正则表达式(Regular expresssion)
正则表达式
匹配单次
. :匹配任意一个字符
[ ] :匹配[ ]里举例的任意一个字符
/d :匹配数字0-9
/D :匹配非数字
/s :匹配空白或tab建
/S :匹配非空白
/w :匹配非特殊字符,a-z, A-Z, 0-9, 汉字
/W :匹配特殊字符匹配不定次数
* :匹配前一个字符出现0次到无数次
+ :匹配前一个字符出现至少一次
? :匹配前一个字符出现1次或0次
{m} :匹配前一个字符出现m次
```bash
[0-9]{6}匹配一串字符串的前六个数字。运用场景:假设你爬取到了手机锁屏6位密码数据库中的数据可以用它做筛选
```
{m,n} :匹配前一个字符出现m次到n次
```bash
[0-9a-z_]{8,20}匹配长度8到20位的数字或小写字母或_,可以运用于设置密码格式
```匹配开头或结尾
^ :匹配字符开头
$ :匹配字符结尾
[^指定字符] : 与^[ ]完全相反,匹配不是[ ]里举例字符开头
```bash
[^a]匹配不是以字母a开头
^[a]匹配以字母a开头
```
★匹配分组相关
| :匹配左右两边任意一个正则表达式
text = '123756786SSSSixstar'
text2 = 'abc'
result = re.match('^[0-9]\d*\w*|abc', text2) # 输出:abc
result2 = re.match('^[0-9]\d*\w*|abc', text) # 输出:123756786SSSSixstar
() :将括号作为一个分组。以下面举例解释
你获取了一个有关邮箱的数据库内容,但是你不知道邮箱的格式是qq.com,163.com,139.com
data = ['123756786@qq.com', 'test@139.com', 'jdfasljsafa@163.com']
for i in range(0, len(data)):result = re.match('([\w]{4,20})@(qq.com|139.com|163.com)', data[i])print(result.group())
# 输出:123756786@qq.com
# test@139.com
# jdfasljsafa@163.com
一个括号是一个分组,从左到右是分组1分组2一次类推通过result.group(索引)可以返回不同的值如下
print(result.group(0))
# 输出:123756786@qq.com
# test@139.com
# jdfasljsafa@163.comprint(result.group(2))
# 输出:123756786
# test
# jdfasljsafaprint(result.group(2))
# 输出:qq.com
# 139.com
# 163.com
\num:这里的num就是分组的序号
```python
假设我要提取网页标签中源代码,例如html标签是<html></html>格式的
text = '<html>hello world</html>'
result1 = re.match('<\D*>', text) # 输出:<html>hello world</html>
注: \D*匹配的内容为html>hello world</html
result2 = re.match(r'<(\w*)>\w*\s\w*</\1>', text) # 输出:<html>hello world</html>
注: </\1>中的\1就是匹配的分组1中的\w*也就是html因为结尾也有html所以可以直接引用分组1中的内容
result3 = re.match('<(\w*)>\w*\s\w*</\\1>', text) # 输出:<html>hello world</html>
注: 因为没有使用result2中的r模式所以要防止\1转义因此为\\1但效果一样
print(result3.group())
```
(?P<别名>):分组起别名
(?P=别名):引用别名name匹配分组字符串
```python
以之前的列子为基础进行修改取别名?P<name1>引用别名?P=name1结果如下不变
text = '<html>hello world</html>'
result1 = re.match('<(?P<name1>\w*)>\w*\s\w*</(?P=name1)>', text) # 输出:<html>hello world</html>```
函数
1.re.match(pattern, string)
功能:从字符串起始位置匹配正则表达式。
特点:仅检查字符串开头,若开头不匹配则返回 None。
等效于正则表达式以 ^ 开头。
```python
示例:
re.match(r'abc', 'abc123') # 匹配成功
re.match(r'abc', '123abc') # 匹配失败
```
- re.search(pattern, string)
