LeetCodehot 力扣热题100 从前序与中序遍历序列构造二叉树
初始版本
这段代码实现了根据前序遍历和中序遍历重建二叉树。下面我将详细解释每一行的作用,并逐步讲解算法的思路和运行步骤。
代码及注释
class Solution {public:// buildTree 函数用来根据前序遍历(pre)和中序遍历(in)重建二叉树TreeNode* buildTree(vector<int>& pre, vector<int>& in){// 基本情况:当前序或中序遍历为空时,返回 nullptrif (pre.empty() || in.empty()) return nullptr;// 创建根节点,根节点的值是前序遍历中的第一个元素TreeNode* subroot = new TreeNode(pre[0]);// 在中序遍历中找到根节点的位置,根节点就是前序遍历的第一个元素for (int i = 0; i < in.size(); i++) {// 如果中序遍历的第 i 个元素等于前序遍历的第一个元素,说明找到了根节点if (in[i] == pre[0]) {// 划分出左子树的前序遍历 (pre[1] 到 pre[i]) 和中序遍历 (in[0] 到 in[i-1])vector<int> _pre(pre.begin() + 1, pre.begin() + i + 1);vector<int> _in(in.begin(), in.begin() + i);// 划分出右子树的前序遍历 (pre[i+1] 到 pre.end) 和中序遍历 (in[i+1] 到 in.end)vector<int> pre_(pre.begin() + i + 1, pre.end());vector<int> in_(in.begin() + i + 1, in.end());// 递归地建立左子树和右子树subroot->left = buildTree(_pre, _in);subroot->right = buildTree(pre_, in_);break; // 找到根节点后退出循环}}// 返回构建好的子树根节点return subroot;}};思路分析
1. 基本情况:
• 当前序遍历 (pre) 或中序遍历 (in) 为空时,说明这部分子树不存在,直接返回 nullptr。
2. 创建根节点:
• 前序遍历的第一个元素即为当前子树的根节点。我们用这个值创建一个新的节点 subroot。
3. 找到根节点的位置:
• 在中序遍历 in 中,找到当前根节点(即前序遍历中的第一个元素)的索引 i。
• 中序遍历的特点是:根节点左边是左子树的元素,右边是右子树的元素。所以我们可以通过根节点的位置将 in 和 pre 数组分成两部分,分别对应左子树和右子树。
4. 递归构建左右子树:
• 左子树的前序遍历是前序遍历的第 1 到第 i 个元素(因为前序遍历中,根节点是第一个元素,左子树的元素紧接着根节点)。
• 左子树的中序遍历是中序遍历的第 0 到第 i-1 个元素。
• 右子树的前序遍历是前序遍历的第 i+1 到最后一个元素。
• 右子树的中序遍历是中序遍历的第 i+1 到最后一个元素。
5. 递归结束条件:
• 当没有更多元素可以划分时,递归会返回 nullptr。
注意
这是一个构造新的 vector<int> 的方法,使用的是 迭代器范围 的方式来构建子数组。具体来说,这里涉及到:
1. pre.begin() + 1
• pre.begin() 返回 pre 数组的第一个元素的迭代器。
• pre.begin() + 1 表示跳过数组的第一个元素,指向第二个元素,即 pre[1]。
2. pre.begin() + i + 1
• pre.begin() + i + 1 表示从 pre 数组的第 i+1 个元素的迭代器开始,注意这并不包括 pre[i+1] 之前的元素。
• 例如,如果 i = 1,pre.begin() + i + 1 就是 pre[2](即 20)
假设前序遍历 pre = [3, 9, 20, 15, 7],在第一次递归中,i = 1。根据上面的划分:
• pre.begin() + 1 指向 9。
• pre.begin() + i + 1 指向 20。
所以,pre.begin() + 1 到 pre.begin() + i + 1 的范围实际上是 [9],而不是 [9, 20],因为这就是 pre[1] 到 pre[1] 之间的范围。
运行步骤(举例)
假设给定前序遍历和中序遍历如下:
• 前序遍历 (pre): [3, 9, 20, 15, 7]
• 中序遍历 (in): [9, 3, 15, 20, 7]
第一步:
• 根节点是前序遍历的第一个元素:3。
• 在中序遍历中找到 3,它的位置是 1。
• 左子树的中序遍历:[9]。
• 右子树的中序遍历:[15, 20, 7]。
第二步:
• 左子树的前序遍历是 [9],中序遍历是 [9]。
• 递归构建左子树:
• 根节点是 9,左右子树为空,返回节点 9。
第三步:
• 右子树的前序遍历是 [20, 15, 7],中序遍历是 [15, 20, 7]。
• 根节点是 20。
• 在中序遍历中找到 20,它的位置是 1。
• 左子树的中序遍历是 [15]。
• 右子树的中序遍历是 [7]。
第四步:
• 左子树的前序遍历是 [15],中序遍历是 [15]。
• 递归构建左子树:
• 根节点是 15,左右子树为空,返回节点 15。
