对输入数据进行批处理的方法(例如,将多个图像或帧一起批处理以进行处理)以提高吞吐量,因为它会分摊开销,例如加载权重;但是,批处理也会增加延迟(例如,在每秒 30 帧和 100 帧的批处理中,某些帧将经历至少 3.3 秒的延迟),这对于实时应用程序(如高速导航)来说是不可接受的,因为高速导航会减少可用于航向校正的时间。因此,根据方法的不同,同时实现低延迟和高吞吐量有时可能会有所不同,并且两者都应该报告4。
有几个因素会影响吞吐量和延迟。在吞吐量方面,每秒的推理次数受以下因素影响:
i n f e r e n c e s s e c o n d = o p e r a t i o n s s e c o n d ∗ 1 o p e r a t i o n s i n f e r e n c e ( 3.1 ) \frac{inferences}{second}=\frac{operations} {second} * \frac{1}{\frac{operations}{inference}} \quad (3.1) secondinferences=secondoperations∗inferenceoperations1(3.1)
其中,每秒的操作数由 DNN 硬件和 DNN 模型决定,而每次推理的操作数由 DNN 模型决定。
当考虑由多个处理元件 (PE) 组成的系统时,其中 PE 对应于执行单个 MAC作的简单或原始内核,每秒的作数可以进一步分解如下:

第一项反映单个 PE 的峰值吞吐量,第二项反映并行量,而最后一项反映由于架构无法有效利用 PE 而导致的退化。
由于处理 DNN 的主要作是 MAC,因此我们将互换使用操作数和 MAC操作数。
4这里描述的现象也可以使用队列理论中的利特尔定律 [118] 来理解,其中平均吞吐量和平均延迟之间的关系与飞行中的平均任务数有关,定义如下:
througnput ‾ = tasks-in-flight ‾ latency ‾ \overline {\text{througnput}}=\frac{\overline{\text {tasks-in-flight}}}{\overline{\text{latency}}} througnput=latencytasks-in-flight
以 DNN 为中心的利特尔定律版本的吞吐量以每秒推理数衡量,延迟以秒为单位,动态推理(相当于飞行任务数),以同时处理的批次中的图像数量来衡量。这有助于解释为什么增加动态推理数量以提高吞吐量可能会适得其反,因为一些增加动态推理数量的技术(例如批处理)也会增加延迟。
可以通过增加每秒的周期数(对应于更高的时钟频率)来提高单个 PE 的峰值吞吐量,方法是减少电路的关键路径或微架构级数,或每个作的周期数,这可能会受到 MAC 设计的影响(例如,非流水线多周期 MAC 每个作将有更多的周期)。
虽然上述方法增加了单个 PE 的吞吐量,但可以通过增加 PE 的数量来提高整体吞吐量,从而增加可以并行执行的最大 MAC作数。PE 的数量由 PE 的面积密度和系统的面积成本决定。如果系统的面积成本是固定的,那么增加 PE 的数量需要增加 PE 的面积密度(即减少每个 PE 的面积)或牺牲片上存储面积以换取更多的 PE。但是,减少片上存储会影响 PE 的利用率,我们接下来将对此进行讨论。
增加 PE 的密度也可以通过减少与向 MAC 提供作数相关的 logic 来实现。这可以通过用单个 logic控制多个 MACs 来实现。这类似于基于指令的系统(如 CPU 和 GPU)中的情况,这些系统通过使用大型聚合指令(例如,单指令、多数据 (SIMD)/矢量指令;单指令、多线程 (SIMT)/张量指令)来减少指令簿记开销,其中单个指令可用于启动多个操作。
PE 的数量和单个 PE 的峰值吞吐量仅表示所有 PE 都执行计算(100% 利用率)时的理论最大吞吐量(即峰值性能)。实际上,可实现的吞吐量取决于这些 PE 的实际利用率,该利用率受以下几个因素的影响:

第一个术语反映了将工作负载分配到 PE 的能力,而第二个术语反映了这些活动 PE 处理工作负载的效率。
活动 PE 的数量是接收工作的 PE 的数量;因此,最好将工作负载分配给尽可能多的 PE。分配工作负载的能力取决于架构的灵活性,例如片上网络,以支持 DNN 模型中的层形状。在片上网络的约束下,活动 PE 的数量也由映射过程对 PE 的特定工作分配决定。映射过程涉及将每个 MAC作(包括交付适当的作数)在空间和时间上放置和调度到 Pe 上。可以将映射视为 DNN 硬件的编译器。片上网络和映射的设计将在第 5 章和第 6 章中讨论。
活动 PE 的利用率在很大程度上取决于及时向 PE 交付工作,以便活动 PE 在等待数据到达时不会变为空闲状态。这可能会受到 (片上和片外) 内存和网络的带宽和延迟的影响。带宽要求可能会受到DNN 模型中数据可重用量以及内存层次结构和数据流可利用的数据重用量的影响。数据流确定作的顺序以及数据的存储和重用位置。还可以使用更大的批处理大小来增加数据重用量,这也是增加批处理大小可以提高吞吐量的原因之一。第 5 章和第 6 章讨论了数据传输和内存带宽的挑战。活动 PE 的利用率也会受到跨 PE 分配的工作不平衡的影响,这可能发生在利用稀疏性时(即,避免与乘以零相关的不必要工作);工作量较少的 PE 变为空闲状态,因此利用率较低。

PE 的数量和 PE 的利用率之间也存在相互作用。例如,降低 PE 需要等待数据的可能性的一种方法是在 PE 附近或内部本地存储一些数据。但是,这需要增加分配给片上存储的芯片面积,如果芯片面积固定,这将减少 PE 的数量。因此,一个关键的设计考虑因素是分配多少区域进行计算(这会增加 PE 的数量)与片上存储(这会增加 PE 的利用率)。
可以使用 Eyexam 捕获这些因素的影响,Eyexam 是一种系统的方法,用于理解 DNN 处理器的性能限制作为 DNN 模型和加速器设计的特定特征的函数。Eyexam包括并扩展了著名的车顶线模型[119]。如图 3.1 所示,roofline 模型将平均带宽需求和峰值计算能力与性能相关联。Eyexam 在第 6 章中介绍。
虽然公式 (3.1) 中每次推理的作数取决于 DNN 模型,但每秒作数取决于 DNN 模型和硬件。例如,如第 9 章所述,设计具有高效层形状(也称为高效网络架构)的 DNN 模型可以减少DNN 模型的MAC操作以及每次推理的操作。然而,这种 DNN 模型可能会导致各种各样的层形状,其中一些层的 PE 利用率可能很差,因此会降低每秒的总操作量,如公式 (3.2) 所示。
对每秒作数的更深入考虑是,并非所有作都是平等的,因此每个作的周期数可能不是恒定的。例如,如果我们考虑任何乘以 0 都是零的事实,那么某些 MAC作是无效的(即,它们不会改变累积值)。无效作的数量是 DNN 模型和输入数据的函数。这些无效的 MAC作可能需要更少的周期或根本不需要周期。相反,我们只需要处理有效(或非零)MAC作,其中两个 inputs 都非零;这被称为利用稀疏性,这将在第 8 章中讨论。
仅处理有效的 MAC作可以通过增加每个周期的(总)作数来增加每秒的(总)作数5。理想情况下,硬件将跳过所有无效的作;然而,在实践中,设计硬件以跳过所有无效的作可能具有挑战性,并导致硬件复杂性和开销增加,如第 8 章所述。例如,设计仅识别其中一个作数(例如权重)中的 0 而不是同时识别两者的硬件可能更容易。因此,无效的作可以进一步分为那些被硬件利用的作(即跳过)和那些未被硬件利用的作(即未跳过)。因此,硬件实际执行的作数是有效作数加上未利用的无效作数。
方程 (3.4) 显示了如何将每个周期的作分解为:
- 每个周期的有效作数加上未开发的无效作数,对于给定的硬件加速器设计,这在某种程度上保持不变;
- 有效作与有效作加上未开发的无效作的比率,这是指硬件开发无效作的能力(理想情况下,未开发的无效作应为零,并且该比率应为 1)
- (总)作中的有效作数,这与稀疏量有关,取决于 DNN 模型。
随着稀疏量的增加(即,(总)作中的有效作数减少),每个周期的作数增加,随后每秒作数增加,如公式 (3.2) 所示:

5总作是指有效和无效的作。

但是,利用稀疏性需要额外的硬件来识别输入何时为零,以避免执行不必要的 MAC作。额外的硬件可以增加关键路径,从而减少每秒的周期数,还可以降低 PE 的区域密度,从而减少给定区域的 PE 数量。这两个因素都会减少每秒作数,如公式 (3.2) 所示。因此,附加硬件的复杂性可能会导致在减少未开发的无效作数量与增加关键路径或减少 PE 数量之间进行权衡。
最后,设计支持降低精度(即每个作数和每个作的位数更少)的硬件和 DNN 模型(如第 7 章所述)也可以增加每秒的作数。每个作数的位数较少意味着支持给定作所需的内存带宽会减少,这可能会提高 PE 的利用率,因为它们不太可能缺乏数据。此外,可以减少每个 PE 的面积,从而增加给定区域的 PE 数量。这两个因素都会增加每秒的作数,如公式 (3.2) 所示。但请注意,如果需要支持多个级别的精度,则需要额外的硬件,这可以再次增加关键路径并降低 PE 的面积密度,这两者都可以减少每秒的作次数,如公式 (3.2) 所示。
在本节中,我们讨论了影响每秒推理次数的多个因素。表 3.1 对因素是由硬件、DNN 模型还是两者决定进行分类。
总之,仅 DNN 模型中的 MAC作数量不足以评估吞吐量和延迟。虽然 DNN 模型可以根据网络架构(即层形状)以及权重和激活的稀疏性影响每次推理的 MAC作数量,但对DNN 模型的吞吐量和延时的影响取决于硬件添加支持以识别这些方法的能力,而不会显著降低 PE 的利用率、PE 数量或每秒周期数。这就是为什么 MAC作的数量不一定是吞吐量和延迟的良好代理(例如,图 3.2),并且设计具有硬件在循环中的高效 DNN 模型通常更有效。第 9 章讨论了在循环中使用硬件设计 DNN 模型的技术。

同样,硬件中的 PE 数量及其峰值吞吐量不足以评估吞吐量和延迟。如公式 (3.2) 所示,报告硬件上 DNN 模型的实际运行时间以考虑其他影响(例如 PE 利用率)至关重要。理想情况下,应在明确指定的 DNN 模型上执行此评估,例如,作为 MLPerf 基准测试套件一部分的模型。此外,应将批处理大小与吞吐量一起报告,以便评估延迟。
3.3 能源效率和功耗
相关文章:
【IC】AI处理器核心--第二部分 用于处理 DNN 的硬件设计
第 II 部分 用于处理 DNN 的硬件设计 第 3 章 关键指标和设计目标 在过去的几年里,对 DNN 的高效处理进行了大量研究。因此,讨论在比较和评估不同设计和拟议技术的优缺点时应考虑的关键指标非常重要,这些指标应纳入设计考虑中。虽然效率通常…...

从 0 开始本地部署 DeepSeek:详细步骤 + 避坑指南 + 构建可视化(安装在D盘)
个人主页:chian-ocean 前言: 随着人工智能技术的迅速发展,大语言模型在各个行业中得到了广泛应用。DeepSeek 作为一个新兴的 AI 公司,凭借其高效的 AI 模型和开源的优势,吸引了越来越多的开发者和企业关注。为了更好地…...

如何本地部署DeepSeek集成Word办公软件
目录 本地部署DeepSeek安装Ollama下载并部署DeepSeek模型安装ChatBox客户端(可选) 将DeepSeek集成到Word修改Word中的VBA代码执行操作 ✍️相关问答如何在Word中安装和使用VBA宏DeepSeek模型有哪些常见的API接口?如何优化DeepSeek在Word中的集…...

Centos10 Stream 基础配置
NetworkManger 安装 dnf install NetworkManager 查看网络配置 nmcli [rootCentos-S-10 /]# nmcli ens33:已连接 到 ens33"Intel 82545EM"ethernet (e1000), 00:0C:29:08:3E:71, 硬件, mtu 1500ip4 默认inet4 192.168.31.70/24route4 default …...

时间序列分析(三)——白噪声检验
此前篇章: 时间序列分析(一)——基础概念篇 时间序列分析(二)——平稳性检验 一、相关知识点 白噪声的定义:白噪声序列是一种在统计学和信号处理中常见的随机过程,由一系列相互独立、具有相同…...

ThinkPHP8视图赋值与渲染
【图书介绍】《ThinkPHP 8高效构建Web应用》-CSDN博客 《2025新书 ThinkPHP 8高效构建Web应用 编程与应用开发丛书 夏磊 清华大学出版社教材书籍 9787302678236 ThinkPHP 8高效构建Web应用》【摘要 书评 试读】- 京东图书 在控制器操作中,使用view函数可以传入视图…...

对贵司需求的PLC触摸的远程调试的解决方案
远程监控技术解决方案 一、需求痛点分析 全球设备运维响应滞后(平均故障处理周期>72小时)客户定制化需求频繁(每月PLC程序修改需求超50次)人力成本高企(单次跨国差旅成本约$5000)多品牌PLC兼容需求&am…...