功能:在整个字符串中搜索第一个匹配项。
特点:不限制匹配位置,找到第一个匹配即返回。
即使字符串中间或结尾有匹配也会成功。
示例:
re.search(r'abc', '123abc456') # 找到 'abc'
- re.findall(pattern, string)
功能:返回所有非重叠匹配项的列表。
特点:无分组时,返回所有完整匹配的字符串列表。
有分组时,返回分组内容的元组列表。
示例:
re.findall(r'\d+', '12 apples, 34 bananas') # ['12', '34']
re.findall(r'(\d)(\w+)', '1a 2b') # [('1', 'a'), ('2', 'b')]
- re.sub(pattern, repl, string)
功能:替换所有匹配项为指定内容。
特点:repl 可以是字符串或函数(动态生成替换内容)。
支持反向引用(如 \1 或 \g<1>)。
示例:
re.sub(r'\d+', 'NUM', 'a1b2') # 'aNUMbNUM'
re.sub(r'(\d{4})-(\d{2})', r'\2/\1', '2023-10') # '10/2023'
- re.split(pattern, string)
功能:按正则表达式分割字符串。
特点:若正则含分组,分隔符会保留在结果中。
支持复杂分隔符(如多字符或模式)。
示例:
re.split(r'\d+', 'a1b22c') # ['a', 'b', 'c']
re.split(r'(\d+)', 'a1b22c') # ['a', '1', 'b', '22', 'c']
练习
练习题
"""
初级题目
提取所有数字
从字符串 "abc123def456ghi789" 中提取所有连续数字(结果应为 ['123', '456', '789'])。匹配邮箱地址
从文本 "联系我:user@example.com 或 admin@test.org" 中提取所有邮箱地址(结果应为 ['user@example.com', 'admin@test.org'])。验证日期格式
检查字符串 "2023-10-05" 是否符合 YYYY-MM-DD 格式(年范围 1900-2099,月 01-12,日 01-31)。"""
str = "abc123def456ghi789"
result = re.findall(r'\d+', str)
print(result)
str2 = "联系我:user@example.com 或 admin@test.org"
result2 = re.findall(r'\b[\w.]+@[\w.]+\.\w+\b', str2)
print(result2)
str3 = "2023-10-30"
result3 = re.match(r'^(19|20)\d{2}-(0[1-9]|1[0-2])-(0[1-9]|1[0-9]|2[0-9]|3[0-1])$', str3)
print(result3.group())
"""
中级题目
提取带区号的电话号码
从 "电话:(021)123-4567 或 022-87654321" 中提取所有电话号码,包括括号和短横线(结果应为 ['(021)123-4567', '022-87654321'])。匹配 HTML 标签内容
从 <div class="title">Hello World</div> 中提取标签内的内容 Hello World(不包含标签本身)。分割混合数据
将字符串 "apple, banana; cherry|orange" 按 , ; | 或空格分割成列表(结果为 ['apple', 'banana', 'cherry', 'orange'])。
"""
str4 = "电话:(021)123-4567 或 022-87654321"
result4 = re.findall(r'\(\d{3}\)\d+-\d+|\d{3}-\d+', str4)
print(result4)
str5 = '<div class="title">Hello World</div>'
result5 = re.sub(r'<[\D]+?>', '', str5)
print(result5)
str6 = "apple, banana; cherry|orange"
result6 = re.split(r'[, ;|]+', str6)
print(result6)
"""
高级题目
排除特定模式
从文本 "error: 404, warn: 302, info: 200 OK" 中提取所有非错误状态码(即排除 error 后的数字,结果为 ['302', '200'])。匹配嵌套 JSON 键值
从简化 JSON 片段 "{\"name\": \"John\", \"age\": 30, \"city\": \"New York\"}" 中提取所有键值对(结果为 ['name', 'John', 'age', '30', 'city', 'New York'])。复杂日期时间提取
