ScoreFlow:通过基于分数的偏好优化掌握 LLM 智体工作流程
25年2月来自 U of Chicago、Princeton U 和 U of Oxford 的论文“ScoreFlow: Mastering LLM Agent Workflows via Score-based Preference Optimization”。
最近的研究利用大语言模型多智体系统来解决复杂问题,同时试图减少构建它们所需的手动工作量,从而推动自动智体工作流优化方法的发展。然而,现有方法在依赖离散优化技术时,由于表征限制、缺乏适应性和可扩展性差,仍然缺乏灵活性。本文用 ScoreFlow 解决这些挑战,这是一个简单但高性能的框架,它利用连续空间中高效的基于梯度优化。ScoreFlow 结合 Score-DPO,一个直接偏好优化(DPO)方法的一种变型,它考虑定量反馈。在涵盖问答、编码和数学推理的六个基准测试中,ScoreFlow 比现有基线提高 8.2%。此外,它使较小的模型能够以较低的推理成本胜过较大的模型。
大语言模型 (LLM) 已证明其在解决自然语言任务方面表现出色 [25, 33, 1, 2, 41, 42]。此外,LLM 的多智体系统(工作流)中,多个智体协调并交换信息以完成任务,这使得基于 LLM 的智体能够协作并解决广泛领域的复杂任务,例如数学问题解决 [47, 38]、问答 [24] 和编码任务 [12, 28]。
然而,这些手动设计的智体工作流需要付出巨大努力,并且处理不同领域任务的能力有限。因此,该领域的新兴重点是通过开发自动化的工作流生成和优化方法来解决静态工作流的局限性。这些优化可以针对各个方面,包括快速细化、超参调整和工作流结构设计 [17, 49, 44, 14, 46, 7, 19, 21, 32, 45]。
自动优化方法可能受到预定义工作流结构固有限制和工作流空间表征的刚性限制 [17, 49, 44, 21]。DyLAN [21] 深思熟虑地强调 LLM 辩论中的通信结构,但忽略其他潜在的通信结构。GPTSwarm [49] 利用基于图的结构并采用强化微调进行优化。然而,图结构中缺乏对条件状态的考虑,对搜索空间施加限制。
为了提高表示能力,AFlow [46] 和 ADAS [14] 使用代码作为工作流的表示,从而促进稳健而灵活的工作流搜索。然而,ADAS 面临着搜索过程效率低下和工作流存储粗糙的挑战,这导致无关数据的积累和复杂性增加,最终降低其有效性。为了解决这些问题,AFlow 采用蒙特卡洛树搜索(MCTS)的变型作为优化方法来提高效率。然而,工作流结构收敛速度过快,再加上离散优化方法,限制搜索空间的探索,常常导致结果不理想。此外,它们都针对整个任务集优化单一工作流,这限制包含各种问题较大数据集的适应性和可扩展性 [45, 32]。
智体工作流优化
针对提示和超参的自动优化。强调提示优化 [11, 44, 40, 17] 或超参优化 [29] 的自动优化方法可以提高性能;但是,它们对工作流结构施加限制,并且通常需要手动修改以适应新任务,从而限制它们的适应性和可扩展性。
工作流结构的自动优化。工作流优化方法 [48, 49, 14, 46, 7, 19, 21, 32, 45] 专注于改进工作流的结构,使其更强大,可以处理各种任务。但是,工作流表征的不灵活性和局限性(例如图结构中条件状态的丢失)可能会限制搜索空间,从而妨碍适应多样化和复杂工作流的能力。
从语言模型的偏好中学习
PPO。近端策略优化 (PPO) [30] 分两个阶段处理偏好反馈。首先,在偏好数据集 D_R 上训练奖励模型 R_φ,其中每个条目 (x, y_w, y_l) 由提示 x、首选响应 y_w 和拒绝响应 y_l 组成。通过最小化以下损失函数来优化奖励模型,该函数的灵感来自 Bradley-Terry (BT) 模型 [5],用于对排名(pair-ranking)。
接下来,通过最大化分配给其生成响应的奖励来完善策略模型 π_θ,同时保持软 KL 散度约束以防止退化。
DPO。直接偏好优化 (DPO) [27] 使用偏好数据促进直接策略优化,无需显式奖励模型或主动策略采样。这种方法提高优化过程的效率和稳定性。从上述策略模型目标函数的闭式解中,隐式奖励可以表示为 R_φ(x, y) = β log π_θ^⋆ (y | x)/π_ref (y | x) + βZ(x),其中 π_θ^⋆ 是最优策略,Z(x) 是分区函数。然后可以使用上述奖励目标直接优化策略模型,从而导致 DPO 损失。
ScoreFlow 是一种自动化且经济高效的多智体工作流生成框架,它采用优化方法来实现高性能、可扩展性和适应性。其流程如下:

