【进阶】JVM篇
为什么学习jvm
1、面试的需要
学过java的程序员对jvm应该不陌生,程序员为什么要学习jvm呢?其实不懂jvm也可以照样写出优质的代码,但是不懂jvm会被大厂的面试官虐的体无完肤。
2、高级程序员需要了解
jvm作用
jvm负责把编译后的字节码转换为机器码
jvm内部构造
1.类加载部分:负责把硬盘上字节码加载到内存中(运行时数据区)
2.运行时数据区:负责存储运行时产生的各种数据 类信息,对象信息,方法信息……
3.执行引擎:负责将字节码转为机器码
4.本地方法接口:调用本地方法, Object类中的 hashCode()--拿对象的内存地址
public native int hashCode();
private native int read0() throw IOEception;
垃圾回收部分
jvm类加载系统
1.类加载子系统概述
类加载器子系统负责从文件系统或者网络中加载class文件,类加载系统只负责class文件的加载,至于它是否可以运行,则由执行引擎决定。
加载的类信息存放于一块称为方法区的内存空间
类加载系统,负责将硬盘上的字节码文件加载到jvm中,生成类的Class对象,存储在方法区。
类就是一个模板
2、类加载过程
1.加载
以二进制字符流进行读取
在内存中为类生成Class对象
2.链接
·验证:检验被加载的类是否有正确的内部结构,并和其他类协调一致;
·准备 为类的静态属性进行初始化的赋值
准备阶段 先赋值为默认0 在初始化阶段赋值为‘123’
·解析 把字节码的符号引用 替换成 内存中的直接引用地址
3.初始化
初始化阶段主要是为类中的静态成员进行赋值
因为类加载执行完初始化阶段,才说明类加载完成了。
类在哪些情况下会被加载
调用类中静态成员(变量,方法)
new关键字调用
执行该类的main()
反射加载类 Class class.forName("地址");
子类被加载
类在以下两种情况下,是不会被加载的
1.类作为数组类型 Demo[] demo = new Demo[10]; //new的数组对象 不是Demo对象 2.只是访问类中的静态的常量 System.out.println(Demo.P);// 优化 不加载整个类了,只获取到用到的静态常量
类加载器
类加载器就是实际负责读取类的功能
类加载器分类:
站在jvm的角度上,分为
引导类加载器(不是用java写的,是用c/c++),负责读取加载java中底层系统库
java写的类加载器(用来读取我们写的应用程序)
在细分类加载器
1.启动类加载器
C/C++语言实现,负载加载java核心类库(系统库 java.lang)
2.扩展类类加载器
用java语言实现的,继承ClassLoader类,加载jre下面扩展类的 jre/lib/ext 子目录
3.应用程序类加载器
用java语言实现的,继承ClassLoader类,用于加载用户自己定义的类(开发的应用程序).
双亲委派机制
当加载一个类时,总是先让他的父级类加载器去加载,确保把系统中类优先加载,直到父类加载器找不到类时,再逐级向下,让子类加载器加载,
如果子级也找不到,最终抛出类找不到异常
为什么这样做?
防止我们自己写的类替换了系统中的类
如何打破双亲委派机制
自定义类加载器
MyClassLoader extends ClassLoader //重写findClass()
运行时数据区
存储运行时产生的各种数据
程序计数器
程序计数器用来记录每一个线程执行的指令位置,
速度是最快的,是线程私有的(每一个线程都会有一个程序计数器)
此区域不会出现内存溢出,也不会垃圾回收
虚拟机栈
栈是运行的,解决程序方法执行,在虚拟机栈中,运行我们java自己写的方法
调用方法,方法入栈,运行结束出栈(先进后出 栈顶的方法,称为当前栈帧)
一个方法就是一个栈帧,在栈帧中存储局部变量,运行结果……
虚拟机栈也是线程私有的,线程之间互相隔离
栈区域不存在垃圾回收,但是会存在内存溢出问题
栈帧中存储什么内容?
局部变量表 int a=10;
操作数栈(计算过程) int c = a+b;
方法返回地址
本地方法栈
本地方法栈是用来执行调用的本地方法的.
是线程私有的,不会存在垃圾回收,
会出现内存溢出问题
堆
堆概述
堆的作用是用来存储java语言产生的对象的.
是运行时数据区中最大的一块内存空间,空间大小可以设置
堆空间是所有线程共享的.
对空间是垃圾回收的重点区域,堆中没有被使用到的垃圾对象,会被垃圾回收器回收调用
堆空间区域划分
堆分为
新生区(新生代 年轻代)
伊甸园区
幸存者0区
幸存者1区
老年区(老年代)
为什么分区(代)?
可以将不同生命周期的对象存储在不同的区域,针对不同的区域采用不同的垃圾回收算法,使得垃圾回收策略更加优化.
对象创建存储过程
新创建的对象都存储在伊甸园区
当垃圾回收时,将还被使用的对象,转移至某一个幸存者区,将伊甸园区进行清除,
当下一次垃圾回收时,将伊甸园区存储的对象与当前正在使用的幸存者区存活的对象,转移至另一个幸存者区(每一次会空闲一个幸存者区)
当一个对象经历过15次垃圾回收后,仍然存活的话,那么就把该对象移动到老年代,
老年代就比较少的进行垃圾回收,在老年代空间不足时,对老年代会进行垃圾回收,
当回收后,内存仍然不足时,会触发FULL GC(整堆收集 应尽量避免)
当整堆收集后仍然不够使用,那么就会出现内存溢出错误 --OOM