第五步:
• 右子树的前序遍历是 [7],中序遍历是 [7]。
• 递归构建右子树:
• 根节点是 7,左右子树为空,返回节点 7。
最终结果:
构建的二叉树如下:
3
/ \
9 20
/ \
15 7
时间复杂度
• 在每一层递归中,我们需要查找当前根节点在中序遍历中的位置,这需要 O(n) 时间(n 是当前子树的大小)。
• 总共有 O(n) 层递归,故总的时间复杂度是 O(n^2),其中 n 是节点数。
空间复杂度
• 每次递归中需要创建新的数组用于存储左子树和右子树的前序遍历和中序遍历,空间复杂度是 O(n)。
如果可以优化查找中序位置的过程,可以将时间复杂度降低到 O(n)。
优化方案
优化的思路:
为了降低时间复杂度,我们可以利用哈希表(unordered_map)来存储每个元素在中序遍历中的位置,这样在查找根节点的位置时,就可以在 O(1) 的时间内完成查找。
优化后的步骤:
1. 创建哈希表:在开始构建二叉树之前,先遍历一次中序遍历数组,将每个元素的值与它的索引建立映射。这允许我们在递归过程中直接通过哈希表找到根节点在中序遍历中的位置,从而避免每次都要遍历整个中序数组。
2. 递归时直接访问位置:通过哈希表可以在 O(1) 时间内找到当前根节点在中序遍历中的位置,从而使得每次递归只需要 O(1) 时间来分割数组,避免了 O(n) 的查找操作。
优化后的代码:
class Solution {public:// 哈希表用于存储中序遍历每个元素的索引unordered_map<int, int> inOrderMap;TreeNode* buildTree(vector<int>& pre, vector<int>& in) {// 初始化哈希表for (int i = 0; i < in.size(); ++i) {inOrderMap[in[i]] = i;}// 调用递归函数,初始时传入前序遍历的全部元素return build(pre, 0, pre.size() - 1, 0, in.size() - 1);}TreeNode* build(const vector<int>& pre, int preStart, int preEnd, int inStart, int inEnd) {// 递归出口:如果当前子树的范围为空if (preStart > preEnd || inStart > inEnd) {return nullptr;}// 当前子树的根节点是前序遍历中的第一个元素TreeNode* root = new TreeNode(pre[preStart]);// 获取当前根节点在中序遍历中的位置int rootIndexInInOrder = inOrderMap[pre[preStart]];// 左子树的元素数量int leftSize = rootIndexInInOrder - inStart;// 递归构建左子树root->left = build(pre, preStart + 1, preStart + leftSize, inStart, rootIndexInInOrder - 1);// 递归构建右子树root->right = build(pre, preStart + leftSize + 1, preEnd, rootIndexInInOrder + 1, inEnd);return root;}};解释:
1. 哈希表的构建:
• 在 buildTree 函数中,首先我们创建一个 unordered_map<int, int> inOrderMap 来存储中序遍历中每个元素的索引。
• 通过一次遍历中序数组,我们将元素和它们的索引存入哈希表。这个过程的时间复杂度是 O(n)。
2. 递归函数 build:
• 该函数接受前序遍历的子数组范围 preStart 到 preEnd 和中序遍历的子数组范围 inStart 到 inEnd。
• 每次递归从前序遍历中取出一个元素作为根节点,通过哈希表在 O(1) 时间内找到该根节点在中序遍历中的索引。
• 然后,根据根节点的位置将数组分成左子树和右子树,并递归构建左右子树。
3. 递归过程:
• 在构建每个子树时,计算左子树的大小 leftSize,并使用前序遍历的下一个元素作为左子树的根节点,递归地构建左子树和右子树。
时间复杂度:
• 创建哈希表:这一步需要遍历整个中序数组,时间复杂度是 O(n)。
• 递归构建树:每次递归操作仅需 O(1) 时间来查找根节点的位置,并且每个节点都会被访问一次,因此总的时间复杂度是 O(n)。
因此,优化后的算法的总时间复杂度是 O(n)。
好的,下面我将详细解释优化后的代码的运行步骤,展示如何通过前序遍历和中序遍历重建二叉树,特别是在使用哈希表优化查找操作之后。
我们仍然使用以下例子:
• 前序遍历 (pre): [3, 9, 20, 15, 7]
• 中序遍历 (in): [9, 3, 15, 20, 7]
1. 哈希表的构建
首先,我们构建一个哈希表 inOrderMap 来存储中序遍历每个元素的索引。遍历一次中序数组:
unordered_map<int, int> inOrderMap;
for (int i = 0; i < in.size(); ++i) {
inOrderMap[in[i]] = i;
}
结果:
inOrderMap = {
9: 0,
3: 1,
15: 2,
20: 3,
7: 4
};
这个哈希表允许我们在 O(1) 时间内找到任意元素在中序遍历中的位置。