ScoreFlow 的推理过程概述,如图所示。给定数学任务 A 和 B,以及可选择的智体类型(程序员、可自定义操作员、集成操作员和审阅人),将为每个任务生成一个基于 Python 的工作流,其中工作流 A 和 B 的智体集分别包含一个和五个状态。然后将每个任务输入到其各自的工作流中以产生执行结果。

现在将 LLM 多智体工作流优化问题和一些符号形式化如下。
给定一个输入任务 q,格式化为提示,希望确定解决此任务的最佳工作流 G(q),其中 G 是工作流生成器。工作流函数 W_f 定义为某个任务 q 和智体集 V ,(q,V)的集成到执行结果 W_f (q,V) 的映射,通常是该任务的解决方案。智体集 V 由一组智体组成,每个智体都以其系统提示、温度设置和其他相关参数为特征。然后,将工作流定义为智体集和工作流函数的组合:(V,W_f)。定义工作流搜索空间为:W = {(V,W_f)| V ⊂ V,(V,W_f)满足条件 C},其中 V 表示整个智体空间。
条件 C 对搜索空间施加约束,使得 W_f 对于智体集 V 是可执行的。给定这些符号,优化目标是确定最佳的工作流生成器:

其中 D 表示任务数据集,S 是针对任务 q 执行工作流 G(q) 所生成结果的第三方评估器,例如人工提供的分数、平均胜率或其他相关指标。
使用代码作为工作流函数 W_f [14, 46] 的表示可以解释线性序列、循环、条件逻辑,并提供超出图或网络结构的灵活性。此外,按照 Aflow [46],将 V 中的智体表征为操作员。操作员是预定义的、可重复使用的智体节点组合,代表常见操作,例如程序员、审阅员、校对员、问答操作员、集成操作员、测试操作员和可定制操作员等。通过允许生成器 G 自定义操作员内的系统提示,实现提示的优化,扩展智体空间 V,丰富搜索空间 W。
为了使工作流适应输入任务 q,即根据输入问题调整所选的操作员和生成工作流的结构复杂性,需要从 q 中提取语义信息。具体来说,用一个开源的预训练大语言模型作为生成器 G 的基础模型。生成器的输入包括任务 q 和生成指南的组合,包括格式要求和可用操作员的介绍,所有这些都被格式化为一个指导提示。
直接使用 DPO 对收集的偏好数据进行生成器微调,会导致收敛速度慢并且无法达到最佳性能。这些问题是由于评估分数中的错误和方差造成的。本文提出一种广泛适用的优化方法 Score-DPO,这是 DPO 的改进版,旨在解决这些挑战。本文实验证明 Score-DPO 在优化 LLM 工作流生成器方面的优势,表明它适用于类似的设置。
增强的采样分布。在设置中应用 DPO 时观察的收敛速度慢和性能不佳,可以归因于收集的偏好数据不准确,这是由评估分数中不可避免的方差和误差造成的。为了解决这个问题,建议增加样本对 (w, l) 的权重,使分数差异 s_w − s_l 更大。具体来说,引入一个函数 d(x, y) : [0, 1]2 → [0, 1],该函数关于 x − y 严格单调递增。然后,根据 P^⋆(w, l) ∝ d(s_w, s_l)P(w, l) 增加得分差异较大的数据对采样概率,通过增加其可能性来提高权重,其中 P(w, l) 表示偏好数据集 D_pre 上的均匀随机采样分布。此调整可确保在采样过程中优先考虑得分差异较大的对,从而提高优化过程的有效性。
将评估分数纳入排名目标。Bradley-Terry (BT) [5] 排名目标 σ(r_w −r_l) 有一些替代公式,比 DPO [23, 4, 26] 更有效,其中 r_w := β log(π_θ(y_w|x)/π_ref (y_w|x)) 和 r_l := β log(π_θ(yl|x)/π_ref (yl|x))。在设置中,结合评估分数来指导隐性奖励。具体来说,将基于分数的 BT 排名目标定义为 σ(r_w⋆ − r_l⋆),其中 r_w⋆ := f(s_w)r_w,r_l^⋆ := (1 − f(s_l))r_l,f(x) : [0, 1] → [0, 1] 是严格单调递增函数。从经验上讲,这种方法可确保,具有更确定性评估分数的数据点,对损失函数的影响更大。最后,将 Score-DPO 的损失函数定义为