从日志 "[2023-10-05 14:30:00] ERROR: System failure" 中提取日期和时间(结果为 ['2023-10-05', '14:30:00'])。
"""
str7 = 'error: 404, warn: 302, info: 200 OK'
result7 = re.findall(r'[0-35][0-9][0-9]', str7)
print(result7)
json_str = "{\"name\": \"John\", \"age\": 30, \"city\": \"New York\"}"
result = re.findall(r'"(\w+)":\s*"([^"]+)"|"(\w+)":\s*(\d+)', json_str)
print(result)
# 合并结果并过滤空值
clean_result = [tuple(filter(None, item)) for item in result]
print(clean_result)
str9 = "[2023-10-05 14:30:00] ERROR: System failure"
result9 = re.findall(r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}', str9)
print(result9)
str10 = "https://example.com/search?q=python&page=2&sort=desc"
result11 = re.findall(r'[?&][\w]+=[\w]+', str10)
result12 = re.findall(r'[^?=&]+=[^&]+', str10)
result13 = re.findall(r'([^?=&]+)=([^&]+)', str10)
print(result11)
print(result12)
print(result13)
相关文章:
)
正则表达式(Regular expresssion)
正则表达式 匹配单次 . :匹配任意一个字符 [ ] :匹配[ ]里举例的任意一个字符 /d :匹配数字0-9 /D :匹配非数字 /s :匹配空白或tab建 /S :匹配非空白 /w :…...

Python的那些事第二十一篇:Python Web开发的“秘密武器”Flask
基于 Flask 框架的 Python Web 开发研究 摘要 在 Web 开发的江湖里,Python 是一位武林高手,而 Flask 则是它手中那把小巧却锋利的匕首。本文以 Flask 框架为核心,深入探讨了它在 Python Web 开发中的应用。通过幽默风趣的笔触,结合实例和表格,分析了 Flask 的特性、优势以…...

MySQL的聚簇索引与非聚簇索引
前言 首先我们要了解到,聚簇索引只能有一个,而非聚簇可以有多个。在本文中可以了解到,范围查询时聚簇索引的优势,以及非聚簇索引在频繁更新时的劣势。 在MySQL中,主键索引通常就是聚簇索引,如果没有显式…...

vscode的一些实用操作
1. 焦点切换(比如主要用到使用快捷键在编辑区和终端区进行切换操作) 2. 跳转行号 使用ctrl g,然后输入指定的文件内容,即可跳转到相应位置。 使用ctrl p,然后输入指定的行号,回车即可跳转到相应行号位置。...

C++11 thread
文章目录 C11 线程库线程对象的构造方式无参的构造函数调用带参的构造函数调用移动构造函数thread常用成员函数 this_thread命名空间join && detachmutex C11 线程库 线程对象的构造方式 无参的构造函数 1、调用无参的构造函数,调用无参的构造函数创建出来的线程对象…...

rabbitmq五种模式的总结——附java-se实现(详细)
rabbitmq五种模式的总结 完整项目地址:https://github.com/9lucifer/rabbitmq4j-learning 一、简单模式 (一)简单模式概述 RabbitMQ 的简单模式是最基础的消息队列模式,包含以下两个角色: 生产者:负责发…...

Qt中基于开源库QRencode生成二维码(附工程源码链接)
目录 1.QRencode简介 2.编译qrencode 3.在Qt中直接使用QRencode源码 3.1.添加源码 3.2.用字符串生成二维码 3.3.用二进制数据生成二维码 3.4.界面设计 3.5.效果展示 4.注意事项 5.源码下载 1.QRencode简介 QRencode是一个开源的库,专门用于生成二维码&…...

Java数据结构---链表
目录 一、链表的概念和结构 1、概念 2、结构 二、链表的分类 三、链表的实现 1、创建节点类 2、定义表头 3、创建链表 4、打印链表 5、链表长度 6、看链表中是否包含key 7、在index位置插入val(0下标为第一个位置) 8、删除第一个关键字key …...