2. 递归构建树的过程
接下来,我们通过递归构建二叉树。递归函数 build 的参数是:
• pre:前序遍历数组。
• preStart 和 preEnd:当前子树在前序遍历中的范围。
• inStart 和 inEnd:当前子树在中序遍历中的范围。
初始调用:
build(pre, 0, pre.size() - 1, 0, in.size() - 1);
也就是 preStart = 0, preEnd = 4, inStart = 0, inEnd = 4,这表示我们要构建整个二叉树。
第一步:构建根节点
1. 根节点:当前子树的根节点是前序遍历的第一个元素 pre[preStart] = 3。
所以当前树的根节点是 3。
2. 查找根节点位置:在中序遍历 [9, 3, 15, 20, 7] 中,通过哈希表,我们可以直接在 O(1) 时间内找到 3 的位置 inOrderMap[3] = 1。
3. 计算左子树大小:根据根节点的位置,左子树的元素数量是 rootIndexInInOrder - inStart = 1 - 0 = 1。
4. 递归构建左右子树:
• 左子树的前序遍历是 [9],中序遍历是 [9]。
• 右子树的前序遍历是 [20, 15, 7],中序遍历是 [15, 20, 7]。
递归调用:
• 构建左子树:build(pre, 1, 1, 0, 0)。
• 构建右子树:build(pre, 2, 4, 2, 4)。
第二步:构建左子树
左子树的递归调用 build(pre, 1, 1, 0, 0):
1. 根节点:当前子树的根节点是 pre[preStart] = 9。
所以当前左子树的根节点是 9。
2. 查找根节点位置:在中序遍历 [9] 中,通过哈希表找到 9 的位置 inOrderMap[9] = 0。
3. 计算左子树大小:左子树的元素数量是 rootIndexInInOrder - inStart = 0 - 0 = 0。
4. 递归构建左右子树:
• 左子树的前序遍历是 [],中序遍历是 []。
• 右子树的前序遍历是 [],中序遍历是 []。
递归调用:
• 构建左子树:build(pre, 2, 1, 0, -1),返回 nullptr(空树)。
• 构建右子树:build(pre, 2, 1, 1, 0),返回 nullptr(空树)。
左子树构建完成,返回节点 9。
第三步:构建右子树
右子树的递归调用 build(pre, 2, 4, 2, 4):
1. 根节点:当前子树的根节点是 pre[preStart] = 20。
所以当前右子树的根节点是 20。
2. 查找根节点位置:在中序遍历 [15, 20, 7] 中,通过哈希表找到 20 的位置 inOrderMap[20] = 3。
3. 计算左子树大小:左子树的元素数量是 rootIndexInInOrder - inStart = 3 - 2 = 1。
4. 递归构建左右子树:
• 左子树的前序遍历是 [15],中序遍历是 [15]。
• 右子树的前序遍历是 [7],中序遍历是 [7]。
递归调用:
• 构建左子树:build(pre, 3, 3, 2, 2)。
• 构建右子树:build(pre, 4, 4, 4, 4)。
第四步:构建左子树(右子树的左子树)
左子树的递归调用 build(pre, 3, 3, 2, 2):
1. 根节点:当前子树的根节点是 pre[preStart] = 15。
所以当前左子树的根节点是 15。
2. 查找根节点位置:在中序遍历 [15] 中,通过哈希表找到 15 的位置 inOrderMap[15] = 2。
3. 计算左子树大小:左子树的元素数量是 rootIndexInInOrder - inStart = 2 - 2 = 0。
4. 递归构建左右子树:
• 左子树的前序遍历是 [],中序遍历是 []。
• 右子树的前序遍历是 [],中序遍历是 []。
递归调用:
• 构建左子树:build(pre, 4, 3, 2, 1),返回 nullptr(空树)。
• 构建右子树:build(pre, 4, 3, 3, 2),返回 nullptr(空树)。
左子树构建完成,返回节点 15。
第五步:构建右子树(右子树的右子树)
右子树的递归调用 build(pre, 4, 4, 4, 4):
1. 根节点:当前子树的根节点是 pre[preStart] = 7。
所以当前右子树的根节点是 7。
2. 查找根节点位置:在中序遍历 [7] 中,通过哈希表找到 7 的位置 inOrderMap[7] = 4。
3. 计算左子树大小:左子树的元素数量是 rootIndexInInOrder - inStart = 4 - 4 = 0。
4. 递归构建左右子树:
• 左子树的前序遍历是 [],中序遍历是 []。
• 右子树的前序遍历是 [],中序遍历是 []。
递归调用:
• 构建左子树:build(pre, 5, 4, 4, 3),返回 nullptr(空树)。
• 构建右子树:build(pre, 5, 4, 5, 4),返回 nullptr(空树)。
右子树构建完成,返回节点 7。
最终结果
经过所有递归调用,我们最终得到了以下的二叉树:
3
/ \
9 20
/ \
15 7
总结
通过哈希表优化查找根节点在中序遍历中的位置,我们将每次递归中的查找操作的时间复杂度降低为 O(1),使得整体的时间复杂度从 O(n²) 优化到了 O(n)。
相关文章:

LeetCodehot 力扣热题100 从前序与中序遍历序列构造二叉树
初始版本 这段代码实现了根据前序遍历和中序遍历重建二叉树。下面我将详细解释每一行的作用,并逐步讲解算法的思路和运行步骤。 代码及注释 class Solution {public:// buildTree 函数用来根据前序遍历(pre)和中序遍历(in)重建二叉树TreeNode* buildTree(vector<…...

Day45(补)【软考】2022年下半年软考软件设计师综合知识真题-计算机软件知识1
文章目录 2022年下半年软考软件设计师综合知识真题第1章 计算机系统基础知识(12/38)计算机软件知识1-6/6哲学概念及收敛思维:是Python程序语言中,处理异常的结构集合,和这个集合之外的结构的区分,考Python集合之外的结构 哲学概念…...
luoguP8764 [蓝桥杯 2021 国 BC] 二进制问题
luogu题目传送门 题目描述 小蓝最近在学习二进制。他想知道 1 到 N 中有多少个数满足其二进制表示中恰好有 K 个 1。你能帮助他吗? 输入格式 输入一行包含两个整数 N 和 K。 输出格式 输出一个整数表示答案。 输入输出样例 输入 #1 7 2 输出 #1 3 说明/提示 对于…...
——Skia、OpenGL、Mesa 和 Vulkan简介)
图形渲染(一)——Skia、OpenGL、Mesa 和 Vulkan简介
1.Skia —— 2D 图形库 Skia 是一个 2D 图形库,它的作用是为开发者提供一个高层次的绘图接口,方便他们进行 2D 图形渲染(比如绘制文本、形状、图像等)。Skia 本身不直接管理 GPU 或进行底层的渲染工作,而是通过 底层图…...