虽然 DPO 很难有效地学习偏好排名 [6],但以下定理将证明这种分数-指导方法将每个样本对优化目标的影响与其评估分数的大小相一致。
为了使分析形式化,引入符号来量化每个特定样本对优化目标的影响。
定义 1(每个样本的影响)。对于给定的样本 z,z 对目标函数的影响(称为每个样本的影响)定义为:

每个样本的影响 I(z) 是样本 z 贡献的梯度,表示 z 对优化目标的定量影响。当 I(z) > 0 时,优化过程会增加 z 的对数,使其更有可能被优先考虑。当 I(z) < 0 时,它会降低 z 的对数,使其不太可能被优先考虑。以下定理 2 展示分数指导对 I(z) 的影响。
定理 2。假设函数 d(x, y) : [0, 1]^2 → [0, 1] 关于 x − y 严格单调递增,函数 f(x) : [0,1] → [0,1] 关于 x 严格单调递增。样本 z 的每个样本影响由以下公式给出:

当 −(1 − f(s_z))−1 ≤ r_z ≤ f^−1(s_z) 成立时,该影响随得分 s_z 严格单调递增。
因此,Score-DPO 可以将得分信息纳入自采样偏好优化中,使优化过程能够考虑定量信息,而不是仅使用赤裸裸偏好对信息,并且可以减少得分不准确造成的误差和方差。请注意,定理 2 中所述的条件不是限制性的,因为 |r_z | ≤ 1 为其有效性提供充分条件。此外,实验结果表明,在收敛之前的优化过程中,|r_z| ≤ 1 成立的概率约为 91.1%。
最后总结的算法如下:

数据集。专注于六个公共数据集,涵盖一系列任务,包括数学问题、问答问题和编码问题。具体来说,利用 HumanEval [8] 和 MBPP [3] 的完整数据集。按照 Aflow [46] 的方法,对于 GSM8K [9],在测试集中使用 1,319 个数据点。对于 MATH 数据集,为了强调高级和具有挑战性的问题,从以下问题类型中选择难度级别为 5 的问题:组合和概率、数论、初等代数和初等微积分,就像 Hong [12] 所做的那样。对于 DROP [10] 和 HotpotQA [43],遵循 Hu [14]、Shinn [31] 和 Zhang [46] 概述的方法,从每个数据集中随机选择 1,000 个样本。使用 1:4 的比例将数据分成验证集和测试集。
基线。手动设计的静态工作流基线包括:直接 LLM 调用、思维链 [36]、自洽性 CoT(对集成生成 5 个响应)[34]、MedPrompt(3 个响应和 5 张票)[24]、多人辩论 [35] 和自我优化(2 轮)[22]。还与代码表示自动化工作流优化方法进行比较:ADAS [14] 和 Aflow [46],其中使用 GPT-4o-mini 作为它们的优化模型。将 Aflow 的迭代轮数设置为 20,如 Zhang [46] 所述。
模型。默认情况下,用 Llama-3.1-8B-Instruct 作为生成器的基础模型(使用 vLLM [18] 进行推理),并使用 GPT-4o-mini 作为执行器(通过 API 进行推理,温度为 0)。在消融研究中,用 Qwen2.5-7B-Instruct [39] 作为生成器,并使用 GPT-4o 和 DeepSeek 系列模型 [20] 作为执行器。所有实验均使用 2 个 A6000 GPU 和 LoRA [13]。
指标和评估分数。在最终结果中报告解决率(评估 3 次并取平均值)。用 GPT-4o-mini 作为 MATH、DROP 和 HotpotQA 的评判模型,以避免格式不一致问题。在优化过程的每次迭代中(总共 3 次迭代),为每个问题生成 k = 8 个工作流并获得它们的评估分数,其中不使用判断模型来降低成本和计算开销。具体来说,用 F1 分数作为 DROP 和 HotpotQA 的评估指标,并解决剩余数据集的速率(评估 3 次并取平均值)。为了应用 Score-DPO,将 f (x) = x 和 d(x, y) = (x − y)^3 设置为默认选择。
相关文章:
ScoreFlow:通过基于分数的偏好优化掌握 LLM 智体工作流程
25年2月来自 U of Chicago、Princeton U 和 U of Oxford 的论文“ScoreFlow: Mastering LLM Agent Workflows via Score-based Preference Optimization”。 最近的研究利用大语言模型多智体系统来解决复杂问题,同时试图减少构建它们所需的手动工作量,从…...

数字水印嵌入及提取系统——基于小波变换GUI
数字水印嵌入及提取系统——基于小波变换GUI 基于小波变换的数字水印系统(Matlab代码GUI操作) 【有简洁程序报告】【可作開题完整文档达辩PPT】 本系统主要的内容包括: (1)使用小波变换技术实现二值水印图像的加密、…...

基于海思soc的智能产品开发(图像处理的几种需求)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 对于一个嵌入式设备来说,如果上面有一个camera,那么就可以有很多的用途。简单的用途就是拍照,比拍照更多一点的…...

【R语言】聚类分析
聚类分析是一种常用的无监督学习方法,是将所观测的事物或者指标进行分类的一种统计分析方法,其目的是通过辨认在某些特征上相似的事物,并将它们分成各种类别。R语言提供了多种聚类分析的方法和包。 方法优点缺点适用场景K-means计算效率高需…...

Spring 项目接入 DeepSeek,分享两种超简单的方式!
⭐自荐一个非常不错的开源 Java 面试指南:JavaGuide (Github 收获148k Star)。这是我在大三开始准备秋招面试的时候创建的,目前已经持续维护 6 年多了,累计提交了 5600 commit ,共有 550 多位贡献者共同参与…...

docker 进阶命令(基于Ubuntu)
数据卷 Volume: 目录映射, 目录挂载 匿名绑定: 匿名绑定的 volume 在容器删除的时候, 数据卷也会被删除, 匿名绑定是不能做到持久化的, 地址一般是 /var/lib/docker/volumes/xxxxx/_data 绑定卷时修改宿主机的目录或文件, 容器内的数据也会同步修改, 反之亦然 # 查看所有 vo…...

机器学习数学基础:29.t检验
t检验学习笔记 一、t检验的定义和用途 t检验是统计学中常用的假设检验方法,主要用于判断样本均值与总体均值间,或两个样本均值间是否存在显著差异。 在实际中应用广泛,例如在医学领域可用于比较两种药物的疗效;在教育领域&…...

HarmonyNext上传用户相册图片到服务器
图片选择就不用说了,直接用 无须申请权限 。 上传图片,步骤和android对比稍微有点复杂,可能是为了安全性考虑,需要将图片先拷贝到缓存目录下面,然后再上传,当然你也可以转成Base64,然后和服务…...

WebAssembly 3.0发布:浏览器端高性能计算迎来新突破!
“WebAssembly 3.0来了,浏览器端的高性能计算将彻底改变!”2025年,WebAssembly(Wasm)迎来了重大更新——WebAssembly 3.0正式发布。这次更新不仅支持多线程和SIMD指令集,还优化了内存管理,让浏览…...