jvm调优
可以根据程序具体的使用场景,对运行时数据区的各种空间大小调整 例如堆,方法区
对垃圾回收器进行选择(根据使用的场景选择单线程的或者是多线程的)
方法区
方法区主要用来存储加载的类 信息
方法区的大小也是可以设置的
方法区也会进行垃圾回收,方法区也可能会出现内存溢出的问题
方法区的垃圾回收
方法区的垃圾回收,是对类信息进行回收的
类信息如果不再被使用,类信息也可以被卸载
卸载条件
该类所产生的对象都不存在了
该类的Class对象,也不再被使用了
加载该类的类加载器也被回收了.
本地方法接口
是虚拟机中专门用来调用本地方法的接口
什么是本地方法
在java中被native关键字修饰的方法,没有方法体,不是用java语言实现的方法,用C/C++在操作系统底层实现的方法
Object hashCode() 获取对象内存地址 涉及到读取内存
IO中读文件(输入文件 操作硬盘) read0();
启动线程 native void start0(); 启动线程 就是把这个线程注册到操作系统
java中为什么要调用本地方法
因为java属于应用层语言,有时候,需要对硬件系统资源进行调用
此时就不方便,再一个系统资源不允许应用层程序直接调用
那么就需要通过本地方法 调用操作硬件资源
执行引擎
1.执行引擎是java虚拟机核心的组成部分之一
主要作用是将加载到虚拟机中的字节码,再次转换为机器码(字节码并不是系统能够直接执行的机器码)
执行引擎可以通过解释/编译两种方式 实现将字节码转为机器码
java程序执行过程中涉及两次编译
第一次 .java(源代码 通过jdk javac 调用编译器) -->.class文件 称为前端编译
第二次 通过执行引擎 将字节码 编译为 机器码 称为后端编译
将字节码转为机器码有两种方式:
解释器(解释执行):对字节码逐行进行解释翻译,重复性的代码,也是每次都要解释执行,效率低
编译器(编译执行):对某一段字节码进行整体编译,然后存储起来,以后使用时不再需要编译了,效率高。
编译器会针对执行过程中的热点代码进行编译,并缓存起来
为什么要使用解释执行和编译执行并存这样的设计?
程序开始运行时,解释器可以立即发挥作用,投入使用
而编译器虽然执行效果高,但是前期需要对热点代码进行跟踪和编译,需要消耗时间
垃圾回收
什么是垃圾对象?
垃圾是指在运行程序中没有任何引用指向的对象
就是一个对象 不再被任何的引用所指向。
没有任何引用所指向的对象
垃圾对象如果不清理,新的对象可能没有足够的空间,可能会导致内存的溢出问题。
垃圾回收发展
早期c/c++这类语言,内存管理都是手动的,使用时申请,使用完后手动释放
优点:对内存管理更加精确,效率高
缺点:增加程序员的负担,控制不好,容易出事(忘了释放,误操作内存空间)
后来发展为自动回收:
java,,C#…都采用自动垃圾回收
优点:解放了程序员
缺点:会占用一些内存空间(垃圾不是出现后立即回收的),降低了程序员管理内存的能力
哪些区域会出现垃圾回收?
堆 对象 频繁回收年轻代 较少回收老年代
方法区 类信息卸载 整堆收集时,会进行回收 FULL GC
内存溢出与内存泄漏
内存溢出:内存不够用了
内存泄漏:系统中那些用不到的,但是又不能回收的对象
案例:单例对象
数据库连接对象,IO流,socket 这些提供close()类
用完之后,如果没有关闭, 垃圾回收器是不能主动回收这些对象的.
内存泄漏,虽然不能直接触发内存溢出,但是长期有对象不能被回收,也是导致内存泄漏的原因之一.
Stop the world
垃圾回收时。会经历两个阶段:一是标记阶段 二是回收阶段。
在标记和回收时,需要我们的用户线程暂停,不暂停的话 在标记和回收时可能会出现错标和漏标
垃圾回收阶段算法
1.垃圾标记阶段
将虚拟机中不再被任何引用指向的对象标记出来,在垃圾回收阶段,就会将标记出来对象进行回收
垃圾标记阶段相关算法
引用计数算法(存在缺陷的,没有被虚拟机所使用的)
设计思想: 在对象中维护一个整数计数器变量 当有引用指向对象时,计数器就加一,相反就减一(引用断开)
优点: 设计实现简单,容易分辨对象是否是垃圾对象
缺点:需要维护一个变量存储引用数量,频繁修改引用计数器变量,占空间,还耗时
最重要的是,无法解决循环引用问题
可达性分析算法(根搜索法)