mongodb是怎么分库分表的
在构建高性能的数据库架构时,MongoDB的分库分表策略扮演着至关重要的角色,它通过一系列精细的步骤确保了数据的高效分布与访问。以下是对这一过程的详尽阐述,旨在提供一个清晰且优化过的理解框架。 确定分片键(Shard Key…...

C++自研游戏引擎-碰撞检测组件-八叉树AABB检测算法实现
八叉树碰撞检测是一种在三维空间中高效处理物体碰撞检测的算法,其原理可以类比为一个管理三维空间物体的智能系统。这个示例包含两个部分:八叉树部分用于宏观检测,AABB用于微观检测。AABB可以更换为均值或节点检测来提高检测精度。 八叉树的…...
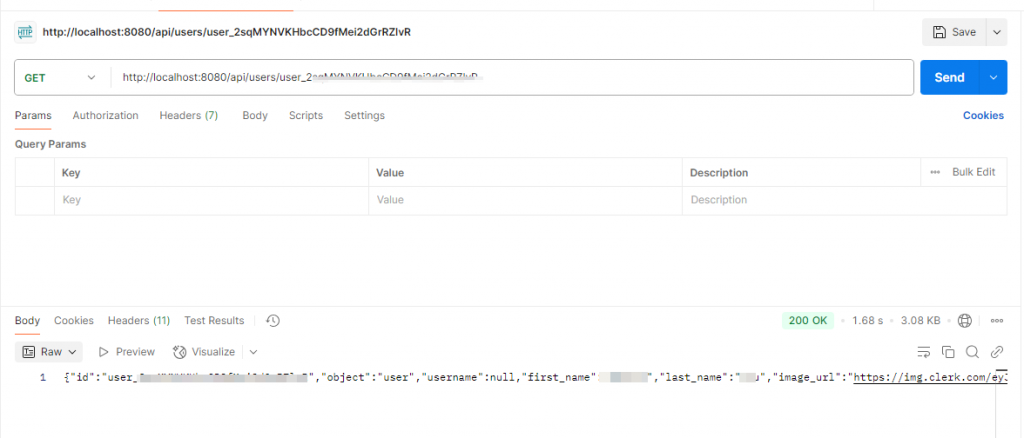
spring boot对接clerk 实现用户信息获取
在现代Web应用中,用户身份验证和管理是一个关键的功能。Clerk是一个提供身份验证和用户管理的服务,可以帮助开发者快速集成这些功能。在本文中,我们将介绍如何使用Spring Boot对接Clerk,以实现用户信息的获取。 1.介绍 Clerk提供…...

一种动态地址的查询
背景 当我们注入一个进程,通过函数地址进行call时经常会遇到这样的一个问题。对方程序每周四会自动更新。更新后之前的函数地址就变化了,然后需要重新找地址。所以,我就使用了一个动态查询的方式。 第一步:先为需要call的函数生…...

周雨彤:用角色与生活,诠释审美的艺术
提到内娱审美优秀且持续在线的女演员,周雨彤绝对是其中最有代表性的一个。 独树一帜的表演美学 作为新生代演员中的实力派代表,周雨彤凭借细腻的表演和对角色的深度共情,在荧幕上留下了多个令人难忘的“出圈”形象。在《我在他乡挺好的》中…...
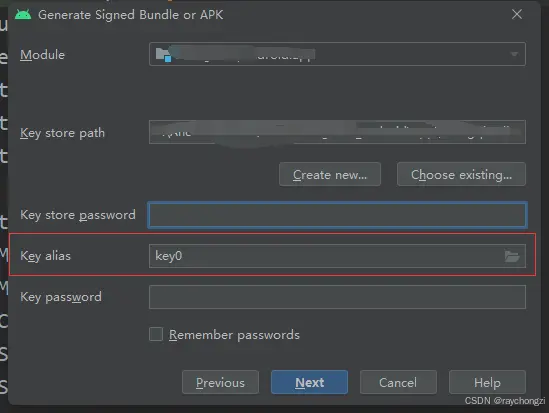
使用jks给空apk包签名
1、在平台官方下载空的apk包(上传应用时有提醒下载) 2、找到jdk目录,比如C:\Program Files\Java\jdk1.8\bin,并把下载的空包apk和jks文件放到bin下 3、以管理员身份运行cmd,如果不是管理员会签名失败 4、用cd定位到…...