计算机组成原理—— 外围设备(十三)
记住,伟大的成就往往诞生于无数次尝试和失败之后。每一次跌倒,都是为了让你学会如何更加坚定地站立;每一次迷茫,都是为了让你找到内心真正的方向。即使前路漫漫,即使困难重重,心中的火焰也不应熄灭。它代表…...

面试题之Vuex,sessionStorage,localStorage的区别
Vuex、localStorage 和 sessionStorage 都是用于存储数据的技术,但它们在存储范围、存储方式、应用场景等方面存在显著区别。以下是它们的详细对比: 1. 存储范围 Vuex: 是 Vue.js 的状态管理库,用于存储全局状态。 数据存储在内…...

window中git bash使用conda命令
window系统的终端cmd和linux不一样,运行不了.sh文件,为了在window中模仿linux,可以使用gui bash模拟linux的终端。为了在gui bash中使用python环境,由于python环境是在anaconda中创建的,所以需要在gui bash使用conda命…...
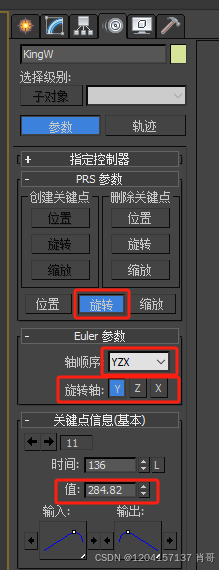
象棋掉落动画(局部旋转动画技巧)
1.被撞击阶段:根据被撞击速度,合理设置被撞距离 2.倒地阶段:象棋倒地的同时稍微前移 3.滚地阶段:象棋滚地后停止,在最后5帧内稍微回转一下。这里启用“PRS参数”的旋转来制作局部旋转动画...

Pycharm 2024在解释器提供的python控制台中运行py文件
2024版的界面发生了变化, run with python console搬到了这里:...

课题推荐:高空长航无人机多源信息高精度融合导航技术研究
高空长航无人机多源信息高精度融合导航技术的研究,具有重要的理论意义与应用价值。通过深入研究多源信息融合技术,可以有效提升无人机在高空复杂环境下的导航能力,为无人机的广泛应用提供强有力的技术支持。希望该课题能够得到重视和支持&…...

《DeepSeek训练算法:开启高效学习的新大门》
在人工智能的浪潮中,大语言模型的发展日新月异。DeepSeek作为其中的佼佼者,凭借其独特的训练算法和高效的学习能力,吸引了众多目光。今天,就让我们深入探究DeepSeek训练算法的独特之处,以及它是如何保证模型实现高效学…...

promise用法总结以及手写promise
JavaScript中的 Promise 是用于处理异步操作的对象,它代表了一个异步操作的最终完成(或失败)及其结果值。Promise 是异步编程的一种更简洁和更可读的方式,避免了回调地狱的问题。 Promise 的基本概念 一个 Promise 是一个表示异步…...

春招项目=图床+ k8s 控制台(唬人专用)
1. 春招伊始 马上要春招了,一个大气的项目(冲击波项目)直观重要,虽然大家都说基础很重要,但是一个足够新颖的项目完全可以把你的简历添加一个足够闪亮的点。 这就不得不推荐下我的 k8s 图床了,去年折腾快…...

Android 11.0 系统settings添加ab分区ota升级功能实现二
1.概述 在11.0的系统rom定制化开发中,在进行系统ota升级的功能中,在10.0以前都是使用系统 RecoverySystem的接口实现升级的,现在可以实现AB分区模式来进行ota升级的,但是 必须需要系统支持ab分区升级的模式才可以的,接下来分析下看怎么样进行ota升级功能实现 2.系统sett…...

【Spring+MyBatis】_图书管理系统(上篇)
目录 1. MyBatis与MySQL配置 1.1 创建数据库及数据表 1.2 配置MyBatis与数据库 1.2.1 增加MyBatis与MySQL相关依赖 1.2.2 配置application.yml文件 1.3 增加数据表对应实体类 2. 功能1:用户登录 2.1 约定前后端交互接口 2.2 后端接口 2.3 前端页面 2.4 单…...