设计思想:从一些可以被称为GCRoots的对象开始向下查找,只要某一个对象与GCRoots对象有联系的,就可以判定对象是被使用的,与跟对象引用链没有任何关系的对象,可以视为垃圾对象
哪些对象可以作为GCRoots(根对象)?
1.虚拟机栈中(被调用的方法)所使用的对象
2.类中的静态属性
3.虚拟机中使用的系统类对象
4.所有被同步锁synchronized持有的对象
对象中的finalize机制
Object类中有一个finalize()这个方法是在对象被回收之前,由虚拟机自动调用的,
在对象被回收前,需要执行的一些操作,就可以在此方法中编写
finalize()方法可以在子类中重写
finalize()方法指挥被调用一次(第一次被判定为垃圾,要对其回收,调用finalize(),对象有可能又被引用了,对象就不能被回收,当下一次被判定为垃圾对象时,就不会调用finalize())
由于finalize()方法存在,被标记为垃圾的对象,也不是非死不可的。
可以将对象分为三种状态:
可触及:被GCRoots引用的, 不是垃圾对象
可复活的:被判定为垃圾的,但是finalize()方法还没有被调用过的
不可触及的(必死无疑的):被判定为垃圾,且执行过finalize()方法
2.垃圾回收阶段
1.标记-复制算法
将内存可以分为多个较小的块,当发生垃圾回收时,将一个区域中存活的对象复制到另一个区域,
在另一个区域从头开始排列,清除当前垃圾回收的区域
优点:清理之后,内存没有碎片
不足:回收时,需要移动对象,所以适合小内存块,而且存活对象少的情况
适合用于新生代
2.标记-清除算法
将被标记为垃圾的对象地址进行记录。后面如果分配新对象,判断垃圾对象空间能否存储下新的对象,
如果能存储下,用新对象直接覆盖垃圾对象即可
存活对象是不发生移动的.
优点:不会移动对象
不足:回收后,内存空间碎片化
3.标记-压缩(整理)算法
将存活的对象会移动到内存区域的一端,按顺序排列(压缩),清理边界以外的空间,在标记清除的基础上进行一次内存整理.
优点:回收后没有内存碎片
标记-清除和标记压缩对比
标记-清除:不移动存活对象
标记-压缩:会移动存活对象
两者都适合用于老年代对象回收
先使用标记-清除,当老年代 空间不足时,或者不能存储一个比较大的对象时,在使用标记-压缩算法
垃圾回收时,根据不同的分区采用不同的回收算法
新生代 : 标记-复制
老年代 : 标记-清除 标记-压缩
垃圾回收器
什么是垃圾回收器
垃圾回收器,是对垃圾回收过程实践者(落地)
不同的虚拟机中,垃圾回收器种类也是很多的
有哪些垃圾回收器 特点
垃圾回收器分类:
从线程数量上分:
单线程 垃圾回收线程只有一个
多线程 有多个垃圾回收线程
从工作模式上分:
独占式:垃圾回收线程执行时,其他用户线程需要暂停(stop the world)
并发式: 垃圾回收线程和用户线程可以做到并发执行
从分区角度上分:
新生代
老年代
垃圾收集器性能指标:
吞吐量
用户线程暂停时间(重点)
回收时内存开销
Serial 单线程 新生代
Serial Old, 单线程 老年代
ParNew、Parallel Scavenge, 多线程 新生代收集器
Parallel Old, 多线程老年代收集器
CMS, 多线程老年代收集器 (开创了垃圾收集线程与用户线程并发执行的先例)
并发标记清除 收集器
初始标记 --独占执行
并发标记 --并发执行
重新标记 --独占执行
并发清除 --并发执行
G1
G1垃圾回收器,继承了CMS中,垃圾收集线程和用户线程并行执行的特点,减少了用户线程暂停的时间
同时,将新生代和老年代的各个区域,又划分成更小的区域,对每个区域进行跟踪,
优先回收价值高的区域(垃圾多的区域,例如可以把伊甸园区可以分成好几个小的区域)
提升回收效率,提高了吞吐量,不再区分年轻代和老年代,可以做到对整个堆进行回收。
非常适合服务器端程序,大型项目
设置垃圾回收器
相关文章:
【进阶】JVM篇
为什么学习jvm 1、面试的需要 学过java的程序员对jvm应该不陌生,程序员为什么要学习jvm呢?其实不懂jvm也可以照样写出优质的代码,但是不懂jvm会被大厂的面试官虐的体无完肤。 2、高级程序员需要了解 jvm作用 jvm负责把编译后的字节码转换…...