浏览器打开Axure RP模型
1,直接使用chrome打开,提示下载插件 2,需要做一些操作 打开原型文件,找到resources\chrome\axure-chrome-extension.crx文件,这就是我们需要的Chrome插件。 将axure-chrome-extension.crx文件后缀名改为axure-chrome…...
格式)
【计算机网络】数据链路层数据帧(Frame)格式
在计算机网络中,数据帧(Frame) 是数据链路层的协议数据单元(PDU),用于在物理介质上传输数据。数据帧的格式取决于具体的链路层协议(如以太网、PPP、HDLC 等)。以下是常见数据帧格式的…...

平面与平面相交算法杂谈
1.前言 空间平面方程: 空间两平面如果不平行,那么一定相交于一条空间直线, 空间平面求交有多种方法,本文进行相关讨论。 2.讨论 可以联立方程组求解,共有3个变量,2个方程,而所求直线有1个变量…...

web集群(LVS-DR)
LVS是Linux Virtual Server的简称,也就是Linux虚拟服务器, 是一个由章文嵩博士发起的自由软件项 目,它的官方站点是 www.linuxvirtualserver.org。现在LVS已经是 Linux标准内核的一部分,在 Linux2.4内核以前,使用LVS时必须要重新编…...

更高效实用 vscode 的常用设置
VSCode 可以说是文本编辑神器, 不止程序员使用, 普通人用其作为文本编辑工具, 更是效率翻倍. 这里分享博主对于 VSCode 的好用设置, 让 VSCode 如虎添翼 进入设置 首先进入设置界面, 后续都在这里进行配置修改 具体设置 每项配置通过搜索关键字, 来快速定位配置项 自动保存…...

win11 终端乱码导致IDE 各种输出也乱码
因为 win11 终端乱码导致IDE 各种输出也乱码导致作者对此十分头大。所以研究了各种方法。 单独设置终端编码对 HKEY_CURRENT_USER\Console 注册表进行修改对 HKEY_LOCAL_MACHINE\Software\Microsoft\Command Processo 注册表进行修改使用命令[Console]::OutputEncoding [Syst…...

对于简单的HTML、CSS、JavaScript前端,我们可以通过几种方式连接后端
1. 使用Fetch API发送HTTP请求(最简单的方式): //home.html // 示例:提交表单数据到后端 const submitForm async (formData) > {try {const response await fetch(http://your-backend-url/api/submit, {method: POST,head…...

Flutter中 List列表中移除特定元素
在 Dart 语言里,若要从子列表中移除特定元素,可以使用以下几种方法,下面为你详细介绍: 方法一:使用 where 方法创建新列表 where 方法会根据指定的条件筛选元素,然后通过 toList 方法将筛选结果转换为新列…...

DeepSeek从入门到精通(清华大学)
DeepSeek是一款融合自然语言处理与深度学习技术的全能型AI助手,具备知识问答、数据分析、编程辅助、创意生成等多项核心能力。作为多模态智能系统,它不仅支持文本交互,还可处理文件、图像、代码等多种格式输入,其知识库更新至2…...

动态规划:解决复杂问题的高效策略
动态规划(Dynamic Programming,简称 DP)是一种在数学、管理科学、经济学、计算机科学等领域中广泛使用的算法设计技术。它通过将复杂问题分解为更简单的子问题,并通过存储子问题的解来避免重复计算,从而高效地解决问题…...

【kafka系列】Kafka事务的实现原理
目录 1. 事务核心组件 1.1 幂等性生产者(Idempotent Producer) 1.2 事务协调器(TransactionCoordinator) 1.3 事务日志(Transaction Log) 2. 事务执行流程 2.1 事务初始化 2.2 发送消息 2.3 事务提…...

网络将内网服务转换到公网上
当然,以下是根据您提供的描述,对内网端口在公网上转换过程的详细步骤,并附上具体例子进行说明: 内网端口在公网上的转换过程详细步骤 1. 内网服务配置 步骤说明: 在内网中的某台计算机(我们称之为“内网…...

c#自动更新-源码
软件维护与升级 修复漏洞和缺陷:软件在使用过程中可能会发现各种漏洞和缺陷,自动更新可以及时推送修复程序,增强软件的稳定性和安全性,避免因漏洞被利用而导致数据泄露、系统崩溃等问题。提升性能:通过自动更新&#x…...

爬虫实战:利用代理ip爬取推特网站数据
引言 亮数据-网络IP代理及全网数据一站式服务商屡获殊荣的代理网络、强大的数据挖掘工具和现成可用的数据集。亮数据:网络数据平台领航者https://www.bright.cn/?promoRESIYEAR50/?utm_sourcebrand&utm_campaignbrnd-mkt_cn_csdn_yingjie202502 在跨境电商、社…...
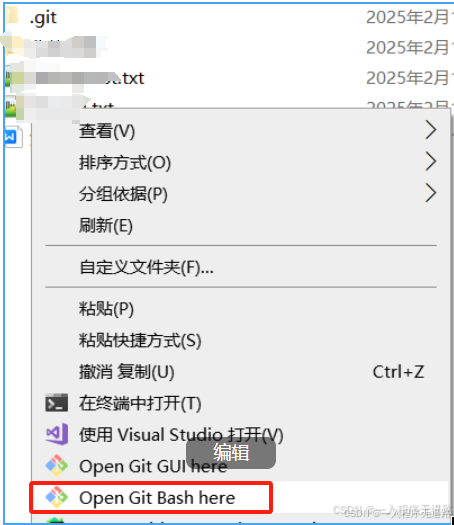
git使用,注意空格
第一节 安装完成后,找个目录用于存储,打开目录右击选择git bash here 命令1 姓名 回车 git config --global user.name "li" 命令2 邮箱 回车 git config --global user.email "888163.com" 命令3 初始化新仓库,下载克隆 回…...