500. 键盘行 771. 宝石与石头 简单 find接口的使用
500. 键盘行1 给你一个字符串数组 words ,只返回可以使用在 美式键盘 同一行的字母打印出来的单词。键盘如下图所示。 请注意,字符串 不区分大小写,相同字母的大小写形式都被视为在同一行。 美式键盘 中: 第一行由字符 "qwer…...

仙剑世界手游新手攻略 仙剑世界能用云手机玩吗
欢迎来到《仙剑世界》手游的仙侠世界!作为新手玩家,以下是一些详细的攻略和建议,帮助你快速上手并享受游戏的乐趣。 一、新手职业推荐 1.轩辕:这是一个偏辅助的职业,可以给队友提供输出加成等增益效果,不过…...

[题解]2024CCPC重庆站-小 C 的神秘图形
Sources:K - 小 C 的神秘图形Abstract:给定正整数 n ( 1 ≤ n ≤ 1 0 5 ) n(1\le n\le 10^5) n(1≤n≤105),三进制字符串 n 1 , n 2 ( ∣ n 1 ∣ ∣ n 2 ∣ n ) n_1,n_2(|n_1||n_2|n) n1,n2(∣n1∣∣n2∣n),按如下方法…...
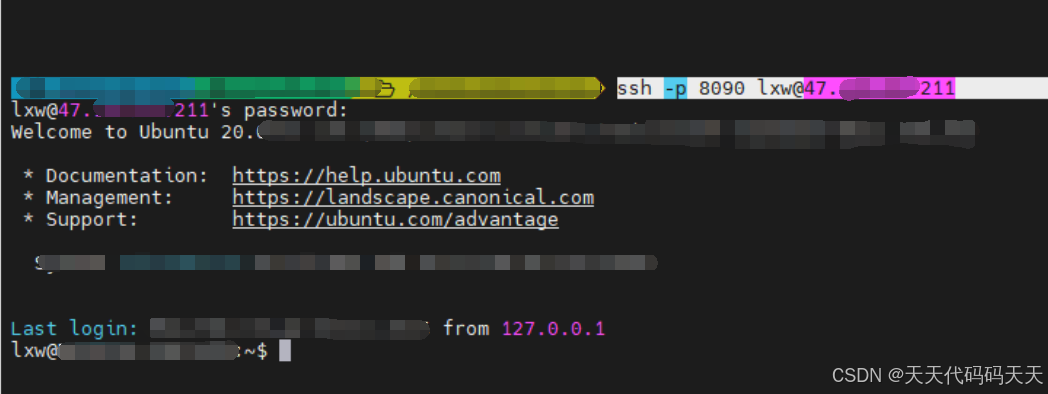
NPS内网穿透SSH使用手册
1、说明 nps-一款轻量级、高性能、功能强大的内网穿透代理服务器 github地址:https://github.com/ehang-io/nps 官网文档地址:https://ehang-io.github.io/nps/#/?idnps 2、服务端 下载地址:https://github.com/ehang-io/nps/releases 下…...
大幂计算和大阶乘计算【C语言】
大幂计算: #include<stdio.h> long long int c[1000000]{0}; int main() {long long a,b,x1;c[0]1;printf("请输入底数:");scanf("%lld",&a);printf("请输入指数:");scanf("%lld",&b…...