DeepSeek官方推荐的AI集成系统
DeepSeek模型虽然强大先进,但是模型相当于大脑,再聪明的大脑如果没有输入输出以及执行工具也白搭,所以需要有配套工具才能让模型发挥最大的作用。下面是一个典型AI Agent架构图,包含核心组件与数据流转关系: #mermaid-…...

【动态规划篇】:当回文串遇上动态规划--如何用二维DP“折叠”字符串?
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨ ✨ 个人主页:余辉zmh–CSDN博客 ✨ 文章所属专栏:动态规划篇–CSDN博客 文章目录 一.回文串类DP核心思想(判断所有子串是否是回文…...

JENKINS(全面)
一.linux系统中JENKINS的安装 注意:安装jenkins需要安装jdk,而且具体版本的jenkins有相对应的jdk版本。可参考以下链接。 Redhat Jenkins 软件包https://pkg.jenkins.io/redhat-stable/https://pkg.jenkins.io/redhat-stable/https://pkg.jenkins.io/r…...

Promise详解大全:介绍、九个方法使用和区别、返回值详解
Promise的介绍 Promise是异步编程的一种解决方案,它的构造函数是同步执行的,then 方法是异步执行的,所以Promise创建后里面的函数会立即执行,构造函数中的resolve和reject只有第一次执行有效,,也就是说Pro…...

尚硅谷爬虫note004
一、urllib库 1. python自带,无需安装 # _*_ coding : utf-8 _*_ # Time : 2025/2/11 09:39 # Author : 20250206-里奥 # File : demo14_urllib # Project : PythonProject10-14#导入urllib.request import urllib.request#使用urllib获取百度首页源码 #1.定义一…...