终极指南:如何在Vim中使用syntastic实现Kotlin语法检查
终极指南:如何在Vim中使用syntastic实现Kotlin语法检查 【免费下载链接】syntastic Syntax checking hacks for vim 项目地址: https://gitcode.com/gh_mirrors/sy/syntastic syntastic是一款强大的Vim插件,为开发者提供实时语法检查功能…...
)
Python跨端二进制交付前必须执行的7步标准化测试协议(附可直接落地的pytest-xdist+docker-compose验证套件)
更多请点击: https://intelliparadigm.com 第一章:Python跨端二进制交付的底层挑战与标准化必要性 Python 作为解释型语言,其“跨平台”本质依赖于目标环境预装兼容版本的 CPython 解释器。当面向无 Python 运行时的终端(如嵌入式…...

OmniFusion多模态翻译系统架构与优化实践
1. 项目背景与核心价值在全球化交流日益频繁的今天,语言障碍仍然是横亘在不同文化群体之间的无形屏障。传统翻译工具往往只能处理单一语言对的转换,且对多模态内容(如包含文字、图像、语音的混合内容)的支持有限。OmniFusion项目的…...

MiGPT开源项目:让小爱音箱秒变AI语音助手的技术改造指南
MiGPT开源项目:让小爱音箱秒变AI语音助手的技术改造指南 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 你是否曾对小爱音箱的"…...

Word论文排版避坑指南:用页眉插入背景图解决PDF导出重叠,以及参考文献页眉‘0’的终极解法
Word论文排版实战:页眉背景图与参考文献页眉零误差解决方案 引言 学术写作从来不是件轻松的事——当你熬过无数个深夜终于完成论文内容,却在最后排版阶段被Word的"任性"折磨得抓狂。背景图在PDF导出时莫名重叠、参考文献页眉顽固显示"0&q…...

FluxCD v2实战:基于Kustomize与Helm的GitOps自动化部署指南
1. 项目概述:一个声明式GitOps的实战演练场如果你正在寻找一个能帮你快速上手FluxCD v2,并理清它如何与Kustomize和Helm协同工作的“一站式”示例项目,那么fluxcd/flux2-kustomize-helm-example这个官方仓库就是你梦寐以求的宝藏。它不是一个…...

UE5新手别慌!从Canvas画布到按钮交互,手把手带你搞定第一个HUD界面
UE5新手实战:从零构建可交互HUD界面的完整指南 第一次打开虚幻引擎5的UI编辑器时,满屏的专业术语和复杂面板确实容易让人望而生畏。但别担心,今天我们就用一个完整的微型HUD项目作为切入点,带你体验从空白画布到功能齐全的交互界面…...
)
C盘告急别慌!保姆级教程:用WSL2自带命令把Ubuntu搬到D盘(附默认用户修复)
C盘空间告急?WSL2迁移至D盘的完整解决方案与深度优化指南 每次打开资源管理器看到C盘那刺眼的红色警告条,心跳是不是都会漏跳一拍?作为Windows开发者,我们既依赖WSL2带来的Linux开发便利,又苦于它不断蚕食宝贵的C盘空间…...

智能代码生成工具ReflexiCoder:强化学习驱动的开发革命
1. 项目背景与核心价值在软件开发领域,代码生成工具正逐渐从简单的模板填充演变为具备一定智能的辅助系统。传统代码生成器通常依赖预定义规则和有限上下文,难以应对复杂多变的编程需求。ReflexiCoder的突破性在于将强化学习机制引入代码生成过程&#x…...

MySQL事务、隔离级别、数据库锁
文章目录一、先搞懂:到底什么是MySQL事务?1.1 事务ACID四大特性(对应英文\核心作用)二、必懂基础:脏读、不可重复读、幻读到底是什么?2.1 脏读(读到别人没提交的作废数据)2.2 不可重…...