2.12寒假作业
web:[HDCTF 2023]Welcome To HDCTF 2023 可以直接玩出来 但是这边还是看一下怎么解吧,看一下js代码,在js.game里面找到一个类似brainfuck加密的字符串 解密可以得到答案,但是后面我又去了解了一下let函数let命令、let命令 let命…...
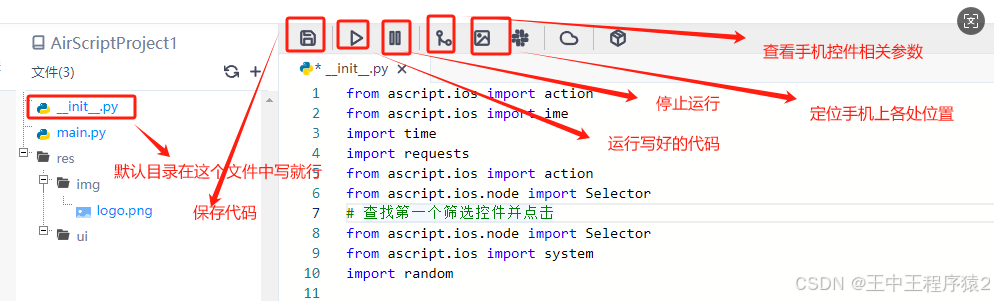
记使用AScript自动化操作ios苹果手机
公司业务需要自动化操作手机,本来以为很困难,没想到使用AScript工具出乎意料的简单,但是还有很多坑存在,写个博客记录一下。 工具信息: 手机:iphone7 系统版本:ios15 AScript官方文档链接&a…...

【Apache Paimon】-- 16 -- 利用 paimon-flink-action 同步 kafka 数据到 hive paimon 表中
目录 引言CDC 技术概述 2.1 什么是 CDC2.2 CDC 的应用场景Kafka 作为 CDC 数据源的原理与优势 3.1 Kafka 的基本架构3.2 Kafka 在 CDC 中的角色...

基于 PyTorch 的树叶分类任务:从数据准备到模型训练与测试
基于 PyTorch 的树叶分类任务:从数据准备到模型训练与测试 1. 引言 在计算机视觉领域,图像分类是一个经典的任务。本文将详细介绍如何使用 PyTorch 实现一个树叶分类任务。我们将从数据准备开始,逐步构建模型、训练模型,并在测试…...

算法之 数论
文章目录 质数判断质数3115.质数的最大距离 质数筛选204.计数质数2761.和等于目标值的质数对 2521.数组乘积中的不同质因数数目 质数 质数的定义:除了本身和1,不能被其他小于它的数整除,最小的质数是 2 求解质数的几种方法 法1,根…...

Java 大视界 -- 人工智能驱动下 Java 大数据的技术革新与应用突破(83)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

【04】RUST特性
文章目录 隐藏shadowing所有权ownership堆区&栈区所有权规则变量&数据Copy Trait与Drop TraitCopy TraitDrop Trait移动克隆函数参数与返回值的所有权参数引用可变引用悬垂引用slice生命周期隐藏shadowing 有点像同名覆盖 let mut guess = String::new();let guess: u3…...

PlantUml常用语法
PlantUml常用语法,将从类图、流程图和序列图这三种最常用的图表类型开始。 类图 基础语法 在 PlantUML 中创建类图时,你可以定义类(Class)、接口(Interface)以及它们之间的关系,如继承&#…...

保存字典类型的文件用什么格式比较好
保存 Python 字典类型的数据时,有几个常见的格式可以选择,这些格式都具有良好的可读性和提取内容的便利性。以下是几种推荐的格式: JSON 格式: 优点:JSON 格式非常适合存储和传输结构化数据,具有良好的跨平…...
)
开源模型应用落地-Qwen1.5-MoE-A2.7B-Chat与vllm实现推理加速的正确姿势(一)
一、前言 在人工智能技术蓬勃发展的当下,大语言模型的性能与应用不断突破边界,为我们带来前所未有的体验。Qwen1.5-MoE-A2.7B-Chat 作为一款备受瞩目的大语言模型,以其独特的架构和强大的能力,在自然语言处理领域崭露头角。而 vllm 作为高效的推理库,为模型的部署与推理提…...