Debezium系列之:时区转换器,时间戳字段转换到指定时区
Debezium系列之:时区转换器,时间戳字段转换到指定时区 示例:基本配置应用TimezoneConverter SMT的效果示例:高级配置配置选项当Debezium发出事件记录时,记录中的时间戳字段的时区值可能会有所不同,这取决于数据源的类型和配置。为了在数据处理管道和应用程序中保持数据一…...

ubuntu20.04声音设置
step1:打开pavucontrol,设置Configuration和Output Devices, 注意需要有HDMI / DisplayPort (plugged in)这个图标。如果没有,就先选择Configuration -> Digital Stereo (HDMI 7) Output (unplugged) (unvailable),…...

如何设置Python爬虫的User-Agent?
在Python爬虫中设置User-Agent是模拟浏览器行为、避免被目标网站识别为爬虫的重要手段。User-Agent是一个HTTP请求头,用于标识客户端软件(通常是浏览器)的类型和版本信息。通过设置合适的User-Agent,可以提高爬虫的稳定性和成功率…...

深度学习框架探秘|TensorFlow:AI 世界的万能钥匙
在人工智能(AI)蓬勃发展的时代,各种强大的工具和框架如雨后春笋般涌现,而 TensorFlow 无疑是其中最耀眼的明星之一。它不仅被广泛应用于学术界的前沿研究,更是工业界实现 AI 落地的关键技术。今天,就让我们…...

C++:高度平衡二叉搜索树(AVLTree) [数据结构]
目录 一、AVL树 二、AVL树的理解 1.AVL树节点的定义 2.AVL树的插入 2.1更新平衡因子 3.AVL树的旋转 三、AVL的检查 四、完整代码实现 一、AVL树 AVL树是什么?我们对 map / multimap / set / multiset 进行了简单的介绍,可以发现,这几…...

建筑兔零基础自学python记录18|实战人脸识别项目——视频检测07
本次要学视频检测,我们先回顾一下图片的人脸检测建筑兔零基础自学python记录16|实战人脸识别项目——人脸检测05-CSDN博客 我们先把上文中代码复制出来,保留红框的部分。 然后我们来看一下源代码: import cv2 as cvdef face_detect_demo(…...