【Linux】详谈 进程控制
目录 一、进程是什么 二、task_struct 三、查看进程 四、创建进程 4.1 fork函数的认识 4.2 2. fork函数的返回值 五、进程终止 5.1. 进程退出的场景 5.2. 进程常见的退出方法 5.2.1 从main返回 5.2.1.1 错误码 5.2.2 exit函数 5.2.3 _exit函数 5.2.4 缓冲区问题补…...
)
【SCI复现】三电平NPC变流器中点电位平衡下零序电压的分析与计算研究(Simulink仿真实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
Android Studio新手必看:一招解决Gradle JDK和JAVA_HOME不一致的警告(附环境变量设置图解)
Android开发环境配置:彻底解决Gradle与JDK路径冲突问题 刚接触Android开发时,配置开发环境就像学习骑自行车前的平衡训练——看似简单却总让人手忙脚乱。特别是当Android Studio弹出一堆关于Gradle、JDK、环境变量的警告时,新手往往会陷入&q…...

效率提升:用快马生成win10桌面图标一键配置脚本工具
最近重装了几次Win10系统,每次都要手动调出"我的电脑"、"控制面板"这些常用图标,重复操作特别浪费时间。作为开发者,我决定用InsCode(快马)平台制作一个自动化工具,把这项繁琐工作变成一键操作。 工具设计思路…...

ROS机器人视觉实战:用USB摄像头和OpenCV实现一个简易的‘挥手检测’Demo
ROS机器人视觉实战:用USB摄像头和OpenCV实现挥手检测 想象一下,当你走进实验室,机器人通过摄像头识别到你的挥手动作,立即启动迎宾程序——这种充满未来感的交互,其实用ROS和OpenCV就能轻松实现。本文将带你从零构建一…...

魔兽地图转换与修复终极指南:w3x2lni如何拯救你的地图文件
魔兽地图转换与修复终极指南:w3x2lni如何拯救你的地图文件 【免费下载链接】w3x2lni 魔兽地图格式转换工具 项目地址: https://gitcode.com/gh_mirrors/w3/w3x2lni 你是否曾因魔兽地图版本不兼容而烦恼?是否遇到过重要地图文件损坏却束手无策&…...

Android 14刷机踩坑记:vendor_boot.img大小不对导致fastbootd报‘misc‘分区错误的完整修复流程
Android 14刷机疑难解析:vendor_boot.img镜像校验与misc分区修复全指南 当你在深夜的代码海洋中遨游,终于完成了Android 14内核的定制编译,却在刷机时遭遇那个令人窒息的红色错误提示——failed to open /dev/block/bootdevice/by-name/misc。…...

如何用Python工具突破百度网盘限速?这3个核心技巧让你下载速度提升50倍!
如何用Python工具突破百度网盘限速?这3个核心技巧让你下载速度提升50倍! 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘的蜗牛下载速度…...

V4L2应用程序开发实战:枚举摄像头所有支持的格式和分辨率
V4L2应用程序开发实战:枚举摄像头所有支持的格式和分辨率 这节课我们只做一件事:用手把手的方式,从零写出一个完整的 V4L2 程序,它能列出你的摄像头设备所有支持的像素格式(比如 YUYV、MJPEG)以及每种格式下…...

Windows 11 下用 Node.js 和 crypto-js 逆向分析网站登录密码加密,保姆级实战拆解
Windows 11 下用 Node.js 和 crypto-js 逆向分析网站登录密码加密,保姆级实战拆解 在当今的Web安全领域,前端加密已成为保护用户敏感数据的标配方案。当我们面对一个加密的登录请求时,如何从黑盒状态一步步揭开其加密逻辑?本文将带…...

快速构建kernel32.dll API学习工具:用快马生成安全的函数查询桌面原型
今天想和大家分享一个实用的小工具开发过程——用Python快速构建一个kernel32.dll API学习工具。作为一个Windows开发者,经常需要查阅kernel32.dll中的各种系统API,但直接从网上下载dll文件既不安全也不规范。于是我用InsCode(快马)平台快速生成了一个桌…...