138,【5】buuctf web [RootersCTF2019]I_<3_Flask
进入靶场 这段代码是利用 Python 的类继承和反射机制来尝试执行系统命令读取flag.txt文件内容 .__class__:空字符串对象调用__class__属性,得到str类,即字符串的类型。__class__.__base__:str类的__base__属性指向其基类…...

技术决策中的概率思维:没有100%的可靠系统
一、软件测试中的“绝对可靠”幻象在软件测试的日常工作中,我们常常会陷入一种追求“绝对可靠”的执念。测试人员耗费大量时间设计用例、执行测试,试图找出所有潜在的Bug,期望交付一个毫无瑕疵的系统。然而,现实却一次次给我们泼冷…...

ARM Cortex-A7内存系统架构与优化实践
1. ARM Cortex-A7内存系统架构概览Cortex-A7作为ARMv7-A架构中的经典低功耗处理器,其内存子系统设计体现了现代嵌入式处理器的典型优化思路。L1缓存采用分离式指令/数据设计(哈佛架构),指令侧最大支持64KB 2路组相联VIPT缓存&…...

3分钟掌握手机号码精准定位:开源工具location-to-phone-number完全指南
3分钟掌握手机号码精准定位:开源工具location-to-phone-number完全指南 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://git…...

3203黄大年茶思屋榜文保姆级全落地解法「32期3题」量子启发式算法|大规模百万节点图平衡最小分割优化
03华夏之光永存・开源:黄大年茶思屋榜文保姆级全落地解法「32期3题」 【题目通用标题】 量子启发式算法|大规模百万节点图平衡最小分割优化 (前20% 干货区・免费可见) 核心结论先行(上机可跑、全参数开源、零修改直接用) 本题所属大规模图计算、组合优化、量子启发式…...

用Python 和 java 写 10 道题
1.已知1、1、2、3、5、8、13......就是从第三项开始,每一项等于前两项之和。求第100项。python写a,b 1,1 #第一项和第二项 for _ in range(3,101): #从第3项计算到第100项,需循环98次(前两项已有)a,b b,ab #a 变成前一项 b 变成新的当前…...

agent-skills中的异步编程:提高应用并发性能的实用方法
agent-skills中的异步编程:提高应用并发性能的实用方法 【免费下载链接】agent-skills Production-grade engineering skills for AI coding agents. 项目地址: https://gitcode.com/GitHub_Trending/agentskill/agent-skills 在现代应用开发中,异…...

AMD GPU深度学习优化:ROCm环境配置与性能调优
1. AMD GPU在深度学习领域的现状与挑战AMD GPU在深度学习领域一直处于追赶者的角色,这与CUDA生态的先发优势密不可分。但近年来随着ROCm平台的持续完善,特别是从ROCm 5.0版本开始,AMD显卡在深度学习工作负载上的表现已经能够满足生产需求。我…...
三种模式:--soft、--mixed(默认)、--hard;修改最近提交、合并多个提交、取消git add、回退版本回退)
Git Reset命令介绍(用于移动HEAD,并选择是否同步更新暂存区工作区)三种模式:--soft、--mixed(默认)、--hard;修改最近提交、合并多个提交、取消git add、回退版本回退
注意区分:git reset和git reset HEAD~1(功能完全不同,git reset只用于取消文件暂存) 命令移动HEAD重置暂存区保留工作目录更改主要用途git reset❌ 不移动✅ 重置到HEAD✅ 保留取消文件暂存git reset HEAD~1✅ 移动到前一个提交✅…...

收藏!小白程序员必看:2026年AI岗位平均月薪60K+,如何抓住高薪机遇?
2026年春招显示AI岗位平均月薪达60738元,远超行业平均水平,但高校毕业生求职难与AI人才紧缺并存。文章分析指出,AI技能普及化、企业招聘偏好成熟人才、灵活用工趋势等,都要求求职者具备复合能力,主动提升AI技能。职场正…...

收藏!小白程序员必看:如何用Tair构建秒级响应的AI Agent记忆系统?
本文以淘宝闪购AI Agent项目为例,阐述了AI Agent对高性能记忆层的迫切需求。文章深入分析了Tair在数据模型设计(List、Hash)、压缩策略与并发控制方面的关键实践,并探讨了Tair如何通过多线程内核、读写分离、弹性扩缩容及带宽管理…...