【MySQL数据库】Ubuntu下的mysql
目录 1,安装mysql数据库 2,mysql默认安装路径 3,my.cnf配置文件? 4,mysql运用的相关指令及说明 5,数据库、表的备份和恢复 mysql是一套给我们提供数据存取的,更加有利于管理数据的服务的网络程序。下…...
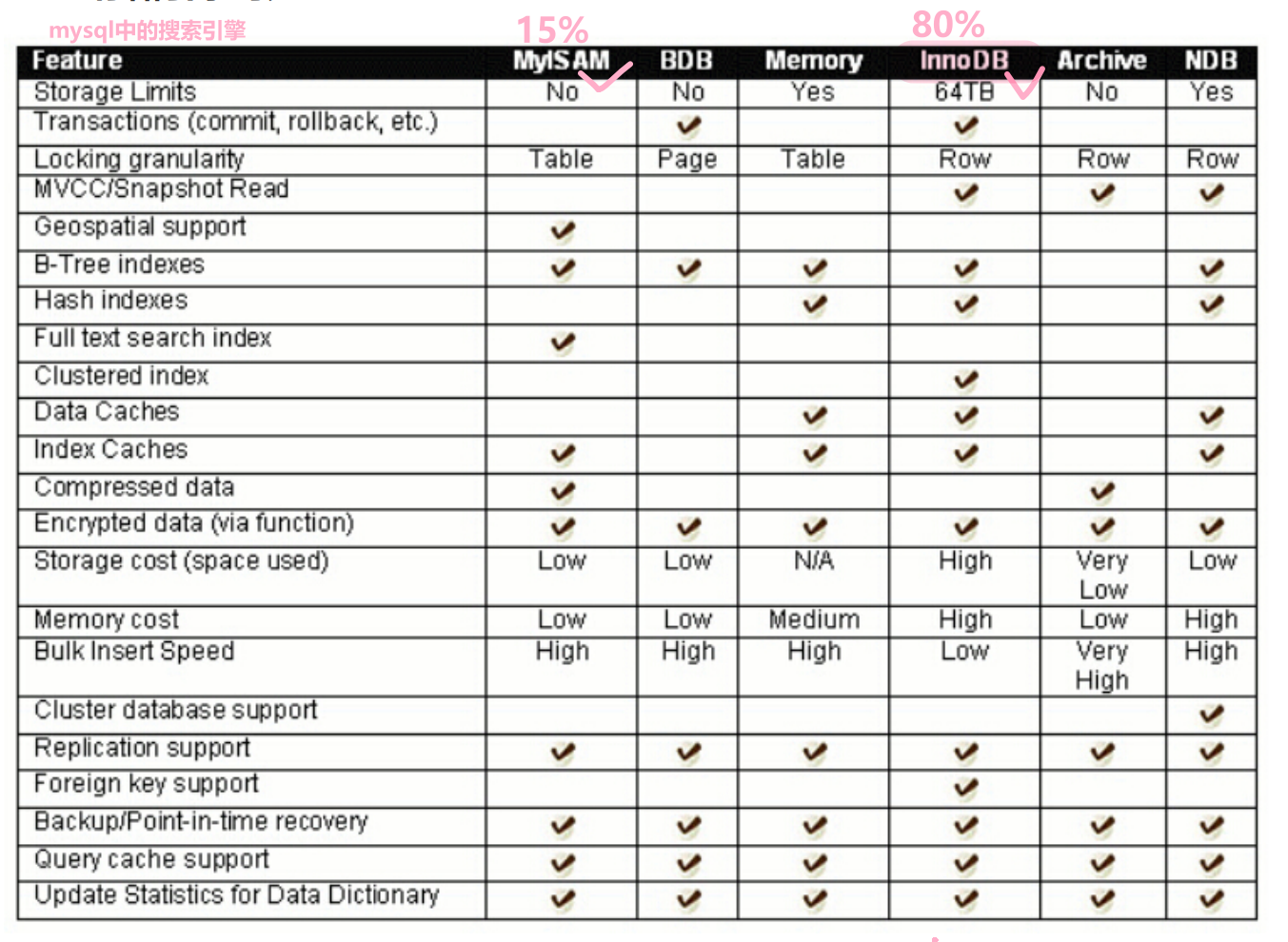
[MySQL#1] database概述 常见的操作指令 MySQL架构 存储引擎
#1024程序员节|征文# 目录 一. 数据库概念 0.连接服务器 1. 什么是数据库 口语中的数据库 为什么数据不直接以文件形式存储,而需要使用数据库呢? 总结 二. ??基础操作 三. 主流数据库 四. 基础知识 服务器,数据库&…...

1.从零开始学会Vue--{{基础指令}}
全新专栏带你快速掌握Vue2Vue3 1.插值表达式{{}} 插值表达式是一种Vue的模板语法 我们可以用插值表达式渲染出Vue提供的数据 1.作用:利用表达式进行插值,渲染到页面中 表达式:是可以被求值的代码,JS引擎会将其计算出一个结果 …...

VS2022中.Net Api + Vue 从创建到发布到IIS
VS2022中.Net Api Vue 从创建到发布到IIS 前言一、先决条件二、创建项目三、运行项目四、增加API五、发布到IIS六、设置Vue的发布 前言 最近从VS2019 升级到了VS2022,终于可以使用官方的.Net Vue 组合了,但是使用过程中还是有很多问题,这里记录一下. 一、先决条件 Visual …...

RFID技术在制造环节的应用与价值
在现代制造业中,信息化和智能化已经成为企业提升竞争力的重要手段。RFID技术因其非接触式、远距离和高效识别的特点,广泛应用于生产的多个环节。本文将详细解读生产过程中RFID的关键应用场景,并结合实际案例,展示其为制造业带来的…...

(前端基础)HTML(一)
前提 W3C:World Wide Web Consortium(万维网联盟) Web技术领域最权威和具有影响力的国际中立性技术标准机构 其中标准包括:机构化标准语言(HTML、XML) 表现标准语言(CSS) 行为标准…...