一竞技瓦拉几亚S4预选:YB 2-0击败GG
在2月11号进行的PGL瓦拉几亚S4西欧区预选赛上,留在欧洲训练的YB战队以2-0击败GG战队晋级下一轮。双方对阵第二局:对线期YB就打出了优势,中期依靠卡尔带队进攻不断扩大经济优势,最终轻松碾压拿下比赛胜利,以下是对决战报。 YB战队在天辉。阵容是潮汐、卡尔、沙王、隐刺、发条。G…...

deepseek+kimi一键生成PPT
1、deepseek生成大纲内容 访问deepseek官方网站:https://www.deepseek.com/ 将你想要编写的PPT内容输入到对话框,点击【蓝色】发送按钮,让deepseek生成内容大纲,并以markdown形式输出。 等待deepseek生成内容完毕后,…...

mybatis 是否支持延迟加载?延迟加载的原理是什么?
1. MyBatis 是否支持延迟加载? 是的,MyBatis 支持延迟加载。延迟加载的主要功能是推迟数据加载的时机,直到真正需要时再去加载。这种方式能提高性能,尤其是在处理关系型数据时,可以避免不必要的数据库查询。 具体来说…...

gRPC流量分析实战:用cursor-tap工具实现AI对话可视化与游戏集成
1. 项目概述:从零到一,打造一个能“监听”AI对话的独立游戏 最近在折腾一个挺有意思的玩意儿,叫 cursor-tap 。这名字听起来有点神秘,对吧?简单来说,它是一个用来分析 gRPC 通信流量的工具。但如果你以为…...

体验Taotoken聚合路由在单一模型临时故障时的自动容灾效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken聚合路由在单一模型临时故障时的自动容灾效果 在实际的AI应用开发与集成过程中,服务的稳定性是开发者关注…...

如何用Obsidian主页插件打造你的专属数字工作台?
如何用Obsidian主页插件打造你的专属数字工作台? 【免费下载链接】obsidian-homepage Obsidian homepage - Minimal and aesthetic template (with my unique features) 项目地址: https://gitcode.com/gh_mirrors/obs/obsidian-homepage 你是否厌倦了每次打…...

Next.js企业级开发样板Next-Enterprise:一站式集成最佳实践与工具链
1. 项目概述:为什么说 Next-Enterprise 是 Next.js 企业级开发的“瑞士军刀”? 如果你正在用 Next.js 构建一个中大型、对代码质量和开发体验有要求的企业级应用,那你大概率遇到过这些头疼事:项目初始化配置繁琐,得花…...

为什么数据科学家都爱用Spyder?这6个独特优势让你告别Python开发烦恼! [特殊字符]
为什么数据科学家都爱用Spyder?这6个独特优势让你告别Python开发烦恼! 😊 【免费下载链接】spyder Official repository for Spyder - The Scientific Python Development Environment 项目地址: https://gitcode.com/gh_mirrors/sp/spyder…...

深度解析:libiec61850开源库如何解决电力系统通信的三大核心挑战
深度解析:libiec61850开源库如何解决电力系统通信的三大核心挑战 【免费下载链接】libiec61850 Official repository for libIEC61850, the open-source library for the IEC 61850 protocols 项目地址: https://gitcode.com/gh_mirrors/li/libiec61850 在电…...

第八部分-企业级实践——36. CI/CD 集成
36. CI/CD 集成 1. CI/CD 概述 CI/CD(持续集成/持续部署)与 Docker 结合,可以实现代码提交后自动构建镜像、测试、部署的完整流程,大幅提升开发效率和发布质量。 ┌──────────────────────────────…...

Python 3.14.5 发布:多项改进,垃圾回收器回滚,还有这些新特性!
Python 3.14.5 发布Python 3.14.5 现已发布,这是 3.14 的第五个维护版本。自 3.14.4 以来,包含约 154 项错误修复、构建改进和文档更改。垃圾回收器回滚值得注意的是,Python 3.14.5 中的垃圾回收器 (GC) 发生了变化。由于一些原因,…...
)
保姆级教程:用Sigrity PowerSI提取5GHz内单端S参数(附DDR4仿真实例)
从零掌握Sigrity PowerSI:5GHz单端S参数提取与DDR4实战解析 在高速PCB设计中,信号完整性问题往往成为工程师的"隐形杀手"。当DDR4内存接口速率突破2400MHz时,传统时域分析方法已难以捕捉信号在传输过程中的微妙变化。散射参数&…...

毫米波雷达选型指南:HLK-LD1125H-24G vs 传统红外/超声波,在智能办公场景下怎么选?
毫米波雷达选型指南:HLK-LD1125H-24G vs 传统红外/超声波,在智能办公场景下怎么选? 在智能办公场景中,人员检测技术的选择直接影响着空间管理效率与用户体验。传统红外(PIR)和超声波传感器曾长期主导市场&…...