Linux文件管理:硬链接与软链接
文章目录 1. 硬链接的设计目的(1)节省存储空间(2)提高文件管理效率(3)数据持久性(4)文件系统的自然特性 2. 软链接的设计目的**(1)跨文件系统引用****&#x…...

pnpm, eslint, vue-router4, element-plus, pinia
利用 pnpm 创建 vue3 项目 pnpm 包管理器 - 创建项目 Eslint 配置代码风格(Eslint用于规范纠错,prettier用于美观) 在 设置 中配置保存时自动修复 提交前做代码检查 husky是一个 git hooks工具(git的钩子工具,可以在特定实际执行特…...
工具】Asteria warp簡単紹介(アステリア ワープ))
【EAI(企业应用集成)工具】Asteria warp簡単紹介(アステリア ワープ)
目录 ■前言 ■Asteria warp簡単紹介 ■ASTERIA Warpとは ■ASTERIA Warp 命名哲学 ■ASTERIA WARPについて ■19年連続国内シェアNo.1 ■10,000社以上の企業での導入実績 ■ノーコードだから誰でも使える ■市场地位:日本市场的绝对王者 ■核心产品力&am…...

内容创作团队如何借助Taotoken灵活调用不同模型优化文案生成
内容创作团队如何借助Taotoken灵活调用不同模型优化文案生成 1. 多模型统一接入的价值 内容创作团队在日常工作中需要处理多种风格的文案需求,从正式商业报告到社交媒体短文,每种场景对语言风格和内容结构的要求各不相同。传统单一模型接入方式往往难以…...

HybridMimic框架:强化学习与质心动力学融合的机器人控制
1. HybridMimic框架解析:当强化学习遇见质心动力学在实验室第一次看到Booster T1人形机器人执行踢腿动作时,我意识到传统控制方法的局限性——那些精心调参的PD控制器在面对动态运动时显得如此笨拙。这正是HybridMimic诞生的背景:一个融合强化…...

【RAG】【node_postprocessor02】Cohere Rerank 重排序功能完整案例
本案例演示如何使用Cohere Rerank重排序器来提高检索增强生成(RAG)系统的检索质量,通过重排序初始检索结果来获取更相关的文档片段。1. 案例目标本案例的主要目标是展示如何:使用LlamaIndex构建基本的向量检索系统集成Cohere Rerank重排序器优化检索结果…...

开源真空吸附机械爪:从气动原理到嵌入式控制的完整实现
1. 项目概述:一个开源硬件驱动的“泵爪”机器人最近在开源硬件和机器人社区里,一个名为clawd800/pumpclaw的项目引起了我的注意。乍一看这个标题,你可能会和我最初一样感到一丝困惑:“泵爪”是什么?是某种新型的机械爪…...

3分钟掌握鸣潮120FPS解锁:WaveTools工具箱终极使用指南
3分钟掌握鸣潮120FPS解锁:WaveTools工具箱终极使用指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 你是否厌倦了《鸣潮》游戏中的60FPS帧率限制?想要让你的高端硬件完全发挥性能…...

08-MLOps与工程落地——模型注册表与模型服务
模型注册表与模型服务(MLflow Model Registry、Seldon Core) 一、模型注册表概述 1.1 什么是模型注册表? import matplotlib.pyplot as plt from matplotlib.patches import Rectangle, FancyBboxPatch import warnings warnings.filterwarni…...

Keras模型推理超快
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 Keras模型推理加速:构建实时AI应用的超快引擎目录Keras模型推理加速:构建实时AI应用的超快引擎 引言&…...

从D435i的深度图反推:如何让OpenCV SGBM的输出更接近工业级传感器效果?
从D435i深度图反推:OpenCV SGBM算法优化实战指南 当你在机器人导航或三维重建项目中对比OpenCV SGBM算法生成的深度图与Intel RealSense D435i输出的结果时,是否发现前者总是显得"平面化"且噪声明显?这背后隐藏着工业级深度传感器在…...

VMware Workstation 虚拟机创建客户端系统,出现此主机不支持64位客户机操作系统问题解决
安装VMware Workstation 虚拟机(版本15.5),选择windows 11 64位是出现此主机不支持64位客户机操作系统.硬件以及系统支持64位。网上找了几个情况1、hyper-v 功能选项是否开启状态,关闭它2、看CPU技术是否支持虚拟技术,打开任务管…...